
一、Zookeeper简介
** 分布式协调框架,小型的树形结构数据共享储存系统。 **
zookeeper的应用场景
集群管理
注册中心
配置中心
发布者将数据发布到ZooKeeper一系列节点上面,订阅者进行数据订阅,当数据有变化时,可及时得到数据的变化通知。
数据的发布/订阅
分布式锁
分布式队列
负载均衡
负载均衡是通过负载均衡算法,客户端负载均衡。
1.1、组成
1.1.1、集群角色
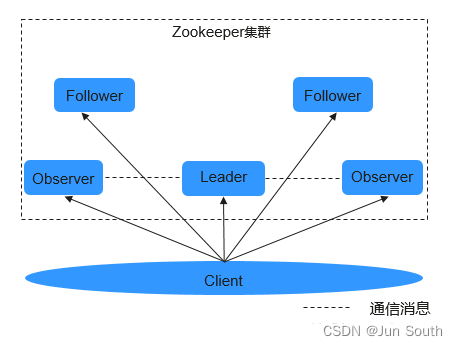
领导者(leader):
各Follower通过ZAB(ZooKeeper Atomic Broadcast)协议选举产生,主要负责接收和协调所有写请求,把写入的信息同步到Follower和Observer。
跟随者(follower):
1.每个Follower都作为Leader的储备,当Leader故障时重新选举Leader,避免单点故障。
2.处理读请求,并配合Leader一起进行写请求处理。
观察者(observer):
不参与选举和写请求的投票,只负责处理读请求、并向Leader转发写请求,避免系统处理能力浪费。
1.1.2、会话
Session指客户端会话,⼀个客户端连接是指客户端和服务端之间的⼀个TCP⻓连接,通过心跳机制来保持有效会话。
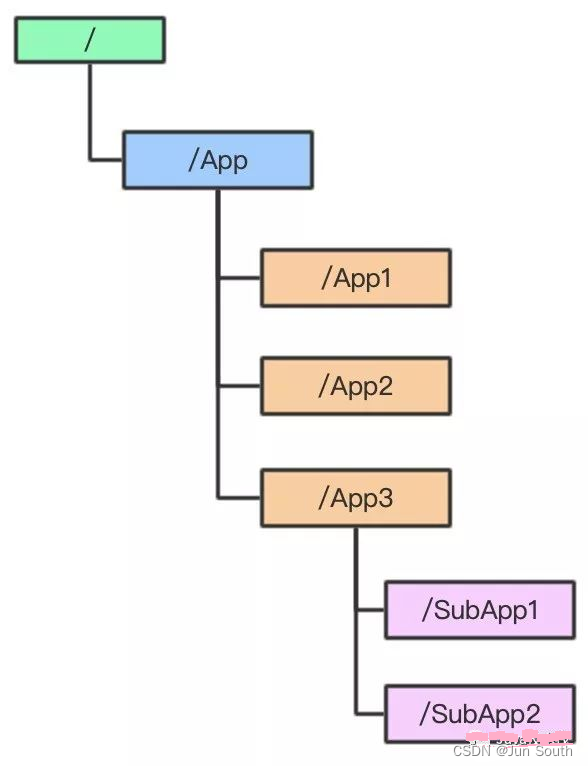
1.1.3、数据节点(Znode)
数据模型中的数据单元,ZNode Tree,它采用类似⽂件系统的层级树状结构进行管理。
1.1.4、Watcher
就是特定的事件监听机制,进行特殊化通知某个服务器协同处理某些逻辑。
2、Zookeeper节点类型
**1. 持久节点(PERSISTENT) : **
1.1 zk客户端连接zk服务器端会话(session)结束后数据不会丢失
1.2 持久节点在其下方可以创建子节点
**2. 临时节点(EPHEMERAL) : **
2.1 zk客户端连接zk服务器端会话(session)结束后数据会丢失
2.2 临时节点在其下方不可以创建子节点
**3. 持久顺序节点(PERSISTENT_SEQUENTIAL) : **
3.1 zk客户端连接zk服务器端会话(session)结束后数据不会丢失
3.2 持久节点在其下方可以创建子节点
3.3 持久节点在创建同名节点时不能创建成功,但是持久顺序节点可以
3.4 创建持久顺序节点时,zk会在名称后自动添加一个序号,序号是一个单调递增的计数器,由父节点维护
**4. 临时顺序节点(EPHEMERAL_SEQUENTIAL) : **
4.1 zk客户端连接zk服务器端会话(session)结束后数据会丢失
4.2 临时节点在其下方不可以创建子节点
4.3 临时节点在创建同名节点时不能创建成功,但是临时节点顺序节点可以
4.3 创建持久顺序节点时,zk会在名称后自动添加一个序号,序号是一个单调递增的计数器,由父节点维护
二、安装及使用
2.1、安装
下载zookeeper-3.4.9.tar.gz压缩包(在Windows/Linux/Mac下通用)
https://archive.apache.org/dist/zookeeper/zookeeper-3.4.9/
- 平台支持
1.1 Windows 服务端和客户端开发和生产环境都支持
1.2 Linux 服务端和客户端开发和生产环境都支持- 软件环境
2.1 客户端和服务器端都是用Java语言编写,需要本机安装JDK
2.2 zookeeper3.4.9版本需要JDK版本大于等于1.6- 单点安装步骤
3.1 下载zookeeper安装包
3.2 解压zookeeper
3.3 在conf文件夹下找到zoo_sample.cfg将其重命名为zoo.cfg
3.4 修改配置
# zookeeper服务器心跳检测
tickTime=2000
# zookeeper存放数据的目录,zookeepr服务器可以保存数据
dataDir=/tmp/zookeeper
# 服务器启动占用的端口号,用于客户端连接使用
clientPort=2181- 启动和停止
4.1 启动
- Windows: bin目录下直接双击 zkServer.cmd
- Linux : 使用命令行工具,在bin目录下 zkServer.sh start
4.2 停止
- Windows: ctrl+c 或者 使用命令杀进程
- Linux : 使用命令行工具,在bin目录下 zkServer.sh stop
2.2、集群配置
2.2.1、zk1实例
- 解压zk压缩包
- 在解压文件中创建data(在data文件中创建myid文件,并且存一个服务器编号)和log文件夹 和bin目录平级即可
- 修改conf中的zoo_sample.cfg配置文件,重命名为zoo.cfg
- 修改配置文件内容,内容如下:
心跳检测(zk服务器和zk客户端之间每隔一个tickTime检查一次是否还连着[毫秒])
tickTime=2000zk和zk之间(leader和follower)初始化连接时能忍受几个tickTime的个数,超过个数没有连接,剔除
initLimit=10zk和zk(leader和follower)之间发送消息请求和应答的时间长度多少个tickTime数量
syncLimit=5数据存储位置
dataDir=../data事务日志存储位置
