
文章目录
Flink初次见面
什么是Flink?
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments,perform computations at in-memory speed and at any scale.
Flink的世界观是数据流,对Flink而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已,所以Flink也是一款真正的流批统一的计算引擎。
什么是Unbounded streams?
无界流:有定义流的开始,但没有定义流的结束。它们会无休止的产生数据。无界流的数据必须持续处理,即数据被摄取后需要立即处理。我们不能等到所有数据都到达后再进行处理,因为输入是无限的,在任何时候输入都不会结束。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
什么是Bounded streams?
有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流中所有数据可以被再次排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
无界流和有界流: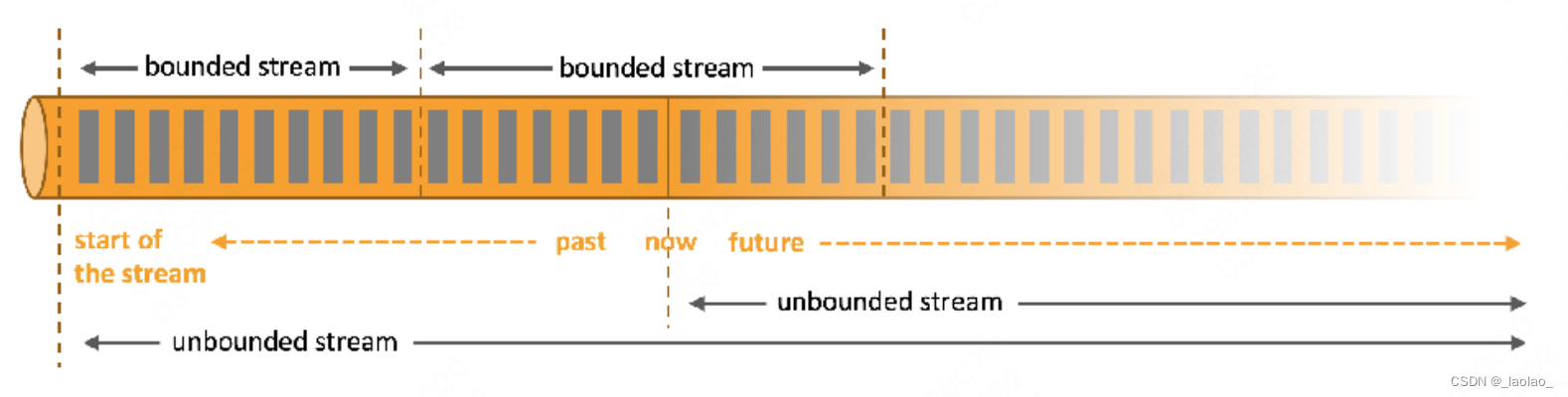
什么是stateful computations?
有状态的计算: 每次进行数据计算的时候都会基于之前数据的计算结果(状态)做计算,并且每次的计算结果会报存在存储介质中,即每次计算都会产生or影响状态。基于有状态的计算不需要将历史数据重新计算,提高了计算效率。
无状态的计算: 每次进行数据计算时都仅和当前数据有关,和其之前的数据无关。即每次的数据处理都是独立的。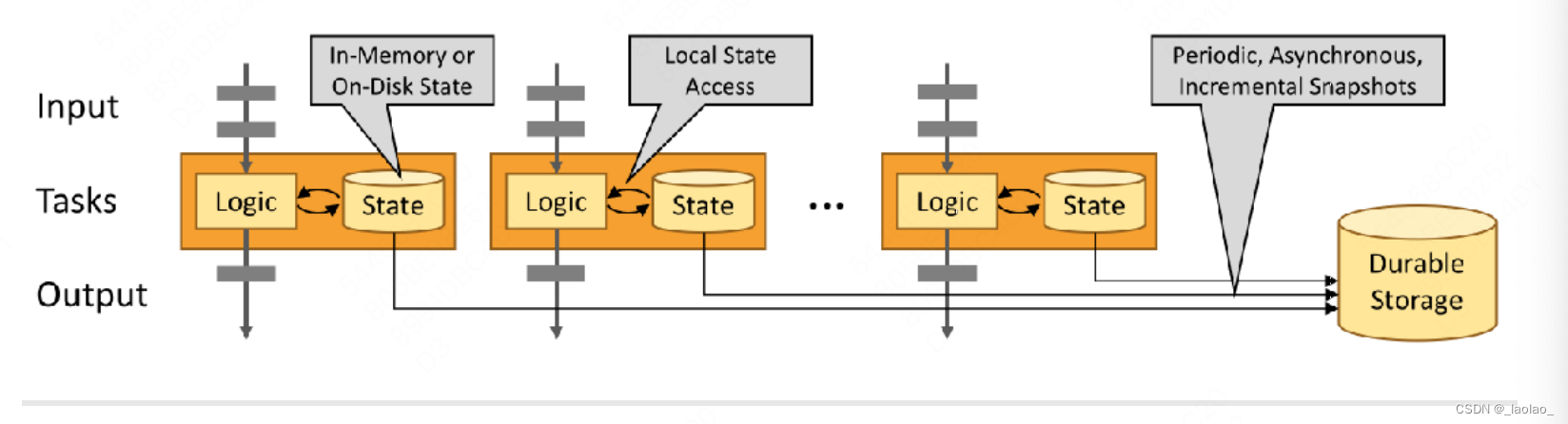
Flink使用用户
自2019年1月起,阿里逐步将内部维护的Blink回馈给Flink开源社区,目前贡献的代码数量已经超过了100W行。国内腾讯、百度、字节等公司,国外Uber、Netflix等公司都是Flink的使用者。
Flink的特点和优势
- 同时支持高吞吐、低延迟、高性能
- 支持事件时间(Event Time)概念,结合Watermark处理乱序数据。(Watermark=当前观测到的最大事件时间-最大延迟时间-1ms)
- 支持有状态计算,并且支持多种状态后端。内存、文件、RocksDB
- 支持高度灵活的窗口(Window)操作。time、count、session
- 基于轻量级分布式快照(Checkpoint)实现的容错,保证exactly-once语义 Chandy-Lamport算法 分布式快照算法_bilibili Chandy-Lamport算法核心解读 Flink详解Exactly-Once机制(端到端) Flink实现Exactly once
- 基于JVM实现独立的内存管理(subtask独占一个taskslot,内存隔离,共享cpu)
- save points(保存点)
Flink安装&部署
Flink基本架构
Flink系统架构中包含了两个角色,分别是JobManager和TaskManager,是一个典型的Master-Slave架构。其中JobManager是Master,TaskManager是SLAVE。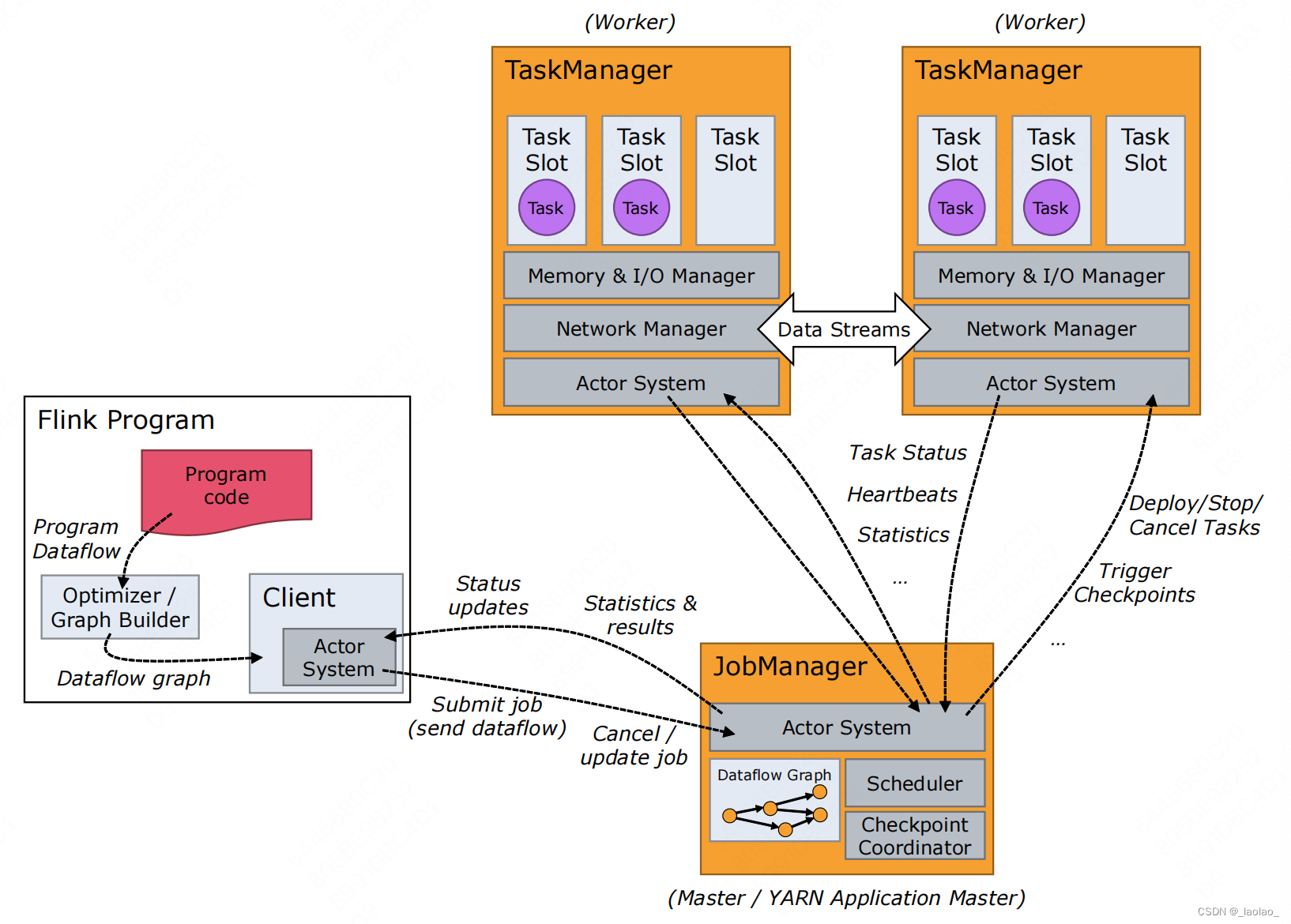
JobManager(JVM进程)作用
JobManager负责整个集群的资源管理与任务管理,在一个集群中只能有一个正在工作(active)的JobManager,如果是HA集群,那么其他JM一定是Standby状态。
1.资源调度
- 集群启动时,TM会将当前节点的资源信息注册给JM,所有TM全部注册完毕后,集群启动成功,此时JM就掌握了整个集群的资源情况
- client提交Application给JM,JM会根据集群中的资源情况,为当前的Application分配TaskSlot资源
2.任务调度
- 根据各个TaskManager节点上的资源分发task到TaskSlot中运行
- Job执行过程中,JobManager会根据设置的触发策略触发checkpoint,通知TaskManager开始制作checkpoint
- 任务执行完毕后,JobManager会将Job执行的信息反馈给client,并且释放TaskManager资源
TaskManager(JVM进程)作用
- 负责当前节点上的任务运行及当前节点上的资源管理,TaskManager将资源通过TaskSlot进行了划分,每个TaskSlot代表的是一份固定资源。例如,具有三个slots的TaskManager会将其管理的内存资源分成三等份给每个slot。划分资源意味着subtask之间不会竞争内存资源,但是也意味着它们只拥有固定的资源,不能抢占彼此的内存资源。注意这里并没有CPU隔离,当前slots之间只是划分了任务的内存资源
- 负责TaskManager之间的数据交换
client客户端
- 负责将要执行的任务提交给JobManager,提交任务的常用方式有:flink命令提交,flink ui页面提交。
- 获取任务的执行信息
Standalone集群安装&测试
Standalone是flink的独立部署模式,它不依赖其他任何平台,不依赖任何的资源调度框架。
Standalone集群是由JobManager、TaskManager两个JVM进程组成
集群角色划分
node01node02node03node04JobManagerTaskManagerTaskManagerTaskManager
安装步骤
1.官网下载Flink安装包
Apache Flink® 1.10.0 is our latest stable release。现在最稳定的是1.10.0,但是不建议采用这个版本,因为Flink刚从1.9升级到1.10,会存在一些bug,不建议采用小版本号为0的安装包,所以我们建议使用1.9.2版本。
下载链接:https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.2/flink-1.9.2-bin-scala_2. 11.tgz
2.安装包上传到node01节点
3.解压、修改配置文件
解压:tar -zxvf flink-1.9.2-bin-scala_2.11.tgz
修改flink-conf.yaml配置文件:
jobmanager.rpc.address: node01 JobManager rpc通信地址
jobmanager.rpc.port: 6123 JobManagerRPC通信端口
jobmanager.heap.size: 1024m JobManager所能使用的堆内存大小
taskmanager.heap.size: 1024m TaskManager所能使用的堆内存大小
taskmanager.numberOfTaskSlots: 2 TaskManager管理的TaskSlot个数,依据当前物理机的
核心数来配置,一般预留出一部分核心(25%)给系统及其他进程使用,一个slot对应一个core。如果
core支持超线程,那么slot个数*2
rest.port: 8081 指定WebUI的访问端口
修改slaves配置文件(这里直接写nodexx的前提是每台机器的hosts文件都已经做好了域名->ip地址的映射):
node02
node03
node04
4.同步安装包到其他节点(这里的前提是已经配好了ssh免密登陆)
例:同步到node02
scp-r /path/flink username@node2:/path/flink
5.node01配置环境变量
vim ~/.bashrc
exportFLINK_HOME=/opt/software/flink/flink-1.9.2
exportPATH=$PATH:$FLINK_HOME/bin
:wq
source ~/.bashrc
6.启动standalone集群
启动集群:start-cluster.sh
关闭集群:stop-cluster.sh
7.查看Flink Web UI页面
http://node01:8081/ 这里的Web UI端口号可以在JM所在机器上的flink-conf.yaml配置文件中的rest.port: 8081配置项指定
提交Job到Standalone集群
常用提交任务的方式有两种,分别是命令提交和Web页面提交
1.命令提交
flink run -c 全类名 jar包
-c:指定主类
-d:独立运行、后台运行
-p:指定并行度
2.Web页面提交
可以在Flink Web UI中提交flink作业,指定jar包的位置、主类路径、并行数等即可
web.submit.enable:必须是true,否则不支持Web提交Application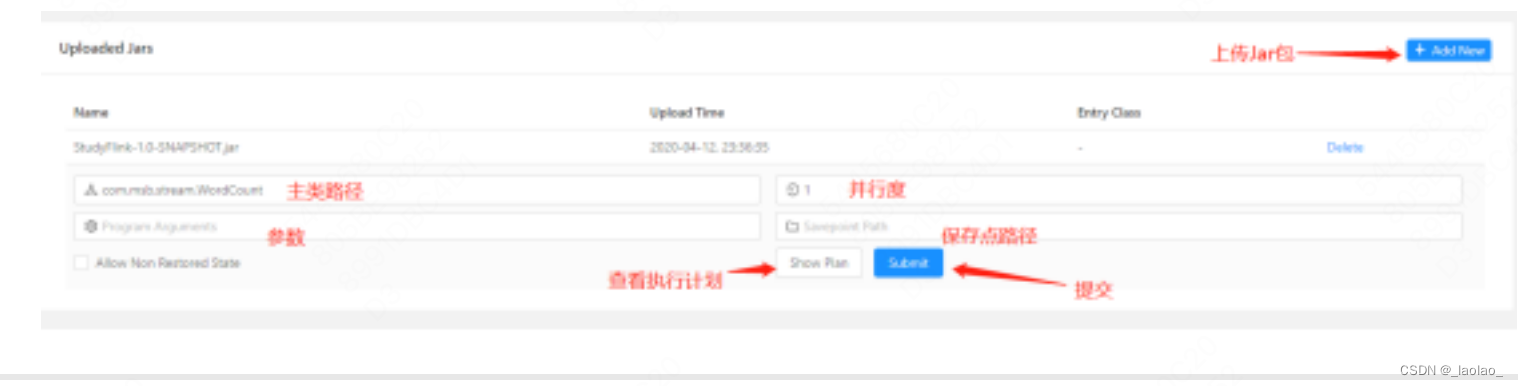
Standalone HA集群安装&测试
JobManager协调每个flink任务部署,它负责调度和资源管理。
默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF single-point-of-failure):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。
