
目的: 鉴于目前网络上没有完整的kafka数据投递至splunk教程,通过本文操作步骤,您将实现kafka数据投递至splunk日志系统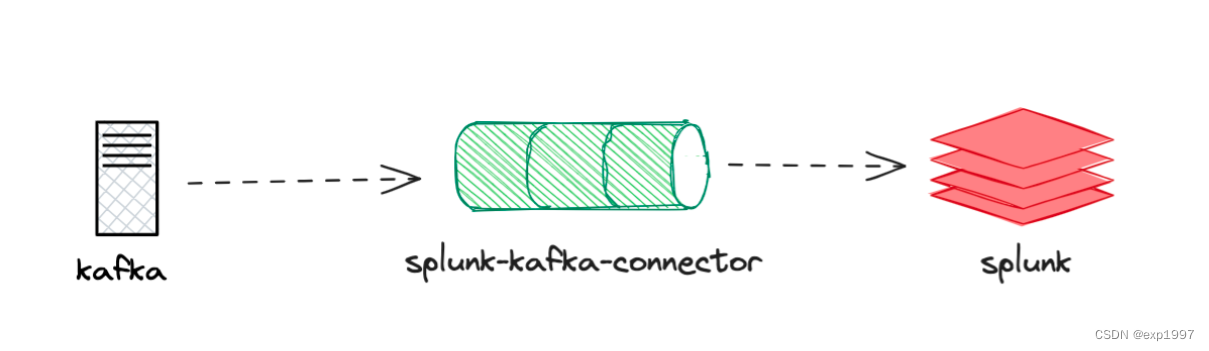
实现思路:
- 创建kafka集群
- 部署splunk,设置HTTP事件收集器
- 部署connector服务
- 创建connector任务,将kafka主题消息通过connector投递到splunk
测试环境:
- 测试使用的操作系统为centos7.5_x86_64
- 文章提供了两种部署方式,分别是单机部署和容器化部署
- 单机部署使用的主机来自腾讯云-cvm产品(腾讯云CVM),1台4c8g(如果条件允许,建议使用3台2c4g主机,分别部署kafka、connector、splunk,钱包有限,这里只是教程,不讲究这些)
- 上述云主机,已安装JDK8及以上版本
- 容器化部署使用的k8s集群来自腾讯云TKE,可以一键部署k8s集群,欢迎体验~
一、部署splunk
●splunk是一款收费软件,如果每天的数据量少于500M,可以使用Splunk提供的免费License,但不能用安全,分布式等高级功能。
部署步骤如下:
部署方式1:容器部署:
- 安装并启动docker(k8s集群节点可免除此步骤):
yum installdocker-y
systemctl start docker
- 获取splunk镜像:
# https://hub.docker.com/r/splunk/splunk/tagsdocker pull splunk/splunk
- 【非必须,3和4选一个】启动splunk容器,设置为自动接受lic,设置密码:
