
集成模型是什么?
集成是一种机器学习概念,使用相同的学习算法训练多个模型。Bagging是一种减少预测方差的方法,通过使用重复组合生成多组原始数据,从数据集生成额外的训练数据。Boosting 是一种基于最后分类调整观测值权重的迭代技术。如果一条观察数据被错误地分类,它会试图增加这个观察数据的权重。总体而言,Boosting 建立了强大的预测模型。
导入所需要的包
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from pandas import DataFrame
make_blobs用于生成数据
它的参数如下:
参数
N_samples:如果为int,则为集群间平均分配的点数总数。如果是数组,则序列的每个元素表示每个集群的样本数量。
n_features: 每个样本的特征数量。
centers:生成的中心数量,或固定的中心位置。如果n_samples为int且centers为None,则生成3个中心。如果n_samples是数组,那么centers必须是None或者是长度等于n_samples长度的数组。
cluster_std:生成簇的标准差。
center_box: 每个簇中心随机生成时的边界框。
shuffle:是否打乱样本。
random_state:确定用于创建数据集的随机数生成。通过多个函数调用传递一个int类型的可复现输出。
return_centers: 如果为True,则返回每个集群的中心
返回值
X: 生成的样本。ndarray (n_samples, n_features)
Y: 每个样本的集群成员的整数标签。ndarray (n_samples,)
中心:centers 每个集群的中心。仅当return_centers=True时返回 ndarray(n_centers, n_features)
一般的训练流程
创建2d分类数据集
X, y = make_blobs(n_samples=1000, centers=5, n_features=2, cluster_std=2, random_state=2)
print(X)

print(y)

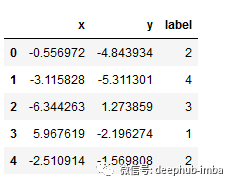
将X和y转换到pandas df
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
df.head()
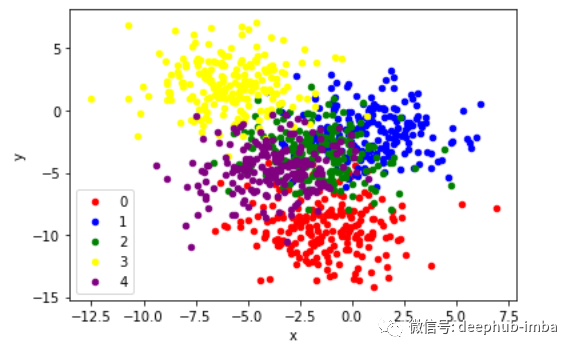
散点图可视化,按类值着色的点
colors = {0:'red', 1:'blue', 2:'green', 3:'yellow', 4:'purple'}
fig, ax = plt.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
plt.show()
from tensorflow.keras.utils import to_categoricaly = to_categorical(y)
print(y)

