

1. 一段线程不安全的代码
我们先来看一段代码:
public class ThreadDemo {
public static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 10_0000; i++) {
count++;
}
System.out.println("count = " + count);
}
}
// 打印结果:count = 10000
这段代码是对 count 自增 10w 次,随之的打印结果 count = 100000,相信也没有任何的歧义,那么上述代码是否能优化呢?能否让速度更快呢?
相信学习到这里大家都会想到用多线程,可以搞两个线程,每个线程执行 5w 次自增就行了,甚至还可以搞五个线程,每个线程执行 2w 次就行了。
此处为了代码简洁,我们弄两个线程,每个线程对 count 自增 5w 次,最终也相当于对 count 自增了 10w 次了:
public class ThreadDemo {
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
count++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
count++;
}
});
t1.start();
t2.start();
// 下面的等待是为了让两个线程都自增完成
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
// 第一次执行打印结果:count = 64121
// 第二次执行打印结果:count = 54275
// 第三次执行打印结果:count = 63608
小伙伴们下去执行这个代码,可能跟我的打印结果不同,但是会发现,好像怎么样都到不了 10w,明明我们预期结果是 10w,但是达不到预期,此时就可以认为程序出现了 BUG!
凡是实际结果与预期结果不同,都认为是出现了 BUG!
上述代码就是典型的线程安全问题,也可以称为线程不安全!
由以上两段代码可知:
如果没有多线程,那么代码的执行顺序是固定的,代码执行顺序固定,那么程序的结果也就是固定的!
如果使用多线程,那么代码的执行顺序会出现更多的变数,执行顺序的可能性由于 CPU 的随机调度,可能出现了无数情况!
所以我们就要解决这类问题,保证在无数种执行顺序下,代码执行结果仍然正确!
要解决上述的问题,首先要理解 count++ 这个操作到底做了一件什么事。
这个 ++ 操作本质上要分成三步执行!
先把内存中的值,读取到 CPU 寄存器中 (load)
把 CPU 寄存器的数值进行 +1 运算 (add)
把得到的结果写回到内存中 (save)
由于 CPU 是随机调度的,所以就可能出现以下的情况:

情况1 相当于就是执行了 t1 线程的 ++ 操作后,再去执行 t2 线程的 ++ 操作。
情况2 相当于 t1 在执行 ++ 操作第一步 load 的时候,t1 线程被切走了,CPU 去调用了 t2 线程执行 ++ 操作的第一步 load 操作,执行完 t2 的load 操作后,又被切走了,CPU 去执行 t1 线程的 add 和 save 操作了。
像上述 情况1 和 情况2 所得到的结果可能就是截然不同的!

上图可以发现,由于是两个线程同时针对 count 变量进行修改,因为 ++ 操作是分三次执行的,此时不同的线程调度顺序,就可能产生不同的结果。
情况1,线程1和2 同时对 count++,结果自增了两次,没有任何问题!
情况2,线程1 和 2 同时对 count++,但由于执行顺序不同,导致 count 只自增了一次!
所以这就是为什么上述代码每次打印的结果都不同了,那有没有可能刚好打印 10w 呢?也是有可能的!
为什么会出现上述情况呢?请往下看:
2. 线程不安全的原因
2.1 随机调度
罪魁祸首,就是 CPU 随机调度,线程抢占式执行带来的风险,就是由于随机调度和抢占式执行,让代码的顺序不可预估,不同的顺序带来的结果也可能截然不同。
就好比结婚:
需要先认识妹子,建立感情,谈恋爱,见家长,给彩礼,领结婚证,结婚
那如果顺序乱了,那麻烦可就大了!
2.2 修改共享数据
上面线程不安全的代码中,涉及到多个线程同时对 count 变量进行修改,此时这个 count 变量就是一个多个线程都能访问到的 "共享数据"。
多个线程读同一个变量,没问题
多个线程修改不同的变量,没问题
多个线程修改相同的变量,有问题
一个线程读,一个线程改,有问题
......
2.3 原子性
上述的 count++ 这个操作就不是原子性的,也就是可以分成 load,add,save 三个指令操作,如果我们能将 count++ 这个操作改成原子性的,也就是三个指令操作必须一次完成(合并成一个指令),此时也就解决了线程安全问题。
一条 Java 语句不一定是原子的,也不一定只是一条指令!
如何保证原子性呢?可以使用 synchronized 关键字,后续就会讲解到。
2.4 内存可见性
一个线程对共享变量值的修改,能够及时地被其他线程看到,如果没有被及时发现,那么可能读的线程,读到了一个修改之前的值,也会造成线程不安全!有点类似于数据库事务那块的脏读概念!
