
前言
本章介绍LinuxShell知识点,以及Shell命令操作使用,学习LinuxShell编程前需要掌握Linux的基础命令。
提示:以下是本篇文章正文内容,下面案例可供参考
一、shell基础知识
1、shell概念
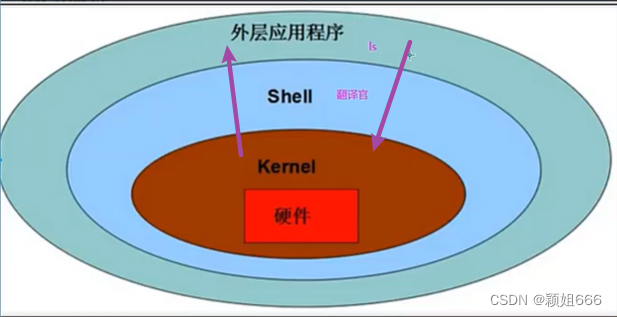
Shell的英文单词是外壳,Shell是一类用C语言编写的命令行解释器程序的统称,同时也是一个脚本编程语言,俗称Sell编程。
它是用户与内核交互的桥梁,Shell对操作者屏蔽了内核的处理。
简单来说Shell就相当于是一个翻译官,我们编写的代码,内核看不懂需要Shell进行翻译才能看懂,同理,内核发送给我们的信息我们用户也看不懂,是Shell翻译管在中间给翻译成了我们可以看懂的代码。
2、Shell的功能
接收:用户命令
调用:相应的应用程序
解释并交给:内核去处理
返还:内核处理结果
3、Shell种类(了解)
3.1、MS-DOS
本身就是一个Shell
3.2、Windows的Shell
Windows Explorer(图形化)、cmd(命令行)
3.3、UNIX的Shell
sh、bash、ksh等等(平时我们所说的Shell,多指UNIX的Shell)
sh(Bourne Shell)- sh是一个遵循Unix POSIX标准的Shell程序。 sh是所有其他Unix Shel的基础。 sh的可移植性最高。
bash(Bourne Again Shell)- bash是sh的增强版,是用来替代sh的,它兼容sh,同时也融入了ksh和csh的有用功能,bash是大多数Linux系统的默认Shell。
shell种类
类别说明实例(使用ll命令查看)
/bin/sh
是bash shell的一个快捷方式
/bin/bash
bash shell是大多数Linux默认的shell,包含的功能几乎可以涵盖shell所有的功能。
/sbin/nologin
表示非交互,该用户不能登录操作系统。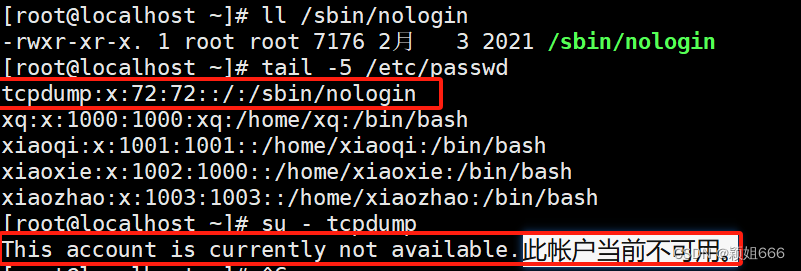
/bin/dash
小巧,高效,功能相比少一些。
我这的系统没有该shell种类
/bin/tcsh
是csh的增强版,完全兼容csh。
/bin/csh
具有C语言风格的一种shell,具有许多特性,但也有一些缺陷。
4、Shell调用命令
4.1、查看shell命令
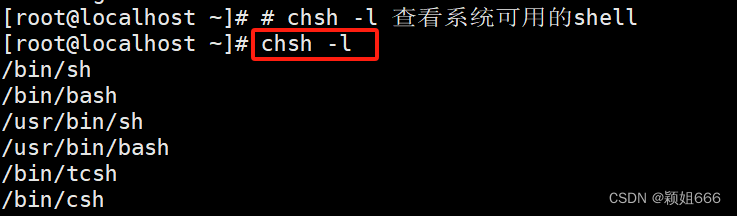
1)chsh -l命令:查看系统可用的Shell
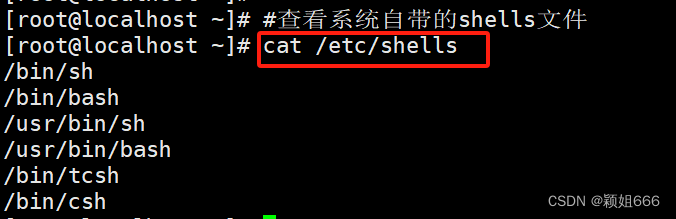
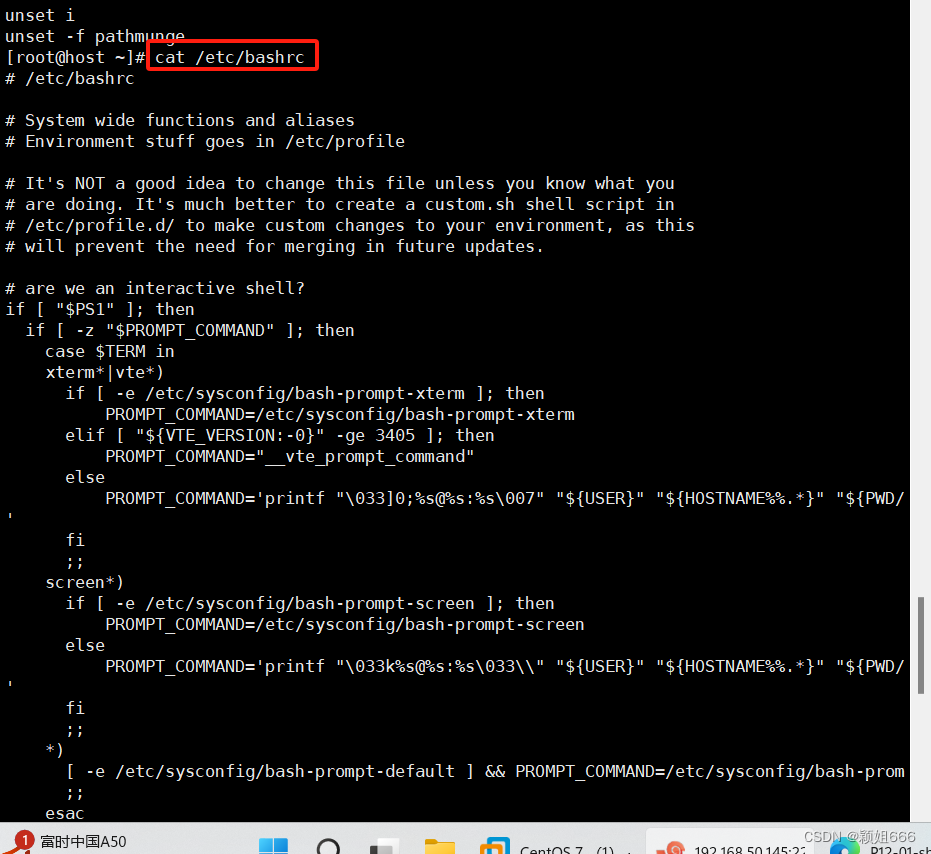
2)cat 命令:查看系统自带的shells文件
2)echo $SHELL命令:查看当前用户使用的Shell

4.2、chsh -s命令:永久更改用户登录的Shell
注意:要更改的Shell类型必须是系统Shell文件里面有的Shell类型。
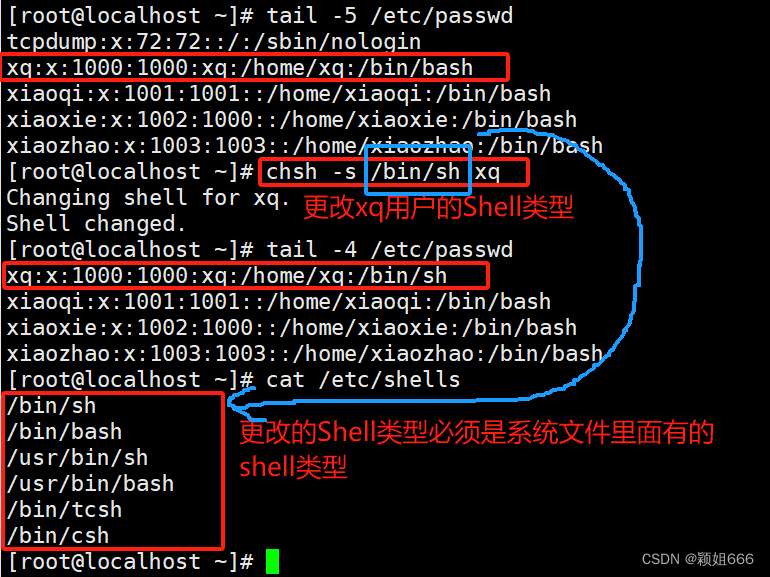
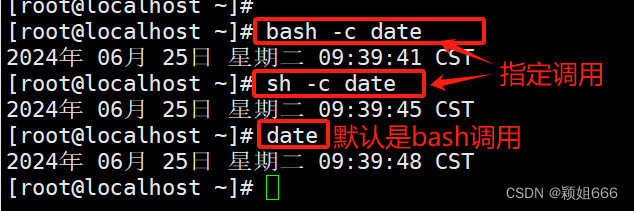
4.3、调用shell执行命令
1)bash -c命令:调用bash
2)sh -c命令:调用sh命令
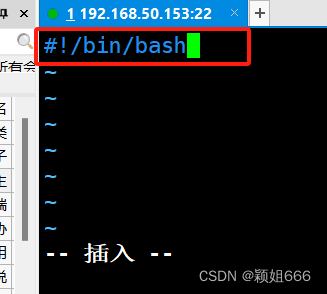
4.4、【#!】:Shell命令行解释器,声明该脚本是Shell脚本
#!/bin/bash
声明:在<本Shell脚本>中,针对【#!行】之后的<行>,开始使用/bin/bash命令行解释器。
【#!】用于声明本脚本需要采用的命令行解释器
4.5、Shell脚本的基本写法
1)创建后缀名为sh的文件
#vim test.sh

2)脚本编写
第一步:【#!】声明该脚本用什么解释器来执行
#!/bin/bash //脚本第一行
#!脚本声明:即它告诉系统这个脚本需要声明解释器来执行,也就是使用哪一种Shell
第二步:对脚本的基本信息的描述(通常简写,无强制规定)
“#”开头的行为注释行,不会执行
#Name:名字
#Desc:描述describe
#Path:存放路径
#Usage:用法
#Update:更新时间
第三步:脚本的具体内容(Linux基本命令,脚本需要执行的命令)
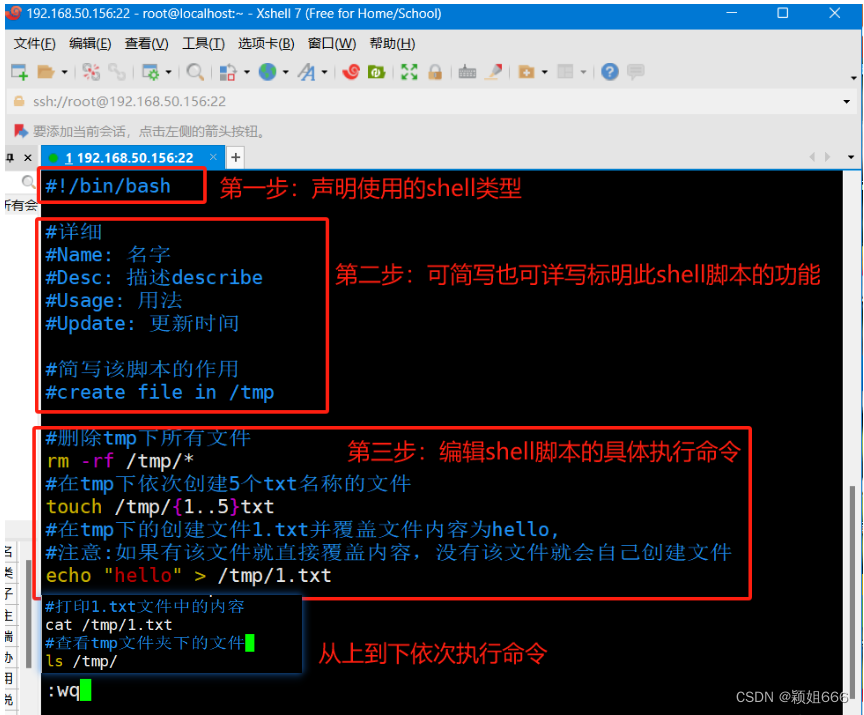
3)脚本运行
脚本运行的两种情况:
直接通过命令解释器就无需添加执行权限 共享父进程执行法:source test02.sh 或者 .test02.sh
独立子进程执行法: bash test.sh 或者 sh test.sh
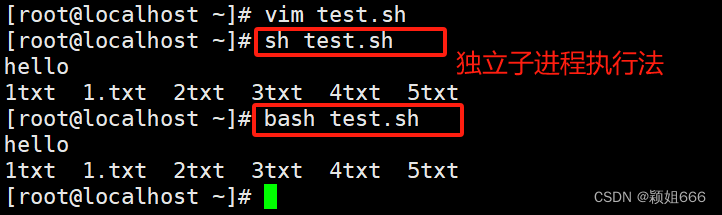
共享父进程执行法,在当前 Shell 进程中执行命令或脚本,使用 source 或 .,会直接影响当前 Shell 环境。
独立子进程执行法,在新的 Shell 子进程中执行命令或脚本,直接执行脚本或使用括号 (),不会影响父进程的环境。
需要添加执行权限(x)才能进行脚本运行 相对路径 绝对路径
在下面内置变量的相关符号举例图5中可以看到在添加执行权限,在绝对路径下使用共享父进程执行法执行脚本。
4)shell脚本中的引号
双引号- “”是<部分引用>,可以识别<特殊符号> 可以识别${...}变量引用符号-
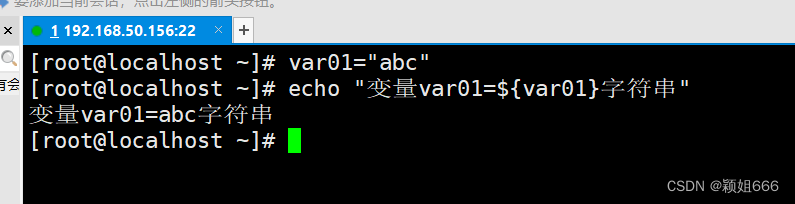
单引号- ‘’是<完全引用>,不能识别<特殊符号>- 单引号:中间值当成字符串进行输出

5、Shell变量
5.1、概念(了解)
一个进程中用于存储数据的内存实体,它对应着一个内存存储空间。
man帮助手册用于描述命令的帮助信息。例如#man bash
5.2、变量类型
变量类型
类型概念作用域定义方法
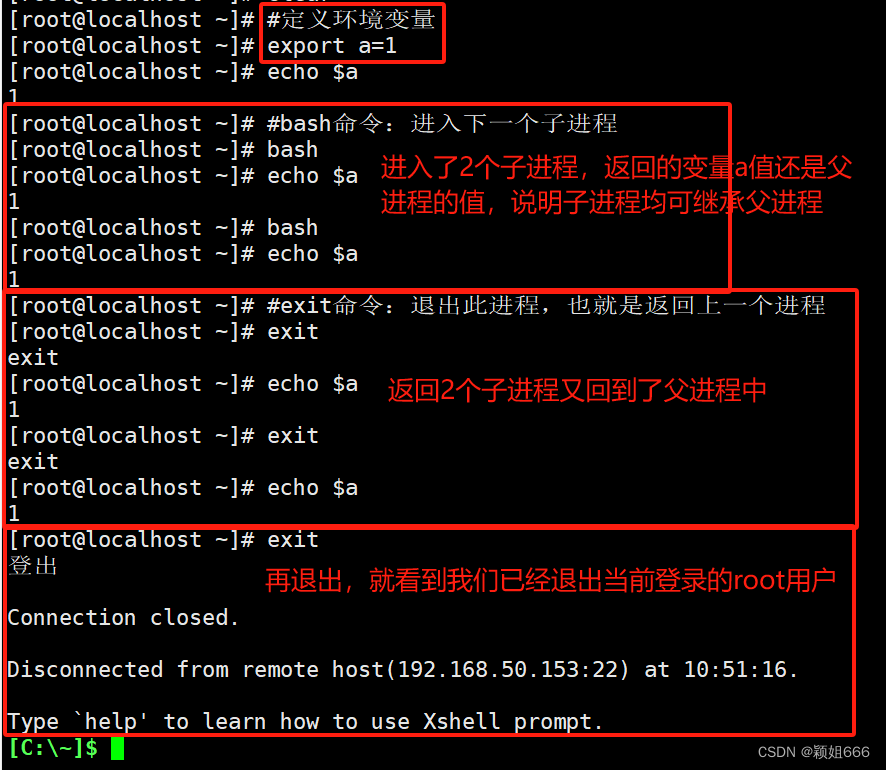
环境变量
当前进程有效,并且能够被子进程调用。
当前进程及子进程生效,传子不传父,所有子进程均可继承export var01=值
环境变量和本地变量都是要在当前进程(当前终端)中才能生效,如果换了另一个终端就它们是无效的。
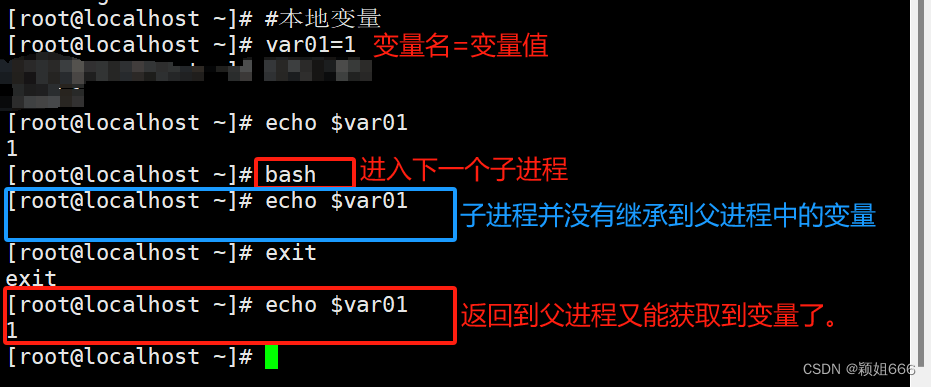
本地变量
当前用户自定义的变量。当前进程中有效,其他进程及当前进程的子进程无效。
当前进程生效,不可继承var01=值
内置变量
系统变量,shell本身已经固定好了它的名字和作用。
/
/
/
举例:
环境变量
本地变量
1)环境变量的相关命令
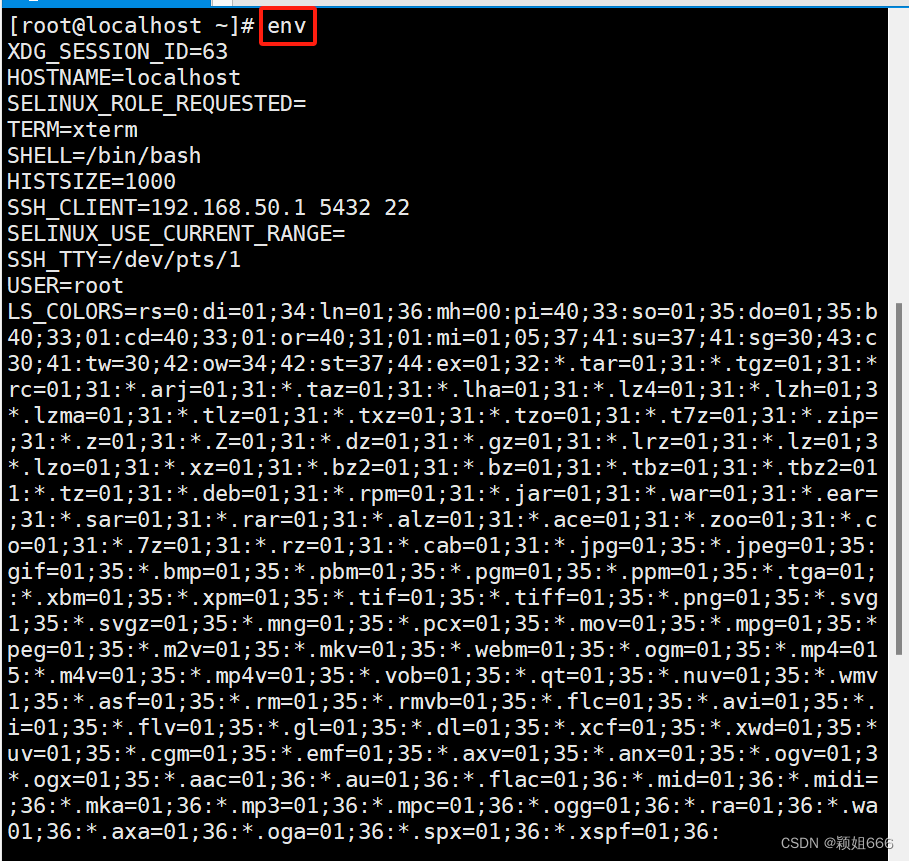
env命令:查看当前用户的环境变量
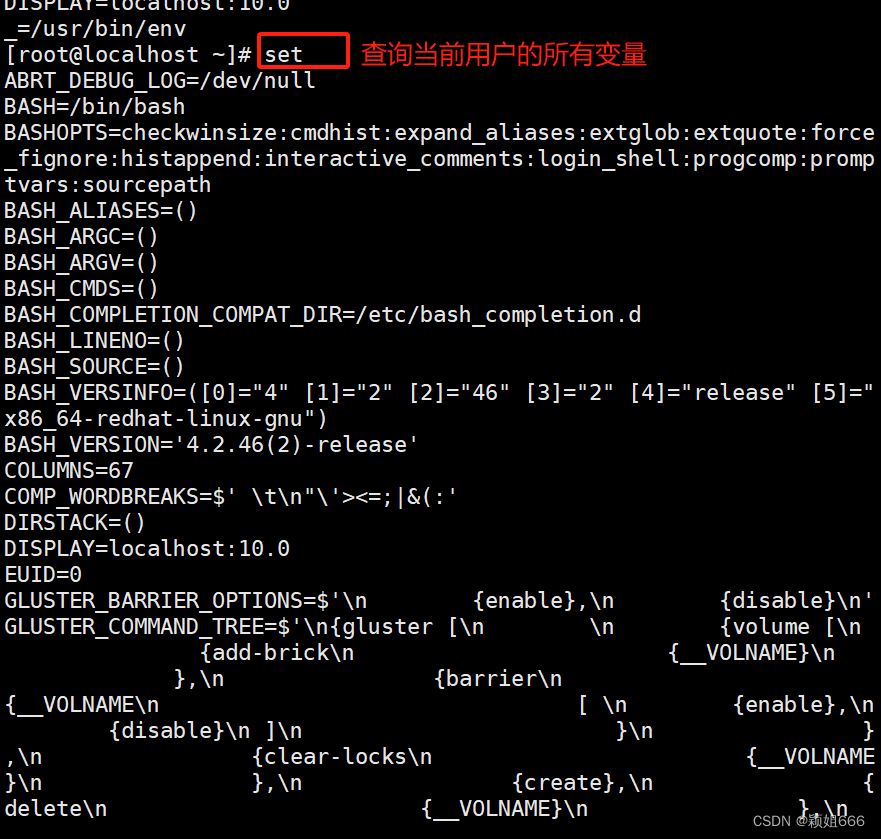
set命令:查询当前用户的所有变量(临时变量与环境变量)
export命令:将当前变量变成环境变量- 永久生效 /etc/profile是系统文件,对所有用户生效,在系统启动的时候会执行/etc/profile里面所有的变量。/etc/profile里面都是脚本**#vim /etc/profile** 进入此文件里面添加变量export name=xq

2)内置变量的相关符号
内置变量的相关符号
符号说明举例
$?
上一条命令执行后返回的状态,当返回状态值为0时表示执行正常,非0值表示执行异常或出错。
#echo $?
(通过$?来进行一个判断,判断上一条命令的执行状态正确执行还是错误执行。)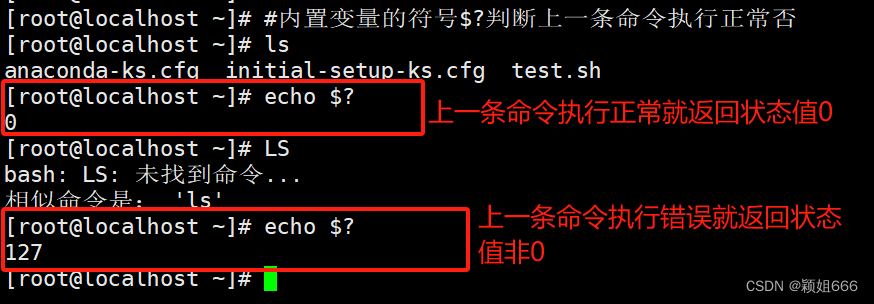
$$
当前所在进程的进程号 echo $$
eg:退出当前会话 kill -9 echo $$ ====> 相当于exit命令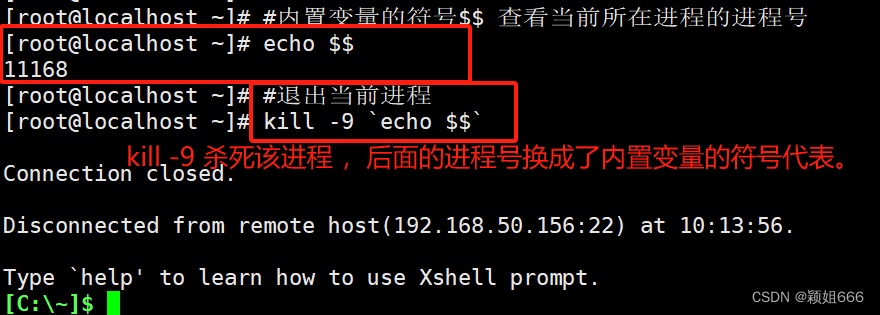
$!
后台运行的最后一个进程号(当前终端)。
!$
调用最后一条命令历史中的参数。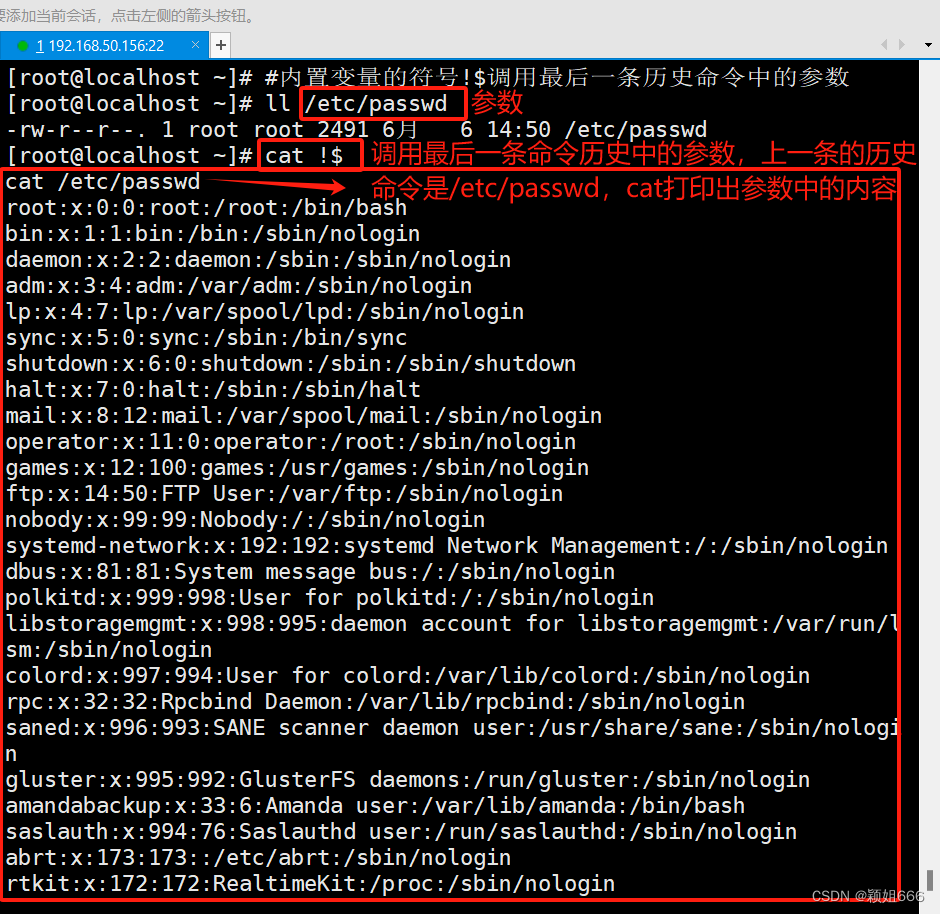
!!
调用最后一条历史命令。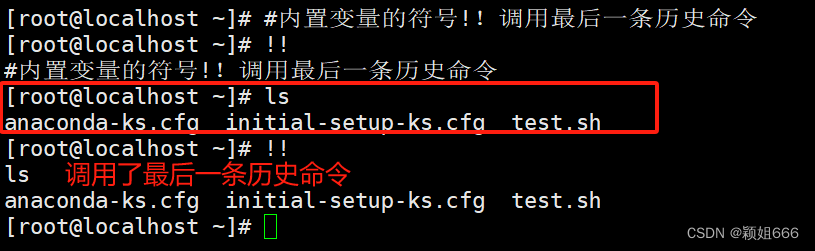
$#
脚本后面接的参数的个数。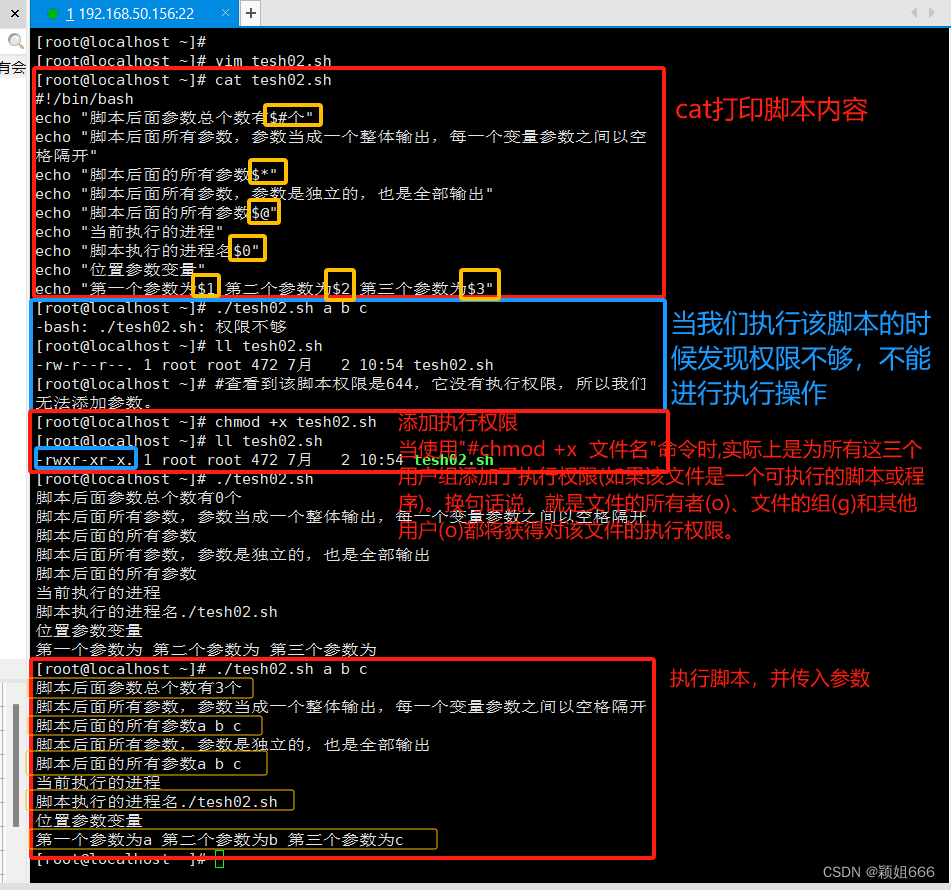
图5
$*
脚本后面所有参数,参数当成一个整体输出,每一个变量参数之间以空格隔开。
$@
脚本后面所有参数,参数是独立的,也是全部输出。
$0
当前执行是进程/程序名 echo $0
$1~$9
位置参数变量
$(10)~$(n)
扩展位置参数变量 第10个位置变量必须用{}大括号括起来。
3)用户环境变量配置文件
用户级是对当前用户生效
系统级是对所有用户生效

