
一、Spark概述
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)
二、Spark的特点
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
特点可以概括为以下四点
1:运行速度快
2:容易使用
3:通用性
4:运行模式多样
Spark支持使用Scala Java Python和R语言编程,由于Spark采用Scala语言进行开发,因此建议采用Scala语言进行Spark应用程序的编写,采用Scala语言编写Spark应用程序,可以获得最好的性能,和其他语言相比,Scala主要有以下三个方面的优势
1:Java代码比较繁琐
2:Python语言并发性能不好
3:Scala兼容Java
三、Spark生态系统
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。
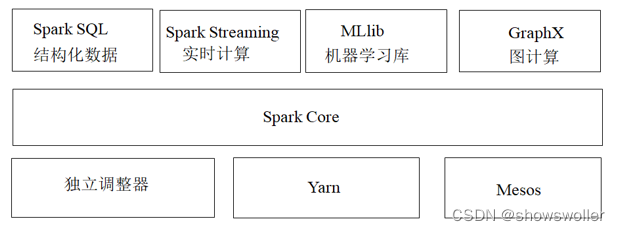
Spark Core:Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。
Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。
MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
GraphX:Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。
独立调度器、Yarn、Mesos:集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
四、Spark与Hadoop对比
1:编程方式
Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2:数据存储
Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
3:数据处理
Hadoop在每次执行数据处理时,都要从磁盘中加载数据,导致磁盘IO开销较大;而Spark在执行数据处理时,要将数据加载到内存中,直接在内存中加载中间结果数据集,减少了磁盘的IO开销。
4:数据容错
MapReduce计算的中间结果数据,保存在磁盘中,Hadoop底层实现了备份机制,从而保证了数据容错;Spark RDD实现了基于Lineage的容错机制和设置检查点方式的容错机制,弥补数据在内存处理时,因断电导致数据丢失的问题。
五、Spark的部署方式

1:Standalone模式
Standalone模式被称为集群单机模式。
该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
2:Mesos模式
Mesos模式被称为Spark on Mesos模式。
Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
3:Yarn模式
Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
六、Spark运行架构与原理
Spark运行架构主要由SparkContext、Cluster Manager和Worker组成,其中Cluster Manager负责整个集群的统一资源管理,Worker节点中的Executor是应用执行的主要进程,内部含有多个Task线程以及内存空间,
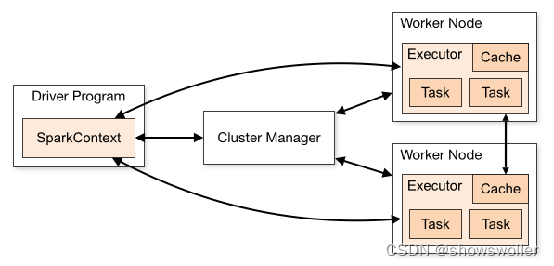
七、Spark运行基本流程
Spark应用在集群上作为独立的进程组来运行,具体运行流程如下所示。
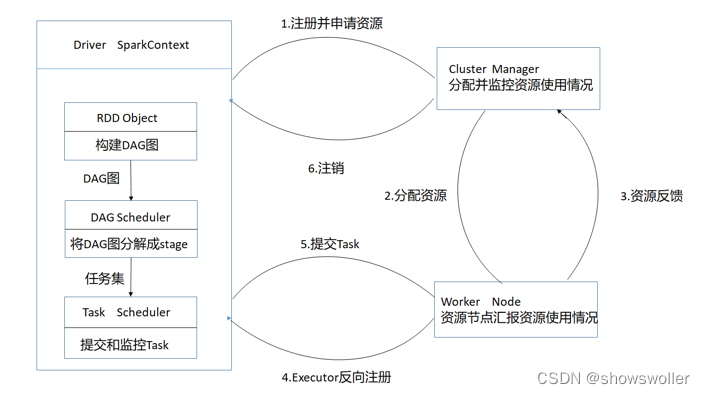
1)当一个Spark应用被提交时,根据提交参数创建Driver进程,为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控。
2)SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器Task Scheduler处理。
3)资源管理器Cluster Manager为Executor分配资源,并启动Executor进程
4)Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
5)Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
创作不易 觉得有帮助请点赞关注收藏~~~
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。