
写在前面
本篇主要说明了源码学习过程中服务端的相关知识点。通过本章节的学习,
1、对服务端的网络、存储、副本同步、集群管理相关的细节又回顾了一篇,比之前死记硬背好很多。
2、感觉很多架构的设计还是来源于实际需求,当然kafka的核心点就是:异步、削峰、解耦。
注意:
1、Kafka网络设计,理解超高并发的网络设计
2、juc,跳表,log【存储】,内存映射写稀松索引,时间轮机制,后续需要持续跟进。
1、服务端—网络
参考链接:深度剖析:Kafka 请求是如何处理? 看完这篇文章彻底懂了!
Kafka 服务端的网络设计通常采用三层架构,它包括以下三层:
网络层:Acceptor负责接受来自客户端的连接请求,并创建对应的网络连接。
请求层:Processor 负责处理来自客户端的请求,并将其传递给合适的 Handler 进行处理。它处于请求处理的中间层,负责请求的分发和路由。
处理层:Handler 接收到 Processor 分发的请求后,负责解析请求、执行相应的操作,并生成响应返回给客户端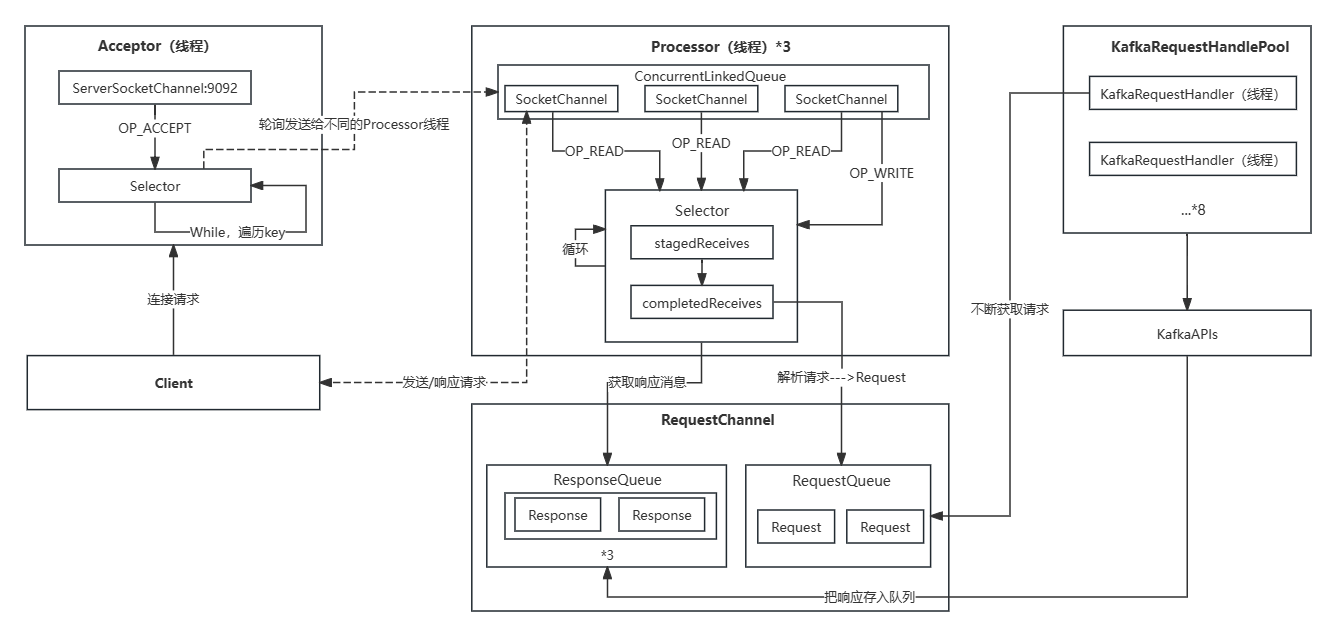
1.1、服务端acceptor线程启动
- 入口函数:main;完成参数设置,调用启动函数
包名kafka.Kafka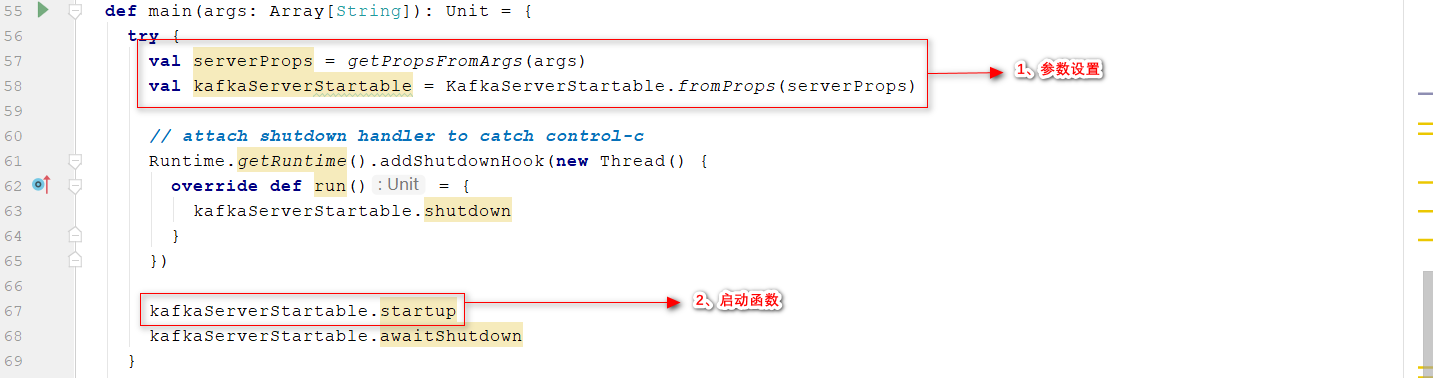
- kafka服务端启动的核心方法在
startup()中,Start up API for bringing up a single instance of the Kafka server.,启动NIO服务端 kafka.server.KafkaServer
- SocketServer启动后,创建acceptor线程 位置1:endpoints取决于配置kafka的时候,在
config/server.properties里面的配置个数,例如:kafka1:9092,一般设置一个服务实例就可以 位置2:创建一个acceptor对象,继承AbstractServerThread,Acceptor 是整个网络通信的入口点之一,负责处理客户端的连接请求,从而允许客户端与 Kafka 集群进行通信 位置3:Utils是一个工具类,里面由一个newThead方法,帮我们启动线程使用
- run()方法中,执行逻辑就像JavaNIO中服务端轮询查看是否有请求接入 位置1:
ServerChannel向Selector注册一个OP_ACCEPT事件,表示Selector会检查ServerChannel中是否有新的请求到达位置2、位置3:Selector遍历注册的Key,如果key=OP_ACCEPT,调用accept()接收请求 位置4:创建SocketChannel,以轮询的方式放入到不同的Processor线程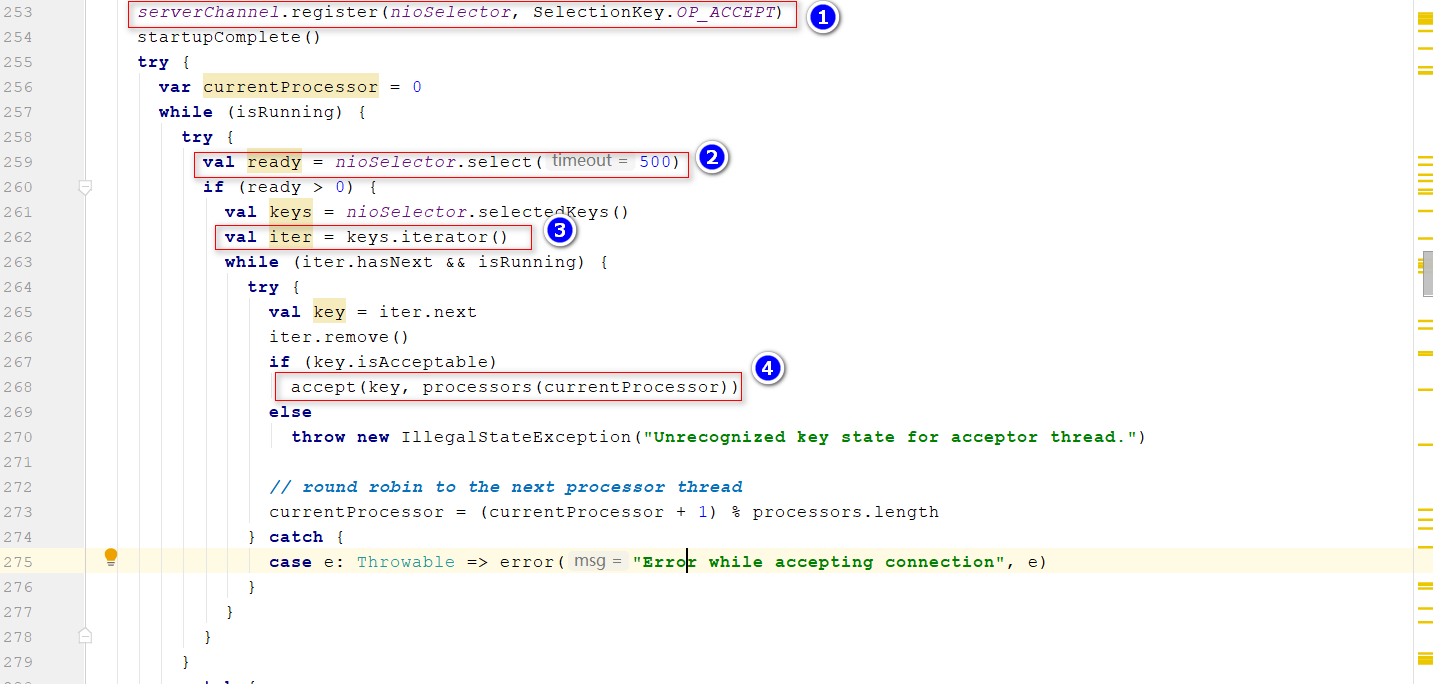
