
1.1.1 YARN的介绍
*为克服***Hadoop 1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop 1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. **
** Apache YARN(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作 **
**系统之上的应⽤程序。 **
** YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的 分布式计算模式,⽐如Spark,Tez等计算框架。**
1.2.1 YARN的配置
YARN属于Hadoop的核⼼组件,不需要单独安装,只需要修改⼀些配置⽂件即可。
注:以下需要配置的配置文件均在hadoop-3.1.1安装目录下的 /etc/hadoop 文件夹里
1.2.2 mapred-site.xml
<configuration>
<!-- 指定MapReduce作业执⾏时,使⽤YARN进⾏资源调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value> #写hadoop的安装路径,下同
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
</configuration>
1.2.3 yarn-site.xml
<configuration>
<!-- 设置ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>shulin</value> #主机名
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
1.2.4 hadoop-env.sh
# 在最后面添加如下:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
1.2.5 分发到其他节点
#如果没有其他节点,这步请忽略
[root@shulin ~]# cd $HADOOP_HOME/etc/
[root@shulin etc]# scp -r hadoop shulin02:$PWD
[root@shulin etc]# scp -r hadoop shulin03:$PWD
1.2.6 YARN****的服务启停
描述命令
开启YARN全部服务
start-yarn.sh
停⽌YARN全部服务
stop-yarn.sh
单点开启YARN相关进程
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
单点停⽌YARN相关进程
yarn --daemon stop resourcemanager
yarn --daemon stop nodemanager
1.3.1 YARN的历史日志
1.3.2 历史日志概述
