

总的来说,SQL分为四大类,分别是数据定义语言DDL,数据操作语言DML,数据查询语言DQL和数据控制语言DCL。
而SQL的基本操作一般是指对数据库,数据表,数据的增删改查。
文章目录
1. DDL- 操作数据库
首先要学习的是使用DDL来对数据库进行操作,主要是对数据库的增删改查操作。
1.1 查询
查询所有的数据库:
showdatabases;
例如:

1.2 创建数据库
创建新的数据库:
createdatabase 数据库名称;
使用上面的方式创建新的数据库时,如果该数据库已经存在,则会出现错误,所以我们在创建新的数据库时一般会判断该数据库是否存在,如果已存在,则不会创建。
创建新的数据库(判断数据库是否已经存在):
createdatabaseifnotexists 数据库名称;
例如:

1.3 删除数据库
删除数据库:
dropdatabase 数据库名称;
和前面创建新的数据库相同,为了避免出现错误,我们一般会先判断该数据库是否存在,如果不存在,则不会删除。
删除数据库(判断数据库是否已经存在):
dropdatabaseifexists 数据库名称;
例如:

1.4 使用数据库
现在我们已经成功创建了新的数据库,接下来,我们要在数据库中创建数据表,首先我们要明白是对哪一个数据库进行操作,此时我们要先学会使用数据库,才能对数据库中的表进行操作。
使用数据库:
use 数据库名称;
查询当前正在使用的数据库:
selectdatabase();
例如:

2. DDL- 操作数据表
同样,对数据表的操作无非就是增删改查,在学习相关操作之前,我们先要熟悉一下MySQL的数据类型。
2.1 数据类型
MySQL支持多种数据类型,但是大致可以分为3中,分别是数值型,日期型和字符串型。下面是比较常用的几种数据类型:
数值:
数据类型解释tinyint小整数型,占1个字节int大整数型,占4个字节double浮点类型
日期:
数据类型解释date日期值,只包含年月日datetime混合日期和时间值,包含年月日时分秒
字符串:
数据类型解释char定长字符串varchar变长字符串
定长字符串和变长字符串的区别:
字符串是我们在数据库中经常使用的数据类型,使用变长字符串,如果字符的长度没有达到指定的长度,那么实际的长度是多少就占用几个字符,这样的做法显然是使用时间换空间,而使用定长字符串虽然有时会出现浪费空间的情况,但是一般储存性能比较高。
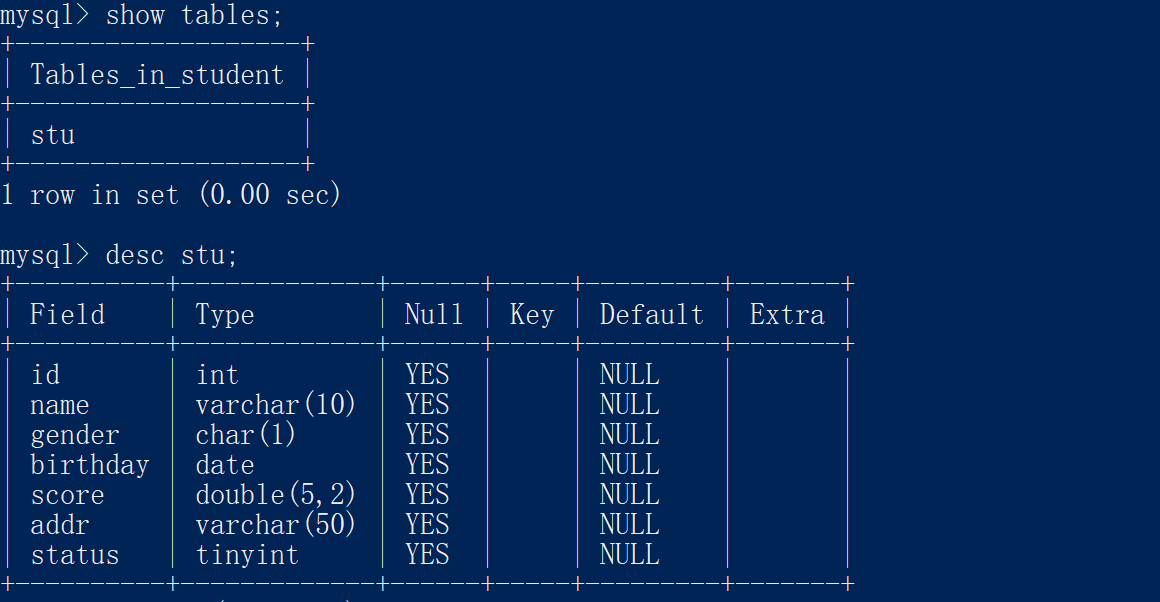
2.2 查询表
查询当前数据库下所有的表:
showtables;
查询表结构:
desc 表名称;
例如:
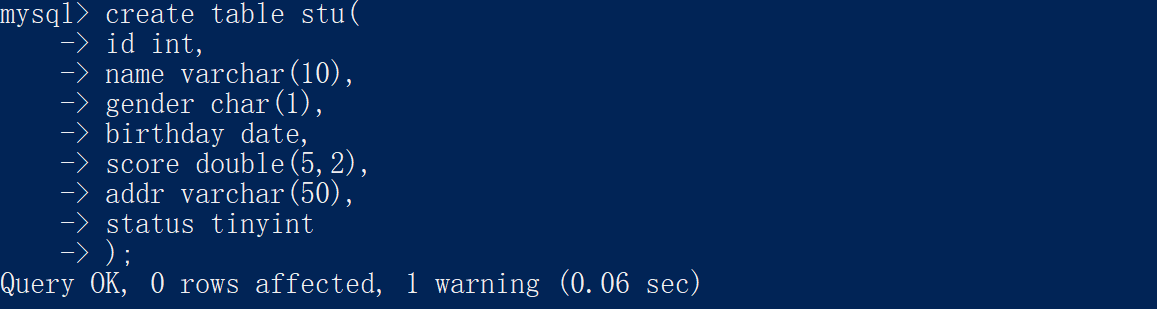
2.3 创建表
创建一个新的表:
createtable 表名称(
字段名1 数据类型,
字段名2 数据类型,...
字段名n 数据类型 #这里是不需要加上,的);
例如:
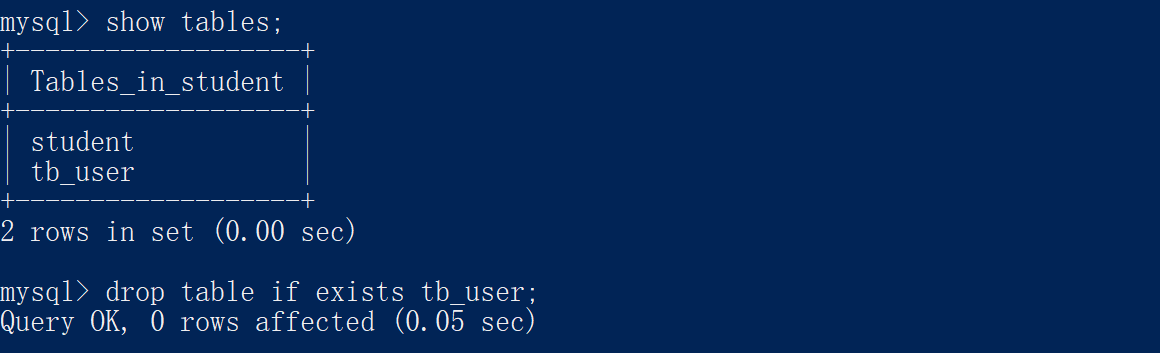
2.4 删除表
删除表:
droptable 表名;
删除表(判断表是否存在):
droptableifexists 表名;
例如:
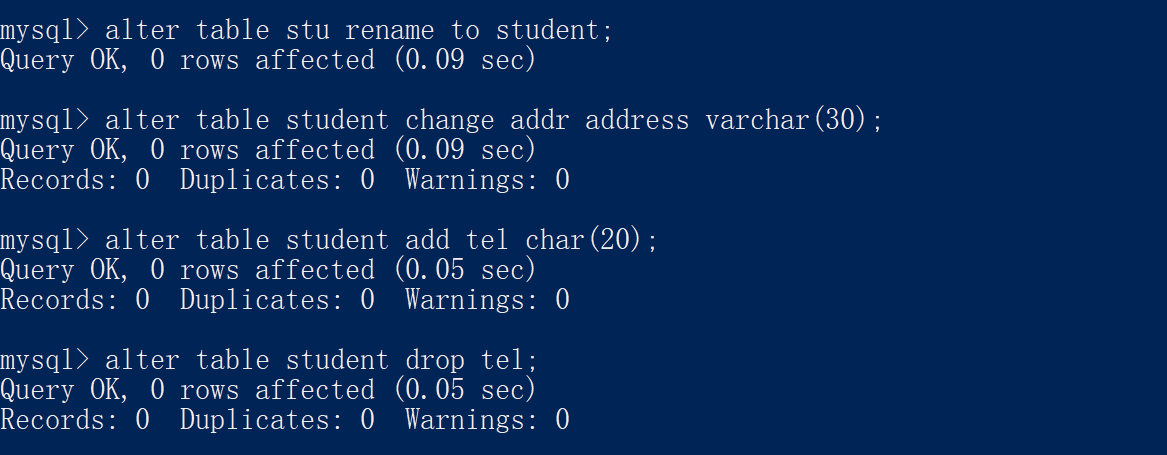
2.5 修改表
修改表名:
altertable 表名 renameto 新的表名;
增加一列:
altertable 表名 add 列名 数据类型;
修改数据类型:
altertable 表名 modify 列名 新数据类型;
修改列名和数据类型:
altertable 表名 change 列名 新列名 新数据类型;
删除列:
altertable 表名 drop 列名;
例如:
3. 实战案例详解
需求:设计包含如下信息的学生表,请注重数据类型、长度的合理性。
- 编号
- 姓名,姓名最长不超过10个汉字
- 性别,因为取值只有两种可能,因此最多一个汉字
- 生日,取值为年月日
- 成绩,小数点后保留两位
- 地址,最大长度不超过 64
- 学生状态(用数字表示,正常、休学、毕业…)
在完成这样一个案例前,首先要创建一个学生数据库,在数据库中创建一张新的表,创建表时注意语法格式,数据类型和长度的合理性。
以管理员身份运行命令提示符cmd,启动Mysql服务,登录MySQL:

创建学生信息数据库:
createdatabaseifnotexists student;
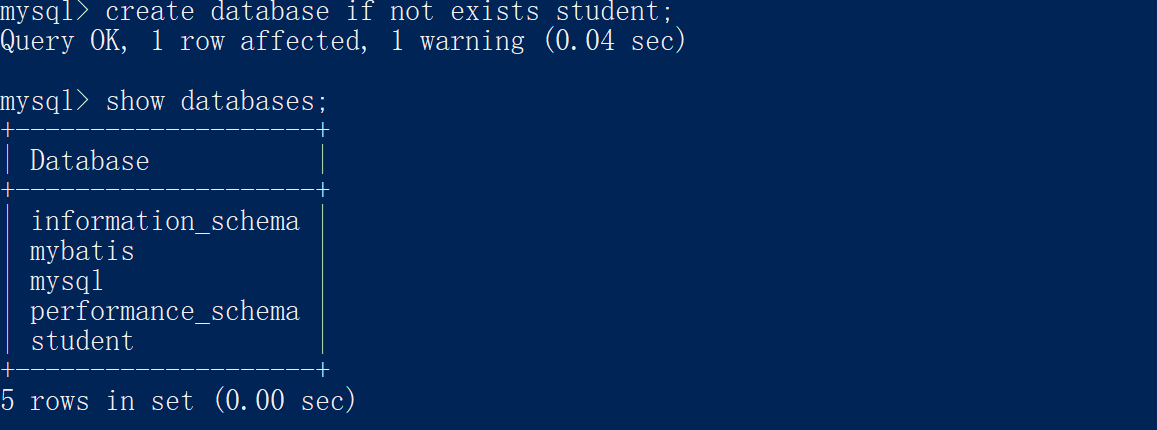
使用
student
数据库:
use student;

创建数据表:
createtable stu(
id int,-- 编号
name varchar(10),-- 姓名
gender char(1),-- 性别
birthday date,-- 生日
score double(5,2),-- 分数
addr varchar(50),-- 地址statustinyint-- 状态);
现在,我们已经学会了写SQL来操作数据库,但是我们在命令行中写SQL时,往往有体验感差,效率低等问题,今天开始我们就要学习
在MySQL的图形化客户端Navicat中执行SQL语句
。