1.2、服务端Processor线程
1.2.1、Processor线程启动
- 创建位置和Acceptor一样,不过这里并没有启动Processor线程 processorBeginIndex:0 numProcessorThreads:默认值是3,由参数
num.network.threads控制
- Acceptor构造的时候,会在其主构造函数中执行(Scala),这个时候Processor线程启动

1.2.2、Processor如何接收请求
在Processor的run()方法,
configureNewConnections(),Register any new connections that have been queued up位置1:不断轮询,获取队列里面的SocketChannel 位置2:获取配置信息,产生ConnectionId 位置3:向Selector中注册这个SocketChannel,这里的Selector是kafka自己封装的一个KSelector,和Acceptor中的Selector不是一个import org.apache.kafka.common.network.{ChannelBuilders, KafkaChannel, LoginType, Mode, Selector => KSelector}(对生产者代码封装的Selector进行复用)
- 向KSelector中注册一个OP_READ的事件,这个时候就可以读取来自客户端发送过来的请求;此外,封装了一个KafkaChannel,放入到

poll():根据之前对Producer源码剖析,读取和发送数据的底代码都是在这个方法里面完成,具体剖析过程略;将数据放入stagedReceives(尚未处理的数据)
1.2.3、Processor如何处理stagedReceives的请求
在Processor的run()方法,
processCompletedReceives(),处理接收标记完成的数据, 位置1:遍历每一个请求 位置2:对于获取到的请求按照协议进行解析,解析出来就是一个个Request 位置3:本质上调用requestQueue.put(request),把这个请求放入RequestQueue 通过参数queued.max.requests设置,RequestChannel在SocketServer初始化的时候创建位置4:底层代码,移除OP_READ事件,因为接下来要写数据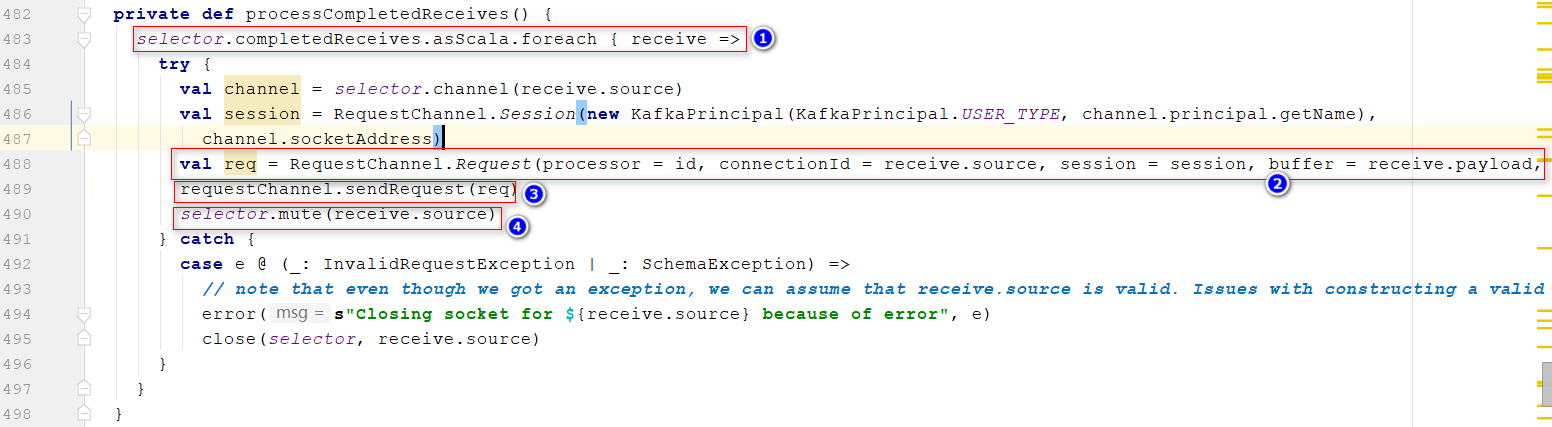
1.2.4、队列里面的Request什么时候被处理?