使用JobManager HA,集群可以从JobManager故障中恢复,从而避免SPOF
Standalone模式(独立模式)下JobManager的高可用性的基本思想是,任何时候都有一个Active JobManager,并且多个Standy JobManagers。Standby JobManagers可以在Master JobManager挂掉的情况下接管集群成为Master JobManager。这样保证了没有单点故障,一旦某一个Standy JobManager接管集群,程序就可以继续运行。Standy JobManager和Active JobManager实例之间没有明确区别。每个JobManager可以成为Active或Standy节点。
Flink的HA集群也有依靠zookeeper实现。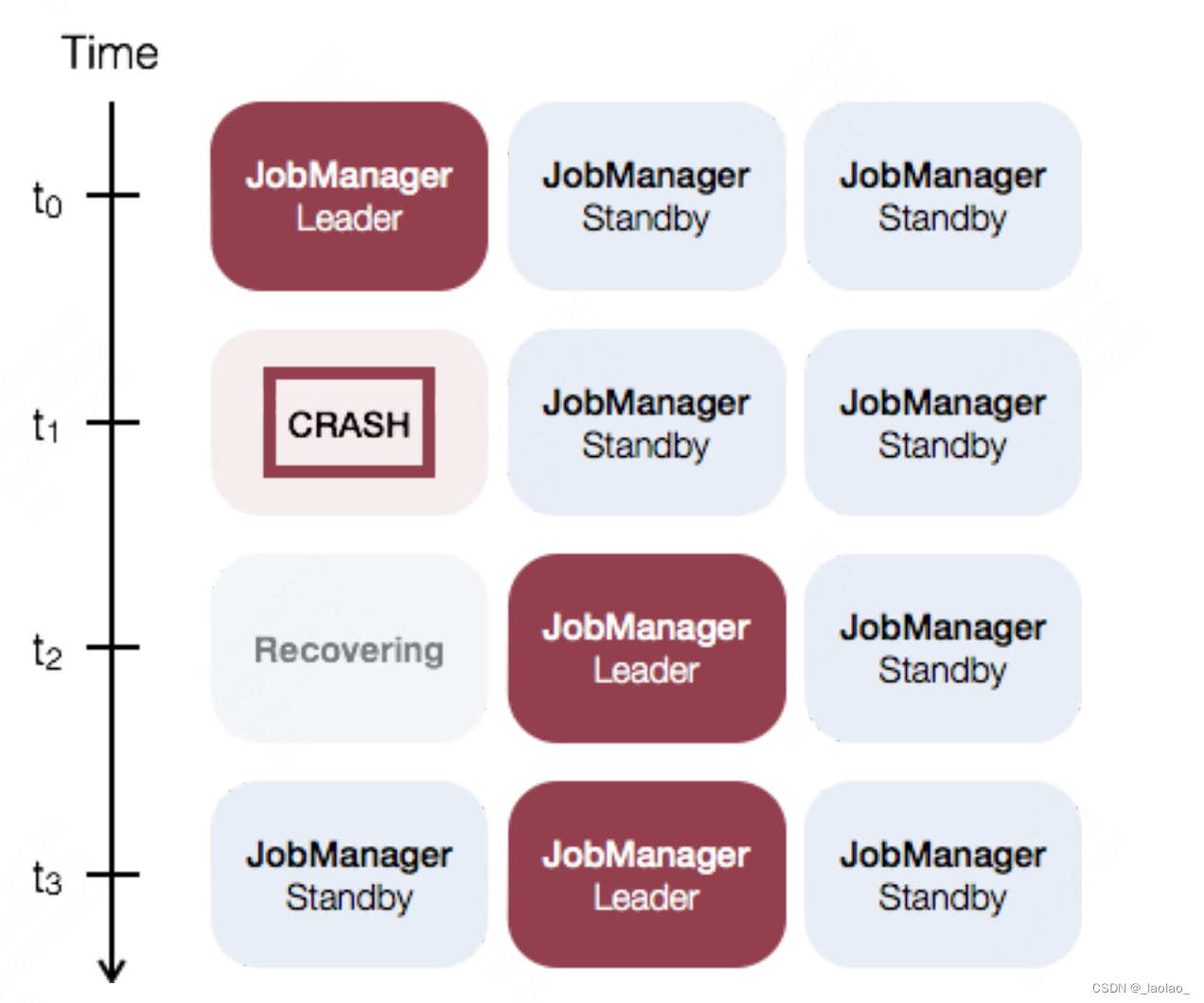
集群角色划分
node01node02node03node04JobManager✅✅❌❌TaskManager❌✅✅✅
安装步骤
1.修改配置文件conf/flink-conf.yaml
high-availability:zookeeper
# 保存JobManager恢复所需要的所有元数据信息
high-availability.storageDir:hdfs://node01:9000/flink/ha/
# zookeeper地址
high-availability.zookeeper.quorum:node01:2181,node02:2181,node03:2181
2.修改配置文件conf/masters
node01:8081
node02:8081
3.同步配置文件到各个节点
4.下载支持Hadoop插件并且拷贝到各个节点的安装包的lib目录下
下载地址:https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-%20uber/2.6.5-10.0/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar
Flink on Yarn
Flink on Yarn依托Yarn作为资源管理器,现在很多分布式任务都可以支持基于Yarn运行,这是在企业中使用最多的方式。Why?
- 基于Yarn的运行模式可以充分使用集群资源,Spark on Yarn、MapReduce on Yarn、Flink on Yarn等多套计算框架都可以基于Yarn运行,充分利用集群资源。可以发现,大数据的这些计算框架都可以依托yarn进行资源调度,所以我们不用安装多套资源管理器,安装一个yarn即可
- 给予Yarn的运行模式降低维护成本
运行流程
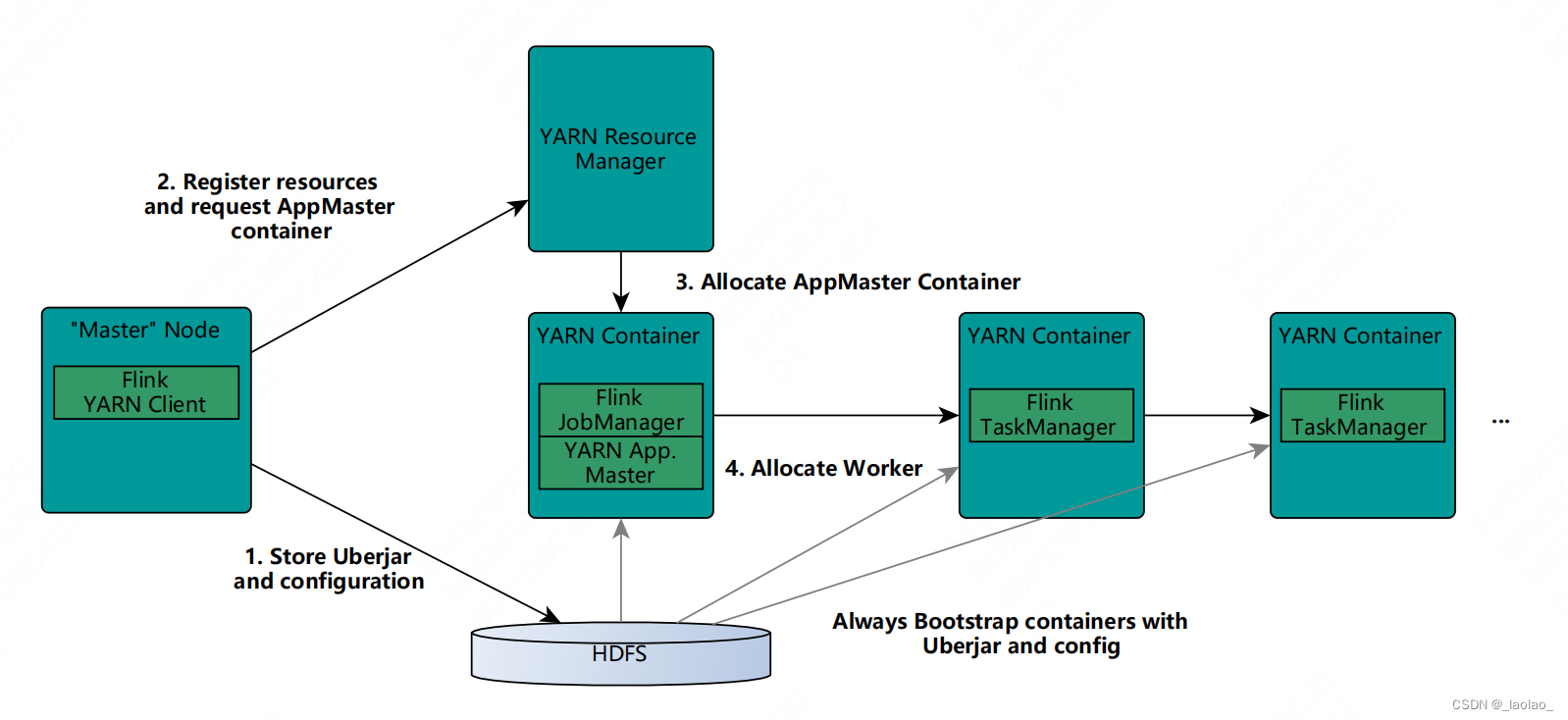
1.每当创建一个新flink任务的yarn session的时候,客户端会首先检查要请求的资源(containers和memory)是否可用。然后将包含flink相关的用户任务jar包和配置上传到HDFS
2.客户端会向ResourceManager申请一个yarn container用以启动ApplicationMaster(AppMaster可以理解为一个计算任务的代言人,计算框架是通过AppMaster和yarn的ResourceManager完成交互的。实际是yarn提供的一个接口,不同的计算框架 如spark flink都去实现重写了这个接口 类似模板模式。它负责代表这个任务向Yarn的ResourceManager申请container,ResourceManager会根据当前集群的资源情况和任务申请的资源情况返回可用的container)。由于客户端已经将配置和jar文件上传到了HDFS,ApplicationMaster会下载这些jar包和配置,然后启动任务。
3.JobManager和ApplicationMaster运行在同一个container
4.ApplicationMaster开始向Yarn的Resource Manager申请启动Flink TaskManager的containers,这些containers会从HDFS上下载jar文件和已修改的配置文件。一旦这些步骤完成,flink就可以接受任务了。
Flink on Yarn两种运行模式
相比于Standalone模式,解脱了JobManager的压力,ResourceManager做资源管理,JobManager只负责任务管理。
- yarn session(Start a lone-running Flink cluster on Yarn):这种方式是在yarn中先启动Flink集群,然后再提交作业,这个Flink集群会一直停留在yarn中,一直占据着yarn集群的资源(只是JobManager会一直占用,没有实际任务TaskManager不会占用。等于是Flink的JobManager进程一直跑),不管有没有任务运行。这种方式能够降低任务的启动时间。提前初始好固定资源的Flink集群,比如提前启动好JM和TM。
- Run a Flink job on Yarn:每次提交一个Flink任务的时候,先去yarn中申请资源启动JobManager和TaskManager,然后在当前集群中运行,任务执行完毕,集群关闭。任务之间互相独立,互不影响,可以最大化的使用集群资源(来一个任务启动一个JM),但是每个任务的启动时间变长了。一般企业中用这个比较多,1.方便各任务间资源隔离 2.充分利用集群资源。 Flink on Yarn运行模式
配置两种运行模式
yarn session模式配置
- Flink on Yarn依赖Yarn集群和HDFS集群,启动Yarn、HDFS集群
- 下载支持Hadoop插件并拷贝到各个节点的安装包的lib目录下。下载地址:https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2- uber/2.6.5-10.0/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar
- 在yarn中启动Flink集群
启动:yarn-session.sh -n3-s3-nm flink-session -d-q
关闭:yarn application -kill applicationId
yarn-session选项:
-n,--container <arg>:在yarn中启动container的个数,实质就是TaskManager的个数
-s,--slots <arg>:每个TaskManager管理的Slot个数
-nm,--name <arg>:给当前的yarn-session(Flink集群)起一个名字
-d,--detached:后台独立模式启动,守护进程
-tm,--taskManagerMemory <arg>:TaskManager的内存大小 单位:MB
-jm,--jobManagerMemory <arg>:JobManager的内存大小 单位:MB
-q,--query:显示yarn集群可用资源(内存、core)

- 提交Flink Job到yarn-session集群中运行
flink run -c com.test.zy.WordCount -yid application_1586794520478_0007 ~/WordCount-1.0-SNAPSHOT.jar
yid:指定yarn-session的ApplicationID
不使用yid也可以,因为在启动yarn-session的时候,在tmp临时目录下已经产生了一个隐藏小文件
vim /tmp/.yarn-properties-root
# Generated YARN properties file# Mon Apr 13 23:39:43 CST 2020parallelies=9dynamicPropertiesString=applicationID=application_1586794520478_0007
Run a Flink job on YARN模式配置
flink run -m yarn-cluster -yn3-ys3-ynm flink-job -c com.test.zy.WordCount ~/WordCount-1.0-SNAPSHOT.jar
-yn,--container <arg>:表示分配容器的数量,也就是TaskManager的数量
-d,--detached:设置在后台运行
-yjm,--jobManagerMemory <arg>:设置JobManager的内存,单位是MB
-ytm,--taskManagerMemory <arg>:设置每个TaskManager的内存,单位是MB
-ynm,--name:给当前Flink Application指定名称
-yq,--query:显示yarn中可用的资源(内存、cpu核数)
-yqu,--queue <arg>:指定yarn资源队列
-ys,--slots <arg>:每个TaskManager可以使用的slot数量
Flink on Yarn HA集群安装&测试
