
文章目录
0 前言
🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 毕业设计 大数据招聘数据可视化系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
难度系数:3分
工作量:3分
创新点:4分
🧿 项目分享:见文末!
1 项目运行效果





视频效果:
毕业设计 大数据招聘数据可视化系统
2 课题背景
随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。
本文基于这个问题,针对 boss 直聘网站,使用 Scrapy 框架爬取了全国热门城市大数据、数据分析、数据挖掘、机器学习、人工智能等相关岗位的招聘信息。分析比较了不同岗位的薪资、学历要求;分析比较了不同区域、行业对相关人才的需求情况;分析比较了不同岗位的知识、技能要求等。
3 项目实现
3.1 概述
该项目一共分为三个子任务完成,数据采集—数据预处理—数据分析/可视化。
项目流程图

项目架构图
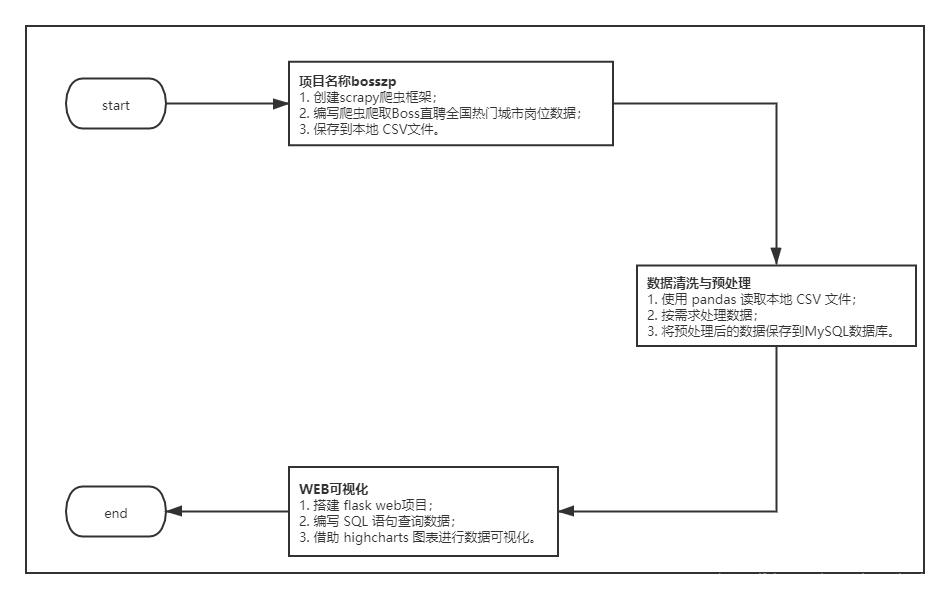
3.2 数据采集
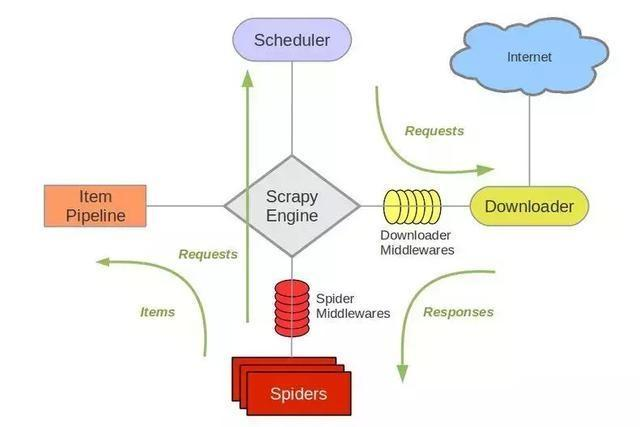
Scrapy 爬虫介绍
Scrapy是基于Twisted的爬虫框架,它可以从各种数据源中抓取数据。其架构清晰,模块之间的耦合度低,扩展性极强,爬取效率高,可以灵活完成各种需求。能够方便地用来处理绝大多数反爬网站,是目前Python中应用最广泛的爬虫框架。Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。各个组件的作用如下:
- 调度器(Scheduler):说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
- 下载器(Downloader):是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
- 爬虫(Spider):是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 实体管道(Item Pipeline):用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
- Scrapy引擎(Scrapy Engine):Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
Scrapy 官网架构图
爬取 Boss直聘热门城市岗位数据,并将数据以 CSV 文件格式进行保存。如下图所示:

编写爬虫程序
创建和配置好 Scrapy 项目以后,我们就可以编写 Scrapy 爬虫程序了。
import scrapy
import json
import logging
import random
from bosszp.items import BosszpItem
classBossSpider(scrapy.Spider):
name ='boss'
allowed_domains =['zhipin.com']
start_urls =['https://www.zhipin.com/wapi/zpCommon/data/cityGroup.json']# 热门城市列表url# 设置多个 cookie,建议数量为 页数/2 + 1 个cookie.至少 设置 4 个# 只需复制 __zp_stoken__ 部分即可
cookies =['__zp_stoken__=f330bOEgsRnsAIS5Bb2FXe250elQKNzAgMBcQZ1hvWyBjUFE1DCpKLWBtBn99Nwd%2BPHtlVRgdOi1vDEAkOz9sag50aRNRfhs6TQ9kWmNYc0cFI3kYKg5fAGVPPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D','__zp_stoken__=f330bOEgsRnsAIUsENEIbe250elRsb2U4Bg0QZ1hvW19mPEdeeSpKLWBtN3Y9QCN%2BPHtlVRgdOilvfTYkSTMiaFN0X3NRAGMjOgENX2krc0cFI3kYKiooQGx%2BPX0WO2I3OipvRlwbP1YFBQlHOQ%3D%3D','__zp_stoken__=f330bOEgsRnsAITsLNnJIe250elRJMH95DBAQZ1hvW1J1ewdmDCpKLWBtBHZtagV%2BPHtlVRgdOil1LjkkR1MeRAgdY3tXbxVORWVuTxQlc0cFI3kYKgwCEGxNPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D']# 设置多个请求头
user_agents =['Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15','Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0','Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1','Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',]
page_no =1# 初始化分页defrandom_header(self):"""
随机生成请求头
:return: headers
"""
headers ={'Referer':'https://www.zhipin.com/c101020100/?ka=sel-city-101020100'}
headers['cookie']= random.choice(self.cookies)
headers['user-agent']= random.choice(self.user_agents)return headers
defparse(self, response):"""
解析首页热门城市列表,选择热门城市进行爬取
:param response: 热门城市字典数据
:return:
"""# 获取服务器返回的内容
city_group = json.loads(response.body.decode())# 获取热门城市列表
hot_city_list = city_group['zpData']['hotCityList']# 初始化空列表,存储打印信息# city_lst = []# for index,item in enumerate(hot_city_list):# city_lst.apend({index+1: item['name']})# 列表推导式:
hot_city_names =[{index +1: item['name']}for index, item inenumerate(hot_city_list)]print("--->", hot_city_names)# 从键盘获取城市编号
city_no =int(input('请从上述城市列表中,选择编号开始爬取:'))# 拼接url https://www.zhipin.com/job_detail/?query=&city=101040100&industry=&position=# 获取城市编码code
city_code = hot_city_list[city_no -1]['code']# 拼接查询接口
city_url ='https://www.zhipin.com/job_detail/?query=&city={}&industry=&position='.format(city_code)
logging.info("<<<<<<<<<<<<<正在爬取第_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))yield scrapy.Request(url=city_url, headers=self.random_header(), callback=self.parse_city)defparse_city(self, response):"""
解析岗位页数据
:param response: 岗位页响应数据
:return:
"""if response.status !=200:
logging.warning("<<<<<<<<<<<<<获取城市招聘信息失败,ip已被封禁。请稍后重试>>>>>>>>>>>>>")return
li_elements = response.xpath('//div[@class="job-list"]/ul/li')# 定位到所有的li标签
next_url = response.xpath('//div[@class="page"]/a[last()]/@href').get()# 获取下一页for li in li_elements:
job_name = li.xpath('./div/div[1]//div[@class="job-title"]/span[1]/a/text()').get()
job_area = li.xpath('./div/div[1]//div[@class="job-title"]/span[2]/span[1]/text()').get()
job_salary = li.xpath('./div/div[1]//span[@class="red"]/text()').get()
com_name = li.xpath('./div/div[1]/div[2]//div[@class="company-text"]/h3/a/text()').get()
com_type = li.xpath('./div/div[1]/div[2]/div[1]/p/a/text()').get()
com_size = li.xpath('./div/div[1]/div[2]/div[1]/p/text()[2]').get()
finance_stage = li.xpath('./div/div[1]/div[2]/div[1]/p/text()[1]').get()
work_year = li.xpath('./div/div[1]/div[1]/div[1]/div[2]/p/text()[1]').get()
education = li.xpath('./div/div[1]/div[1]/div[1]/div[2]/p/text()[2]').get()
job_benefits = li.xpath('./div/div[2]/div[2]/text()').get()
item = BosszpItem(job_name=job_name, job_area=job_area, job_salary=job_salary, com_name=com_name,
com_type=com_type, com_size=com_size,
finance_stage=finance_stage, work_year=work_year, education=education,
job_benefits=job_benefits)yield item
if next_url =="javascript:;":
logging.info('<<<<<<<<<<<<<热门城市岗位数据已爬取结束>>>>>>>>>>>>>')
logging.info("<<<<<<<<<<<<<一共爬取了_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))return
next_url = response.urljoin(next_url)# 网址拼接
self.page_no +=1
logging.info("<<<<<<<<<<<<<正在爬取第_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))yield scrapy.Request(url=next_url, headers=self.random_header(), callback=self.parse_city)
保存数据
from itemadapter import ItemAdapter
classBosszpPipeline:defprocess_item(self, item, spider):"""
保存数据到本地 csv 文件
:param item: 数据项
:param spider:
:return:
"""withopen(file='全国-热门城市岗位数据.csv', mode='a+', encoding='utf8')as f:
f.write('{job_name},{job_area},{job_salary},{com_name},{com_type},{com_size},{finance_stage},{work_year},''{education},{job_benefits}'.format(**item))return item
编辑本地 CSV 文件
job_name,job_area,job_salary,com_name,com_type,com_size,finance_stage,work_year,education,job_benefits

3.3 数据清洗与预处理