** 我们在YARN上运⾏MapReduce的程序的时候,可以在控制台上看到任务的⽇志输出,以获取到任务的运⾏状态。同 时,YARN也会将⽇志写在本地的$HADOOP_HOMOE/logs/userlogs⽂件夹中,我们可以到⽂件夹中进⾏⽇志的查 看。但是这个⽂件夹中的内容,会随着YARN的重启⽽被删除掉。那么此时我们将如何查看⽇志? **
** 此时就需要开启Hadoop的历史⽇志服务了,Hadoop会将MapReduce的任务⽇志在HDFS也保留⼀份,我们可以通过 Hadoop的历史任务服务来查看到之前的历史⽇志! **
** 但是每⼀个程序会被分布在不同的节点上进⾏运⾏,我们在进⾏任务查看的时候还得⼀个个的去指定节点进⾏查看, 并⼀个个的找MapTask或者ReduceTask的⽇志,很麻烦!预设YARN提供了历史⽇志聚合的服务! **
**顾名思义,就是将每⼀个程序的历史⽇志都聚合在⼀起,存储在HDFS上,⽅便查看! **
1.3.3 mr-historyserver
顾名思义,就是去记录MapReduce的历史⽇志的。接下来我们从配置开始、到⽇志聚合、运⾏任务去讲解
1.3.4 配置文件
1.mapred-site.xml
<configuration>
<!-- 添加如下配置 -->
<!-- 历史任务的内部通讯地址 -->
<property>
<name>MapReduce.jobhistory.address</name>
<value>shulin:10020</value>
</property>
<!--历史任务的外部监听⻚⾯-->
<property>
<name>MapReduce.jobhistory.webapp.address</name>
<value>shulin:19888</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<!-- 添加如下配置 -->
<!-- 是否需要开启⽇志聚合 -->
<!-- 开启⽇志聚合后,将会将各个Container的⽇志保存在yarn.nodemanager.remote-app-log-dir的位置 -->
<!-- 默认保存在/tmp/logs -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 历史⽇志在HDFS保存的时间,单位是秒 -->
<!-- 默认的是-1,表示永久保存 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://shulin:19888/jobhistory/logs</value>
</property>
</configuration>
1.3.5 分发配置
#没有其他节点的这步可以忽略
[root@shulin ~]# cd $HADOOP_HOME/etc/hadoop
[root@shulin hadoop]# scp mapred-site.xml yarn-site.xml shulin01:$PWD
[root@shulin hadoop]# scp mapred-site.xml yarn-site.xml shulin02:$PWD
1.3.6 开启历史服务
# 重启YARN集群
[root@shulin ~]# stop-yarn.sh
[root@shulin ~]# start-yarn.sh
# 打开历史服务
[root@shulin ~]# mapred --daemon start historyserver
# 开启之后,通过jps可以查看到 JobHistoryServer 进程,表示开启成功
在浏览器输入IP地址加端口号8088即可打开YARN界面
http://192.168.184.12:8088
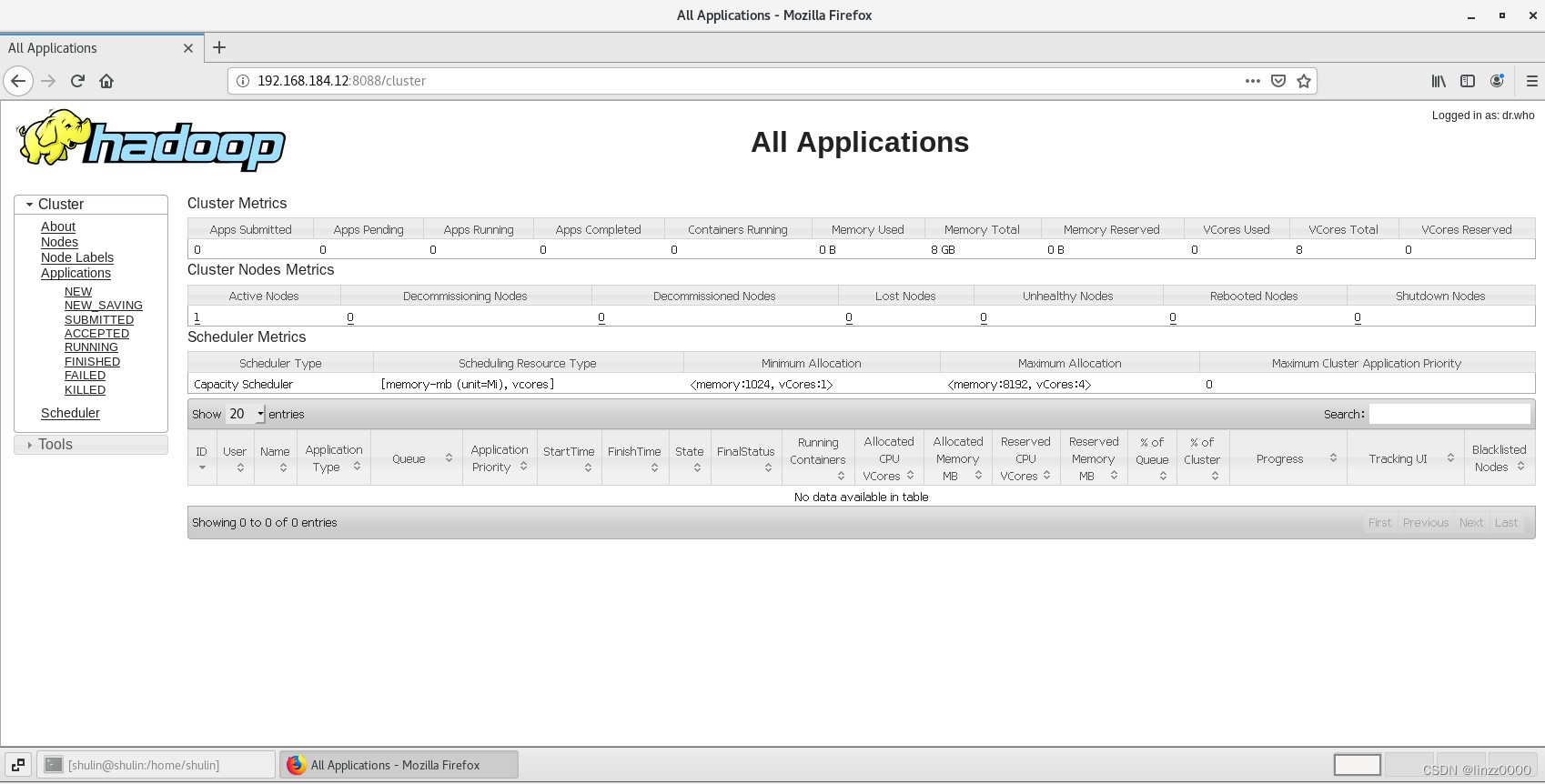
现在配置的服务已够学习使用,后续还会更新其他配置如timeline服务,YARN的队列配置等。
版权归原作者 linzz0000 所有, 如有侵权,请联系我们删除。