
基于Ubuntu的Hadoop伪分布式配置
Hadoop 下载
推荐去我的网盘下载或者找国内镜像资源,因为https://hadoop.apache.org/下载速度龟速。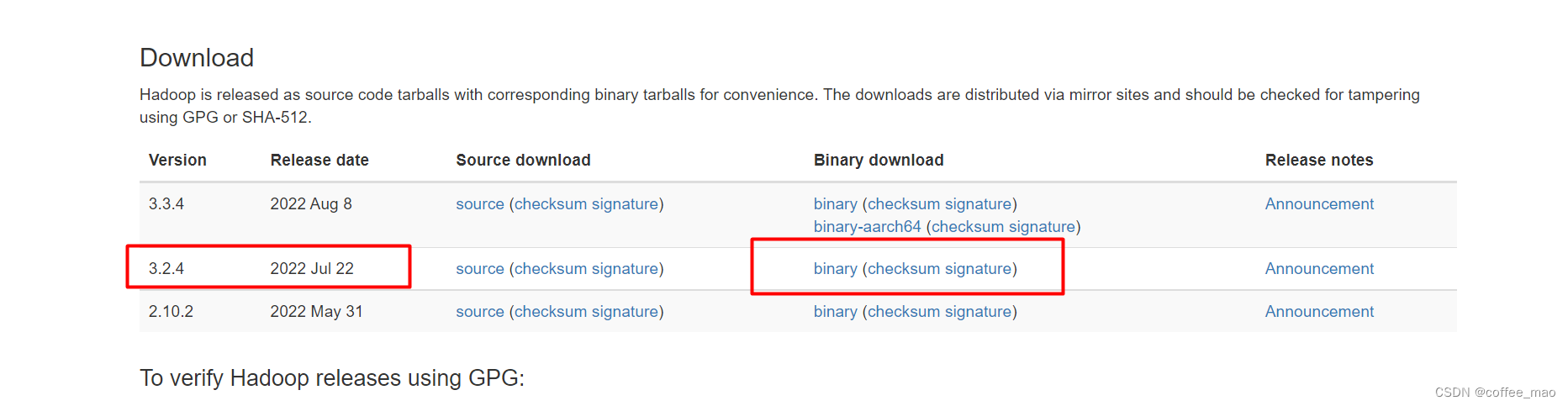
链接:https://pan.baidu.com/s/1uwqnN4rMWfGNIB-33fFZKw?pwd=1010
提取码:1010
Hadoop 安装
需要具有
Ubuntu
环境
sudouseradd -m hadoop -s /bin/bash
sudopasswd hadoop
# 对 hadoop用户添加管理员权限sudo adduser hadoop sudosudoapt-get update
# ssh 安装和登录sudoapt-getinstall openssh-server
ssh localhost
# 配置无密码登录exitcd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
sudoapt-get update
sudoapt-getinstall openjdk-8-jdk
java -version
gedit ~/.bashrc
exportJAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
source ~/.bashrc
echo$JAVA_HOME
java -version
whereis java
# 安装 hadoopsudotar -zxf ~/下载/hadoop-3.2.4.tar.gz -C /usr/local
cd /usr/local/
sudomv ./hadoop-3.2.4/ ./hadoop
sudochown -R hadoop ./hadoop
cd /usr/local/hadoop
# 检查 hadoop是否是可用的
./bin/hadoop version
mkdir ./input
cp ./etc/hadoop/*.xml ./input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'cat ./output/*
# hadoop 默认不会覆盖结果文件,因此再次运行上面实类时,会报错,需要要将 ./output 删除rm -r ./output
# hadoop 伪分布式配置cd /usr/local/hadoop
gedit ./etc/hadoop/core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
gedit ./etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>cd /usr/local/hadoop
./bin/hdfs namenode -format
# 开启 NameNode和 DataNode守护进程
./sbin/start-dfs.sh
# 判断是否成功启动
jps
火狐浏览器访问
localhost:9870

win10上访问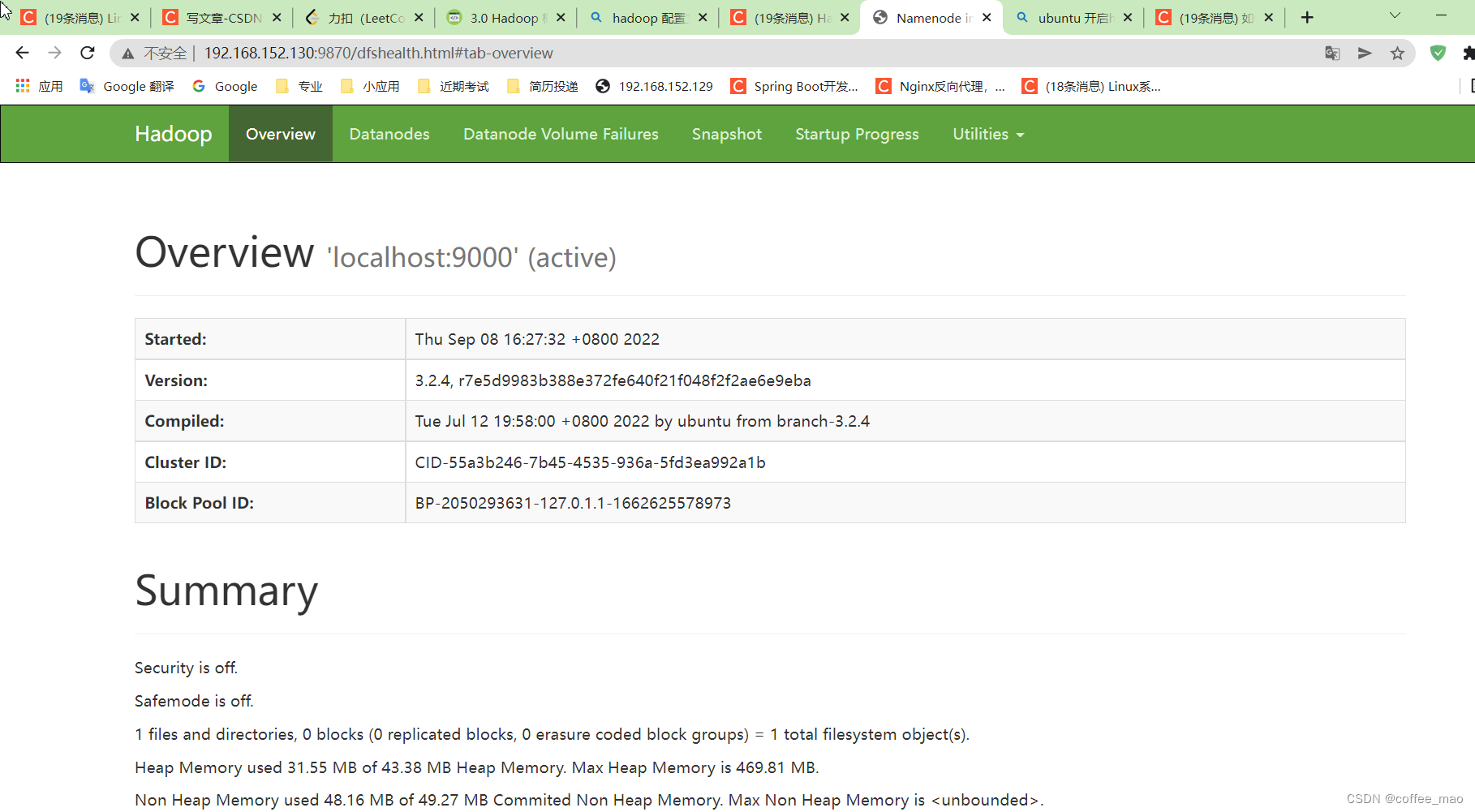
./bin/hdfs dfs -mkdir -p /user/hadoop
./bin/hdfs dfs -mkdir input
# 复制到分布式文件系统中
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
# 查看文件列表
./bin/hdfs dfs -ls input
./sbin/start-dfs.sh
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output `dfs[a-z.]+`
./bin/hdfs dfs -cat output/*
# 可能无法删除rm -f ./output
./bin/hdfs dfs -get output ./output
