
摘要:本文整理自字节跳动基础架构工程师刘畅和字节跳动机器学习系统工程师张永强在本次 CommunityOverCode Asia 2023 中的《字节跳动 Spark 支持万卡模型推理实践》主题演讲。
背景介绍
在云原生化的发展过程中 Kubernetes 由于其强大的生态构建能力和影响力,使得包括大数据、AI 在内越来越多类型的负载应用开始向 Kubernetes 迁移,字节内部探索 Spark 从 Hadoop 迁移到 Kubernetes 对作业的云原生化运行。字节跳动的大数据资源管理架构和 Spark 的部署演进大致可分为三个阶段:
- 第一个阶段是完全基于 YARN 的离线资源管理,通过大规模使用 YARN 管理大数据集群,可以有效提高 Spark 资源使用率的同时降低资源的运营和维护成本。
- 第二个阶段是离线资源混部阶段,通过构建 YARN 和 Kubernetes 混合部署集群,进一步提升在离线资源整体的利用率。通过混合部署技术,集群和单机的资源利用率都得到了显著的提升。更高的资源利用率提升意味着需要更完整的隔离手段。因此我们开始逐步推进 Spark 的容器化部署。
- 第三个阶段是彻底的云原生化部署。在离线负载不再使用不同的架构进行管理,真正实现了技术栈和资源池的统一,Spark 的云原生化也在逐步地构建和完善。
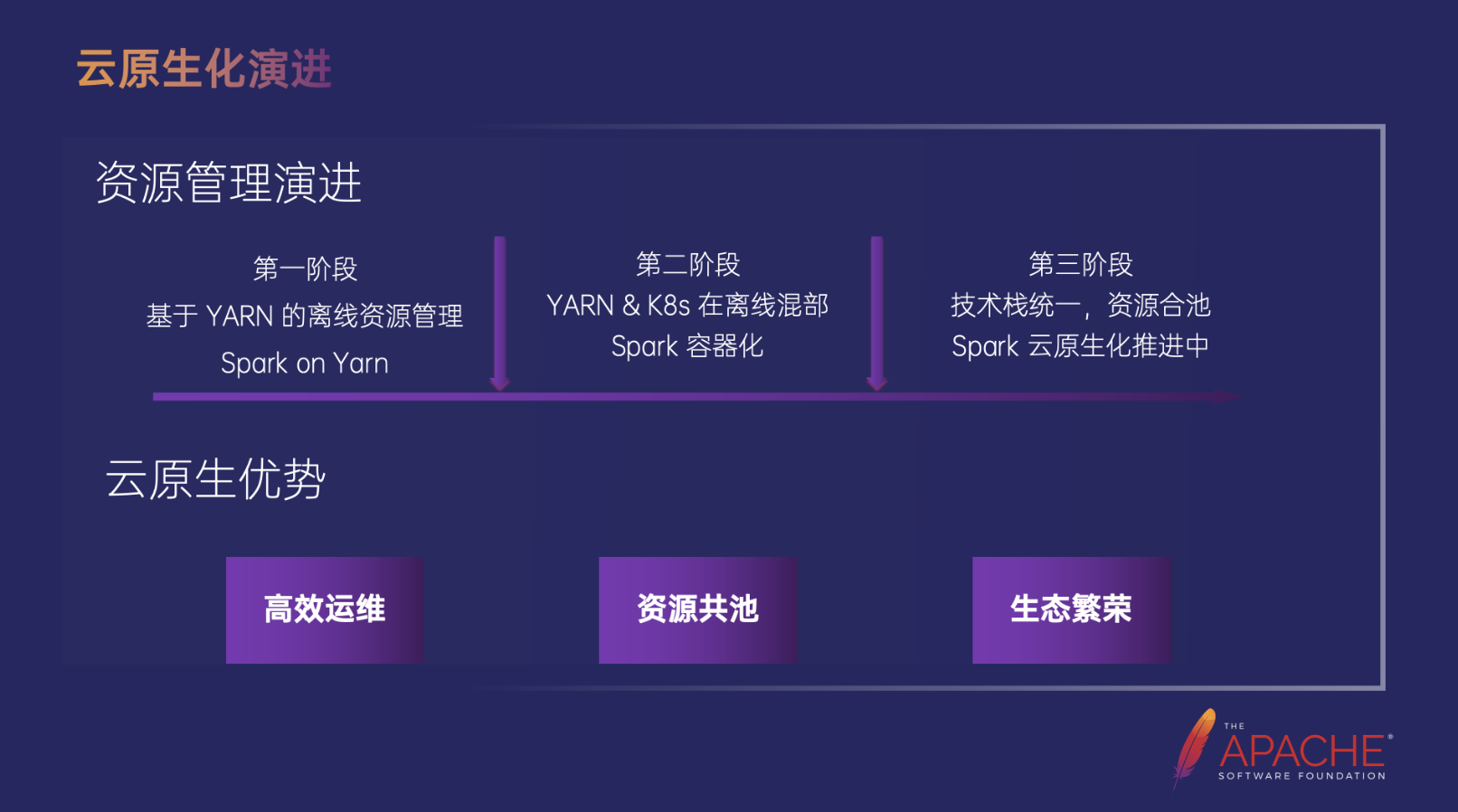
当然云原生化几乎是业界一致的发展趋势,那为什么要使用云原生?为什么要使用 Kubernetes 作为统一的资源管理底座呢?主要有三个优势,第一个是高效运维,Kubernetes 提供敏捷的负载创建和管理,无论是在线负载还是大数据负载,都能够便捷实现持续开发、集成和部署。第二个是资源共池,统一的云原生底座减少了基础设施开销,也进一步提升了资源流转效率,在资源利用率方面,整个数据中心的利用率可以得到更全面、充分的提升,实现降本增效。第三个就是生态繁荣,我们知道 Kubernetes 拥有几乎最活跃的生态圈,它通过提供标准化的接口定义,促进了各个层次的生态发展,无论是基础运维设施、上层应用管理还是底层的网络、存储等,在管理中都有非常多的可选方案,为Spark的云原生化使用提供了便利。
字节跳动 Spark 规模

字节跳动拥有业界领先的 Spark 业务规模,每天运行数百万的离线作业,占有资源量数百万核,GPU 数万张卡,总集群规模节点也达到了上万台。如此大规模的 Spark 负载意味着要实现 Spark 彻底原生化不是一件容易的事情。以下是我们在实践中思考的问题。Spark 作业部署是 Standalone 的静态部署还是 K8s Native 动态部署,是否使用 Operator?在 K8s 上如何实现 Spark 作业的租户级别资源管控,在作业提交时进行管控还是在 Pod 创建时进行管控?如何支持 Spark 的调度需求?在 Spark 提交作业时,大量的 Pod 创建是否引起调度瓶颈?如此大规模作业的架构迁移,我们如何做周边能力建设,打平作业迁移前后的体验?