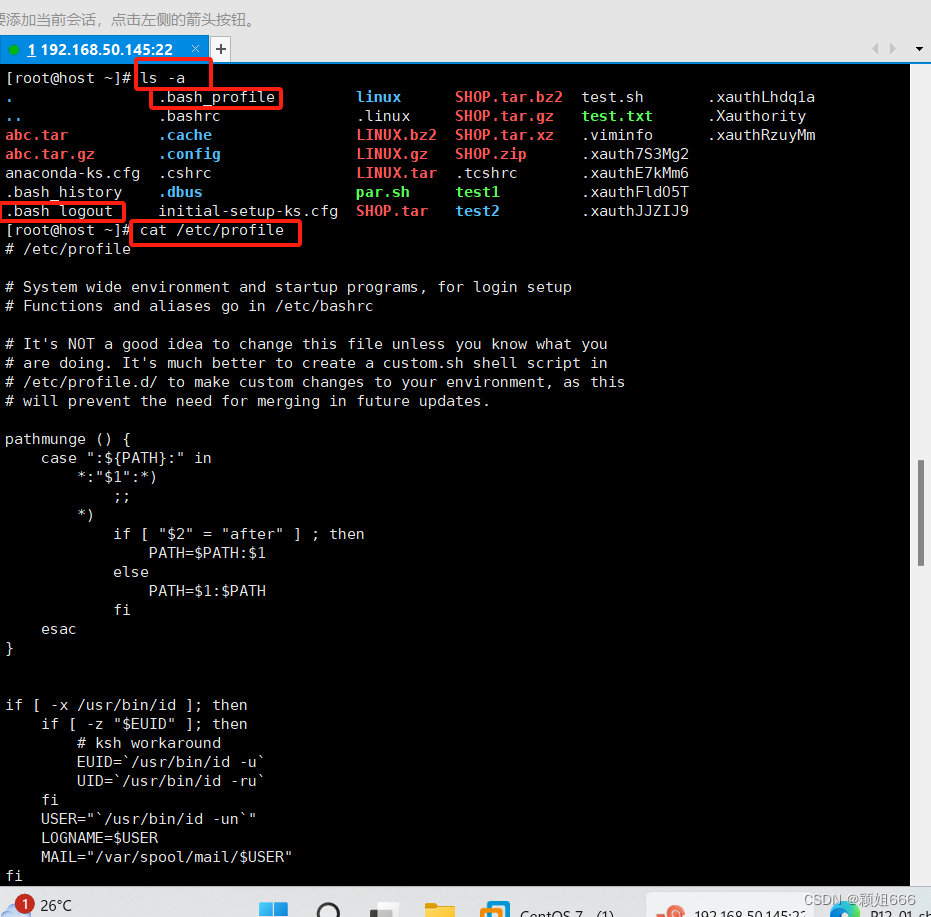

5.3、定义变量规则
1)命名规则
可以由字母、数字、下划线组成, 不能以数字开头, 不能是关键字,见名知意。
2)定义方式
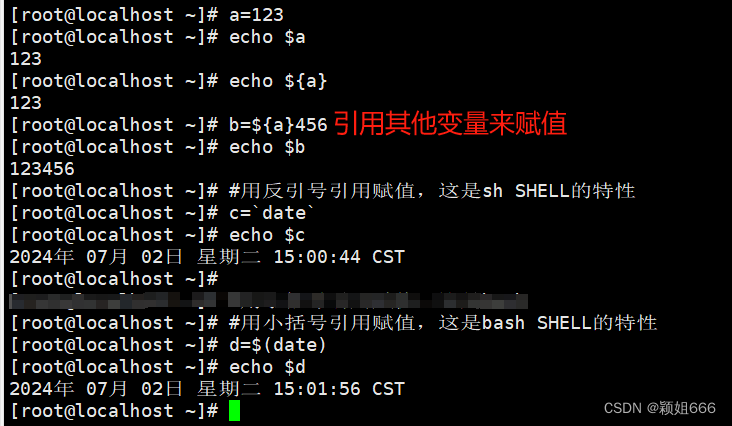
变量名=“变量值” 或者 变量名=变量值
注意:变量名与变量值等号之间不能有空格,不然就定义失败。
- 调用(提取)变量: $变量名 或 ${变量名}
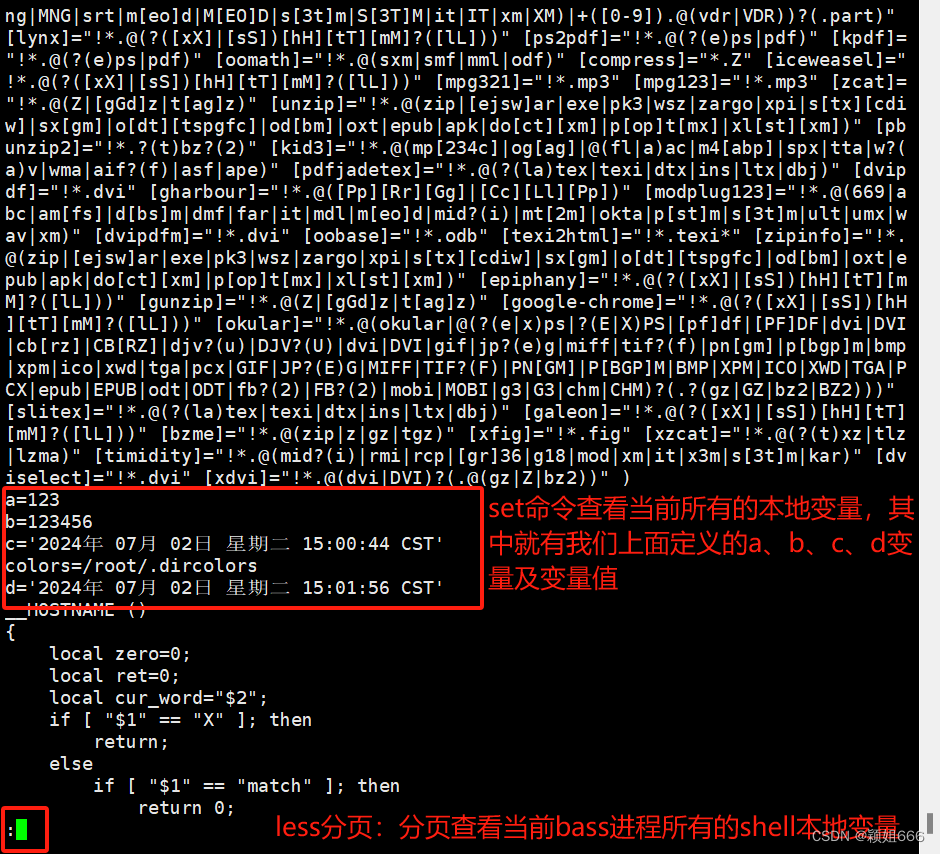
5.4、set命令:查看变量
查看:当前bash进程的Shell本地变量
#var02="456"
#set 查看当前bash进程所有的Shell本地变量
#set | less 分页查看当前bash进程所有的Shell本地变量
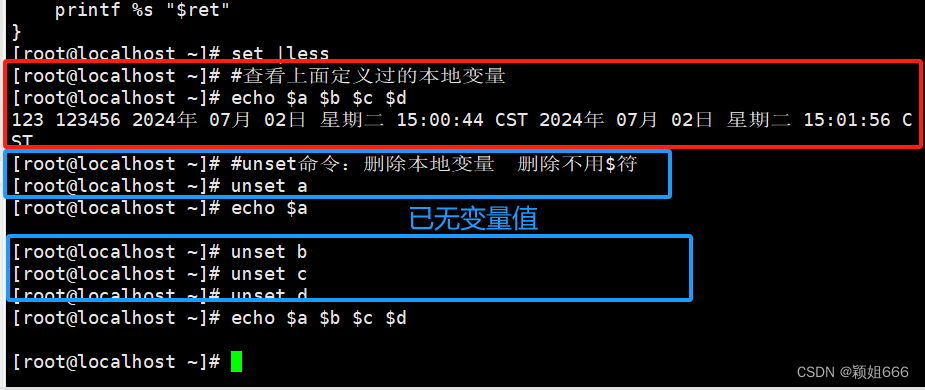
5.5、unset命令:删除变量
通常我们是在<Shell脚本>定义并使用<Shell变量>,当<Shell脚本>执行结束之后,<Shell变量>将随着<进程>的消亡而消亡。
(也就是当我们把终端关闭,之前定义的本地变量就会消失,因为它们不是环境变量,不是永久生效的,它们只是在当前终端生效。)
删除:当前<bash进程>的与<Shell本地变量>
unset var02 set | grep var02
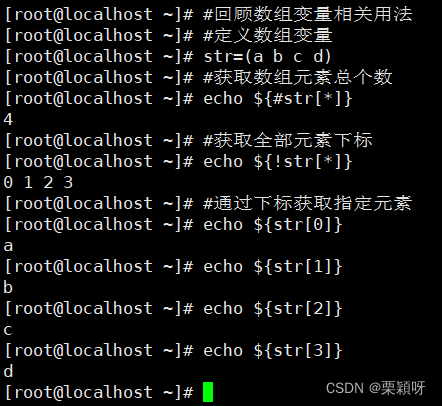
5.6、特殊变量(数组变量)
1)概念
把多个元素按一定顺序排列的集合,就是把有限个元素用一个名字命名,然后用编号区分它们的变量的集合,这个名字称为数组名,编号称为下标。
数组下标:一般从0开始。
数组是可以保存一组值的变量。

2)定义数组
Shell数组用括号来表示,元素用空格分割开,
语法格式:
array_name=(value1 value2 ... valuen)
定义数组 :
数组名=(值1 值2 ... 值n)

3)查看数组中某个元素值
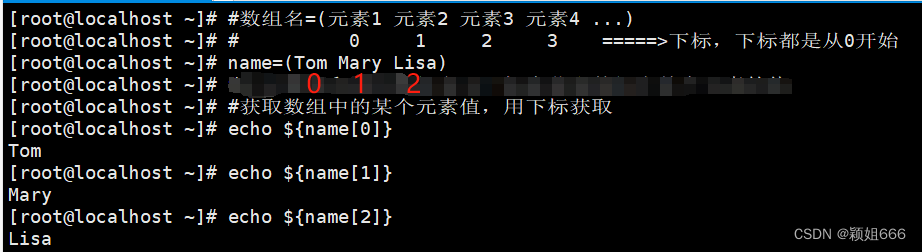
4)数组的遍历
遍历数组全部元素
***和@**符号数组遍历:通过数组名遍历出所有元素的值
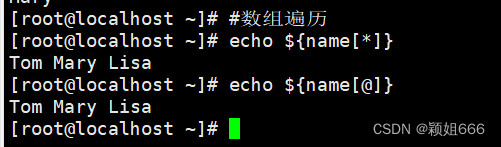
5)查看数组中全部元素的下标以及数组中元素的总个数
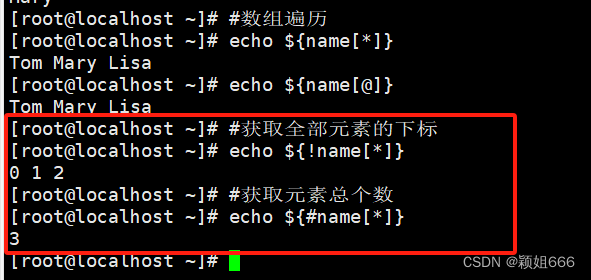
6)添加元素

7)unset命令:删除数组元素
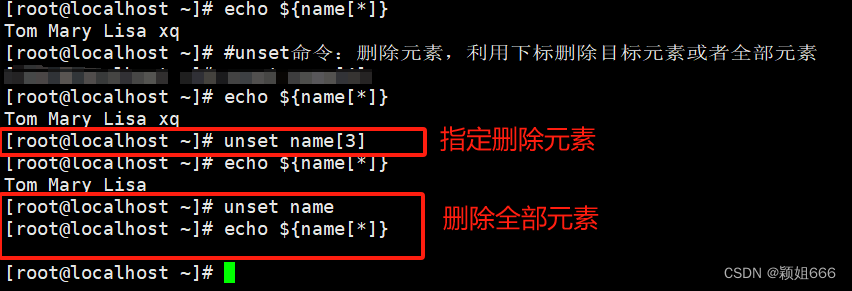
二、Shell辅助命令
1、标准输入输出及重定向
1.1、标准输入输出概念
stdin标准输入:打开终端在键盘上输入的内容就是标准输入。
stdout标准输出:就是在终端显示出来的内容就是标准输出。
1.2、echo命令:将指定内容输出到屏幕(标准输出)
常用选项说明
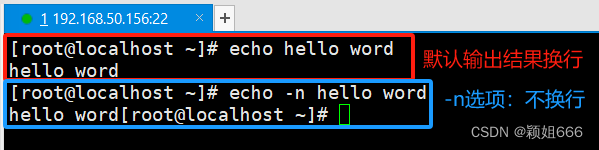
-n
输出结果后面没有换行符,也就是不换行
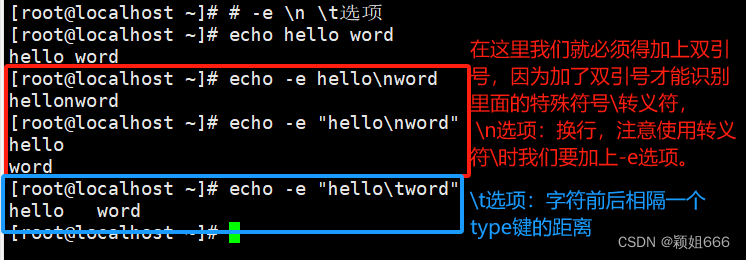
-e
启用转义符\(需要输出特殊符号的时候:\n \t)
\n
换行
\t
横向制表符,有一个type键的长度,一个type键就相当于四个空格
其他选项我们就查手册#man echo或查帮助,查帮助前要先确定echo是内部命令还是外部命令,用type命令查看, 是内部命令我们就用和help echo命令。
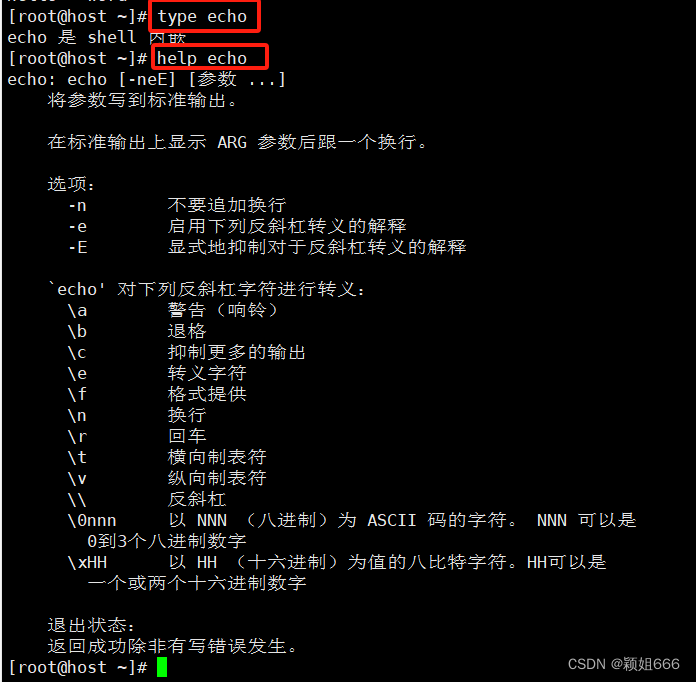
常用选项举例
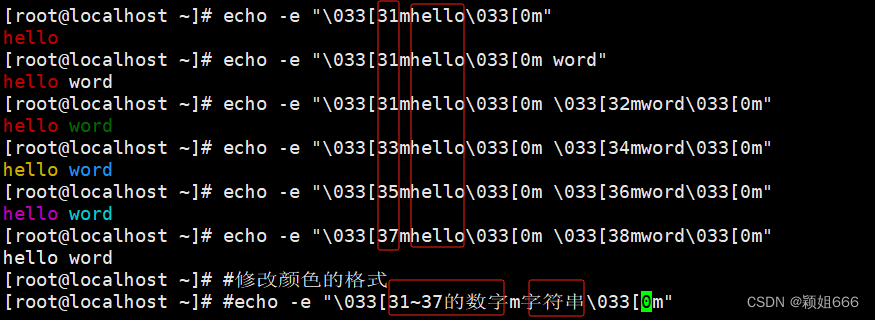
其他选项:修改输出字体颜色
1.3、标准输出重定向
1)概念
是指把本应该输出到屏幕的内容重新导向其他地方,比如导入文件中。 标准输出又分为标准输出和标准错误输出。
2)分类
stdout标准输出:一个命令执行之后的正确结果输出,在输出重定向是用数字1表示,也可以省略不写。
stderr标准错误输出:一个命令执行之后的报错信息输出,在输出重定向是用数字2表示。
3)符号>和>>、&
>符号表示覆盖式重定向
覆盖式重定向,把原本输出到终端的内容覆盖到指定文件的文件内容。 该文件可以存在也可以不存在。存在的话直接覆盖内容,不存在的话就会创建文件加覆盖文件内容。
正确输出
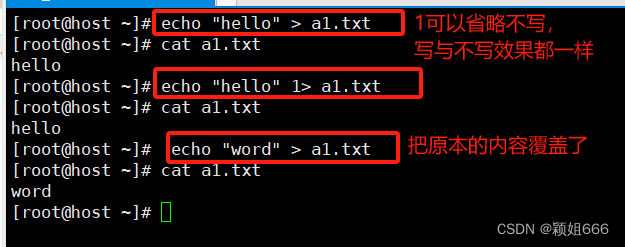
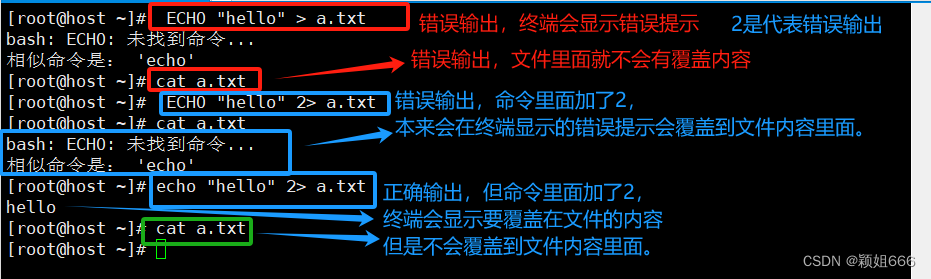
错误输出: 也就是说命令里面加了2,错误输出命令的错误提示会覆盖文件的内容, 相反正确输出的命令反而不会覆盖文件的内容,因为加了2,就算是正确的输出命令也被认定为错误的输出命令,该命令就不会被执行。
>>表示追加式重定向
正确输出
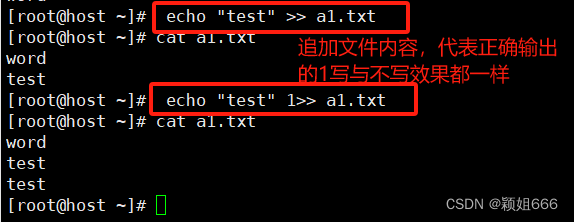
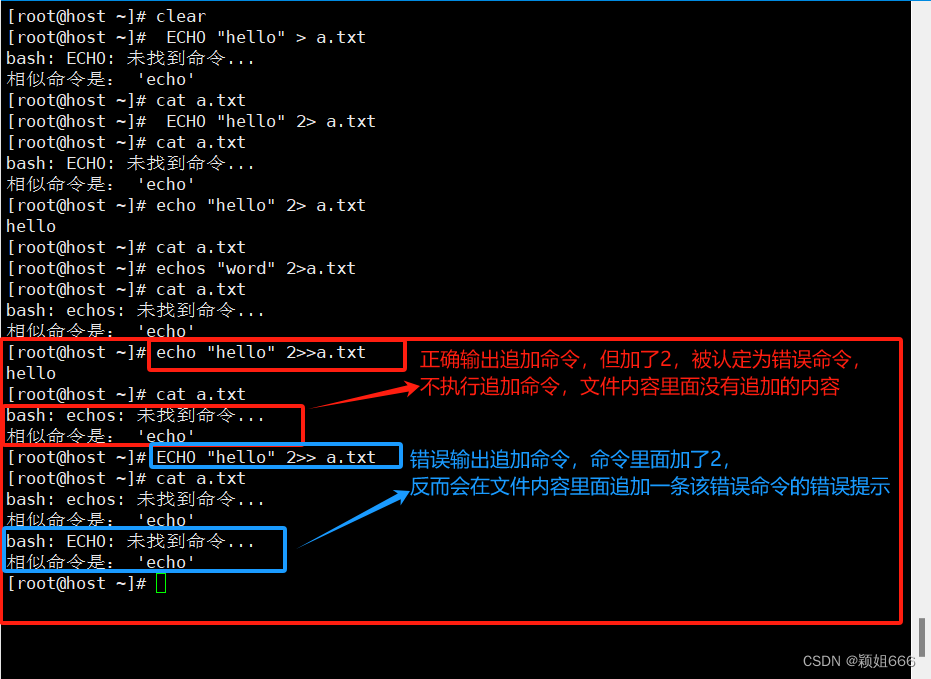
错误输出: 错误命令会显示在文件内容中,正确的不会显示在文件内容中。
&符号表示1和2
会将标准输出和标准错误输出的信息,全部重定向输入到指定文件

