
什么是****hbase
1.1****简介
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。
HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。
HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案
**1.2.**特点
- 易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于运算能力(RegionServer) 的扩展,通过增加 RegionSever 节点的数量,提升 Hbase 上层的处理能力;另一个是基于存储能力的扩展(HDFS),通过增加 DataNode 节点数量对存储层的进行扩容,提升 HBase 的数据存储能力。
- 海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
- 列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
- 高可靠性
WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
- 稀疏性
在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
- 模块组成
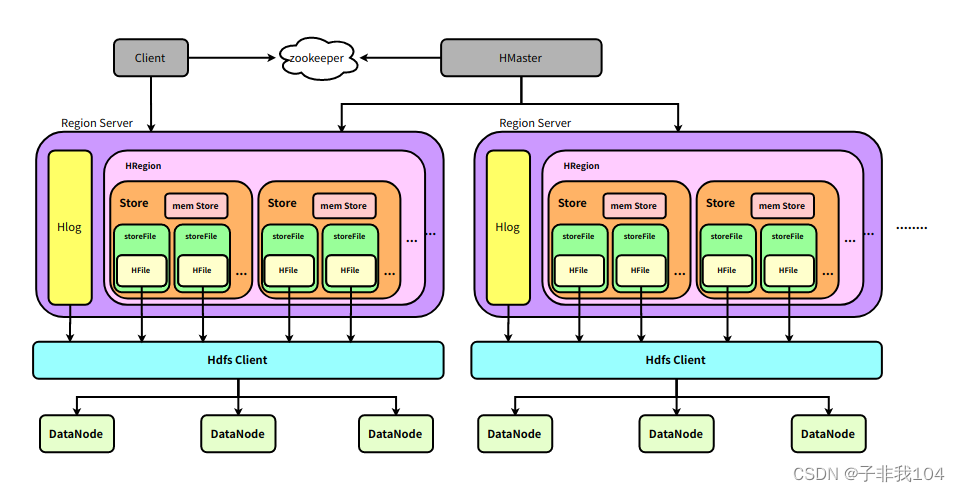
HBase 可以将数据存储在本地文件系统,也可以存储在 HDFS 文件系统。在生产环境中,HBase 一般运行在HDFS 上,以 HDFS 作为基础的存储设施。HBase 通过 HBase Client 提供的 Java API 来访问 HBase 数据库,以完成数据的写入和读取。HBase 集群主由HMaster、Region Server 和 ZooKeeper 组成。
**1.3.**使用场景
HBase擅长于存储结构简单的海量数据但索引能力有限,而Oracle,mysql等传统关系型数据库(RDBMS)能够提供丰富的查询能力,但却疲于应对TB级别的海量数据存储,HBase对传统的RDBMS并不是取代关系,而是一种补充。
适合使用** **对于关系型数据库的一种补充,而不是替代
数据库中的很多列都包含了很多空字段(稀疏数据),在 HBase 中的空字段不会像在关系型数据库中占用空间。
需要很高的吞吐量,瞬间写入量很大。
数据有很多版本需要维护,HBase 利用时间戳来区分不同版本的数据。
具有高可扩展性,能动态地扩展整个存储系统。
比如:用户画像(给用户打标签),搜索引擎应用,存储用户交互数据等
不适合使用
需要数据分析,比如报表(rowkey) 对sql支持不好
单表数据不超过千万(数据量小)
1.4hbase****的架构
HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
client
提供了访问hbase的接口
提供cache缓存提高访问hbase的效率 , 比如region的信息
Zookeeper
保证任何时候,集群中只有一个 Master;
存储所有 Region 的寻址入口;
实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master
为 Region Server 分配 Region;
负责 Region Server 的负载均衡 ;
发现失效的 Region Server 并重新分配其上的 Region;
GFS 上的垃圾文件回收;
处理 Schema 的更新请求
Region Server
Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
Region Server 负责切分在运行过程中变得过大的 Region
客户端操作
shell****客户端
HBase****数据模型概念:
在hive表或者mysql表中说描述哪一个数据都是说的哪个库里面的哪张表里面的哪一行数据中的哪一列,才能定位到这个数据
但是在hbase中没有库的概念,说一个数据说的是哪一个名称空间下的那一张表下的哪一个行键的哪一个列族下面的哪一个列对应的是这个数据
namespace:doit
table:user_info
Rowkey
Column Family1****(列族)
Column Family2****(列族)
id
Name
age
gender
phoneNum
address
job
code
rowkey_001
1
柳岩
18
女
88888888
北京....