docker run -d-p8000:8000 -e"SPLUNK_START_ARGS=--accept-license"-e"SPLUNK_PASSWORD=你的密码"-p8088:8088 --name splunk splunk/splunk:latest
- 【非必须,3和4选一个】在k8s中以工作负载方式部署splunk,这将为你创建一个splunk-ns命名空间,并创建deployment类型的工作负载部署splunk,以及一个LB类型的service,请根据你的需要修改命名空间、镜像、密码、端口:
vi splunk-deployment.yaml
apiVersion: v1
kind: Namespace
metadata:name: splunk-ns
---apiVersion: apps/v1
kind: Deployment
metadata:name: splunk
namespace: splunk-ns
spec:replicas:1selector:matchLabels:app: splunk
template:metadata:labels:app: splunk
spec:containers:-name: splunk
image: splunk/splunk:latest
ports:-containerPort:8000-containerPort:8088env:-name: SPLUNK_START_ARGS
value:"--accept-license"-name: SPLUNK_PASSWORD
value:"你的密码"volumeMounts:-name: splunk-data
mountPath: /opt/splunk/var
volumes:-name: splunk-data
emptyDir:{}---apiVersion: v1
kind: Service
metadata:name: splunk
namespace: splunk-ns
spec:selector:app: splunk
ports:-name: http
port:8000targetPort:8000-name: mgmt
port:8088targetPort:8088type: LoadBalancer
- 打开浏览器,访问splunk的地址:8000,预期可以看到splunk的页面。用户名/密码:admin/你的密码

部署方式2:单机部署:
- 注册账号并获取splunk下载链接:https://www.splunk.com/en_us/download/splunk-enterprise.html ⚠️
- 解压缩
# 解压到/opttar-zxvf splunk-8.0.8-xxzx-Linux-x86_64.tgz -C /opt
- 启动splunk,接受许可
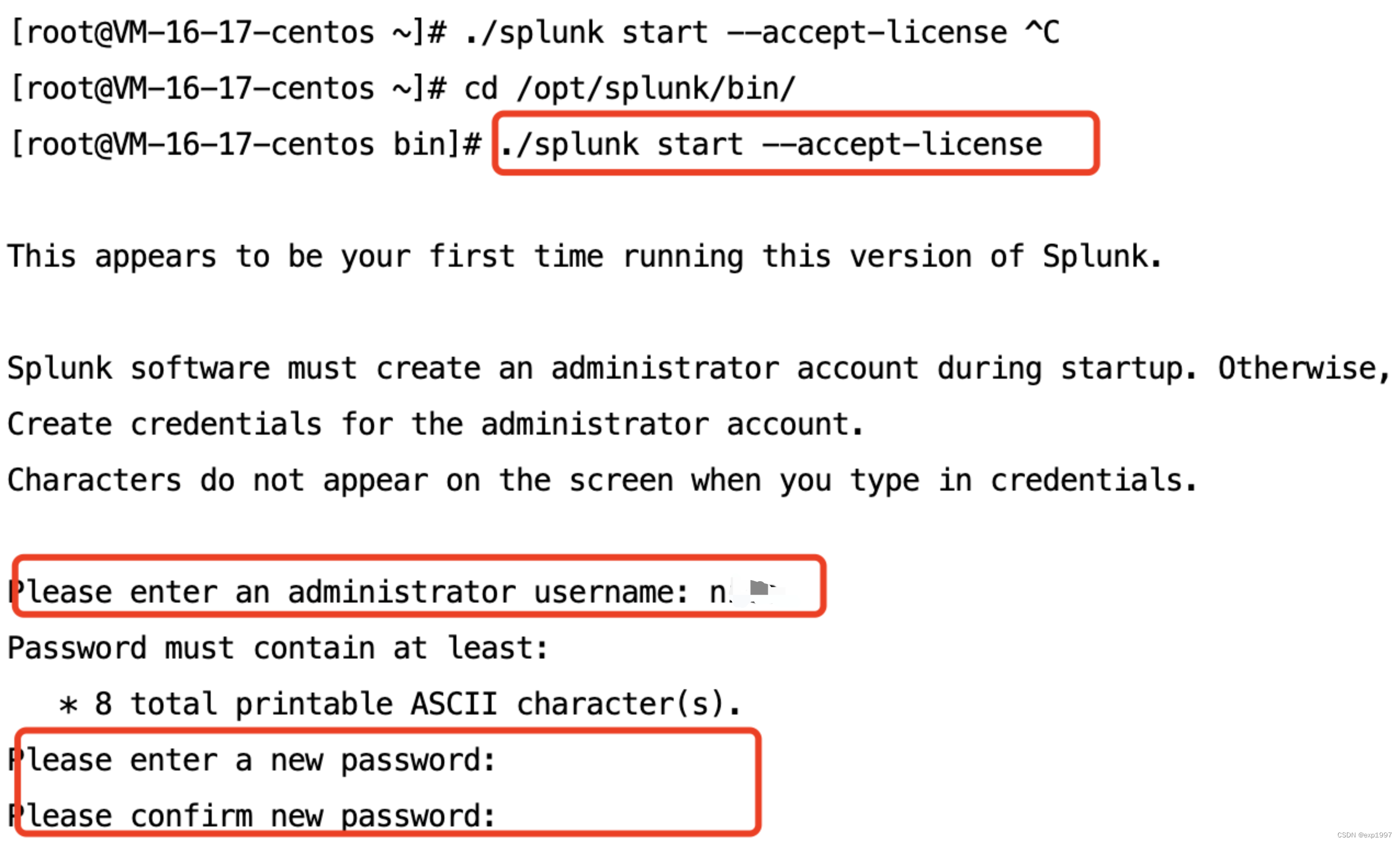
cd /opt/splunk/bin/
./splunk start --accept-license //启动,并自动接收许可
- 输入自定义用户名、密码
 其他命令参考:
其他命令参考:
./splunk start //启动splunk
./splunk restart //重启splunk
./splunk status //查看splunk状态
./splunk version //查看splunk版
#卸载
./splunk disable boot-start //关闭自启动