KafkaRequestHandlerPool处理请求队列里面的请求
- 池子里面,默认启动8个线程处理请求队列里面的请求,通过参数
num.io.threads设置
- 查看
KafkaRequestHandler里面的,交给apis.handle(req)处理
- 以处理生产者的请求为例,对应方
handleProducerRequest()方法 位置1:获取到生产者发送过来的请求信息 位置2:按照分区的方式去遍历数据,authorizedRequestInfo授权并且可以访问的Topic 位置3:把数据追加到磁盘上,网络部分先暂时不分析
- 数据完成存储后,调用
sendResponseCallback()回调函数 位置1:封装响应头和响应体 位置2:把响应的消息放入到ResponseQueues,一个队列数组new Array[BlockingQueue[RequestChannel.Response]](numProcessors)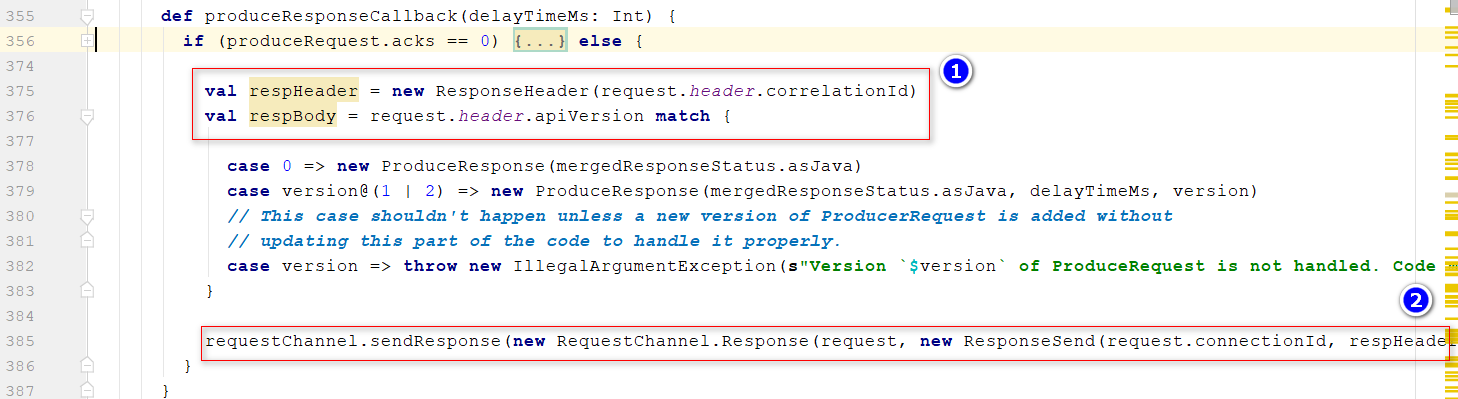
1.2.5、服务端响应客户端
Response放入到队列数组中,数组大小等于Processor的大小,可以推测出应该在Processor中处理响应消息,
- 回到run()方法里面的processNewResponses() 位置1:读取对应响应队列里面Response 位置2:发送消息,核心注册
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);事件,然后通过poll()方法完成响应消息的发送,发送完成后解绑OP_WRITE事件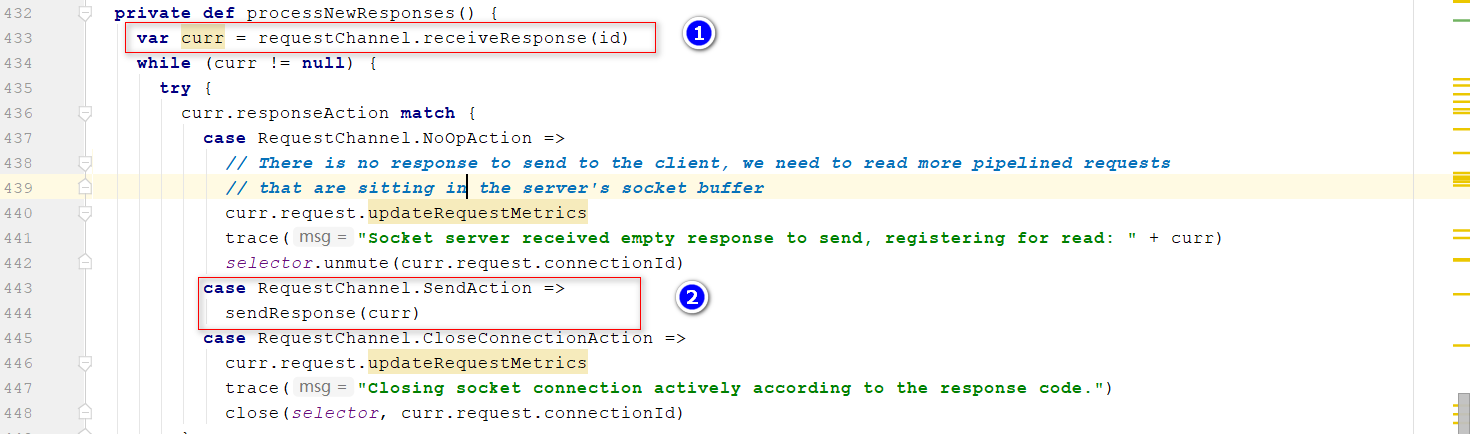
processCompletedSends():发送完响应消息后 位置1:从响应消息队列里面移除Response 位置2:解绑OP_RED事件
2、服务端—存储
参考链接:搞透Kafka的存储架构,看这篇就够了
参考链接:kafka中Topic、Partition、Groups、Brokers概念辨析,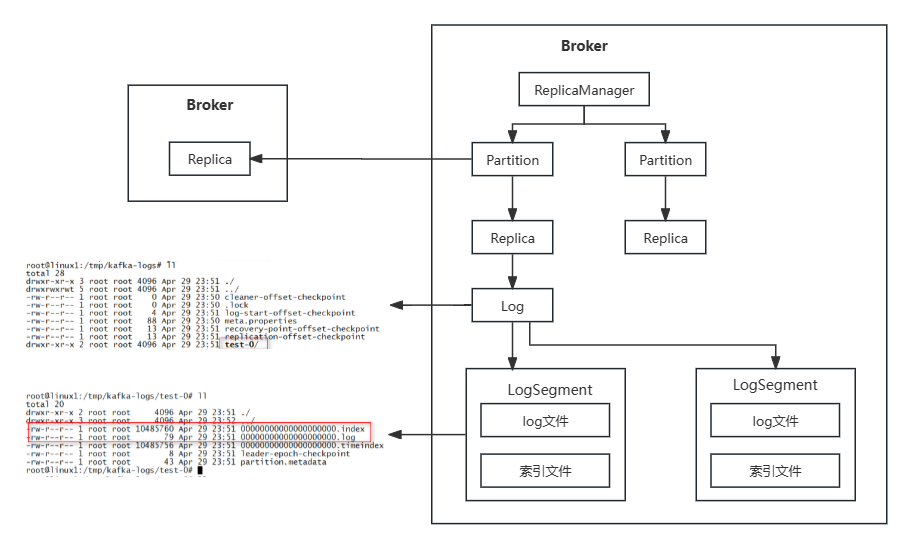
注:图中的Partition其实应该是带Topic信息的Partition,即
kafka.cluster.Partition
,相关注释:
Data structure that represents a topic partition. The leader maintains the AR, ISR, CUR, RAR
2.1、ReplicaManager写数据流程
extends Logging
- 在
kafka.server.KafkaServer中,初始化ReplicaManager,核心参数LogManager
- 回到之前网络请求部分,
kafka/server/KafkaApis.scala调用replicaManager.appendMessages将数据存储到本地磁盘位置1:判断传入的acks是否合法(-1,0,1) 位置2:把数据追加到本地日志里面 位置3:根据写日志返回的结果,去封装返回给生产者的响应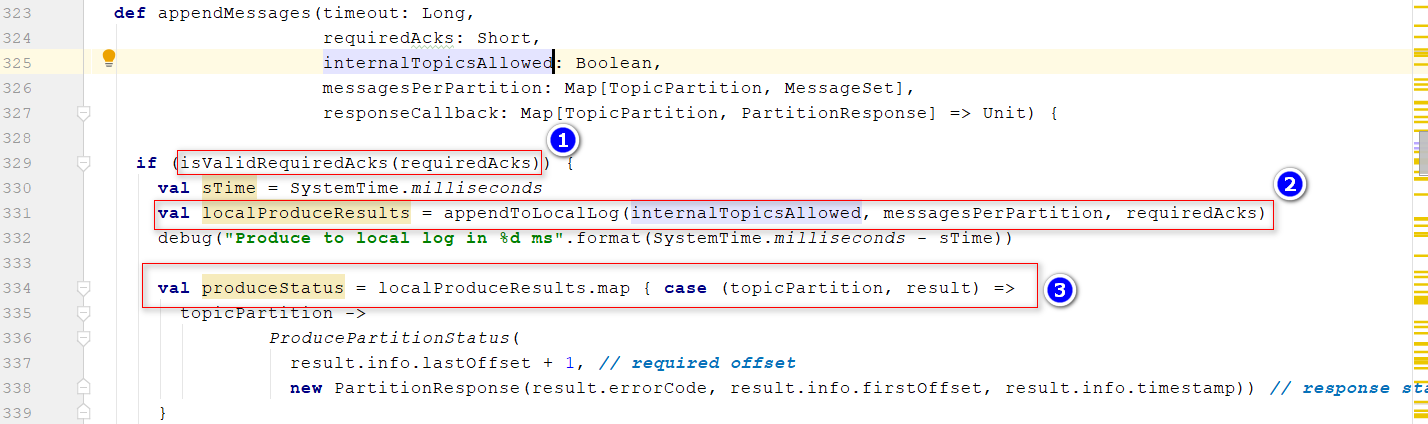
