
这是目前遇到的最简单但最头疼的安装,因为是在公司之前用过的服务器上进行安装测试,加上又使用比较新的版本,结果踩了不少坑。Kettle连接Hive这个坑,从2023年4月11日下午开始,一致到2023年4月12日中午才弄好,不得不写篇博客记录一下这段难忘的经历。
真是郁闷了半天,明明就几个步骤,却搞了半天都没搞好。后来,我现在自己电脑试了一遍,成功后再在公司电脑试了一下,终于成功啦!
一、版本说明
kettle8.2.0 Hive3.1.2 Hadoop3.1.3
二、前提
Hadoop、Hive因为是环境搭建测试,所以就只是单机版,没有搭建集群
1.在Kettle连接Hive之前,Hadoop和Hive、Hbase等必须安装好
2.Hive的hiveserver2还可以后台启动远程访问
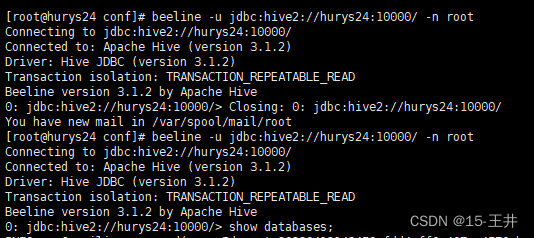
3.注意kettle8.2里MySQL驱动包的版本以及hive312里MySQL驱动包的版本
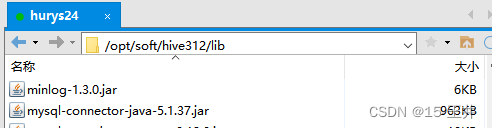
3.1 Hive312的lib里面MySQL驱动包的版本是mysql-connector-java-5.1.37.jar
3.2 Kettle8.2的lib里面我放了2个MySQL驱动包,一个高版本,一个普通版本,为了防止出现驱动包不匹配
mysql-connector-java-8.0.30.jar ; mysql-connector-java-5.1.49-bin.jar

三、开始步骤
(一)根据你的Hadoop、hive安装版本,在D:\java\kettle\pdi-ce-8.2.0.0-342\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations选择相应的文件
这个很重要!!!千万不要随便选