无论以什么样的模式提交Application到Yarn中运行,都会启动一个yarn-session(Flink集群),依然是由JobManager和TaskManager组成。在这种单主节点的情况下,如果JobManager节点宕机,那么整个Flink集群就不会正常运转,所以接下来搭建Flink on Yarn HA集群
安装步骤
- 修改Hadoop安装包下的yarn-site.xml文件
<property><name>yarn.resourcemanager.am.max-attempts</name><value>10</value><description>
The maximum number of application master execution attempts AppMaster最大
重试次数
</description></property>
- 修改Flink安装包下的fink-conf.yaml文件
high-availability: zookeeper
high-availability.storageDir: hdfs://node01:9000/flink/ha/
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181
HA集群测试
两种模式都可以测试,因为不管哪种模式都会启动yarn-session
yarn-session模式测试
- 启动yarn-session
yarn-session.sh -n3-s3-nm flink-session -d
- 通过yarn web ui 找到ApplicationMaster,发现此时的JobManager是在node02,现在kill掉JobManager进程,现在kill掉JobManager进程 kill -9 进程号

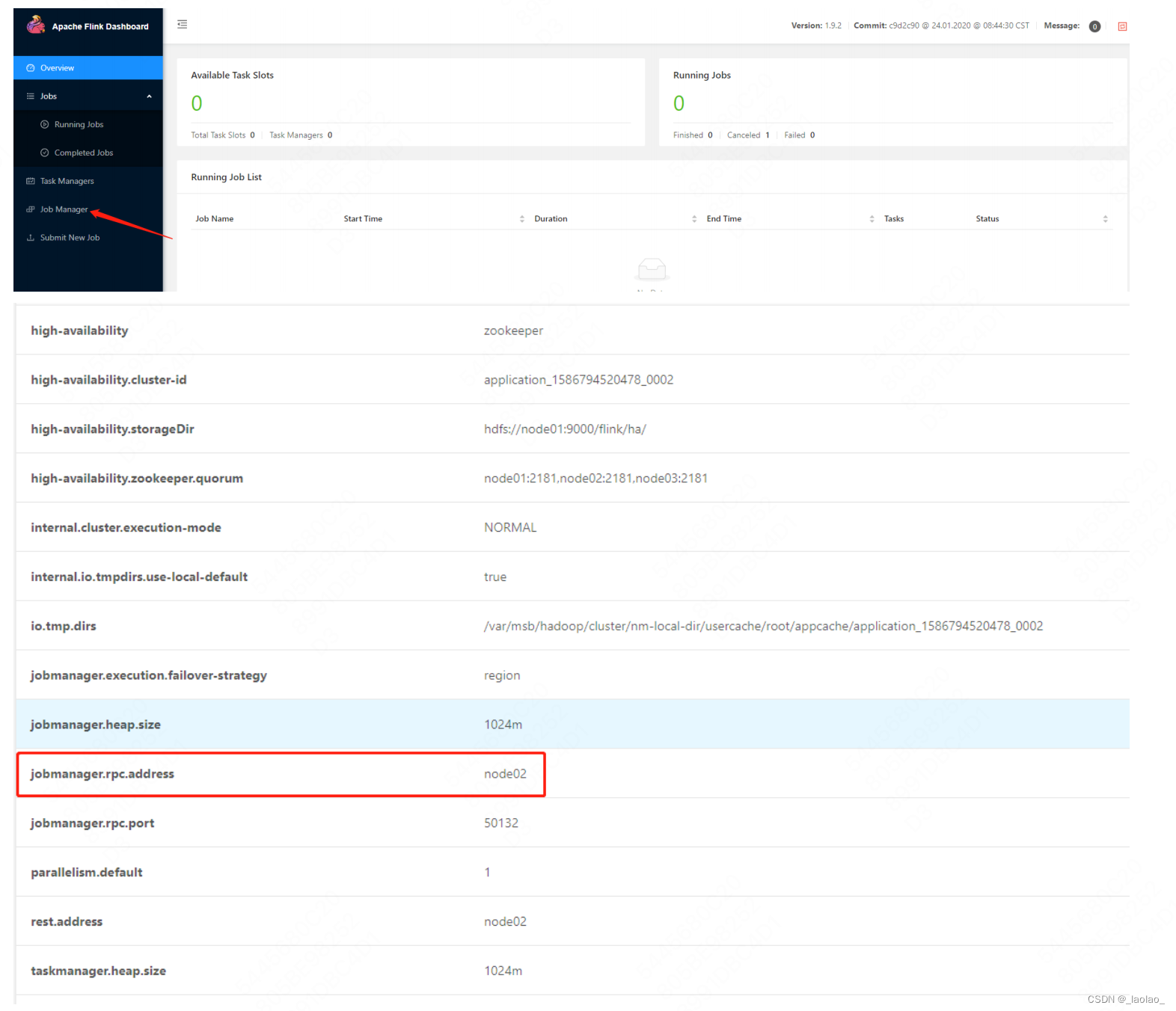
- 再次查看 发现JobManager切换到node03
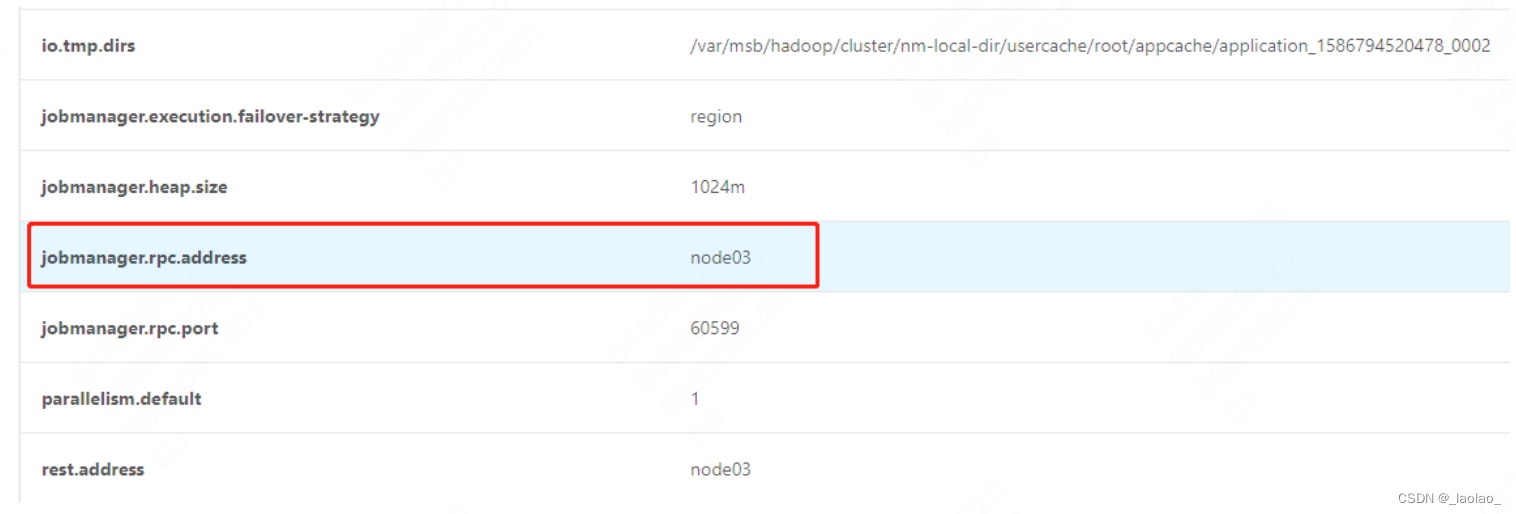
- 查看node03日志,可以看到node03被授权为了leader
2020-04-08 22:21:36,044 INFO org.apache.flink.yarn.YarnResourceManager
- ResourceManager
akka.tcp://flink@node03:60599/user/resourcemanager was granted leadership
with fencing token 94c94c3d68ed799374303fad7447418b
- 取消job
flink list
flink cancel id
Run a Flink job on Yarn模式测试
- 提交job
flink run -m yarn-cluster -yn3-ys3-ynm flink-job -c com.test.zy.WordCount ~/WordCount-1.0-SNAPSHOT.jar
- 停掉JobManager观察,JobManager完成了自动选主换主
- 测试完毕,取消job
yarn application -kill applicationId
Flink API详解&实操
Flink API介绍
Flink提供了不同的抽象级别以开发 流式或者批处理应用程序。从下往上,抽象程度越高,开发越简单,越不灵活。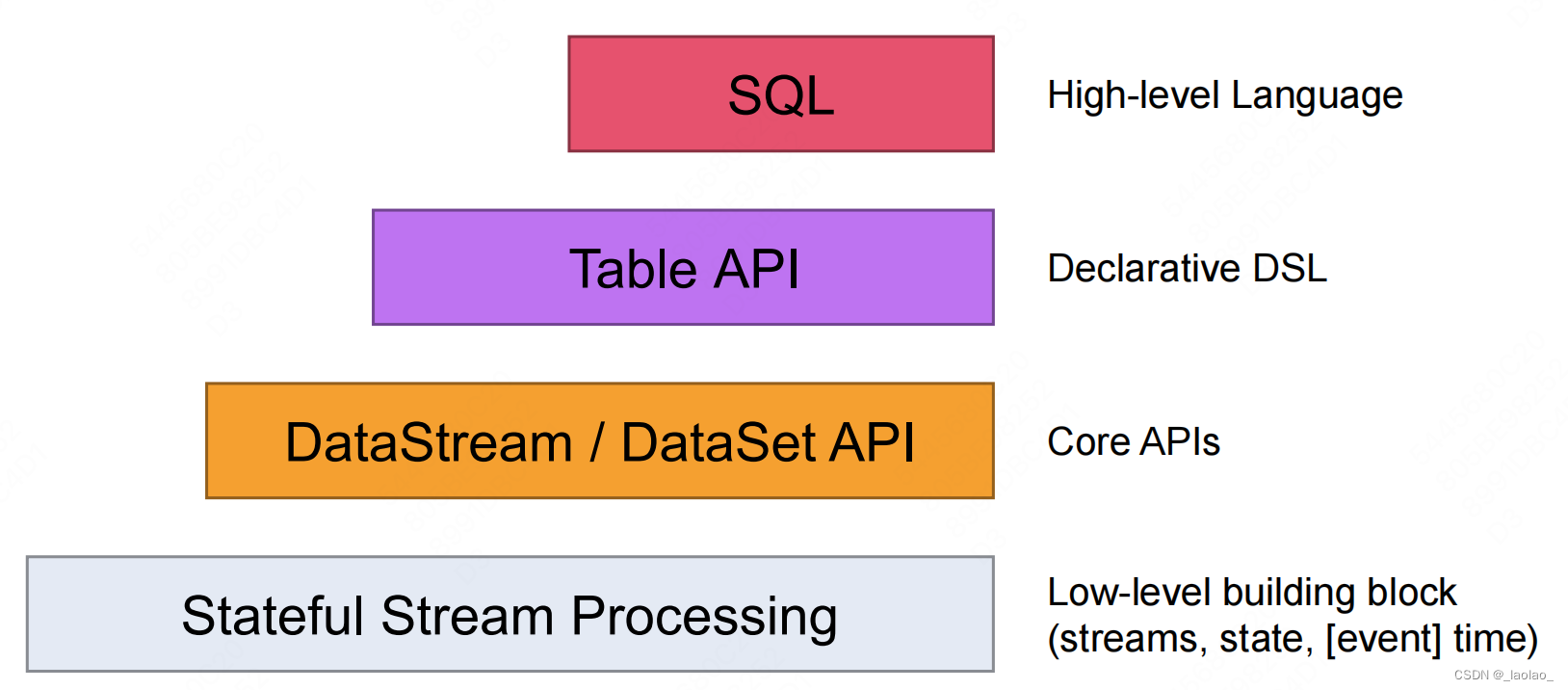
- Stateful Stream Processing 最低级的抽象接口是状态化的数据流接口(stateful streaming)。Flink上层的DataStream api和Table api包括Flink SQL(比如各种算子,函数等)都是用底层的process function实现的。这个接口是通过ProcessFunction集成到DataStream API中的。该接口允许用户自由的处理一个或多个流中的事件,并使用一致的容错状态。另外,用户也可以通过注册event time和processing time,以及配合定时器、状态变量等方式完成复杂的计算。
- DataStream/DataSet API DataStream/DataSet API是Flink提供的核心API,DataSet处理有界的数据集,DataStream处理有界或者无界的数据流(Flink把DataStream和DataSet的获得体现在了创建环境的不同上,流环境是StreamExecutionEnvironment,批环境是ExecutionEnvironment。通过它们获得DataStream/DataSet)。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join)将数据进行转换/计算。
- Table API Table API提供了例如select、project、join、group-by、aggregate等操作,使用起来却更加简洁,可以在Table和DataStream/DataSet之间无缝切换,也允许程序将Table API与DataStream以及DataSet混合使用。
- SQL Flink提供的最高级层次的抽象是SQL。这一层抽象在语法与表达能力上与Table API类似。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
Table API现在的地位比较尴尬,相比Flink SQL不够简单,相比DataStream、ProcessFunction又不够底层灵活。
Dataflows数据流图
在Flink的世界观中,一切都是数据流,对于批计算来说,也只是流计算的一个特例而已。
Flink Dataflow/Flink编程模型是由三部分组成:分别是source、transformation、sink
source数据源会源源不断的产生数据,transformation将产生的数据进行各种业务逻辑的数据处理,最终由sink输出到外部(console、kafka、redis、DB…)
基于Flink开发的程序都能过映射成一个Dataflows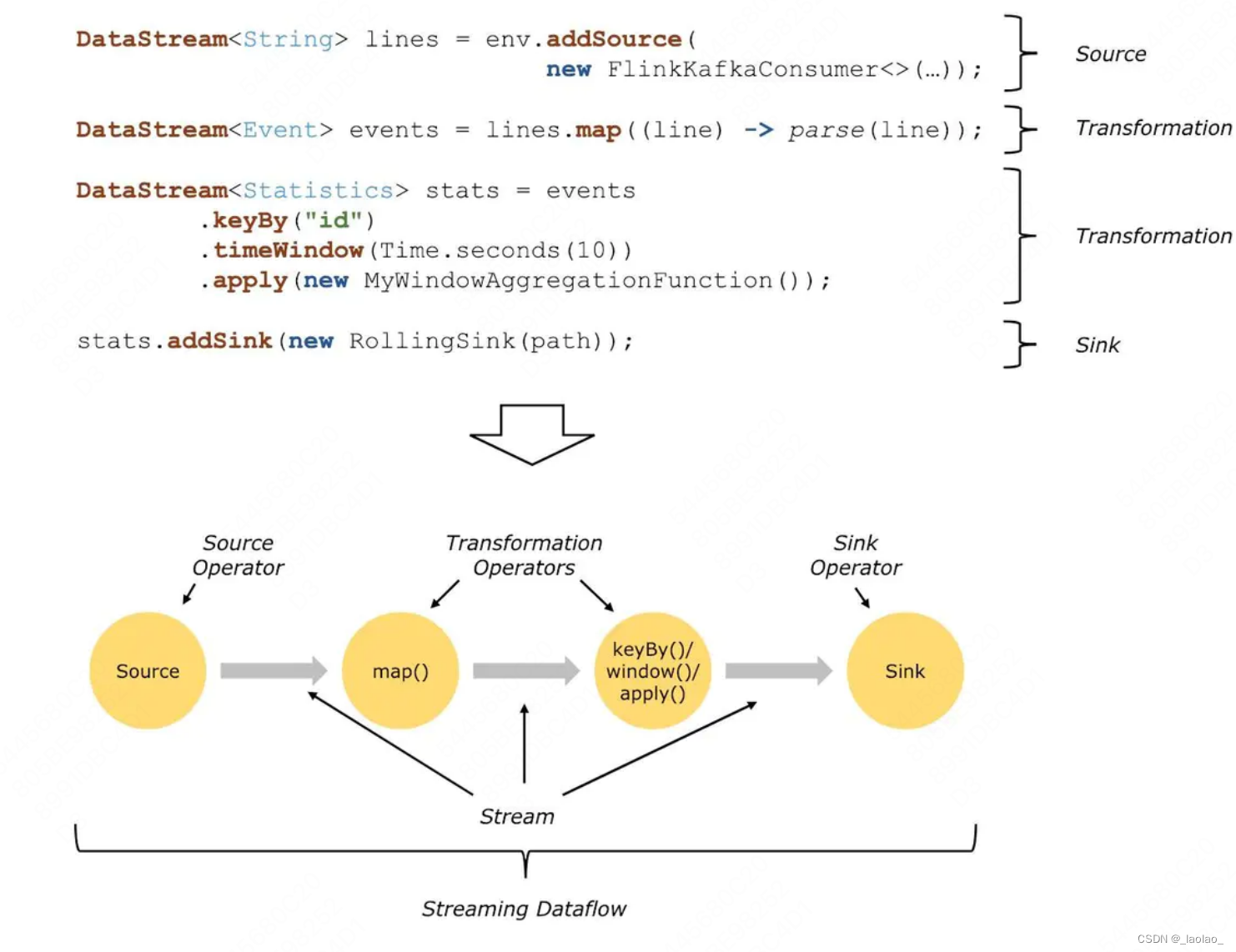
当source数据源的数据量比较大或者计算逻辑比较复杂的情况下,需要提高并行度来处理数据,采用并行数据流。
我们可以设置不同算子的并行度 比如把map算子的并行度设为2。代表会启动多个并行的线程来处理数据。每个线程占用一个taskslot。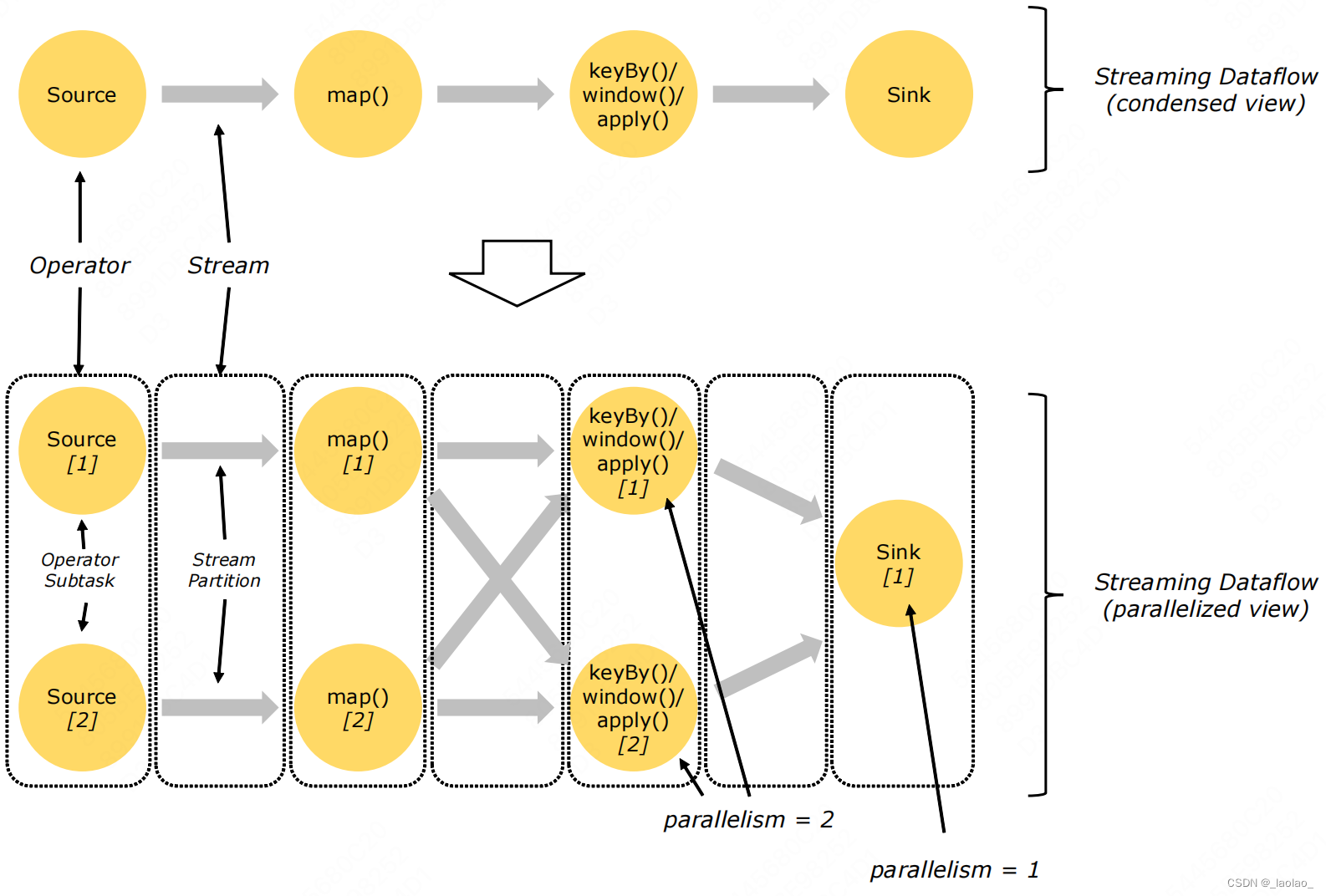
配置开发环境
每个Flink应用都需要依赖一组Flink类库。Flink应用至少需要依赖Flink APIs。许多应用还会额外依赖依赖器类库(比如Kafka、Cassandra等)。当用户运行Flink应用时(无论是在IDEA中进行测试,还是部署在分布式环境中),运行时类库都必须可用
配置开发Maven依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>1.10.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.11</artifactId><version>1.10.0</version></dependency>
注意点:
- 如果要将程序打包提交到集群中运行,打包的时候不需要带这些依赖,因为集群环境中已经包含了这些依赖。此时依赖的作用域应该设置为 provided,在打包的时候不把依赖打进去 maven打包范围
- 如果Flink应用在idea中运行,这些Flink核心依赖的作用域需要设置为compile而不是provided。否则intellij不会添加这些依赖到classpath,会导致应用运行时抛出NoClassDefFoundError异常
添加打包插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!--不要拷贝 META-INF 目录下的签名,
否则会引起 SecurityExceptions 。 --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransfor
mer"><mainClass>my.programs.main.clazz</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
WordCount 流批计算程序
批计算:统计HDFS数据需要添加Hadoop依赖
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.5</version></dependency>
WordCount代码:
val env = ExecutionEnvironment.getExecutionEnvironment