4)应用场景
做MySQL数据监控的时候,不想看到错误的提示消息就会用到输出重定向,把错误输出把它过滤掉只留下正确输出。
1.4、标准输入重定向
1)概念
输入重定向是指把本应该从键盘输入的来源换成从文件或屏幕中的内容进行输入。
2)符号<和<<
<符号表示覆盖式重定向
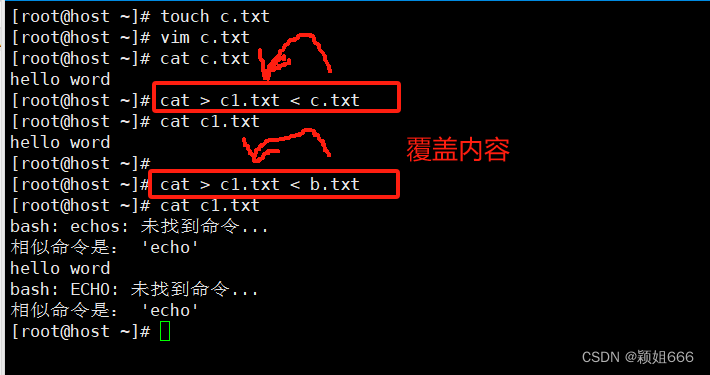
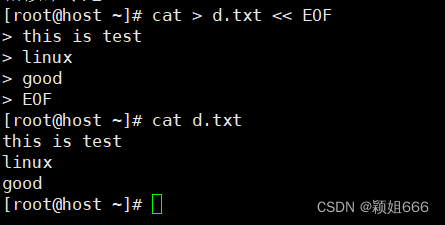
<<符号表示追加式重定向
手动输入内容创建文件:用标准输入追加式写内容到d.txt文件中 EOF标识符既是开始也是结束
更加方便我们编写shell脚本
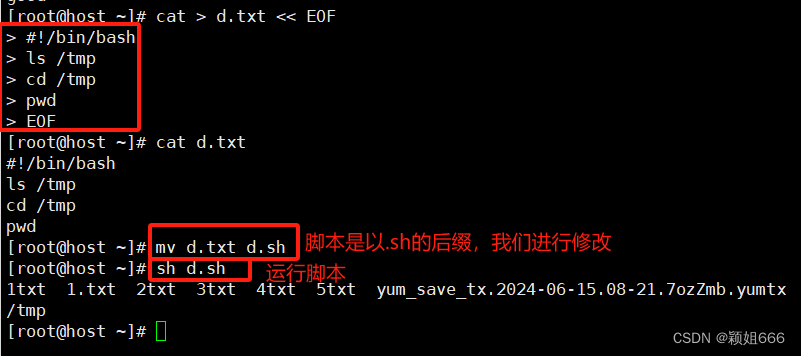
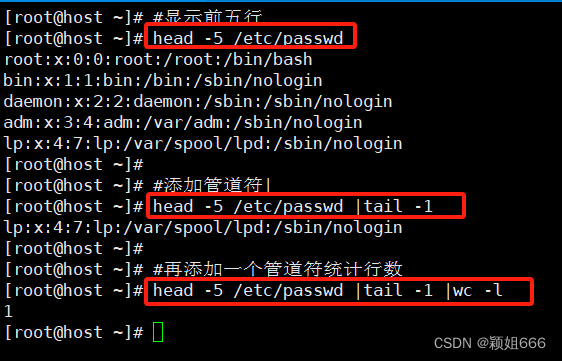
1.5、管道符| 与 xargs命令
1)管道符|
作用: 将前一个命令的标准输出,作为后一个命令的标准输入。(Linux基础命令知识点有讲过)
2)xargs命令
作用
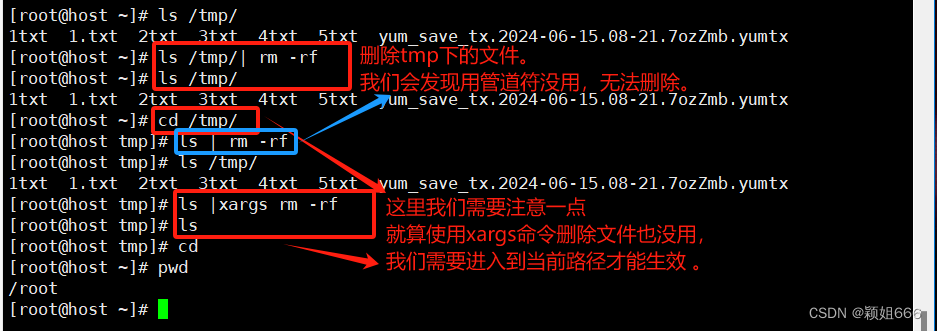
部分命令不支持通过管道符传入的标准输入,可以使用xargs来强制使用管道符传递输入(比如rm,kill等)
举例
rm是不能直接接收管道符前面的标准输入,我们就使用xargs命令
2、grep命令和正则的使用
2.1、grep命令
1)功能
筛选过滤出包含<匹配字符串>的<整行>
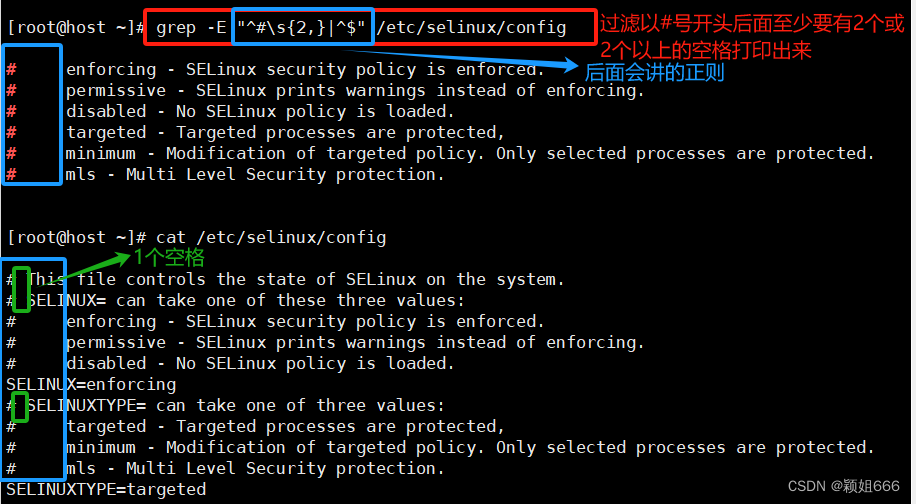
例如:筛选出以#开头的打印出来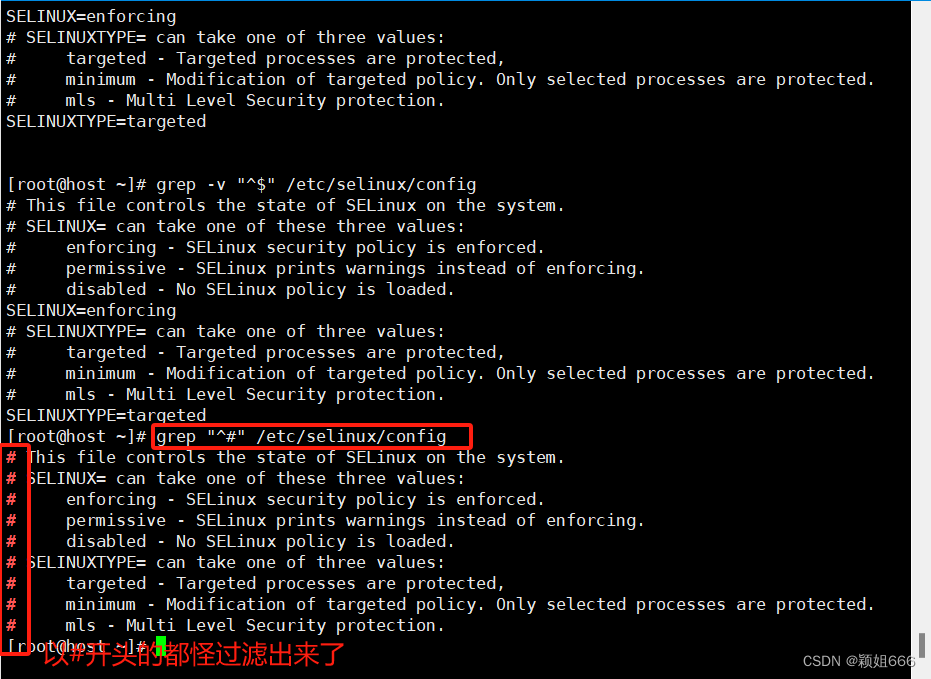
2)语法
grep [选项] PATTERN [FILE....]
PATTERN:就是正则表达式,默认情况下,grep命令使用基本正则
3)选项
-i
表示忽略大小写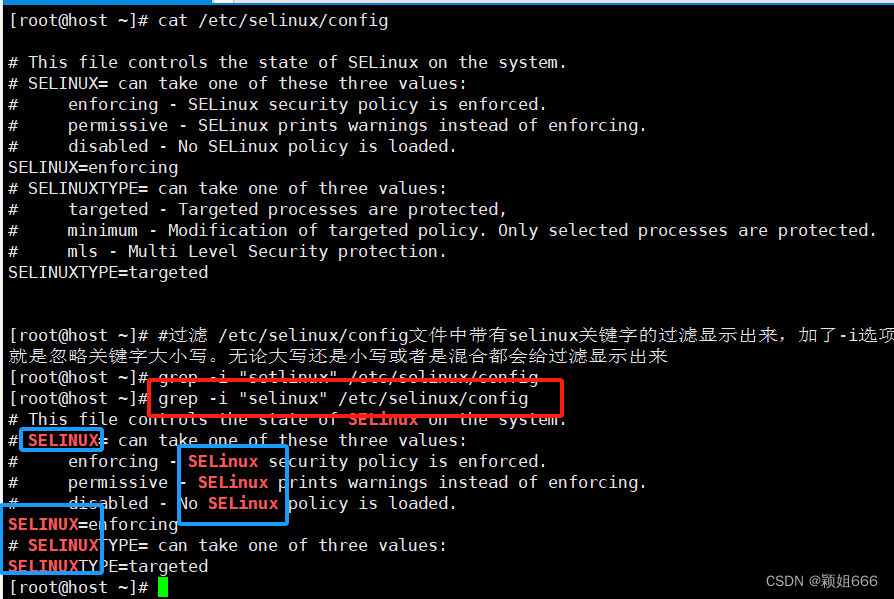
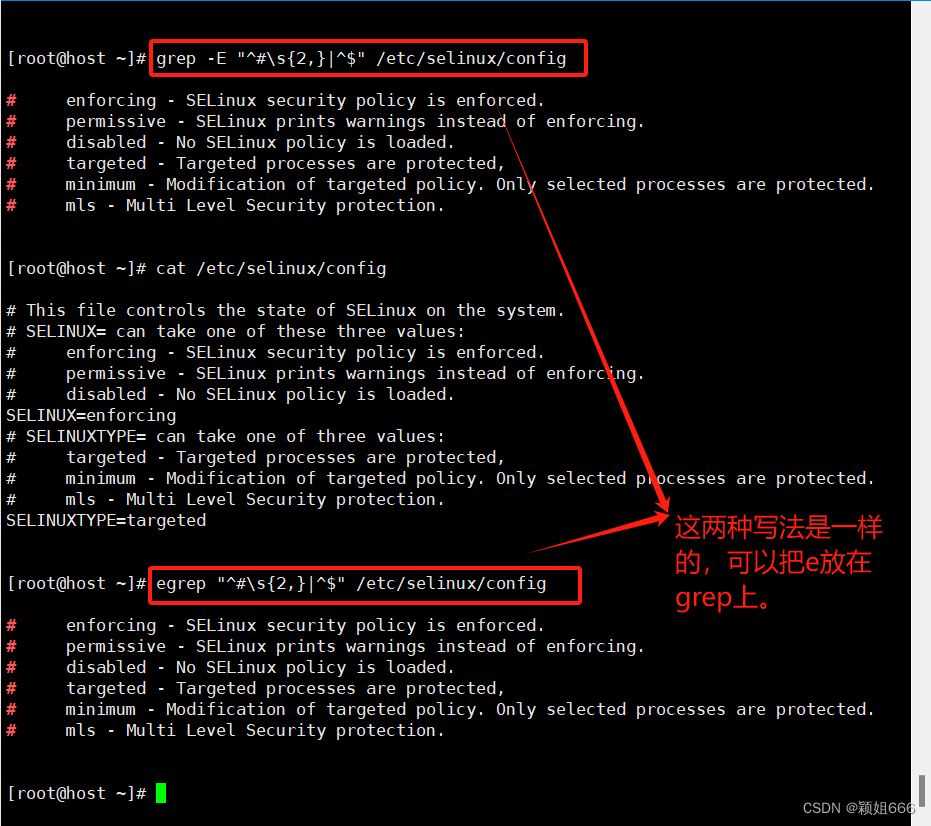
-E
表示启用<扩展正则>,将模式 PATTERN 作为一个扩展的正则表达式来解释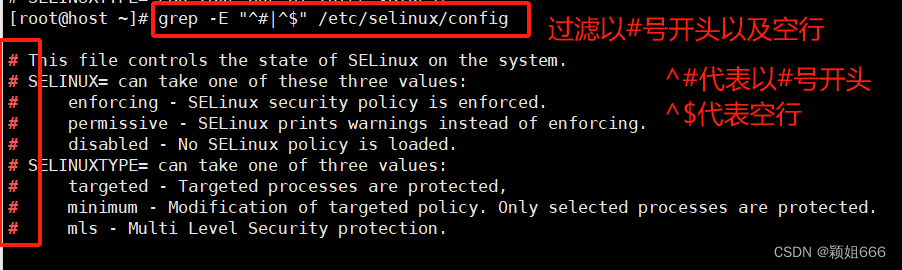
-o
只显示匹配的行中与 PATTERN 相匹配的部分。
默认情况下,是输出包含<匹配内容>的<一行数据>。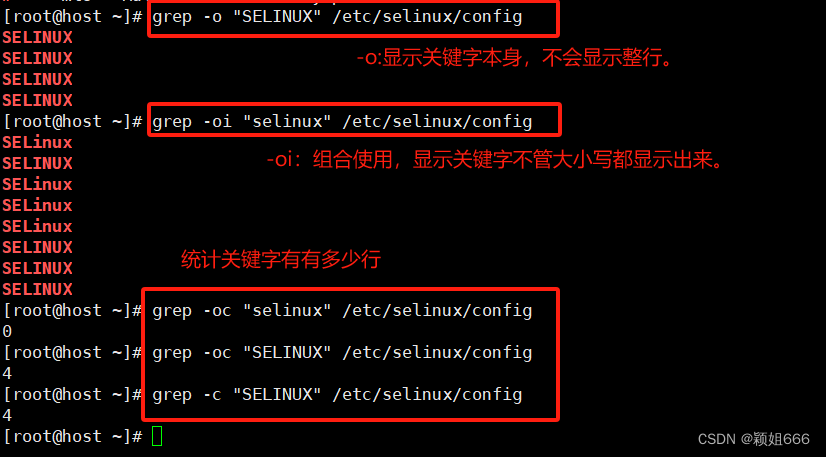
-v
表示仅输出<不匹配的数据行> 注意是<不匹配的行>,也就是取反
^和$代表空行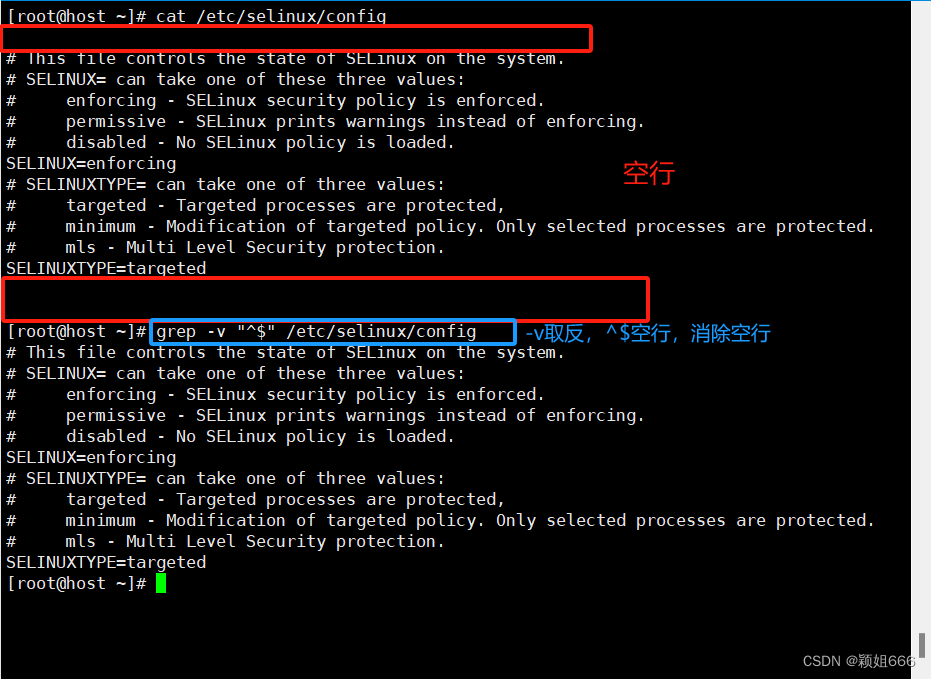
-B
打印出匹配的行之前的上文 NUM 行。
在相邻的匹配组之间将会打印内容是 -- 的一行。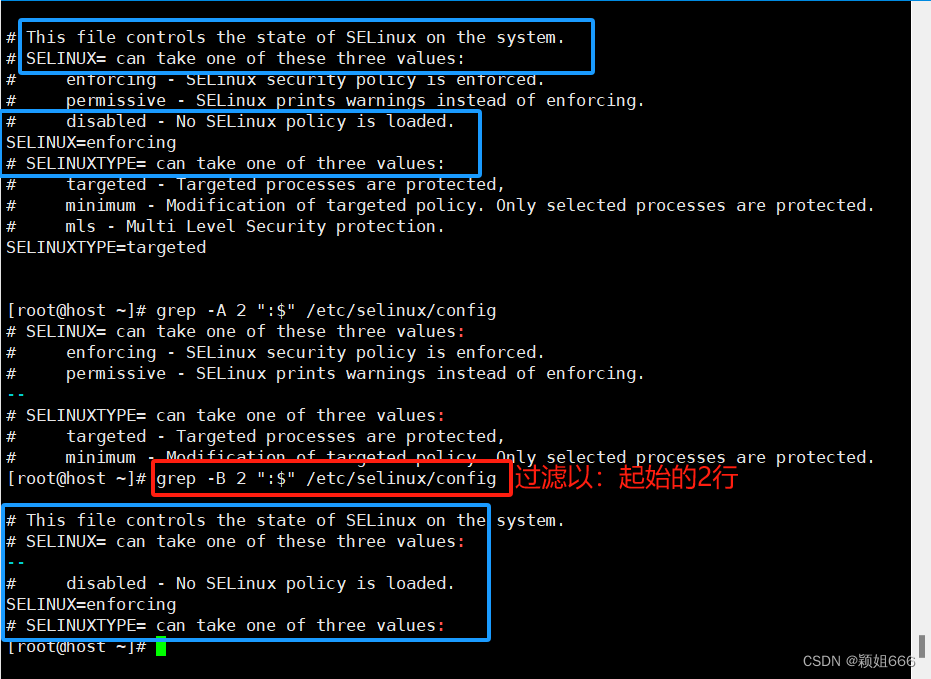
-A
打印出紧随匹配的行之后的下文NUM行。
在相邻的匹配组之间将会打印内容是 -- 的一行。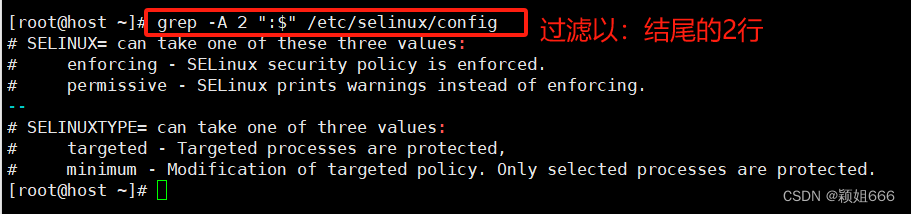
-c
显示匹配的<数据行>的<行总数>
2.2、正则表达式
1)bash通配符
Bash通配符是Bash Shell自带的
- 表示匹配任意的一个或多个字符
?表示匹配任意的一个字符
[] 表示匹配[xyx]列表中的任意的一个字符
2)基本正则元字符(常用)
^匹配:行首$匹配:行尾.匹配:任意单个字符*匹配:前一个字符出现0次或多次[]匹配:括号里的内容任意一字符 例: [a]、[b][-]匹配:括号范围中的任意一个字符 例:[0-9]、[a-Z][^]匹配:括号内以外的内容 例: [^0-9]、[^a-d]{}匹配:定义正则分组 例:(hello)(word){n]匹配:前一个字符出现的n次 例:go{1}d ==> good{n,}匹配:前一个字符最少出现n次 例:ab{2,}c ==>abbbc、abbbbc、abb...c{n,m}匹配:前一个字符最少出现n次,最多出现m次 例::ab{1,2}c ==>abbc、abbbc<或\b匹配:词首定位符 例:<he ==>开头为 he 后面任意的单词>或\b匹配:词尾定位符 例:od> ==> 结尾为 od 前任意的单词\s匹配:单个空白字符,包含:水平 垂直制表符 例:^\s ==>空白开头\t匹配:水平制表符(一个 tab 键的长度)\匹配:转义符,恢复元字符的原义 例:. ;
3)扩展正则元字符(常用)
多了?和+,(),个别不同与基本正则元字符,其他一样。
^匹配:行首$匹配:行尾.匹配:任意单个字符?匹配:前一个字符出现0次或1次+匹配:前一个字符出现1次或多次*匹配:前一个字符出现0次或多次[]匹配:括号里的内容任意一字符 例: [a]、[b][-]匹配:括号范围中的任意一个字符 例:[0-9]、[a-Z][^]匹配:括号内以外的内容 例: [^0-9]、^a-d匹配:定义正则分组 例:(hello)(word){n]匹配:前一个字符出现的n次 例:go{1}d ==> good{n,}匹配:前一个字符最少出现n次 例:ab{2,}c ==>abbbc、abbbbc、abb...c{n,m}匹配:前一个字符最少出现n次,最多出现m次 例::ab{1,2}c ==>abbc、abbbc<或\b匹配:词首定位符 例:<he ==>开头为 he 后面任意的单词>或\b匹配:词尾定位符 例:od> ==> 结尾为 od 前任意的单词\s匹配:单个空白字符,包含:水平 垂直制表符 例:^\s ==>空白开头
4)实用案例
1、打印过滤掉注释行和空白行后的内容
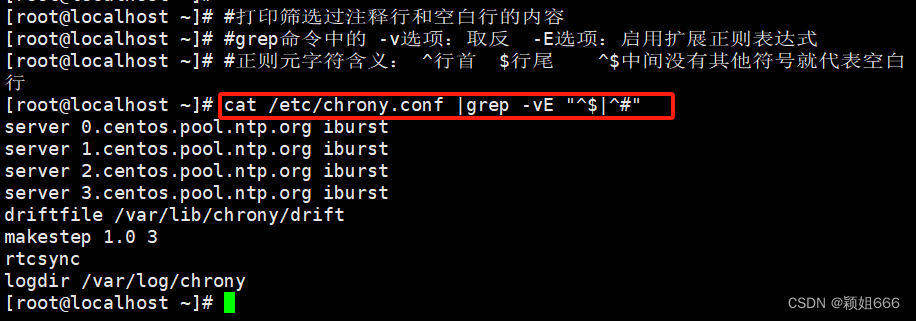
2、打印过滤出的IP地址
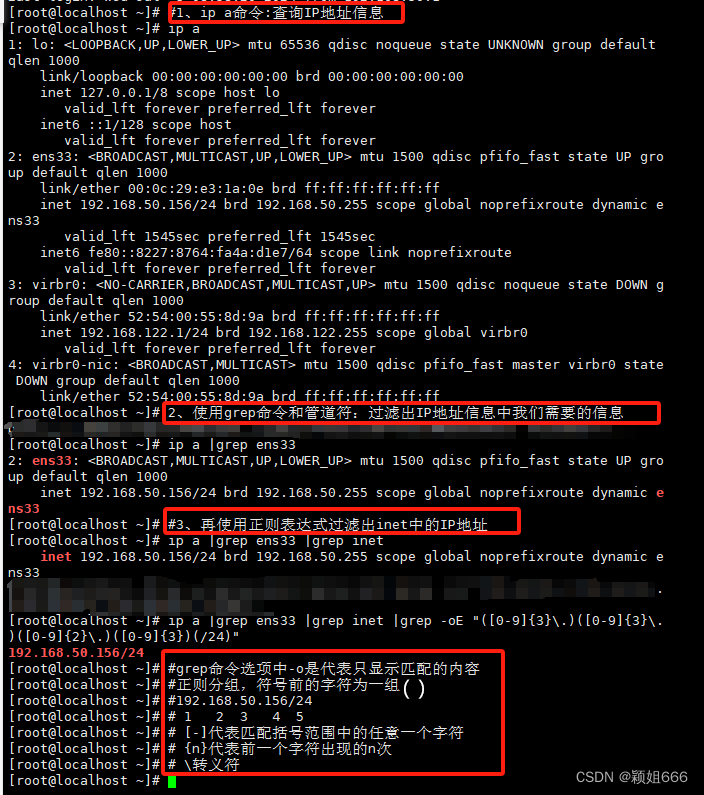
3、查看过滤出系统中所有uid大于等于1000的普通用户的信息

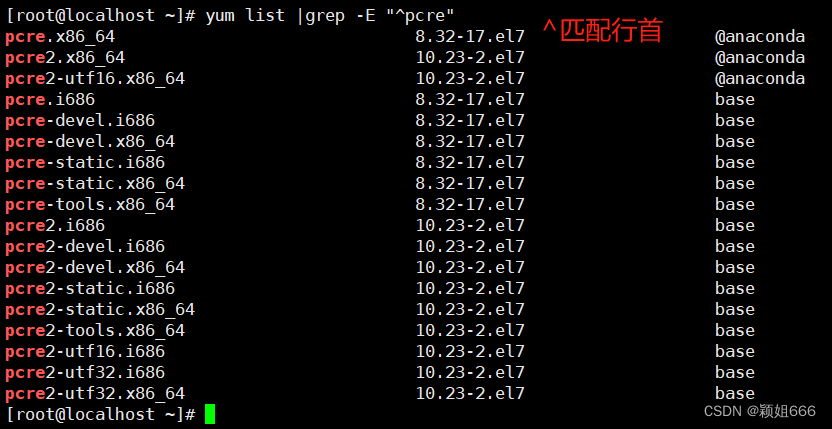
4、查找本地yum源中以pcre开头的软件包
-E代表启用扩展正则
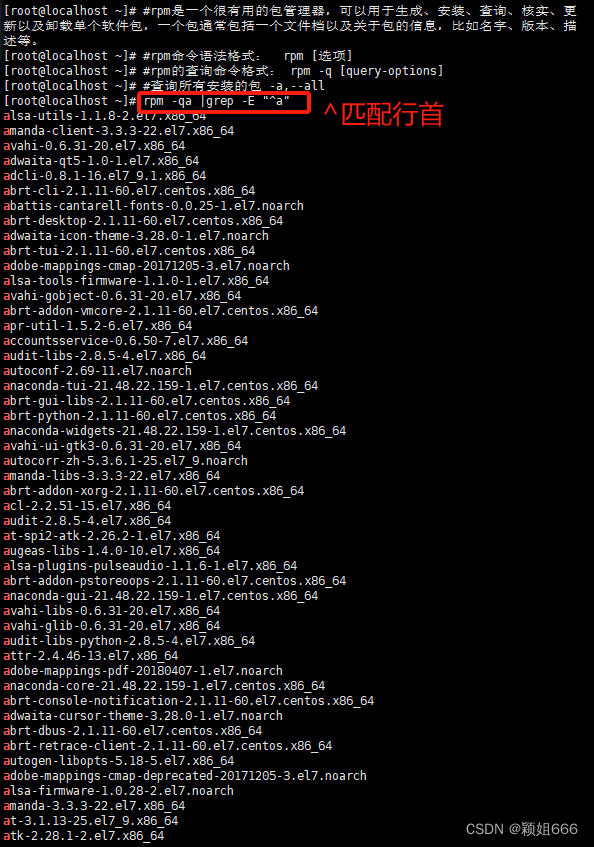
5、查找本机安装的所有以a开头的软件
-E代表启用扩展正则
6、查找安全日志secure中关于failed和error的失败和错误的信息

7、过滤出行首单词
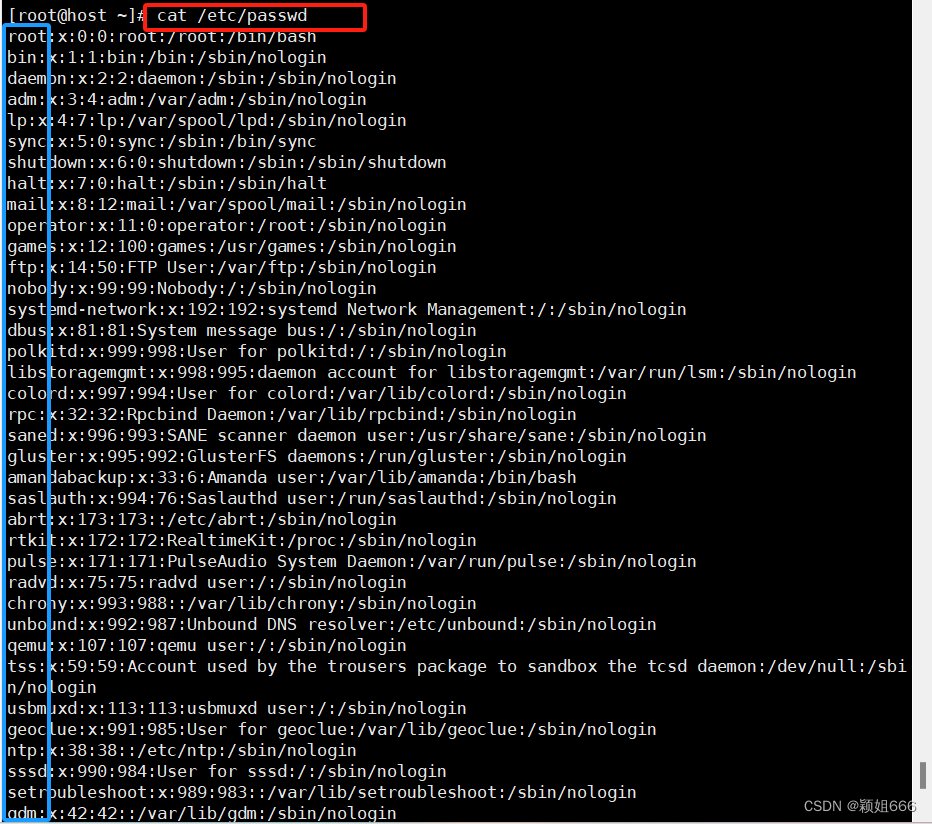
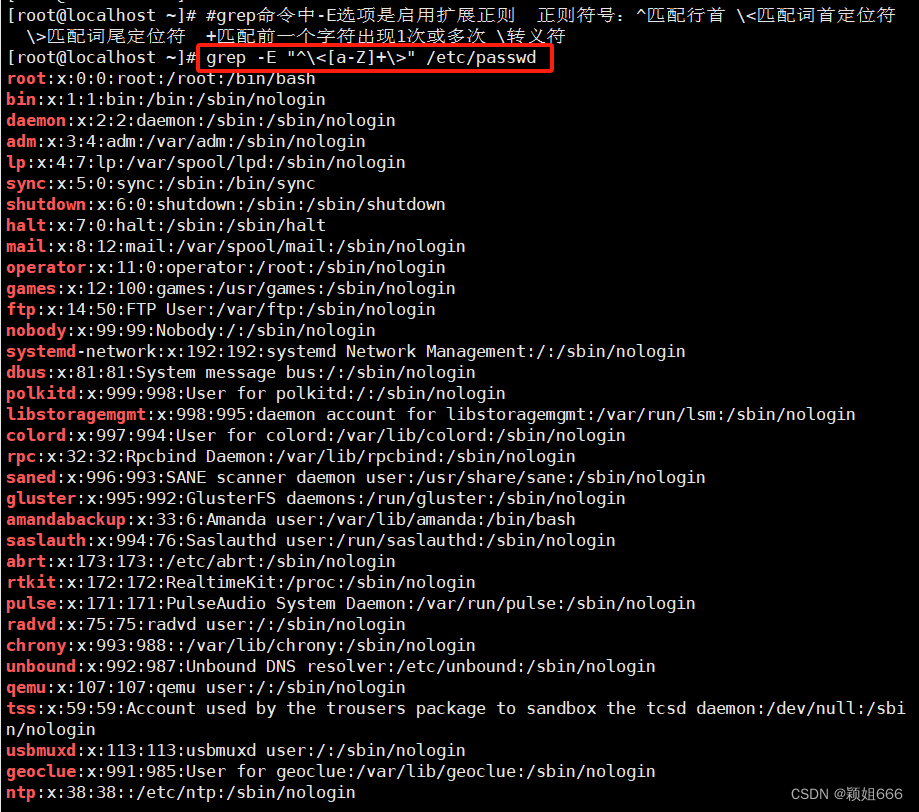
8、过滤出行尾单词
$匹配行尾
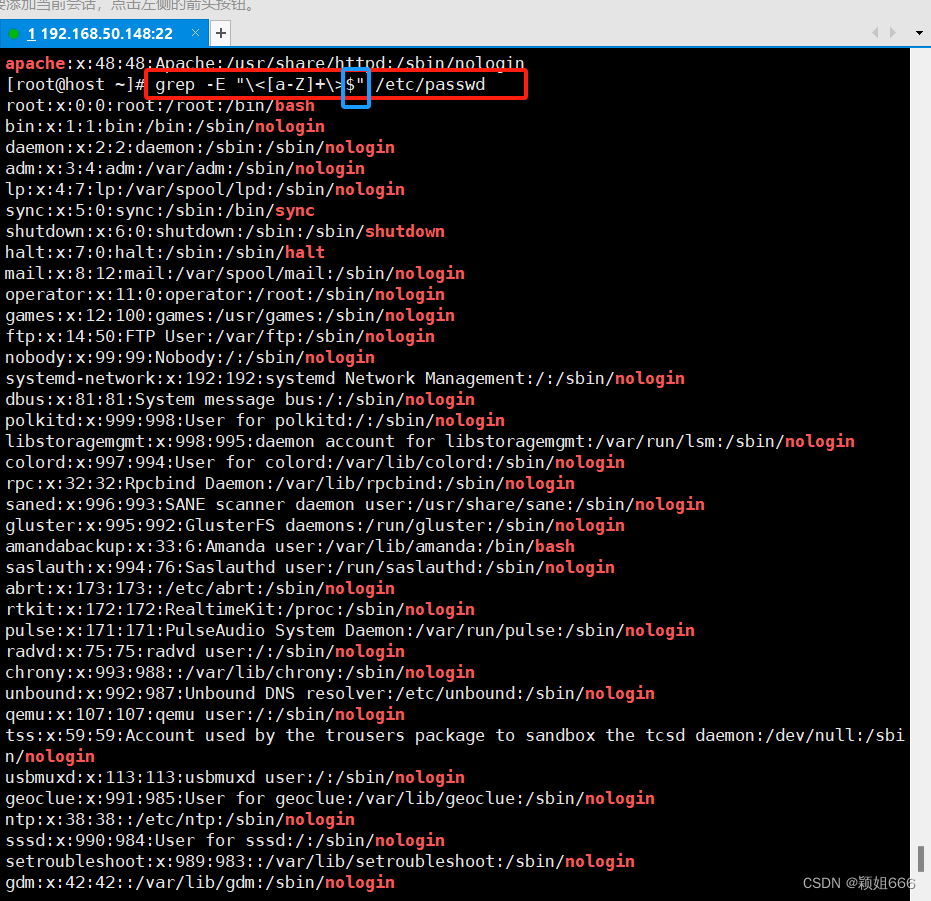
9、过滤任意个字符
一个点代表一个字符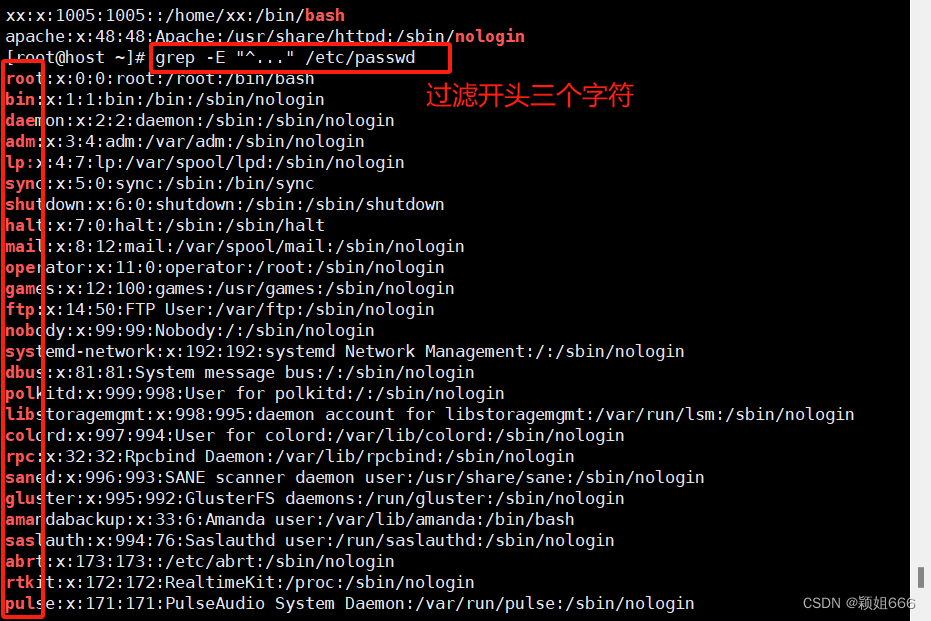
10、过滤磁盘空间
df -h命令:查看磁盘空间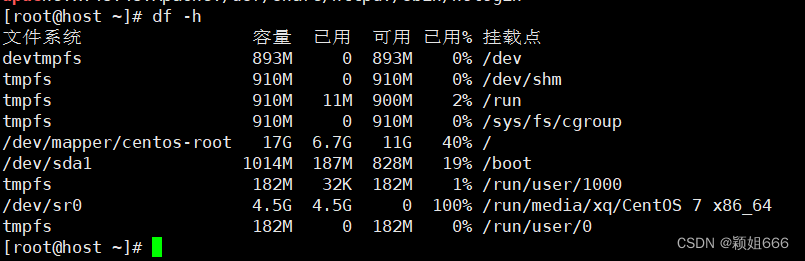
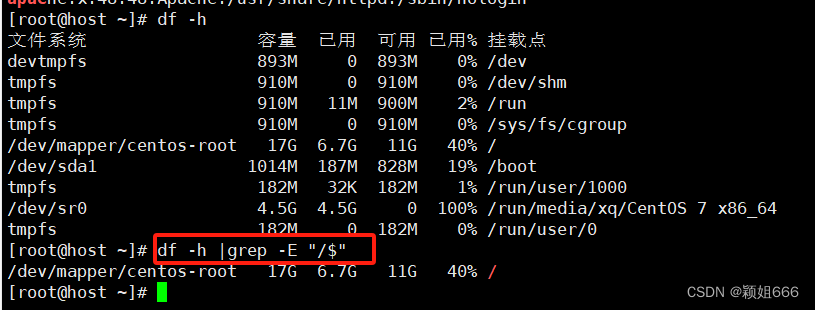
3、shell辅助命令
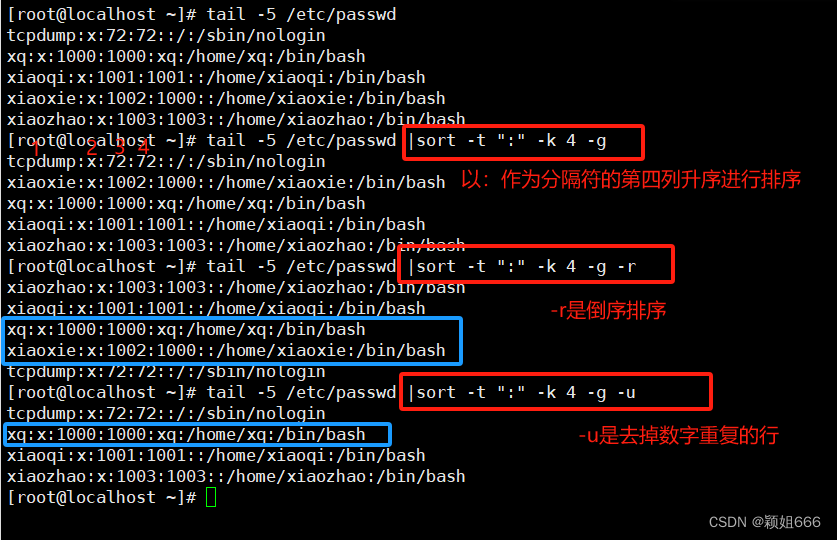
3.1、sort命令:排序
命令选项
-g
按照通常的数字值顺序排序,暗含-b
-n
按照字符串的数值顺序排序,暗含-b
-r
逆序/降序排序(没有-r默认是:升序)
-f
忽略<字母大小写>
-b
忽略排序字段或关键字中开头的空格
-t
指定分割符 一般和-k结合使用
-k
使用分隔符分隔的第几列
-u
去掉连续的重复行,
如果有-c,则按严格的顺序进行检查; 如果有-m,则只输出相等顺序的第一个.
-o
将<排序结果>回写入<原文件>,例如:cat 1.text
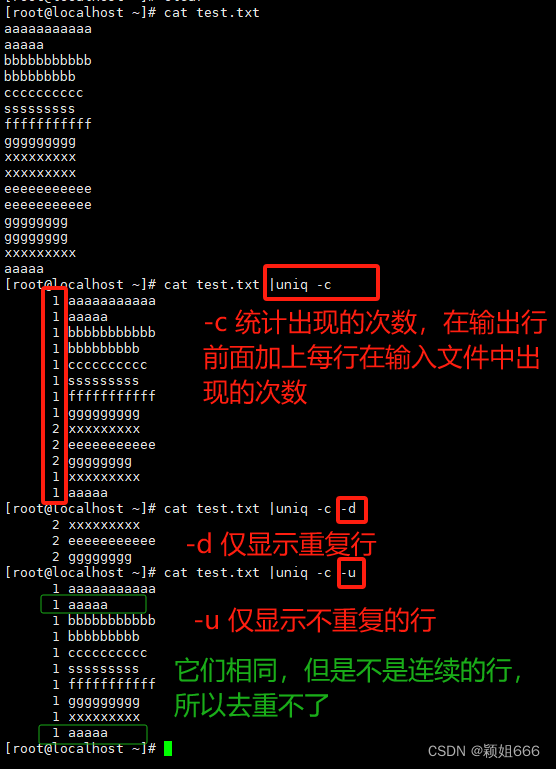
3.2、uniq命令:去重
1)作用
unip命令删除文件中的重复行。
unip命令读取由InFile参数指定的标准输入或文件。该命令首先比较相邻的行,然后除去第二行和该行的后续副本。
2)命令选项
-c统计,在输出行前面加上每行在输入文件中出现的次数。-d 仅显示重复行。-u
仅显示不重复的行。
注意:只能对连续的行去重,因此去重前一般需要先排序。
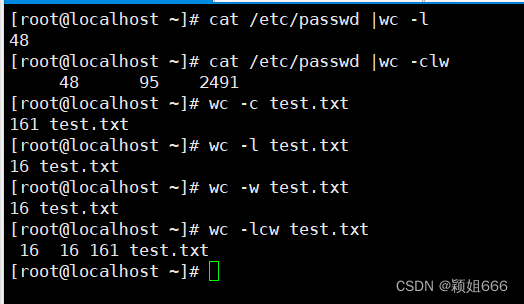
3.3、wc命令:统计
wc命令在Linux基础命令中也有过详细介绍。
1)作用
统计指定文件中的字节数、字数、行数,并将统计结果显示输出。
2)命令选项
-c统计字节数。-l统计行数。-w 统计字数,单词数。
举例:
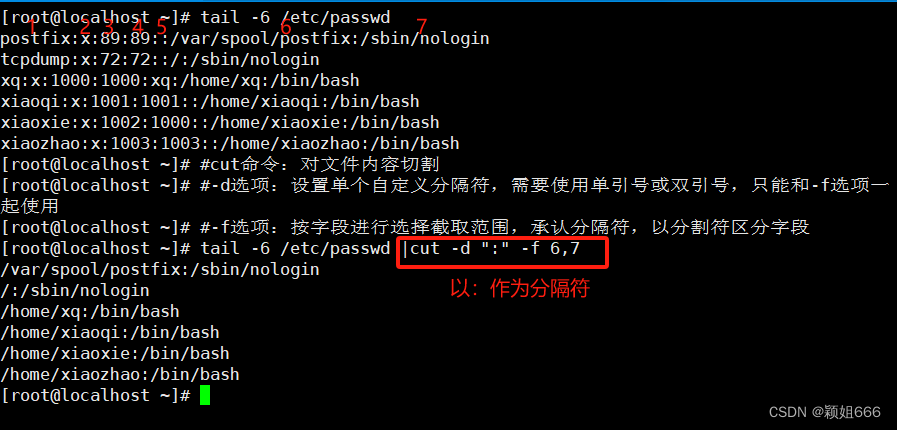
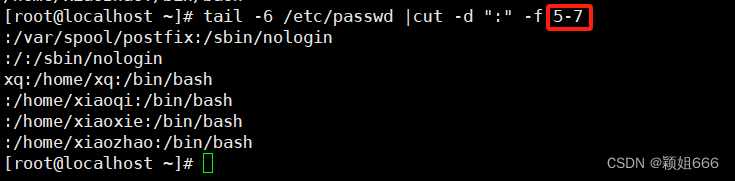
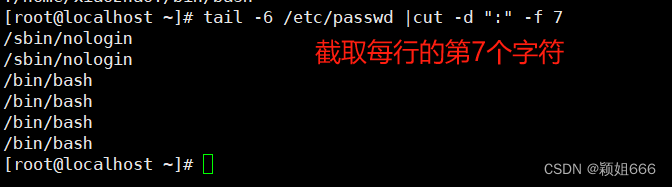
3.4、cut命令:对文件切割
1)功能
将每个文件中每一行的匹配部分(按指定规则截取)打印到标准输出。
2)语法
cut OPTION... [FILE]...
3)常用选项


