
本文带您快速体验Flink Python流作业和批作业的创建、部署和启动,以了解实时计算Flink版Python作业的操作流程。
前提条件
- 如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
- 已创建Flink工作空间,详情请参见开通实时计算Flink版。
步骤一:下载Python测试文件
本文为您提供了测试Python文件和输入数据文件,您可以直接单击下载待后续步骤使用。
- 您可以单击下载以下任意Python测试作业。- 单击word_count_streaming.py,下载Python流作业测试Python文件。- 单击word_count_batch.py,下载Python批作业测试Python文件。
- 单击Shakespeare,下载输入数据文件Shakespeare。
Flink控制台不提供Python包的开发平台,因此您需要在线下完成Python包的开发。Python作业的开发方法,调试及连接器的使用等详情请参见Python作业开发。
步骤二:上传Python文件
- 登录实时计算控制台。
- 单击目标工作空间操作列下的控制台。
- 在左侧导航栏,单击文件管理。
- 单击上传资源,选择测试Python文件和数据文件。- 如果您工作空间存储类型为OSS Bucket,则文件实际会被存放至名称为您开通Flink工作空间时绑定的OSS Bucket下的artifacts目录。上传后,文件路径格式为
oss://<您绑定的OSS Bucket名称>/artifacts/namespaces/<项目空间名称>目录下。- 如果您工作空间存储类型为全托管存储,则文件实际会被存放至实时计算开发控制台文件管理。上传后,文件路径格式为oss://flink-fullymanaged-<工作空间ID>/artifacts/namespaces/<项目空间名称>目录下。
说明
在Python作业中使用其他依赖(例如自定义的Python虚拟环境、第三方Python包、JAR包和数据文件等)的方法请参见使用Python依赖。
步骤三:创建作业
流作业
批作业
- 在运维中心 > 作业运维界面,单击部署作业,选择Python作业。
- 填写部署信息。参数说明示例****部署模式请选择部署为流模式。流模式部署名称填写对应的Python作业名称。flink-streaming-test-python引擎版本当前作业使用的Flink引擎版本。建议使用带有推荐、稳定标签的版本,这些版本具有更高的可靠性和性能表现,详情请参见功能发布记录和引擎版本介绍。vvr-8.0.8-flink-1.17Python文件地址单击word_count_streaming.py下载测试Python文件后,再单击右侧