// 按行读取数据val initDS: DataSet[String]= env.readTextFile("hdfs://node01:9000/flink/data/wc")// 1.对每行数据(eg:hello world)按空格切分后 2.转成tuple2类型 eg:(hello,1) (world,1) 3.groupBy(0)按tuple的第一个元素分组后 按tuple的第二个元素进行sum计算val restDS: AggregateDataSet[(String,Int)]= initDS.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
restDS.print()
流计算:统计数据流中,单词出现的次数
//准备环境/**
* createLocalEnvironment 创建一个本地执行的环境 local
* createLocalEnvironmentWithWebUI 创建一个本地执行的环境 同时还开启Web UI的查看端口 8081
* getExecutionEnvironment 根据你执行的环境创建上下文,比如local cluster
*/val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)/**
* DataStream:一组相同类型的元素 组成的数据流
*/// 监听8888端口val initStream:DataStream[String]= env.socketTextStream("node01",8888)val wordStream = initStream.flatMap(_.split(" "))val pairStream = wordStream.map((_,1))val keyByStream = pairStream.keyBy(0)val restStream = keyByStream.sum(1)
restStream.print()/**
* 6> (msb,1)
* 1> (,,1)
* 3> (hello,1)
* 3> (hello,2)
* 6> (msb,2)
* 默认就是有状态的计算
* 6> 代表是哪一个线程处理的,线程名称
* * 相同的数据一定是由某一个thread处理(因为相同key一定会被分到相同分区)
**///启动Flink 任务
env.execute("first flink job")
WordCount Dataflows 算子链
为了更高效的分布式执行,Flink会尽可能的窄依赖的算子(subtask)链接(chain)在一起形成task。以task为粒度,放在一个线程中执行。将subtask链接成task在一个线程中一口气执行是非常有效的优化:它能减少线程之间的切换,减少消息的序列化和反序列化,减少数据在缓冲区的交换,减少延迟的同时提高整体的吞吐量。
Flink任务调度规则
- 不同task下的subtask会分到同一个TaskSlot,计算向数据移动,提高数据传输效率
- 相同task下的subtask不会分到同一个TaskSlot不会分到同一个TaskSlot,充分利用集群资源,提高并行度 ps:这里的Example2画的有点问题,一个Task下的多并行度的subtask会分到不同的taskslot中执行,但是会优先到同一个TM中进行执行
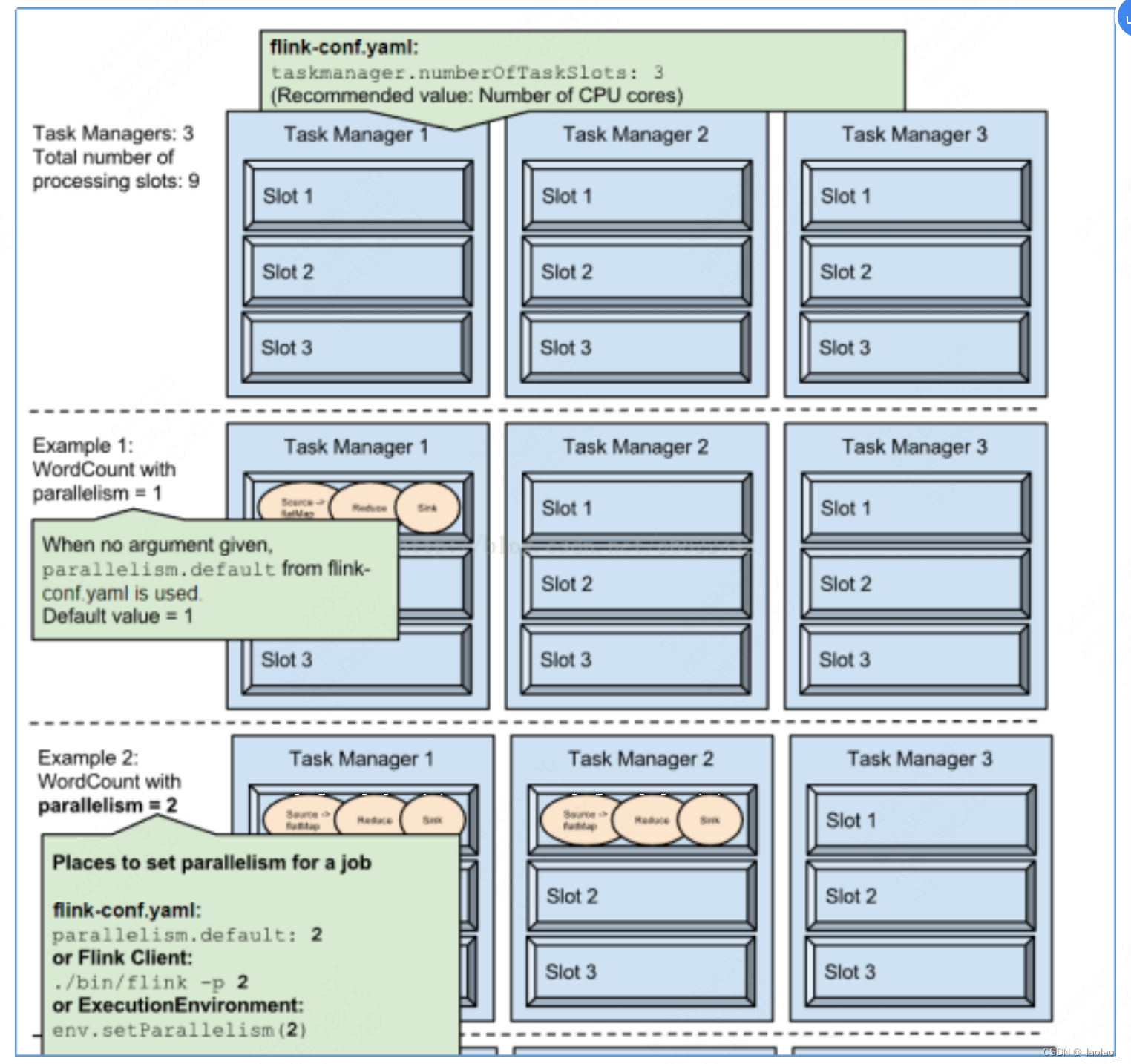
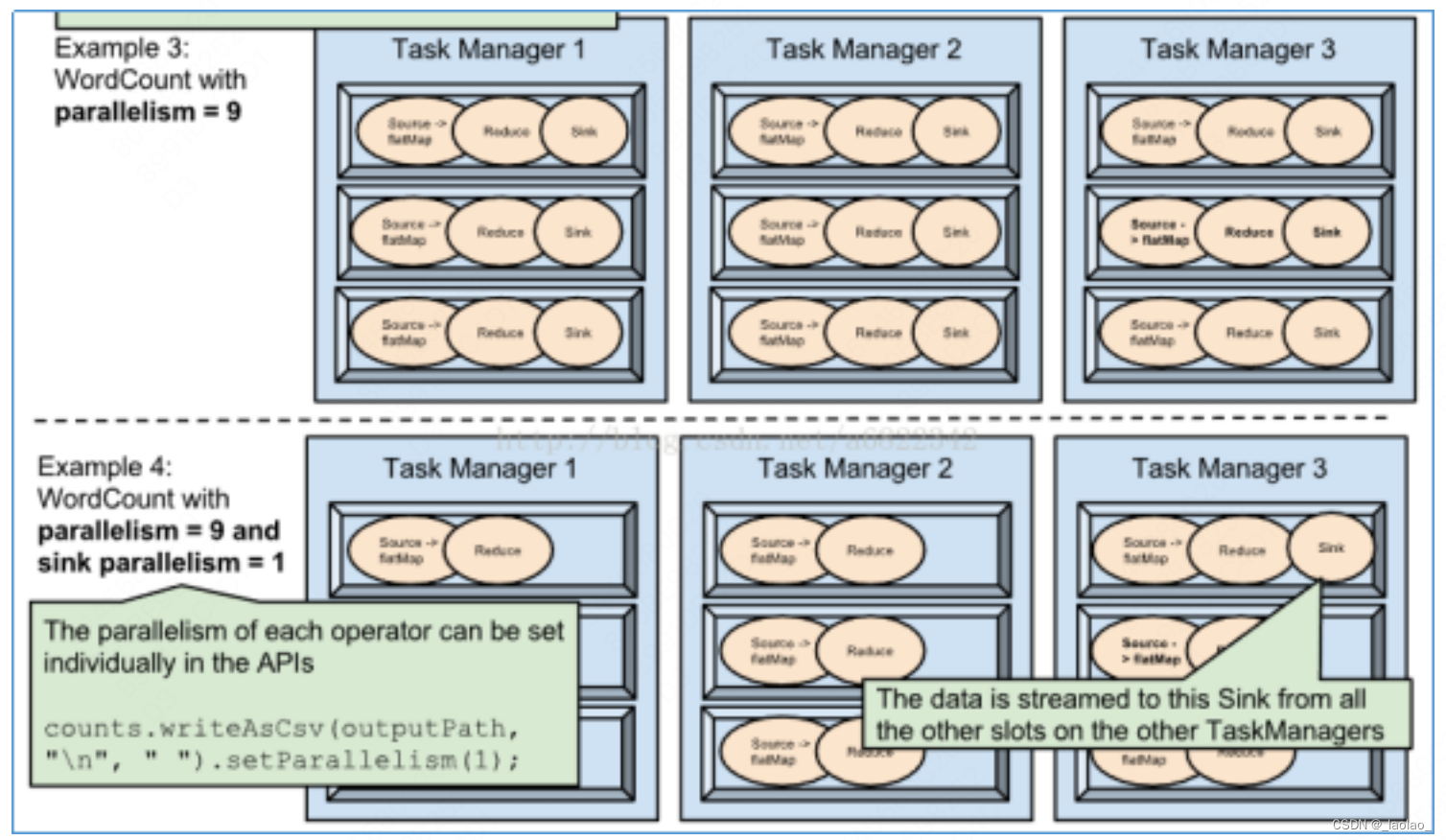
Flink并行度设置方式
1.在算子上设置
val wordStream = initStream.flatMap(_.split(" ")).setParallelims(2)
2.在上下文环境中设置
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
3.client提交Job时设置
flink run -c com.zy.stream.WordCount -p 3 StudyFlink-1.0.SNAPSHOT.jar
4.在flink-conf.yaml配置文件中设置
parallelism.default:1
这四种设置并行度方式的优先级从高到低是:1>2>3>4 (算子粒度>作业粒度>提交时声明粒度>默认配置文件粒度)
Dataflows DataSource数据源
Flink内嵌支持的数据源非常多,比如HDFS、Socket、Kafka、Collections Flink也提供了addSource方式,同时也可以支持自定义数据源。本小结将讲解Flink所有内嵌数据源以及自定义数据源的原理以及API
File Source
- 通过读取本地、HDFS文件创建一个数据源 如果读取的是HDFS上的文件,那么就需要导入Hadoop依赖。同时在申明读入文件路径的时候,以hadoop文件url的格式去写。(如果想读本地文件,写file:///啥的即可)
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.5</version></dependency>
代码:
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//在算子转换的时候,会将数据转换成Flink内置的数据类型,所以需要将隐式转换导入进来,才能自动进行类型转换importorg.apache.flink.streaming.api.scala._
object FileSource {def main(args: Array[String]):Unit={val env = StreamExecutionEnvironment.getExecutionEnvironment
val textStream = env.readTextFile("hdfs://node01:9000/flink/data/wc")
textStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()//读完就停止
env.execute()}
- 每隔10s读取HDFS指定目录下的新增文件内容,并且进行WordCount。 业务场景:企业中的实时ETL场景,每当Flume等采集工具采集来新的数据,就基于Flink进行计算。
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//在算子转换的时候,会将数据转换成Flink内置的数据类型,所以需要将隐式转换导入进来,才能自动进行类型转换importorg.apache.flink.streaming.api.scala._
object FileSource {def main(args: Array[String]):Unit={val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取hdfs文件val filePath ="hdfs://node01:9000/flink/data/"val textInputFormat =new TextInputFormat(new Path(filePath))//每隔10s中读取 hdfs上新增文件内容val textStream = env.readFile(textInputFormat,filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,10)// val textStream = env.readTextFile("hdfs://node01:9000/flink/data/wc")
textStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()}}
readTextFile底层调用的就是readFile方法,使用readFile读取文件是一个更加底层的方式,使用起来会更加的灵活
Collection Source
基于本地集合的数据源,一般用于测试场景,没有太大意义
importorg.apache.flink.streaming.api.scala.StreamExecutionEnvironment
importorg.apache.flink.streaming.api.scala._
object CollectionSource {def main(args: Array[String]):Unit={val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromCollection(List("hello flink zy","hello zy zy"))
stream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()}}
Socket Source
监听指定端口的数据
val initStream:DataStream[String]= env.socketTextStream("node01",8888)
Kafka Source
Flink想要读取kafka中的数据,首先要配置flink与kafka的连接器依赖
官网地址:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/connectors/kafka.html
maven依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.9.2</version></dependency>
代码:
packageexample;importorg.apache.flink.api.common.eventtime.SerializableTimestampAssigner;importorg.apache.flink.api.common.eventtime.WatermarkStrategy;importorg.apache.flink.api.common.functions.MapFunction;importorg.apache.flink.api.common.serialization.SimpleStringSchema;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;importorg.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;importorg.apache.flink.streaming.api.windowing.time.Time;importorg.apache.flink.streaming.api.windowing.windows.TimeWindow;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;importorg.apache.flink.util.Collector;importjava.sql.Timestamp;importjava.time.Duration;importjava.util.ArrayList;importjava.util.Comparator;importjava.util.HashMap;importjava.util.Properties;//从kafka读取test-topic的topic的数据 并按取出pv次数最多的前3种商品publicclassExample2{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);Properties properties =newProperties();
properties.setProperty("bootstrap.servers","hadoop102:9092");
properties.setProperty("group.id","consumer.group");
properties.setProperty("key,deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset","latest");
env.addSource(newFlinkKafkaConsumer<String>("test-topic",newSimpleStringSchema(),properties)).map(newMapFunction<String,UserBehavior>(){@OverridepublicUserBehaviormap(String value)throwsException{String[] arr = value.split(",");returnnewUserBehavior(arr[0],arr[1],arr[2],arr[3],Long.parseLong(arr[4])*1000L);}}).filter(r -> r.behavior.equals("pv")).assignTimestampsAndWatermarks(WatermarkStrategy.<UserBehavior>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(newSerializableTimestampAssigner<UserBehavior>(){@OverridepubliclongextractTimestamp(UserBehavior element,long recordTimestamp){return element.timestamp;}}))//这样所有数据都进入到同一个TaskSlot 没有分布式特性 内存要爆炸 数据严重倾斜 还使用的是全窗口聚合函数.keyBy(r ->true).window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5))).process(newProcessWindowFunction<UserBehavior,String,Boolean,TimeWindow>(){@Overridepublicvoidprocess(Boolean aBoolean,Context context,Iterable<UserBehavior> elements,Collector<String> out)throwsException{HashMap<String,Long> hashMap =newHashMap<>();for(UserBehavior e:elements){if(hashMap.containsKey(e.itemID)){
hashMap.put(e.itemID,hashMap.get(e.itemID)+1L);}else{
hashMap.put(e.itemID,1L);}}ArrayList<Tuple2<String,Long>> arrayList =newArrayList<>();for(String key:hashMap.keySet()){
arrayList.add(Tuple2.of(key,hashMap.get(key)));}
arrayList.sort(newComparator<Tuple2<String,Long>>(){@Overridepublicintcompare(Tuple2<String,Long> o1,Tuple2<String,Long> o2){return(int)(o2.f1-o1.f1);}});StringBuilder result =newStringBuilder();
result.append("窗口:"+newTimestamp(context.window().getStart())+"->"+newTimestamp(context.window().getEnd())).append("\n");for(int i =0; i <3; i++){Tuple2<String,Long> ele = arrayList.get(i);
result.append("第"+(i+1)+"名的商品ID是:"+ele.f0+"浏览次数是:"+ele.f1).append("\n");}
out.collect(result.toString());}}).print();
env.execute();}publicstaticclassUserBehavior{publicString userID;publicString itemID;publicString category;publicString behavior;publicLong timestamp;publicUserBehavior(String userID,String itemID,String category,String behavior,Long timestamp){this.userID = userID;this.itemID = itemID;this.category = category;this.behavior = behavior;this.timestamp = timestamp;}publicUserBehavior(){}}}
补充:
1.kafka复习
2.kafka的key value:我们之前向kafka send数据的时候,有3种发送方式:1.自己指定要发送到的topic和partition以及value 2.自己指定要发送的topic和key以及value 此时发送到哪个partition由对key取模决定 3.只指定要发送的topic和value,此时随机向一个partition发送数据,采用粘性分区的方式发送。
向kafka发送数据的几种方式
3.kafka命令消费key value值:
# 默认只消费value值
kafka-console-consumer.sh --zookeeper node01:2181 --topic flink-kafka --propertyprint.key=true
4.KafkaDeserializationSchema:读取Kafka中的key,value
5.SimpleStringSchema:读取kafka中的value
Custom Source
Sources are where your program reads its input from.You can attach a source to your program by using StreamExecutionEnvironment.addSource(new SourceFunction{…}).