./splunk stop //停止splunk
/opt/splunk/bin/rm–rf/opt/splunk //移除splunk安装目录
- splunk安装之后,默认开启Splunk Web端口8000。我们访问8000端口 ●ps:Splunkd端口8089为管理端口
至此,splunk部署成功
二、配置Splunk HTTP 事件收集器
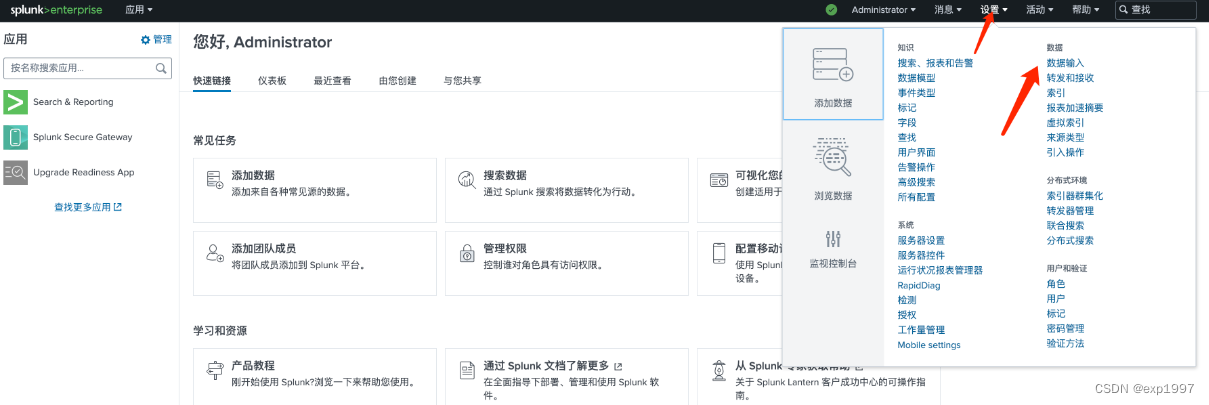
- 在splunk中配置HTTP 事件收集器: a. 进入splunk web页面,点击右上角【设置】-【数据输入】
 b. 选择HTTP事件收集器,点击【全局设置】,启用标记,HTTP端口为8088,点击【保存】
b. 选择HTTP事件收集器,点击【全局设置】,启用标记,HTTP端口为8088,点击【保存】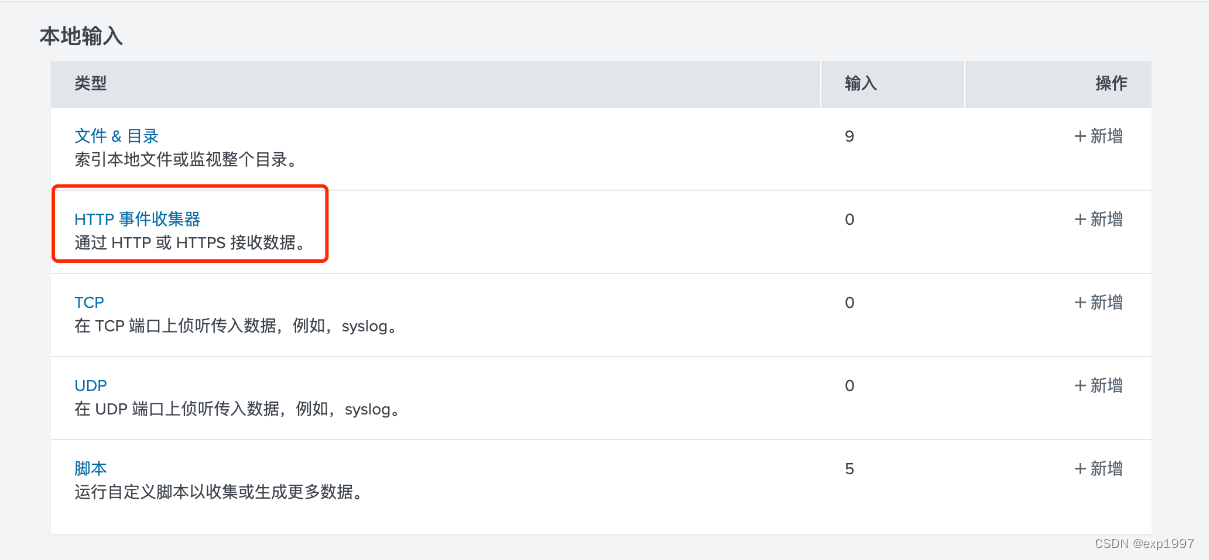 c. 点击右上角【新建标记】,新建HTTP事件收集器,填写:> 填写名称:splunk_kafka_connect_token,点击【下一步】;> 新建来源类型“splunk_kafka_data”,新建索引“splunk_kafka_index”,点击【检查】;> 提交;
c. 点击右上角【新建标记】,新建HTTP事件收集器,填写:> 填写名称:splunk_kafka_connect_token,点击【下一步】;> 新建来源类型“splunk_kafka_data”,新建索引“splunk_kafka_index”,点击【检查】;> 提交;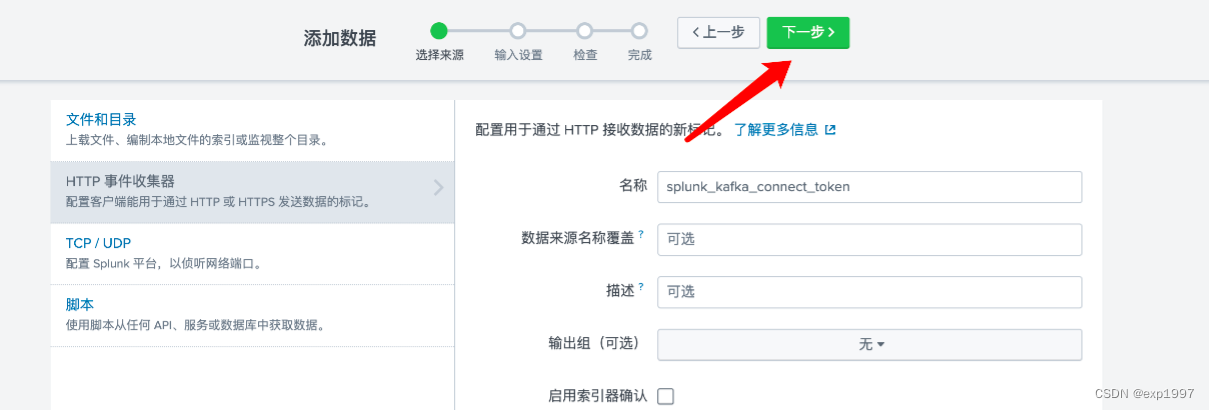
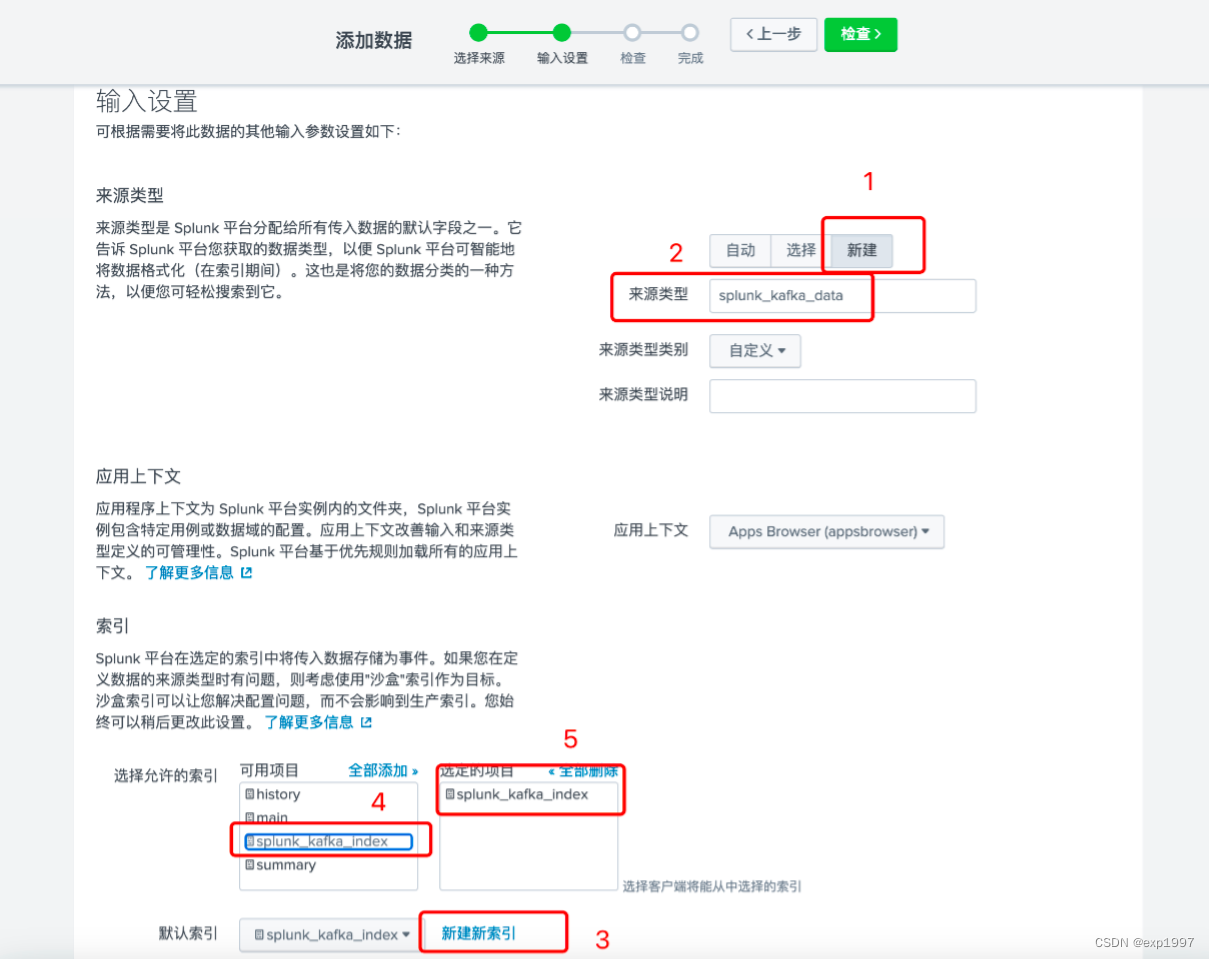
