
大数据框架

kafka目的是为了缓冲。
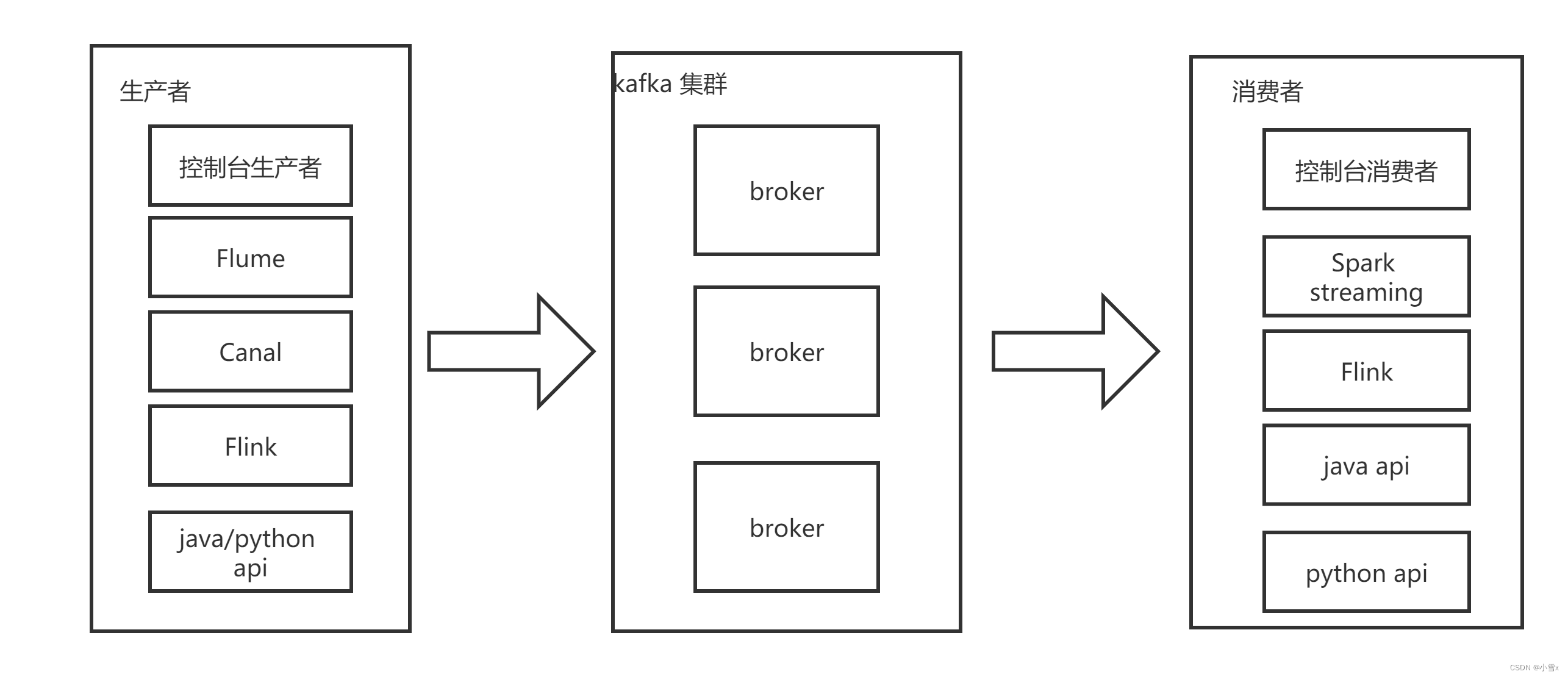
1、Kafka简介
1.1什么是kafka
kafka是一个高吞吐的分布式消息系统,实时数据存储。
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列。相当于银行办理业务,进行排队。
分区:分布式
副本:容错性
1.2 kafka的特点
- 消息系统的特点:生存者消费者模型,FIFO
- 高性能:单节点支持上千个客户端,百MB/s吞吐
- 持久性:消息直接持久化在普通磁盘上且性能好
- 分布式:数据副本冗余、流量负载均衡、可扩展
- 很灵活:消息长时间持久化+Client维护消费状态
1.3 kafka性能好的原因
- kafka写磁盘是顺序的,所以不断的往前产生,不断的往后写
- kafka还用了sendFile的0拷贝技术,提高速度
- 而且还用到了批量读写,一批批往里写,64K为单位
2、Kafka搭建
kafka集群

2.1搭建kafka
2.1.1上传解压修改环境变量
解压
tar -xvf kafka_2.11-1.0.0.tgz
配置环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/soft/kafka_2.11-1.0.0
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
2.1.2修改配置文件
vim config/server.properties
broker.id=0 每一个节点broker.id 要不一样
zookeeper.connect=master:2181,node1:2181,node2:2181/kafka
log.dirs=/usr/local/soft/kafka_2.11-1.0.0/data 数据存放的位置
2.1.3将kafka文件同步到node1,node2
同步kafka文件
scp -r kafka_2.11-1.0.0/ node1:
pwd
scp -r kafka_2.11-1.0.0/ node2:pwd将master中的而环境变量同步到node1和node2中
scp /etc/profile node1:/etc/
scp /etc/profile node2:/etc/在ndoe1和node2中执行source
source /etc/profile
2.1.4修改node1和node2中的broker.id
vim config/server.properties
node1
broker.id=1
node2
broker.id=2
2.1.5启动kafka
1、需要先穷zookeeper, kafka使用zo保存元数据
需要在每隔节点中执行启动的命令
zkServer.sh start
查看启动的状体
zkServer.sh status
2、启动kafka,每个节点中都要启动(去中心化的架构)
-daemon后台启动
kafka-server-start.sh -daemon /usr/local/soft/kafka_2.11-1.0.0/config/server.properties
测试是否成功
#生产者
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic shujia消费者
--from-beginning 从头消费,, 如果不在执行消费的新的数据
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic shujia
2.2 使用kafka
1、创建topic
在生产和消费数据时,如果topic不存在会自动创建一个分区为1,副本为1的topic
--replication-factor ---每一个分区的副本数量, 同一个分区的副本不能放在同一个节点,副本的数量不能大于kafak集群节点的数量
--partition --分区数, 根据数据量设置
--zookeeper zk的地址,将topic的元数据保存在zookeeper中设定分区数为3,副本数为2
kafka-topics.sh --create --zookeeper master:2181,node1:2181,node2:2181/kafka --replication-factor 2 --partitions 3 --topic bigdata
2、查看topic描述信息
kafka-topics.sh --describe --zookeeper master:2181,node1:2181,node2:2181/kafka --topic bigdata

分区1在leader1节点上,副本在1,2节点上
副本保证高可用,一个节点挂了,会自动主备切换。
bigdata-1,1表示分区编号。
bigdata-2,是表示分区2的副本在该节点上。

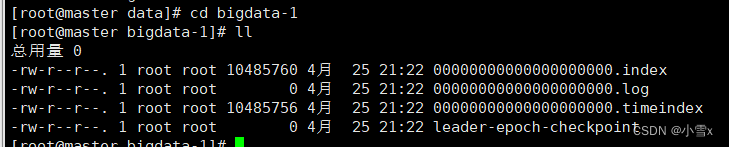
** .index索引文件**
.log表示数据文件
.timeindex 时间文件保存分区创建的时间,默认七天,删除该log文件
3、获取所有topic
__consumer_offsetsL kafka用于保存消费便宜量的topic
kafka-topics.sh --list --zookeeper master:2181,node1:2181,node2:2181/kafka
4、创建控制台生产者
kafka-console-producer.sh --broker-list
master:9092,node1:9092,node2:9092 --topic bigdata
**5、创建控制台消费者 **
--from-beginning 从头消费,, 如果不在执行消费的新的数据