dataLogDir=../log端口号
clientPort=2181集群配置 server.A=B.C.D 解释: server集群配置属性(固定值) 1:和myid中存的值相同用于表示当前zk的服务编号 B:服务器主机IP C: zk服务器之间通信端口 D:zk选举端口
server.1=127.0.0.1:2555:3555
server.2=127.0.0.1:2556:3556
server.3=127.0.0.1:2557:3557
2.2.2、zk2实例
1.解压zk压缩包
2.在解压文件中创建data(在data文件中创建myid文件,并且存一个服务器编号)和log文件夹 和bin目录平级即可
3.修改conf中的zoo_sample.cfg配置文件,重命名为zoo.cfg
4.修改配置文件内容,内容如下:心跳检测(zk服务器和zk客户端之间每隔一个tickTime检查一次是否还连着[毫秒])
tickTime=2000
zk和zk之间(leader和follower)初始化连接时能忍受几个tickTime的个数,超过个数没有连接,剔除
initLimit=10
zk和zk(leader和follower)之间发送消息请求和应答的时间长度多少个tickTime数量
syncLimit=5
数据存储位置
dataDir=../data
事务日志存储位置
dataLogDir=../log
端口号
clientPort=2182
集群配置 server.A=B.C.D 解释: server集群配置属性(固定值) 2:和myid中存的值相同用于表示当前zk的服务编号 B:服务器主机IP C: zk服务器之间通信端口 D:zk选举端口
server.1=127.0.0.1:2555:3555
server.2=127.0.0.1:2556:3556
server.3=127.0.0.1:2557:3557
2.2.3、zk3实例
- 解压zk压缩包
- 在解压文件中创建data(在data文件中创建myid文件,并且存一个服务器编号)和log文件夹 和bin目录平级即可
- 修改conf中的zoo_sample.cfg配置文件,重命名为zoo.cfg
- 修改配置文件内容,内容如下:
心跳检测(zk服务器和zk客户端之间每隔一个tickTime检查一次是否还连着[毫秒])
tickTime=2000zk和zk之间(leader和follower)初始化连接时能忍受几个tickTime的个数,超过个数没有连接,剔除
initLimit=10zk和zk(leader和follower)之间发送消息请求和应答的时间长度多少个tickTime数量
syncLimit=5数据存储位置
dataDir=../data事务日志存储位置
dataLogDir=../log端口号
clientPort=2183集群配置 server.A=B.C.D 解释: server集群配置属性(固定值) 3:和myid中存的值相同用于表示当前zk的服务编号 B:服务器主机IP C: zk服务器之间通信端口 D:zk选举端口
server.1=127.0.0.1:2555:3555
server.2=127.0.0.1:2556:3556
server.3=127.0.0.1:2557:3557
2.3、常见命令
注意: 所有命令设计到的路径操作必须是绝对路径,不可以是相对路径
0. help命令 -- 查看当前环境下都可以使用哪些命令
- ls命令 -- 查看某一个路径下的目录列表 例如: ls / 查看根目录下的目录列表
- ls2命令 -- 查看某个路径下目录列表(相比于ls命令信息更详细) 例如: ls2 / 查看根目录下的目录列表
- create命令 -- 创建节点并赋值 例如: create /ukoko val1 创建了一个ukoko节点,并在此节点存储了val1字符串
3.1 create的格式为 create [-s] [-e] path data acl
3.2 [-s] [-e] 中括号的参数可有可无 -s表示创建顺序节点 -e表示创建临时节点 不加默认创建持久节点
3.3 path 指定要创建节点的路径
3.4 data 要在此节点存储的数据
3.5 acl 访问权限相关,默认是 world,全世界都能访问- get命令 -- 获取节点数据和状态信息 例如: get /ukoko 查看当前节点下的数据以及节点固有属性信息
4.1 get格式 get path [watch]
4.2 path 要查询的节点路径
4.3 [watch] 中括号的参数可有可无, watch对节点进行事件监听 例如: get /ukoko watch 查看这个节点,并且监听这个节点数据变化,测试这个节点时需要开启至少两个客户端- set命令 -- 修改节点存储的数据 例如: set /ukoko 100 给ukoko节点设置数据
5.1 set格式 set path data [version]
5.2 [version] 中括号的参数可有可无 version版本号
5.3 path 要设置数据的节点路径
5.4 data 需要存储的数据- delete命令 -- 删除某节点 例如: delete /ukoko
6.1 delete格式 delete path [version]
6.2 path 要删除的节点路径
6.3 [version] 中括号的参数可有可无 version版本号(同set命令)- stat命令 -- 查看节点状态信息 例如: stat /ukoko