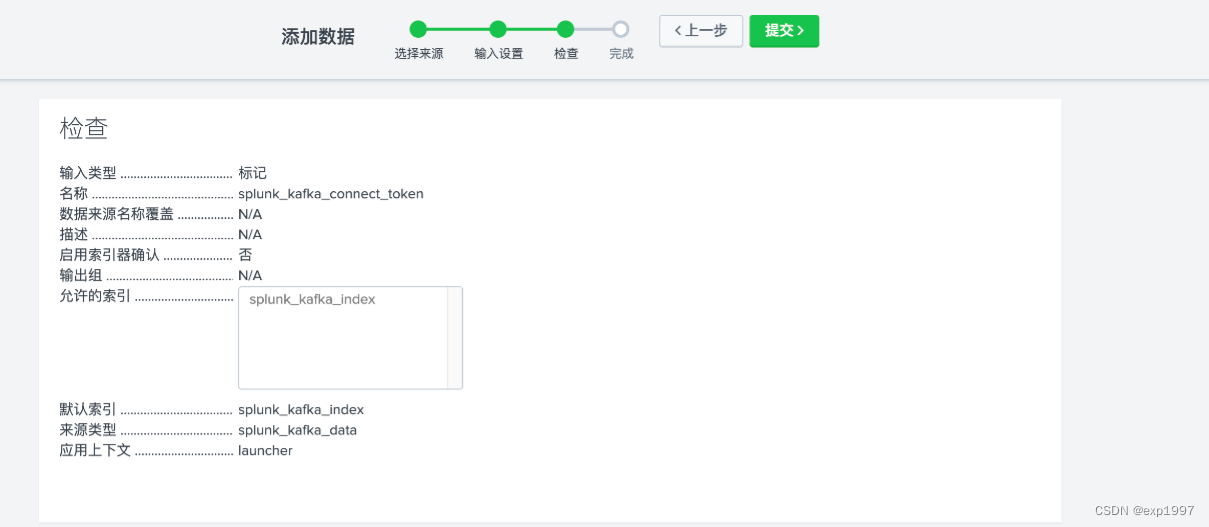
- 随后,在设置-数据输入-HTTP事件收集器页面,将得到一个token,记录此token

三、启动kafka并生产消息
- 启动kafka实例 a. 安装jdk
yum installjava-y
b. 下载kafka:https://kafka.apache.org/downloads,以2.12版本为例
c.解压
tar-zxvf kafka_2.12-3.6.1.tgz
d.启动zookeeper
cd kafka_2.12-3.6.1/
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
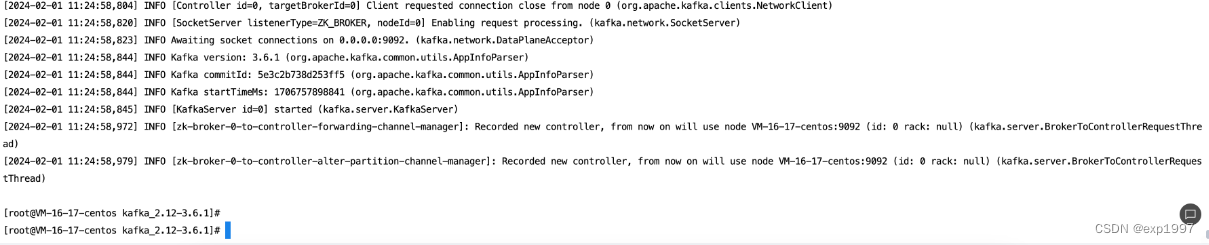
e.启动kafka
./bin/kafka-server-start.sh config/server.properties &
f.创建topic,假设叫topic0
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1--partitions1--topic topic0

g.使用生产者发送若干条消息
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic0

h.消费
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic topic0
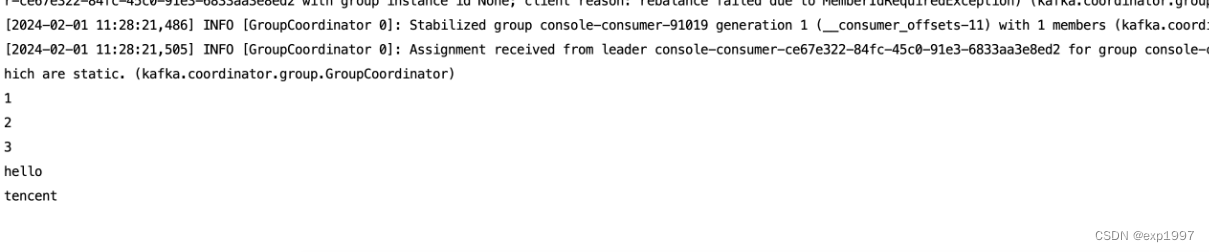
至此,kafka启动成功