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic bigdata
2.3 kafka数据保存的方式
1、保存的文件
/usr/local/soft/kafka_2.11-1.0.0/data2,每一个分区,每一个副本对应一个目录
3、每一个分区目录中可以有多个文件, 文件时滚动生成的,7天后会默认删除
00000000000000000000.log
00000000000000000001.log
00000000000000000002.log4、滚动生成文件的策略
文件大小1G:log.segment.bytes=1073741824
每隔100秒检查一下:log.retention.check.interval.ms=3000005、文件删除的策略,默认时7天,以文件为单位删除
log.retention.hours=168
3、Kafka架构

- producer:消息生存者
- consumer:消息消费者
- broker:kafka集群的server, 就是节点,有多个,多个节点就构成了kafka集群(master,node1,node2)。负责处理消息读、写请求,存储消息(/kafka....../data/)。
- topic:可以理解为一个队列,生产者和消费者面对一个队列。一个topic就是一个目录,一个表,一组数据,会自动创建。
- zookeeper:这个架构里面有些元信息是存在zookeeper上面的,整个集群的管理也和zookeeper有很大的关系
- partiton:一个非常大的Topic可以分布到多个Broker上(分布式),一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)。每个partition内部消息强有序,其中的每个消息都有一个序号叫offset。一个partition只对应一个broker,一个broker可以管多个partition。
- Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower。同一个分区的副本不能放在同一个节点。
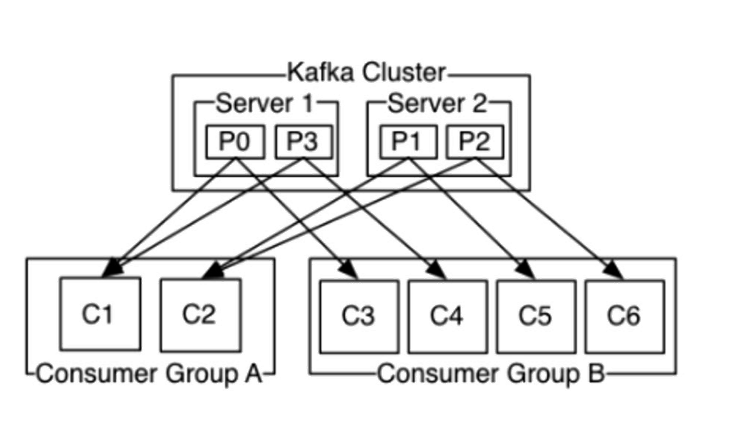
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
kafka的消息存储和生产消费模型,注意:
- 一个topic分成多个partition
- 每个partition内部消息强有序,其中的每个消息都有一个序号叫offset
- 一个partition只对应一个broker,一个broker可以管多个partition
- 消息不经过内存缓冲,直接写入文件
- 根据时间策略删除,而不是消费完就删除。默认是7天。
- producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
- consumer自己维护消费到哪个offset
- 每个consumer都有对应的group
- group内是queue消费模型
- 各个consumer消费不同的partition 因此一个消息在group内只消费一次
- group间是publish-subscribe消费模型
- 各个group各自独立消费,互不影响 因此一个消息在被每个group消费一次

4、Kafka Java API
通过java代码生产数据。
1、增加依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.0.0</version> </dependency>
2、创建生产者
val properties = new Properties()
//kafka集群的列表
properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092")//数据key和value的格式
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")//创建生产者,相当于和kafka建立连接
val producer = new KafkaProducerString, String
3、代码:
package com.shujia.kafka
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import java.util.Properties
object Demo1KafkaProducer {
def main(args: Array[String]): Unit = {
/**
* 1、创建生产者
*/
val properties = new Properties()
//kafka集群的列表
properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092")
//数据key和value的格式
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//创建生产者,相当于和kafka建立连接
val producer = new KafkaProducer[String, String](properties)
//构建一行,指定topic和数据
val record = new ProducerRecord[String, String]("bigdata", "大数据")
//发送数据到kafka中
producer.send(record)
//关闭连接
producer.close()
}
}
5、Kafak python API
5.1、通过python代码生产数据
from kafka import KafkaProducer