7.1 stat格式 stat path [watch]
7.2 [watch]中括号的参数可有可无- rmr 命令 -- 强制删除节点以及下子节点 例如 rmr /app
3、创建节点
- 创建持久化节点:
1.1 命令 create /ukoko val0 创建ukoko节点,并且存储数据val0
1.2 命令 create /ukoko val1 创建ukoko节点,并且存储数据val1,失败报 Node already exists: /ukoko- 创建顺序持久化节点:
2.1 命令 create -s /ukoko val1 创建ukoko节点,并且存储数据val1
2.2 命令 create -s /ukoko val2 创建ukoko节点,并且存储数据val2,成功,因为顺序节点会在节点名称后自动添加序号,使用 ls命令查看- 创建临时节点
3.1 命令 create -e /ukoko1 val0 创建ukoko1临时节点,并且存储数据val0
3.2 使用quit退出命令退出当前会话,会在控制台打印出当前会话id和ephemeralOwner属性对比
3.3 重新使用客户端命令连接zk服务器,使用ls命令查看,临时节点消失- 创建顺序临时节点
4.1 命令 create -s -e /ukoko2 val0 创建ukoko2顺序临时节点,并且存储数据val0
4.2 命令 create -s -e /ukoko2 val1 创建ukoko2顺序临时节点,并且存储数据val1,成功,因为顺序节点会在节点名称后自动添加序号,使用 ls命令查看
4.3 使用quit退出命令退出当前会话,会在控制台打印出当前会话id和ephemeralOwner属性对比
4.3 重新使用客户端命令连接zk服务器,使用ls命令查看,临时节点消失
4、节点其它操作
1.给节点设置数据
1. 设置普通数据(如果set设置值时不加版本,那么数据版本会随着每次set递增,可以在每次set成功之后查看dataVersion属性)
1.1 命令 set /ukoko 100
1.2 查看数据 get /ukoko
2. 设置带版本数据(如果带版本set,那么必须保证版本号与dataVersion版本相同,保证修改的是当前版本数据)
2.1 命令 set /ukoko 100 1 如果设置数据的版本,与dataVersion不相同会报version No is not valid(版本号无效)
2.2 查看数据 get /ukoko
2.获取节点
1. 获取普通数据: get /ukoko
2. 获取数据并且添加监听: get /ukoko watch
3.查看节点状态
1. 查看节点状态: stat /ukoko
2. 查看节点状态并对节点进行监听: stat /ukoko watch
4.删除节点
1. 删除节点
1.1 命令 delete /ukoko 删除节点
2. 删除带版本的节点
2.1 命令 delete /ukoko 1 如果后面带有版本那么要和dataVersion版本号相同
三、项目里的使用
Curator
Netflix公司开源的 zookeeper 客户端,在 zookeeper 原生API接口上进行包装,解决了很多zooKeeper客户端非常底层的细节开发。
提供 zooKeeper 分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等的抽象封装,实现了Fluent风格的APl接口。
解决session会话超时重连、watcher反复注册、简化开发api、遵循Fluent风格API。
3.1、引入依赖
<!-- zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.10</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.1</version>
</dependency>
3.2、配置参数
zookeeper:
curator:
ip: 192.168.213.138:2181
sessionTimeOut: 50000
sleepMsBetweenRetry: 1000
maxRetries: 3
namespace: demo
connectionTimeoutMs: 50000
3.3、创建客户端和监听
创建客户端——注入IOC容器
@Configuration
@ConfigurationProperties(prefix = "zookeeper.curator")
@Data
public class ZookeeperConfig {
/**
* 集群地址
*/
private String ip;
/**
* 连接超时时间
*/
private Integer connectionTimeoutMs;
/**
* 会话超时时间
*/
private Integer sessionTimeOut;
/**
* 重试机制时间参数
*/
private Integer sleepMsBetweenRetry;
/**
* 重试机制重试次数
*/
private Integer maxRetries;
/**
* 命名空间(父节点名称)
*/
private String namespace;
/**