Hadoop、Hive版本hadoop-configurations对应文件夹Hive3.1.2 Hadoop3.1.3hdp30Hadoop260-cdh、hive110-cdhcdh514
这两个版本我都亲测过,我自己电脑之前 安装的是Hadoop260-cdh、hive110-cdh,所以我在自己电脑选的文件是cdh514;公司服务器上安装的版本是Hive3.1.2 Hadoop3.1.3,所以我在公司电脑里选的文件是hdp30
这里就展示公司服务器里选择修改文件夹hdp30,从而实现kettle8.2连接hive3.1.2
(二)修改kettle里pentaho-big-data-plugin文件夹里的源文件plugin.properties
文件路径:D:\java\kettle\pdi-ce-8.2.0.0-342\data-integration\plugins\pentaho-big-data-plugin
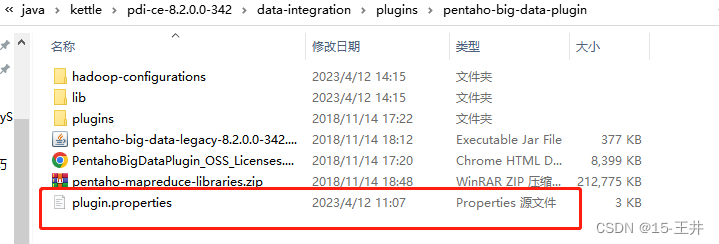
只要设置 active.hadoop.configuration=hdp30

(三)从我们安装的Hadoop、hive、hbase里拉取需要的文件从而替代hdp30文件里的原有文件
主要替换6个文件
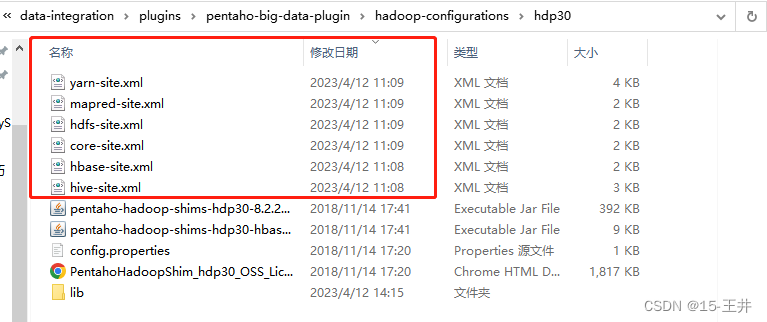
Hadoop4个文件: yarn-site.xml、mapred-site.xml、hdfs-site.xml、core-site.xml
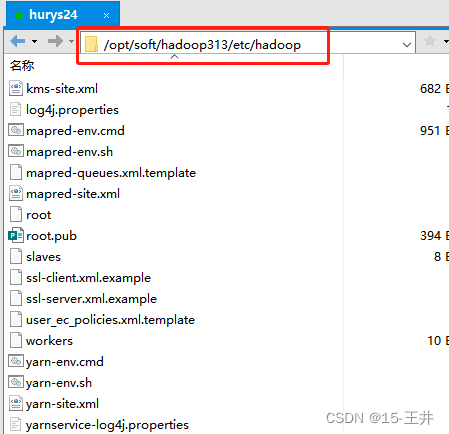
Hive1个文件: hive-site.xml
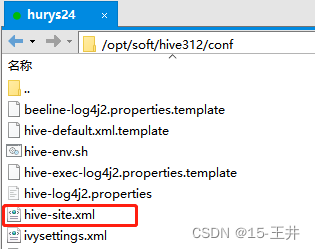
HBase1个文件: hbase-site.xml
成果如下图,结束后可以按照修改日期排序确认一下
(四)从Hive安装路径的lib目录复制以hive开头的jar包,并替换hdp30\lib里hive开头的jar包
