
Flink 维表关联方案
1、Flink DataStream 关联维表
1)概述
1.分类
实时数据库查找关联(Per-Record Reference Data Lookup)
预加载维表关联(Pre-Loading of Reference Data)
维表变更日志关联(Reference Data Change Stream)
根据实现上的优化可以衍生出多种关联方式,且这些优化还可以灵活组合产生不同效果。
2.衡量指标
实现简单性: 设计是否足够简单,易于迭代和维护。
吞吐量: 性能是否足够好。
维表数据的实时性: 维度表的更新是否可以立刻对作业可见。
数据库的负载: 是否对外部数据库造成较大的负载(负载越低分越高)。
内存资源占用: 是否需要大量内存来缓存维表数据(内存占用越少分越高)。
可拓展性: 在更大规模的数据下会不会出现瓶颈。
结果确定性: 在数据延迟或者数据重放情况下,是否可以得到一致的结果。
2)实时数据库查找关联
1.概述
在 DataStream API 用户函数中直接访问数据库进行关联。
开发量最小,会给数据库带来很大压力,而且关联基于 Processing Time,如果数据有延迟或重放,会得到和原来不一致的结果。
2.同步数据库查找关联
a) 概述
在一个 Map 或者 FlatMap 函数中访问数据库,处理好关联逻辑后,将结果数据输出。
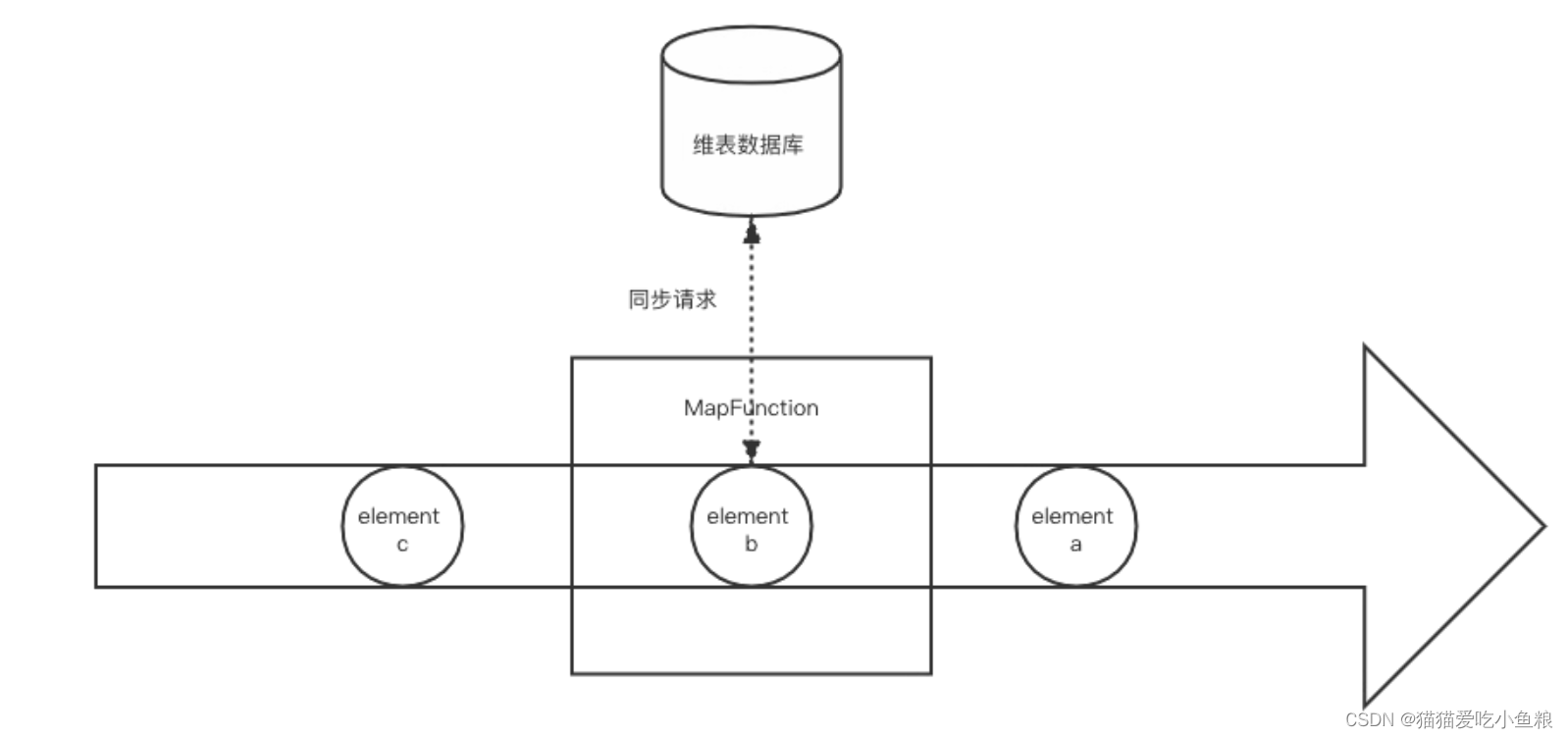
b) 优缺点
优点:
实现简单、不需要额外内存且维表的更新延迟很低。
缺点:
每条数据都需要请求一次数据库,给数据库造成的压力很大;
访问数据库是同步调用,导致 subtak 线程会被阻塞,影响吞吐量;
关联是基于 Processing Time 的,结果并不具有确定性;
瓶颈在数据库端,但实时计算的流量通常远大于普通数据库的设计流量,因此可拓展性比较低。
c) 应用场景
适合流量比较低的作业,但通常不是最好的选择。
3.异步数据库查找关联
a) 概述
通过 AsyncIO 利用数据库提供的异步客户端,AsyncIO 可以并发地处理多个请求,很大程度上减少对 subtask 线程的阻塞。
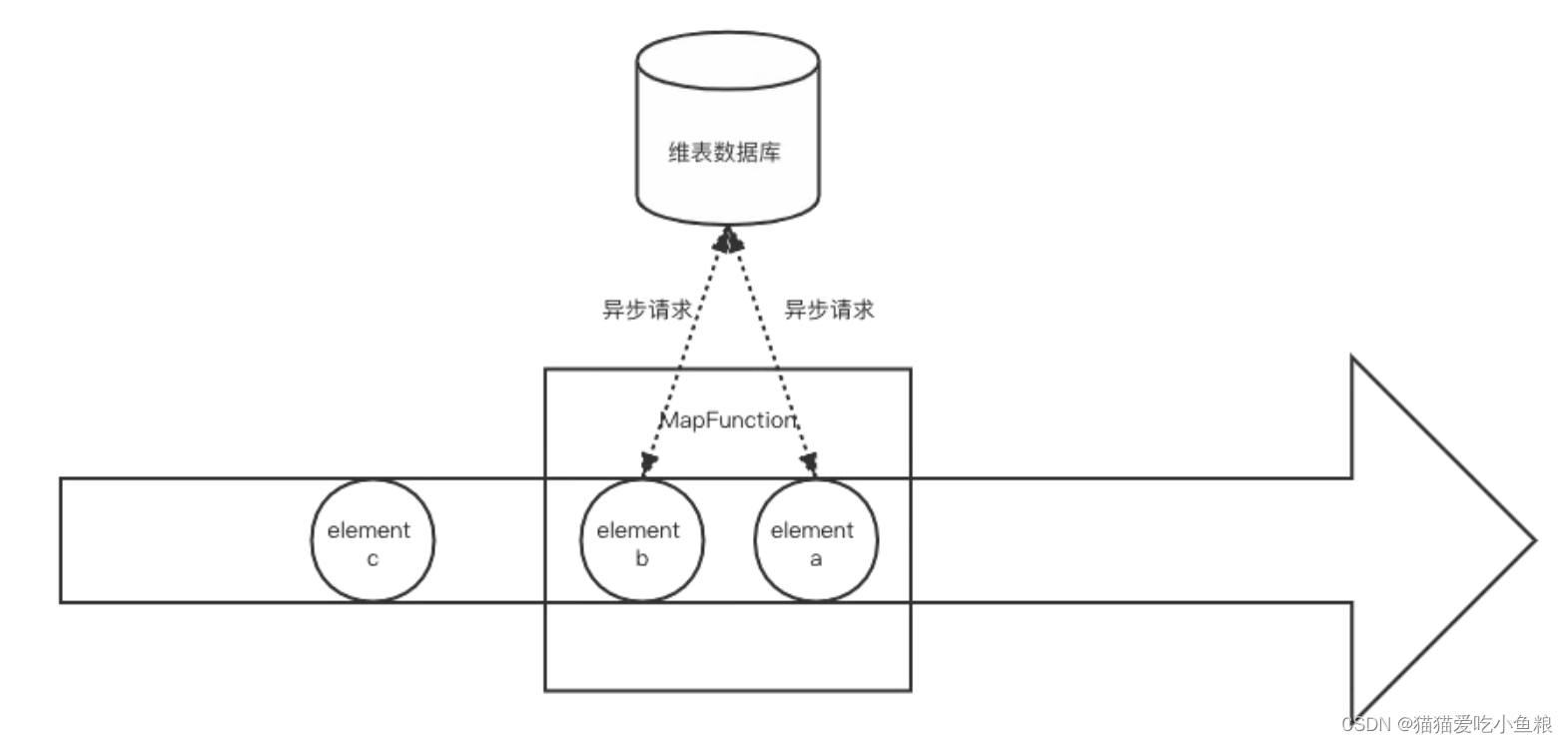
