
目录
前言
Hadoop的单词统计(Word Count)是一个经典的MapReduce示例,用于计算输入文本文件中每个单词出现的次数。本指南旨在帮助读者在搭建完Hadoop集群后运行单词统计程序,并最终分析输出结果,全程详细解析,帮助读者深入理解大数据处理的核心流程。
一、启动hadoop HA高可用集群
1. 启动hadoop集群
切换到Hadoop安装目录的sbin子目录,并执行启动脚本。
位置:
/usr/local/src/hadoop/sbin
./start-all.sh
2. 启动zookeeper集群
ZooKeeper是Hadoop HA高可用性的关键组件,确保ZooKeeper集群正常启动。
位置:
/usr/local/src/zookeeper/bin
./zkServer.sh start
3. 验证集群状态
通过Hadoop和ZooKeeper的管理界面或使用命令行工具,验证所有服务组件均正常运行。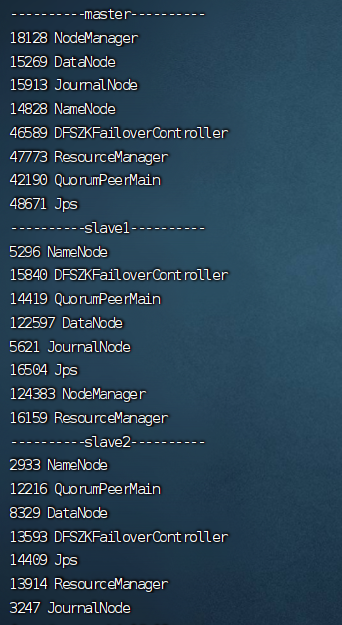
4.启动脚本提供
hadoop
#!/bin/bash
case $1in"start"){/usr/local/src/hadoop/sbin/start-dfs.sh
/usr/local/src/hadoop/sbin/start-yarn.sh
};;"stop"){/usr/local/src/hadoop/sbin/stop-dfs.sh
/usr/local/src/hadoop/sbin/stop-yarn.sh
};;
esac
zookeeper
for host in master slave1 slave2 #节点名称
docase $1in"start"){
echo "------------ $host zookeeper -----------"