扩展:top命令:查看系统信息
3.5、tr命令:替换命令
1)功能
tr 命令可以对来自标准输入的字符进行替换、压缩和删除。
2)语法
tr [选项] 字符集1 字符集2
字符集1:指定要转换或者删除的原字符集.。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”。
3)常用选项
-s替换连续出现的字符-d删除字符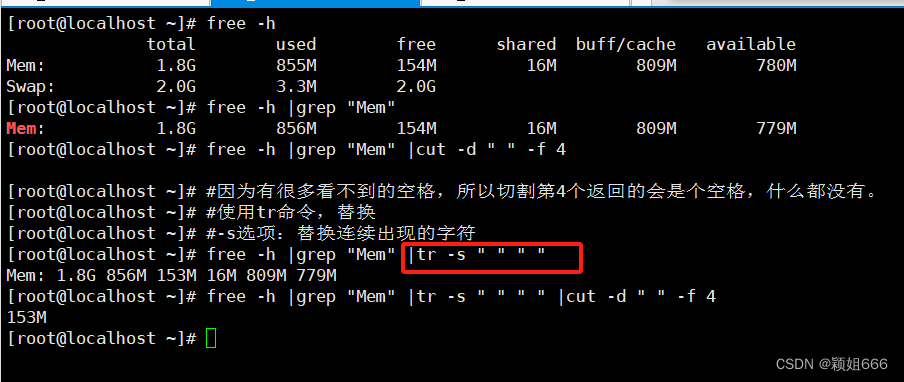

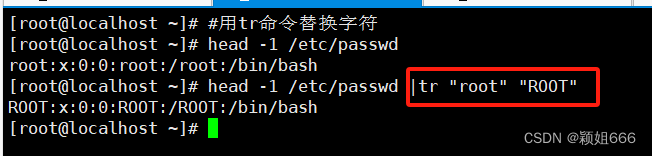
3.6、tee命令:类似于重定向
1)功能
把 标准输入 的 数据 复制到 每一个 文件 FILE, 同时 送往 标准输出。
2)语法
tee【OFFION】... 【FILE】...
3)常用选项
-a,--append 内容追加到给定的文件,而非覆盖
与重定向的区别: 重定向命令执行后不会在终端上显示内容信息, 而tee命令执行后会在终端上显示内容信息
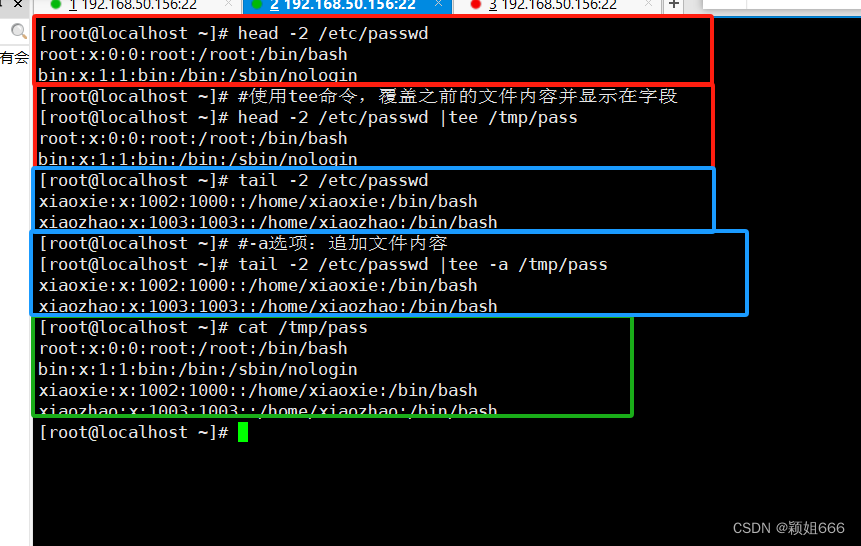
3.7、watch命令:监控输出结果
1)功能
watch命令可以实时全屏监控当前命令执行的动态变化结果。
2)语法
watch [options] comman
3)常用选项
-n每隔几秒刷新一次结果(默认是每隔2秒刷新一次)-d高亮显示命令执行结果的变化-t隐藏全屏顶端的时间间隔,命令信息
查看文件有没有在变化


3.8、sleep命令
1)功能
暂停一段时间,时间单位可以是s m h d,默认是s(秒)
2)举例
sleep 10s
3.9、wait命令
1)功能
wait命令是用来阻塞当前进程的执行,直到当前进程的指定子进程或者当前进程的所有子进程返回状态为0,执行结束之后,方才继续执行。
使用wait命令可以在bash脚本的多进程执行模式下,起到一些特殊控制的作用。
2)举例

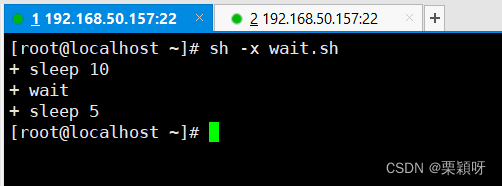
3.10、read命令
1)功能
用于脚本与用户的交互,可以将用户输入的值存入变量。
2)常用选项
-p设置提示信息-e用户输入的时候允许回退-s不显示输入的内容(密码输入的时候使用)-ttimeout设置超时时限,单位:秒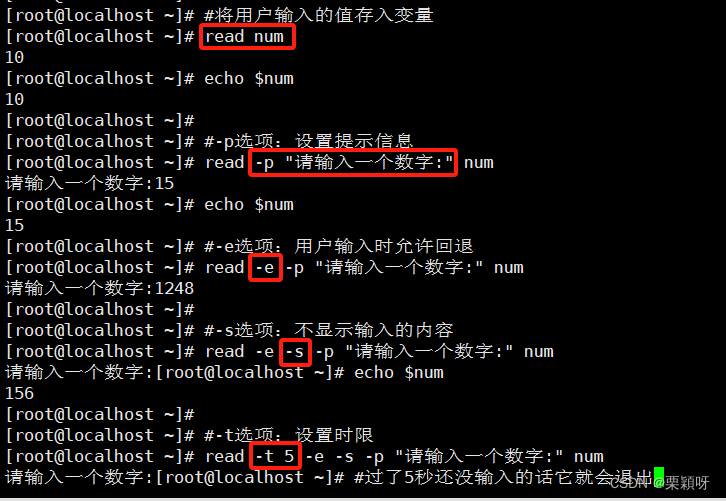
举例
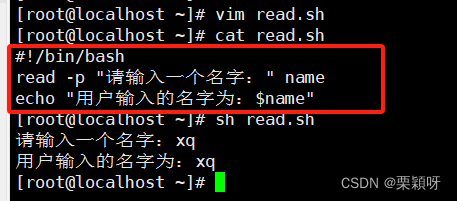
3.11、timeout命令
1)功能
控制命令的执行时长
2)语法
timeout [OPTION] N[s|m|d] command [参数]...
N[s|m|d] 设置命令的执行时长为N,默认单位为s秒,还可以是m分钟、h小时、d天
3)常用选项
-s,--signal=SIGNAL
TERM/15
SIGKILL/9
设置终止命令进程的信号名,默认为TERM信号
优雅的终止命令的进程(留有时间,非立即,非强制)
强制的终止命令进程(不留时间,立即执行,只能由管理员发出)
-k,--lill-after =N 设置当第一个终止信号发出N时长之后,如果命令进程仍在运行,则执行SIGKILL强制终止。
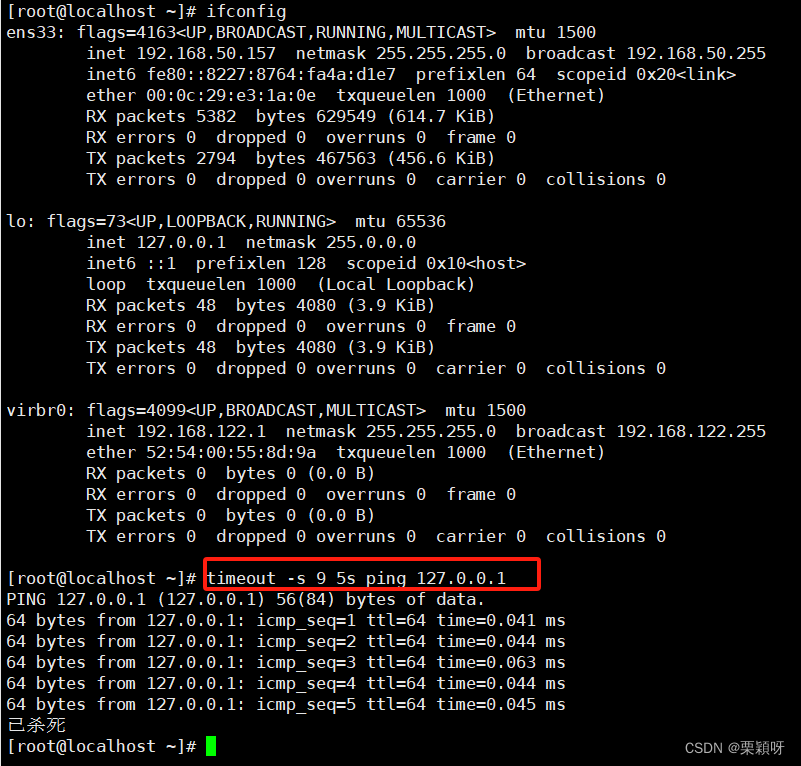
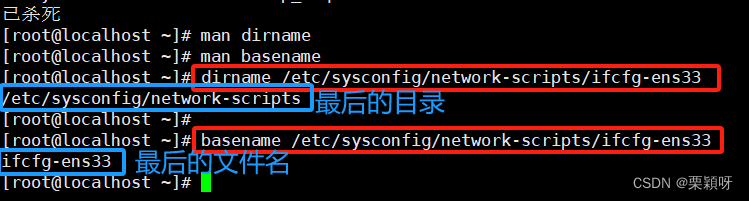
3.12、dirname命令
1)功能
指令去除文件名中的非目录部分,删除最后一个“\”后面的路径,显示父目录。dirname返回文件所在目录路径,而basename则相反,去掉路径返回最后的文件名。
2)语法
dirname [选项] 参数
3.13、basename命令
1)功能
指令用于打印文件的基本名称,显示最后的文件名。
2)语法
basename [选项] 参数
三、Shell流程控制语句
1、shell的算数计算方法
1.1、算数运算符
1)基础运算符
**加:+**减:-*乘:**除:/
2)shell脚本常用的运算符
&:取余自增自减
id ++,id-- #变量后增量,变量后减量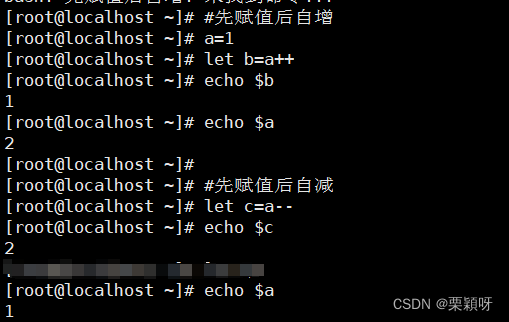 自增自减
自增自减
++id,--id #变量预增量,变量预减量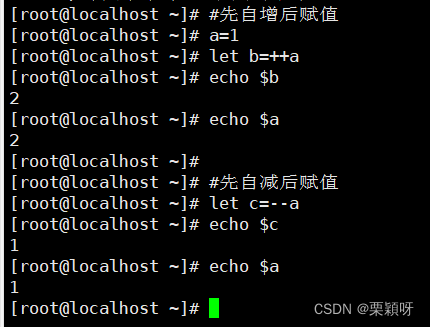
1.2、整数计算
let命令变量赋值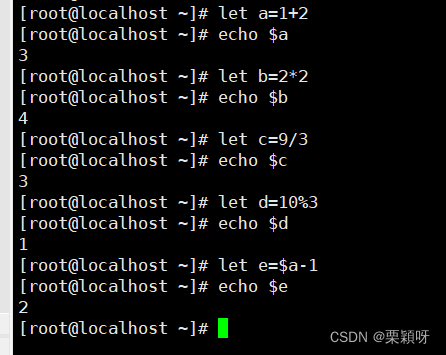 expr命令
expr命令
expr命令也支持算术运算功能,虽然它的功能不止于此,但是此处我们只使用它进行算术运算,expr命令与let命令相似,也只能进行整数运算。
使用expr命令进行算术运算时,需要注意以下两点:
- 数值与运算符之间需要用空格隔开,否者无法进行算术运算。
- 使用expr命令进行乘法运算时,需要将“乘号”转义,否则会报错。
 使用算数语法$((算数表达式))
使用算数语法$((算数表达式))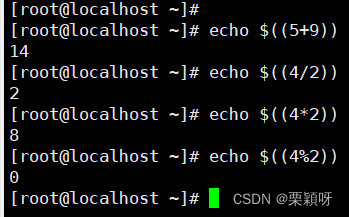 使用算数语法$[算数表达式]
使用算数语法$[算数表达式]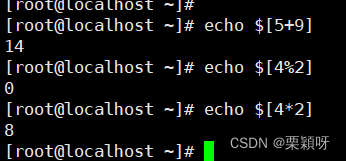
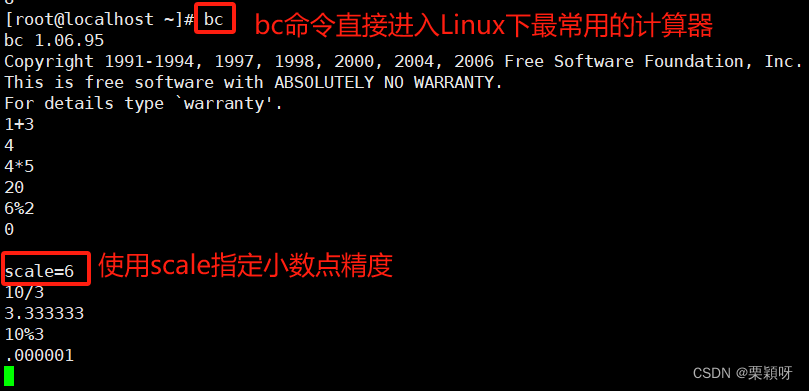
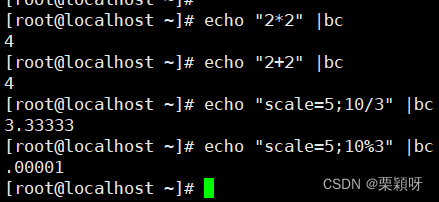
1.3、bc命令:小数计算
bc命令是linux下最常用的“计算器”,我们可以借助bc命令进行算术运算,使用这种方法的优势就是支持小数运算。
注意:在使用“除法”时,需要指定小数点精度,否则运算结果中不会包含小数,使用scale指定小数点精度。
安装bc(最小安装时不会安装)
yum install -y bc
交互式bc命令
非交互式bc命令
2、shell的条件判断使用方法
test命令:用于判断表达式是否成立,成立返回0,不成立则返回其他数字。
格式1:test条件表达式
格式2:[ 条件表达式 ](记住左右都要有空格)
1)文件判断
格式:[ 操作符 文件或目录 ]
常用的测试操作符
常用的测试操作符说明举例-d用于测试是否是目录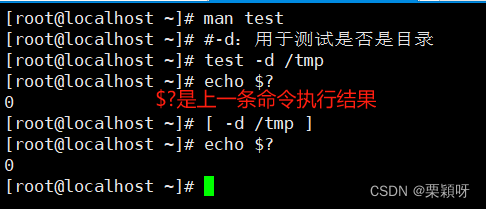 -e测试目录或文件是否存在
-e测试目录或文件是否存在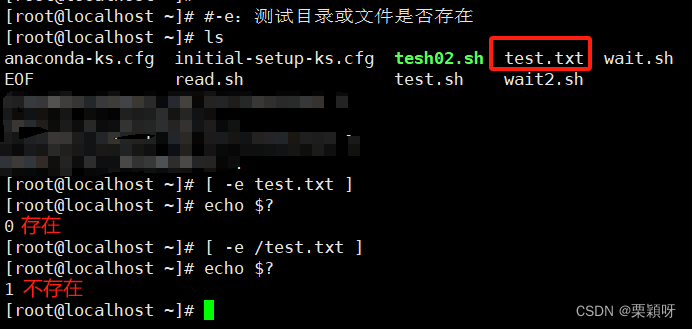 -f测试文件是否存在且为普通文件
-f测试文件是否存在且为普通文件 -r测试当前的用户是否有读的权限
-r测试当前的用户是否有读的权限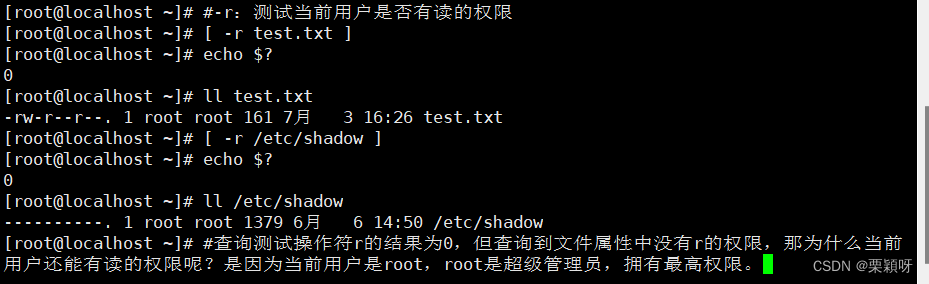 -w测试当前的用户是否有写的权限
-w测试当前的用户是否有写的权限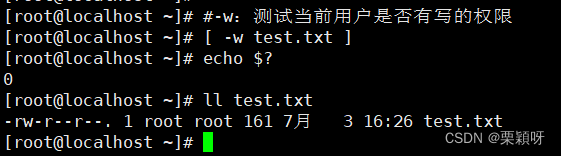 -x测试当前的用户是否具有可执行的权限
-x测试当前的用户是否具有可执行的权限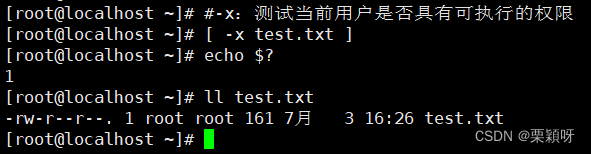 -L测试是否为链接文件[ -L 文件或目录 ]-b测试是否为块设备文件[ -b 文件或目录 ]-c测试是否为字符型特殊文件[ -c 文件或目录 ]
-L测试是否为链接文件[ -L 文件或目录 ]-b测试是否为块设备文件[ -b 文件或目录 ]-c测试是否为字符型特殊文件[ -c 文件或目录 ]
有关什么是块设备文件和字符型特殊文件,请看此博主的文章有解释到。关于字符设备文件和块设备文件的区别_块设备文件和字符设备文件-CSDN博客
2)判断数值大小
格式1:test条件表达式
格式2:[ 整数1 操作符 整数2 ]
常用的测试操作符
-eq等于=-ne不等于-gt大于>-lt小于<-le
小于等于<=
-ge大于等于>=
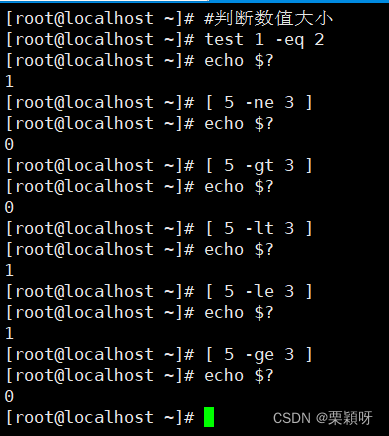
3)判断字符串
格式:【 字符串1 操作符 字符串2】 或者 :【 操作符 字符串 】
常用的测试操作符
-z STRING
#判断:字符串是否为空
不为空返回1,
为空返回0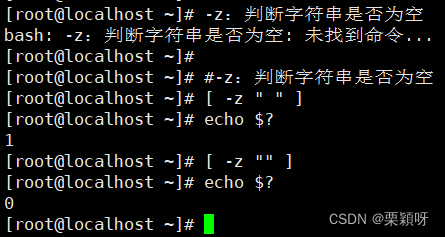 -n STRING
-n STRING
#判断:字符串是否为非空
不为空返回0,
为空返回1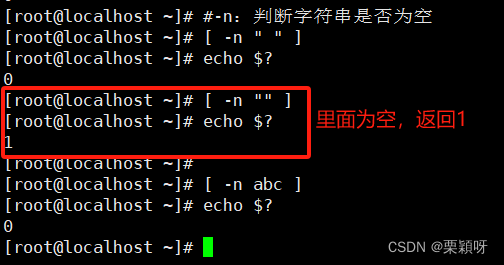 STRING1 = STRING2#判断:两个字符串内容是否相同
STRING1 = STRING2#判断:两个字符串内容是否相同 STRING1 ! = STRING2#判断:两个字符串内容是否不同
STRING1 ! = STRING2#判断:两个字符串内容是否不同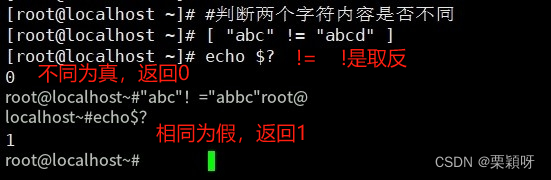
4)逻辑操作(多条件判断)和命令连接符(;号和 && 和 || )
格式:[ 条件表达式1 逻辑操作符 条件表达式2 ] 或者 :[ 逻辑操作符 条件表达式 ]
常用的测试操作符
!EXPR#执行:逻辑取反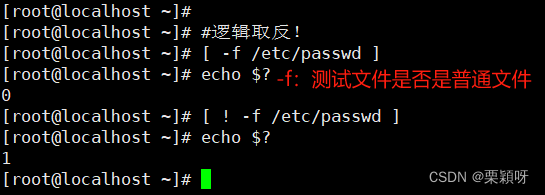 EXPR1 -a EXPR2#执行:逻辑取与
EXPR1 -a EXPR2#执行:逻辑取与 EXPR1 -o EXPR2#执行:逻辑取或
EXPR1 -o EXPR2#执行:逻辑取或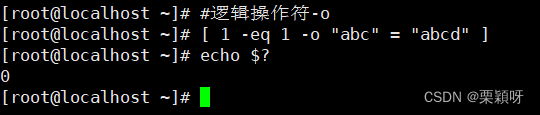
a和o不支持多条件判断,会报错
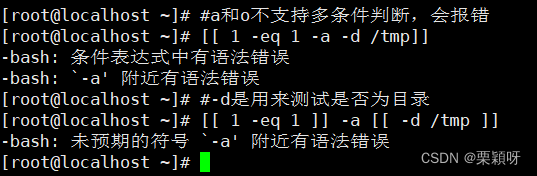
解决方法: && || 逻辑与和逻辑或的多条件写法
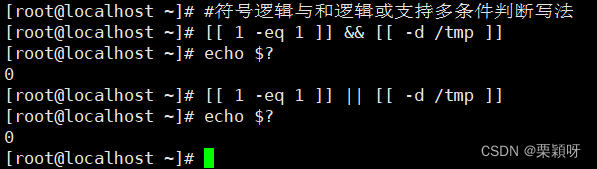
命令连接符(;号和 && 和 || )
用于连接多条命令,并通过前面命令的执行结果,判断后面命令的执行



ifdown 停止网卡
ifup 启动网卡



ls &> /dev/null ,返回结果我们什么内容都看不到。
ls &> /dev/null 是在类似于Unix 操作系统中使用的一个命令,用于列出目录内容,但将标准输出(stdout)和标准错误(stderr)都重定向到 /dev/null,从而有效地丢弃任何输出。
ls:列出当前目录中的文件和目录。
&>:同时重定向标准输出(stdout)和标准错误(stderr)。
/dev/null:一个特殊的文件,所有写入它的数据都会被丢弃,通常用于抑制输出。相当于Linux的一个黑洞,黑洞文件什么都可以往里面丢,不占存储空间,你看不到它的一个内容。
当你运行 ls &> /dev/null 时,ls 命令的输出(包括任何错误消息)都会被发送到 /dev/null,不会在终端上显示。这在你希望执行某个命令但不想看到其输出或错误消息时非常有用。
3、shell的流程控制语句
3.1、if语句
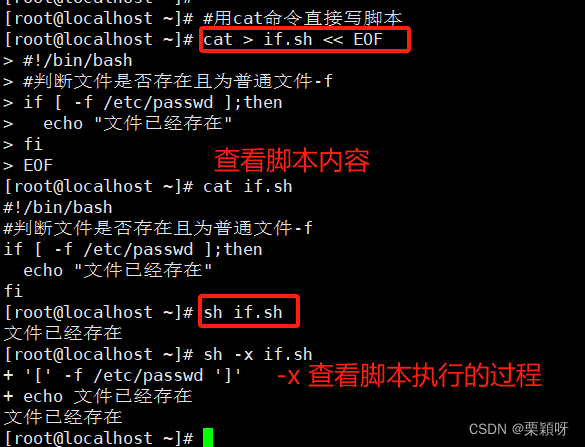
1)单分支语句
概念
单分支if条件语句最为简单,就只有 一个判断条件,如果符合条件则执行某个程序,否则什么事情都不做。
语法格式