演员
123
rowkey_002
2
唐嫣
38
女
66666666
上海....
演员
213
rowkey_003
3
大郎
8
男
44444444
南京....
销售
312
rowkey_004
4
金莲
33
女
99999999
东京....
销售
321
...
**namespace:**hbase中没有数据库的概念 , 是使用namespace来达到数据库分类别管理表的作用
table****:表,一个表包含多行数据
Row Key (行键):一行数据包含一个唯一标识rowkey、多个column以及对应的值。在HBase中,一张表中所有row都按照rowkey的字典序由小到大排序。
Column Family**(列族):**在建表的时候指定,不能够随意的删减,一个列族下面可以有多个列(类似于给列进行分组,相同属性的列是一个组,给这个组取个名字叫列族)
**Column Qualifier (列):**列族下面的列,一个列必然是属于某一个列族的行
**Cell:**单元格,由(rowkey、column family、qualifier、type、timestamp,value)组成的结构,其中type表示Put/Delete操作类型,timestamp代表这个cell的版本。KV结构存储,其中rowkey、column family、qualifier、type以及timestamp是K,value字段对应KV结构的V。
**Timestamp(时间戳):**时间戳,每个cell在写入HBase的时候都会默认分配一个时间戳作为该cell的版本,用户也可以在写入的时候自带时间戳。HBase支持多版本特性,即同一rowkey、column下可以有多个value存在,这些value使用timestamp作为版本号,版本越大,表示数据越新。
进入客户端命令:
Shell
如果配置了环境变量:在任意地方敲 hbase shell,如果没有配置环境变量,需要在bin目录下**./hbase shell**
[root@linux01 conf]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/app/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/app/hbase-2.2.5/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.5, rf76a601273e834267b55c0cda12474590283fd4c, 2020年 05月 21日 星期四 18:34:40 CST
Took 0.0026 seconds
hbase(main):001:0> **--**代表成功进入了hbase的shell客户端
命令大全
通用命令** **
*status: 查看HBase*的状态,例如,服务器的数量。
Shell
hbase(main):001:0> status
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
Took 0.3609 seconds
*version: 提供正在使用HBase*版本。
Shell
hbase(main):002:0> version
2.2.5, rf76a601273e834267b55c0cda12474590283fd4c, 2020年 05月 21日 星期四 18:34:40 CST
Took 0.0004 seconds
**table_help: **表引用命令提供帮助。
Shell
关于表的一些命令参考
如:
To read the data out, you can scan the table:
hbase> t.scan
which will read all the rows in table 't'.
**whoami: **提供有关用户的信息。
Shell
hbase(main):004:0> whoami
root (auth:SIMPLE)
groups: root
Took 0.0098 seconds
命名空间相关命令
list_namespace****:列出所有的命名空间
Shell
hbase(main):005:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.0403 seconds
create_namespace****:创建一个命名空间
Shell
hbase(main):002:0> create_namespace doit
NameError: undefined local variable or method `doit' for main:Object
hbase(main):003:0> create_namespace 'doit'
Took 0.2648 seconds
注意哦:名称需要加上引号,不然会报错的
describe_namespace****:描述一个命名空间
Shell
hbase(main):004:0> describe_namespace 'doit'
DESCRIPTION
{NAME => 'doit'}
Quota is disabled
Took 0.0710 seconds
drop_namespace****:删除一个命名空间
Shell
注意 :只能删除空的命名空间,如果里面有表是删除不了的
hbase(main):005:0> drop_namespace 'doit'
Took 0.2461 seconds
--命名空间不为空的话
hbase(main):035:0> drop_namespace 'doit'
ERROR: org.apache.hadoop.hbase.constraint.ConstraintException: Only empty namespaces can be removed. Namespace doit has 1 tables
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.prepareDelete(DeleteNamespaceProcedure.java:217)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:78)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:45)
at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:194)
at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:962)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1662)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.executeProcedure(ProcedureExecutor.java:1409)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$1100(ProcedureExecutor.java:78)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.run(ProcedureExecutor.java:1979)
For usage try 'help "drop_namespace"'
Took 0.1448 seconds
alter_namespace:修改namespace****其中属性
Shell
hbase(main):038:0> alter_namespace 'doit',{METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
Took 0.2491 seconds
list_namespace_tables:列出一个命名空间下所有的表
Shell
hbase(main):037:0> list_namespace_tables 'doit'
TABLE
user
1 row(s)
Took 0.0372 seconds
=> ["user"]
DDL****相关命令
**list:**列举出默认名称空间下所有的表
Shell
hbase(main):001:0> list
TABLE
doit:user
1 row(s)
Took 0.3187 seconds
=> ["doit:user"]