Flink comes with a number of pre-implemented source functions,but you can always write your own custom sources by implementing the SourceFunction for non-parallel sources,or by implementing the ParallelSourceFunction interface or extending the RichParallelSourceFunction for parallel sources.
- 基于SourceFunction接口实现单并行度数据源
packageexample;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importjava.util.Calendar;importjava.util.Random;//自定义数据源(产生数据)publicclassDataSource{publicstaticvoidmain(String[] args)throwsException{//使用自定义的Source//1.获取运行时环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//2.获得输入流 DataStreamSource是DataStream的一个子类DataStreamSource<Event> stream = env.addSource(newClickSource());//3.打印流
stream.print();//Event{user='Alice', url='./fav', timestamp=1671787196643}//Event{user='Alice', url='./cart', timestamp=1671787197645}//Event{user='Bob', url='./prod?id=1', timestamp=1671787198665}//Event{user='Alice', url='./cart', timestamp=1671787199675}//Event{user='Marry', url='./prod?id=2', timestamp=1671787200695}//Event{user='Bob', url='./cart', timestamp=1671787201715}//一直打印
env.execute();}//SourceFunction<T>的泛型T是自定义数据源里面元素的泛型//SourceFunction的并行度只能为1//如果要自定义并行化版本的数据源 需要继承ParallelSourceFunction 生产环境里不太可能让你自定义数据源 flink的数据源一般来自于KafkapublicstaticclassClickSourceimplementsSourceFunction<Event>{privateboolean running =true;privateString[] userArr ={"Marry","Bob","Alice","Liz"};privateString[] urlArr ={"./home","./cart","./fav","./prod?id=1","./prod?id=2"};privateRandom random =newRandom();@Overridepublicvoidrun(SourceContext<Event> ctx)throwsException{//无限向下游发送数据while(running){//collect方法 向下游发送数据
ctx.collect(newEvent(userArr[random.nextInt(userArr.length)],
urlArr[random.nextInt(urlArr.length)],Calendar.getInstance().getTimeInMillis()));//每隔1000ms发送一次数据Thread.sleep(1000L);}}@Overridepublicvoidcancel(){
running =false;}}//用户行为POJO类//POJO类:简单的Java对象 POJO最明显的特点是有一些private的参数作为对象的属性。然后针对每个参数都定义了get和set方法作为访问的接口publicstaticclassEvent{publicString user;publicString url;publicLong timestamp;publicEvent(String user,String url,Long timestamp){this.user = user;this.url = url;this.timestamp = timestamp;}publicEvent(){}@OverridepublicStringtoString(){return"Event{"+"user='"+ user +'\''+", url='"+ url +'\''+", timestamp="+ timestamp +'}';}}}
Dataflows Transformations
Transformations算子可以将一个或者多个算子转换成一个新的数据流,使用Transformations算子组合可以进行复杂的业务处理
Map
DataStream -> DataStream
遍历数据流中的每一个元素,产生一个新的元素
FlatMap
DataStream -> DataStream
遍历数据流中的每一个元素,产生N个元素 N=0,1,2…
Filter
DataStream -> DataStream
过滤算子,根据数据流的元素计算出一个boolean类型的值,true代表保留,false代表过滤掉
KeyBy
DataStream -> KeyedStream
根据数据流中指定的字段来分区,相同指定字段值的数据一定是在同一个分区中(同一个TaskSlot中),分区使用的是HashPartitioner。
Reduce
KeyedStream:根据key分组 -> DataStream
注意:reduce是基于分区后的流对象进行聚合,也就是说,DataStream类型的对象无法调用reduce方法
packageexample;importorg.apache.flink.api.common.functions.ReduceFunction;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;//sum滚动聚合 为什么叫滚动聚合 因为sum内部维护了一个累加器 随着数据不断进来 我们不断更新这个累加器publicclassKeyBy{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);DataStreamSource<Tuple2<Integer,Integer>> stream = env.fromElements(Tuple2.of(1,2),Tuple2.of(1,3));//f0用来访问元组的第0个元素 sum(1)针对1位置(位置从0开始)做聚合
stream.keyBy(r -> r.f0).sum(1).print();//输出(1,2)//(1,5)//第一条数据(1,2)来就是(1,2) 第二条数据(1,3)来就更新状态 输出(1,5)//reduce算子只能对于Tuple2类型 也就是kv类型的数据使用(因为它定义在了KeyedStream里) 并且它的输出也只能是KV/Tuple2(必须和输入保持一致)//reduce是sum/max/min的泛化实现//eg:用reduce实现sum
stream.keyBy(r -> r.f0).reduce(newReduceFunction<Tuple2<Integer,Integer>>(){@OverridepublicTuple2<Integer,Integer>reduce(Tuple2<Integer,Integer> value1,Tuple2<Integer,Integer> value2)throwsException{//reduce聚合逻辑returnTuple2.of(value1.f0,value1.f1+value2.f1);//eg:用reduce实现max://return Tuple2.of(value1.f0,Math.max(value1.f1,value2.f1));}}).print();//输出也是(1,2) (1,5)
env.execute();}}
Aggregations
KeyedStream -> DataStream
Aggregations代表的是一类聚合算子,具体算子如下:
keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")
keyedStream.minBy(0)
keyedStream.minBy("key")
keyedStream.maxBy(0)
keyedStream.maxBy("key")
Union 真合并
DataStream* -> DataStream
Union of two or more datastreams craeting a new stream containing all the elements from all the streams.