b) 优缺点
优点:
实现简单
缺点:
有序输出模式下的 AsyncIO 需要缓存数据,且这些数据会被写入 checkpoint,占用内容资源;
相比数据库查找关联的吞吐量更高,但仍存在数据库负载高和结果不确定的问题。
c) 应用场景
适合流量低的实时计算。
4.带缓存的数据库查找关联
a) 概述
引入一层缓存来减少直接对数据库的请求,缓存一般不需要通过 checkpoint 持久化,可用 WeakHashMap 或 Guava Cache 实现。
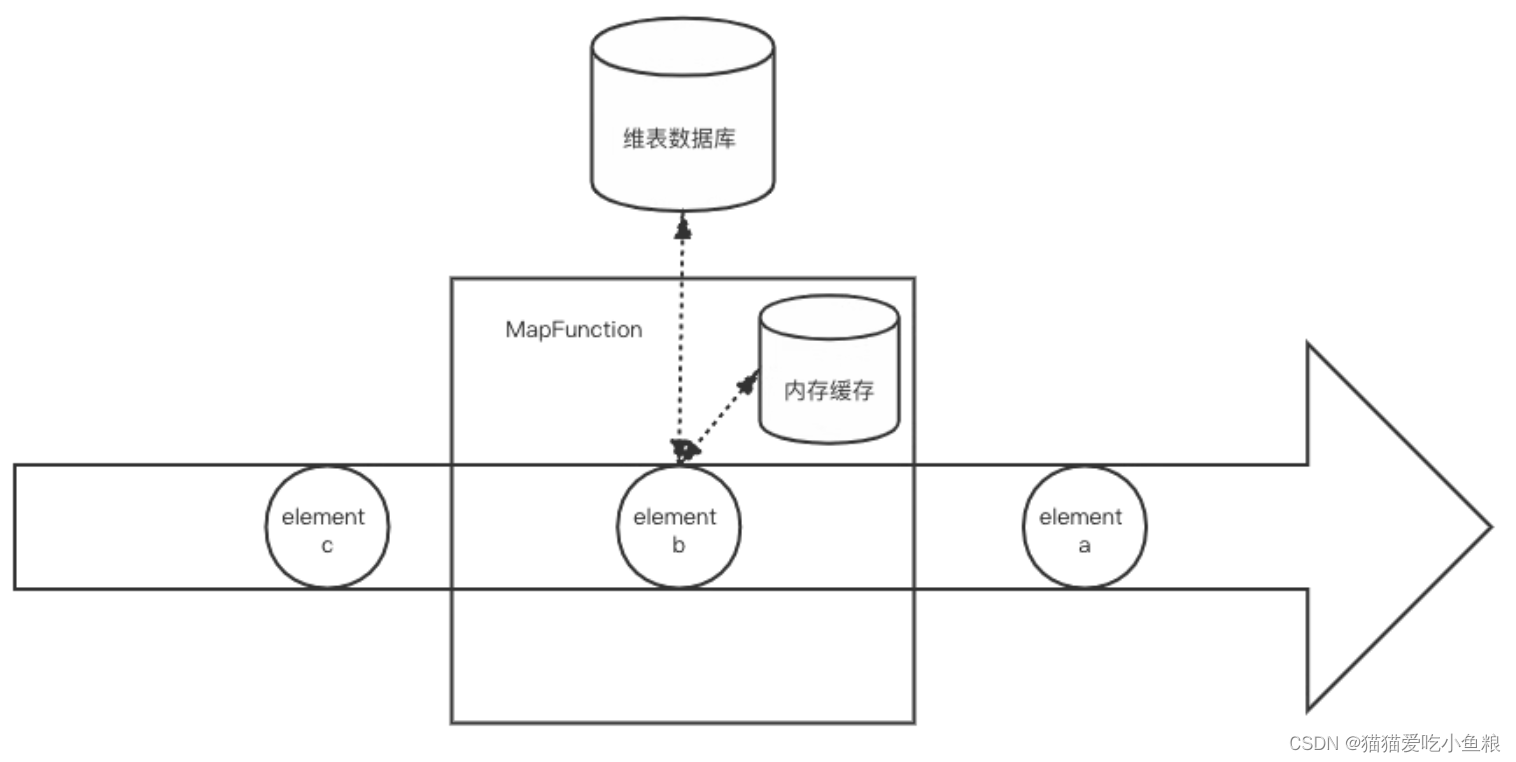
b) 优缺点
优点:
数据库压力小;
缺点:
冷启动时会给数据库造成压力,后续取决于缓存命中率,数据库的压力将得到缓解;
维表的更新不能及时反应到关联操作上,需要根据维度表更新频率和业务对过时维表数据的容忍程度来设计缓存剔除的策略;
c) 应用场景
适合流量比较低,且对维表数据实时性要求不太高或维表更新比较少的业务场景。
3)预加载维表关联
1.概述
相比实时数据库查找在运行期间为每条数据访问一次数据库,预加载维表关联是在作业启动时就将维表读到内存中,在后续运行期间,每条数据都会和内存中的维表进行关联,而不会直接触发对数据库的访问。
与带缓存的实时数据库查找关联相比,区别是后者如果不命中缓存还可以 fallback 到数据库访问,而前者如果不命中则会关联不到数据。
2.启动预加载维表
a) 概述
在作业初始化时,比如用户函数的 open() 方法,直接从数据库将维表拷贝到内存中,维表不需要用 State 保存。
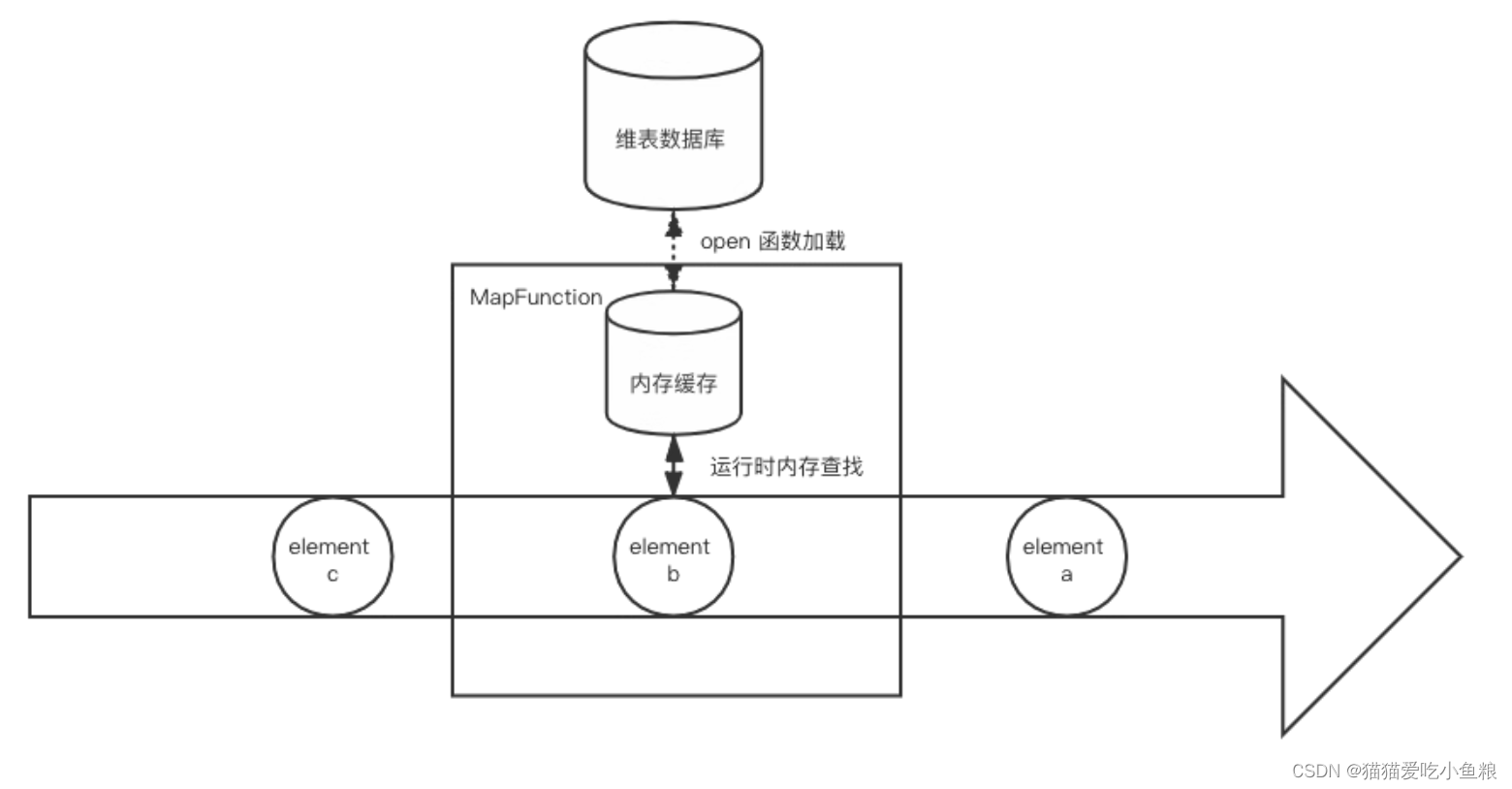
b) 优缺点
优点:
对数据库的压力只持续很短时间,在运行期间不需要再访问数据库。
缺点:
拷贝整个维表对 TaskManager 内存的要求较高;
运行期间维表数据不能更新。
c) 应用场景
适合于维表较小、变更实时性要求不高的场景,比如根据 ip 库解析国家地区,如果 ip 库有新版本,重启作业即可。
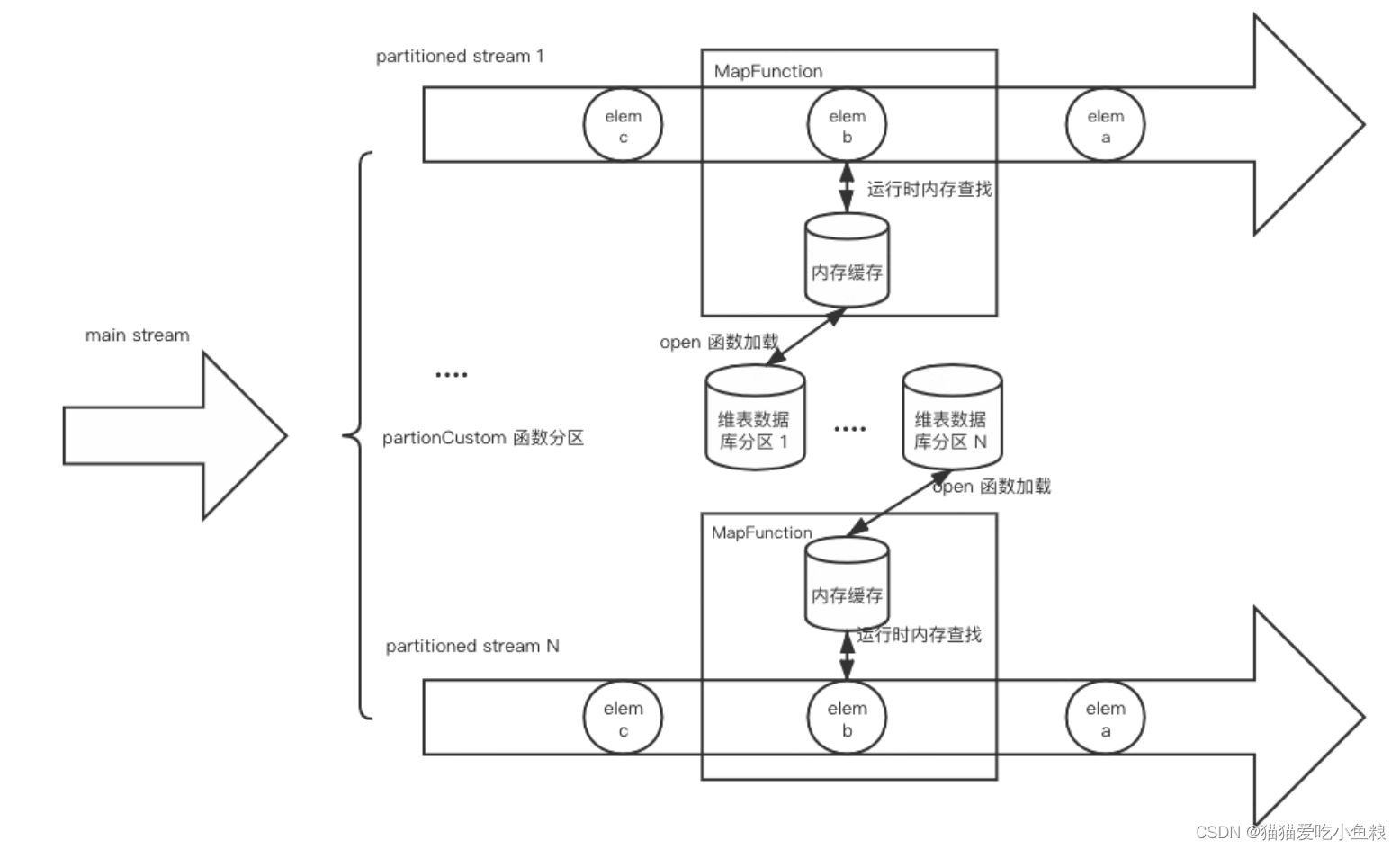
3.启动预加载分区维表
a) 概述
将数据流按字段分区,每个 Subtask 只需要加载对应分区范围的维表数据;
注意:
分区并不是用 keyby 这种通用的 hash 分区,而是需要根据业务数据定制化分区策略,调用 DataStream#partitionCustom;
比如按照 userId 的区间划分,0-999 划分到 subtask 1,1000-1999 划分到 subtask 2,在 open() 方法中,再根据 subtask 的 id 和总并行度来计算应该加载的维表数据范围。
b) 优缺点
优点:
维表的大小上限可以线性拓展,解决了维表大小受限于单个 TaskManager 内存的问题(取决于所有 TaskManager 的内存总量);
缺点:
设计和维护分区策略较复杂;
c) 应用场景
适合维表较大而变更实时性要求不高的场景,比如用户点击数据关联用户所在地。
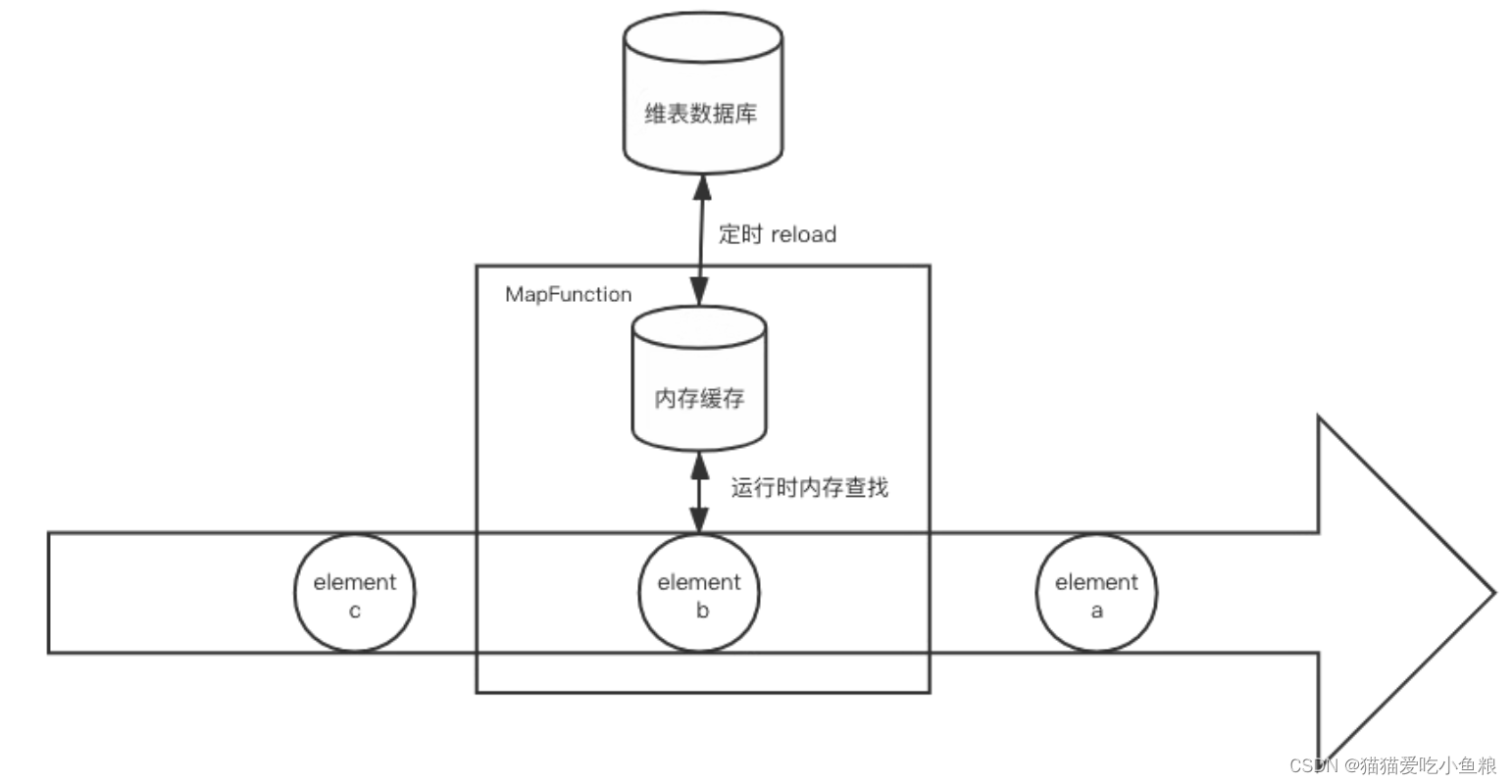
4.启动预加载维表并定时刷新
a) 概述
引入定时刷新机制解决维度数据的更新问题;
定时刷新可以通过 Flink ProcessFucntion 提供的 Timer 或者在 open() 初始化一个线程(池)来完成;
b) 优缺点
优点:
复杂性小,缓解了维度表更新问题;
缺点:
给维表数据库带来更多压力,每次 reload 都是一次请求高峰。
c) 应用场景
适合维表变更实时性要求不高的场景;
取决于定时刷新的频率和数据库的性能,可以满足大部分关联维表的业务。
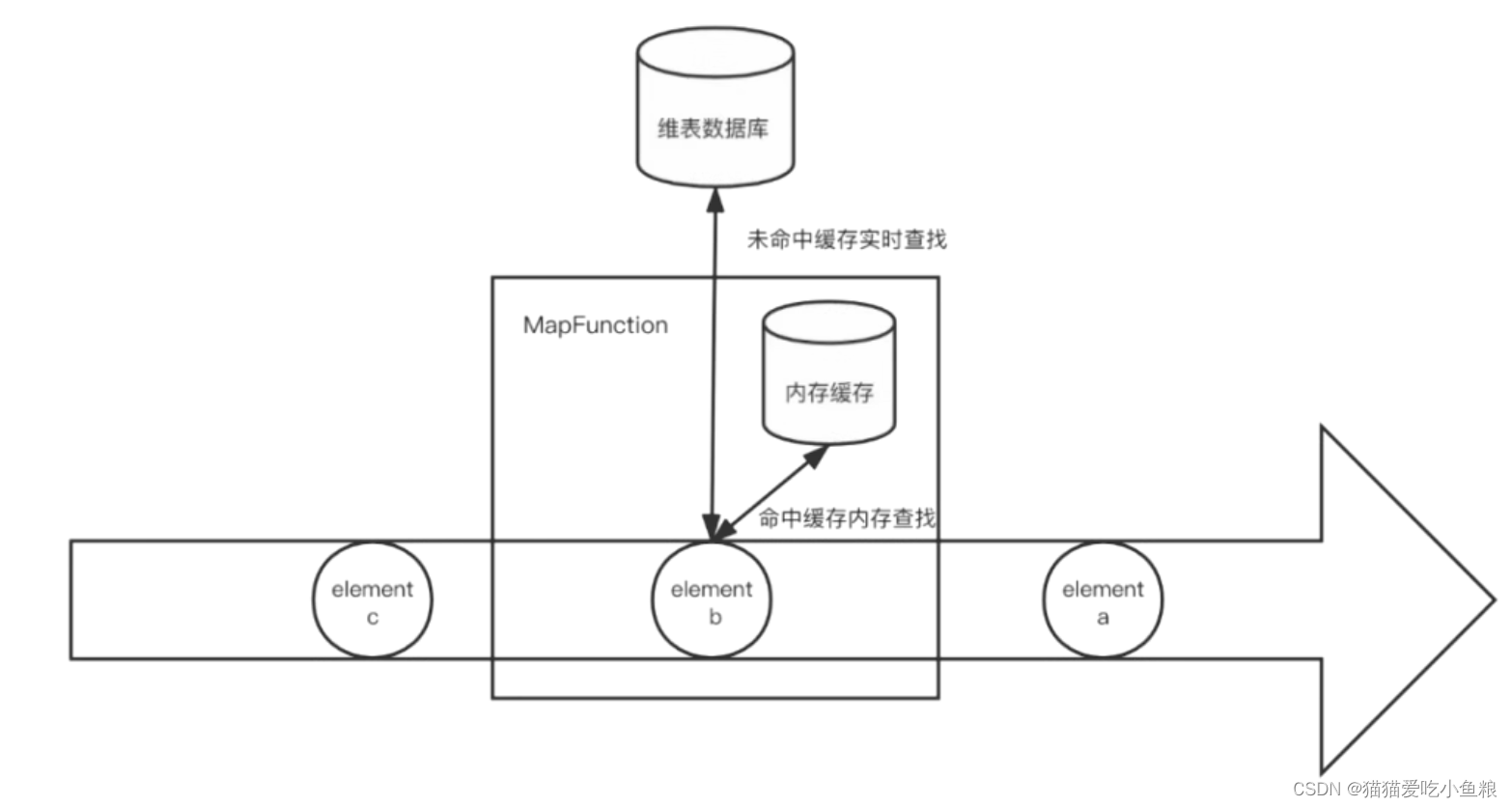
5.启动预加载维表 + 实时数据库查找
a) 概述
将预加载的维表作为缓存使用,若未命中则 fallback 到数据库查找。
b) 优缺点
优点:
相比冷启动时未命中缓存导致的多次实时数据库访问,直接拉取整个维表效率更高;
缺点:
可能拉取到不会访问的多余数据;
c) 应用场景
适合流量较低,且对维表数据实时性要求不高或维表更新较少的场景。
4)维表变更日志关联
1.概述
将维表以 changelog 数据流的方式表示,将维表关联转变为两个数据流的 join;
changelog 数据流类似于 MySQL 的 binlog,需要维表数据库端以 push 的方式将日志写到 Kafka 等消息队列中;