- 进入
appendToLocalLog()方法,Append the messages to the local replica logs位置1:遍历每个分区,注意这里的数据结构Map[TopicPartition, MessageSet],和之间我们封装消息最开始的格式一样, 位置2:判断是否是内部的主题__consumer_offsets,这里消息来自生产者,内部不在这里处理 位置3:把数据写入LeaderPartition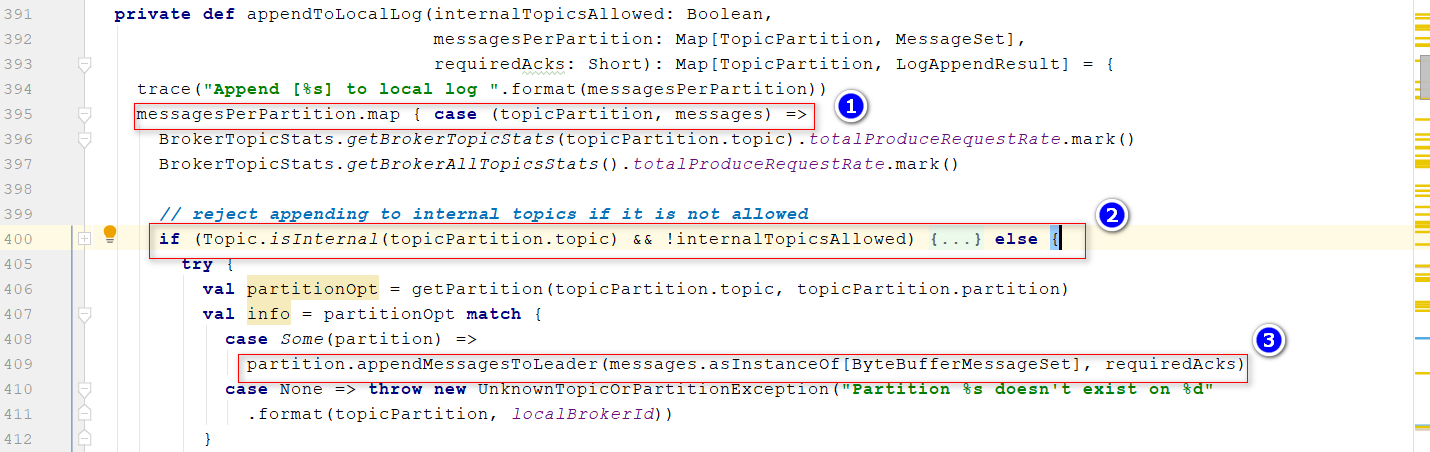
- 进入
appendMessagesToLeader()方法, 位置1:返回一个LeaderReplica对象, 位置2:获取log对象 位置3:使用log对象写消息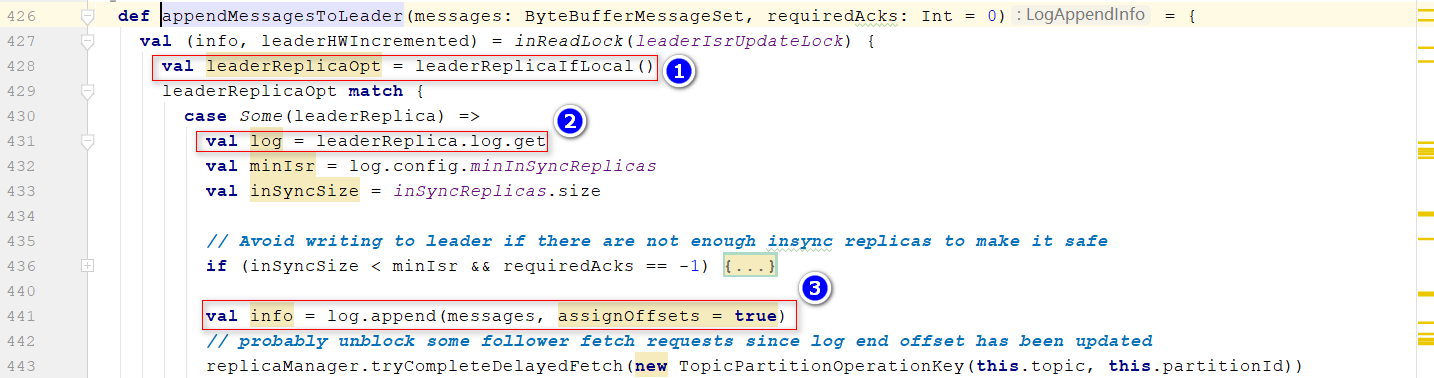
2.2、LogManager启动
extends Logging
- 在
kafka.server.KafkaServer中,初始化LogManager
- 方法
createLogManager()中,logDirs = config.logDirs.map(new File(_)).toArray,通过参数log.dirs设置,可以配置多个目录 查看主构造函数 位置1:
查看主构造函数 位置1:一个分区(磁盘上的一个目录)一个Log位置2:创建log.dirs位置3:加载Logs
- 进入
loadLogs(),Recover and load all logs in the given data directories 遍历所有的目录(配置的存储日志的目录),为每个目录创建一个线程池,后续为每个TopicPartition创建一个Log对象
- 初始化完成后,在
startup()方法中调用三个定时任务 *定时检查文件,清理超时的文件,cleanupExpiredSegments(log)+cleanupSegmentsToMaintainSize(log),默认定期删除,但是不按照文件大小删除 *定时把内存数据刷新到磁盘里面去,默认由操作系统完成,通过参数
*定时把内存数据刷新到磁盘里面去,默认由操作系统完成,通过参数flush.ms设置 *定时更新检查点文件,用于kafka服务重启时,恢复数据
*定时更新检查点文件,用于kafka服务重启时,恢复数据
2.2、Log对象append过程
extends Logging
- 进入
append()方法 位置1:校验数据(Producer—>broker) 位置2:分配偏移量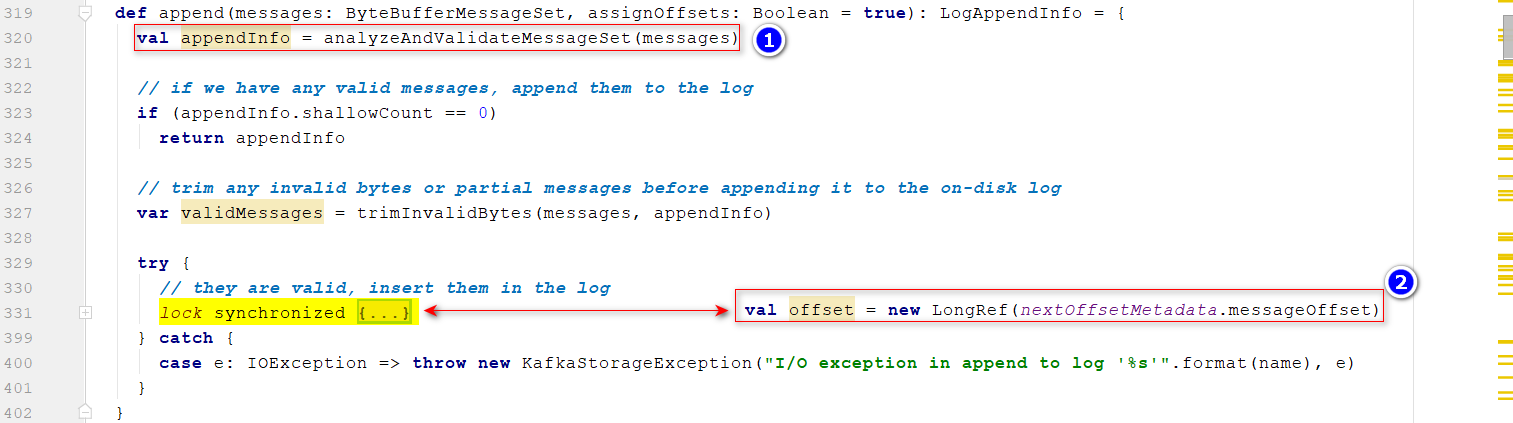 位置3:获取一个segment,把书记写入到segment中去 位置4:更新
位置3:获取一个segment,把书记写入到segment中去 位置4:更新LEO:LEO=lastoOffset+1 位置5:根据配置的频率,把内存的数据写入到磁盘