Navicat 为数据库管理、开发和维护提供了一款直观而强大的图形化界面,大大的提高了工作效率,建议在学习中也使用这款开发工具。
接下来,在Navicat中新建数据库,新建查询,我们就可以编写SQL并且执行SQL语句了。
4. DML- 增删改数据
4.1 添加数据
给指定列添加数据:
insertinto 表名(列名1,列名2...)values(值1,值2...);
给全部列添加数据:
insertinto 表名 values(值1,值2...);
批量添加数据:
insertinto 表名(列名1,列名2...)values(值1,值2...),(值1,值2...),(值1,值2...)...;
批量添加数据(省略字段名):
insertinto 表名 values(值1,值2...),(值1,值2...),(值1,值2...)...;
在开发过程中添加数据时是不建议省略字段名的,这样降低了代码的可读性,使效率下降。例如:
查询表中的所有数据的方法是:
select*from 表名;
后面会用到的。
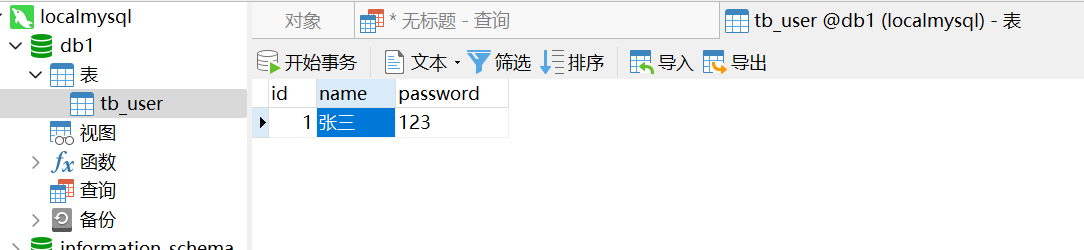
需求:往下面的
tb_user
表中添加一条数据。
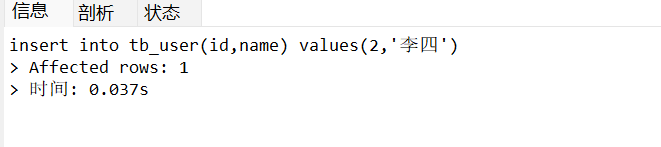
insertinto tb_user(id,name)values(2,'李四');
添加成功:
4.2 修改数据
修改表的数据:
update 表名 set 列名1=值1,列名2=值2...[where 条件];
在修改数据时,也可以不使用where条件,此时的操作是修改整列数据,这样的操作是很危险的。
需求:把下面
tb_user
表中的张三的密码改为abc23

update tb_user set passwor d ='abc123'where name='张三';
修改成功:

4.3 删除数据
删除表的数据:
deletefrom 表名 [where 条件];
在删除某条数据时,如果不使用where条件,将会导致删除整个表的数据。
需求:删除tb_user表中的李四记录。
deletefrom tb_user where name='李四';
操作成功:

5. DQL- 数据的查询操作
查询是数据操作至关重要的一部分,
比如说在所有商品中查找出价格在规定范围内的所有商品,要想把数据库中的数据在客户端中展示给用户,一般都进行了查询的操作。
在实际开发中,我们要根据不同的需求,并且考虑查询的效率来决定怎样进行查询,学习查询前,可以先看看查询的完整语法:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUPBY
分组字段
HAVING
分组后条件
ORDERBY
排序字段
LIMIT
分页限定
根据查询的完整语法中的关键字,我们分别来学习
基础查询,条件查询,排序查询,分组查询和分页查询。
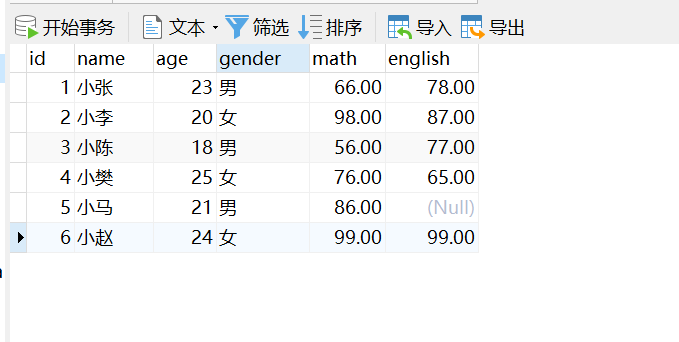
下面的练习中使用以下的案例学习单表查询:
-- 删除stu表droptableifexists stu;-- 创建stu表CREATETABLE stu (
id int,-- 编号
name varchar(10),-- 姓名
age int,-- 年龄
gender varchar(5),-- 性别
math double(5,2),-- 数学成绩
english double(5,2)-- 英语成绩);-- 添加数据INSERTINTO stu(id,name,age,gender,math,english)VALUES(1,'小张',23,'男',66,78),(2,'小李',20,'女',98,87),(3,'小陈',55,'男',56,77),(4,'小樊',20,'女',76,65),(5,'小马',20,'男',86,NULL),(6,'小赵',57,'男',99,99);
在Navicat中选中SQL并执行:
5.1 基础查询
1.1 基础查询语法
查询多个字段:
select 字段列表 from 表名;
查询全部字段:
select*from 表名;
去除重复记录:
selectdistinct 字段列表 from 表名;
起别名操作:
select 字段名 别名 from 表名;
1.2 基础查询练习
使用学生表进行基础查询练习:
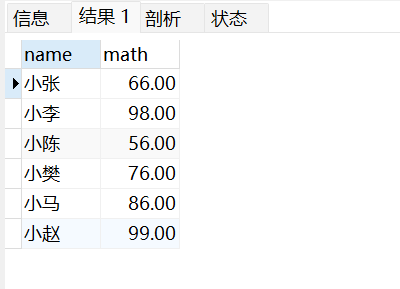
查询多个字段的练习:
select name,math from stu;
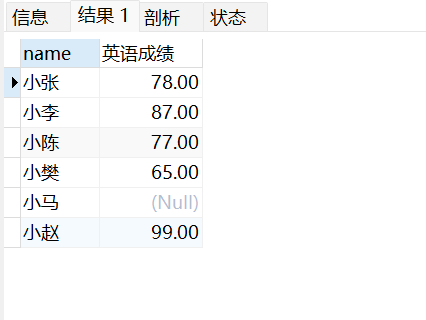
起别名操作练习:
select name,english 英语成绩 from stu;
5.2 条件查询
2.1 条件查询语法
一般语法:
select 字段列表 from 表名 where 条件列表;
条件查询一般配合运行符进行,下面是常见的几个运算符:
运算符功能描述> < = !大于 小于 等于 不等于between…and…在这个范围之内in(…)多选一is null / is not null是null / 不是nulland 或 &&并且or 或 ||或者
2.2 条件查询练习
使用学生表进行条件查询练习:
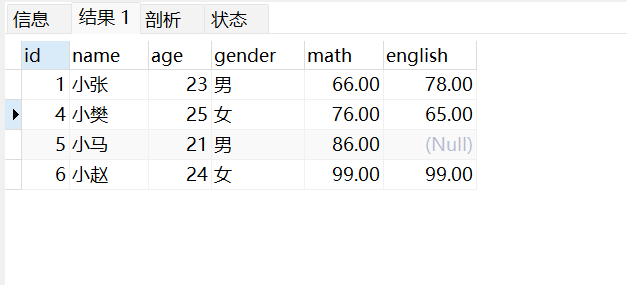
查询年龄大于20的学生信息:
select*from stu where age>20;
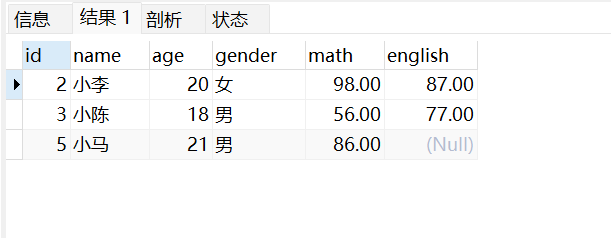
 查询年龄等于18岁 或者 年龄等于20岁 或者 年龄等于21岁的学生信息:
查询年龄等于18岁 或者 年龄等于20岁 或者 年龄等于21岁的学生信息:
select*from stu where age in(18,20,21);
 模糊查询使用like关键字,可以使用通配符进行占位:
模糊查询使用like关键字,可以使用通配符进行占位:
- _ : 代表单个任意字符
- % : 代表任意个数字符
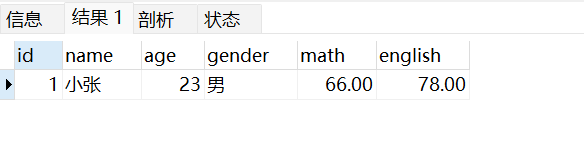
查询姓名中含有张的学生信息:
select*from stu where name like'%张%';
5.3 排序查询
3.1 排序查询语法
select 字段列表 from 表名 orderby 排序字段名1[排序方式]...;
注:排序方式有两种:分别是升序ASC和降序DESC,默认情况下是升序ASC。
3.2 排序查询练习
使用学生表进行排序查询练习:
查询学生信息,按照数学成绩降序排列:
select*from stu orderby math DESC;
5.4 聚合函数
4.1 聚合函数语法
什么是聚合函数呢?在进行查询操作时,往往需要对一整列进行运算,例如可以计算一整列成绩数据的平均值,我们就要使用聚合函数。下面是常见的聚合函数:
函数名功能count(列名)统计数量(一般选用不为null的列)max(列名)最大值min(列名)最小值sum(列名)求和avg(列名)平均值
一般语法:
select 聚合函数 from 表名;
注:NULL值不参与聚合函数运算。
4.2 聚合函数练习
使用学生表进行聚合函数的练习:
统计该表中一共有几个学生:
selectcount(id)from stu;