`session`重连策略
`RetryPolicy retry Policy = new RetryOneTime(3000);`
说明:三秒后重连一次,只重连一次
`RetryPolicy retryPolicy = new RetryNTimes(3,3000);`
说明:每三秒重连一次,重连三次
`RetryPolicy retryPolicy = new RetryUntilElapsed(1000,3000);`
说明:每三秒重连一次,总等待时间超过个`10`秒后停止重连
`RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3)`
说明:这个策略的重试间隔会越来越长
公式:`baseSleepTImeMs * Math.max(1,random.nextInt(1 << (retryCount + 1)))`
`baseSleepTimeMs` = `1000` 例子中的值
`maxRetries` = `3` 例子中的值
*/
@Bean("curatorClient")
public CuratorFramework curatorClient() throws Exception {
CuratorFramework client = CuratorFrameworkFactory.builder()
//连接地址,集群用,隔开
.connectString(ip)
.connectionTimeoutMs(connectionTimeoutMs)
//会话超时时间
.sessionTimeoutMs(sessionTimeOut)
//设置重试机制
.retryPolicy(new ExponentialBackoffRetry(sleepMsBetweenRetry,maxRetries))
//设置命名空间 在操作节点的时候,会以这个为父节点
.namespace(namespace)
.build();
client.start();
//注册监听器
ZookeeperWatches watches = new ZookeeperWatches(client);
watches.znodeWatcher();
watches.znodeChildrenWatcher();
return client;
}
}
注册监听机制watches
public class ZookeeperWatches {
private CuratorFramework client;
public ZookeeperWatches(CuratorFramework client) {
this.client = client;
}
public void znodeWatcher() throws Exception {
NodeCache nodeCache = new NodeCache(client, "/node");
nodeCache.start();
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("=======节点改变===========");
String path = nodeCache.getPath();
String currentDataPath = nodeCache.getCurrentData().getPath();
String currentData = new String(nodeCache.getCurrentData().getData());
Stat stat = nodeCache.getCurrentData().getStat();
System.out.println("path:"+path);
System.out.println("currentDataPath:"+currentDataPath);
System.out.println("currentData:"+currentData);
}
});
System.out.println("节点监听注册完成");
}
public void znodeChildrenWatcher() throws Exception {
PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/node",true);
pathChildrenCache.start();
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("=======节点子节点改变===========");
Type type = event.getType();
String childrenData = new String(event.getData().getData());
String childrenPath = event.getData().getPath();
Stat childrenStat = event.getData().getStat();
System.out.println("子节点监听类型:"+type);
System.out.println("子节点路径:"+childrenPath);
System.out.println("子节点数据:"+childrenData);