问题:新建loadSegment的策略Log下的segments定义的类型为ConcurrentNavigableMapkafka.log.Log ConcurrentNavigableMap:java JUC下面的一个数据结构,是跳表实现的一个并发安全的Map集合;key:文件名(base offset),value:一个segment,目的是为了用户根据offset大小快速定位到segment 参考链接:跳表的原理与实现 [图解],本质上
参考链接:跳表的原理与实现 [图解],本质上二分查找
2.3、LogSegment建立索引,写入数据
extends Logging,
利用内存因素,建立系数索引
- 进入上面
Log的append()步骤3中,通过segment去append数据 位置1:indexIntervalBytes:通过参数index.interval.bytes配置,默认值4096,即当写入的消息超过4096个字节的时候会更新一条索引,bytesSinceLastIndexEntry = 0; 位置2:写数据到磁盘(内存)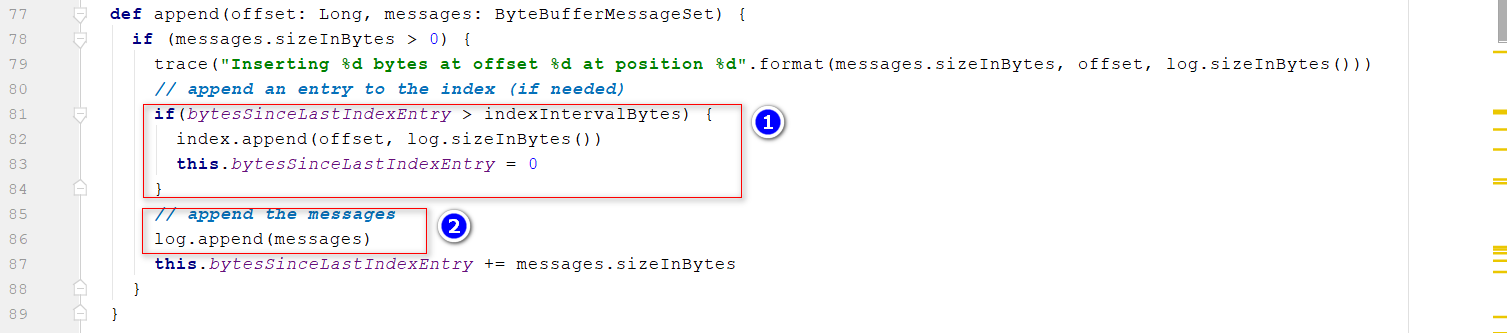
- 进入
index.append()方法,记录索引的时候,记录以下两个位置: offset:逻辑位置,即偏移量 position:物理位置,消息在磁盘上的位置
- 进入
log.append()方法,最终进入writeFullyTo(),写入数据 位置1:标记一下position位置 位置2:java NIO,通过FileChannel写入数据到内存位置3:恢复之前标记的position位置
2.4、发送响应给客户端
- 在
kafka.server.ReplicaManager中,完成消息的存储后,返回一个localProduceResults
- 将
localProduceResults封装后,返回给生产者 位置1:如果ack=s-1,调用位置2;acks=-1表示需要等follower节点拷贝leader的数据后返回响应位置2:涉及到时间轮机制,核心等follower节点拷贝leader的数据后,唤醒发送响应的任务 位置3:调用responseCallback的回调函数,即sendResponseCallback(responseStatus)方法,这里就和服务端网络部分返回响应连接起来了
3、服务端—副本同步
3.1、ReplicaFetcherManager启动fetcherThread线程
- 进入
ReplicaManager,发现定义了ReplicaFetcherManager,负责管理副本数据拉取, 执行代码replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset),添加follower partition去leader partition拉取任务。
- 进入
addFetcherForPartitions方法 位置1:按照topicPartition+broker进行分组; 位置2:将得到的partitionsPerFetcher对象,拆解为broker+partitionOffset, 位置3:匹配brokerAndFetcherId,针对不同的broker开启一个线程,用于去同步数据,这里就类似之前在生产者发送数据给broker一样的方式,减少网络请求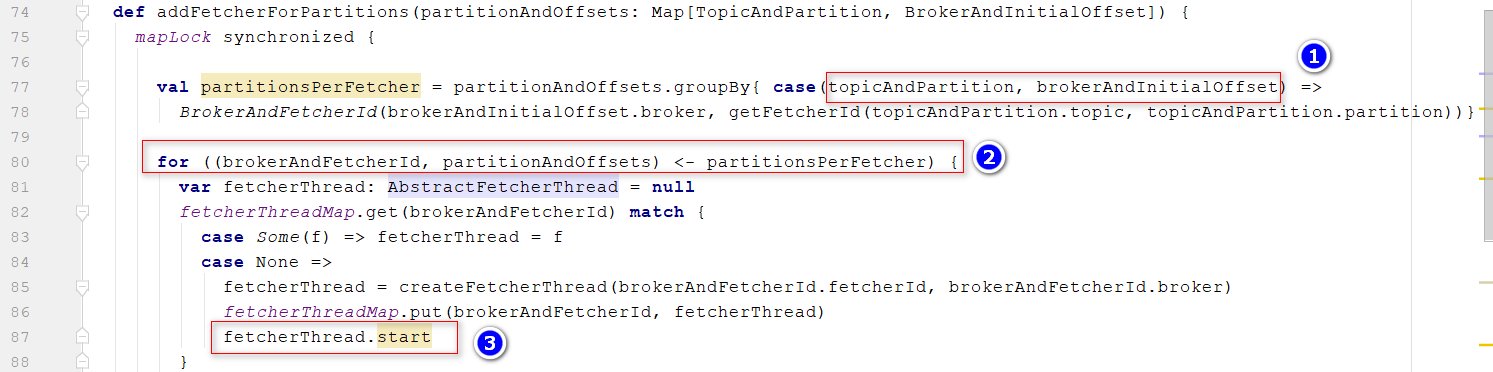