举例

2)双分支语句
概念
在双分支if条件语句中,当条件判断式成立时,则执行某个命令块;当条件判断式不成立时,则执行另一个命令块。
语法格式

举例

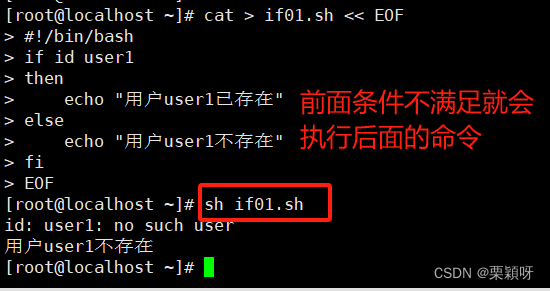
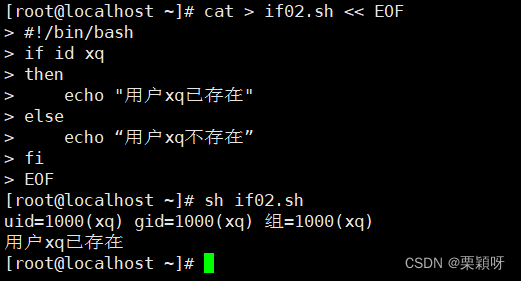
如果不想看到id xq查询用户信息的命令,我们可以把它直接丢进黑洞里面
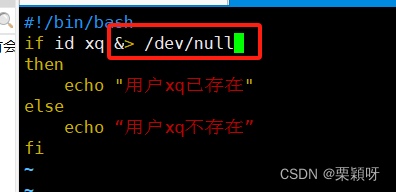
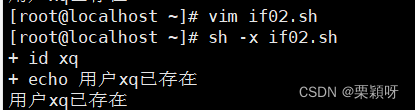
灵活设置,随意查看任何用户是否存在
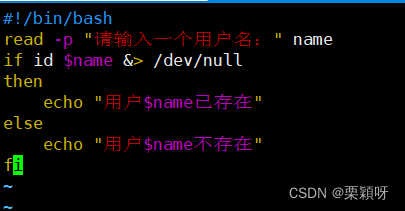
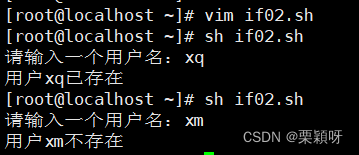
3)多分支语句
概念
在多分支if条件语句中,允许执行多次判断。也就是当条件判断式1成立时,执行命令块1;当条件判断式2成立时,执行命令块2;依次类推,当所有条件不成立时,执行最后的程序。
语法格式

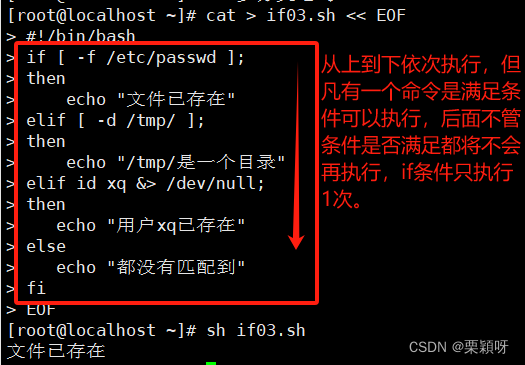
案例
判断分数
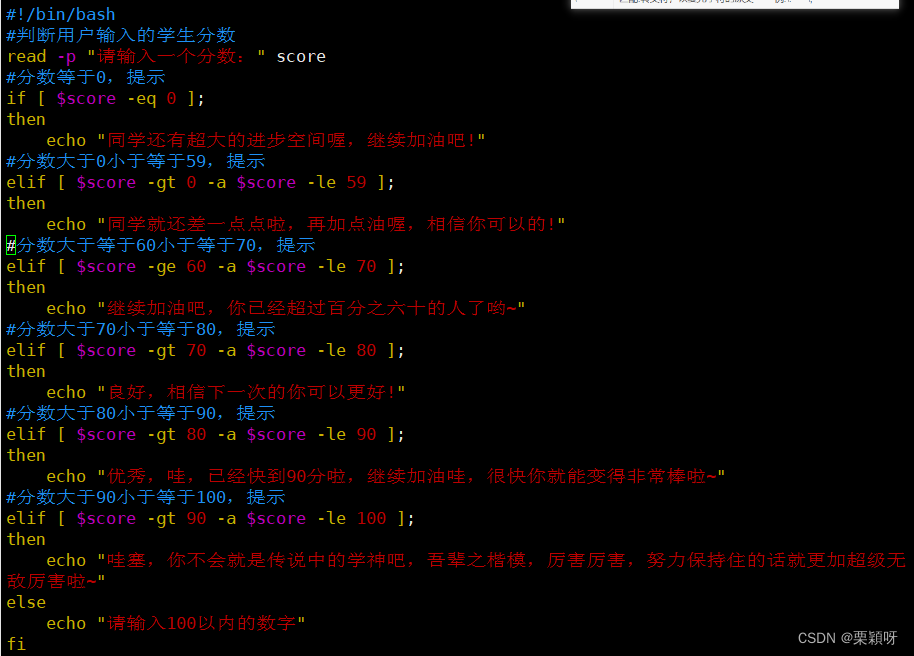
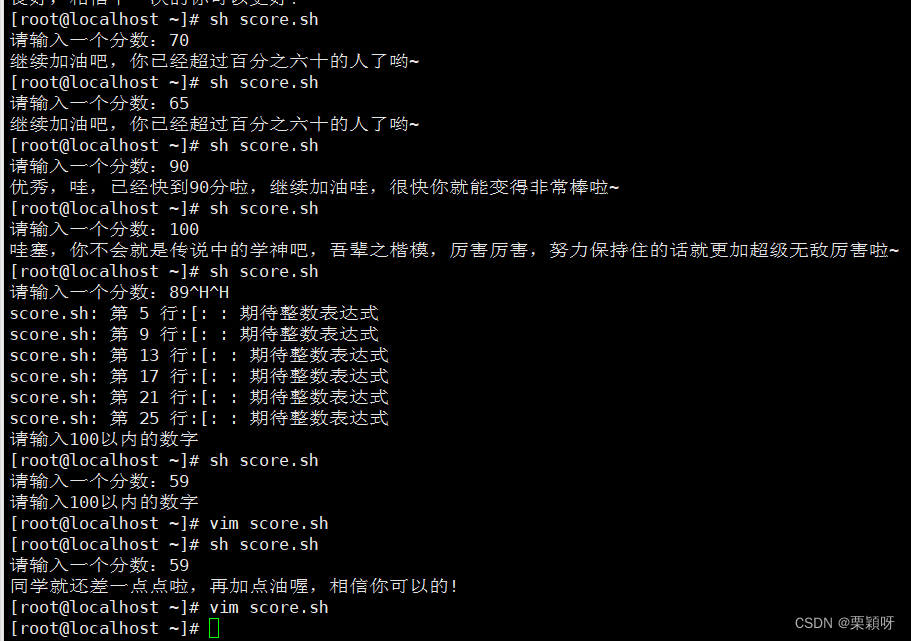
执行脚本
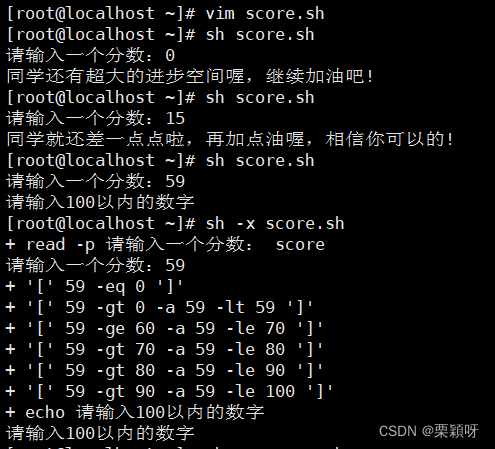
如果脚本命令有什么地方写错了,我们检查命令,就用sh -x 来检查脚本执行过程
3.2、case语句
1)概念
case语句主要适用于某个变量存在多种取值,需要对其中的每一种取值分别执行不同的命令序列的情况(写脚本服务/工具箱)。它和if语句十分相似,只不过if语句是需要判断多个不同的条件,而case语句只是判断一个变量的不同取值。
2)工作流程
首先使用“变量值”与模式1进行比较,若取得相同则执行模式1后的命令序列,直到遇到双分号“;;”后调至esac,表示结束分支。
若与模式1不匹配,则继续与模式2进行比较,若取值相同则执行模式2后的命令序列,直到遇到双分号“;;”后调至esac,表示结束分支。
后面的以此类推.......
若找不到任何匹配的值,则执行默认模式“*)”后的命令序列,直到遇到esac后结束分支。
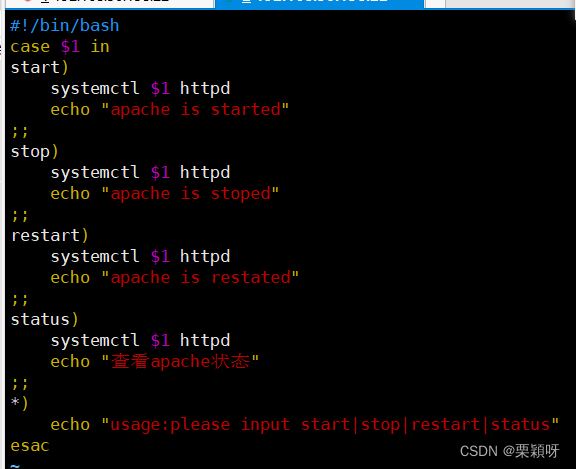
3)语法格式

案例
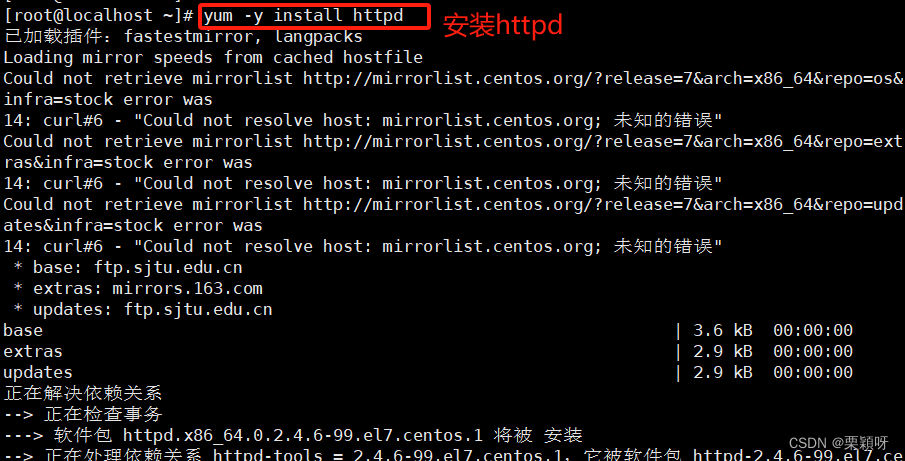
因为我们后面要用到httpd所以先进行安装
访问apache网站
安装httpd
查看安装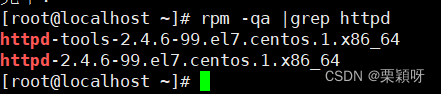
脚本编写
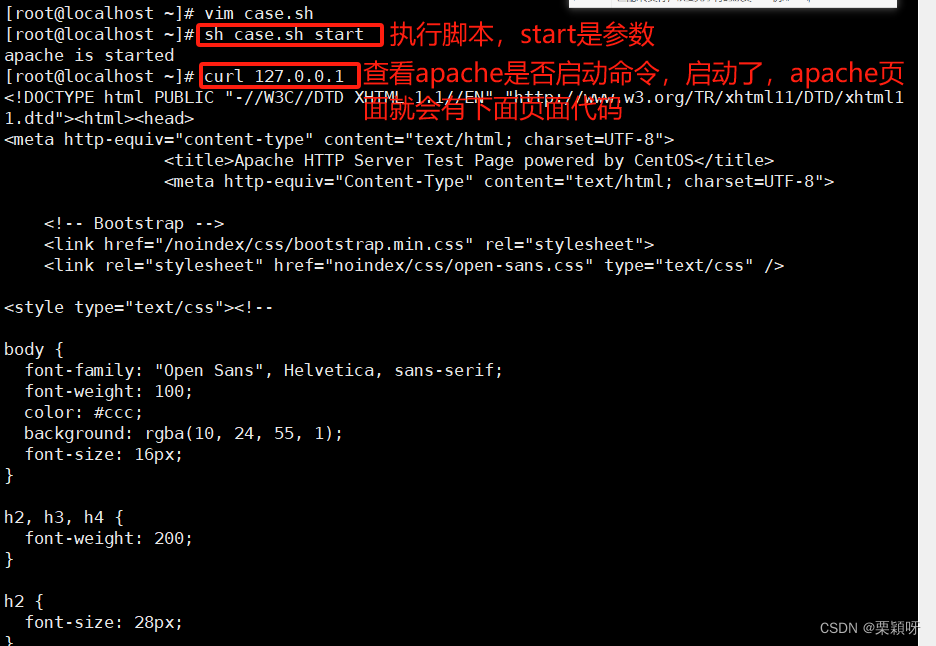
查看apache网址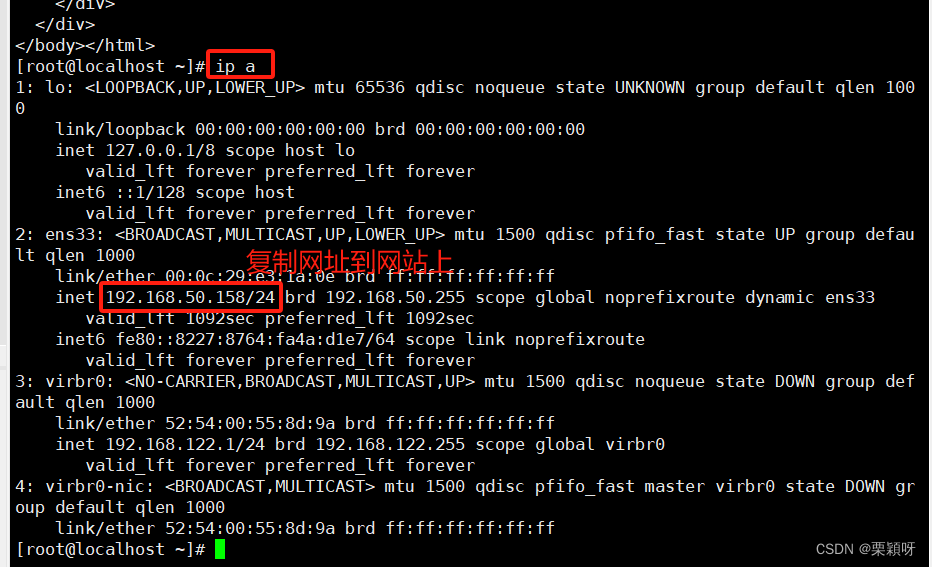
网页访问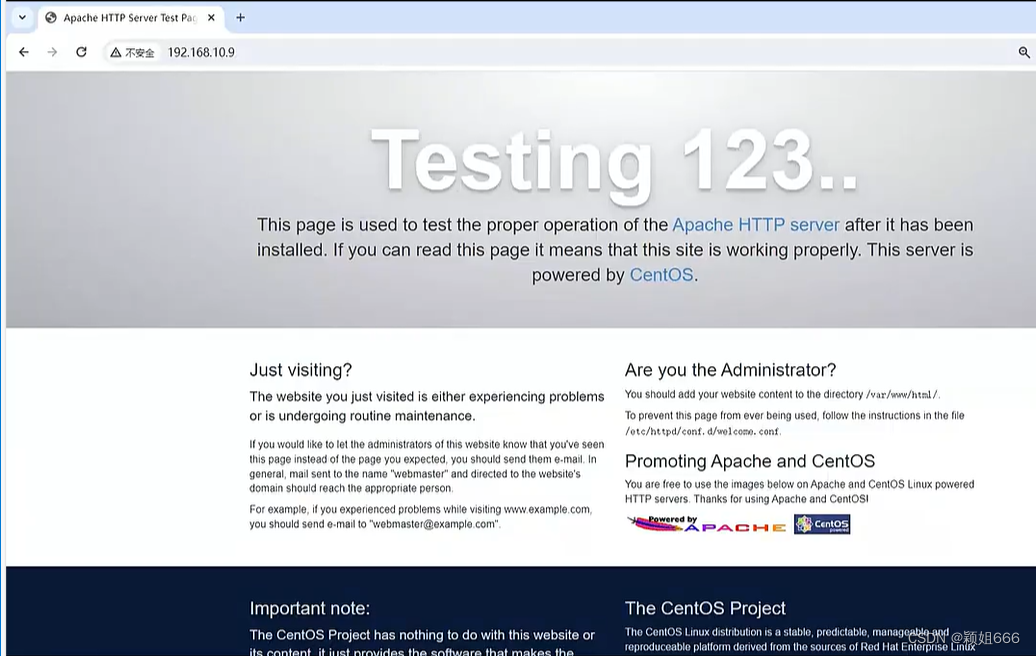
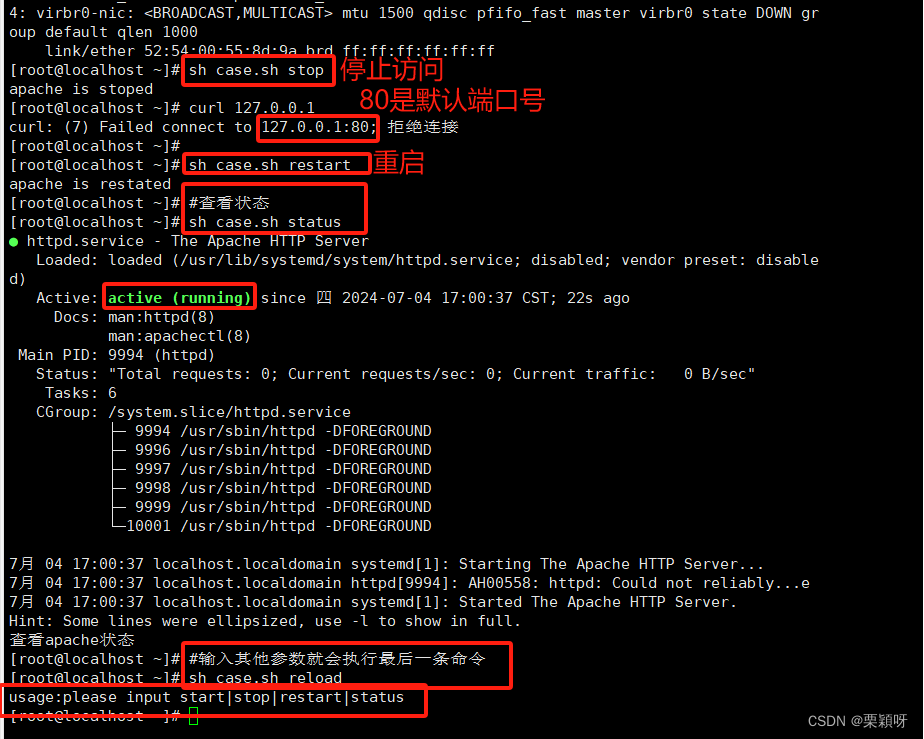
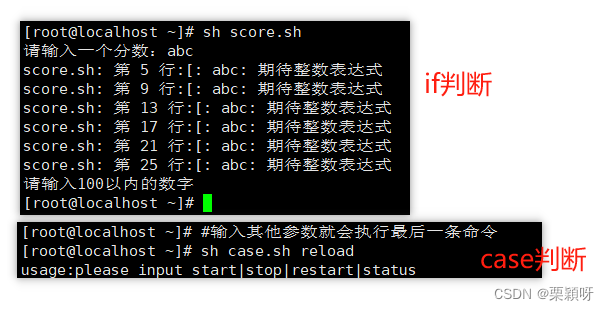
3.3、if和case的区别
if和case的比较 :
case比较好用,if判断有个缺陷。
如果if参数输入都不匹配的就会报错,除非你把那种结果的判断加入进去了,要不然就是会报错,而case中参数输入都不匹配就是只会执行最后一条命令,因为case的*,表示任意。
四、Shell循环语句
1、shell循环语句
1.1、for循环语句
1)流程图
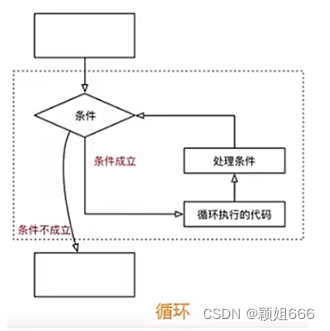
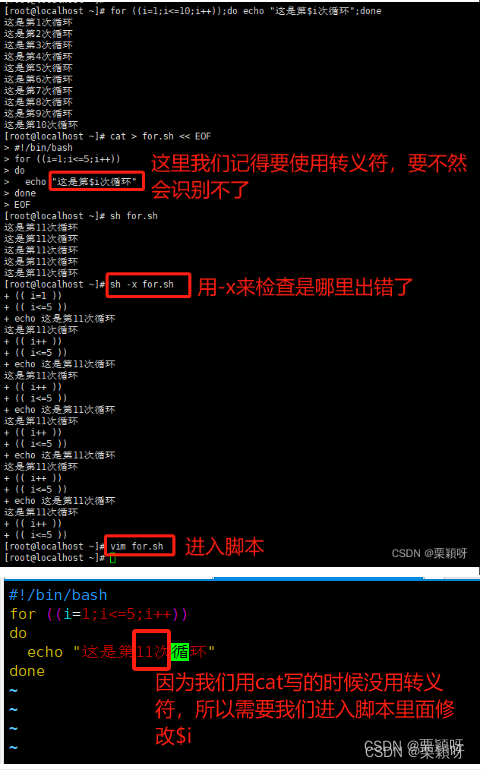
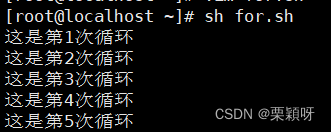
2)语法格式
格式一:
算数条件判断for循环(c风格)
()形式

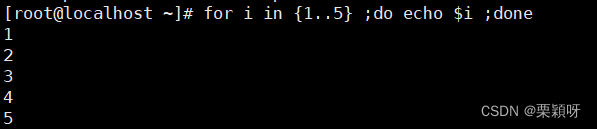
格式二:
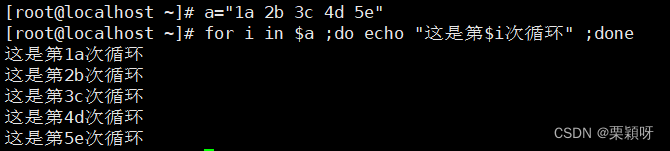
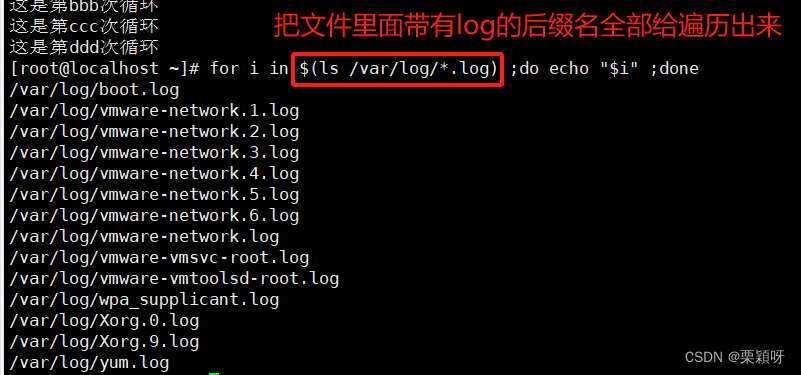
遍历单词序列for循环
for i in


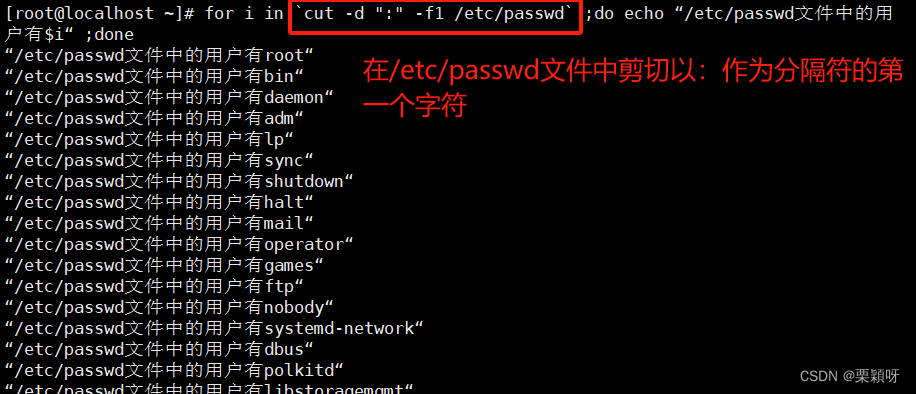
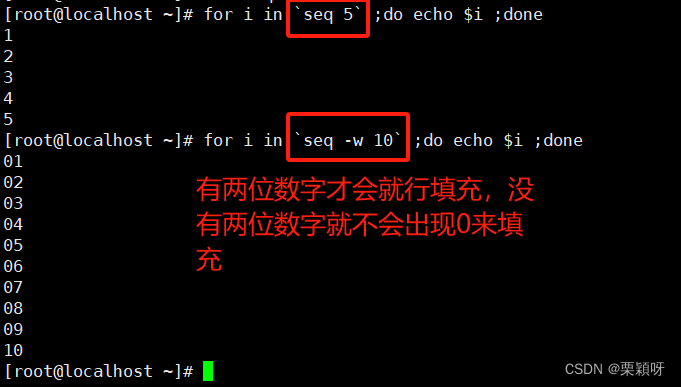
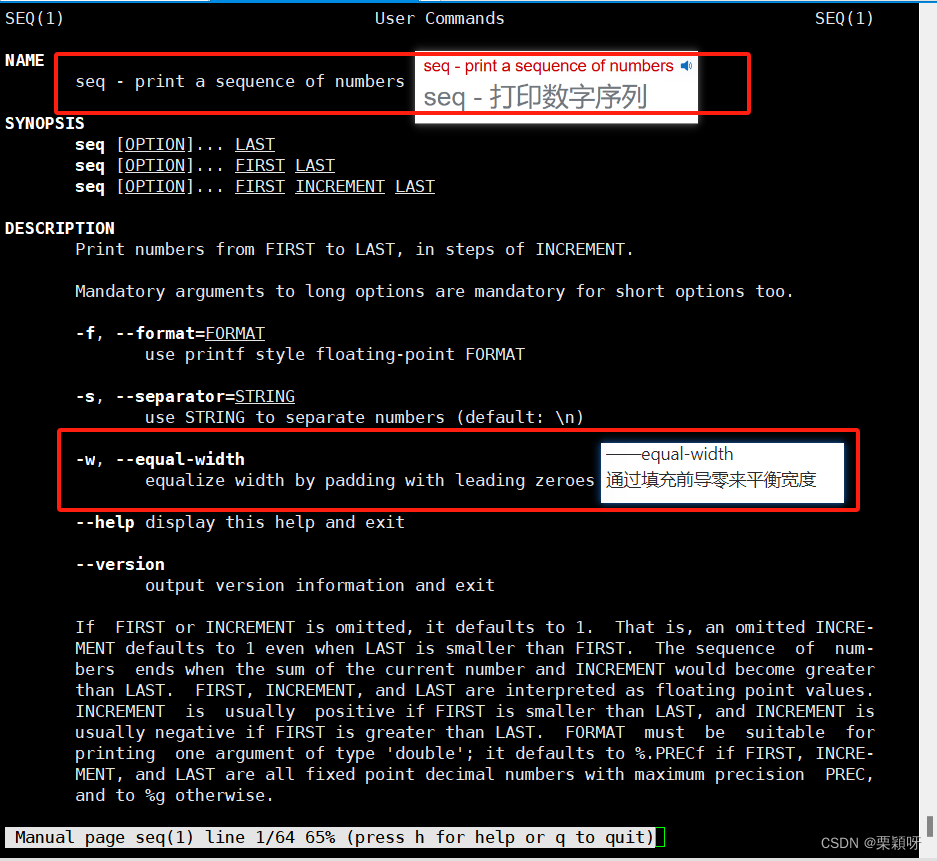
 有不知道命令是什么作用的就查man手册。
有不知道命令是什么作用的就查man手册。
小应用:批量创建用户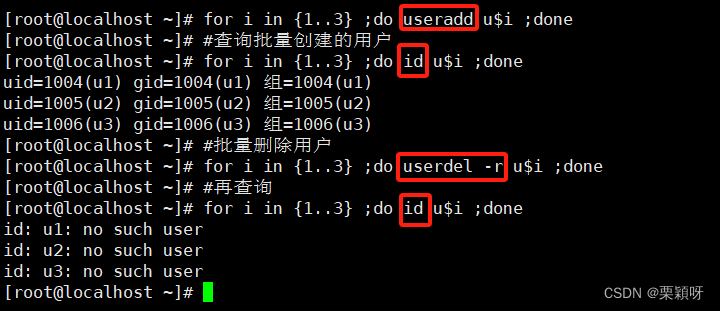
变形语句举例:


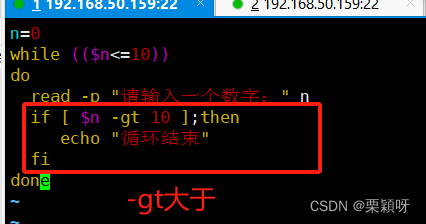
1.2、while循环语句
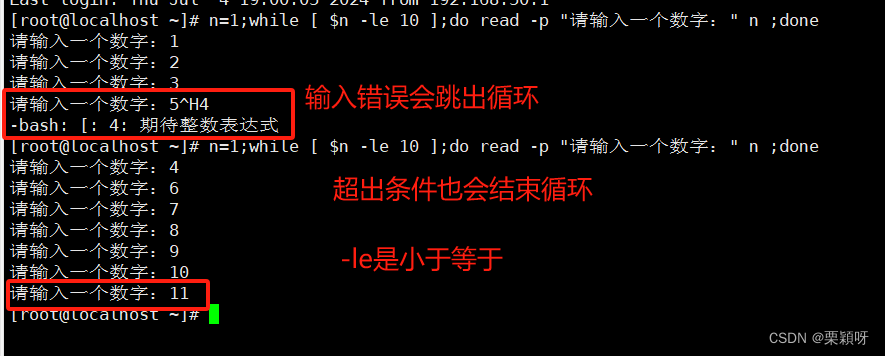
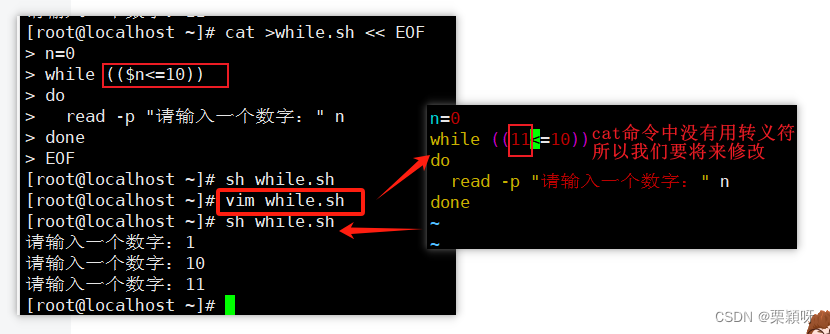
重复测试某个条件,主动条件成立则反复执行,相对于for,需要知道循环次数;
如果我们只知道停止条件,不知道次数,就需要使用while,直到循环条件不满足。
语法格式

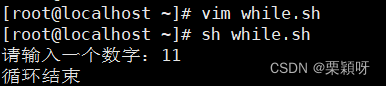
举例
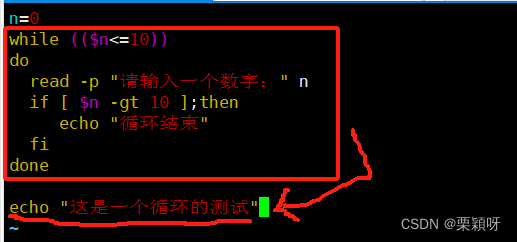
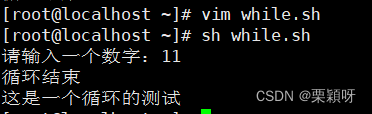
用if循环语句添加结束语
另一种方式结束语 echo
死循环方式

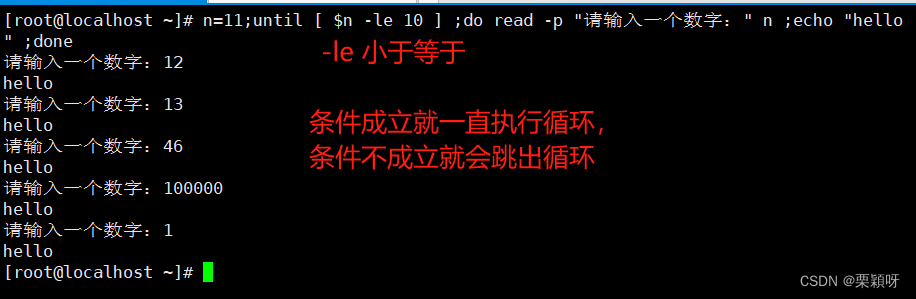
1.3、unit循环语句
重复测试某个条件,主要条件不成立则反复执行,基本上与while用法和使用场景相同。
语法格式

举例

while和until都是要先定义变量
1.4、循环控制语句
有时我们在脚本中执行循环的过程中,我们需要根据特定的条件来及时的退出循环去执行其他的任务,所以我们要能够对循环进行条件上的控制,shell中exit命令、break命令、continue命令能帮我们控制循环内部的情况。
1)exit命令
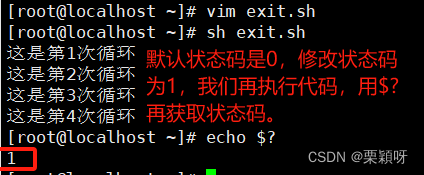
不管出现在循环语句中,还是脚本的其他位置都会直接退出整个脚本,exit命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是0。
举例
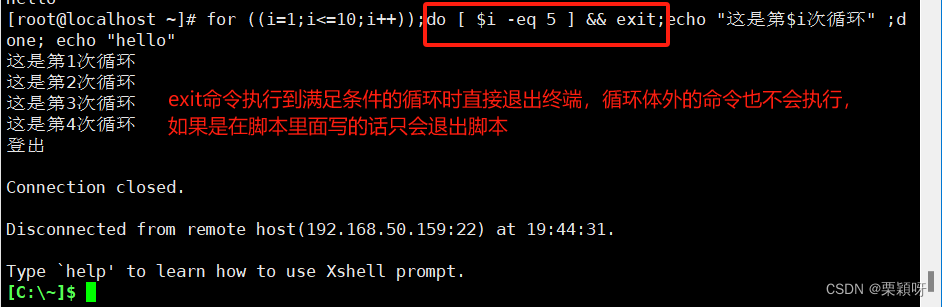
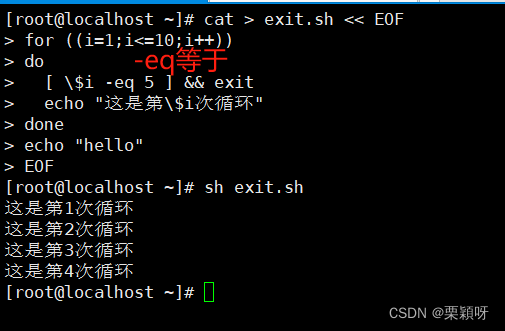
执行脚本,满足退出条件直接退出脚本,包括循环体以外的命令仍然没有执行
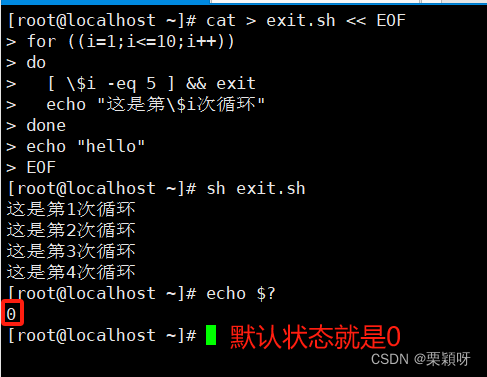
另一种写法,定义状态码1
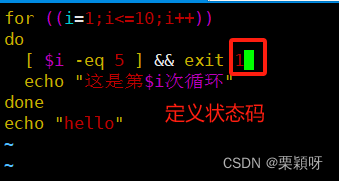
后面我们可以通过状态码值1来进行判断
2)break命令
break命令是退出循环的一个简单方法,可以用break命令来退出任意类型的循环,包括while和until循环。
在shell执行break命令时,它会尝试跳出当前正在执行的循环。如果在内部循环,但需要停止外部循环,break命令接受单个命令行参数值,break n 其中n指定了要跳出的循环层级。默认情况下,n为1,表示跳出的是当前的循环。如果你将n设为2,break命令就会停止下一级的外部循环。
举例
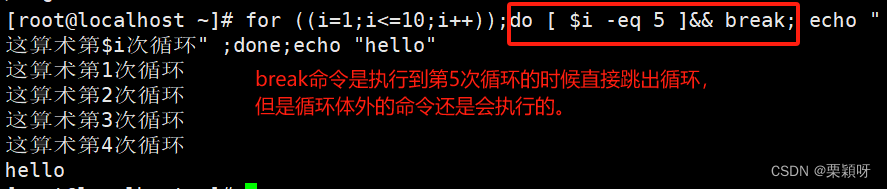
3)continue命令
continue命令可以提前中止某次循环中的命令,但并不会完全终止整个循环。比如提前终止本次循环,进入下一次循环。
举例

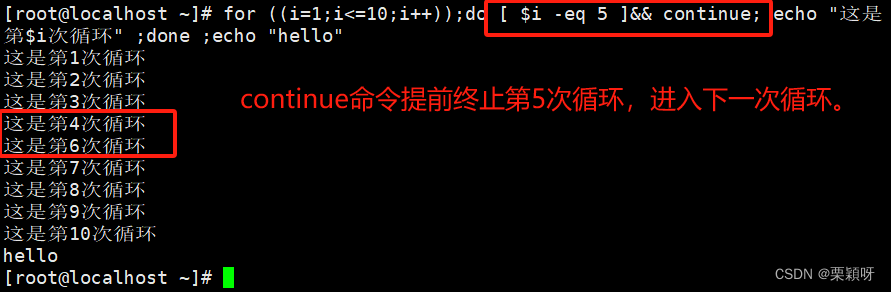
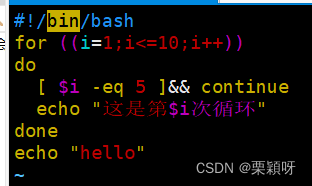
1.5、随机数$RANDOM
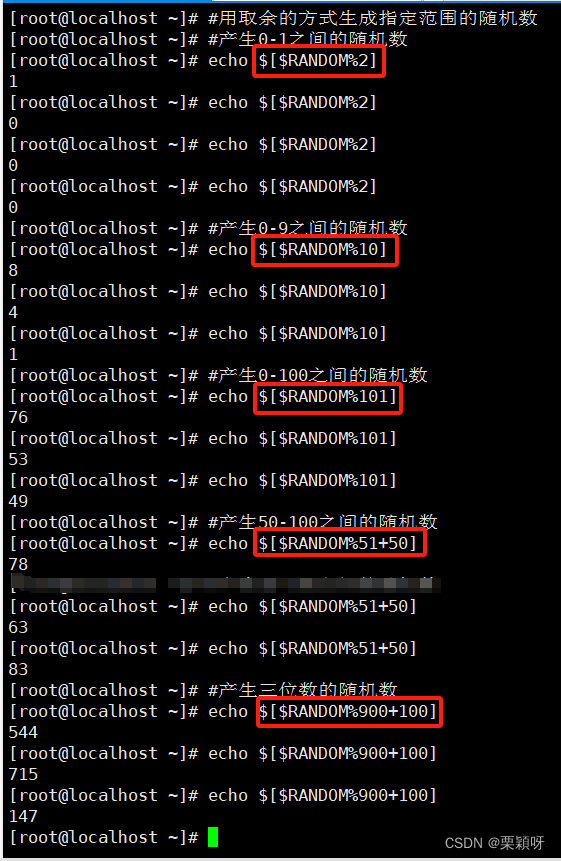
在Linux Shell中,生成随机数是一个常见的需求。无论是在写shell脚本中还是在命令行中,生成随机数都可以帮助我们解决很多问题。在bash shell中,还有一个环境变量**$RANDOM,它会在每次访问时生成一个随机数,随机数范围0-32767。
应用:生成指定范围的随机数(取余的方式**)
举例

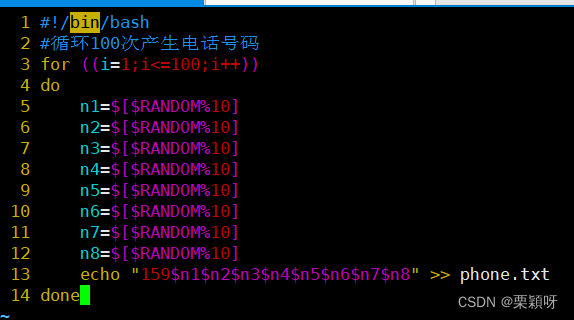
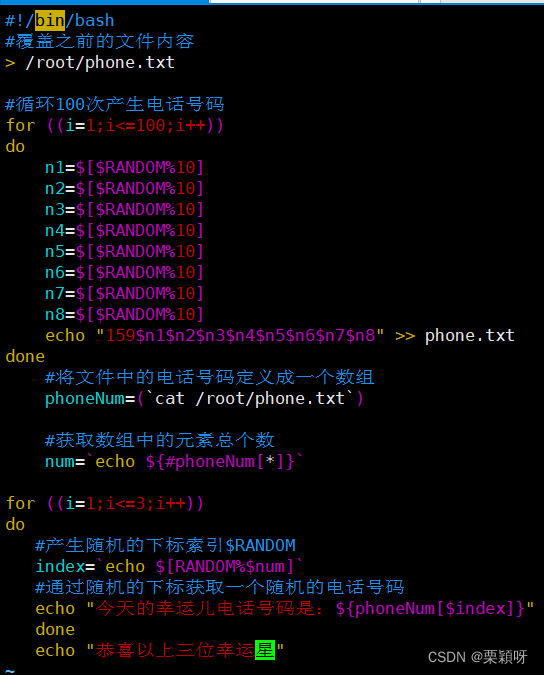
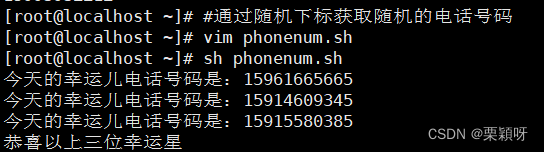
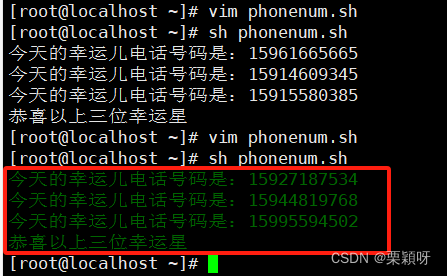
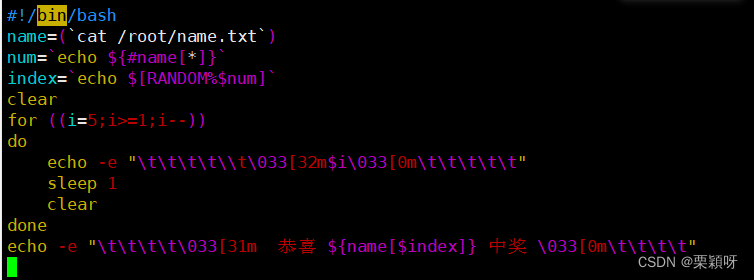
实例1:获取随机电话号码

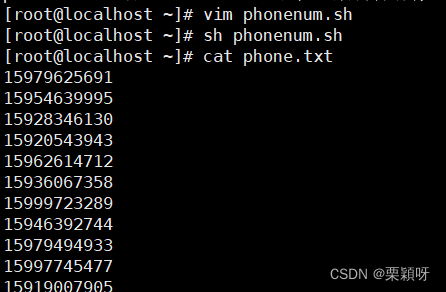
随机抽取:把文件内容定义数组 定义变量,变量值是获取到的元素个数,索引产生随机的下标,通过随机下标获取一个随机的电话号码

实例2:随机抽奖

2、嵌套循环语句与函数
2.1、嵌套循环
嵌套循环就是循环语句里面包含其他的循环语句,每次外部循环都会触发内部循环,直至内部循环完成,才接着执行下一次的外部循环。for循环、while循环和until循环可以相互嵌套。
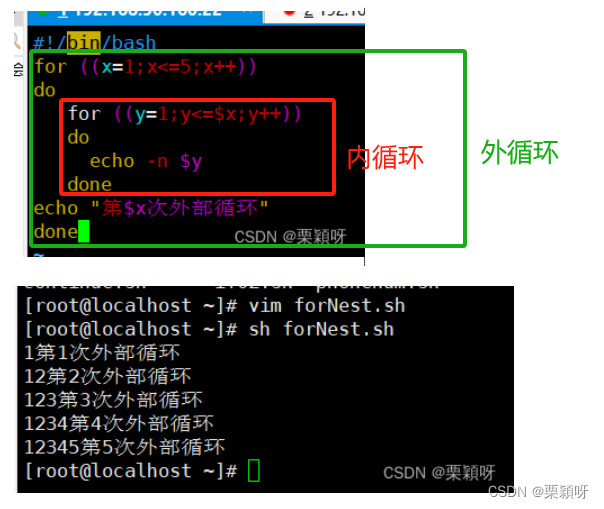
举例1
执行完内循环再执行1次外循环,可以用-x来观察脚本执行过程
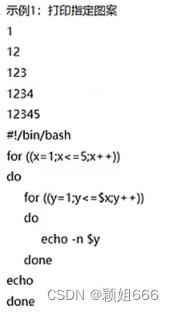
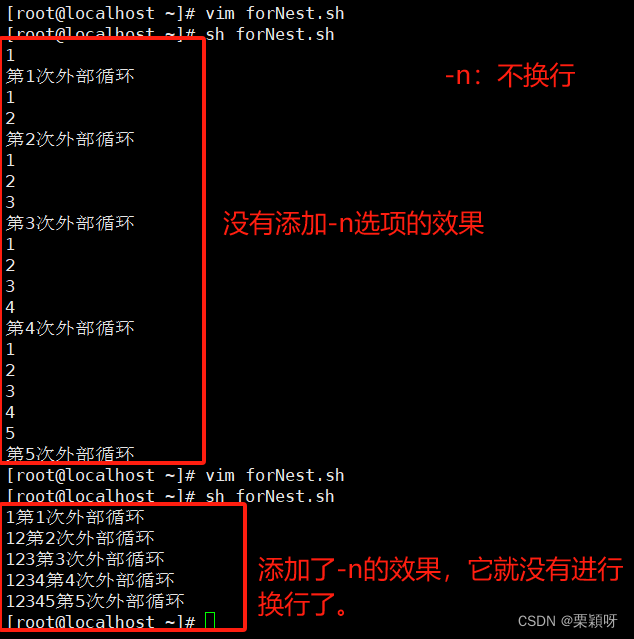
举例2
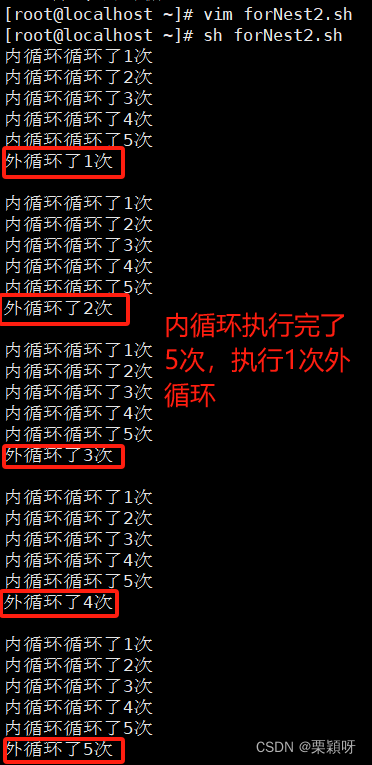
内循环执行5次执行一次外循环,内循环做完再做外循环,一共循环5次。

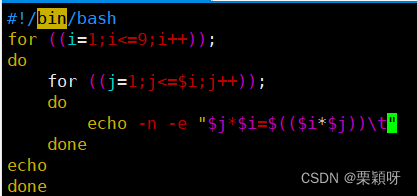
举例3 九九乘法表
在echo里面直接进行计算,两种方式执行结果都是一样的。
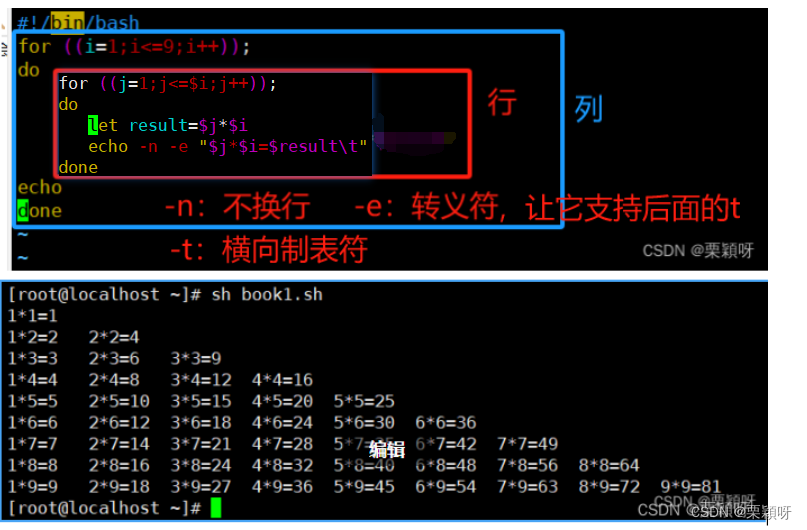
定义一个result变量来进行计算
举例4 达到要求的全部文件重命名添加后缀名



2.2、shell函数
shell函数:将命令序列按格式写在一起,可方便重复使用命令序列。
函数相当于是一段封装的代码,实现某项功能,重复使用代码,简洁代码量
函数定义的语法
语法一和语法二


举例

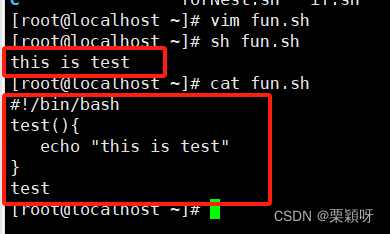

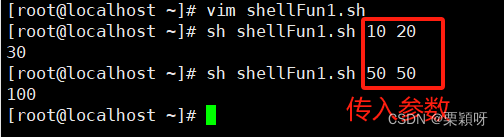
$@内置变量,脚本外输的变量值,我们就调用这个函数进行判断。返回值0是服务开启,非0是未开启。



修改颜色


添加时间


3、案例练习
案例1 ping网段
提示用户输入网段(如:192.168.100),然后测试该网络有哪些主机可以ping通,并记录这些主机地址。
window键加r键

查看本地的网段ip



在编写脚本的时候ping接试试能否ping通

执行脚本


案例2:整数求和
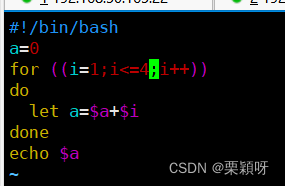
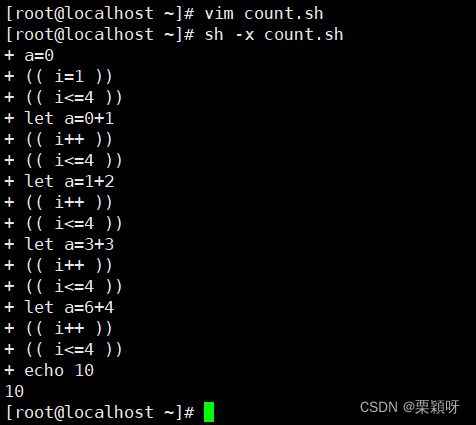
写脚本用来1加到100的整数求和
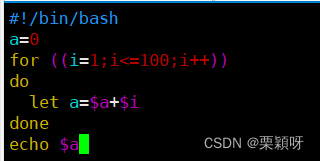
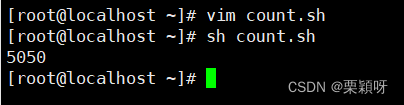
1到4的整数求和
求偶数和
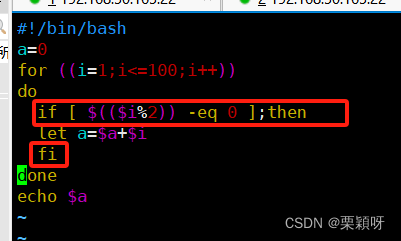

求奇数和,就是条件不等于0就可以了。
五、文本处理sed与awk命令
1、sed命令的使用
1.1、sed简介
sed是一个用于:过滤并转换文本行的流编辑器
1.2、sed和vi的区别
sed是非交互式的文本流编辑器,接受input输入字符流,然后过滤并转换,最后输出output输出字符流。
vi算术交互式的文本编辑器。
1.3、sed和awk的区别
sed是一个基于行字符流,执行整行处理的文本处理工具。
awk是一个基于行字符流,精细到列处理的文本处理工具。
1.4、sed工作原理图
一行一行进行匹配处理
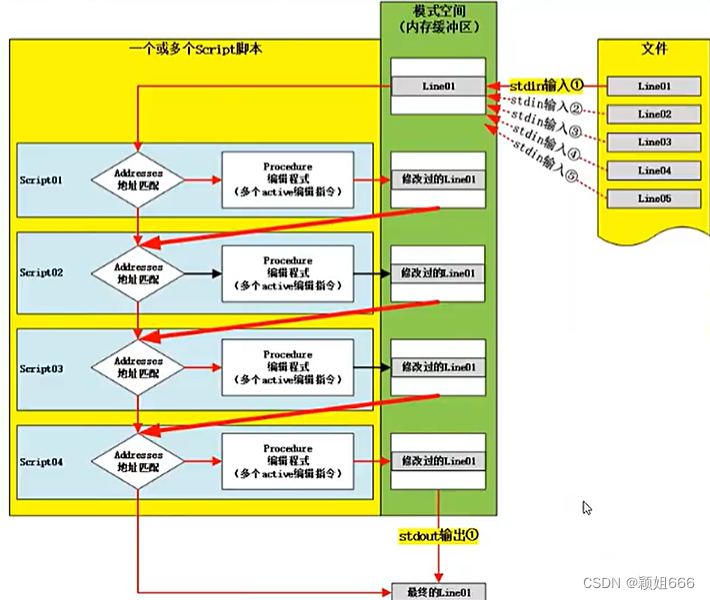
1.5、sed的工作原理简介
(1)读入<新行>到<模式空间>(内存缓冲区)
<1><script01脚本>执行<addresses地址匹配>
====》如果不匹配,则不执行<script01脚本>的<Procedure编辑程式>,然后将<未处理的行>传给<script02脚本>
=====》如果 匹配,则 执行<script01脚本>的<Procedure编辑程式>,然后将<已处理的行>传给<script02脚本>
<2><script02脚本>执行<addresses地址匹配>
=====》如果不匹配,则不执行<script02脚本>的<Procedure编辑程式>,然后将<未处理的行>传给<script03脚本>。
=====》如果匹配,则执行<script02脚本>的<Procedure编辑程式>,然后将<已处理的行>传给<script03脚本>
<3>同理类推......,依次执行后续的<script03脚本>和<script04脚本>
<4>当所有<操作script脚本>都执行完毕之后,标准输出:<模式空间>中<行数据>
(2)然后:返回到<第(1)步>,继续读取处理<下一行>
(3)直到<所有行>均<读取处理>完毕之后,结束<sed命令>!
1.6、sed的优点
(1)Sed不会导致内存不足
Sed只会缓存<一行的内容>在<模式空间>,这样的好处是:
- sed可以缓存<大文件>,而不会有任何问题
- 不像一些编辑器,因为要一次性载入<文件的一大块内容>到<缓存>中,从而导致<内存不足>
(2)Sed是一个<非交互式>的<字符流编辑器>
所谓<非交互式> 是指使用sed只能在命令行下输入编辑命令来编辑文本,然后在屏幕上查看<标准输出>。
所谓<流编辑器> 是指sed每次只从文件(或输入)读入一行,并将<处理结果>标准输出到<屏幕>,然后,读入<下一行>。
整个文件像流水一样,被<逐行读入>、<逐行处理>,然后<逐行输出>。
(3)Sed不是在源输入上直接进行处理的。
sed 不是在源输入上直接进行处理的,而是先将读入的行放到缓冲区中,对缓冲区中的内容进行处理,处理完毕后,直接将处理结果标准输出到屏幕上,而不会写回<源文件>。除非用sed -i命令将输出重定向到源文件。
1.7、sed的基本语法
(1)sed的语法结构