**create:**建表
Shell
create ‘xx:t1’,{NAME=>‘f1’,VERSION=>5}
创建表t1并指明命名空间xx
{NAME} f1指的是列族
VERSION 表示版本数
多个列族f1、f2、f3
create ‘t2’,{NAME=>‘f1’},{NAME=>‘f2’},{NAME=>‘f3’}
hbase(main):003:0> create 'doit:student' 'f1','f2','f3'
Created table doit:studentf1
Took 1.2999 seconds
=> Hbase::Table - doit:studentf1
创建表得时候预分region
hbase(main):106:0> create 'doit:test','f1', SPLITS => ['rowkey_010','rowkey_020','rowkey_030','rowkey_040']
Created table doit:test
Took 1.3133 seconds
=> Hbase::Table - doit:test
**drop:**删除表
Shell
hbase(main):006:0> drop 'doit:studentf1'
ERROR: Table doit:studentf1 is enabled. Disable it first.
For usage try 'help "drop"'
Took 0.0242 seconds
注意哦:删除表之前需要禁用表
hbase(main):007:0> disable 'doit:studentf1'
Took 0.7809 seconds
hbase(main):008:0> drop 'doit:studentf1'
Took 0.2365 seconds
hbase(main):009:0>
drop_all:丢弃在命令中给出匹配“regex”****的表
Shell
hbase(main):023:0> disable_all 'doit:student.*'
doit:student1
doit:student2
doit:student3
doit:studentf1
Disable the above 4 tables (y/n)?
y
4 tables successfully disabled
Took 4.3497 seconds
hbase(main):024:0> drop_all 'doit:student.*'
doit:student1
doit:student2
doit:student3
doit:studentf1
Drop the above 4 tables (y/n)?
y
4 tables successfully dropped
Took 2.4258 seconds
disable****:禁用表
Shell
删除表之前必须先禁用表
hbase(main):007:0> disable 'doit:studentf1'
Took 0.7809 seconds
disable_all:禁用在命令中给出匹配“regex”****的表
Shell
hbase(main):023:0> disable_all 'doit:student.*'
doit:student1
doit:student2
doit:student3
doit:studentf1
Disable the above 4 tables (y/n)?
y
4 tables successfully disabled
Took 4.3497 seconds
enable****:启用表
Shell
删除表之前必须先禁用表
hbase(main):007:0> enable 'doit:student'
Took 0.7809 seconds
enable_all:启用在命令中给出匹配“regex”****的表
Shell
hbase(main):032:0> enable_all 'doit:student.*'
doit:student
doit:student1
doit:student2
doit:student3
doit:student4
Enable the above 5 tables (y/n)?
y
5 tables successfully enabled
Took 5.0114 seconds
is_enabled****:判断该表是否是启用的表
Shell
hbase(main):034:0> is_enabled 'doit:student'
true
Took 0.0065 seconds
=> true
is_disabled****:判断该表是否是禁用的表
Shell
hbase(main):035:0> is_disabled 'doit:student'
false
Took 0.0046 seconds
=> 1
describe****:描述这张表
Shell
hbase(main):038:0> describe 'doit:student'
Table doit:student is ENABLED
doit:student
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLO
CK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE
_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'f2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLO
CK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE
_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'f3', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLO
CK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE
_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
3 row(s)
QUOTAS
0 row(s)
Took 0.0349 seconds
VERSIONS => '1', -- 版本数量
EVICT_BLOCKS_ON_CLOSE => 'false',
NEW_VERSION_BEHAVIOR => 'false',
KEEP_DELETED_CELLS => 'FALSE', 保留删除的单元格
CACHE_DATA_ON_WRITE => 'false',
DATA_BLOCK_ENCODING => 'NONE',
TTL => 'FOREVER', -- 过期时间
MIN_VERSIONS => '0', -- 最小版本数
REPLICATION_SCOPE => '0',
BLOOMFILTER => 'ROW', --布隆过滤器
CACHE_INDEX_ON_WRITE => 'false',
IN_MEMORY => 'false', -- 内存中
CACHE_BLOOMS_ON_WRITE => 'false', --布隆过滤器
PREFETCH_BLOCKS_ON_OPEN => 'false',
COMPRESSION => 'NONE', -- 压缩格式
BLOCKCACHE => 'true', -- 块缓存
BLOCKSIZE => '65536' -- 块大小
alter****:修改表里面的属性
Shell
hbase(main):040:0> alter 'doit:student', NAME => 'cf1', VERSIONS => 5, TTL => 10
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.1406 seconds
alter_async:直接操作不等待,和上面的alter****功能一样
Shell
hbase(main):059:0> alter_async 'doit:student', NAME => 'cf1', VERSIONS => 5, TTL => 10
Took 1.0268 seconds
alter_status:获取alter****命令的执行状态
Shell
hbase(main):060:0> alter_status 'doit:student'
1/1 regions updated.