- 通常情况下,会调用线程的run方法,这里调用的是
kafka/server/AbstractFetcherThread.scala的doWork方法,核心是为了创建fetchRequest,通过fetch(fetchRequest)处理;即会通过Selector发送请求给leader,略
3.2、Leader接收并处理fetch请求
- 从
KafkaApis中找到处理fetch请求的方法
- 进入
fetchMessages()方法 位置1:call the replica manager to fetch messages from the local replica 位置2:调用回调函数
- 进入
readFromLocalLog(),获取localReplica(即Leader的Replica),然后通过log读取需要拉取的数据,本质上还是通过logsegment进行处理的;
- 最终封装的是
FileMessageSet,位置在kafka\log\FileMessageSet.scala
**
问题:Leader 响应失败,如何处理?=Follower fetch失败
**
在
ReplicaManager的fetchMessages()
方法中,
位置1:判断消息返回成功的条件,失败的情况包括
返回的消息<fetchMinBytes
,即生产者长时间未生产消息
位置2:为了避免上述情况导致
Follower持续发生fetch请求,浪费网络资源
,封装一个延迟调度的任务。
位置3:
把延迟调度的任务放到时间轮里面进行调度。
注:这里对应之前生产者发送消息Leader后,再2.4存储的时候唤醒。
3.3、LEO和HW更新流程
参考链接:美团面试官让我聊聊kafka的副本同步机制,我忍不住哭了
参考链接:Kafka-LEO和HW概念及更新流程
- LEO:日志末端位移,代表日志文件中下一条待写入消息的offset,这个offset上实际是没有消息的。
- HW:副本的高水印值,replica中leader副本和follower副本都会有这个值,通过它可以得知副本中已提交或已备份消息的范围,leader副本中的HW,决定了消费者能消费的最新消息能到哪个offset。
- ISR:包含了 leader 副本和所有与 leader 副本保持同步的 Followerer 副本。
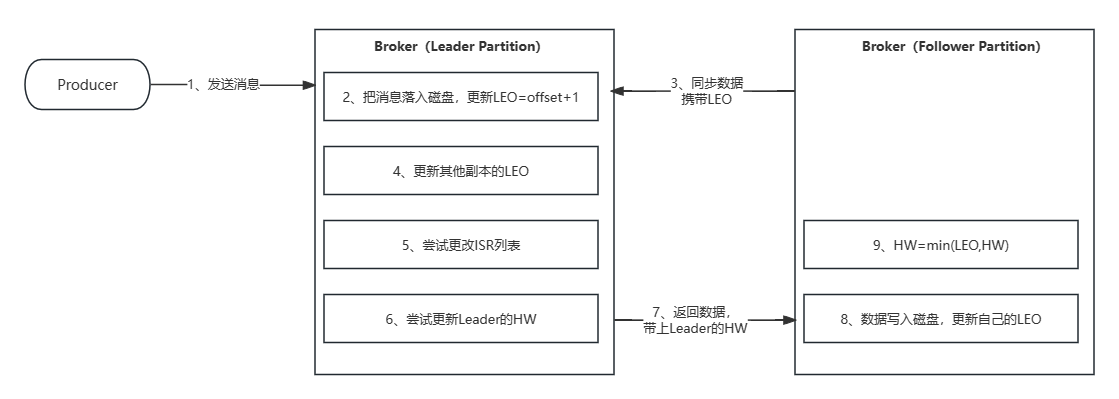
- 生产者发送消息
- 回到
kafka.log.Log的append()方法,可以很清楚的看的segment写完消息后,更新LEO
- follower发送拉取数据的请求,
PartitionFetchState携带LEO信息
- 通过追踪Leader KafkaApis的
case ApiKeys.FETCH => handleFetchRequest(request)方法,标记黄色部分就是更新replica的offset