完成上面爬虫程序的编写与运行,我们就能将 Boss 直聘热门城市岗位数据爬取到本地。通过观察发现爬取到的数据出现了大量的脏数据和高耦合的数据。我们需要对这些脏数据进行清洗与预处理后才能正常使用。
需求:
读取 全国-热门城市岗位数据.csv 文件
对重复行进行清洗。
对工作地址字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段
对薪资字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60
对工作经验字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4
对企业规模字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3
对岗位福利字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)
对缺失值所在行进行清洗。
将处理后的数据保存到 MySQL 数据库
编写清洗与预处理的代码
# -*- coding:utf-8 -*-"""
作者:jhzhong
功能:对岗位数据进行清洗与预处理
需求:
1. 读取 `全国-热门城市岗位数据.csv` 文件
2. 对重复行进行清洗。
3. 对`工作地址`字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段
4. 对`薪资`字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60
5. 对`工作经验`字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4
6. 对`企业规模`字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3
7. 对`岗位福利`字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)
8. 对缺失值所在行进行清洗。
9. 将处理后的数据保存到 MySQL 数据库
"""# 导入模块import pandas as pd
from sqlalchemy import create_engine
import logging
# 读取 全国-热门城市岗位招聘数据.csv 文件
all_city_zp_df = pd.read_csv('../全国-热门城市岗位数据.csv', encoding='utf8')# 对重复行进行清洗。
all_city_zp_df.drop_duplicates(inplace=True)# 对`工作地址`字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段
all_city_zp_area_df = all_city_zp_df['job_area'].str.split('·', expand=True)
all_city_zp_area_df = all_city_zp_area_df.rename(columns={0:"city",1:"district",2:"street"})# 对`薪资`字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60
all_city_zp_salary_df = all_city_zp_df['job_salary'].str.split('K', expand=True)[0].str.split('-', expand=True)
all_city_zp_salary_df = all_city_zp_salary_df.rename(columns={0:'salary_lower',1:'salary_high'})# 对`工作经验`字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4deffun_work_year(x):if x in"1-3年":return1elif x in"3-5年":return2elif x in"5-10年":return3elif x in"10年以上":return4else:return0
all_city_zp_df['work_year']= all_city_zp_df['work_year'].apply(lambda x: fun_work_year(x))# 对`企业规模`字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3deffun_com_size(x):if x in"500-999人":return1elif x in"1000-9999人":return2elif x in"10000人以上":return3else:return0# 对`岗位福利`字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)
all_city_zp_df['job_benefits']= all_city_zp_df['job_benefits'].str.replace(',',',')# 合并所有数据集
clean_all_city_zp_df = pd.concat([all_city_zp_df, all_city_zp_salary_df, all_city_zp_area_df], axis=1)# 删除冗余列
clean_all_city_zp_df.drop('job_area', axis=1, inplace=True)# 删除原区域
clean_all_city_zp_df.drop('job_salary', axis=1, inplace=True)# 删除原薪资# 对缺失值所在行进行清洗。
clean_all_city_zp_df.dropna(axis=0, how='any', inplace=True)
clean_all_city_zp_df.drop(axis=0,
index=(clean_all_city_zp_df.loc[(clean_all_city_zp_df['job_benefits']=='None')].index),
inplace=True)# 将处理后的数据保存到 MySQL 数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/bosszp_db?charset=utf8')
clean_all_city_zp_df.to_sql('t_boss_zp_info', con=engine, if_exists='replace')
logging.info("Write to MySQL Successfully!")