在 Spark 探索云原生化的过程中,合作方也面临着很多问题,搜索任务有大量 GPU 需求量极大的离线批处理任务,在线集群业务低峰可空出大量资源,部分在线服务无法用满 GPU,整体利用率低。机器学习作为 Spark 的重要合作方,我们通过解决以上问题,一起健壮周边生态,Spark 为业务做了针对性的引擎增强,业务也得到 Spark 云原生化资源、调度、管理上的收益。
Spark 云原生方案及引擎增强
Spark 云原生技术方案目前主流的使用方式包括 Spark Native 和 Google 开源的 Spark Operator 两种方式。两种方式殊途同归,最终都是调用 Spark-submit 命令行工具。不同的是,Google 的 Spark Operator 支持了更加丰富的语义,通过 Operator 和 Mutatingwebhook 的方式注入了更加丰富的、贴近 K8s 的 Feature。
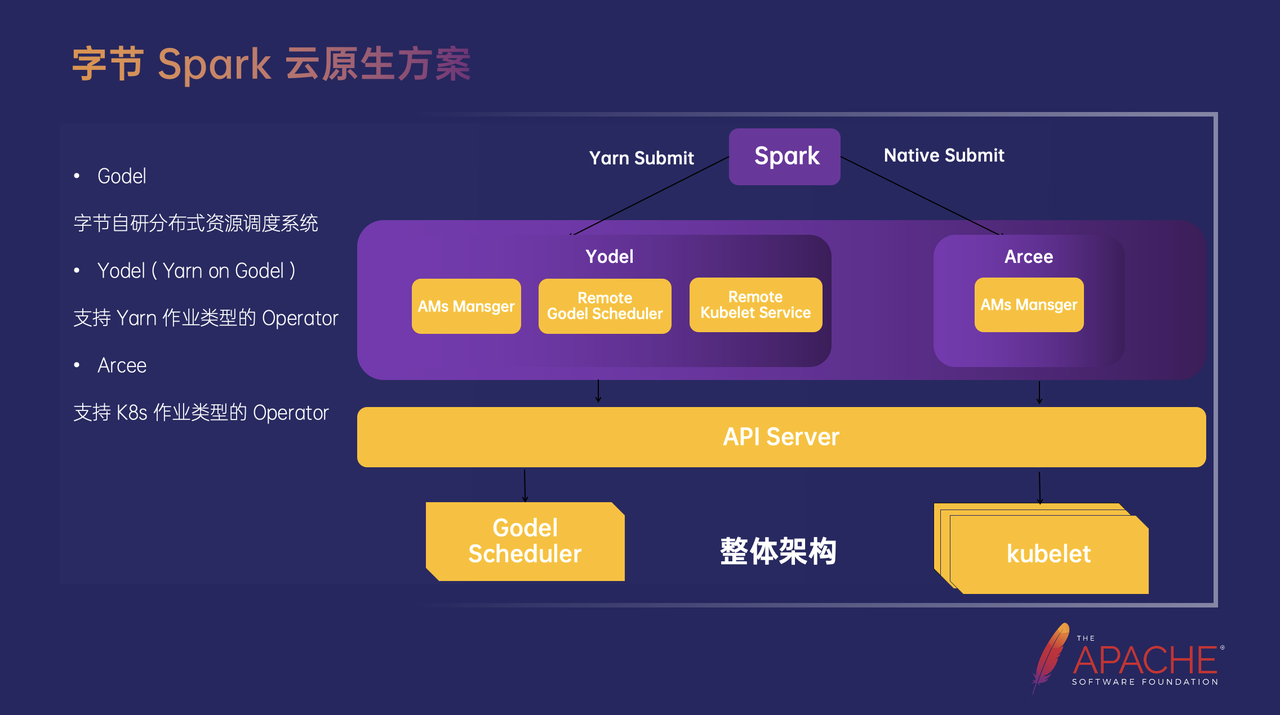
字节 Spark 云原生技术方案有两种,第一种是平滑迁移,无需修改 YARN 的提交方式,通过 Yodel 提交给 Kubelet 或者 Gödel 进行调度,另一种是 Spark Native Submit,通过 Arcee 提交到调度系统上。这里需要解释的概念是:Gödel 是字节自研的分布式资源调度系统,托管 YARN 和 Kubernetes 的资源调度能力,统一 Kubernetes 和 YARN 的资源池、Quota、调度和隔离;Yodel 是字节自研的支持 YARN 作业类型的 Operator,改造了 YARN 的 RM 和 NM 组件。Arcee 是字节自研的统一的云原生大数据 Operator,可以更方便的管理 Spark、Flink 等大数据负载。Yodel 和 Arcee 的区别 在于 Yodel 是“兼容 YARN 协议”的大数据 on Gödel 方案,Arcee 是“兼容 K8s 协议” 的大数据 on Gödel 方案,两者底层会复用相同的 Gödel Scheduler 和 Kubelet 技术。
本篇实践是彻底的云原生部署,即通过 Arcee Operator 提交,Arcee 的核心能力主要包括作业生命周期管理、作业资源管理和一些引擎的定制功能等。
Arcee 介绍