changelog 数据流称为 build 流,待关联的主要数据流成为 probe 流,可以获取某个 key 数据变化的时间,在关联中使用 Event Time 或 Processing Time。
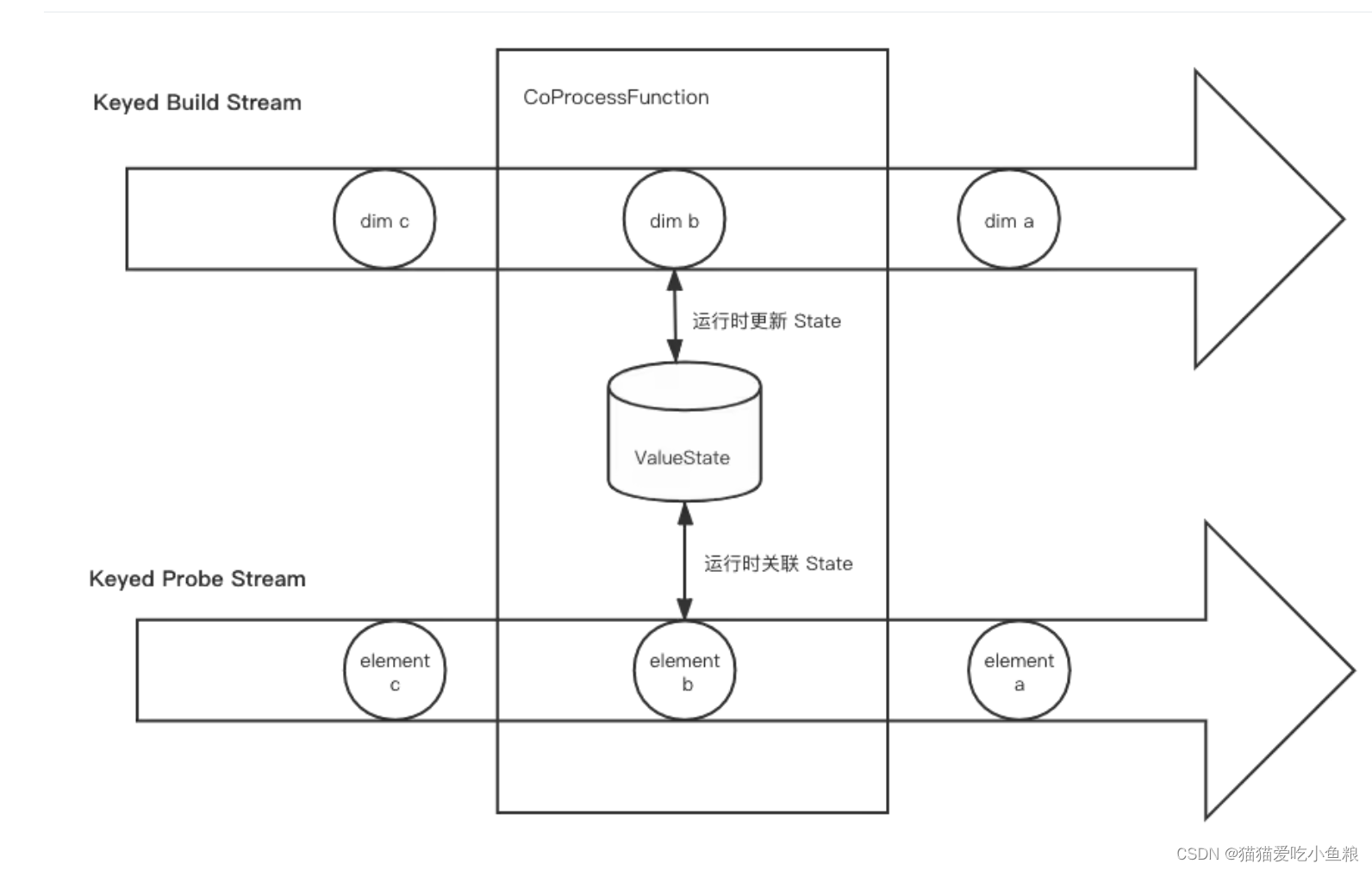
2.Processing Time 维表变更日志关联
a) 概述
基于 Processing Time 关联,利用 keyby 将两个数据流中关联字段值相同的数据划分到 KeyedCoProcessFunction 的同一个分区,用 ValueState 或者 MapState 将维表数据保存下来。
在普通数据流的一条记录进到函数时,到 State 中查找有无符合条件的 join 对象,若有则关联输出结果,若无则根据 join 的类型决定是直接丢弃还是与空值关联。
注意:State 的大小要控制,首先只保存每个 key 最新的维度数据值,其次要给 State 设置 TTL,让 Flink 可以自动清理。
b) 优缺点
优点:
不需要直接请求数据库,不会对数据库造成压力;
利用 Flink 的 RocksDB StateBackend,将大部分的维表数据存在磁盘而不是内存中,并不会占用很高的内存;
缺点:
需要使用 changelog 在 Flink 应用端重新构建一个维表,会占用一定的 CPU 和比较多的内存和磁盘资源;
基于 Processing Time 的关联对两个数据流的延迟要求较高,当其中一个数据流出现 lag 时,可能会关联到未来时间点的维表数据。
c) 应用场景
适用于不便直接访问数据的场景(比如维表数据库是业务线上数据库,出于安全和负载的原因不能直接访问)
对维表的变更实时性要求较高的场景(因为数据准确性的关系,一般用 Event Time 关联会更好)
3.Event Time 维表变更日志关联
a) 概述
将维表 changelog 的多个时间版本都记录下来,每当一条记录进来,会找到对应时间版本的维表数据来关联,而不是总用最新版本,因此延迟数据的关联准确性将提高;
目前 State 并没有提供 Event Time 的 TTL,需要设计和实现 State 的清理策略,比如设置一个 Event Time Timer(注意 Timer 太多会导致性能问题),对于单个 key 只保存最近的 10 个版本,当有更新版本的维表数据到达时,要清理掉最老版本的数据。