运行程序,检查数据是否清洗成功和插入到数据库。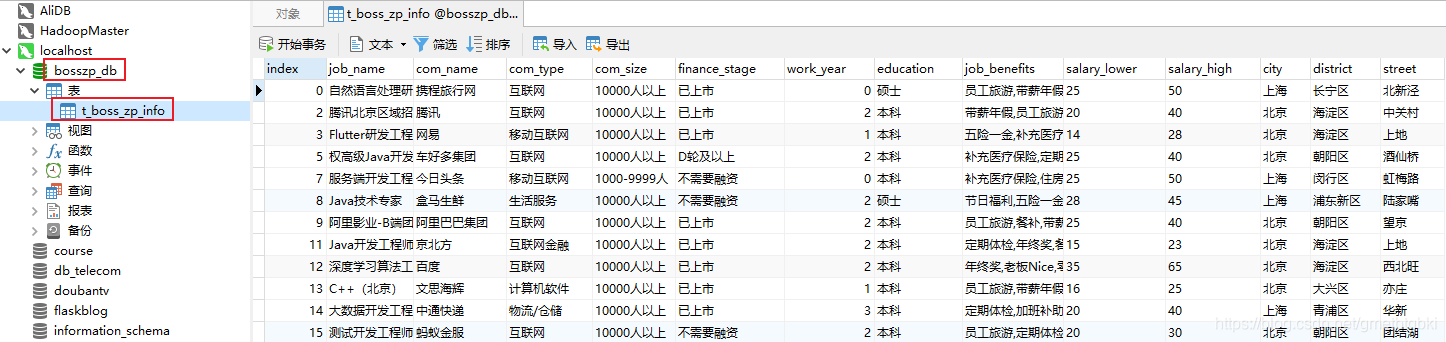
4 数据分析与可视化
成功运行上面两个流程后,我们已经得到了可用于数据分析的高质量数据。拿到这些数据以后,我们使用 python + sql 脚本的方式对数据进行多维度分析,并使用 highcharts 工具进行数据可视化。整个分析可视化通过轻量化 WEB 框架 Flask 来进行部署。
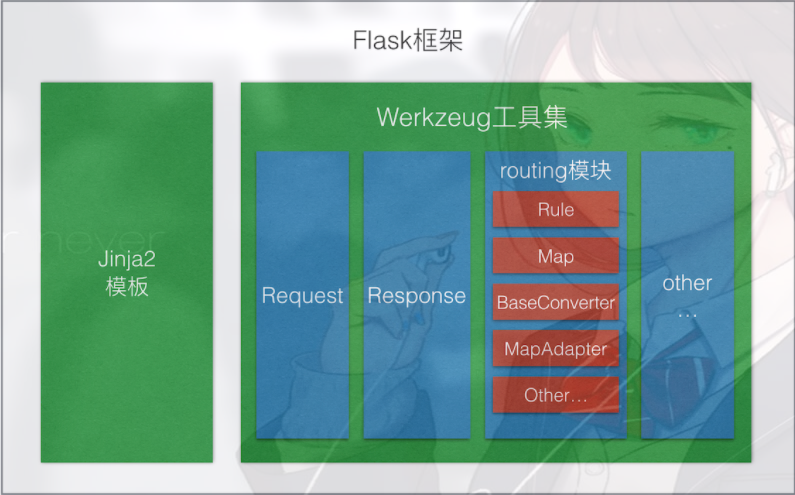
Flask框架介绍
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
Flask框架图
编写可视化代码
# -*- coding:utf-8 -*-"""
作者:jhzhong
功能:数据分析于可视化
"""from flask import Flask, render_template
from bosszp.web.dbutils import DBUtils
import json
app = Flask(__name__)defget_db_conn():"""
获取数据库连接
:return: db_conn 数据库连接对象
"""return DBUtils(host='localhost', user='root', passw='123456', db='bosszp_db')defmsg(status, data='未加载到数据'):"""
:param status: 状态码 200成功,201未找到数据
:param data: 响应数据
:return: 字典 如{'status': 201, 'data': ‘未加载到数据’}
"""return json.dumps({'status': status,'data': data})@app.route('/')defindex():"""
首页
:return: index.html 跳转到首页
"""return render_template('index.html')@app.route('/getwordcloud')defget_word_cloud():"""
获取岗位福利词云数据
:return:
"""
db_conn = get_db_conn()
text = \
db_conn.get_one(sql_str="SELECT GROUP_CONCAT(job_benefits) FROM t_boss_zp_info")[0]if text isNone:return msg(201)return msg(200, text)@app.route('/getjobinfo')defget_job_info():"""
获取热门岗位招聘区域分布
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT city,district,COUNT(1) as num FROM t_boss_zp_info GROUP BY city,district")# {"city":"北京","info":[{"district":"朝阳区","num":27},{"海淀区":43}]}if results isNoneorlen(results)==0:return msg(201)
data =[]
city_detail ={}for r in results:
info ={'name': r[1],'value': r[2]}if r[0]notin city_detail:
city_detail[r[0]]=[info]else:
city_detail[r[0]].append(info)for k, v in city_detail.items():
temp ={'name': k,'data': v}
data.append(temp)return msg(200, data)@app.route('/getjobnum')defget_job_num():"""