Arcee** 的核心设计思路是两级作业管理**,借鉴了 YARN 的两级管理模式——中心管理服务 AM,主要负责创建和维护大数据作业,再由 AM 创建维护计算 Worker。对应到 Spark 作业中就是由 Arcee 创建 Driver,Driver 创建所需的 Executor。这种管理模式,一方面可以有效管理和表达大数据作业状态,定制作业管理策略。另一方面也可以确保计算引擎对计算作业运行有充分的掌握能力,有能力按需调整资源使用。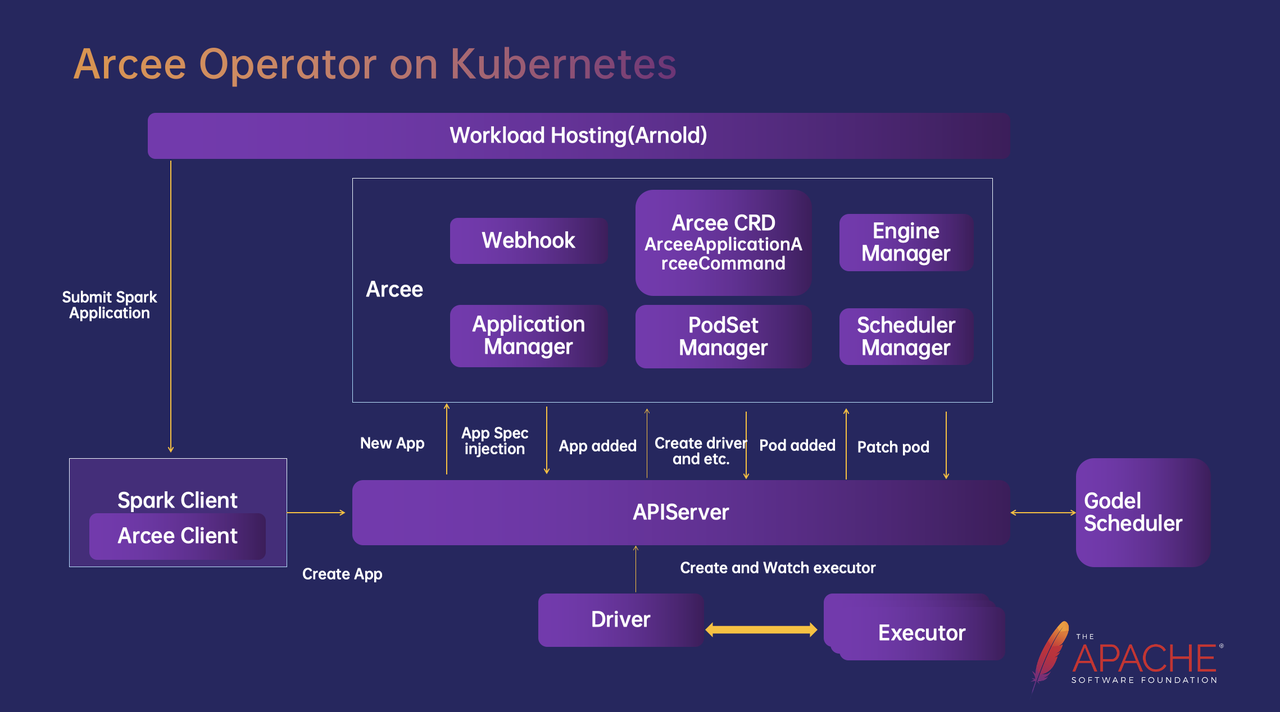
整体架构如图所示,Arcee Operator 内部包含了六个模块,其中 Arcee CRD 模块定义了 ArceeApplication 和 ArceeCommand 两种资源类型:ArceeApplication 用于描述具体的作业,ArceeCommand 描述用于作业的操作;Webhook 模块主要用于 Application / Pod 的配置注入和校验;Application Manager 负责作业的生命周期管理;PodSetManager 是作业资源管理;EngineManager 是引擎管理,用于实现一些引擎定制能力;Scheduler Manager 是调度器对接层,用于完成 Spark 等大数据作业与批调度器的对接。
作业完整的提交流程是 Arnold(机器学习平台)发起 Spark 作业提交,调用 Spark Client 并填上所需的参数向 K8s 提交作业。在 Arcee 模式下,Spark Client 使用内置的 Arcee Client 创建 Spark ArceeApplication,由 Webhook 预处理后提交到 APIServer。接下来由 Arcee Controller 收到 Application 的创建事件,Arcee ApplicationManager 生成对应的作业状态,并根据 Application 内的描述创建 Driver,由 Driver 按需创建所需的 Executor,Arcee 会持续监听所有 Executor,也会进行相关配置的注入。Application 内 Driver、Executor 的所有 Pod 都会维护在 Arcee 的 PodsetManager 中,用于资源使用统计,并向其他模块提供相关信息。