合并两个或者更多的数据流,产生一个新的数据流,这个新的数据流中包含了所合并的数据流的所有元素。
注意:需要保证要合并的各数据流的元素类型一致。
packageexample;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;//union//1.union可以用于多条流的合并//2.所有流中的事件类型必须是一样的publicclassUnionTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);DataStreamSource<Integer> stream1 = env.fromElements(1,2);DataStreamSource<Integer> stream2 = env.fromElements(3,4);DataStreamSource<Integer> stream3 = env.fromElements(5,6);//用union(DataStream<T>... streams)方法来合并流DataStream<Integer> result = stream1.union(stream2, stream3);
result.print();//3 4 5 6 1 2
env.execute();}}
Connect假合并
DatStream,DataStream -> ConnectedStreams
connect一般用到:要么两条流都做了keyBy 把来自两条流的相同key的数据进行处理,要么一条流进行keyBy 一条流进行广播(类似spark里的广播变量了 按key把数据shuffle到了不同分区 然后针对每个分区广播一份变量)。
connect算子返回一个ConnectedStreams流。
packageexample;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.co.CoFlatMapFunction;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.util.Collector;importjava.util.Calendar;importjava.util.Random;//connect联结两条流//1.connect只能联结两条流(union可以联结多条流)//2.connect联结的两条流中的元素类型可以不同//3.connect采用的也是FIFO的方式联结流 先来的事件先处理先输出//举一个查询流的例子(eg:一条流输入用户数据 另一条流输入一个url 输出就是所有包含这个url的用户数据)publicclassConnectTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//流1DataStreamSource<Event> clickStream = env.addSource(newClickSource());//流2DataStreamSource<String> queryStream = env.socketTextStream("localhost",9999).setParallelism(1);
clickStream.keyBy(r -> r.user)//先对clickStream进行了分流 按user进行逻辑分区//此时再和查询流的广播流进行联结//connect算子返回一个ConnectedStreams流.connect(queryStream.broadcast())//广播流会对每一个分区广播一份 和对应分区的clickStream做join 每一个分区一条合流 直接把两条流connect到一起没有意义//这里调用是ConnectedStreams的flatMap方法:public <R> SingleOutputStreamOperator<R> flatMap(CoFlatMapFunction<IN1, IN2, R> coFlatMapper)//它的参数是CoFlatMapFunction<IN1, IN2, OUT> 不是我们正常单流或者键控流的FlatMapFunction<IN,OUT>了.flatMap(newCoFlatMapFunction<Event,String,Event>(){privatestaticfinallong serialVersionUID =5521863320726598088L;//query不是一个状态变量 只是一个JVM普通变量 它是整个任务槽公有的(逻辑分区1即线程1 修改了query 逻辑分区2线程2也能看得到) 因为我们的查询流是广播的 想让所有的分区都知道query是什么 所以没必要做成各个key独立的状态变量(希望一个key中的process修改了query的话 所有分区都能知道)//状态变量有点像ThreadLocal:为每个线程提供了一个独立的变量副本privateString query ="";//联结流中来自流1的事件触发flatMap1的调用@OverridepublicvoidflatMap1(Event value,Collector<Event> out)throwsException{//只有包含查询关键字query的event才向下游输出if(value.url.equals(query)){
out.collect(value);}}//联结流中来自流2的事件触发flatMap2的调用@OverridepublicvoidflatMap2(String value,Collector<Event> out)throwsException{
query = value;}}).print();//eg:nc -lk 9999 输入一个查询的query ./home 此时会把包含./home的event都过滤出来//connect一般用到:要么两条流都做了keyBy 把来自两条流的相同key的数据进行处理,要么一条流进行keyBy 一条流进行广播
env.execute();}publicstaticclassClickSourceimplementsSourceFunction<Event>{privateboolean running =true;privateString[] userArr ={"Marry","Bob","Alice","Liz"};privateString[] urlArr ={"./home","./cart","./fav","./prod?id=1","./prod?id=2"};privateRandom random =newRandom();@Overridepublicvoidrun(SourceContext<Event> ctx)throwsException{//无限向下游发送数据while(running){//collect方法 向下游发送数据
ctx.collect(newEvent(userArr[random.nextInt(userArr.length)],
urlArr[random.nextInt(urlArr.length)],Calendar.getInstance().getTimeInMillis()));//每隔1000ms发送一次数据Thread.sleep(1000L);}}@Overridepublicvoidcancel(){
running =false;}}//用户行为POJO类//POJO类:简单的Java对象 POJO最明显的特点是有一些private的参数作为对象的属性。然后针对每个参数都定义了get和set方法作为访问的接口publicstaticclassEvent{publicString user;publicString url;publicLong timestamp;publicEvent(String user,String url,Long timestamp){this.user = user;this.url = url;this.timestamp = timestamp;}publicEvent(){}@OverridepublicStringtoString(){return"Event{"+"user='"+ user +'\''+", url='"+ url +'\''+", timestamp="+ timestamp +'}';}}}
CoMap,CoFlatMap
ConnectedStreams -> DataStream
CoMap,CoFlatMap并不是具体的算子名称,而是一类操作的名称
凡是基于ConnectedStreams数据流做map遍历,这类操作叫做CoMap
凡是基于ConnectedStreams数据流做flatMap遍历,这类操作叫做CoFlatMap(如上面这个例子)
CoMap第一种实现方式
restStream.map(new CoMapFunction[(String,Int),(String,Int),(String,Int)]{//对第一个数据流做计算overridedef map1(value:(String,Int)):(String,Int)={(value._1+":first",value._2+100)}//对第二个数据流做计算overridedef map2(value:(String,Int)):(String,Int)={(value._1+":second",value._2*100)}}).print()
CoMap第二种实现方式
restStream.map(//对第一个数据流做计算
x=>{(x._1+":first",x._2+100)},//对第二个数据流做计算
y=>{(y._1+":second",y._2*100)}).print()
CoFlatMap第一种实现方式
ds1.connect(ds2).flatMap((x,c:Collector[String])=>{//对第一个数据流做计算
x.split(" ").foreach(w=>{c.collect(w)})},(y,c:Collector[String])=>{//对第二个数据流做计算
y.split(" ").foreach(d=>{c.collect(d)})}).print
CoFlatMap第二种实现方式
ds1.connect(ds2).flatMap(//对第一个数据流做计算
x=>{x.split(" ")},//对第二个数据流做计算
y=>{y.split(" ")}).print()
CoFlatMap第三种实现方式
ds1.connect(ds2).flatMap(new CoFlatMapFunction[String,String,(String,Int)]{
//对第一个数据流做计算
override def flatMap1(value: String, out: Collector[(String, Int)]): Unit ={
val words = value.split(" ")
words.foreach(x=>{out.collect((x,1))})}
//对第二个数据流做计算
override def flatMap2(value: String, out: Collector[(String, Int)]): Unit ={
val words = value.split(" ")
words.foreach(x=>{out.collect((x,1))})}}).print()
Split算子 @Deprecated Please use side output instead
DataStream -> SplitStream
根据条件将一个流分成两个或者更多的流。
仅做了解,分流建议使用site output侧输出流。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,100)val splitStream = stream.split(
d =>{
d %2match{case0=> List("even")case1=> List("odd")}})
splitStream.select("even").print()
env.execute()
Select算子
SplitStream -> DataStream
从SplitStream中选择一个或者多个数据流。仅做了解,建议用getSideOutput(tag)获得侧输出流
splitStream.select("even").print()
site output侧输出流
流计算过程中,通常我们会把一些数据发送到侧输出流(比如迟到事件),然后在侧输出流对它们进行单独处理。
packageexample;importcom.ibm.icu.util.Output;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.ProcessFunction;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.streaming.api.watermark.Watermark;importorg.apache.flink.util.Collector;importorg.apache.flink.util.OutputTag;//把迟到数据发送到侧输出流中publicclassSideOutput1{//定义侧输出流的名字/标签 泛型是输入到这个流的数据类型 要注意写一个{} 不写就报错privatestaticOutputTag<String> outputTag =newOutputTag<String>("late-element"){};publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//换一种抽取水位线的方式(之前是指定时间戳 设置最大延迟时间)SingleOutputStreamOperator<String> result = env.addSource(newSourceFunction<Tuple2<String,Long>>(){@Overridepublicvoidrun(SourceContext<Tuple2<String,Long>> ctx)throwsException{//指定发的这条数据的时间戳是1000ms
ctx.collectWithTimestamp(Tuple2.of("hello,world",1000L),1000L);//发送一个999ms的水位线 emit:发出
ctx.emitWatermark(newWatermark(999L));//继续发送数据
ctx.collectWithTimestamp(Tuple2.of("hello flink",2000L),2000L);//再发送一个水位线事件
ctx.emitWatermark(newWatermark(1999L));
ctx.collectWithTimestamp(Tuple2.of("late element",1000L),1000L);//这是一个迟到元素(时间戳<水位线)}@Overridepublicvoidcancel(){}})//定义侧输出流.process(newProcessFunction<Tuple2<String,Long>,String>(){@OverridepublicvoidprocessElement(Tuple2<String,Long> value,Context ctx,Collector<String> out)throwsException{//如果数据的时间戳小于当前水位线 发送到侧输出流if(value.f1 < ctx.timerService().currentWatermark()){//用context.output方法把数据发送到侧输出流(side output)//public abstract <X> void output(OutputTag<X> outputTag, X value)//outputTag:侧输出流标签 value:数据
ctx.output(outputTag,"迟到元素发送到侧输出流"+ value);}else{//正常到达的元素向下游发送就可以
out.collect("正常到达的元素"+ value);}}});
result.print("正常到达的数据(主流数据):");//打印侧输出流
result.getSideOutput(outputTag).print("侧输出流:");//正常到达的数据(主流数据):> 正常到达的元素(hello,world,1000)//正常到达的数据(主流数据):> 正常到达的元素(hello flink,2000)//侧输出流:> 迟到元素发送到侧输出流(late element,1000)
env.execute();}}
富函数
Flink算子的匿名实现函数基本都有其富函数。
富函数相比于普通的函数,可以获取运行环境的上下文(Context),拥有一些生命周期方法,管理状态,可以实现更加复杂的功能。
普通函数类富函数类MapFunctionRichMapFunctionFlatMapFunctionRichFlatMapFunctionFilterFunctionRickFilterFunction……
代码后续补充
处理函数
后续补充
Dataflows分区策略
shuffle
场景:增大分区、提高并行度、解决数据倾斜
分区元素随机均匀的分发到下游分区,网络开销比较大。
rebalance
场景:增大分区、提高并行度、解决数据倾斜
轮询分区元素,均匀的将元素分发到下游分区,下游每个分区的数据比较均匀,在发生数据倾斜时非常有用,网络开销比较大。
broadcast
场景:需要使用维表等场景
将上游中的每一个元素广播到下游中的每一个分区中
packageexample;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;publicclassShuffle{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();//shuffle:随机物理分配(可能不平均)//fromElements(1,2,3,4)设置了1个分区 print()设置了2个分区 中间用shuffle将原来1个分区里的数据分到2个分区里输出
env.fromElements(1,2,3,4).setParallelism(1).shuffle().print().setParallelism(2);//输出://2> 3//1> 1//2> 4//1> 2//可以看到1 2 进了第一个任务槽里 3 4 进了第二个任务槽里//rebalance:平均物理分配(一定平均) 向下游所有分区轮询
env.fromElements(1,2,3,4).setParallelism(1).rebalance().print().setParallelism(2);//1> 2//2> 1//1> 4//2> 3//broadcast:复制的广播发送 下游每个分区一份数据
env.fromElements(1,2,3,4).setParallelism(1).broadcast().print().setParallelism(2);//1> 1//2> 1//1> 2//2> 2//2> 3//1> 3//2> 4//1> 4
env.execute();}
global
场景:并行度降为1
上游分区的数据只分发给下游的第一个分区
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.global.writeAsText("./data/stream2").setParallelism(4)
env.execute()//stream1:1//1 3 5 7 9//stream1:2//2 4 6 8 10//stream2:1//1 3 5 7 9 2 4 6 8 10
forward
场景:分区不变,一对一的数据分发,map、flatMap、filter等都是这种分区策略
上游分区数据会分发到下游对应分区中:partition1 -> partition1,partition2 -> partition2
注意:必须保证上下游分区数(并行度)一致,否则会有如下异常:
Forward partitioning does not allow change of parallelism
* Upstream operation: Source: Sequence Source-1 parallelism:2,* downstream operation: Sink: Unnamed-4 parallelism:4* stream.forward.writeAsText("./data/stream2").setParallelism(4)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.forward.writeAsText("./data/stream2").setParallelism(2)
env.execute()//stream1:1//1 3 5 7 9//stream1:2//2 4 6 8 10//stream2:1//1 3 5 7 9//stream2:2//2 4 6 8 10
keyBy
场景:下游分区数(并行度)由keyby的key决定
根据上游分区元素的hash值与下游分区数取模计算出,将当前元素分发到下游哪一个分区。所以为了防止数据倾斜,可以有两种方法 1.对上游热点key加盐 2.改变下游分区数
MathUtils.murmurHash(keyHash)(每个元素的Hash值) % maxParallelism(下游分区数)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.keyBy(0).writeAsText("./data/stream2").setParallelism(2)
env.execute()
PartitionCustom
自定义分区器。
通过自定义的分区器,来决定元素是如何从上游分区分发到下游分区。
object ShuffleOperator {def main(args: Array[String]):Unit={val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)val stream = env.generateSequence(1,10).map((_,1))
stream.writeAsText("./data/stream1")
stream.partitionCustom(new customPartitioner(),0).writeAsText("./data/stream2").setParallelism(4)
env.execute()}class customPartitioner extends Partitioner[Long]{overridedef partition(key:Long, numPartitions:Int):Int={
key.toInt % numPartitions
}}}
Dataflows Sink
Flink内置了大量sink,可以将Flink处理后的数据输出到HDFS、kafka、Redis、ES、MySQL等等工程场景中,会经常出现消费kafka中的数据,处理结果存储到Redis或者MySQL或者olap存储引擎比如clickhouse/doris中的场景。