 图标选择文件,上传Python文件。-Entry Module程序的入口类。- 如果Python作业文件为.py文件,则该项不需要填写。- 如果Python作业文件为.zip文件,则需要在此处输入您的Entry Module,例如word_count。无需填写Entry Point Main Arguments填写输入数据文件的存放路径。- OSS Bucket
图标选择文件,上传Python文件。-Entry Module程序的入口类。- 如果Python作业文件为.py文件,则该项不需要填写。- 如果Python作业文件为.zip文件,则需要在此处输入您的Entry Module,例如word_count。无需填写Entry Point Main Arguments填写输入数据文件的存放路径。- OSS Bucket--input oss://<您绑定的OSS Bucket名称>/artifacts/namespaces/<项目空间名称>/Shakespeare- 全托管存储--input oss://flink-fullymanaged-<工作空间ID>/artifacts/namespaces/<项目空间名称>/ShakespearePython Libraries第三方Python包。第三方Python包会被添加到Python worker进程的PYTHONPATH中,从而在Python自定义函数中可以直接访问。如何使用第三方Python包,详情请参见使用第三方Python包。无需填写Python Archives存档文件,Python Archives详情请参见使用自定义的Python虚拟环境和使用数据文件。无需填写附加依赖文件填写目标附加依赖文件的OSS路径或者URL。无需填写部署目标在下拉列表中,选择目标资源队列或者Session集群(请勿生产使用)。详情请参见管理资源队列和步骤一:创建Session集群。说明部署到Session集群的作业不支持显示监控告警、配置监控告警和开启自动调优功能。请勿将Session集群用于正式生产环境,Session集群可以作为开发测试环境。详情请参见作业调试。default-queue备注可选,填写备注信息。无需填写作业标签配置作业标签后,您可以在作业运维页面根据标签名和标签值快速过滤找到目标作业。您最多可以创建3组作业标签。无需填写更多设置打开该开关后,您需要配置以下信息:- Kerberos集群:单击左侧下拉列表选择您已创建的Kerberos集群,Kerberos集群创建操作详情请参见注册Hive Kerberos集群。- principal:Kerberos principal又称为主体,主体可以是用户或服务,用于在Kerberos加密系统中标记一个唯一的身份。无需填写 - 单击部署。
步骤四:启动Python作业
- 在作业运维页面,单击目标作业名称操作列中的启动。
- 配置资源信息和基础设置。作业启动参数配置详情请参见作业启动。