(2)sed的常用选项

(3)地址定位(模式匹配)
地址用于决定对哪些行进行编辑。地址形式可以是“数字”、“正则表达式”或“二者结合”。如果没有指定地址,sed将处理输入文件中的所有行。
1)空模式
表示所有的行都执行(以p为指令为例,该指令用于输出)
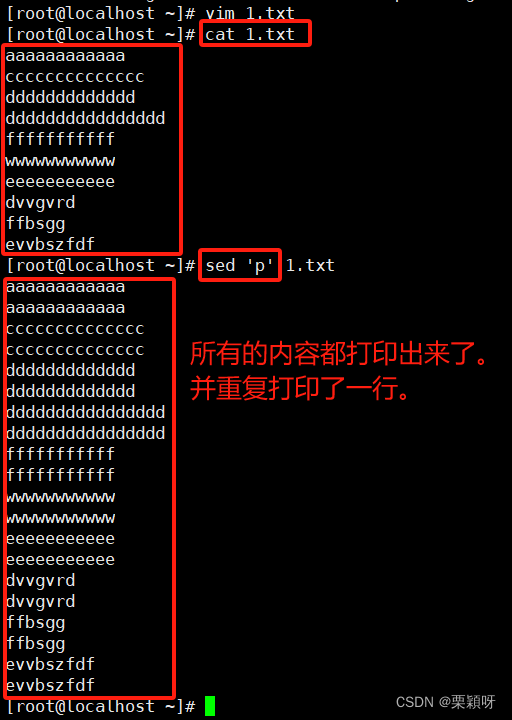
p,sed的操作执行,将每一行打印两行。
为什么最终每个数据行却打印显示了两次呢?
因为哪怕没有p指令,sed也会默认将读取到的所有数据行显示在屏幕上,所以p指令数据行被打印显示了一次,接着sed默认又将读取的数据行再显示了一次,最终每行显示了两次。
可以使用-n选项屏蔽sed默认的输出功能。关闭默认的输出功能后,所有的数据行将仅显示一次。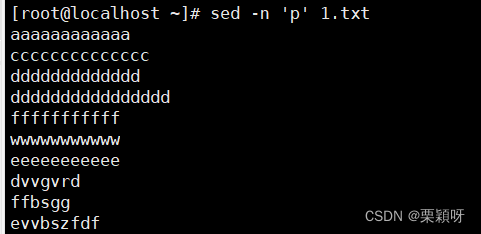
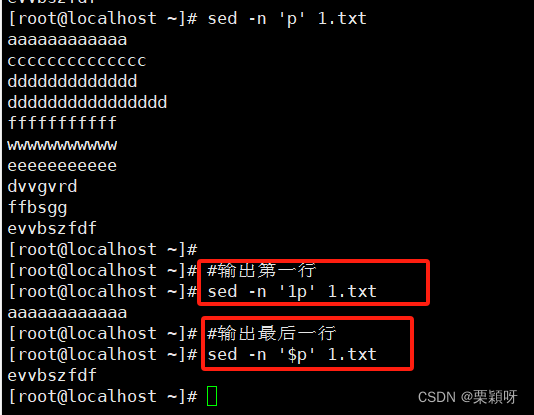
2)用行号进行地址地位
输出单独行
输出范围行
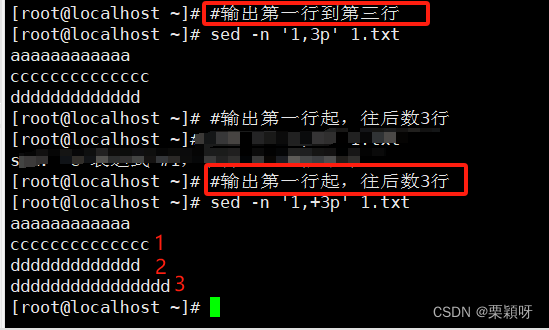
输出间隔行
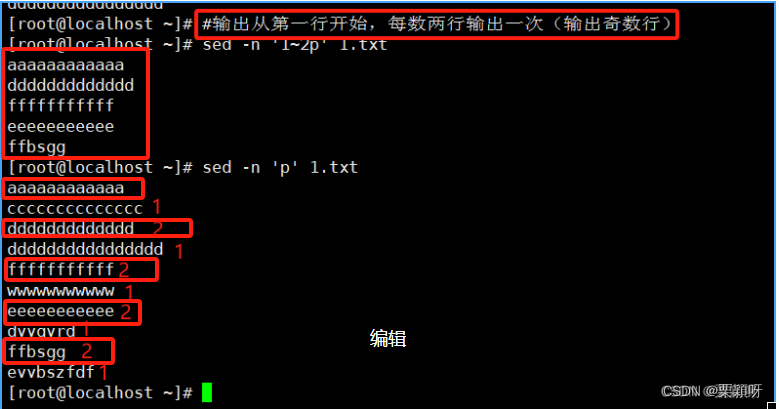
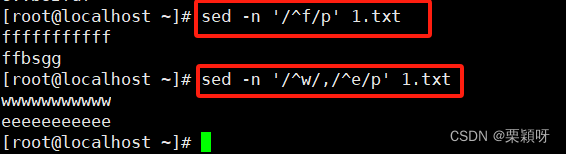
3)以正则地址定位

(4)sed常用指令(子命令动作)
所有的子命令操作默认都不会修改源文件,如果需要修改源文件,则添加-i选项

举例:

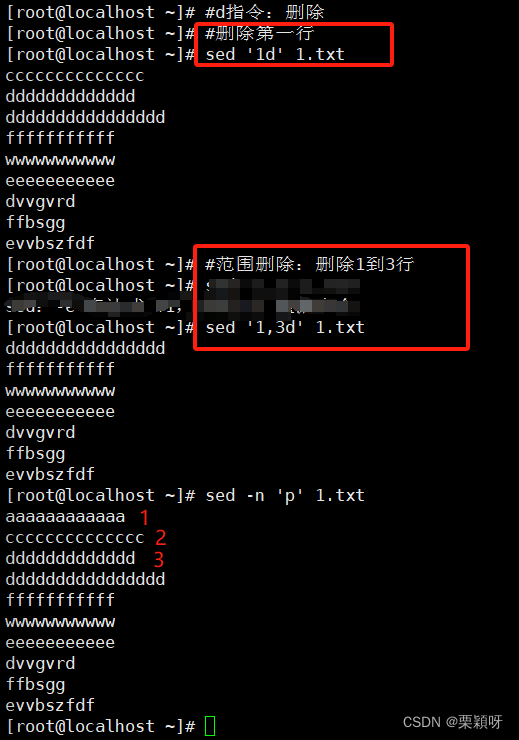
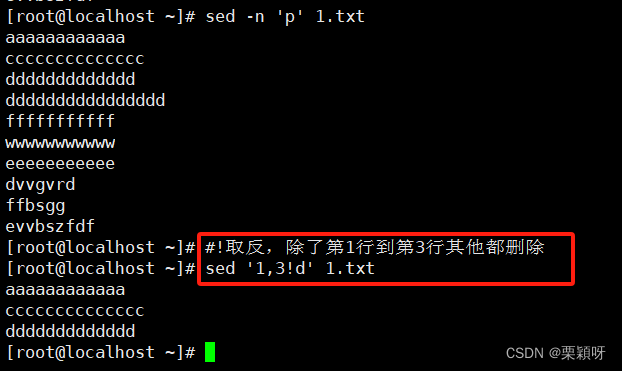
d指令:删除
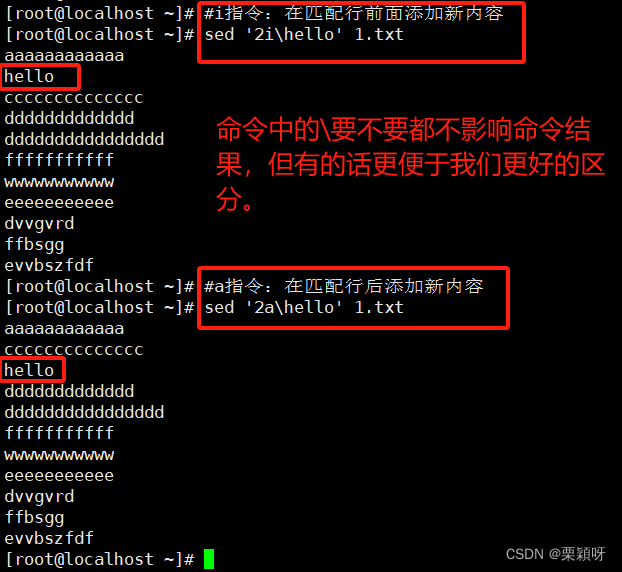
i指令:插入行
a指令:追加行
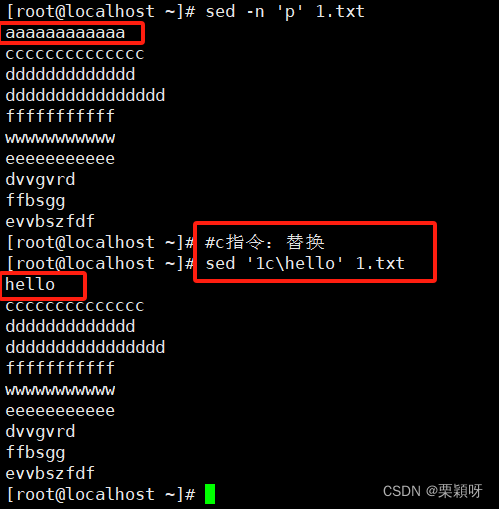
c指令:替换行

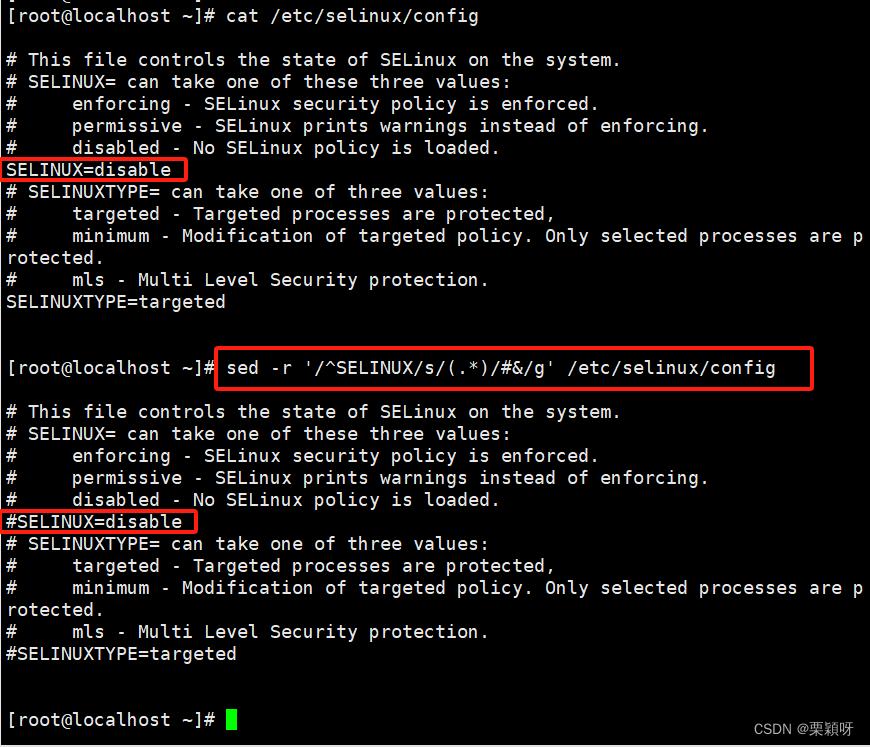
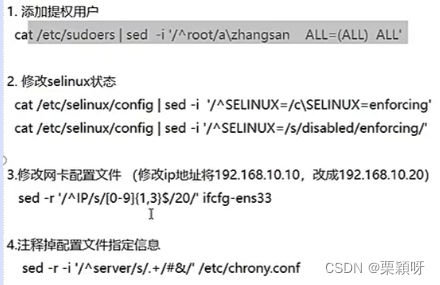
注释掉配置文件指定的信息
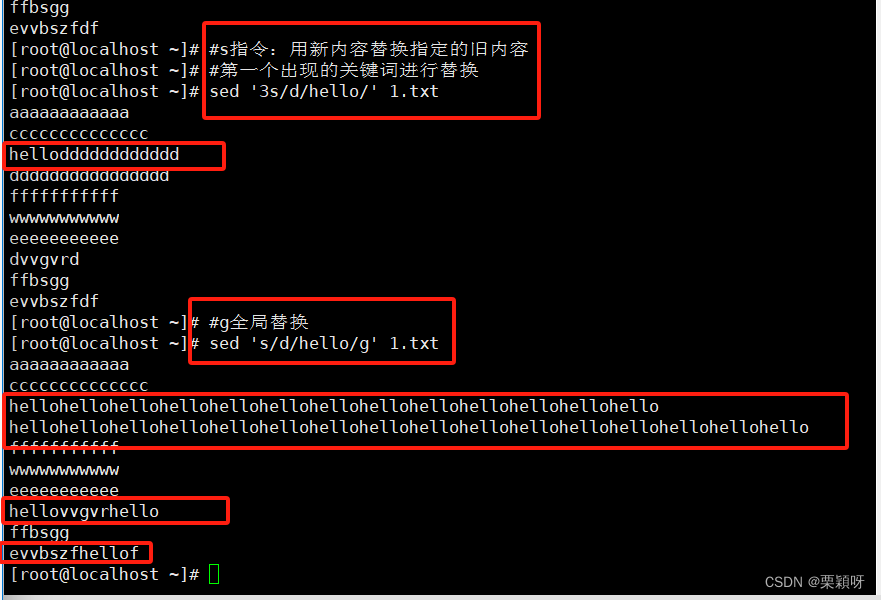
g的用法:和s结合起来用就是全局替换
格式: sed 's/原内容/要替换是内容/g’
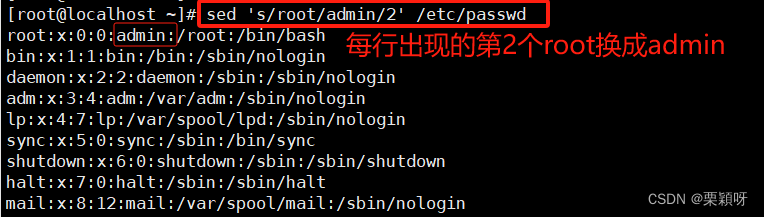
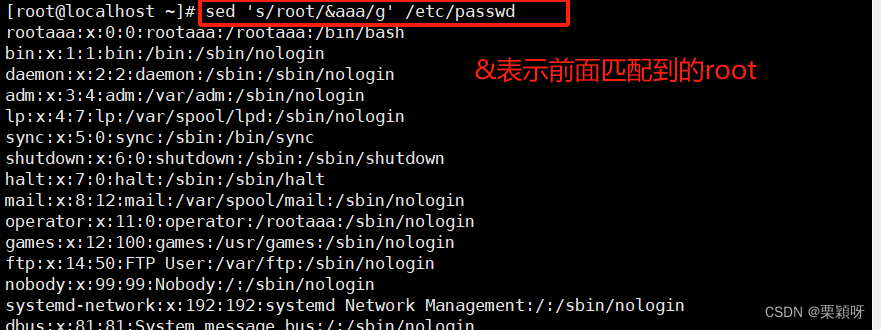
通过-e多条指令进行匹配

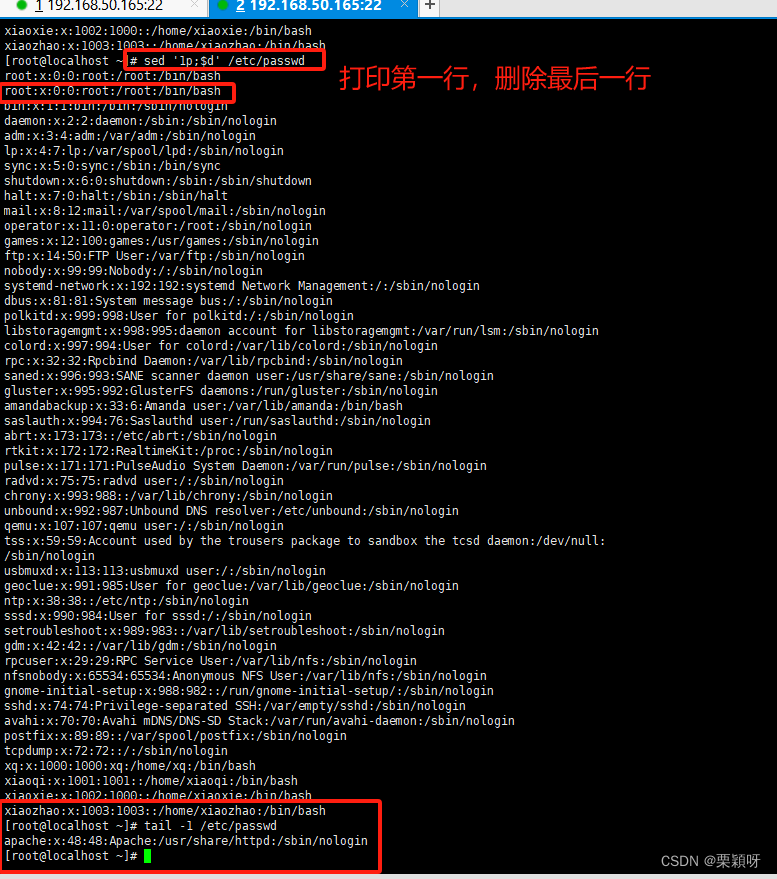

追加内容

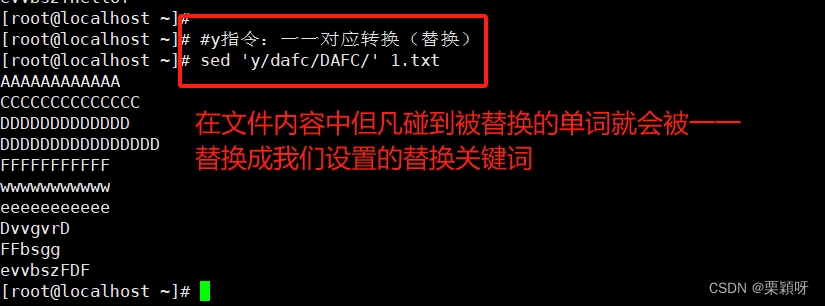
全部内容被替换

(6)使用示例
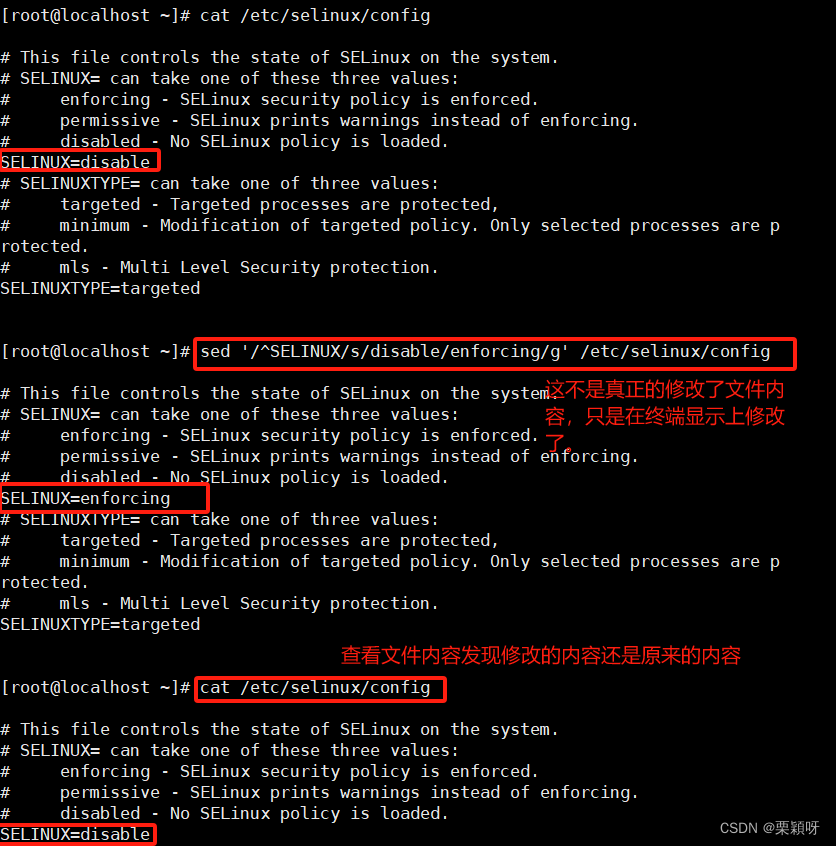
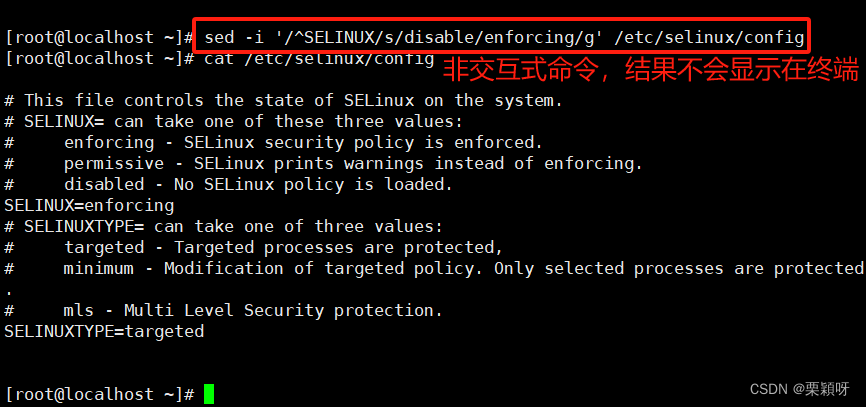
修改selinux状态

修改网卡配置文件
在查看网卡配置文件中,我们会发现网卡中没有IP,那是因为我还没有配置。一般来说网卡默认是dhcp获取的IP地址,所以默认是没有IP的。

需要配置网卡IP,进入系统配置网卡文件进行配置。

后续补充,暂且放一下。😅
2、awd命令的使用
2.1、awk命令概述
AWK是一种解释执行的编程语言,它非常的强大,被设计用来专门处理文本数据。
AWK的名称是由它们设计者的名字缩写而来 ——Afred Aho,Peter Weinberger与Brian Kernighan。
AWK可以做非常多的工作,下面只是其中的一小部分:
文本处理
生成格式化的文本报告
进行算术运算
字符串操作等
2.2、awk与sed、grep的比较
shell三剑客:sed、awk、grep 必须得掌握
sed是一个基于行字符流,执行整行处理的文本处理工具,
awk是一个基于行字符流,精细到列处理的文本处理工具。
grep主要用于从文本快速过滤匹配的行。
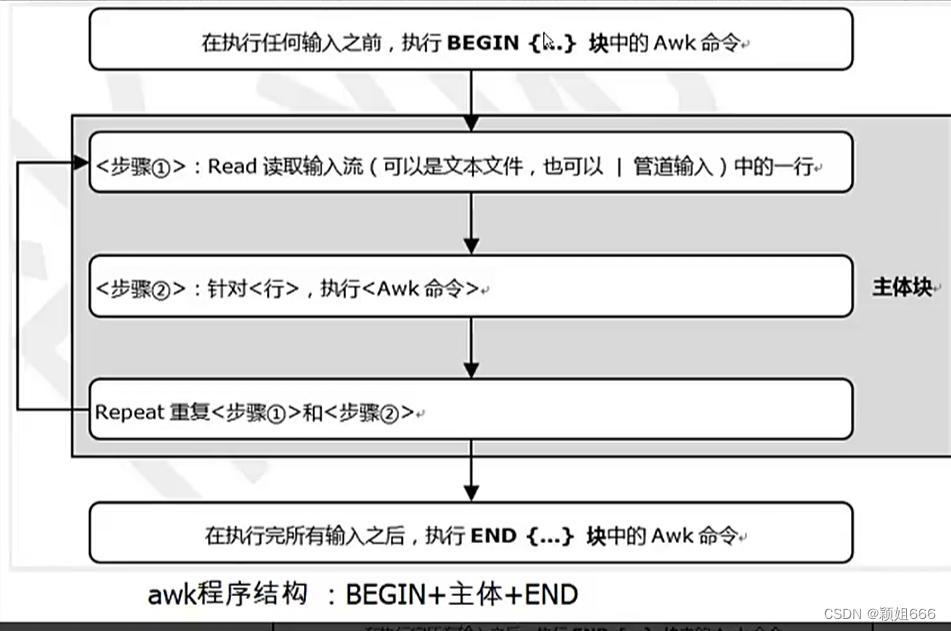
2.3、awk工作流程
AWK执行的流程非常简单:读(read)、执行(Execute)与重复(Repeat) AWK的工作流程图。
2.4、awk语法格式
1)组成结构
awk由三个部分组成:开始(begin)、主体、结束(end),
开始(begin)、结束(end)这两部份可选,一般用于格式化输出。
begin:在主体前运行,只运行一次
end :在主体结束后运行,只执行一次
2)语法:
awk [option] 'pattern(action)' filename
pattern:模式匹配,匹配指定行。可以使用行号变量、正则以及条件
action:执行操作,比如常用命令print:打印输出
3)常用选项
-F定义字段分割符号,默认的分隔符是空格-v定义变量并赋值
4)工作模式
- 行工作模式,读入一行文件,存在"$0"里
- 使用内置变量FS(字段分隔符)分割一行,存在$1-$100
- 输出时也是用内置变量OFS,输出该行
OFS默认换行
5)awk内部变量
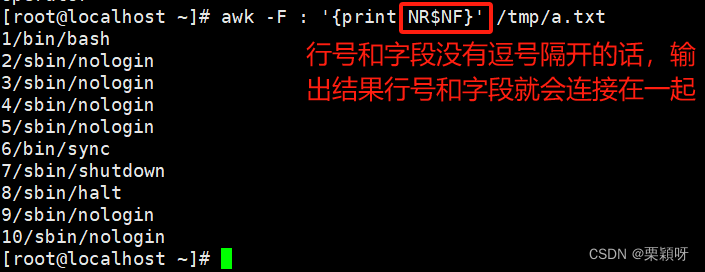
$0当前处理行的所有记录$n文件中每行以间隔符号分割的不同字段NF当前记录的字段数(列数)$NF最后一列 $(NF-1)表示倒数第二列FNR/NR行号FS 定义间隔符OFS定义输出字段分隔符,默认空格'BEGIN{OFS=“\t"};print $1,$3}'RS输入记录分割符,默认换行,一般不更改ORS输出记录分割符,默认换行,一般不更改FILENAME当前输入的文件名
实操
$0 是把全部都给打印出来了,当前处理行的所有信息
$n文件中每行以间隔符号分割的不同字段, $1表示文件中以间隔符分割的第一个字段
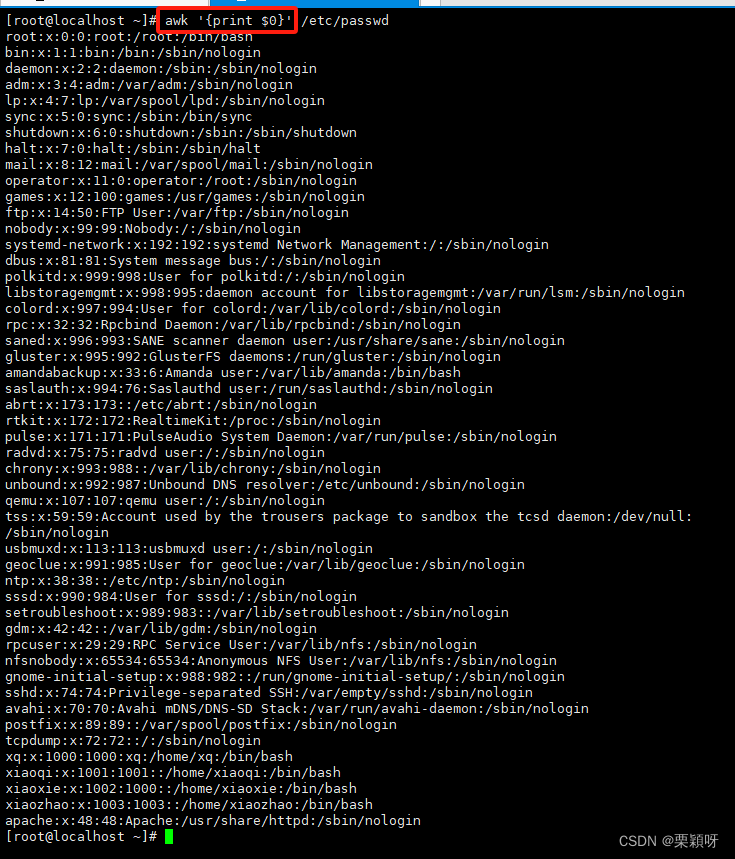
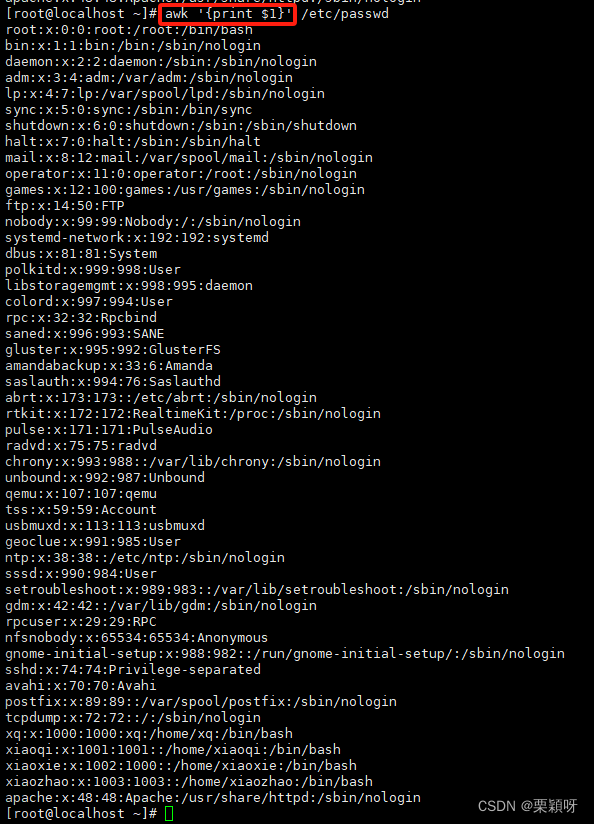
精确到列进行处理
NF 记录当前的字段数(列数)
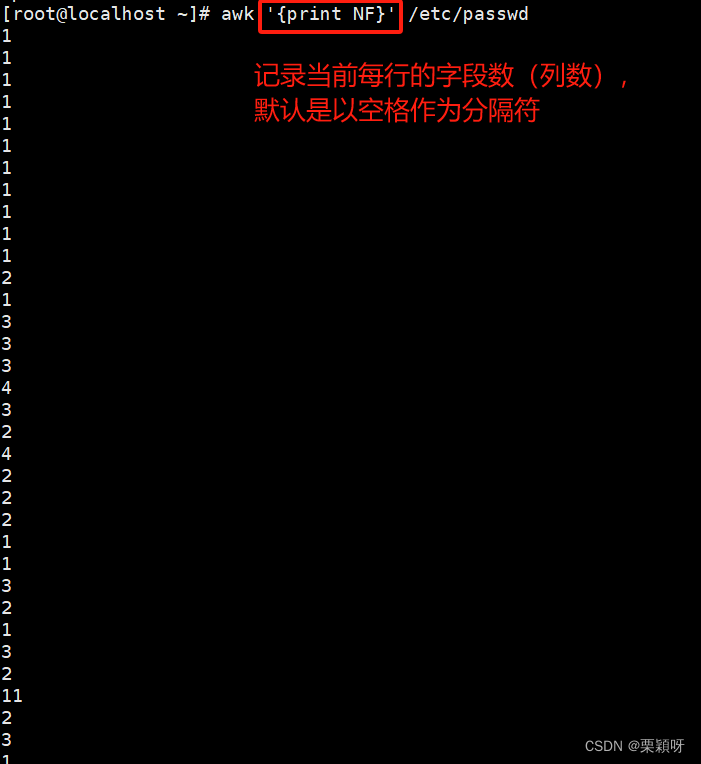
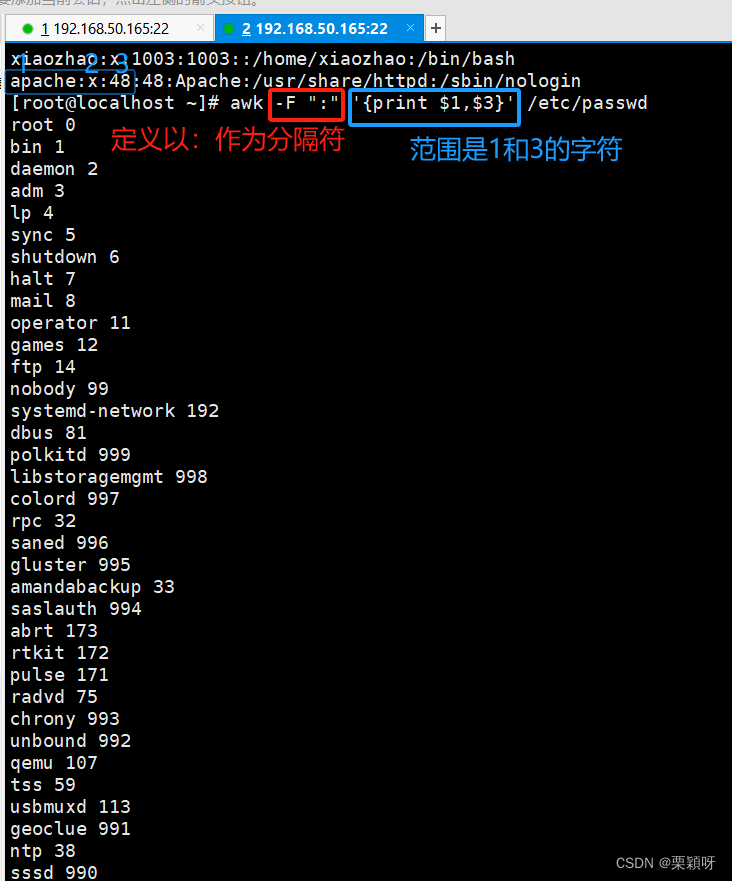
以:作为分隔符打印字段数,每一行都是7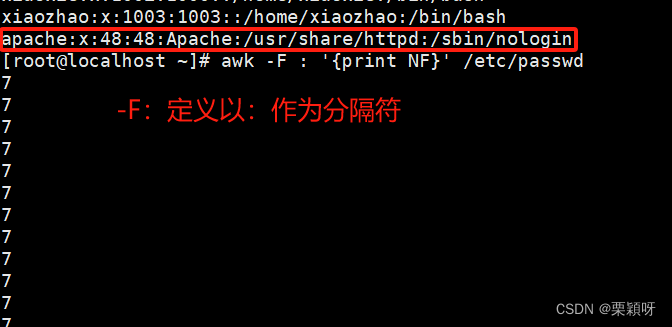
指定列打印
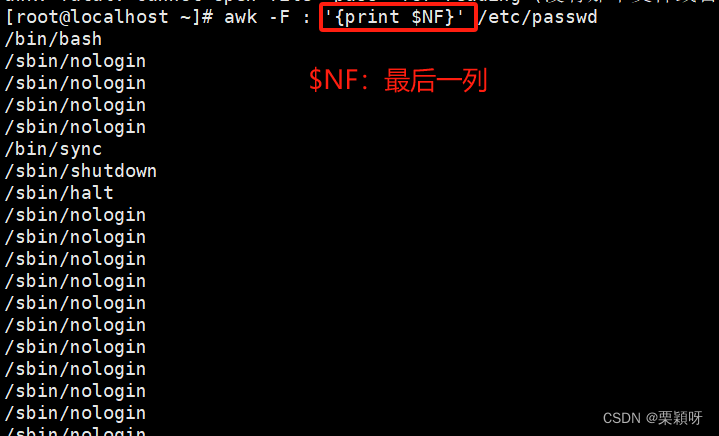
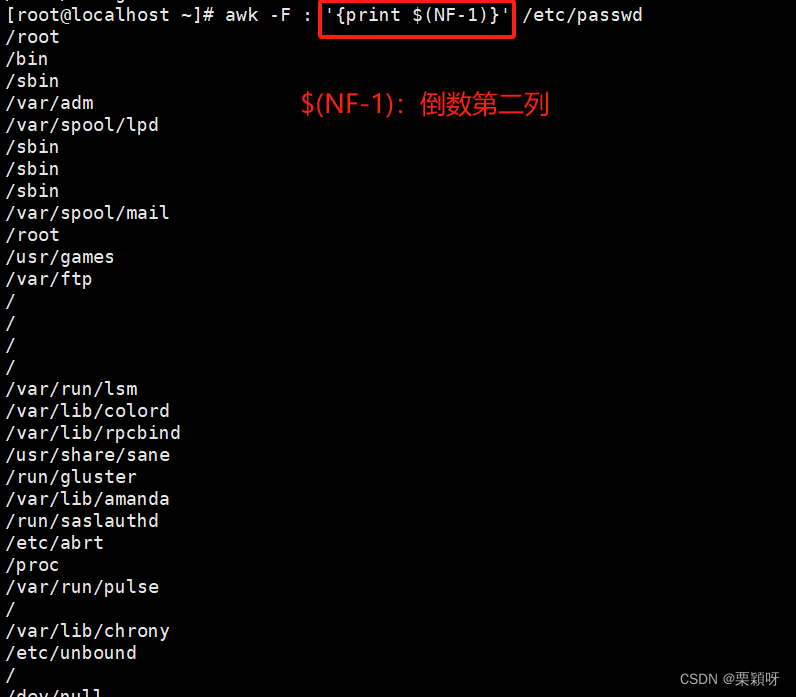
NR打印行号
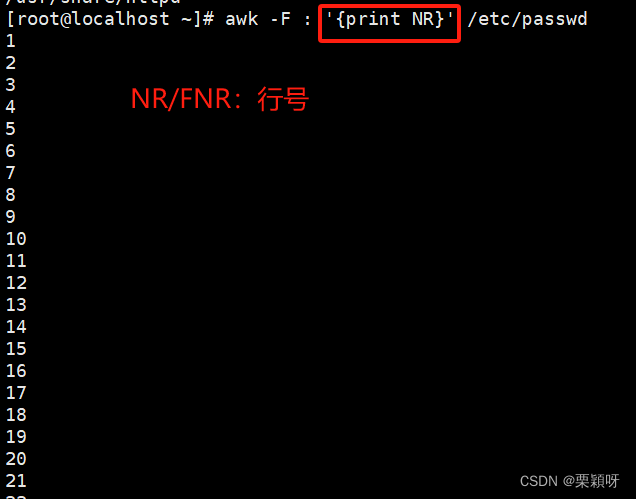
FS指定分隔符,默认是空格作为分隔符
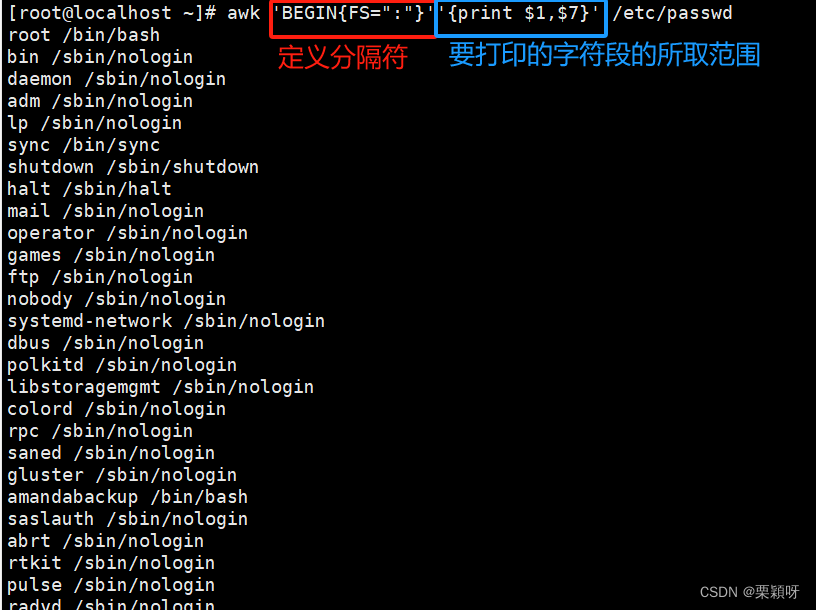
OFS定义输出字段分隔符,默认空格作为分隔符
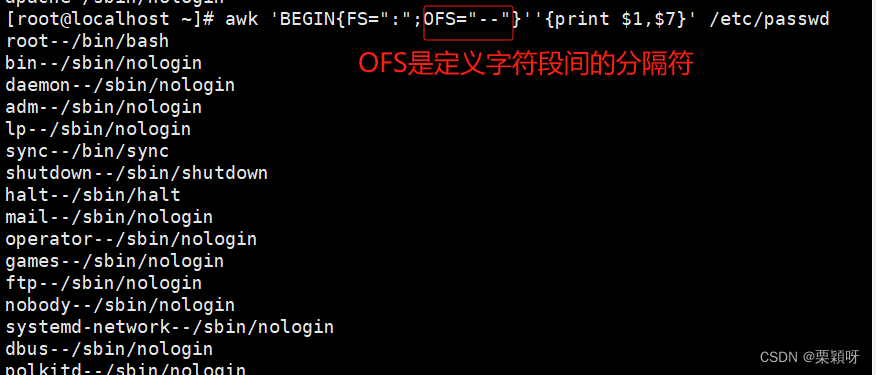
2.5、awk命令
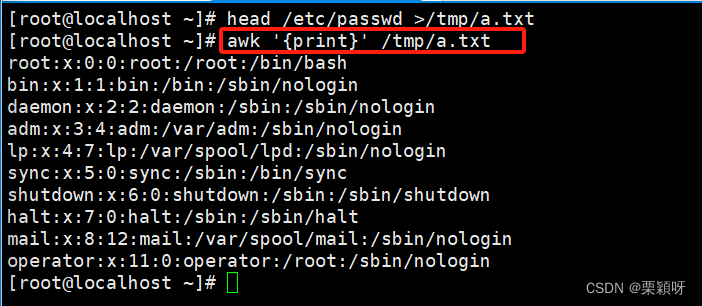
1)输出指定行(类似sed命令的p指令)
- 全文输出