ssh $host "source .bash_profile; zkServer.sh start"};;"stop"){
echo "------------ $host zookeeper -----------"
ssh $host "source .bash_profile; zkServer.sh stop"};;"status"){
echo "------------ $host zookeeper -----------"
ssh $host "source .bash_profile; zkServer.sh status"};;
esac
done
jps
#!/bin/bash
for host in master slave1 slave2
do
echo ----------$host----------
ssh $host /usr/local/src/jdk/bin/jps
done
二、准备数据并上传至HDFS
注意:在进行单词统计时必须在保持active活跃状态下的节点中进行操作,否则会出现错误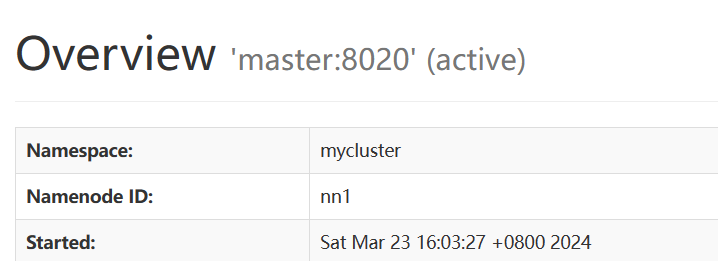
1.创建HDFS输入目录
位置:
/usr/local/src/hadoop/
bin/hdfs dfs -mkdir -p /data/input
2.准备本地单词文件,并随意添加字符
位置:
/usr/local/src/hadoop/data/
touch my-wordcount.txt
3.上传本地文件至HDFS
位置:
/usr/local/src/hadoop/
bin/hdfs dfs -put /usr/local/src/hadoop/data/my-wordcount.txt /data/input
三、运行Hadoop内置的单词统计程序
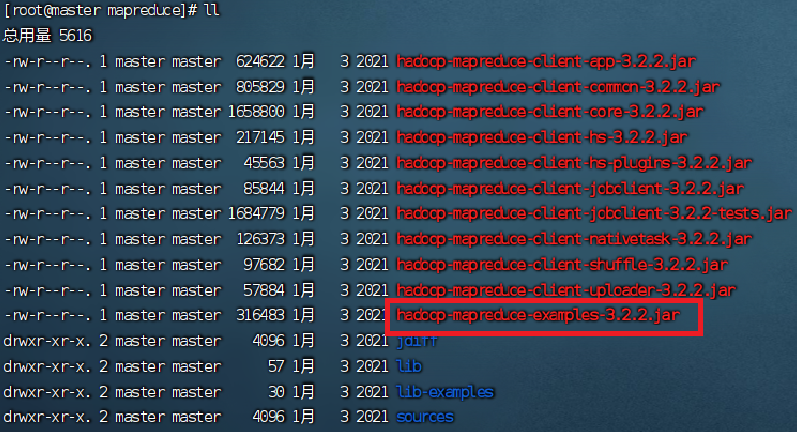
1.定位MapReduce示例JAR包