Spark on Arcee

Spark on Arcee 在一定程度上可以认为是 Spark Native 部署模式的改进,主要区别在于 Spark Client 中间内置的 K8s Client 替换成 Arcee Client;负责管理 Driver 负载的组件变成 Arcee Operator;Driver 和 Executor 从各自独立变成拥有统一的 Arcee Application 进行维护。Arcee 也提供作业生命周期管理、调度屏蔽等相关功能。
Spark 引擎优化
在上一节介绍的业务背景实践下,Spark 引擎侧做了如下几个增强,以下为各问题的产生和解决方案。
- Executor 优雅退出避免 MPS 状态异常 目前一部分需要使用 GPU 的 Spark 刷库作业运行在 K8s 上,并与在线服务进行混部,这些作业通过 MPS 共享宿主上的 GPU 设备( MPS 是 Nvidia 提供的 Multi-Process Service 技术,允许同一时间不同的进程对 GPU 进行空分复用,而不是默认的时分复用),如果多个共享的进程有一个在执行 Kernel 时被 Kill,容易引发硬件层面的 Fatal Exception,会导致此 GPU 上的其他进程一起退出,因此对于每个进程的优雅退出处理十分必要。 在 K8s 上运行可能会因为某些调度原因导致容器驱逐或资源耗尽被杀,我们从 Driver、Executor、 Daemon、Worker 关系中仔细分析了各种 Executor、Worker 退出的情况。通过在容器环境中实现 Executor 优雅退出,捕获退出信号并自动做 cudaDeviceSync,防止离线退出导致 MPS 处于未定义状态 。
- 通过 Quota 解决大量 Pending Pods 问题 Spark 支持 DynamicAllocation,用户在实际使用中,一般设置 Max 为比较大的值,当前 Arnold 为了防止产生大量 Pending Pods,是按照 Max 进行 Quota 校验,只有 Quota 足够启动 Max 个 Executor 时才可以真正提交到 K8s,否则在 Arnold 服务中排队等待。但当前以 Max 来 Check Quota 缺点是容易浪费资源。