- 使用行号NR匹配
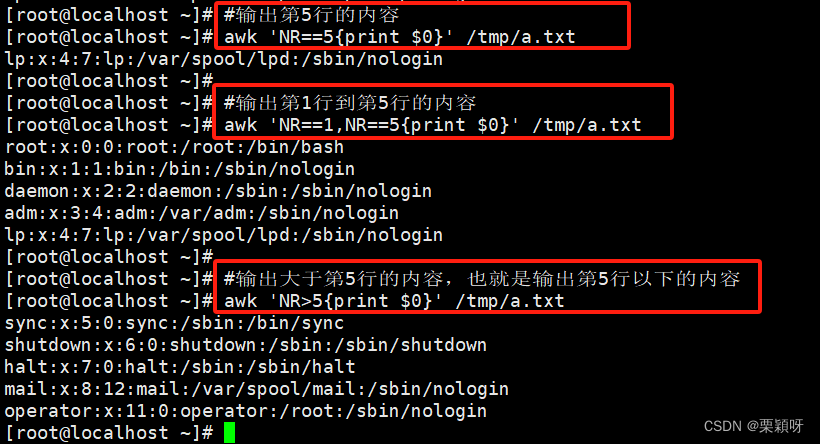
- 使用正则匹配

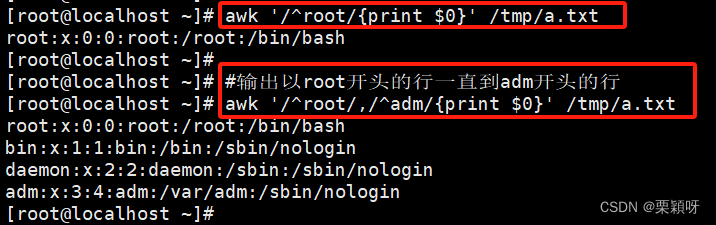
- 使用关系运算符

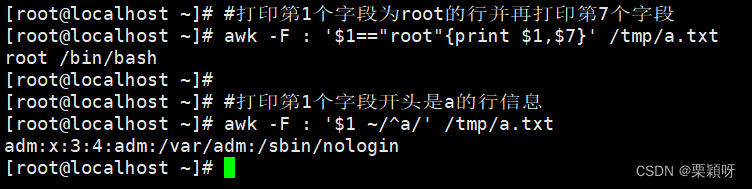
使用关系运算符 ,以:作为分隔符,第3个字符等于0的打印出来
2)输出指定字符(列)
- 输出单列

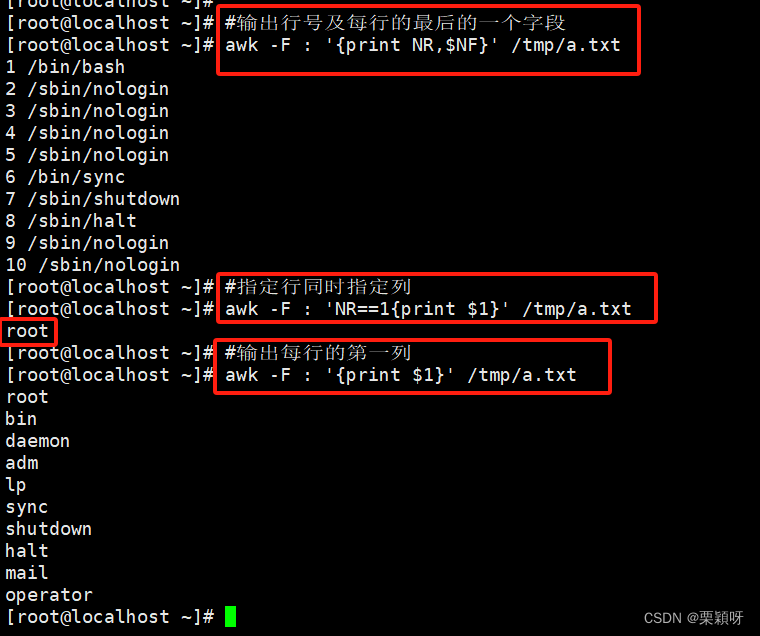
- 输出多列

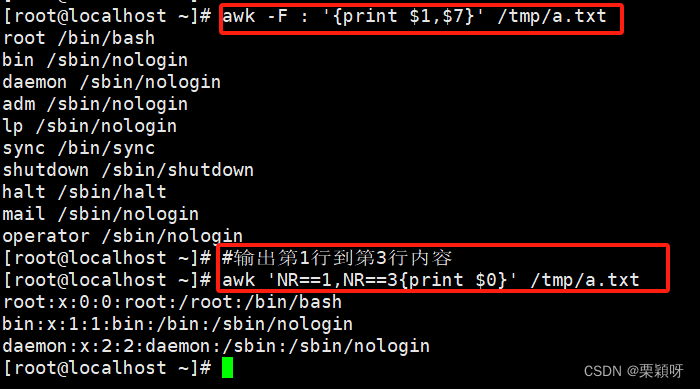
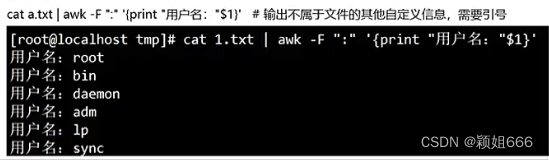
- 输出自定义信息
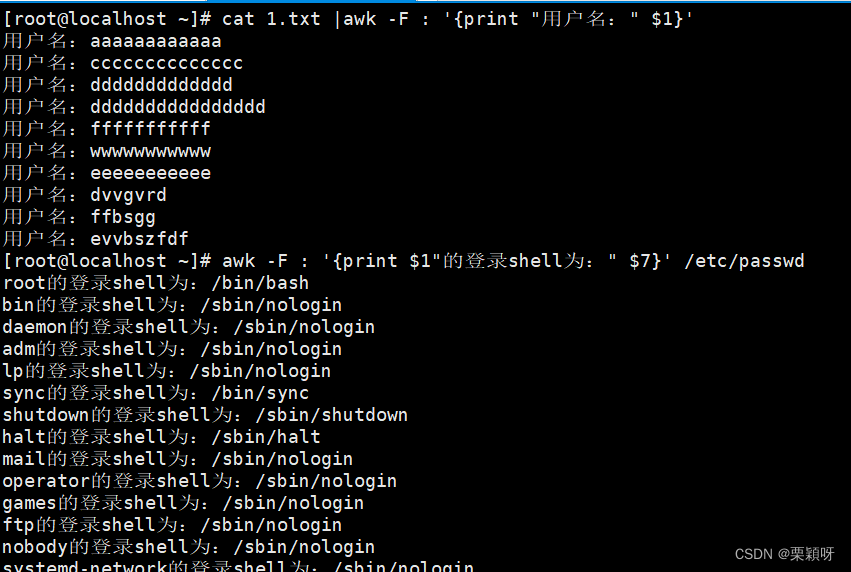
3)awk的操作符
- 算术运算符
awk支持多种算术运算,常见的如:+、-、*、/、%等
为什么会打印这么多行呢?因为1.txt文件中有这么多行的内容。
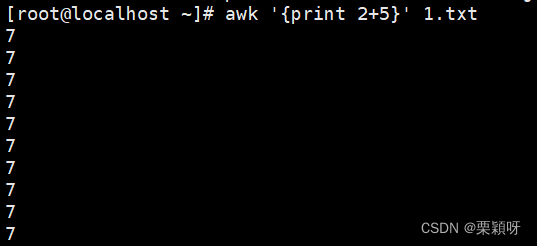
不想看到这么多行,只打印一行的话就用END或者BEGIN

为什么计算结果会是0呢?那是因为这个命令是需要调用 1.txt 文件的第2、3、4字段进行求和计算,如果你1.txt文件中没有内容,就计算不了。

- 关系运算符
整数之间的关系运算符:>、<、>=、<=、==(等于)、!=(不等于)
字符串之间的关系运算符:==(相同)、!=(不相同)、/xxx/(匹配正则)、!/xxx/(不匹配正则)
- 逻辑运算符
&&:逻辑与
||:逻辑或
!:非,取反
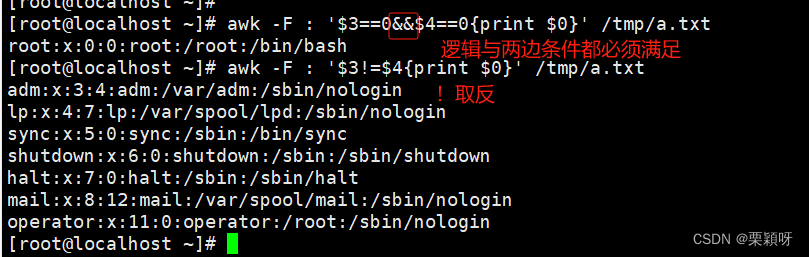
举例:

逻辑与&& 和 取反!
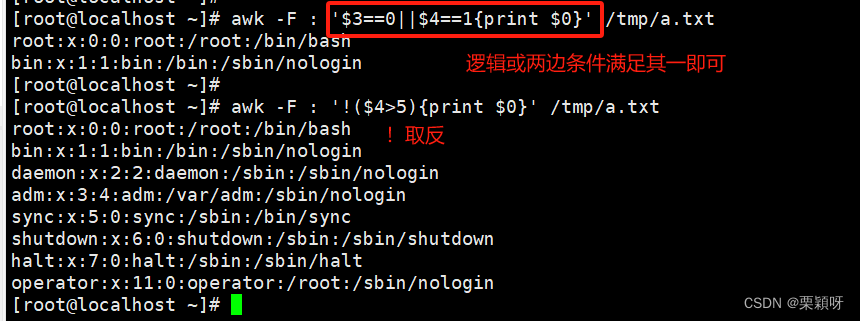
逻辑或||
练习:
1.打印uid和gid不同的用户的用户名、uid、gid信息。
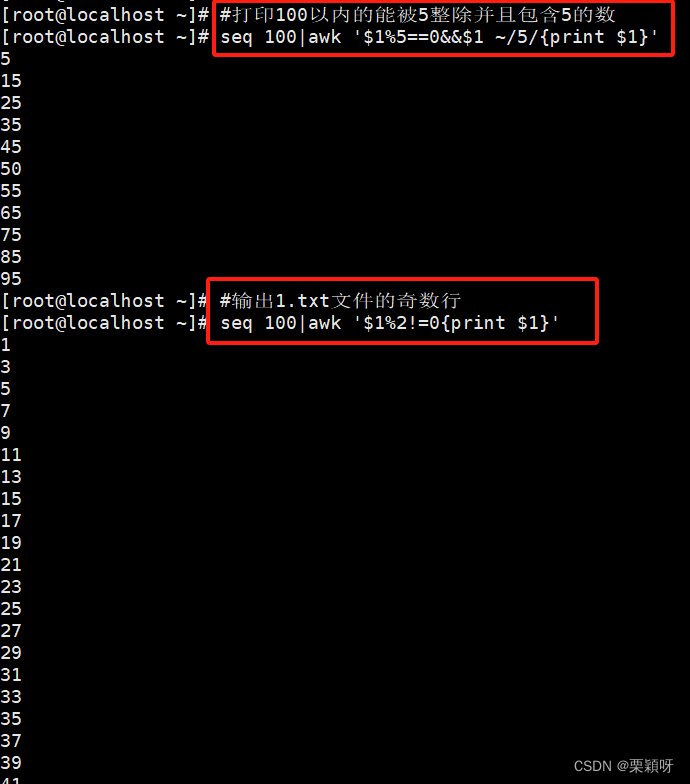
2.打印100以内的能被5整除并且包含5的数。
3.输出1.txt文件的奇数行。
4)BEGIN和END的使用
BEGIN:一般用于打印表头、初始化分隔符、定义变量等,只执行一次。
END :汇总数据 比如:打印总支出金额、总成绩、平均成绩、等等,只执行一次。


实操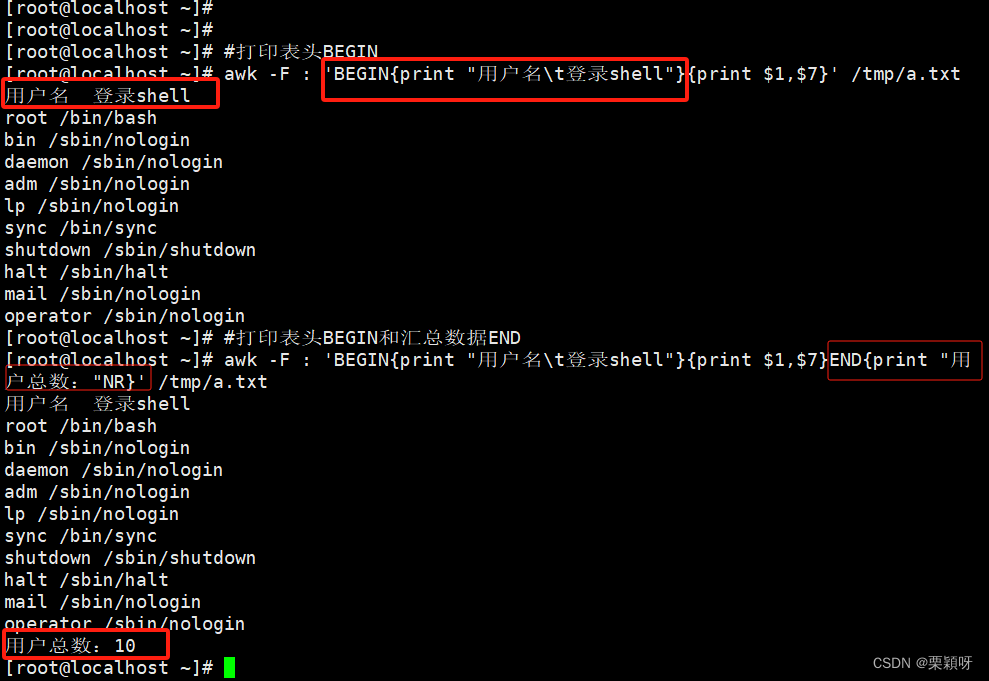
3、综合案例

案例1操作获取inet中ip地址
方法一 cut命令:对文件切割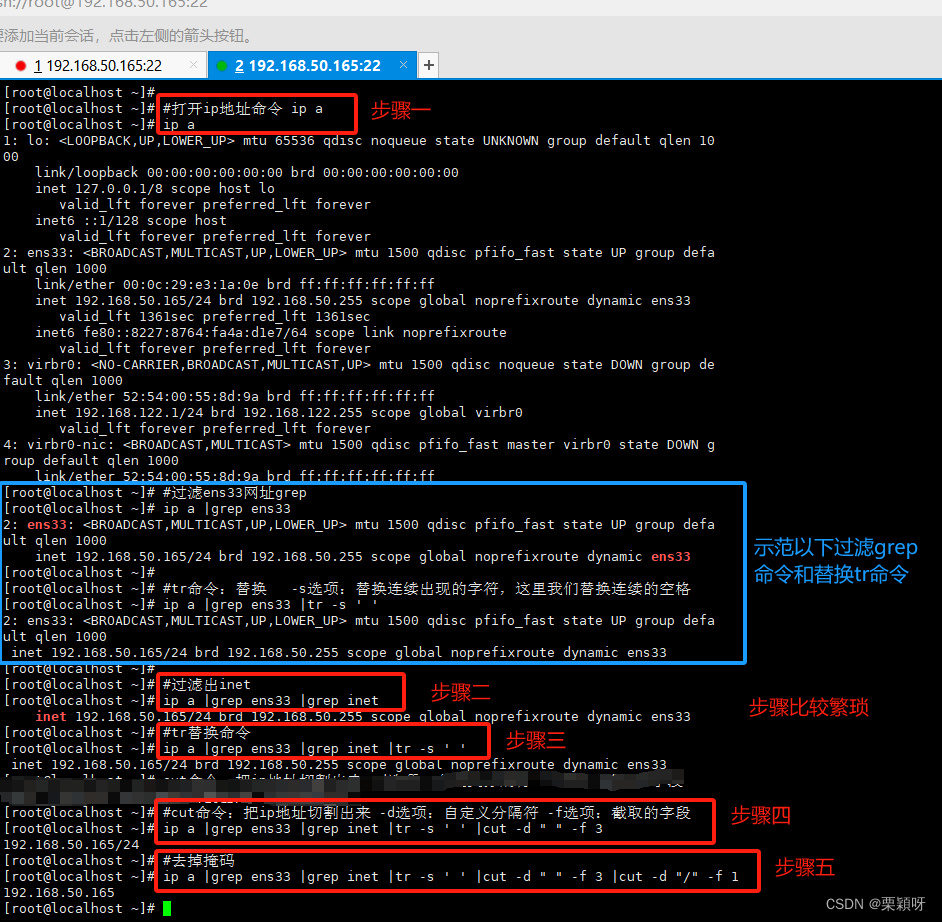
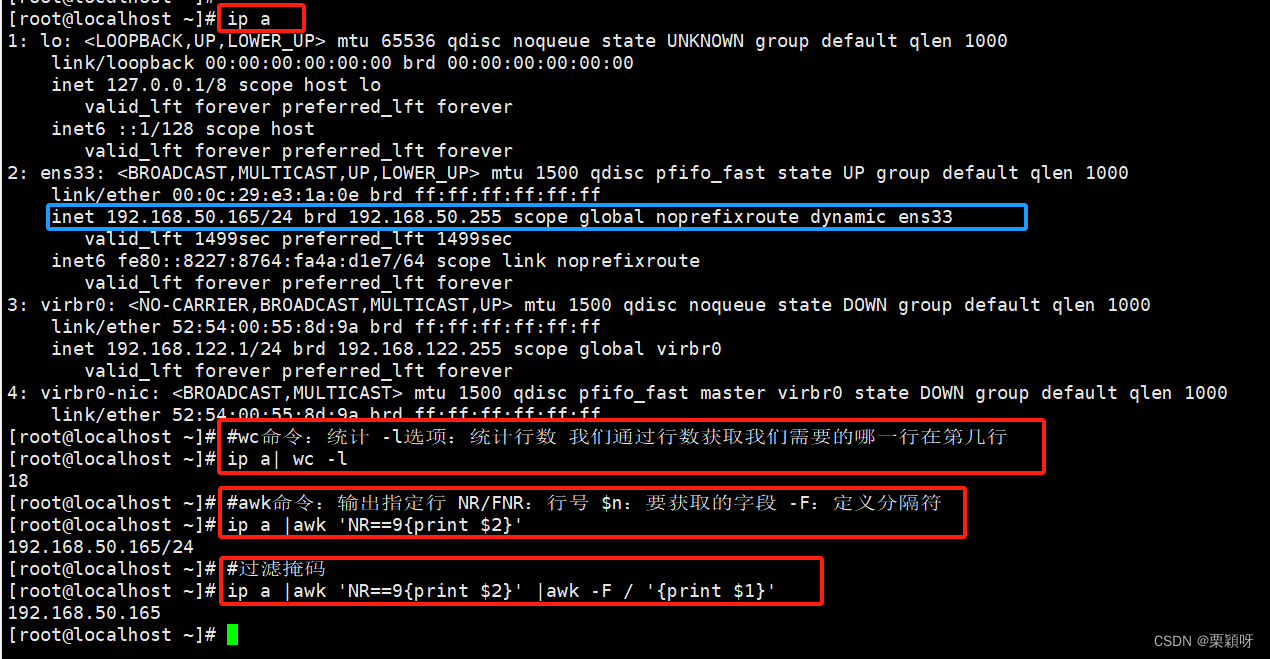
方法二:使用awk命令 此方法比方法一简洁
案例2 监控多台服务器的磁盘使用情况.......

在alert.sh脚本编辑执行


我们先在终端执行一下代码是否正确

再在脚本上编写 将命令定义变量,方便我们后面用if循环语句进行条件判断
将命令定义变量,方便我们后面用if循环语句进行条件判断 执行脚本命令
执行脚本命令 修改条件值执行脚本
修改条件值执行脚本 如果没有接受到可能邮箱设置SMTP服务未开启
如果没有接受到可能邮箱设置SMTP服务未开启


设置白名单

开启服务和添加白名单之后我们再执行一下脚本


实时检测:计划任务crontab

设置每隔一分钟执行下脚本命令,如果磁盘不满足磁盘空间就发送邮箱提醒

查看计划任务

优化代码


这是之前的执行结果
案例3 查看日志...... wtmp里面是有所有登录过服务器的IP
who /var/log/wtmp:
这个命令从 /var/log/wtmp 文件中读取登录记录。/var/log/wtmp 文件记录了所有登录
和注销的信息
awk '{print $5}':
这个 awk 命令从 who 命令的输出中提取第五列,即登录的主机名或IP地址。
awk -F "[()]" '{print $2}':
这个 awk 命令使用圆括号 () 作为字段分隔符,提取包含在圆括号内的内容,即实际的IP
地址

uniq命令:去重
uniq -c:
统计每个唯一IP地址的出现次数,并输出结果


如果你的ip地址中有空行的话,使用grep命令把空行去掉。
-v选项是取反的意思。^$是代表空行的意思。
who /var/log/wtmp |awk '{print $5}' |awk -F "[(|)]" '{print $2}' |grep -v "^$" |uniq -c
用脚本编写封掉ip地址 ,把ip作为变量
根据规则设置防火墙
sort:
将提取的IP地址进行排序,这一步是为了让 uniq -c 能够正确统计每个IP地址的出现次
数。

查帮助

# firewall-cmd --add-rich-rule='rule family=ipv4 source address=192.168.50.1 accept'

案例4 猜数字游戏
输入一个100以内的数字让其他人去猜,猜小猜大会给出对应的提示,猜对则游戏结束,最多10次机会。

总结
以上就是本章节要讲的内容,本文介绍了LinuxShell编程命令及操作。
版权归原作者 栗穎呀 所有, 如有侵权,请联系我们删除。