这个具体后续讲解 volatile 关键字会详细介绍。
2.5 指令重排序
这个可以理解为是编译器想给我们代码做优化,但是好心办坏事了。
就比如说张三女朋友让张三去买菜,给张三列个清单:需要买土豆,黄瓜,青椒,茄子,白菜,豆芽。
张三来到菜市场,如果按照清单的顺序买菜是这种情况:
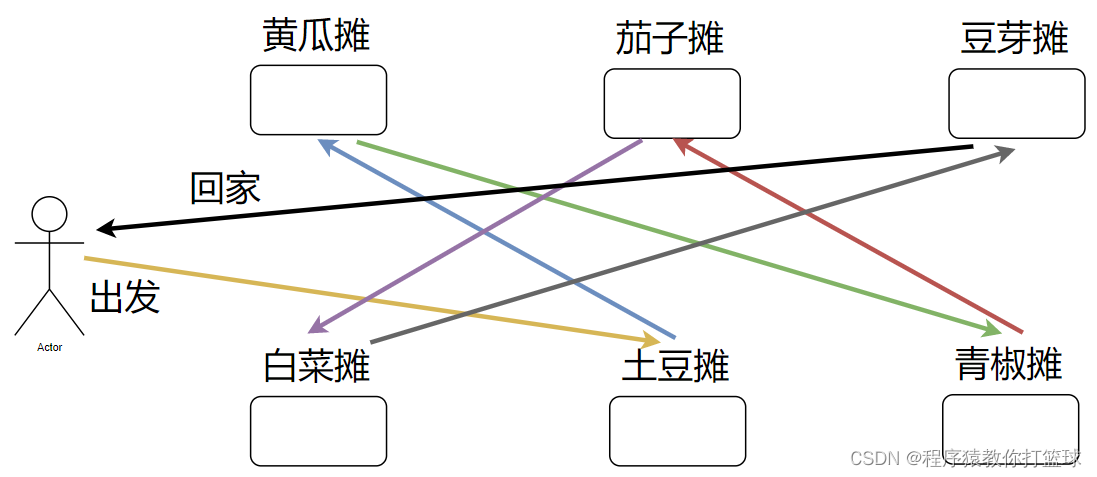
这样显然很麻烦啊,能不能优化买菜的顺序呢?反正只需要把清单上的菜都买到就行了嘛!
于是张三调整顺序后是这样买菜的:
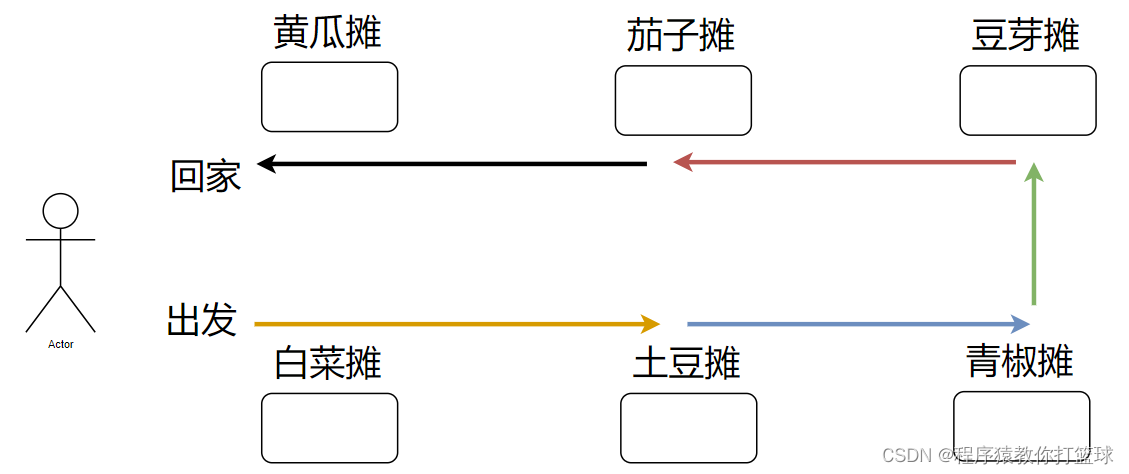
按照上述顺序买菜的话,仍然能买到清单上的菜,但是张三可谓轻松了很多,整体买完菜的速度也提升了不少
指令重排序,就像上述一样,可以少跑很多趟,优化了效率。
编译器对于指令重排序的前提是 "保持逻辑不发生变化",对于单线程环境来讲,比较容易判断,但是在多线程的环境下就没那么容易了,多线程代码执行复杂程序更高,编译器很难在编译阶段对代码的执行结果进行预判,因此编译器激进的指令重排序很容易导致重排后的逻辑和之前不等价,好比现在两个人去买菜,很容易买重,或者少买了。
3. synchronized 加锁操作
3.1 针对指定对象加锁
上述将的五个造成线程不安全的原因,首先要明确CPU 的随机调度,线程抢占式执行,这个是内核规定的,我们无法做出修改,那我们能限制线程不允许访问同一个变量吗?是可以的!但是这样做就进一步削弱了多线程的优势了!