Done.
Took 1.0078 seconds
list_regions:列出一个表中所有的region
Shell
Examples:
hbase> list_regions 'table_name'
hbase> list_regions 'table_name', 'server_name'
hbase> list_regions 'table_name', {SERVER_NAME => 'server_name', LOCALITY_THRESHOLD => 0.8}
hbase> list_regions 'table_name', {SERVER_NAME => 'server_name', LOCALITY_THRESHOLD => 0.8}, ['SERVER_NAME']
hbase> list_regions 'table_name', {}, ['SERVER_NAME', 'start_key']
hbase> list_regions 'table_name', '', ['SERVER_NAME', 'start_key']
hbase(main):045:0> list_regions 'doit:student'
SERVER_NAME | REGION_NAME | START_KEY | END_KEY | SIZE | REQ | LOCALITY |
--------------------------- | ------------------------------------------------------------- | ---------- | ---------- | ----- | ----- | ---------- |
linux02,16020,1683636566738 | doit:student,,1683642944714.39f7c8772bc476c4d38c663e879d50da. | | | 0 | 0 | 0.0 |
1 rows
Took 0.0145 seconds
locate_region:通过表名和row名方式获取region
Shell
hbase(main):062:0> locate_region 'doit:student', 'key0'
HOST REGION
linux02:16020 {ENCODED => 39f7c8772bc476c4d38c663e879d50da, NAME => 'doit:student,,1683642944714.39f7c8772bc476c4d38c663e879d50da.', STARTKEY => '', ENDK
EY => ''}
1 row(s)
Took 0.0027 seconds
show_filters:显示hbase****的所有的过滤器
Shell
hbase(main):058:0> show_filters
DependentColumnFilter
KeyOnlyFilter
ColumnCountGetFilter
SingleColumnValueFilter
PrefixFilter
SingleColumnValueExcludeFilter
FirstKeyOnlyFilter
ColumnRangeFilter
ColumnValueFilter
TimestampsFilter
FamilyFilter
QualifierFilter
ColumnPrefixFilter
RowFilter
MultipleColumnPrefixFilter
InclusiveStopFilter
PageFilter
ValueFilter
ColumnPaginationFilter
Took 0.0035 seconds
DML****相关命令
put**插入/**更新数据【某一行的某一列】(如果不存在,就插入,如果存在就更新)
Shell
hbase(main):007:0> put 'doit:user_info' ,'rowkey_001','f1:name','zss'
Took 0.0096 seconds
hbase(main):008:0> put 'doit:user_info' ,'rowkey_001','f1:age','1'
Took 0.0039 seconds
hbase(main):009:0> put 'doit:user_info' ,'rowkey_001','f1:gender','male'
Took 0.0039 seconds
hbase(main):010:0> put 'doit:user_info' ,'rowkey_001','f2:phone_num','98889'
Took 0.0040 seconds
hbase(main):011:0> put 'doit:user_info' ,'rowkey_001','f2:gender','98889'
注意:put中需要指定哪个命名空间的那个表,然后rowkey是什么,哪个列族下面的哪个列名,然后值是什么
一个个的插入,不能一下子插入多个列名的值
get:获取一个列族中列这个cell
Shell
hbase(main):015:0> get 'doit:user_info' ,'rowkey_001','f2:gender'
COLUMN CELL
f2:gender timestamp=1683646645379, value=123
1 row(s)
Took 0.0242 seconds
hbase(main):016:0> get 'doit:user_info' ,'rowkey_001'
COLUMN CELL
f1:age timestamp=1683646450598, value=1
f1:gender timestamp=1683646458847, value=male
f1:name timestamp=1683646443469, value=zss
f2:gender timestamp=1683646645379, value=123
f2:phone_num timestamp=1683646472508, value=98889
1 row(s)
Took 0.0129 seconds
如果遇到中文乱码的问题怎么办呢?在最后加上{'FORMATTER'=>'toString'}参数即可
hbase(main):137:0> get 'doit:student','rowkey_001',{'FORMATTER'=>'toString'}
COLUMN CELL
f1:name timestamp=1683864047691, value=张三
1 row(s)
Took 0.0057 seconds