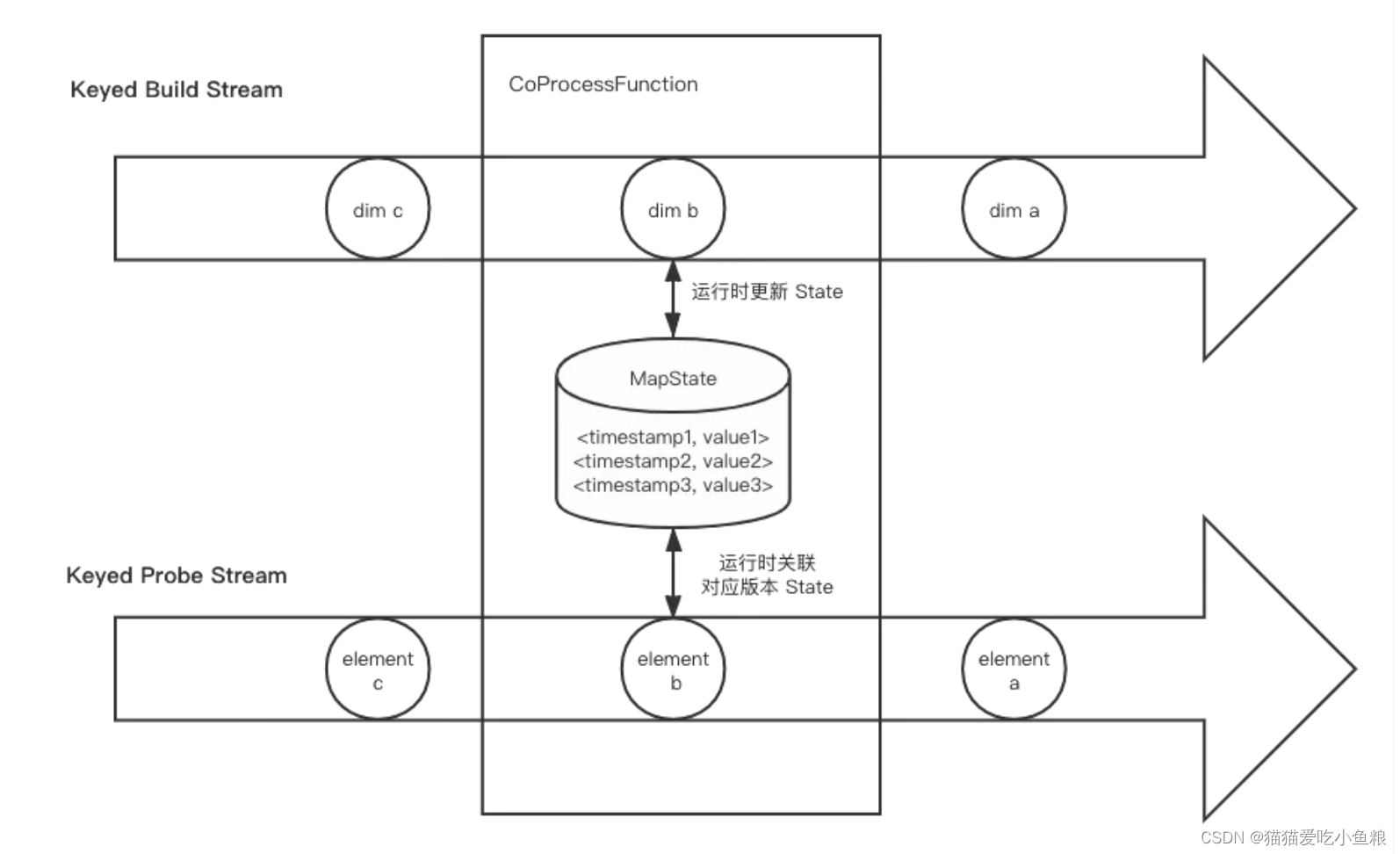
注意:Event Time 要求 build 数据流的延迟低,否则可能一条数据到达时关联不到对应维表数据或者关联了过时版本的维表数据;
b) 优缺点
优点:
可以确保准确性;
缺点:
多个维表版本导致空间资源要求更大;
c) 应用场景
适合维表变更较多且对变更实时性要求较高的场景;
适合不便直接访问数据库的场景;
4.DataStream 的 Temporal Table Join
a) 概述
对两个数据流的输入都进行缓存,比起基于 Event Time 的维表变更日志关联,可以容忍任意数据流的延迟,数据准确性更好。
实现:
使用 CoProcessFunction,将 build 数据流以时间版本为 key 保存在 MapState 中,再将 probe 数据流和输出结果也用 State 缓存起来(同样以 Event Time 为 key),直到 Watermark 提升到它们对应的 Event Time,才把结果输出和将两个数据流的输入清理掉。
Watermark 触发是用 Event Time Timer 实现,但要注意不要为每条数据都设置一个 Timer,否则 Watermark 提升会触发多个 Timer 导致性能急剧下降。
建议为每个 key 只注册一个 Timer,记录当前未处理的最早的一个 Event Time,并用来注册 Timer,每当 Watermark 触发 Timer 时,检查未处理的最早 Event Time 到当前 Event Time 的所有数据,并将未处理的最早 Event Time 更新为当前时间。
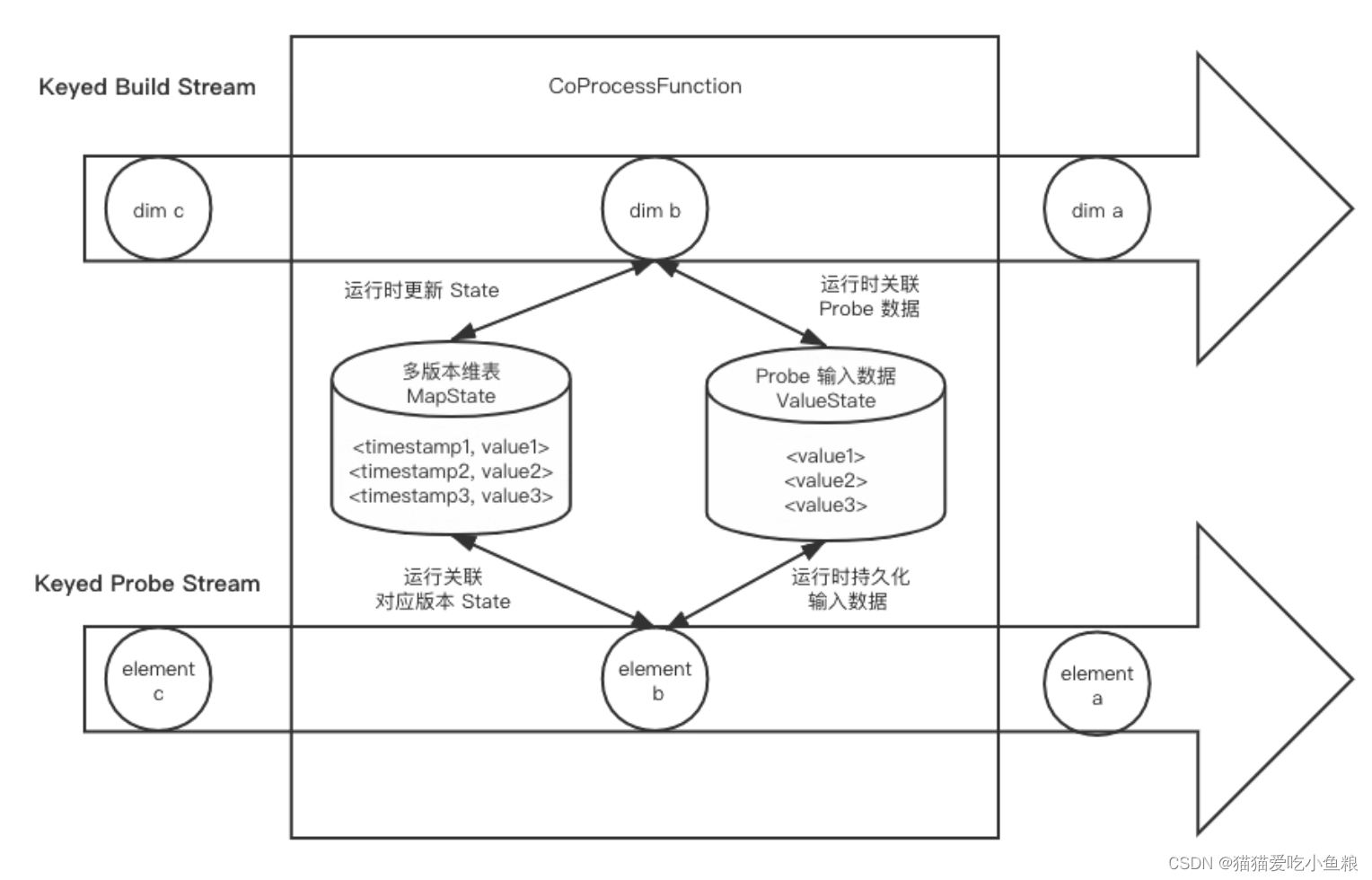
注意:
如果维表变更太慢,导致 Watermark 提升太慢,会导致 probe 数据流被大量缓存,要确保 build 数据流尽量实时,同时给 Source 设置一个比较短的 idle timeout。
b) 优缺点
优点:
对两边数据流延迟的容忍度较大;
缺点:
会引入一定的输出结果的延迟;
因为吞吐量较大的 probe 数据流也需要缓存,对空间资源的需求较大;