如果队列中有配额小于 Max 的值,按当前任务的特性是可以先启动任务把当前资源用起来的,而当前的 Quota Check 逻辑则导致此部分资源无法使用,任务一直在上层排队。可以通过以下几个手段解决这个问题:- 通过 Spark.kubernetes.allocation.batch.size 参数来控制每批拉起的 Pod 数量;- 通过 Spark.kubernetes.allocation.maxPendingPods 参数限制单个作业最大 Pening Pods 数;- 但调参仍无法解决同一队列同时间段的大量提交问题,所以可以通过 Webhook 根据 Queue 检查 Quota,无 Quota 则 Pod 创建失败,Spark 处理 Exception,添加创建 Pod 策略,指数增加创建时间间隔等方式解决这一问题。
- 混部****非稳定资源场景作业健壮性优化
举几个例子,调度资源稳定性优化在多次压测测试中经常会发现 Spark Executor Pod 被异常拒绝 (UnexpectedAdmissionError)。通过集中排查,修复了一系列 Kubelet 逻辑中存在的多个 Race Condition 的问题,日均混部资源可达极限填充率的稳定增大。我们还进行了一系列的调优与改造,增加一些 GPU 指标采集打点方便观察资源的使用情况,通过 Blacklist、Speculation 等参数提升任务对资源不稳定性的容错能力。
周边生态融合
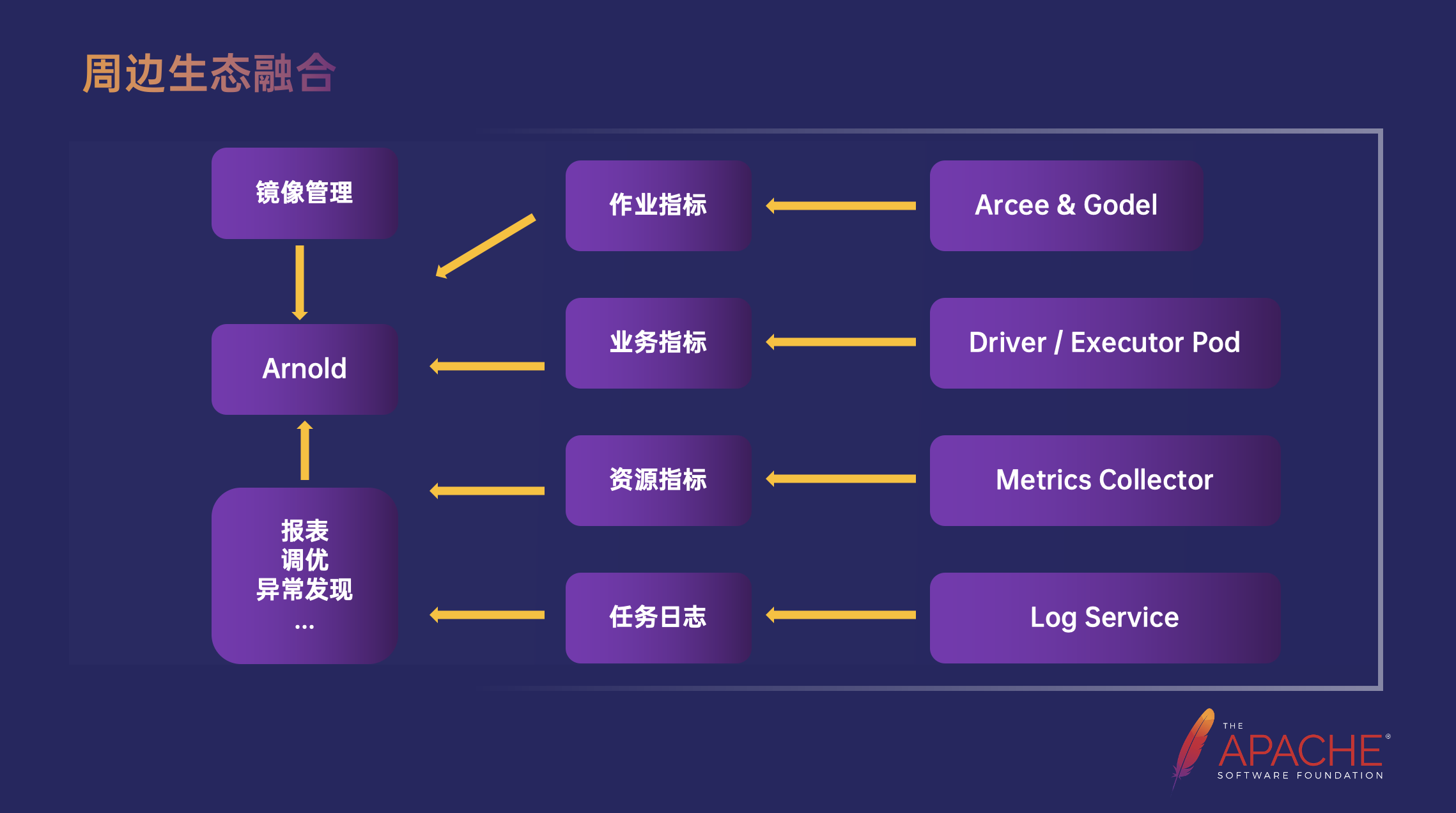
在 Spark on K8s 的环境中,日志和监控指标也是非常重要的,它可以帮助我们观察整个集群、容器、任务的运行情况,根据日志和监控快速定位问题并及时处理。所以也在 Spark 云原生化的过程中逐步构建了一套 Trace 体系。Arcee Operator 和 Gödel 调度器提供了一些作业指标、Spark 提供了业务指标、单机的 Metrics Collector 组件提供了物理机指标和容器指标。在日志方面,通过每个 Node 上运行的 Log Agent 采集指定路径的日志自动上传至日志平台进行解析查询。所有的指标和日志都可以基于 Arnold 机器学习训练平台进行平台化实时查询,也提供了具体的数据表,用户可以根据需求进行更高阶的查询,比如制作报表,作业调优,作业异常发现等。同时 Arnold 也可以通过镜像管理做到及时追新。