System.out.println("子节点元数据:"+childrenStat);
}
});
System.out.println("子节点监听注册完成");
}
}
3.4、代码使用
@RestController
@RequestMapping(value = "/zookeeperController")
public class ZookeeperController {
@Resource(name = "curatorClient")
private CuratorFramework client;
@Value("${zookeeper.curator.namespace}")
String namespace;
递归创建节点
public String createZnode(String path,@RequestParam(defaultValue = "")String data)throws Exception{
path = "/"+path;
List<ACL> aclList = new ArrayList<>();
Id id = new Id("world", "anyone");
aclList.add(new ACL(ZooDefs.Perms.ALL, id));
client.create()
.creatingParentsIfNeeded() //没有父节点时 创建父节点
.withMode(CreateMode.PERSISTENT) //节点类型
.withACL(aclList) //配置权限
.forPath(path, data.getBytes());
return "节点创建成功";
}
异步递归创建节点
public String createAsyncZnode(String path,@RequestParam(defaultValue = "")String data) throws Exception{
String paths = "/"+path;
client.create()
.creatingParentsIfNeeded()
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
//异步回调 增删改都有异步方法
.inBackground(new BackgroundCallback() {
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("异步回调--获取权限:"+client.getACL().forPath(paths));
System.out.println("异步回调--获取数据:"+new String(client.getData().forPath(paths)));
System.out.println("异步回调--获取事件名称:"+event.getName());
System.out.println("异步回调--获取事件类型:"+event.getType());
}
}).forPath(paths, data.getBytes());
return "节点创建成功";
}
查看节点和元数据
public JSONObject selectZnode(String path) throws Exception{
JSONObject jsonObject = new JSONObject();
String namespace = "/"+this.namespace;
Stat stat;
stat = client.checkExists().forPath(path);
if (stat == null) {
jsonObject.put("error", "不存在该节点");
}
String dataString = new String(client.getData().forPath(path));
jsonObject.put(namespace+path, dataString);
jsonObject.put("stat", stat);
return jsonObject;
}
查看子节点和数据
public Map<String,String> selectChildrenZnode(String path){
Map<String, String> map = new HashMap<>();
String namespace = "/"+this.namespace;
List<String> list = client.getChildren().forPath(path);
for (String s : list) {
String dataString = new String(client.getData().forPath(path+"/"+s));
map.put(namespace+path+"/"+s, dataString);
}
return map;
}
设置数据
public JSONObject setData(String path,String data,Integer version) throws Exception{
JSONObject jsonObject = new JSONObject();
Stat stat = client.setData().withVersion(version).forPath(path, data.getBytes());