c) 适用场景
适合对数据准确性要求高且可以容忍一定延迟(一般分钟级别)的业务。
2、Flink SQL 实现数据流的 Join
1.Regular Join
a) 概述
Regular Join 和离线 Hive SQL ⼀样,通过条件关联两条流数据输出。
b) 分类
- Inner Join(Inner Equal Join):流任务中,只有两条流 Join 到才输出,输出 +[L, R]
- Left Join(Outer Equal Join):流任务中,左流数据到达之后,⽆论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R]
- Right Join(Outer Equal Join):与 Left Join ⼀样,左表和右表的执⾏逻辑完全相反
- Full Join(Outer Equal Join):流任务中,左流或者右流的数据到达之后,⽆论有没有 Join 到另外⼀条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果⼀条流的数据到达之后,发现另⼀条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R] )
c) 注意
实时 Regular Join 可以不是 等值 join,等值 join 和 ⾮等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;⾮等值 join 数据 shuffle 策略是 Global,所有数据发往⼀个并发,按照⾮等值条件进⾏关联。
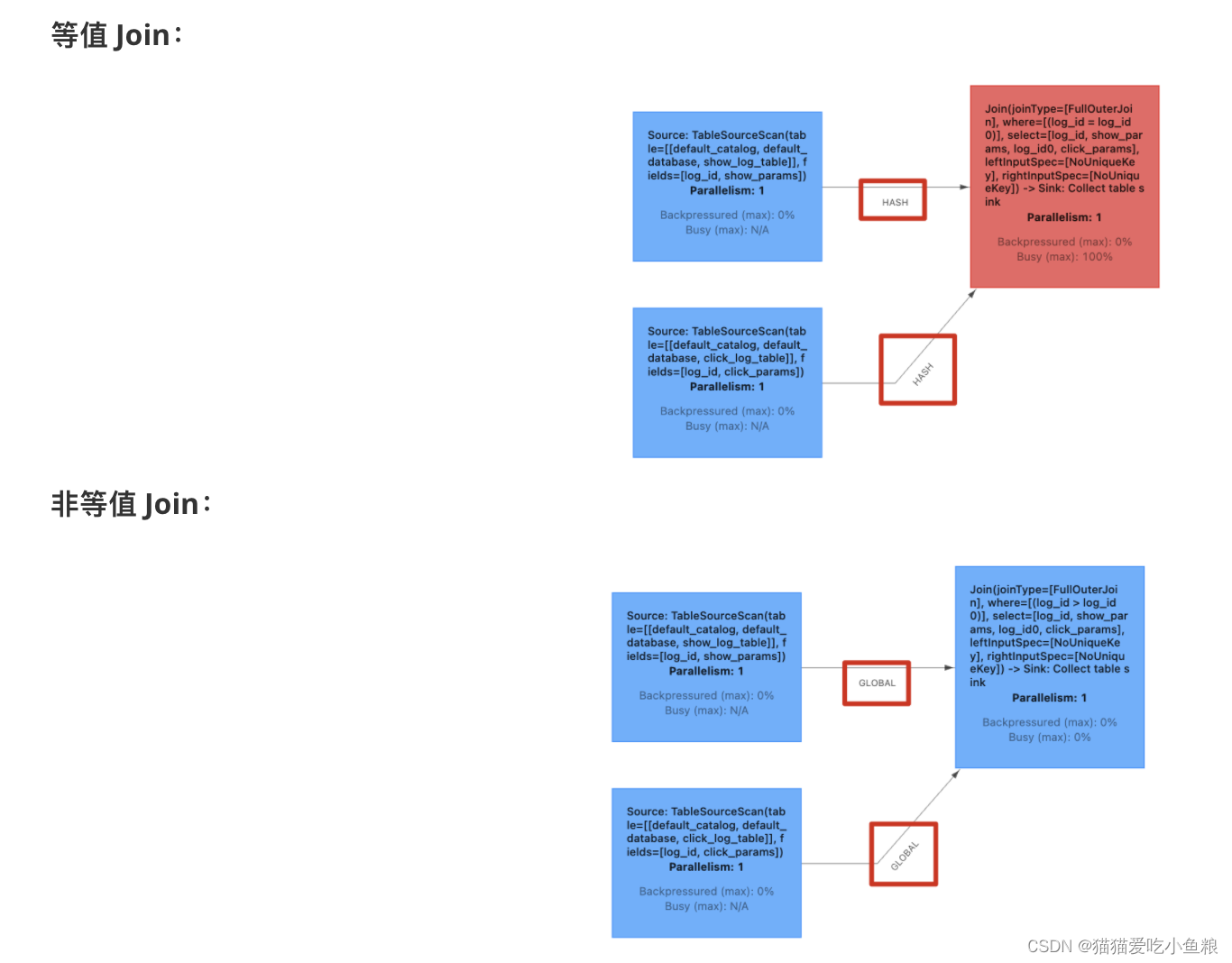
Join 的流程是左流新来⼀条数据后,会和右流中符合条件的所有数据做 Join,然后输出。
流的上游是⽆限的数据,关联需要 Flink 将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会⽆限增⼤,需要为 State 配置合适的 TTL,以防⽌ State 过⼤。
2.Interval Join
a) 概述
Interval Join 可以让⼀条流去 Join 另⼀条流中前后⼀段时间内的数据。