万卡模型推理实践

我们目前的集群主要分为离线集群和在线集群,离线集群以训练任务为主,主要关注任务的吞吐,有 V100、A100、A800 这些卡,在线集群主要以在线推理服务为主,关注延迟和吞吐,主要是 T4、A10、A30 这些小一点儿的卡,整体拥有数万卡的GPU。
主要矛盾

目前的主要矛盾是在离线集群 Quota 都已经满额分配了,从逻辑上来讲资源都已经分配出去了,但在离线集群整体的利用率还有很大的提升空间。另外内部也有很多的计算需求没有得到满足。打个比方来说,我们集群就像一个大的容器,这些高优的任务其实就像石头,石头可能已经塞满,但是石头跟石头之间还有很多的缝隙,这些缝隙其实还可以塞很多的沙子,所以我们的问题定义就是要找到这些缝隙填满沙子,也就是说找到合适的可以再利用的资源,提上合适的任务。
资源
离线集群:低优任务
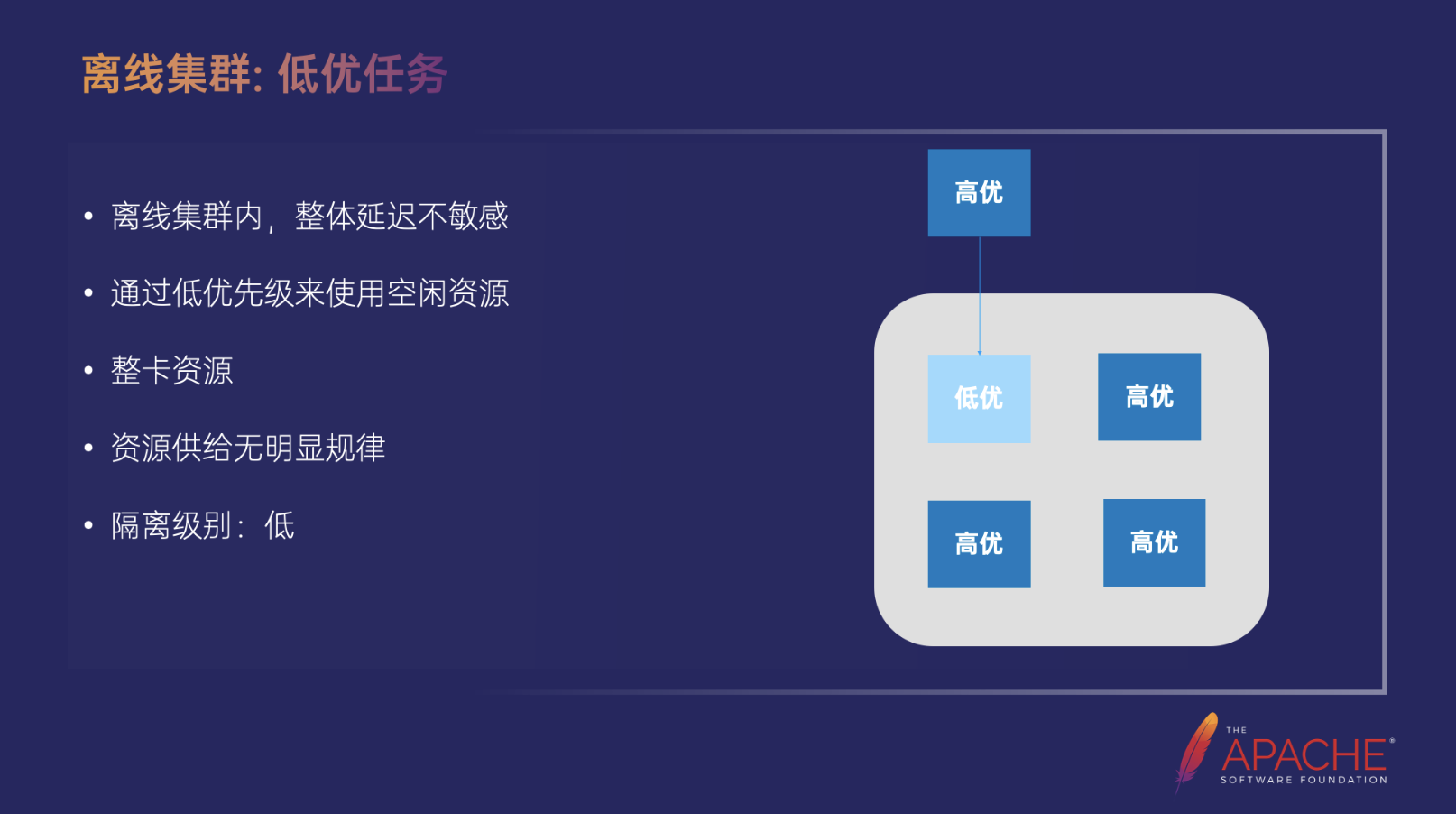
首先是离线集群内的低优任务,这部分整体在离线集群内,延迟都是不敏感,我们就通过低优先级来使用这部分空闲资源,有空闲的时候就调度低优先级的任务过来,然后有高优先级任务时候就抢占。同时这些都是整卡的资源,它的供给没有明显的规律,因为离线的提交本身就没有太明显的规律,隔离级别整体也是比较低的。
在线->离线:潮汐
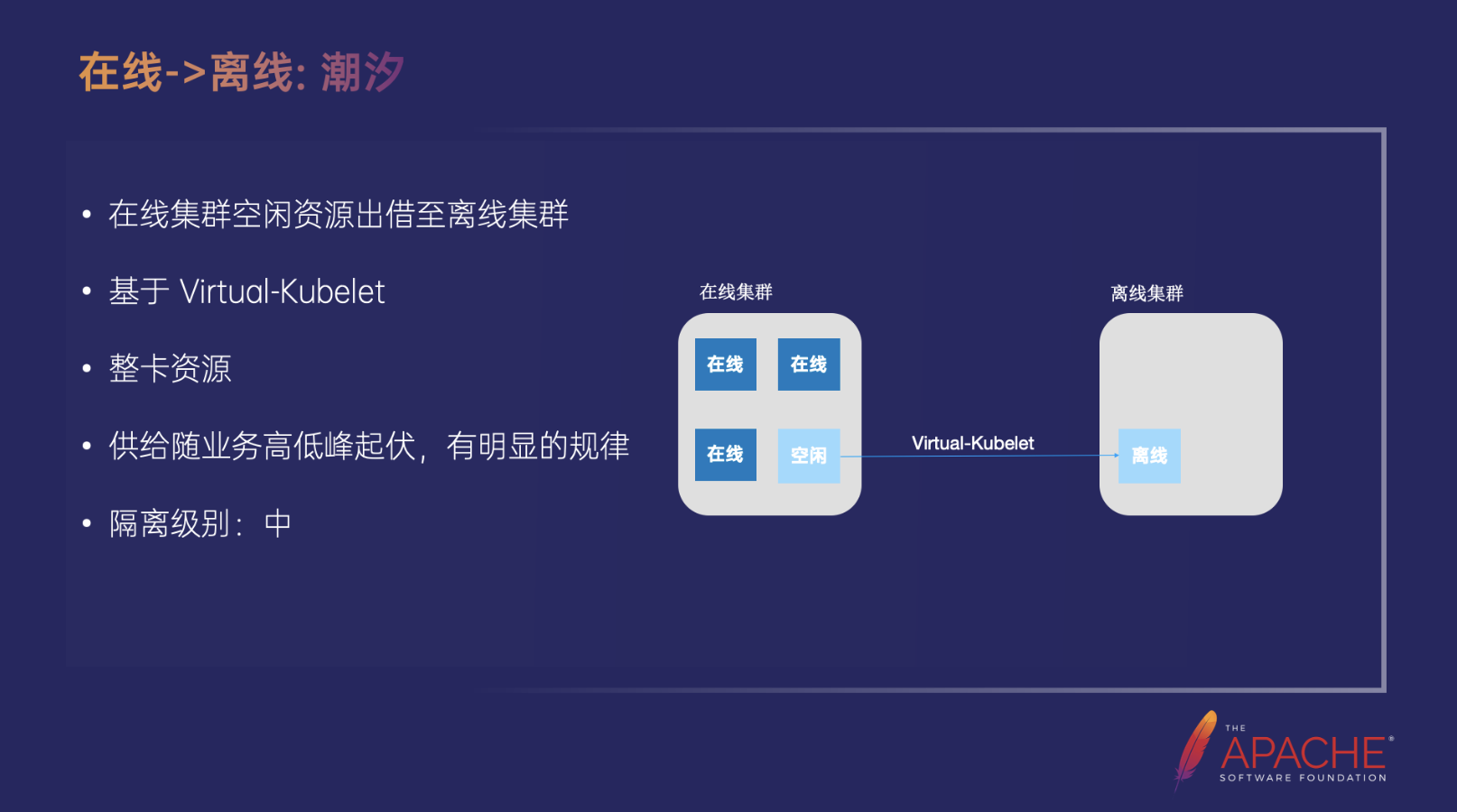
另一部分就是在线到离线的潮汐资源,这部分就需要将在线集群空闲的资源出借到离线集群,我们整体是基于 Virtual-Kubelet 来实现的,这部分也都是整卡资源,它的供给是随着业务高低峰起伏有一个明显的规律,在线业务低峰的时候就通过自动缩容把资源空出来,然后出借到离线集群,等到高峰时又会扩容,集群把离线 Pod 给驱逐掉,它是一个中等的隔离级别,在离线的 Pod 是要跑在同一台机器上,但是卡还是可隔离开的。
在线->离线:常态混部
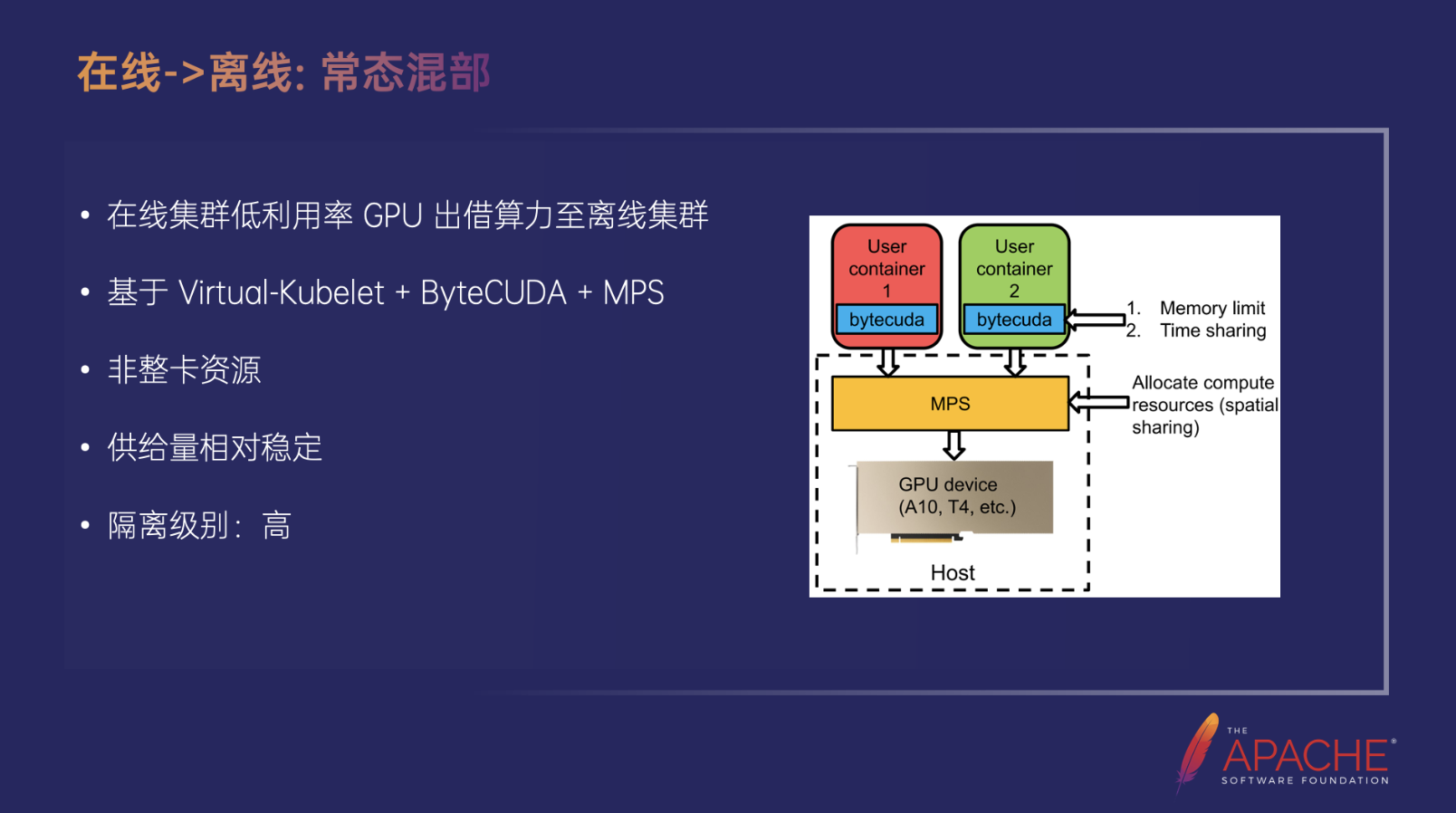
另一部分就是在线到离线的常态混部资源,这部分其实是我们把在线集群内利用率比较低的 GPU 一部分算力出借到离线集群,主要是考虑的是有一些模型用不满整卡,空的算力是可以再被利用起来的,整体是基于 Virtual-Kubelet + ByteCUDA + MPS 实现的。