jsonObject.put("success", "修改成功");
jsonObject.put("version", stat.getVersion());
return jsonObject;
}
删除节点
public JSONObject delete(String path,Integer version,@RequestParam(defaultValue = "0")Integer isRecursive) throws Exception{
JSONObject jsonObject = new JSONObject();
if (isRecursive == 1) {
client.delete().deletingChildrenIfNeeded().withVersion(version).forPath(path);
}else {
client.delete().withVersion(version).forPath(path);
}
jsonObject.put("success", "删除成功");
return jsonObject;
}
测试事务(不开启事务)
public String transactionDisabled(String createPath,String createData,String setPath,String setData)throws Exception{
//创建一个新的路径
client.create().withMode(CreateMode.PERSISTENT).forPath(createPath,createData.getBytes());
//修改一个没有的数据让其报错
client.setData().forPath(setPath, setData.getBytes());
}
测试事务(开启事务)
public String transactionEnabled(String createPath,String createData,String setPath,String setData){
try {
/**
* 这里有个坑点 使用 CuratorFramework 进行事务处理时,如果使用org.apache.zookeeper 的依赖版本是 3.6.x时
* 会出现找不到 MultiTransactionRecord 类的异常
* 在 3.6.x 版本 没有 MultiTransactionRecord 但是在3.4.10版本有这个类 不知道什么删除了
* 而 curator-framework 的 事务处理用到 CuratorMultiTransactionRecord 这个 类
* 但是 CuratorMultiTransactionRecord 继承了 MultiTransactionRecord 这个类 就出现了类找不到的异常
*
* 解决办法 :要么降低zookeeper 的版本 为3.4.10 要么使用zookeeper原生事务代码
*我这里降低了zookeeper的版本
*/
//该方法后续版本建议删除
// client.inTransaction()
// .create().withMode(CreateMode.PERSISTENT).forPath(createPath,createData.getBytes())
// .and()
// .setData().forPath(setPath, setData.getBytes())
// .and().commit();
//上述代码 替换成 以下代码
CuratorOp create = client.transactionOp().create().withMode(CreateMode.PERSISTENT).forPath(createPath,createData.getBytes());
CuratorOp setOp = client.transactionOp().setData().forPath(setPath, setData.getBytes());
//该方法有返回值 可以打印结果查看 一般不需要
client.transaction().forOperations(Arrays.asList(create,setOp));
} catch (Exception e) {
e.printStackTrace();
}finally {
return "执行完成";
}
}
可重入排它锁
public String InterProcessMutexUse() throws Exception{
System.out.println("排它锁测试");
InterProcessMutex lock = new InterProcessMutex(client, "/lock");
System.out.println("占有锁中");
lock.acquire(20L, TimeUnit.SECONDS);
System.out.println("执行操作中");
for (int i = 0; i < 20; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.release();
return "锁已释放";
}
读写锁--写锁