所以我们可以从原子性入手,来解决因为指令不是原子性造成的线程安全问题!
那么针对上述线程不安全的代码,就可以利用 synchronized 关键字进行加锁,来保证加锁的代码块是原子性的:
public class ThreadDemo {
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
Object object = new Object();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
synchronized (object) {
count++;
}
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
synchronized (object) {
count++;
}
}
});
t1.start();
t2.start();
// 下面的等待是为了让两个线程都自增完成
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
// 第一次执行打印结果:count = 100000
// 第二次执行打印结果:count = 100000
// 第三次执行打印结果:count = 100000
上述代码就是针对 object 这个对象加锁了,一个对象只有一把锁,所以当 t1 线程执行到 count++ 时就会尝试获取 object 的锁,如果获取到了,就进行加锁操作,并执行 count++,只有执行完 synchronized 代码块的内容后,才会自动释放锁,如果 t1 在执行 count++ 的过程中,t2也执行到 count++ 了,此时 t2 就会尝试获取 object 对象锁,但是 object 已经被 t1 加锁了,那么 t2 就只能阻塞等待了,等 t1 释放锁,t2 才能获取锁,并加锁!那么 t1 只有执行完 synchronized 代码块后,自动释放锁!
这就好比上公厕,一个公厕只能供一个人使用,如果张三进入了公厕,就会把门锁上,此时外面的人想上厕所,就只能等张三上完厕所出来,其他人才能进去上厕所!
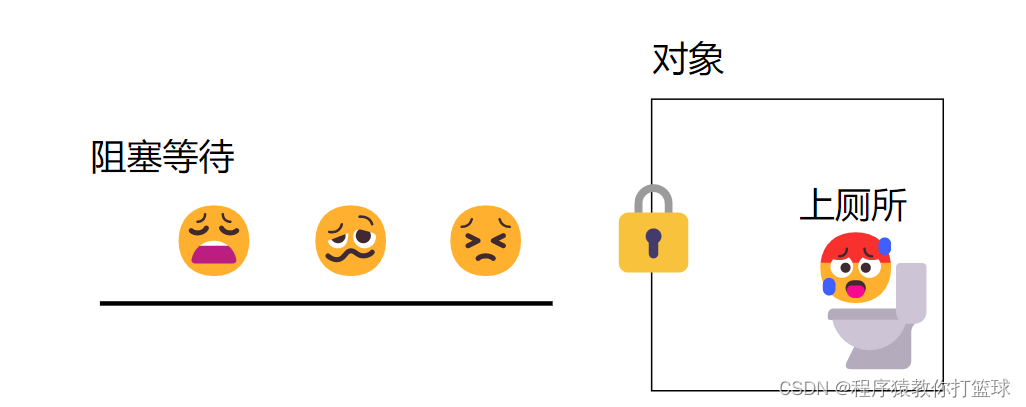
synchronized 用的锁是对象头里的,可以粗略理解成每个对象在存储的时候,都有一块内存表示当前 "锁定" 状态,类似于上述图中厕所有人还是没人,如果厕所有人(对象已经被加锁),此时其他人就无法使用,就得排队(阻塞等待)。如果厕所没人,就能赶紧去厕所,把锁加上,其他人就不能在上厕所了
理解 "阻塞等待",针对每一把锁,操作系统内部都维护了一个等待队列,当这个锁被某个线程占有时,其他线程尝试加锁,就加不上了,就会阻塞等待,而这个等待队列,就存储想要获取到这把锁的线程。
那么上一个线程释放锁了,下一个线程会立即获取到锁吗?并不是,而是需要靠操作系统来进行 "唤醒",这也是操作系统线程调度的一部分工作,假设 A 获取到锁了,B 尝试获取锁,C 后来的也尝试获取锁,当 A 释放锁了,B 一定能获取到锁吗?虽然 B 比 C 先来,但是B 不一定能获取到锁,而是和 C 重新竞争,并不遵循先来后到的原则,具体在介绍锁特性的时候会再次介绍。
3.2 针对 this 加锁
上面的案例我们是针对 object 对象加锁,同时也可以针对 this 加锁:
public class ThreadDemo {
public int count = 0;
public void increment() {
synchronized (this) {
count++;
}
}
}
这里加锁是对 this 对象加锁,在 JavaSE 语法阶段,学习到 this 关键字了解到 this 就是当前对象的引用。
后续要调用上述的 increment 方法时,必须要有一个 ThreadDemo 类型的对象才能调用 increment 方法,那么哪个对象调用了 increment 方法了,就是针对哪个对象加锁!