cat ./output/*
./bin/hdfs dfs -rm -r output
# 关闭hadoop
./sbin/stop-dfs.sh
gedit ~/.bashrc
exportPATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
source ~/.bashrc
hadoop@ubuntu:/usr/local/hadoop$ hadoop version
Hadoop 3.2.4
Source code repository Unknown -r 7e5d9983b388e372fe640f21f048f2f2ae6e9eba
Compiled by ubuntu on 2022-07-12T11:58Z
Compiled with protoc 2.5.0
From source with checksum ee031c16fe785bbb35252c749418712
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.4.jar
视频教程
https://www.bilibili.com/video/BV1eZ4y1k7LZspm_id_from=333.880.my_history.page.click
认识 Hadoop
大数据的定义
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不用于依靠硬件来提供高可用性,而是被设计用来检测和处理应用程序层的故障,因此可以在计算机集群的顶部提供高可用性服务,每台计算机都容易出现故障。
- Hadoop Common:支持其他Hadoop模块的通用实用程序。
- Hadoop分布式文件系统
HDFS:一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。 - Hadoop
YARN:用于作业调度和群集资源管理的框架。 - Hadoop
MapReduce:基于YARN的系统,用于并行处理大数据集。谷歌技术的开源实现 - Hadoop Ozone: Hadoop的对象存储。
Hadoop 历史
2003 年和 2004 年,
Google
公司先后发表了两篇著名的论文
GFS
和
MapReduce
。这两篇论文和 2006 年发表的
BigTable
成为了现在著名的"Google 三大论文"。
Doug Cutting
在受到了这些理论的影响后开始了
Hadoop
的开发。
Hadoop 包含了两大核心组件。在
Google
的论文中,
GFS
是一个在庞大的计算机集群中运行的分布式文件系统,在
Hadoop
中
HDFS
实现了它的功能。
MapReduce
是一个分布式计算的方式,
Hadoop
用同名称的
MapReduce
框架实现了它的功能。
Hadoop 的作用
Hadoop
的作用非常简单,就是在多计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供平台支持。
也就是说,
Hadoop
在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么
HDFS
就相当于这台计算机的硬盘,而
MapReduce
就是这台计算机的
CPU
控制器。
Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度
hadoop3.2.1 中文文档
Hadoop 基本命令
Hadoop
主要包含
HDFS
和
MapReduce
两大组件,
HDFS
负责分布储存数据,
MapReduce
负责对数据进行映射、规约处理,并汇总处理结果。
HDFS
Hadoop Distributed File System
,
Hadoop
分布式文件系统,简称
HDFS
。
HDFS
用于在集群中储存文件,它所使用的核心思想是
Google
的
GFS
思想,可以存储很大的文件。
在服务器集群中,文件存储往往被要求高效而稳定,
HDFS