b) 分类
- Inner Interval Join:流任务中,只有两条流 Join 到(满⾜ Join on 中的条件:两条流的数据在时间区间 + 满⾜其他等值条件)才输出,输出 +[L, R]
- Left Interval Join:流任务中,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果右流之后数据到达,发现能和刚刚那条左流数据 Join 到,则会输出 +[L,R] 。事件时间中随着 Watermark 的推进(也⽀持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出 +[L, null] ,如果右流 State 中的数据过期了,就直接从 State 中删除。
- Right Interval Join:和 Left Interval Join 执⾏逻辑⼀样,只不过左表和右表的执⾏逻辑完全相反。
- Full Interval Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外⼀条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另⼀条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出 +[L, R] 。事件时间中随着 Watermark 的推进(也⽀持处理时间),发现 State 中的数据过期了,就将这些数据从 State 中删除并且输出(左流过期输出+[L, null] ,右流过期输出 -[null, R] )
Inner Interval Join 和 Outer Interval Join 的区别在于:随着时间推移的过程中,如果有数据过期了之后,会根据是否是 Outer 将没有 Join 到的数据也给输出。
c) 注意
实时 Interval Join 可以不是 等值 join ,等值 join 和 ⾮等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;⾮等值 join 数据 shuffle 策略是 Global,所有数据发往⼀个并发,将满⾜条件的数据关联输出。