ByteCUDA 是一个自研的 CUDA Hook,它在上层做一些显存隔离、时分复用的工作,下层 MPS 通过空分复用整体提高隔离级别。由此出借的其实是一个非整卡的资源,即说一卡多用,这个卡上可能有在线的任务,也有离线的任务。好处供给量是相对比较稳定的,这部分服务不太会自动扩缩容,都跑在同一张卡上,隔离级别也是最高的。
关于常态混部我们有一个很大的问题是要如何避免离线影响到在线?首先显存隔离跟算力隔离是必须要做的,另外就是我们通过一套负载自适应的动态出借算法,或者叫出借策略,在一个窗口期内观察 GPU 的一些功耗,然后根据这些指标来判断我们的离线计算是否要主动避让在线的计算请求,使在线少受影响。

另外就是 MPS 比较出名的故障传播问题,上面讲到的是通过优雅退出来解决,通过上面的效果图可以看到在混部前后在线的吞吐几乎是没有变化的,延迟大概增大了 0.75 ms,其实也是可以接受的,它的利用率从原先的 10% 提升到了 70%,这样在整体收益上对在线的影响很小,但利用率得到了大幅度提升。
任务
资源之后就是任务了,也就是我们说的沙子。第一就是他的需求量一定要足够大,不然“折腾”起来没有太大必要。另外因为这些本身就是碎片资源,需要任务的大小尺寸相对适中,不能是特别大的任务。还需要这部分任务不能重度消耗这些不可隔离的资源,比如磁盘、网络等;另外任务也要能够适应资源的自动扩缩,因为这些资源都是弹性资源,在扩任务的时候要自动用上这些资源,缩的时候才不至于被这个缩容打挂。
基于 Spark 的离线推理任务

基于以上的实现需求最终就锁定了基于 Spark 的离线推理任务,首先因为内部有大量的离线推理的需求,需求量足够大;另外推理任务的流程相对是比较简单的,而且 Executor 之间也没有什么通信的需求,也不需要在线的那些卡,不需要 RDMA 等;另外就是大量的数据其实本身就是在 HDFS、 Hive 的存储上,跟 Spark 是天然亲和的;同时我们也要借助 Spark 的数据处理和数据分发的能力;并需要基于 Dynamical Allocation 实现动态扩缩容的能力。
SDK 构建

在锁定任务之后,我们要做的是把最佳实践尽可能的封装起来,以上是 SDK 的一个示意图,即一个 Tide Box,支持了 Pytorch,Tensorflow 等常见的模型推理,同时也支持 Partition 级别的 Checkpoint。这样在资源回撤的时候就不需要重复计算了,能够避免算力的浪费,并通过支持 Batching 可以提高整体的资源利用率。