kettle替换jar包文件路径:D:\java\kettle\pdi-ce-8.2.0.0-342\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30\lib
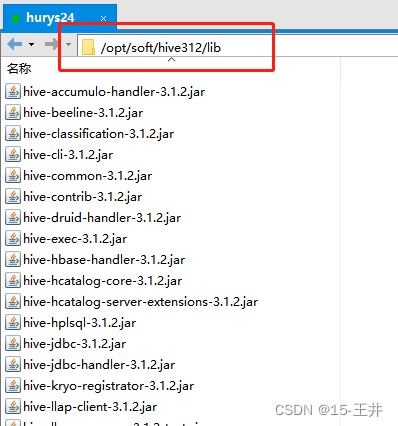
步骤说明:在hdp30\lib的文件夹下,先删除原本自带的hive开头的jar包,然后把我们Hive312里lib目录下的hive开头的jar包全都复制过去
注意:不是像MySQL驱动包直接放在kettle的lib文件下,hive的驱动jar包要放在hdp30\lib的文件夹下
1.Hive312里lib目录,里面hive开头的jar包都要
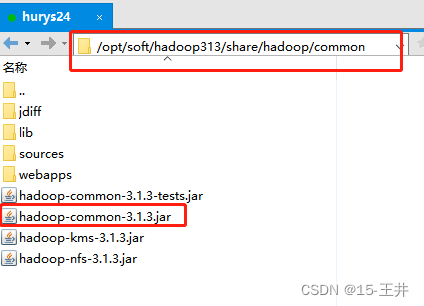
2.在hdp30\lib的文件夹下,除了复制hive312里lib目录下hive开头的jar包,为了后面Hadoop的操作,最好现在一起复制一下Hadoop安装路径里的 hadoop-common-3.1.3.jar
jar包路径: /opt/soft/hadoop313/share/hadoop/common
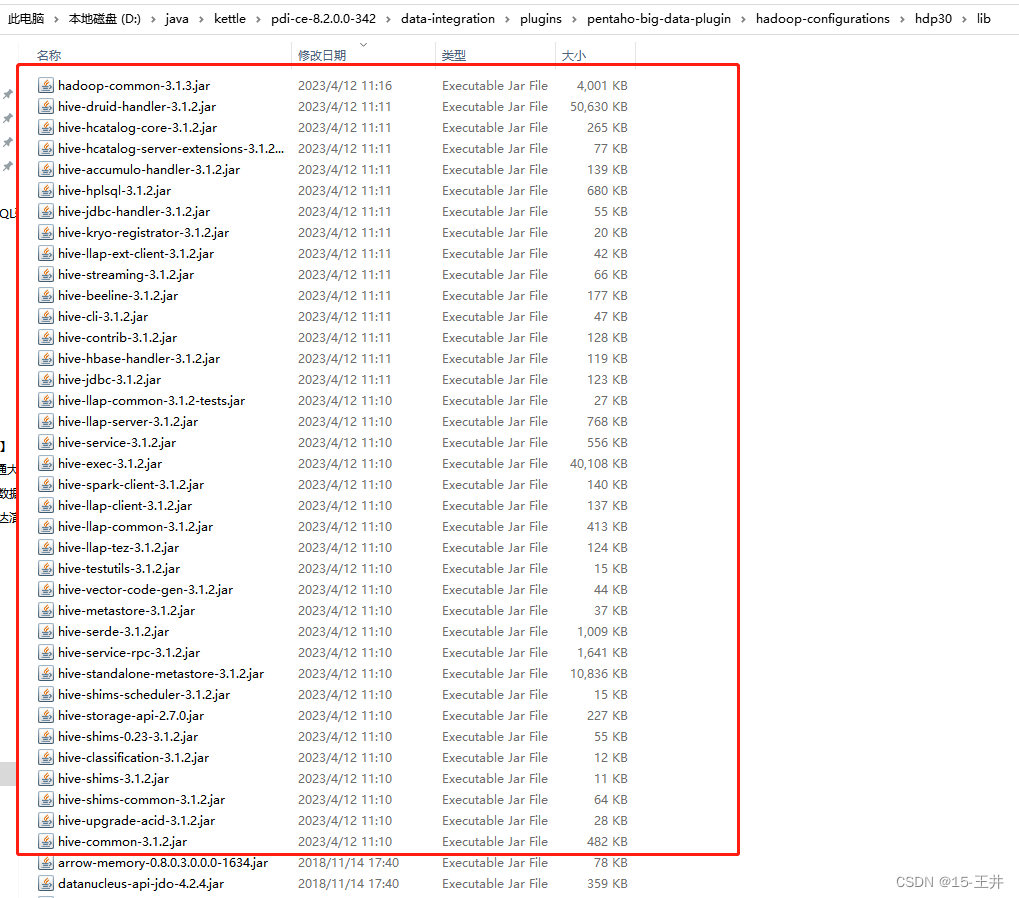
3.最后, 在hdp30\lib的文件夹下,需要复制的jar截图如下
(五)这些准备好后,开启Hadoop服务和hiveserver2服务
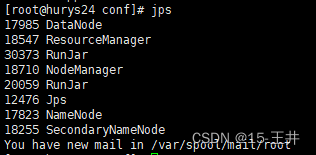
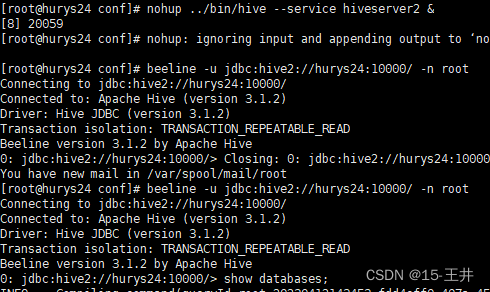
(六)开启kettle,创建hive2数据库连接
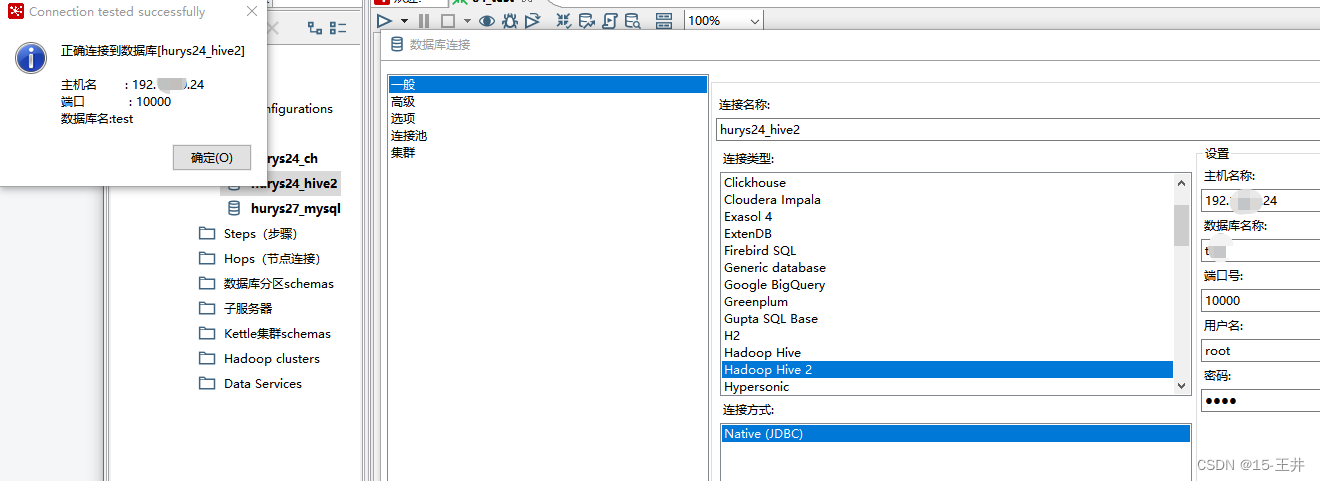
创建成功!
乐于奉献共享,共助你我他!!!
版权归原作者 天地风雷水火山泽 所有, 如有侵权,请联系我们删除。