三、使用splunk for kafka connector实现splunk与kafka数据通路
- github上下载splunk for kafka connector的latest jar,下载地址:https://github.com/splunk/kafka-connect-splunk,在执行以下操作前请仔细阅读github上的redame,因为随着版本更新,配置或许会改变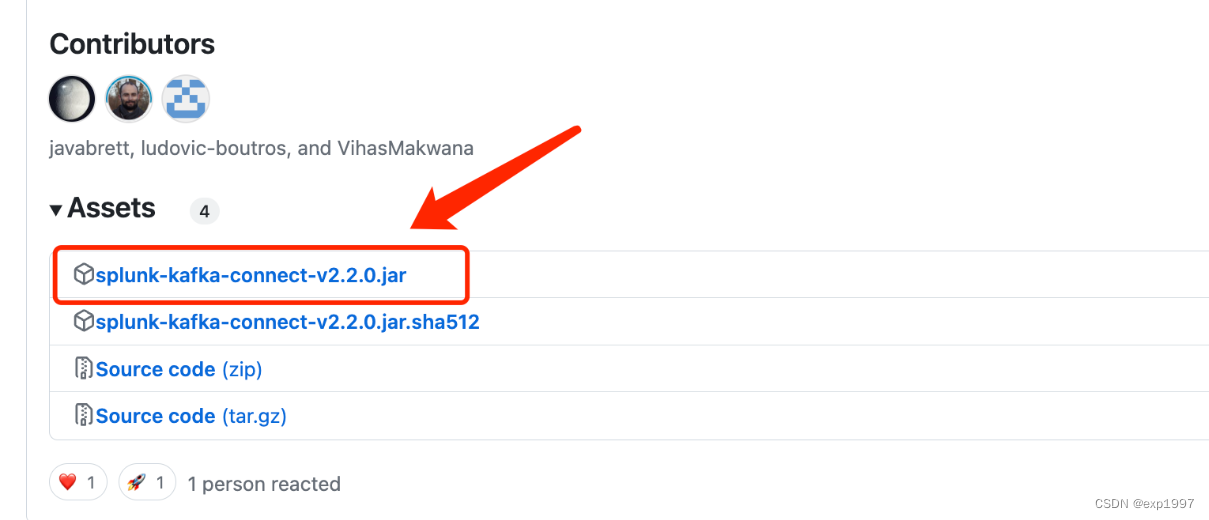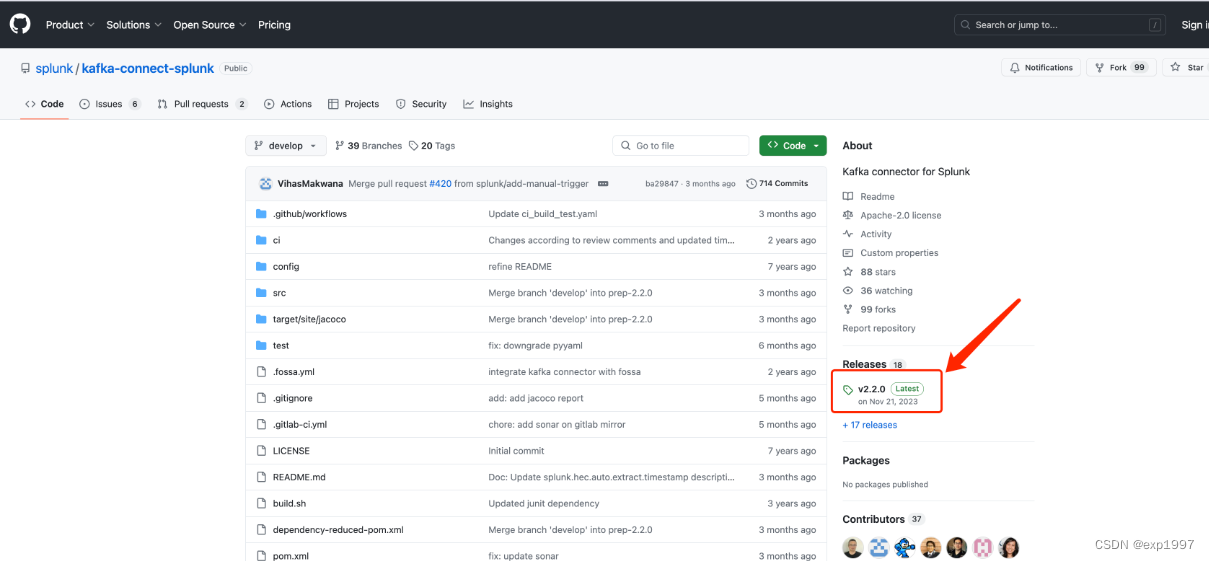
- 配置splunk for kafka connector a.此步骤将完成kafka connector服务。返回带有kafka sdk的主机(注意,这里我只有一台测试机,但是如果你是多台主机分别部署kafka、connector的背景下,这里返回的不是kafka集群主机,我们要创建connector服务,kafka sdk是带有connector的配置的),编辑kafka_2.12-3.6.1/config/connect-distributed.properties参数说明: 注意:rest.advertised.host.name和rest.advertised.port在不同的kafka版本中参数名不同,以connect-distributed.properties原文档参数为准;StringConverter表示日志格式为string,若日志为其他格式,请参考官方文档
# 将10.0.0.0:19000替换为你的kafka地址bootstrap.servers=10.0.0.0:19000
group.id=test-splunk-kafka-connector