注意:get是hbase中查询数据最快的方式,但是只能每次返回一个rowkey的数据
scan****:扫描表中的所有数据
Shell
hbase(main):012:0> scan 'doit:user_info'
ROW COLUMN+CELL
rowkey_001 column=f1:age, timestamp=1683646450598, value=1
rowkey_001 column=f1:gender, timestamp=1683646458847, value=male
rowkey_001 column=f1:name, timestamp=1683646443469, value=zss
rowkey_001 column=f2:gender, timestamp=1683646483495, value=98889
rowkey_001 column=f2:phone_num, timestamp=1683646472508, value=98889
1 row(s)
Took 0.1944 seconds
scan 'tbname',{Filter(过滤器)}
scan 'itcast:t2'
#rowkey前缀过滤器
scan 'itcast:t2', {ROWPREFIXFILTER => '2021'}
scan 'itcast:t2', {ROWPREFIXFILTER => '202101'}
#rowkey范围过滤器
#STARTROW:从某个rowkey开始,包含,闭区间
#STOPROW:到某个rowkey结束,不包含,开区间
scan 'itcast:t2',{STARTROW=>'20210101_000'}
scan 'itcast:t2',{STARTROW=>'20210201_001'}
scan 'itcast:t2',{STARTROW=>'20210101_000',STOPROW=>'20210201_001'}
scan 'itcast:t2',{STARTROW=>'20210201_001',STOPROW=>'20210301_007'}
|- 在Hbase数据检索,==尽量走索引查询:按照Rowkey条件查询==
尽量避免走全表扫描
- 索引查询:有一本新华字典,这本字典可以根据拼音检索,找一个字,先找目录,找字
- 全表扫描:有一本新华字典,这本字典没有检索目录,找一个字,一页一页找
==Hbase所有Rowkey的查询都是前缀匹配==
如果遇到中文乱码的问题怎么办呢?在最后加上{'FORMATTER'=>'toString'}参数即可
hbase(main):130:0> scan 'doit:student',{'FORMATTER'=>'toString'}
ROW COLUMN+CELL
rowkey_001 column=f1:name, timestamp=1683863389259, value=张三
1 row(s)
Took 0.0063 seconds
incr****:一般用于自动计数的,不用记住上一次的值,直接做自增
Shell
注意哦:因为shell往米面设置的value的值是String类型的
hbase(main):005:0> incr 'doit:student','rowkey002', 'f1:age'
COUNTER VALUE = 1
Took 0.1877 seconds
hbase(main):006:0> incr 'doit:student','rowkey002', 'f1:age'
COUNTER VALUE = 2
Took 0.0127 seconds
hbase(main):007:0> incr 'doit:student','rowkey002', 'f1:age'
COUNTER VALUE = 3
Took 0.0079 seconds
hbase(main):011:0> incr 'doit:student','rowkey002', 'f1:age'
COUNTER VALUE = 4
Took 0.0087 seconds
count****:统计一个表里面有多少行数据
Shell
hbase(main):031:0> count 'doit:user_info'
1 row(s)
Took 0.0514 seconds
=> 1
delete****删除某一行中列对应的值
Shell
删除某一行中列对应的值
hbase(main):041:0> delete 'doit:student' ,'rowkey_001','f1:id'
Took 0.0152 seconds
deleteall****:删除一行数据
Shell
根据rowkey删除一行数据
hbase(main):042:0> deleteall 'doit:student','rowkey_001'
Took 0.0065 seconds
append****:追加,假如该列不存在添加新列,存在将值追加到最后
Shell
再原有值得基础上追加值
hbase(main):098:0> append 'doit:student','rowkey_001','f1:name','hheda'
CURRENT VALUE = zsshheda
Took 0.0070 seconds
hbase(main):100:0> get 'doit:student','rowkey_001','f1:name'
COLUMN CELL
f1:name timestamp=1683861530789, value=zsshheda
1 row(s)
Took 0.0057 seconds
#注意:如果原来没有这个列,会自动添加一个列,然后将值set进去
hbase(main):101:0> append 'doit:student','rowkey_001','f1:name1','hheda'
CURRENT VALUE = hheda
Took 0.0063 seconds
hbase(main):102:0> get 'doit:student','rowkey_001','f1:name1'
COLUMN CELL
f1:name1 timestamp=1683861631392, value=hheda
1 row(s)
Took 0.0063 seconds
truncate****:清空表里面所有的数据
Shell
#执行流程
先disable表
然后再drop表
最后重新create表
hbase(main):044:0> truncate 'doit:student'
Truncating 'doit:student' table (it may take a while):
Disabling table...