- Replica的LEO>=Leader的HW,说明Replica的数据与Leader数据同步,则ISR列表添加这个Replica
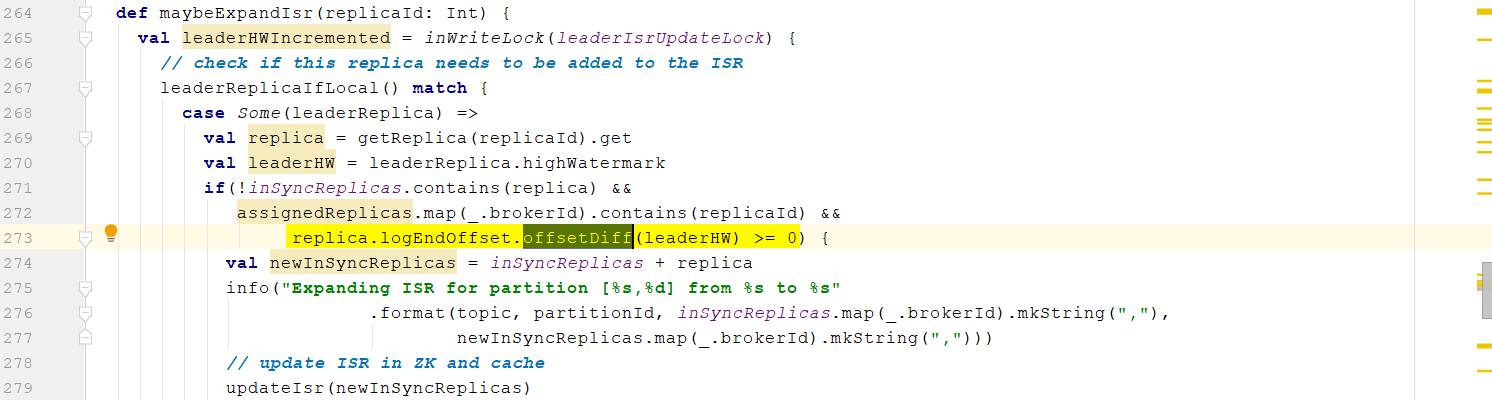
- 用于更新Leader的HW,相关注释见代码
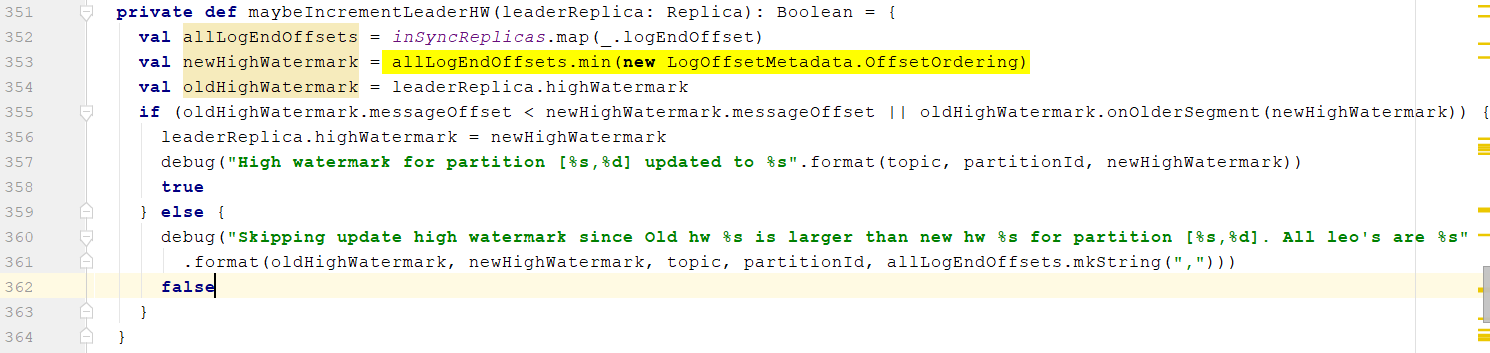
- 返回响应的数据,携带HW

- 进入
processPartitionData(),process fetched data位置1:本质上就是log文件添加消息,和2重复同样的过程 - 位置2:更新follower的HW

3.4、ISR定时检查线程
- 在
ReplicaManager的startup方法,定时调度线程maybeShrinkIsr()方法
- 对于每个Partition(包括Topic),检查是否需要移除ISR列表 位置1:获取需要移除的Replica 位置2:可能需要重新更新HW,保证消费者可以获得最新的已经同步的消息。
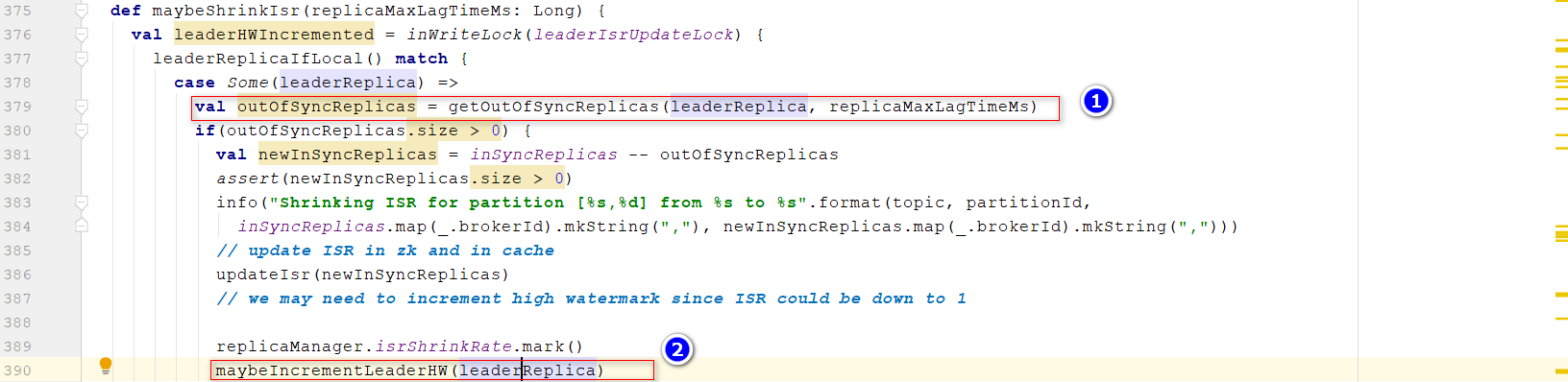 判断是否需要移出ISR的条件:当前时间-上一次获取LEO的时间>默认10s,通过参数
判断是否需要移出ISR的条件:当前时间-上一次获取LEO的时间>默认10s,通过参数replica.lag.time.max.ms设置
4、服务端—集群管理
图中每个链路对应第四章不同的小节
4.1、Controller创建过程
参考链接:Kafka Controller工作原理
Controller是Kafka集群中的一个核心组件,负责管理集群中的分区副本(partition replicas),以及处理集群中的各种状态转换和操作,包括Leader选举、分区的创建与删除、副本的状态监控与管理、集群中Broker的变更处理。
- 进入
KafkaServer,尝试启动controller
- 进入
kafka.server.ZookeeperLeaderElector位置1:对zookeeper上的/controller目录注册监听器 位置2:选举controller
- 进入
elect()方法 封装一个JSON串,用于存储controller信息 第一次启动发时候,leaderId返回值-1
第一次启动发时候,leaderId返回值-1 位置1:
位置1:创建Zookeeper临时目录,在Apache Kafka中,临时目录的使用是为了表示集群成员的活动状态,会话断开时会自动删除。 位置2:调用onControllerFailover()方法,本质上注册各种监听器 位置3:如果Zookeeper上已经存在临时目录,说明controller已经存在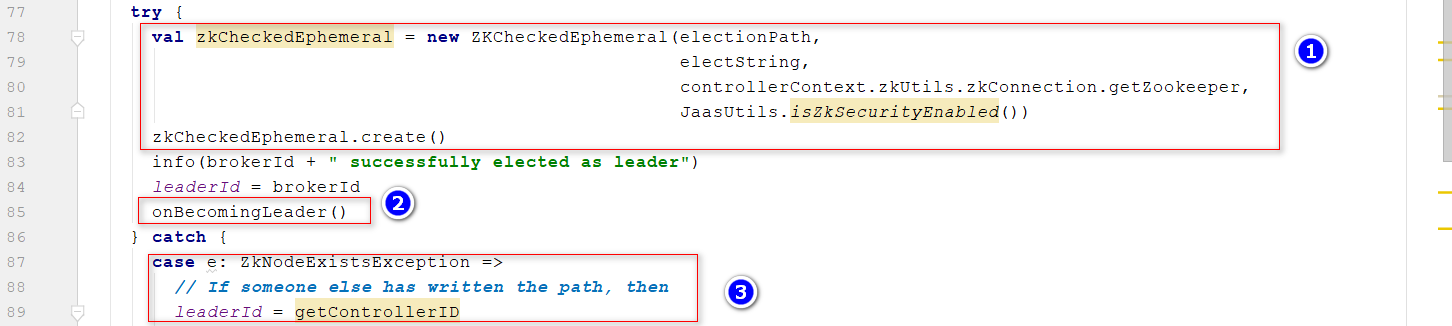
4.2、Broker注册过程
- 进入
KafkaServer,KafkaHealthcheck作用如下:This class registers the broker in zookeeper to allow other brokers and consumers to detect failures.