比如:
public static void main(String[] args) throws InterruptedException {
ThreadDemo demo = new ThreadDemo();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
demo.increment();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
demo.increment();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(demo.count);
}
// 打印结果:count = 100000
此时通过 demo 这个对象调用了 increment 方法,那就就是针对 demo 这个对象加锁,所以针对 this 加锁,也就是针对当前对象加锁,一定要弄清楚当前是哪个对象!
上述代码如果 t1 和 t2 线程都执行到了 demo.increment() 里的 synchronized 代码块,此时就会发送锁竞争。当 t1 竞争到锁了,此时 t2 就需要阻塞等待,等到 t1 执行完 synchronized 代码块后释放锁了,t2 才能尝试获取锁。
同时针对 this 加锁也可以写成如下的样子:
public class ThreadDemo {
public int count = 0;
synchronized public void increment() {
count++;
}
}
此时也是针对 this(当前对象) 加锁,只不过这里进入 increment 方法就会加锁,结束 increment 方法自动释放锁。
3.3 针对类对象加锁
类对象是个啥?不知道大家伙还记不记得学习反射的时候,需要获取类的class这个对象,才能进行反射。
当我们针对静态方法加锁时,就是针对类对象加锁:
public class ThreadDemo {
synchronized public static void func() {
System.out.println("hello world");
}
}
此时也就是相当于针对 ThreadDemo.class 这个对象加锁!
3.4 synchronized 疑难解答
注意!一定要弄清楚针对哪个对象加锁!不存在针对方法加锁!
有一个 Demo 类,并且实例化了一个 d 对象,下面的例子都基于 Demo 类来举例:
例1:synchronized 修饰了 func1 和 func2 方法,如果 t1 线程正在执行 d.func1() 方法,此时就针对 d 这个对象加锁了,如果此时 t2 想执行 d.func2() 就不行了!因为 d 已经被 t1 加锁了!
例2:synchronized 修饰了 fun1 方法但是没有修饰 func2 方法,如果 t1 线程正在执行 d.func1(),此时 t2 仍然能执行 d.func2(),因为 func2 没有被 synchronized 修饰。
例3:synchronized 修饰了静态的func1 方法,也修饰了普通的 func2 方法,如果 t1 线程正在执行 Demo.func1(),此时 t2 能执行 d.func2() 方法,因为是针对不同的对象加锁,t1 是针对 d 对象加锁,而 t2 是针对 Demo.class 类对象加锁。
3.5 synchronized 是可重入锁
这里设想这样的一个场景,t 线程执行 run 方法,进入方法后,针对 object 对象加锁,执行了一会代码后,还没释放锁,又再次对 object 对象加锁了!
按照前面的学习,t 只有等线程释放了锁,才能再次加锁,那上述情况不就是 t 在等待 t 释放锁,但是 t 目前释放不了,所以就僵住了,也就是死锁了!但是 synchronized 不会出现这样的问题:
public static void main(String[] args) {
Object object = new Object();
Thread t = new Thread(() -> {
synchronized (object) {
System.out.println("第一次加锁成功!");
synchronized (object) {
System.out.println("第二次加锁成功!");
}
}
});
t.start();
}
// 打印结果:
// 第一次加锁成功!
// 第二次加锁成功!
这个代码就是对 object 对象重复加锁了两次,按我们理解来说,这里 t 就僵住了!但是运行程序发现居然能正常打印 "第二次加锁成功!",那么就说明没有出现死锁的情况!
可重入锁,对同一个对象加锁两次,如果没有问题,那么就是可重入锁,synchronized 就是可重入锁!
下期预告:死锁的解决方案
版权归原作者 程序猿教你打篮球 所有, 如有侵权,请联系我们删除。