平台建设

在 SDK 构建之后,平台建设也是非常重要的一个方面,我们不希望用户直接通过不便于管控的 Spark Submit 来执行命令。因此整体以 Arnold 机器学习平台作为底座统一管理这些资源,基于 Notebook 开发调试,必要的变量都可以提前设置好,用户也可以单步调试,不需要手动搜 Submit ,相对便捷的同时不同场景的资源切换也更灵活。
另外在任务的启动方式上可以支持基于上游事件触发、定时触发、 API 触发等多种方式,方便了用户的使用。比如在要组一些 Pipeline 或用户自动化的需求中都可以通过这些方式灵活的实现。另外任务的运维也是很重要的,可以实现查看历史任务及问题一键回溯的能力。
任务-资源匹配
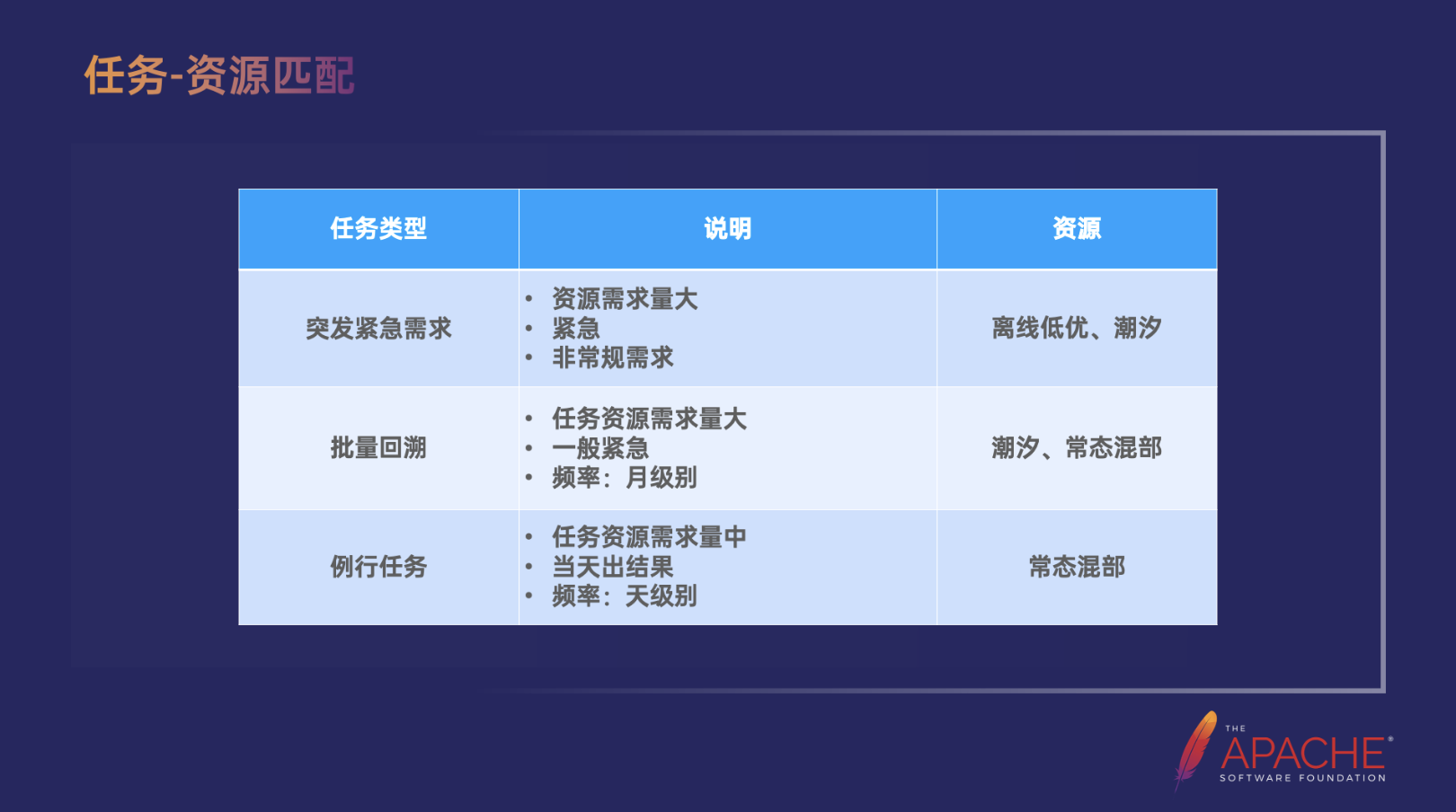
Spark 推理任务分了很多种类型,一种是突发紧急需求,这部分资源需求量是比较大的,时间也比较紧急,而且通常是一些非常规的需求,这部分我们需要使用离线低优和潮汐这种较整卡、算力较强的资源。另外需要批量回溯定期需要重跑、资源需求量相对较大,任务紧急程度一般紧急的任务,并使用潮汐、常态混部的这些资源。而例行任务可能是天级别的,资源需求量是中等的,这种我们会用相对更稳定的,供给更稳定的常态混部资源来支持。
从在线出借到离线的峰值状态大概有 1w+ 的潮汐 GPU;常态混部是 2w+ 左右,这部分也因为在离线的混部,整体利用率翻了一倍;离线推理任务每天大概有 100+,单任务最高 5K+ GPU,这部分是我们主动做限制的,不然用户可能会提高更多,导致资源全部被占用等情况;一个典型的刷库任务从原先需要稳定资源运行 9.5 天,通过这种弹性资源调度缩短到 7.5 个小时就能够完成。
未来展望
未来我们的弹性混部资源需要做的更多,不仅需要提高整体的资源利用率,也需要对整体的资源进行优化。一是尽可能避免对在线的影响,让离线也能用的更多,拟合到一个更高的利用率;另外我们还是要接入更多的业务,扩大整体的规模、收益的同时也要让整体的性能做得更好,同时也要减少或者尽可能避免由于不必要的资源回退引发的相关问题。
版权归原作者 字节跳动云原生计算 所有, 如有侵权,请联系我们删除。