获取个城市岗位数量
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(sql_str="SELECT city,COUNT(1) num FROM t_boss_zp_info GROUP BY city")if results isNoneorlen(results)==0:return msg(201)if results isNoneorlen(results)==0:return msg(201)
data =[]for r in results:
data.append(list(r))return msg(200, data)@app.route('/getcomtypenum')defget_com_type_num():"""
获取企业类型占比
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT com_type, ROUND(COUNT(1)/(SELECT SUM(t1.num) FROM (SELECT COUNT(1) num FROM t_boss_zp_info GROUP BY com_type) t1)*100,2) percent FROM t_boss_zp_info GROUP BY com_type")if results isNoneorlen(results)==0:return msg(201)
data =[]for r in results:
data.append({'name': r[0],'y':float(r[1])})return msg(200, data)# 扇形图@app.route('/geteducationnum')defgeteducationnum():"""
获取学历占比
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT t1.education,ROUND(t1.num/(SELECT SUM(t2.num) FROM(SELECT COUNT(1) num FROM t_boss_zp_info t GROUP BY t.education)t2)*100,2) FROM( SELECT t.education,COUNT(1) num FROM t_boss_zp_info t GROUP BY t.education) t1")if results isNoneorlen(results)==0:return msg(201)
data =[]for r in results:
data.append([r[0],float(r[1])])return msg(200, data)# 获取排行榜@app.route('/getorder')defgetorder():"""
获取企业招聘数量排行榜
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT t.com_name,COUNT(1) FROM t_boss_zp_info t GROUP BY t.com_name ORDER BY COUNT(1) DESC LIMIT 10")if results isNoneorlen(results)==0:return msg(201)
data =[]for i, r inenumerate(results):
data.append({'id': i +1,'name': r[0],'num': r[1]})return msg(200, data)if __name__ =='__main__':
app.run(host='127.0.0.1', port=8080, debug=True)
篇幅有限,更多详细设计见设计论文
6 最后
项目包含内容

完整详细设计论文

🧿 项目分享:见文末!
版权归原作者 bee_dc 所有, 如有侵权,请联系我们删除。