
附面试思维导图:
Hadoop面试题
- 讲述HDFS上传文件和读文件的流程?
- HDFS在上传文件的时候,如果其中一个块突然损坏了怎么办?
- NameNode的作用?
- 4.NameNode在启动的时候会做哪些操作?
- NameNode的HA?
- Hadoop的作业提交流程?
- Hadoop怎么分片?
- 如何减少Hadoop Map端到Reduce端的数据传输量?
- Hadoop的Shuffle?
- 哪些场景才能使用Combiner呢?
- HMaster的作用?
- 如何实现hadoop的安全机制?
- hadoop的调度策略的实现,你们使用的是那种策略,为什么?
- 数据倾斜怎么处理?
- 评述hadoop运行原理?
- 简答说一下hadoop的map-reduce编程模型?
- hadoop的TextInputFormat作用是什么,如何自定义实现?
- map-reduce程序运行的时候会有什么比较常见的问题?
- Hadoop平台集群配置、环境变量设置?
- Hadoop性能调优?
- .Hadoop高并发?
- Hadoop配置文件以及简单的Hadoop集群搭建
- Hadoop参数调优
- Hadoop宕机
- Hadoop 高可用配置
- 配置 HDFS-HA集群
- 配置HDFS-HA自动故障转移
- 配置Yarn-HA

HBase面试题
- HBase的特点是什么?
- HBase和Hive有什么区别?
- HBase的rowkey 设计原则
- HBase中的scan和get的功能以及实现的异同
- 请描述Hbase中scan对象的setCache和setBatch 方法的使用
- 以 start-hbase.sh 为起点,Hbase 启动的流程是什么?
- 简述 HBASE中compact用途是什么,什么时候触发,分为哪两种,有什么区别,有哪些相关配置参数?
- HBase 如何给WEB前端提供接口来访问?
- HBase的导入导出方式
- HBase搭建过程中需要注意什么?
spark面试题
- Spark的Shuffle原理及调优?
- hadoop和spark使用场景?
- spark如何保证宕机迅速恢复?
- hadoop和spark的相同点和不同点?
- RDD持久化原理?
- checkpoint检查点机制?
- checkpoint和持久化机制的区别?
- Spark Streaming和Storm有何区别?
- RDD机制?
- Spark streaming以及基本工作原理?
- DStream以及基本工作原理?
- spark有哪些组件?
- spark工作机制?
- Spark工作的一个流程?
- spark核心编程原理?
- spark基本工作原理?
- spark性能优化有哪些?
- updateStateByKey详解?
- 宽依赖和窄依赖?
- spark streaming中有状态转化操作?
- spark常用的计算框架?
- spark整体架构?
- Spark的特点是什么?
- 搭建spark集群步骤?
- Spark的三种提交模式是什么?
- spark内核架构原理?
- Spark yarn-cluster架构?
- Spark yarn-client架构?
- SparkContext初始化原理?
- Spark主备切换机制原理剖析?
- spark支持故障恢复的方式?
- spark解决了hadoop的哪些问题?
- 数据倾斜的产生和解决办法?
- spark 实现高可用性:High Availability?
- spark实际工作中,是怎么来根据任务量,判定需要多少资源的?
- spark中怎么解决内存泄漏问题?
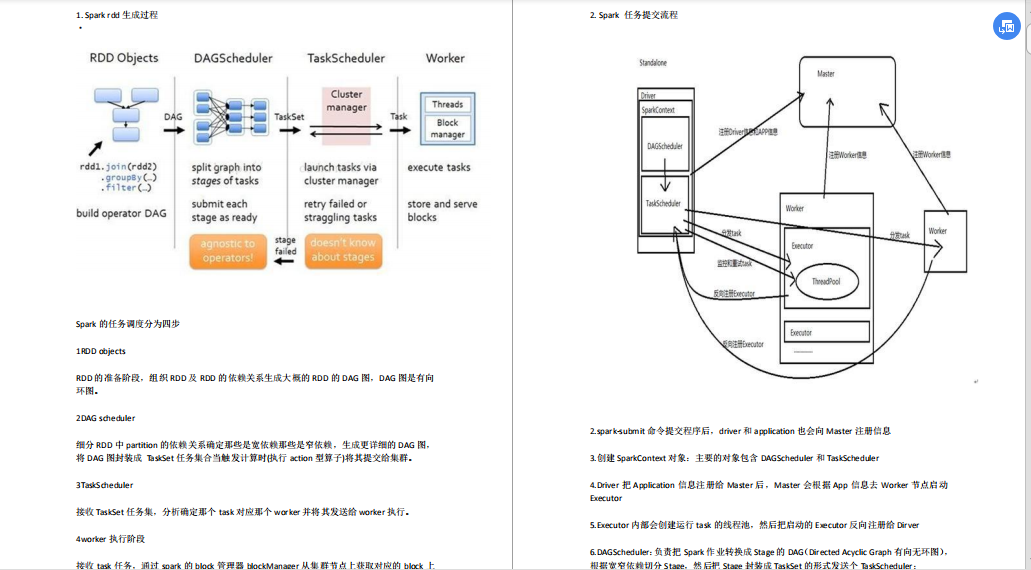

Zookeeper面试题
- zookeeper是什么框架?
- 有哪些应用场景?
- 使用什么协议?
- 说说分布式一致性算法Paxos
- 说一说选举算法及流程
- zookeeper有哪几种节点类型?
- zookeeper对节点的watch监听通知是永久的吗?
- 有哪几种部署模式?
- 集群中的机器角色都有哪些?
- 集群最少要几台机器,集群规则是怎样的
- 集群如果有3台机器,挂掉一台集群还能工作吗?挂掉两台呢?
- 集群支持动态添加机器吗?
- zookeeper的java客户端都有哪些?
- chubby是什么,和zookeeper比你怎么看?
- 说几个zookeeper常用的命令。


针对以上问题小编已经整理好了 面试题+答案文档,除了这份面试专题文档,小编者里还有一些针对性的实战文档都可以免费提供给大家学习。
本文转载自: https://blog.csdn.net/m0_55849656/article/details/125262118
版权归原作者 m0_55849656 所有, 如有侵权,请联系我们删除。
版权归原作者 m0_55849656 所有, 如有侵权,请联系我们删除。