划分数据集
n_train = int(0.9 * X.shape[0])
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
定义模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu'))
model.add(Dense(5, activation='softmax'))
model
编译和训练
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=50, verbose=0)
history
评估模型
train_loss, train_acc = model.evaluate(trainX, trainy, verbose=0)
test_loss, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
Output: Train: 0.749, Test: 0.750
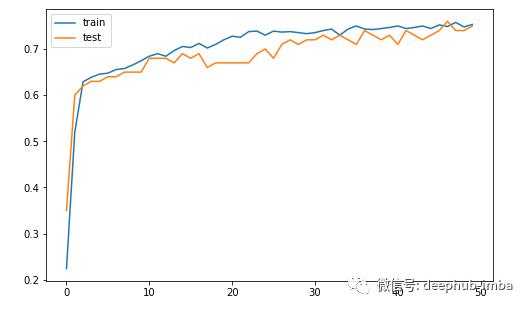
绘制模型精度的学习曲线
每个训练阶段训练和测试数据集模型精度的线图学习曲线
plt.figure(figsize=(8, 5))
plt.plot(history.history['accuracy'], label='train')
plt.plot(history.history['val_accuracy'], label='test')
plt.legend()
plt.show()
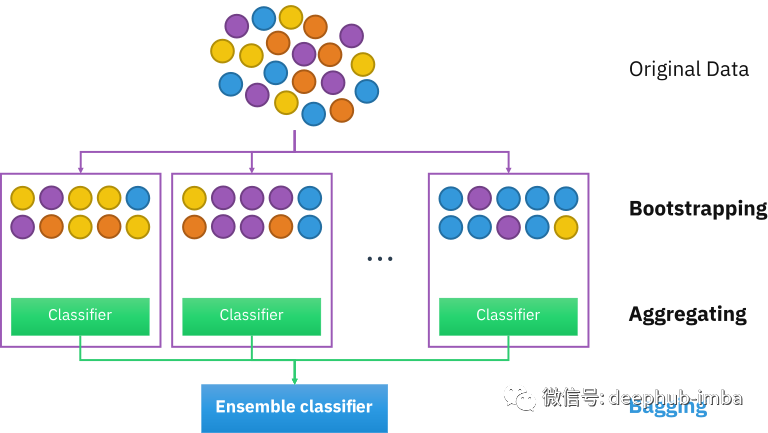
使用Bagging集成
Bootstrap aggregating,又称bagging (from Bootstrap aggregating),是一种用于提高统计分类和回归中机器学习算法的稳定性和准确性的机器学习集成元算法。
在Bagging法中,训练集中的随机数据样本是用替换法选择的——这意味着单个数据点可以被选择不止一次。在生成几个数据样本后,这些弱模型将被独立地训练,根据任务的类型——例如,回归或分类——这些预测的平均或众数将产生更准确的估计。
它还减少了方差,并有助于避免过拟合。虽然它通常应用于决策树方法,但它可以用于任何类型的方法。Bagging是模型平均法的一种特殊情况。
Bootstrapping 使用带有替换的随机抽样的测试或度量,并且属于更广泛的重抽样方法类别。Bootstrapping 为样本估计分配准确性度量(偏差、方差、置信区间、预测误差等)。该技术允许使用随机抽样方法估计几乎任何统计量的抽样分布。
让我们创建额外的数据集
dataX, datay = make_blobs(n_samples=55000, centers=5, n_features=2, cluster_std=2, random_state=2)
X, newX = dataX[:5000, :], dataX[5000:, :]
y, newy = datay[:5000], datay[5000:]
打印 dataX 和 datay 形状
dataX.shape, datay.shape
Output:((55000, 2), (55000,))
X.shape, newX.shape
Output:((5000, 2), (50000, 2))
y.shape, newy.shape
Output:((5000, 2), (50000, ))
现在我们有 5,000 个示例来训练我们的模型并估计其总体性能。我们还有 30,000 个示例,可用于更好地近似单个模型或集成的真实总体性能。
创建函数,该函数用于在训练数据集上拟合和评估模型。它将返回对测试数据的拟合模型的执行情况。
import numpy as np
from sklearn.metrics import accuracy_score
def evaluateModel(trainX, trainy, testX, testy):
#Convert trainy and testy into categorical
trainy_enc = to_categorical(trainy)
testy_enc = to_categorical(testy)
# Create a model
model = Sequential()
model.add(Dense(50, input_dim=2, activation='relu'))
model.add(Dense(5, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy_enc, epochs=50, verbose=0)
# evaluate the model
test_loss, test_acc = model.evaluate(testX, testy_enc, verbose=0)
# return the model and accuracy of test data
return model, test_acc
pass
对多类分类进行集成预测
def ensemblePredictions(members, testX):
# make predictions
yhats = [model.predict(testX) for model in members]
yhats = np.array(yhats)
# sum across ensemble members
summed = np.sum(yhats, axis=0)
# argmax across classes
result = np.argmax(summed, axis=1)
# return the result
return result
pass
创建一个函数来评估集成中特定数量的模型
def evaluateNMembers(members, n_members, testX, testy):
# select a subset of members
subset = members[:n_members]
# make prediction
yhat = ensemblePredictions(subset, testX)
# calculate accuracy
return accuracy_score(testy, yhat)
pass
使用重采样分割训练和测试集
from sklearn.utils import resample
n_splits = 10scores, members = list(), list()
for m in range(n_splits):
# select indexes
ix = [i for i in range(len(X))]
train_ix = resample(ix, replace=True, n_samples=4500)
test_ix = [x for x in ix if x not in train_ix]
# select data
trainX, trainy = X[train_ix], y[train_ix]
testX, testy = X[test_ix], y[test_ix]
# evaluate model
model, test_acc = evaluateModel(trainX, trainy, testX, testy)
print(f'test_acc: {test_acc:.2f}')
scores.append(test_acc)
members.append(model)

评估不同数量的集成效果
single_scores, ensemble_scores = list(), list()
for i in range(1, n_splits+1):
ensemble_score = evaluateNMembers(members, i, newX, newy)
newy_enc = to_categorical(newy)
_, single_score = members[i-1].evaluate(newX, newy_enc, verbose=0)
print(f'{i}: single={single_score: .2f}, ensemble={ensemble_score: .2f}')
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
pass

print(ensemble_scores)
print(single_scores)

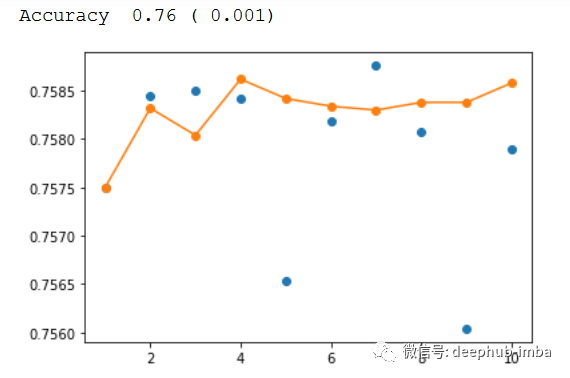
查看分数和集成数量的关系
print(f'Accuracy {np.mean(single_scores): .2f} ({np.std(single_scores): .3f})')
x_axis = [i for i in range(1, n_splits+1)]
plt.plot(x_axis, single_scores, marker='o', linestyle='None')
plt.plot(x_axis, ensemble_scores, marker='o')
plt.show()
本文作者:nutan