
目录
1、 Hive自带的json解析函数
1.1 get_json_object
语法:get_json_object(json_string, ‘$.key’),(使用 "$“的方式,”.“表示对象,”[]"引用数组)
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。这个函数每次只能返回一个数据项。
特征:每次只能解析一个字段,如果需要解析多个字段,需要调用函数多次。
示例:
-- 创建临时表with t as(select1as id,'{"name":"孙先生","carrer":"大数据开发工程师","dream":["开个便利店","去外面逛一逛","看本好书"],"friend":{
"friend_1":"MM",
"friend_2":"NN",
"friend_3":"BB",
"friend_4":"VV"
}
}'as list
unionallselect2as id,'{"name":"唐女士","carrer":"退休农民","dream":["儿子听话","带孙子"],"friend":{
"friend_1":"CC"
}
}'as list
)
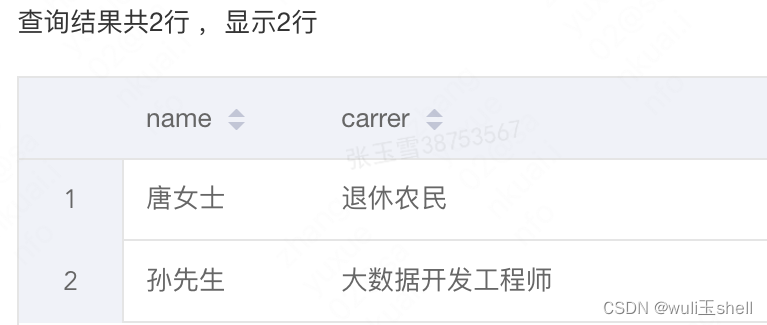
-- get_json_object查询字段select get_json_object(list,'$.name')as name,
get_json_object(list,'$.carrer')as carrer
from t
-- 获取标签中的数组元素select get_json_object(list,'$.dream[0]')as dream1
from t

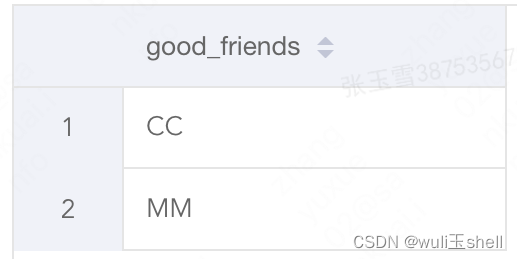
-- 获取多层中的对象select get_json_object(list,'$.friend.friend_1')as good_friends
from t
1.2 json_tuple
语法: json_tuple(json_string, k1, k2 …)
说明:解析json的字符串json_string,可指定多个json数据中的key,返回对应的value。如果输入的json字符串无效,那么返回NULL。
特征:相比get_json_object,json_tuple的优势就是一次可以解析多个json字段。
注意:json_tuple函数**不需要加$.**了,否则会解析不到。
示例:
-- 创建临时表with t as(select1as id,'{"name":"孙先生","carrer":"大数据开发工程师","dream":["开个便利店","去外面逛一逛","看本好书"],"friend":{
"friend_1":"MM",
"friend_2":"NN",
"friend_3":"BB",
"friend_4":"VV"
}
}'as list
unionallselect2as id,'{"name":"唐女士","carrer":"退休农民","dream":["儿子听话","带孙子"],"friend":{
"friend_1":"CC"
}
}'as list
)
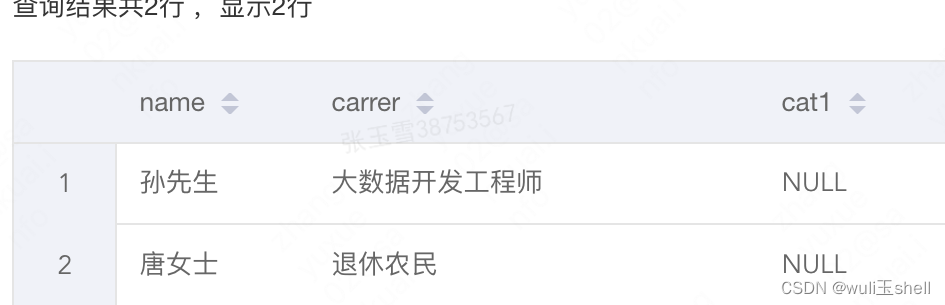
-- json_tuple解析多个字段,由于无cat1字段,则返回null,一级解析select name,
carrer,
cat1
from t lateral view json_tuple(list,'name','carrer','cat1') tb as name,
carrer,
cat1;
-- 二级解析,提取标签中所有的内容(没有的标签,返回null)select good_friend_1,
good_friend_2,
good_friend_3,
good_friend_4
from t lateral view json_tuple(list,'friend') tb as good_friend
lateral view json_tuple(good_friend,"friend_1","friend_2","friend_3","friend_4")dd as good_friend_1,
good_friend_2,
good_friend_3,
good_friend_4

-- 提取Arrayselect dream_col
from t
lateral view json_tuple(list,'dream') tb as dreaming
lateral view explode(dreaming)dd as dream_col
执行报错-待定位
hive解析、处理复杂类型Map、Array、Json
Hive解析Json数组超全讲解
2、Hive复杂数据类型-array,map,struct
map 是一种(key-value)键值对类型;
array 是一种数组类型,array 中存放相同类型的数据;
struct 是一种集合类型。
2.1 建表语句
createtable demo_class(
name string,
score array<int>,
result map<string,int>,
class struct<id:int, grade:string>)row format delimited fieldsterminatedby'\t'#列分隔符
collection items terminatedby'|'#每个map,struct,array 数据之间的分隔符,三种类型的数据统一用一个
map keysterminatedby':'#map 中的key与value的分隔符linesterminatedby'\n'#行分隔符
stored as textfile;