# 安装依赖 pip install kafka-python
if __name__ == '__main__':
# 1、创建生产者
producer = KafkaProducer(bootstrap_servers="master:9092,node1:9092,node2:9092")
# 2、生产数据
producer.send(topic="bigdata", value="大数据".encode("utf-8"))
# 3、将数据刷新到kafka中
producer.flush()
# 4、关闭连接
producer.close()
5.1、读取文件,批量的把数据写入kafka
from kafka import KafkaProducer
if __name__ == '__main__':
# 创建生产者
producer = KafkaProducer(bootstrap_servers="master:9092,node1:9092,node2:9092")
# 读取文件
with open("../data/cars_sample.json", mode="r", encoding="UTF-8") as file:
cars = file.readlines()
# 循环将数据写入kafka
for car in cars:
# 发送数据到kafka
producer.send(topic="cars", value=car.strip().encode("UTF-8"))
producer.flush()
producer.close()
5.3、通过pythondaima消费数据
from kafka import KafkaConsumer
if __name__ == '__main__':
# earliest
# 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest 默认
# 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产认值生的该分区下的数据
# none
# topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
# 1、创建消费者
consumer = KafkaConsumer(
bootstrap_servers="master:9092,node1:9092,node2:9092",
group_id="asd22ss2asd", #消费者组: 同一条数据在一个组内只读取一次
auto_offset_reset="earliest"
)
# 2、订阅topic
consumer.subscribe(topics=["student"])
# 3、从kafka拉取数据,1秒超时
while True:
print("读取数据")
kv_records = consumer.poll(timeout_ms=1000)
# 循环解析数据
for t, records in kv_records.items():
for record in records:
# topic
topic = record.topic
# 偏移量
offset = record.offset
# 分区编号
partition = record.partition
# 数据需要解码
value = record.value.decode("UTF-8")
# 截取数据
print(topic, offset, partition, value)
6、Flume ON Kafka
通过FLumej将数据写入kafka
kafka整合flume
1、写一个配置文件:
vim flume-car-to-kafka.properties
agent.sources=s1
agent.channels=c1
agent.sinks=k1agent.sources.s1.type=exec
#监听文件地址
agent.sources.s1.command=tail -F /root/cars/cars.logagent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100#设置Kafka接收器
agent.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=master:9092,node1:2181,node2:2181#设置Kafka的Topic 如果topic不存在会自动创建一个topic,默认分区为1,副本为1
agent.sinks.k1.topic=car#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder#将三个主件串联起来
agent.sources.s1.channels=c1
agent.sinks.k1.channel=c1
2、上传代码到服务器,不需要打包
3、启动flume
flume-ng agent -n agent -f ./flume-car-to-kafka.properties -Dflume.root.logger=DEBUG,console
4、启动python代码生成数据
python3 demo5_cars.py
5、消费kafka查看结果
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic car
代码:随机生成数据,模拟实时生成数据
import random
import time
#随机生成数据
# 定义卡扣编号列表、车牌号码列表、城市名列表、道路名列表、区县名列表
tollgate_list = ['110', '111', '112', '113', '114']
license_plate_list = ['川A', '鄂B', '湘D', '皖C', '京N']