# 假设消息是string类型,格式不对splunk就不能解析日志key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# 换为connector的地址rest.advertised.host.name=10.1.1.1
rest.advertised.port=8083#指定splunk-kafka-connector.jar所在目录plugin.path=/usr/local/bin/
- 启动conncetor:
cd kafka_2.12-3.6.1/
./bin/connect-distributed.sh config/connect-distributed.properties
- 验证splunk connector:
# curl http://「connector ip」:8083/connector-pluginscurl http://10.1.1.1:8083/connector-plugins
预期出现这个字段,表示splunk connector已经启动了:{“class”:“com.splunk.kafka.connect.SplunkSinkConnector”,“type”:“sink”,“version”:“v2.2.0”}
- 创建connector任务,替换10.1.1.1为您的kafka connector地址10.0.0.0为您的splunk地址,token为splunk事件收集器的token,topics替换为您的kafka topic
curl10.1.1.1:8083/connectors -X POST -H"Content-Type: application/json" -d'{
"name": "splunk-kafka-connect-task",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
"tasks.max": "3",
"topics": "topic0",
"splunk.indexes": "splunk_kafka_index",
"splunk.hec.uri":"https://10.0.0.0:8088",
"splunk.hec.token": "b4594xxxxxx",
"splunk.hec.ack.enabled" : "false",
"splunk.hec.raw" : "false",
"splunk.hec.json.event.enrichment" : "org=fin,bu=south-east-us",
"splunk.hec.ssl.validate.certs": "false",
"splunk.hec.track.data" : "true"
}
}'
预期返回:
- 进入splunk 主页-search&reporting 在搜索栏填写:index="splunk_kafka_index"验证index中的数据,预期能查看到我们生产的消息
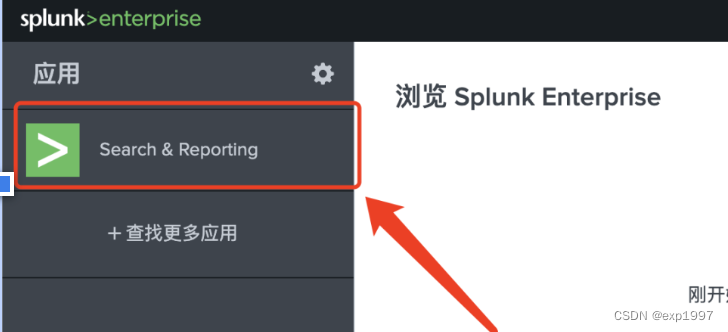
 至此,kafka-splunk已打通
至此,kafka-splunk已打通
本文转载自: https://blog.csdn.net/weixin_44988779/article/details/135991665
版权归原作者 exp1997 所有, 如有侵权,请联系我们删除。
版权归原作者 exp1997 所有, 如有侵权,请联系我们删除。