public String interProcessReadWriteLockUseWrite() throws Exception {
System.out.println("写锁");
// 分布式读写锁
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client, "/lock");
// 开启两个进程测试,观察到写写互斥,特性同排它锁
System.out.println("获取锁中");
lock.writeLock().acquire();
System.out.println("操作中");
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.writeLock().release();
return "释放写锁";
}
读写锁--读锁
public String interProcessReadWriteLockUseRead() throws Exception {
System.out.println("读锁");
// 分布式读写锁
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client, "/lock");
// 开启两个进程测试,观察得到读读共享,两个进程并发进行,注意并发和并行是两个概念,(并发是线程启动时间段不一定一致,并行是时间轴一致的)
// 再测试两个进程,一个读,一个写,也会出现互斥现象
System.out.println("获取锁中");
lock.readLock().acquire();
System.out.println("操作中");
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
lock.readLock().release();
return "释放读锁";
}
分布式唯一id
public String getZookeeperId() throws Exception {
TreeSet<String> sortNode = new TreeSet<>();
//唯一id
String maxId = "";
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/seq/id-");
List<String> forPath = client.getChildren().forPath("/seq");
forPath.forEach(s->{
String id = s.split("-")[1];
sortNode.add(id);
});
String minId = sortNode.first();
client.delete().forPath("/seq/id-"+minId);
maxId= sortNode.last();
return maxId;
}
}
四、浅谈原理
4.1、zk集群的设计
**1. CAP定理之CP设计 **
1.1 CPA定理概念(Consistency[一致性]、Availability[可用性]、Partition tolerance[分区容错性])
1.2 在分布式系统中不可能保证CAP全部实现,一般提供CP或者AP服务
1.3 zk是一个典型的CP设计
2. 集群过半可存活(过半提供服务,低于一半主机不对外提供服务)
2.1 集群部署节点数一般为奇数个,因为过半可存活原理偶数可能浪费机器(3个节点和4个节点是一样的)
2.2 防止脑裂(一个zk集群[5个节点由于网络原因分成了3个和2个单独成为了各自的集群],这就是脑裂)
2.3 过半可存活策略可以很好的解决出现脑裂造成数据不一致的问题
4.2、Zookeeper的写、读
**写 **
1.Follower或Observer接收到写请求后,转发给Leader。
2.Leader协调各Follower,通过投票机制决定是否接受该写请求。
3.如果超过半数以上的Leader、Follower节点返回写入成功,那么Leader提交该请求并返回成功,否则返回失败。
4.Follower或Observer返回写请求处理结果。
**读 **
客户端直接向Leader、Follower或Observer读取数据。
4.3、Zookeeper中排他锁、共享锁
Zookeeper中排他锁实现:
1)定义锁:定义一个lock锁节点。
2)获取锁:所有客户端都尝试在这个lock节点下创建临时子节点,当谁成功创建临时子节点,就是谁持有了排他锁,其他机器在lock注册监听,监听临时子节点变化。
3)释放锁:当临时子节点被删除,当前获取锁客户端宕机或者已经完成操作,其他机器监听到了子节点状态变化,过来争抢创建临时子节点,进行锁的获取。
Zookeeper中共享锁实现:
1)定义锁:定义一个lock锁节点。
2)获取锁:所有客户端都往这个锁节点创建子节点,并往lock锁注册watcher事件监听,允许大家创建临时顺序节点,并且读、写请求的别名不一样,分别是R、W。当读节点前面都是读,那么就可以进行读,当读前面有写,那就等待,当写前面有读,等读完,直到自己是第一顺位写再执行。
3)释放锁:因为都是临时顺序节点,宕机和执行完都会被删除,然后被监听的其他节点获取,相当于就完成了锁的交替。
版权归原作者 Jun South 所有, 如有侵权,请联系我们删除。