- 单击对话框中的启动。单击启动后,您可以看到作业状态变为运行中或已完成,则代表作业运行正常。重要- 如果您使用文档Python测试文件,作业最终运行状态是已完成状态。- 如果您需要启动批作业,则需要在作业运维页面,将作业类型切换为批作业,才可以看到您上线的批作业。系统默认展示的作业为流作业。
步骤五:查看Flink计算结果
- 查看Python流作业计算结果:在TaskManager中以.out结尾的日志文件中,搜索shakespeare查看Flink计算结果。
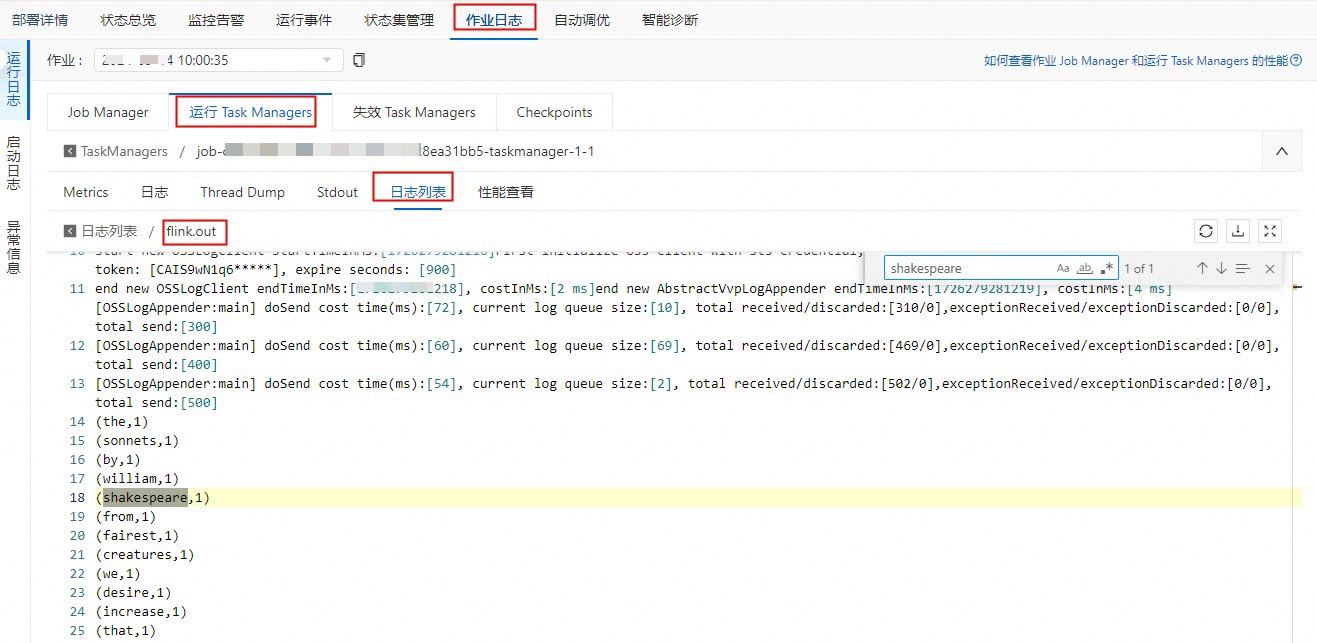 重要如果您使用的是Python测试文件,流作业变为已完成状态时会删除作业结果,故流作业状态为运行中才能查看计算结果。
重要如果您使用的是Python测试文件,流作业变为已完成状态时会删除作业结果,故流作业状态为运行中才能查看计算结果。 - 查看Python批作业计算结果:- OSS Bucket:在OSS管理控制台,oss://<您绑定的OSS Bucket名称>/artifacts/namespaces/<项目空间名称>/python-batch-quickstart-test-output.txt目录,单击名称是作业的启动日期和时间的文件夹,然后单击目标文件名,在弹出的面板上单击下载。
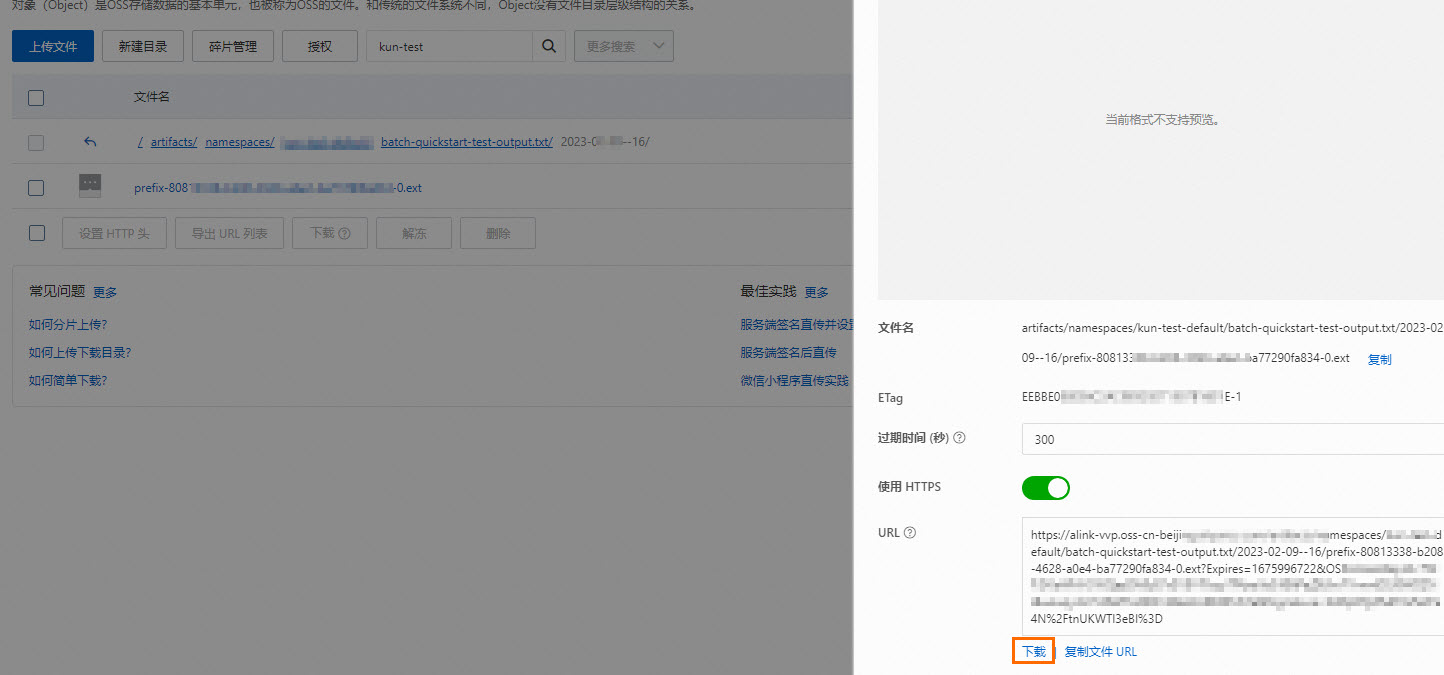 - 全托管存储:您可以在资源管理页面的资源文件页签,单击python-batch-quickstart-test-output.txt/2024-07-11--16/prefix-1a0bb9f5-b972-496f-9354-7e894c807****.ext文件操作列的下载,在本地进行查看。批作业结果为ext文件,下载后可以用记事本或者Microsoft Office Word打开查看结果,计算结果如下图所示。
- 全托管存储:您可以在资源管理页面的资源文件页签,单击python-batch-quickstart-test-output.txt/2024-07-11--16/prefix-1a0bb9f5-b972-496f-9354-7e894c807****.ext文件操作列的下载,在本地进行查看。批作业结果为ext文件,下载后可以用记事本或者Microsoft Office Word打开查看结果,计算结果如下图所示。
(可选)步骤六:停止作业
如果您对作业进行了修改(例如更改代码、增删改WITH参数、更改作业版本等),且希望修改生效,则需要重新部署作业,然后停止再启动。另外,如果作业无法复用State,希望作业全新启动时,或者更新非动态生效的参数配置时,也需要停止后再启动作业。
本文转载自: https://blog.csdn.net/segwy/article/details/142655204
版权归原作者 soso1968 所有, 如有侵权,请联系我们删除。
版权归原作者 soso1968 所有, 如有侵权,请联系我们删除。