Redis Sink
Flink处理的数据可以存储到Redis中,以便实时查询
Flink内嵌连接Redis的连接器,只需要导入链接Redis的依赖就可以
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version></dependency>
WordCount写入到Redis中,选择的是HSET数据类型
代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)val result = stream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)//若redis是单机val config =new FlinkJedisPoolConfig.Builder().setDatabase(3).setHost("node01").setPort(6379).bu
ild()//如果是 redis集群/*val addresses = new util.HashSet[InetSocketAddress]()
addresses.add(new InetSocketAddress("node01",6379))
addresses.add(new InetSocketAddress("node01",6379))
val clusterConfig = new
FlinkJedisClusterConfig.Builder().setNodes(addresses).build()*/
result.addSink(new RedisSink[(String,Int)](config,new RedisMapper[(String,Int)]{overridedef getCommandDescription: RedisCommandDescription ={new RedisCommandDescription(RedisCommand.HSET,"wc")}overridedef getKeyFromData(t:(String,Int))={
t._1
}overridedef getValueFromData(t:(String,Int))={
t._2 +""}}))
env.execute()
Kafka Sink
处理结果写入到kafka topic中,同样需要添加连接器依赖。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink-version}</version></dependency>
packageexample;importorg.apache.flink.api.common.serialization.SimpleStringSchema;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;importjava.util.Properties;//写入KafkapublicclassExample1{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);Properties properties =newProperties();
properties.put("bootstrap.servers","hadoop102:9092");
env.readTextFile("D:\\BaiduNetdiskDownload\\aaa\\bbb\\cc\\day07\\flink0224tutorial\\src\\main\\resources\\UserBehavior.csv")//直接写入kafka FlinkKafkaProducer继承了TwoPhaseCommitSinkFunction继承了SinkFunction 其中的3个参数分别为 topic名 写入数据的数据类型 配置文件.addSink(newFlinkKafkaProducer<String>("test-topic",newSimpleStringSchema(),properties));
env.execute();}}
下面4种暂不补充
MySQL Sink
Socket Sink
File Sink
HBase Sink
Flink State状态
Flink是一个有状态的流式计算引擎,所以会将中间计算结果(状态)进行保存,默认保存到TaskManager的堆内存中。但是当task挂掉,这个task所对应的内存状态都会被清空,会造成状态丢失,此时就需要把数据从头开始再计算一边,效率很低。想要保证At-least-once和Exactly-once,需要把数据状态持久化到更安全的存储介质中,Flink提供了堆内内存、堆外内存、HDFS、RocksDB等存储介质。
有状态/无状态的一些说明:Flink是一个有状态的流式计算引擎。HTTP协议是一个无状态的请求-响应协议,每次请求都是独立的,和之前/之后的请求没有关系。如果想要让HTTP请求变成有状态的,需要用cookie+session。
Flink中状态分为两种类型:
- Keyed State 基于KeyedStream上的状态,这个状态是和每个key绑定,KeyedStream流上的每一个key都对应一个State。每一个Operator可以启动多个Thread处理,但是相同key的数据只能由同一个Thread处理,因此一个Keyed状态只能存在于某一个Thread中,但是一个Thread可能会有多个KeyedState。
- Non-Keyed State(Operator State) Operator State与Key无关,而是与Operator绑定,整个Operator只对应一个State。比如:Flink中的Kafka Connector就使用了Operator State,他会在每个Connector实例中,保存该实例消费Topic的所有(partition,offset)信息。
Flink针对Keyed State提供了以下可以保存State的数据结构
- ValueState:类型为T的单值状态,这个状态与对应的key绑定,是最简单的状态,通过update()更新值,通过value()获取值。
packageexample;importorg.apache.flink.api.common.state.ValueState;importorg.apache.flink.api.common.state.ValueStateDescriptor;importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.configuration.Configuration;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.KeyedProcessFunction;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.util.Collector;importjava.util.Random;//状态变量//10s输出一次平均数publicclassZhuangTaiBianLiang{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(newSourceFunction<Integer>(){privateboolean running =true;privateRandom random =newRandom();@Overridepublicvoidrun(SourceContext<Integer> ctx)throwsException{while(running){
ctx.collect(random.nextInt(10));Thread.sleep(100L);}}@Overridepublicvoidcancel(){
running =false;}}).keyBy(r ->true).process(newKeyedProcessFunction<Boolean,Integer,Double>(){//声明一个状态变量作为累加器//ValueState<T>中有两个方法:value()和update() 它的父接口State中有一个方法clear()//需要记住的关于状态变量的两点://1.每种key独有一个状态变量 状态变量的可见范围是当前key (每种key一个状态变量)//2.状态变量是单例 只能被实例化一次 (要么去检查点拿状态变量 要么new一个) (状态变量是单例 只有一种状态)privateValueState<Tuple2<Integer,Integer>> valueState;//保存定时器的时间戳privateValueState<Long> timerTs;@Overridepublicvoidopen(Configuration parameters)throwsException{//固定写法 实例化状态变量 ValueStateDescriptor:状态描述符 其中给这个状态取了名字sum-count 并指定了这个状态中存的value的类型
valueState =getRuntimeContext().getState(newValueStateDescriptor<Tuple2<Integer,Integer>>("sum-count",Types.TUPLE(Types.INT,Types.INT)));
timerTs =getRuntimeContext().getState(newValueStateDescriptor<Long>("timer",Types.LONG));}@OverridepublicvoidonTimer(long timestamp,OnTimerContext ctx,Collector<Double> out)throwsException{//定时器被触发时 输出平均值//防御式编程if(valueState.value()!=null){
out.collect((double)valueState.value().f0/valueState.value().f1);//10s输出一次平均数 输出后清空定时器 这样在processElement中检测出来定时器为空了 就会再注册一个10s后的定时器
timerTs.clear();}}@OverridepublicvoidprocessElement(Integer value,Context ctx,Collector<Double> out)throwsException{//如果来的是第一条数据//使用.value()读取状态变量的值 使用.update(T)方法更新状态变量ValueState<T>的值if(valueState.value()==null){
valueState.update(Tuple2.of(value,1));}else{//如果来的不是第一条数据 更新
valueState.update(Tuple2.of(valueState.value().f0+value,valueState.value().f1+1));}//每来一条数据 更新状态变量 向下游输出一条数据//reduce的输入和输出的数据类型必须一样都是Tuple2 而KeyedProcessFunction<Key,In,Out>对于Key,In,Out是没有要求的 可见KeyedProcessFunction更底层更灵活//out.collect((double)valueState.value().f0/valueState.value().f1);//如果定时器为空//如果定时器已经存在了 就不注册定时器if(timerTs.value()==null){//注册一个当前时间10秒后的定时器
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime()+10*1000L);
timerTs.update(ctx.timerService().currentProcessingTime()+10*1000L);}}}).print();//10s输出一次流的平均值//KeyedProcessFunction:结合状态变量ValueState再结合定时器onTimer() 十分的强大//底层API中的两个关键点:1.状态 2.时间 这也是flink中最重要的两个点 (这里我们使用的是机器时间 后面我们会引入事件时间)
env.execute();}}
- ListState:Key上的状态值为一个列表,这个列表可以通过add()方法向列表中添加值,可以通过get()方法返回一个Iterable对象来遍历状态值。
packageexample;importorg.apache.flink.api.common.state.ListState;importorg.apache.flink.api.common.state.ListStateDescriptor;importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.configuration.Configuration;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.KeyedProcessFunction;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.util.Collector;importjava.util.Random;//用列表状态变量实现求平均值publicclassListStateTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(newSourceFunction<Integer>(){privateboolean running =true;privateRandom random =newRandom();@Overridepublicvoidrun(SourceContext<Integer> ctx)throwsException{while(running){
ctx.collect(random.nextInt(50));Thread.sleep(300L);}}@Overridepublicvoidcancel(){
running =false;}}).keyBy(r->1).process(newKeyedProcessFunction<Integer,Integer,Double>(){//初始化一个列表状态变量//列表状态变量也遵循:1.每种key独有一个状态变量 2.状态变量是单例的 除此以外ListState和ArrayList的用法基本一致 可以当成数组使用privateListState<Integer> listState;@Overridepublicvoidopen(Configuration parameters)throwsException{
listState =getRuntimeContext().getListState(newListStateDescriptor<Integer>("list-state",Types.INT));}@OverridepublicvoidprocessElement(Integer value,Context ctx,Collector<Double> out)throwsException{//每来一条数据 我们就将它添加到列表中
listState.add(value);Integer sum =0;Integer count =0;//get()方法返回的是列表状态下的所有元素的迭代器for(Integer i : listState.get()){
sum += i;
count +=1;}//我们这个程序的问题是列表状态变量的值会无限扩充 把所有的元素都存进去了 非常的占内存
out.collect((double)sum/count);}}).print();//平均数也能正确输出
env.execute();}}
- ReducingState:每次调用add()方法添加值的时候,会调用用户传入的reduceFunction,最后合并到一个单一的状态值。
- MapState<K,V>:状态值为一个Map,用户通过put或putAll方法添加元素,get(key)通过指定的key获取对应的value,使用entries(),keys(),values()分别获得entry集合,key集合,value集合。
packageexample;importorg.apache.flink.api.common.state.MapState;importorg.apache.flink.api.common.state.MapStateDescriptor;importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.configuration.Configuration;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.KeyedProcessFunction;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importorg.apache.flink.util.Collector;importjava.util.Calendar;importjava.util.Random;//字典状态变量 求每个人的平均PVpublicclassMapStateTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(newClickSource()).keyBy(r ->1).process(newKeyedProcessFunction<Integer,Event,String>(){//MapState的用法和hashmap也类似//Hash表可以说是计算机中最重要的一种数据结构了 具体实现比如HBase,搜索引擎(倒排索引),MySQL的索引也可以不用B+树 而是用Hash表来实现//Hash表的本质是数组+hash算法+链表/红黑树privateMapState<String,Long> mapState;@Overridepublicvoidopen(Configuration parameters)throwsException{
mapState =getRuntimeContext().getMapState(newMapStateDescriptor<String,Long>("map-state",Types.STRING,Types.LONG));}@OverridepublicvoidprocessElement(Event value,Context ctx,Collector<String> out)throwsException{//每来一条事件if(mapState.contains(value.user)){
mapState.put(value.user,mapState.get(value.user)+1);}else{
mapState.put(value.user,1L);}//求PV平均值:总浏览次数/总用户数量long userNum =0L;long pvSum =0L;for(String user : mapState.keys()){
userNum +=1L;
pvSum += mapState.get(user);}
out.collect("当前PV的平均值是:"+(double)pvSum/userNum);}}).print();//也能够正确输出://当前PV的平均值是:1.0//当前PV的平均值是:1.0//当前PV的平均值是:1.5//当前PV的平均值是:1.3333333333333333//当前PV的平均值是:1.6666666666666667//当前PV的平均值是:2.0//当前PV的平均值是:2.3333333333333335//当前PV的平均值是:2.6666666666666665
env.execute();}publicstaticclassClickSourceimplementsSourceFunction<Event>{privateboolean running =true;privateString[] userArr ={"Marry","Bob","Alice","Liz"};privateString[] urlArr ={"./home","./cart","./fav","./prod?id=1","./prod?id=2"};privateRandom random =newRandom();@Overridepublicvoidrun(SourceContext<Event> ctx)throwsException{//无限向下游发送数据while(running){//collect方法 向下游发送数据
ctx.collect(newEvent(userArr[random.nextInt(userArr.length)],
urlArr[random.nextInt(urlArr.length)],Calendar.getInstance().getTimeInMillis()));//每隔1000ms发送一次数据Thread.sleep(1000L);}}@Overridepublicvoidcancel(){
running =false;}}//用户行为POJO类//POJO类:简单的Java对象 POJO最明显的特点是有一些private的参数作为对象的属性。然后针对每个参数都定义了get和set方法作为访问的接口publicstaticclassEvent{publicString user;publicString url;publicLong timestamp;publicEvent(String user,String url,Long timestamp){this.user = user;this.url = url;this.timestamp = timestamp;}publicEvent(){}@OverridepublicStringtoString(){return"Event{"+"user='"+ user +'\''+", url='"+ url +'\''+", timestamp="+ timestamp +'}';}}}
- AggregatingState<IN,OUT>:保留一个单值,表示添加到状态的所有值的聚合。和ReducingState相反的是,聚合类型可能与添加到状态的元素的类型不同,即IN和OUT的类型可能不同。使用add(IN)添加的元素会调用用户指定的AggregateFunction进行聚合
- FoldingState<T,ADD>:已过时,建议使用AggregatingState。
CheckPoint
Flink基于异步轻量级的分布式快照技术提供了Checkpoint容错机制,分布式快照可以讲同一时间点Task/Operator的状态数据进行全局统一的快照处理。当未来程序出现问题时,可以基于保存的快照容错。
版权归原作者 _laolao_ 所有, 如有侵权,请联系我们删除。