city_list = ['北京市', '上海市', '广州市', '深圳市', '杭州市']
road_list = ['朝阳路', '人民路', '中山路', '解放路', '文化路']
district_list = ['东城区', '虹口区', '天河区', '南山区', '西湖区']
# 定义卡扣经纬度范围
tollgate_longitude_range = (116.2, 116.6)
tollgate_latitude_range = (39.8, 40.2)
# # 生成100条随机数据
data_list = []
with open("cars.log", mode="w", encoding="utf-8") as file:
for i in range(100000):
tollgate_id = random.choice(tollgate_list)
license_plate = random.choice(license_plate_list) + str(random.randint(10000, 99999))
timestamp = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(random.randint(1614614400, 1617206400)))
longitude = round(random.uniform(*tollgate_longitude_range), 6)
latitude = round(random.uniform(*tollgate_latitude_range), 6)
speed = random.randint(60, 120)
city = random.choice(city_list)
road = random.choice(road_list)
district = random.choice(district_list)
file.write(
"{},{},{},{},{},{},{},{},{}\n".format(
tollgate_id, license_plate, timestamp, longitude, latitude, speed,
city,
road, district))
file.flush()
time.sleep(1)
7、Spark Streaming ON kafka
通过spark streaming 从kafka中读数据,处理数据
1、添加依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.4.5</version> </dependency>
2、配置文件对象,读取topic,消费数据,读取数据,处理数据
每隔5秒就会计算一组数据。
3、代码:
package com.shujia.spark.stream
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object Demo9ReadKafka {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("kafka")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Durations.seconds(5))
ssc.checkpoint("data/checkpoint")
//配置文件对象
val kafkaParams: Map[String, Object] = Map[String, Object](
"bootstrap.servers" -> "master:9092,node1:9092,node2:9092", //kafka集群列表
"key.deserializer" -> classOf[StringDeserializer], // key反序列化类
"value.deserializer" -> classOf[StringDeserializer], //value 反序列化的
"group.id" -> "use_a_separate_group_id_for_each_stream", //消费者组
"auto.offset.reset" -> "earliest" //读取数据的位置
)
//读取数据的topic
val topics: Array[String] = Array("car")
//消费kafka数据
val recordsDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils
.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//读取value
val carDS: DStream[String] = recordsDS.map(record => record.value())
/**
* 统计每隔城市的车流量
*/
val kvRDD: DStream[(String, Int)] = carDS.map(car => {
val city: String = car.split(",")(6)
(city, 1)
})
val cityFlowDS: DStream[(String, Int)] = kvRDD
.updateStateByKey((seq: Seq[Int], state: Option[Int]) => Option(seq.sum + state.getOrElse(0)))
cityFlowDS.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
8、Flink ON Kafka
版权归原作者 小雪x 所有, 如有侵权,请联系我们删除。