- 在Zookeeper上注册Broker节点信息 brokerIdPath:/brokers/ids/
brokerIDbrokerInfo:jsonMap,封装了Broker的信息,包括:host,port,endpoints,jmx_port,timestamp
4.3、如何感知新注册的Brokers
- controller在
onControllerFailover()方法中,通过注册replicaStateMachine.registerListeners(),监听broker的变化
- 进入
BrokerChangeListener(),查看监听器具体内容 获取所有的Brokers、处于live状态的Brokers、新加入进来的Brokers、宕机的Brokers
- Controller开始处理新的、宕机的brokers,
这个时候只controller知道,因为controller监听Zookeeper目录
- Controller通过网络请求,把
更新元数据的信息发生发送出去,UPDATE_METADATA_KEY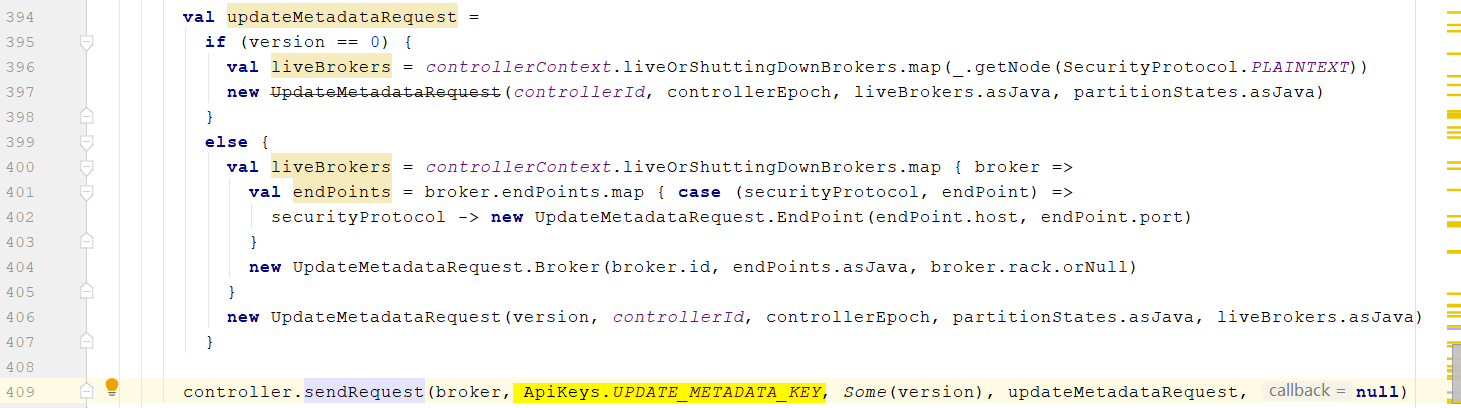
- 其他它节点接受消息,通过KafkaApis处理,
case ApiKeys.UPDATE_METADATA_KEY => handleUpdateMetadataRequest(request),通过handleUpdateMetadataRequest()处理,继续追踪,直到进入kafka.server.MetadataCache的updateCache方法 位置1:清楚之前的Brokers信息 位置2:获取Controller发送过来的Brokers信息 位置3:更新Brokers信息
4.4、Topic创建过程
- 进入
kafka-topics.sh,调用TopicCommand对象
- 进入
createTopic()方法 位置1:assignment=Map[Int, List[Int]],分配方式,如创建一个topic,分区数为3,其中broker0上分配p0,p2,;则assignment=[broker0,[p0_0,p2_0]], 位置2:把分配方案放到Zookeeper上,写入位置/brokers/topics,这样Controller就可以感知到新创建的topic
- 回到KafkaController,通过
PartitionStateMachineController监听topic的变化, BrokerTopicsPath = “/brokers/topics”
BrokerTopicsPath = “/brokers/topics”
TopicChangeListener,查看监听器的处理 This is the zookeeper listener that triggers all the state transitions for a partition 位置1:从Zookeeper里面读取分区的分配方案1位置2:如果有新的Topic创建,则发送请求给其他Brokers,发送请求过程略
版权归原作者 雪碧没有冰块 所有, 如有侵权,请联系我们删除。