
python爬虫学习32
Beautiful soup 其三
目录
七、方法选择器
之前我们学习的方法都是基于属性来选择的,这实际上是非常不方便的,因为在选取某个特定节点的时候pycharm就不给提示了。。。这时候我们就可以使用Beautiful Soup为我们提供的一些查询方法,例如find_all和find等,然后传入响应的参数就可以进行更加灵活查询了。
7-1 find_all方法
查看find_all方法时,可以看到它有如下API
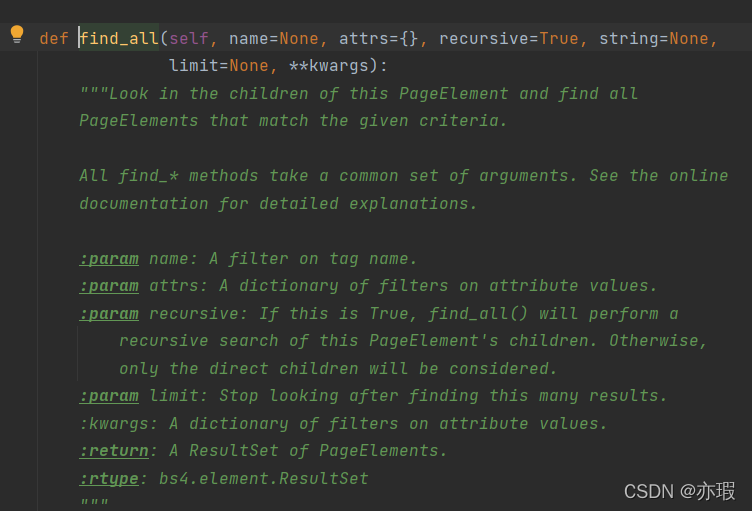
name 字段
这段html,又双叒叕来了:
html = """
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
实例如下
from bs4 import BeautifulSoup
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')# 使用find_all方法,查询所有名称为ul的节点print(soup.find_all(name='ul'))print(type(soup.find_all(name='ul')[0]))
运行结果:显然,文本中的ul节点只有一个,并且返回的结果被放在一个列表中。
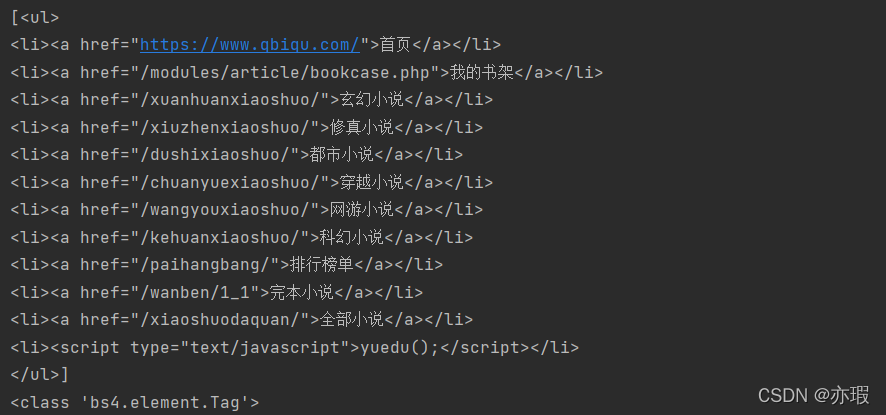
可以看到列表中的每一个元素的类型为Tag类,所以我们可以进行嵌套查询:
from bs4 import BeautifulSoup
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')
ul_list = soup.find_all(name='ul')# 这里为了更加普适使用了循环,但是这个例子里列表中只有一个元素,为了省事的话可以直接进行调用for item in ul_list:print(item.find_all(name='li'))
运行结果:该ul节点下的所有li节点就被查询出来了:

咳咳,大家可以练习一下在以上的基础上嵌套调用所有li节点下的a节点,这里就不再进行展示了(可不是偷懒啊!)
获取节点内的内容:
from bs4 import BeautifulSoup
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')for item in soup.find_all(name='ul'):
i = item.find_all(name='li')for thing in i:print(thing.string)
运行结果:提到内容的话很容易联想到string方法

attrs 字段
attrs字段用于进行按属性查询:
# attrsfrom bs4 import BeautifulSoup
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')# 格式为 字典 “属性名称”:“待检索的值”# 意为检索class属性为dahengfu的节点print(soup.find_all(attrs={'class':'dahengfu'}))print(soup.find_all(attrs={'id':'banner'}))
运行结果:

对于一些常用的属性,我们也可以偷懒一下:
soup = BeautifulSoup(html,'lxml')print(soup.find_all(id='banner'))
运行结果:

text 字段
text字段用于匹配节点文本,其传入形式可以是字符串,也可以是正则表达式对象:
from bs4 import BeautifulSoup
import re
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')# 检索所有含有小说的节点内文本print(soup.find_all(text=re.compile('小说')))
运行结果:

7-2 find
find方法也可以查询符合条件的元素,但是find与find_all最大的区别是find仅仅返回第一个符合的结果,类似于我们之前学习正则时fetch与find_all的区别。
# find方法from bs4 import BeautifulSoup
html ="""
<div class="nav">
<ul>
<li><a href="https://www.qbiqu.com/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/wanben/1_1">完本小说</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
<li><script type="text/javascript">yuedu();</script></li>
</ul>
</div>
<div id="banner" style="display:none"></div>
<div class="dahengfu"><script type="text/javascript">list1();</script></div>
"""
soup = BeautifulSoup(html,'lxml')print(soup.find(name='li'))
运行结果:

今日结束,未完待续
本文转载自: https://blog.csdn.net/szshiquan/article/details/124370894
版权归原作者 亦瑕 所有, 如有侵权,请联系我们删除。
版权归原作者 亦瑕 所有, 如有侵权,请联系我们删除。