查看表结构
打开文件写入三行数据
vim /root/tmp/demo_class.txt
注意分隔符要与建表语句一致,如此表指定每列字段之间用tab分割,数据之间用“|”分隔,map的key与value之间用冒号“:”分隔,回车换行
a 90|92 math:90|english:921|genius
b 80|60 math:80|english:602|excellent
c 50|66 math:50|english:663|fighting
将数据载入表中
loaddatalocal inpath '/root/tmp/demo_class.txt' overwrite intotable test.demo_class ;
查看数据:
2.2 类型构建
-- 语法
array(val1, val2,…)
map(key1, value1, key2, value2,…)
struct(val1, val2, val3,…)-- 表结构已经是写入格式,只需要按照顺序输入value
-- 查询语句select
array(90,92)as score ,
map('math',90,'english',92)as result ,
struct(1,'genius')as class
-- 结果[90,92] {“math”:90,“english”:92} {“col1”:1,“col2”:“genius”}
2.3 array,map,struct语法
2.3.1 array类型
1、语法
语法: A[n]
操作类型: A为array类型,n为int类型
说明:返回数组A中的第n个变量值,数组的起始下标为0
select score, score[0], score[1]from demo_class ;-- 结果[90,92]9092[80,60]8060[50,66]5066
2、size()函数可以查询数组中元素的个数,下标超过长度返回null 值
select score, size(score), score[3]from demo_class ;-- 结果[90,92]2NULL[80,60]2NULL[50,66]2NULL
3、array_contains()函数可以查询数组中是否包含某个元素
array_contains(数组名,值)
返回 true 或 false
select score, array_contains(score,90)from demo_class;-- 结果[90,92]true[80,60]false[50,66]false
2.3.2 map类型
1、语法
语法: M[key]
操作类型: M为map类型,key为map中的key值
说明:返回map类型M中key值为指定值的value值
select result, result['math'], result['english']from demo_class ;-- 结果
{“math”:90,“english”:92} 9092
{“math”:80,“english”:60} 8060
{“math”:50,“english”:66} 5066
2、获取map中的键、值
map_keys()
map_values()
select map_keys(result), map_values(result)from demo_class ;-- 结果[“math”,“english”][90,92][“math”,“english”][80,60][“math”,“english”][50,66]
3、size()函数获取map中键值对的个数
select result, size(result)from demo_class ;-- 结果
{“math”:90,“english”:92} 2
{“math”:80,“english”:60} 2
{“math”:50,“english”:66} 2
4、查询map中是否包含某个键、值
array_contains(map_keys(字段名), 键名)
array_contains(map_values(字段名), 值名)
返回true/false
select result, array_contains(map_keys(result),'math')from demo_class ;-- 结果
{“math”:90,“english”:92} true
{“math”:80,“english”:60} true
{“math”:50,“english”:66} trueselect result, array_contains(map_values(result),90)from demo_class ;-- 结果
{“math”:90,“english”:92} true
{“math”:80,“english”:60} false
{“math”:50,“english”:66} false
可以当做where 过滤条件,如选取所有result 值为90的数据
select*from demo_class where array_contains(map_values(result),90);
2.3.3 struct类型
1、语法
语法: S.x
操作类型: S为struct类型
说明:返回集合S中的x字段
select class, class.id, class.grade from demo_class ;-- 结果
{“id”:1,“grade”:“genius”} 1 genius
{“id”:2,“grade”:“excellent”} 2 excellent
{“id”:3,“grade”:“fighting”} 3 fighting
hive复杂类型数据详解—array,map,struct
2.4 与其他数据类型转换
版权归原作者 wuli玉shell 所有, 如有侵权,请联系我们删除。