上面我们使用某一字段进行运算,这样做可能面临的问题是某一个值可能是NULL,所以我们一般使用
*
进行运算,因为一行中不可能所有的字段都是NULL。
selectcount(*)from stu;
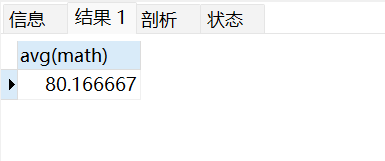
查询数学成绩的平均分:
selectavg(math)from stu;
5.5 分组查询
5.1 分组查询语法
select 字段列表 from 表名 [where 分组前的条件限定]groupby 分组字段名 [having 分组后的条件过滤]
注:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义。
5.2 分组查询练习
使用学生表进行分组查询练习:
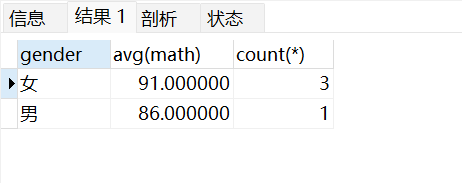
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组:
select gender,avg(math),count(*)from stu where math >70groupby gender;
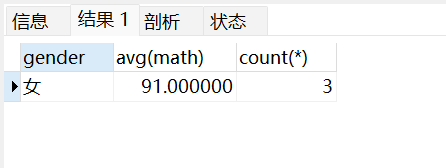
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的:
select gender,avg(math),count(*)from stu where math >70groupby gender havingcount(*)>2;
注:
where 和 having
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。所以,where 不能对聚合函数进行判断,having 可以。
5.6 分页查询
6.1 分页查询语法
在我们的印象中,网页在展示大量的数据时,往往不是把数据一下全部展示出来,而是用分页展示的形式,其实就是对数据进行分页查询的操作,即每次只查询一页的数据展示到页面上。
select 字段列表 from 表名 limit 查询起始索引,查询条目数;
在
limit
关键字中,查询起始索引这个参数是从0开始的。
6.2 分页查询练习
使用学生表进行分页查询练习:
从0开始查询,查询3条数据:
select*from stu limit0,3;
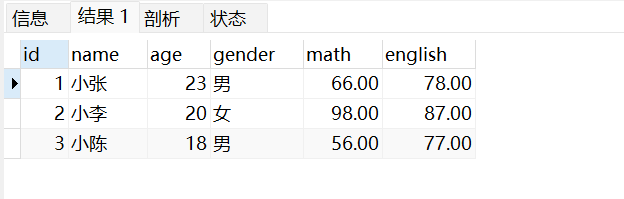
起始索引 = (当前页码 - 1) * 每页显示的条数
6. 总结
关于SQL的常用操作:CRUD,增加(create),查询(retrieve),更新(update) 以及删除(delete) 已经做了一个硬核的整理,为深入学习sql做了充分的准备。从今天开始,你也是一个会sql的人了!
版权归原作者 橙子! 所有, 如有侵权,请联系我们删除。