位置:
/usr/local/src/hadoop/share/hadoop/mapreduce
2.执行单词统计作业
位置:
/usr/local/src/hadoop/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /data/input/my_wordcount.txt /data/out/my_wordcount
下图代表运行成功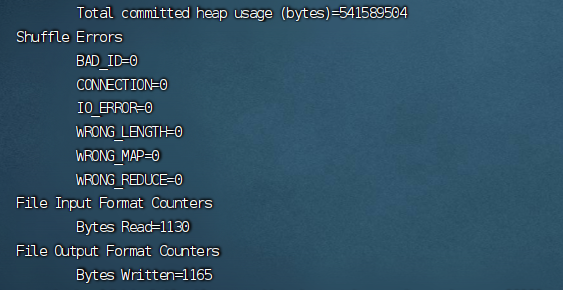
3.监控作业执行
通过Hadoop的Web界面或命令行工具监控作业的执行状态,确保作业成功完成。
四、查看结果
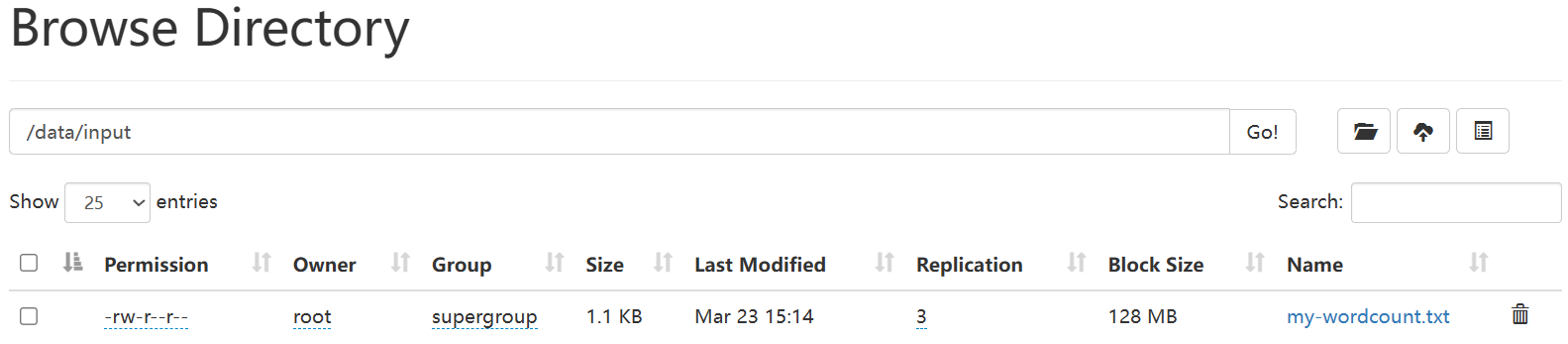
方法一:查看HDFS上输出目录中的结果文件
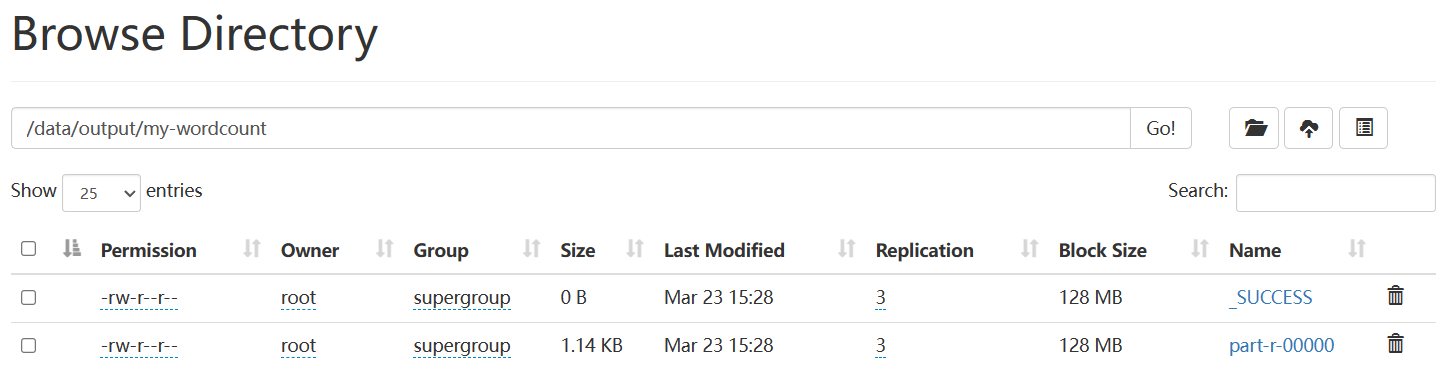
分析输出结果
了解每个单词在输入文本中的出现次数,以及统计结果的准确性。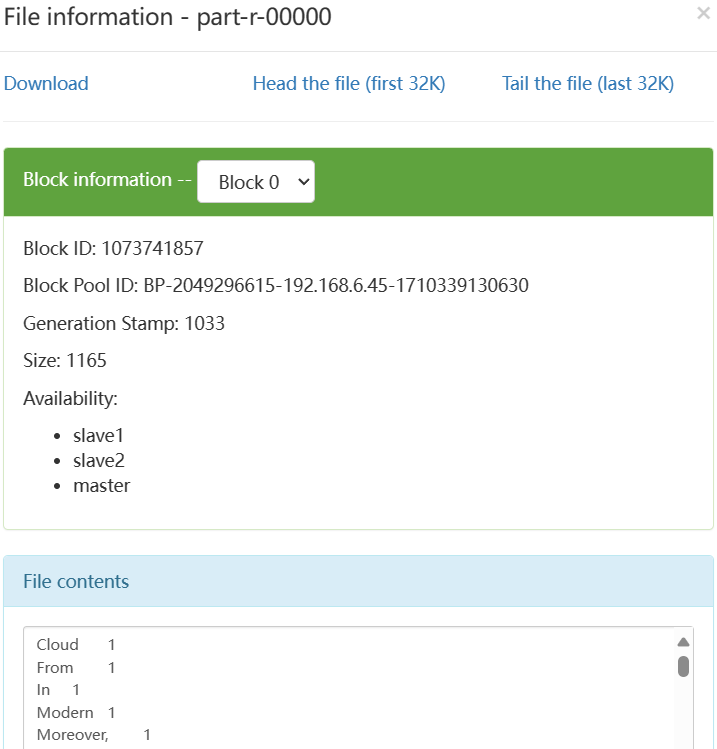
方法二:在虚拟机中查看结果
位置:
/usr/local/src/hadoop/
bin/hdfs dfs -cat /data/output/my-wordcount/part-r-00000

五、总结
通过虚拟机实现Hadoop单词统计是一个很好的学习和实践大数据处理的方式。通过搭建Hadoop集群、准备数据、运行作业,这不仅增强了我们对大数据处理流程的理解,也提高了我们运用Hadoop进行实际数据处理的能力。
本文转载自: https://blog.csdn.net/weixin_74865657/article/details/136968737
版权归原作者 提醒一下哟 所有, 如有侵权,请联系我们删除。
版权归原作者 提醒一下哟 所有, 如有侵权,请联系我们删除。