
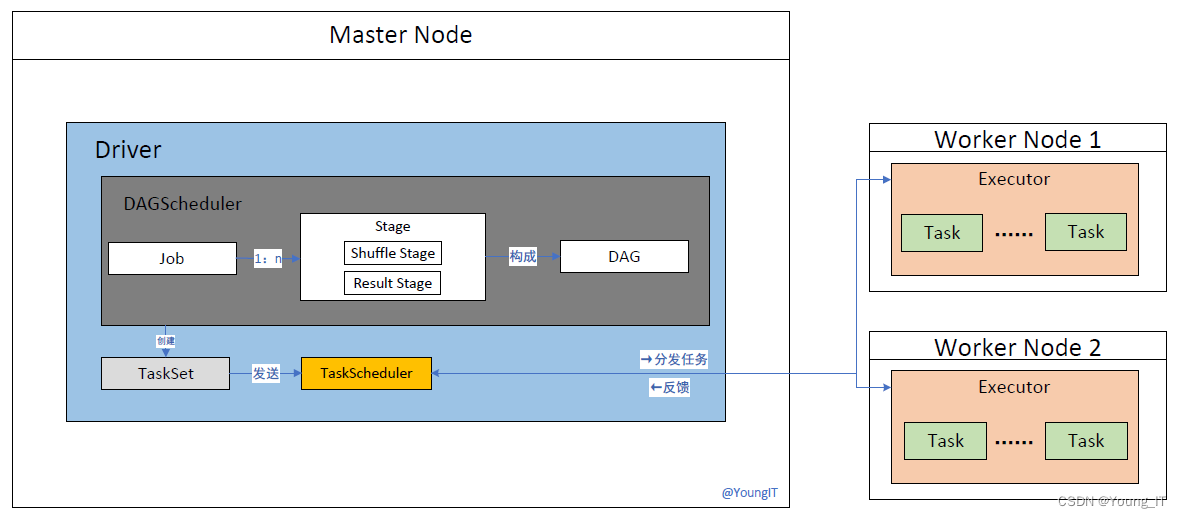
工作流程:
- Driver 创建 SparkSession 并将应用程序转化为执行计划,将作业划分为多个 Stage,并创建相应的 TaskSet。
- Driver 将 TaskSet 发送给 TaskScheduler 进行调度和执行。
- TaskScheduler 根据资源情况将任务分发给可用的 Executor 进程执行。
- Executor 加载数据并执行任务的操作,将计算结果保存在内存中。
- Executor 将任务的执行结果返回给 Driver。
- DAGScheduler 监控任务的执行状态和依赖关系,并根据需要调整任务的执行顺序和依赖关系。
- TaskScheduler 监控任务的执行状态和资源分配情况,负责任务的调度和重新执行。
在 Spark 中,有多个概念和组件相互协作,以实现分布式数据处理。下面是这些概念和组件的详细说明及它们之间的工作关系:
- Driver(驱动器):
- Driver 是 Spark 应用程序的主要组件,负责整个应用程序的执行和协调。
- 它包含了应用程序的主函数,并将用户程序转化为执行计划。
- Driver 与集群管理器通信,请求资源,并监控应用程序的执行状态。
- 它还与 Executor 进程进行通信,发送任务并接收任务执行结果。
- Executor(执行器):
- E
本文转载自: https://blog.csdn.net/2401_84166878/article/details/137489752
版权归原作者 2401_84166878 所有, 如有侵权,请联系我们删除。
版权归原作者 2401_84166878 所有, 如有侵权,请联系我们删除。