
yarn 工作机制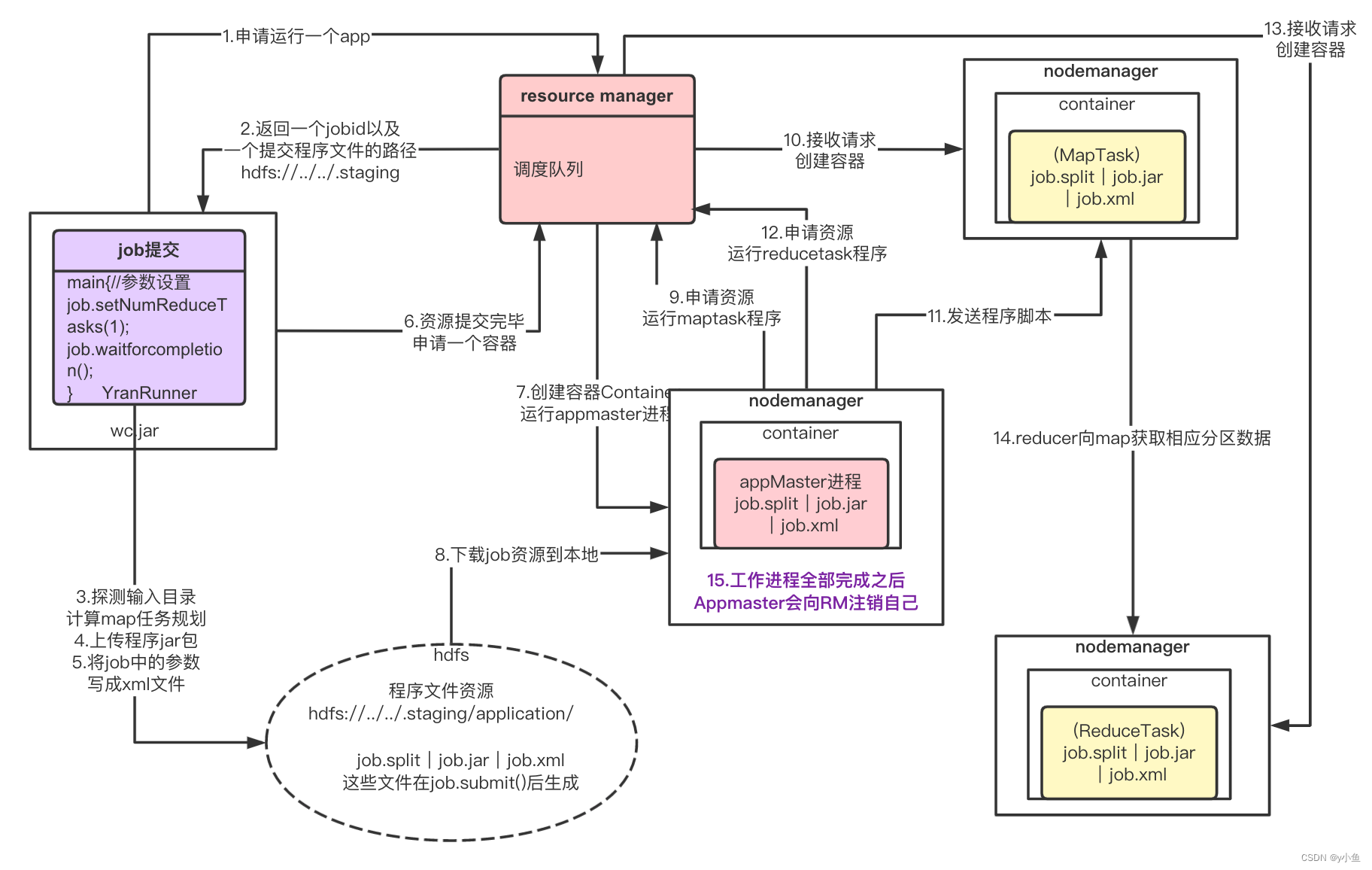
1.用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
2.ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
3.ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束。
4.ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
5.一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
6.NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7.各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
8.应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
相关参数: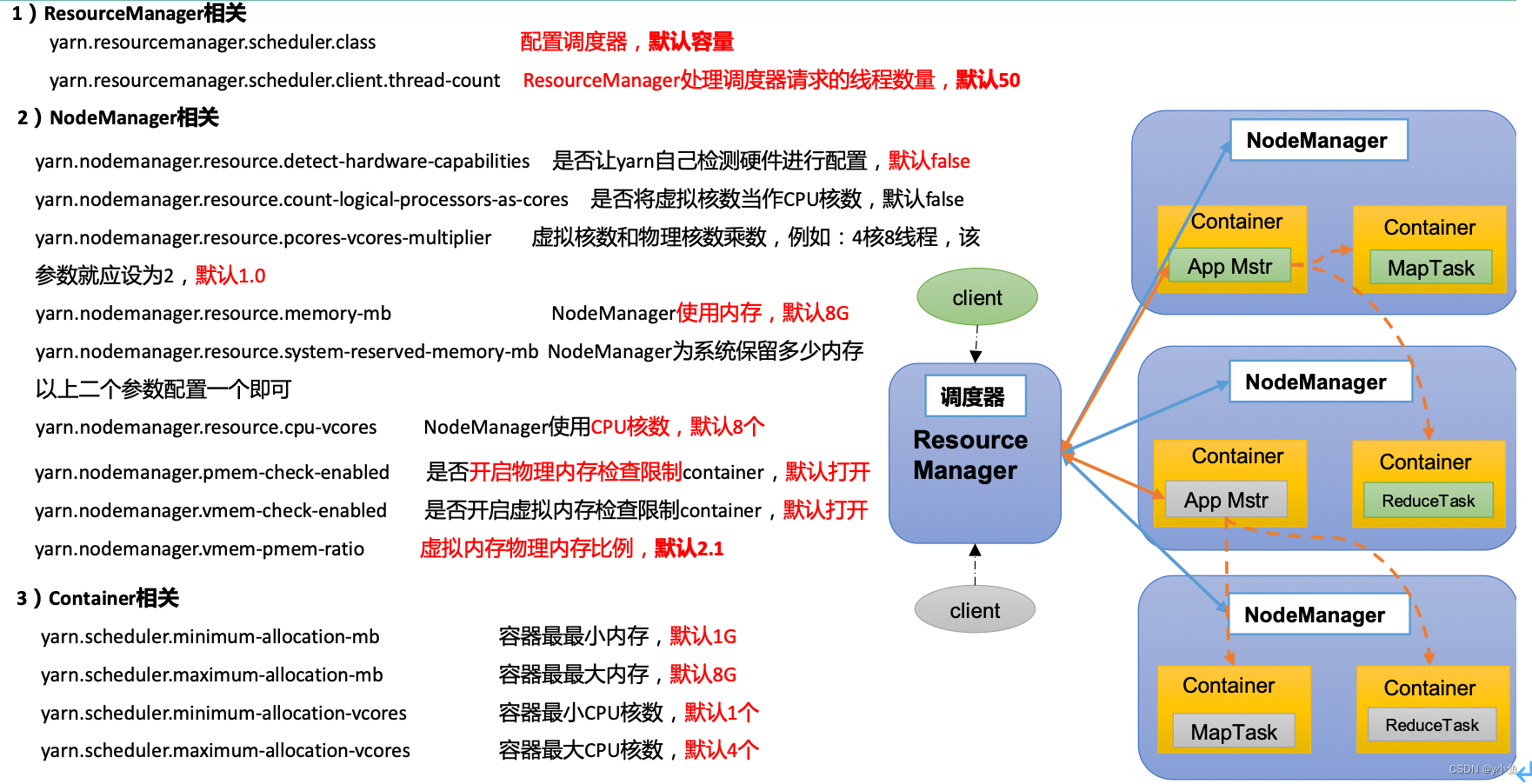
Yarn调度器
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。
2)区别:
FIFO调度器:支持单队列 、先进先出 生产环境不会用。
容量调度器:支持多队列。队列资源分配,优先选择资源占用率最低的队列分配资源;作业资源分配,按照作业的优先级和提交时间顺序分配资源;容器资源分配,本地原则(同一节点/同一机架/不同节点不同机架)
公平调度器:支持多队列,保证每个任务公平享有队列资源。资源不够时可以按照缺额分配。
3)在生产环境下怎么选择?
大厂:如果对并发度要求比较高,选择公平,要求服务器性能必须OK;
中小公司,集群服务器资源不太充裕选择容量。
4)在生产环境怎么创建队列?
(1)调度器默认就1个default队列,不能满足生产要求。
(2)按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
(3)按照部门:算法、数仓、商业化
(4)按照业务模块:业务1、业务2、业务3
5)创建多队列的好处?
(1)因为担心任务中有写递归死循环代码,把所有资源全部耗尽。
(2)实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
业务部门1(重要)=》业务部门2(比较重要)=》业务模块(一般)=》业务模块(次要)
版权归原作者 y小鱼 所有, 如有侵权,请联系我们删除。