Truncating table...
Took 2.5457 seconds
**truncate_preserve:**清空表但保留分区
Shell
hbase(main):008:0> truncate_preserve 'doit:test'
Truncating 'doit:test' table (it may take a while):
Disabling table...
Truncating table...
Took 4.1352 seconds
hbase(main):009:0> list_regions 'doit:test'
SERVER_NAME | REGION_NAME | START_KEY | END_KEY | SIZE | REQ | LOCALITY |
--------------------------- | -------------------------------------------------------------------- | ---------- | ---------- | ----- | ----- | ---------- |
linux03,16020,1684200651855 | doit:test,,1684205468848.920ae3e043ad95890c4f5693cb663bc5. | | rowkey_010 | 0 | 0 | 0.0 |
linux01,16020,1684205091382 | doit:test,rowkey_010,1684205468848.f8a21615be51f42c562a2338b1efa409. | rowkey_010 | rowkey_020 | 0 | 0 | 0.0 |
linux02,16020,1684200651886 | doit:test,rowkey_020,1684205468848.25d62e8cc2fdaecec87234b8d28f0827. | rowkey_020 | rowkey_030 | 0 | 0 | 0.0 |
linux03,16020,1684200651855 | doit:test,rowkey_030,1684205468848.2b0468e6643b95159fa6e210fa093e66. | rowkey_030 | rowkey_040 | 0 | 0 | 0.0 |
linux01,16020,1684205091382 | doit:test,rowkey_040,1684205468848.fb12c09c7c73cfeff0bf79b5dda076cb. | rowkey_040 | | 0 | 0 | 0.0 |
5 rows
Took 0.1019 seconds
get_counter****:获取计数器
Shell
hbase(main):017:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 1
Took 0.0345 seconds
hbase(main):018:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 2
Took 0.0066 seconds
hbase(main):019:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 3
Took 0.0059 seconds
hbase(main):020:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 4
Took 0.0061 seconds
hbase(main):021:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 5
Took 0.0064 seconds
hbase(main):022:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 6
Took 0.0062 seconds
hbase(main):023:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 7
Took 0.0066 seconds
hbase(main):024:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 8
Took 0.0059 seconds
hbase(main):025:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 9
Took 0.0063 seconds
hbase(main):026:0> incr 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 10
Took 0.0061 seconds
hbase(main):027:0> get_counter 'doit:student','rowkey_001','f1:name2'
COUNTER VALUE = 10
Took 0.0040 seconds
hbase(main):028:0>
get_splits:用于获取表所对应的region****数个数
Shell
hbase(main):148:0> get_splits 'doit:test'
Total number of splits = 5
rowkey_010
rowkey_020
rowkey_030
rowkey_040
Took 0.0120 seconds
=> ["rowkey_010", "rowkey_020", "rowkey_030", "rowkey_040"]
尖叫总结:实际生产中很少通过hbase shell去操作hbase,更多的是学习测试,问题排查等等才会使用到hbase shell ,hbase总的来说就是写数据,然后查询。前者是通过API bulkload等形式写数据,后者通过api****调用查询。
版权归原作者 子非我104 所有, 如有侵权,请联系我们删除。