3.Temporal Join
a) 概述
同离线中的 拉链快照表 ,Flink SQL 中对应的表叫做 Versioned Table ,使⽤⼀个明细表去 join 这个 Versioned Table 的 join 操作叫做 Temporal Join。
Temporal Join 中,Versioned Table 是对同⼀条 key(在 DDL 中以 primary key 标记同⼀个 key)的历史版本(根据时间划分版本)做维护,当有明细表 Join 这个表时,可以根据明细表中的时间版本选择 Versioned Table 对应时间区间内的快照数据进⾏ join。
b) Verisoned Table
Verisoned Table 中存储的数据通常来源于 CDC 或者会发⽣更新的数据,Flink SQL 会为 Versioned Table 维护 Primary Key 下的所有历史时间版本的数据。
c) 注意
事件时间的 Temporal Join ⼀定要给左右两张表都设置 Watermark。
事件时间的 Temporal Join ⼀定要把 Versioned Table 的主键包含在 Join on 的条件中。
4.Lookup Join(维表 Join)
a) 概述
Lookup Join 是维表 Join,实时数仓场景中,实时获取外部缓存。
b) 注意
同⼀条数据关联到的维度数据可能不同;
会发⽣实时的新建及更新的维表应该建⽴起数据延迟的监控,防⽌流表数据先于维表数据到达,关联不到维表数据;
5.Time-Windowed Join
利用窗口给两个输入表设定一个 Join 的时间界限,超出时间范围的数据则对 JOIN 不可见并可以被清理掉;
时间可以是指计算发生的系统时间(即 Processing Time),也可以是指从数据本身的时间字段提取的 Event Time;
如果是 Processing Time,Flink 根据系统时间自动划分 Join 的时间窗口并定时清理数据;如果是 Event Time,Flink 分配 Event Time 窗口并依据 Watermark 来清理数据。
版权归原作者 猫猫爱吃小鱼粮 所有, 如有侵权,请联系我们删除。