同时实现了这两个优点。
HDFS
使用了多个块进行存储,将文件划分为多个块(
Block
)存储在物理服务器中,
HDFS
会按照设计者的需求将文件复制
n
份,将存储在不同的数据节点中,储存数据的服务器,如果一个数据节点发生故障数据也不会丢失。
HDFS
运行在不同的计算机上,有的计算机(
DataNode
)数据节点 专门进行数据的存储,有的计算机
NameNode
命名节点 专门指挥其他计算机存储数据,指挥其他计算机存储数据的计算机配备了一个秘书
Secondary NameNode
副命名节点
NameNode
指挥其他节点存储的节点,任何一个文件系统
FS
都需要将文件路径映射到文件的功能,
NameNode
就是储存这些映射信息并提供映射服务的计算机,在整个
HDFS
中扮演了管理者的角色,因此在一个
HDFS
中只允许有一个
NameNode
Secondary NameNode
别名
次命名节点
,它可以具有多个,共同为一个
NameNode
服务,不能代替
NameNode
进行工作,无论
NameNode
是否可以继续工作,她的职责就是为
NameNode
分担压力,备份
NameNode
状态以及管理一些工作,一旦
NameNode
崩掉了,次命名节点提供备份数据,以便
NameNode
复原。
DataNode
用于存储数据块的节点。当一个文件被
NameNode
承认后会被存储到分配的数据节点中去。数据节点具有存储,读写数据的功能,存储的数据块比较类似于硬盘中的"扇区"概念,是
HDFS
存储的基本单位。
MapReduce
Map
和
Reduce
(映射和规约)
通过
map
对每个大的数据分化成为小的
map
数据,方便进行处理,数据处理完成之后,
reduce
合并为最终需要的结果
Hadoop 配置
HDFS 配置和启动
Hadoop 三种模式:单机模式、伪集群模式和集群模式。
单机模式:Hadoop 仅作为库存在,可以在单计算机上执行 MapReduce 任务,仅用于开发者搭建学习和试验环境。
伪集群模式:此模式Hadoop 将以守护进程的形式在单机运行,一般用于开发者搭建学习和试验环境。
集群模式:此模式是 Hadoop的生产环境模式,也就是说这才是 Hadoop 真正使用的模式,用于提供生产级服务。
HDFS和数据库类似,是后台启动的,使用HDFS需要HDFS Client通过网络套接字连接到服务器端实现文件系统的使用。
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.4</version><scope>provided</scope></dependency>
core-site.xml
<!--配置伪分布式--><configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration><!--
指定NameNode的地址
hadoop3.x默认端口为8020
--><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!--
指定hadoop数据的存储目录
--><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.2.4/data</value></property><!--
配置HDFS网页登录使用的静态用户为coffee
--><property><name>hadoop.http.staticuser.user</name><value>coffee</value></property>
hdfs-site.xml
<!--
NameNode web端访问地址
--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!--
ScondNameNode web端访问地址
--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!--
指定HDFS副本的数量,默认3,最大副本数默认512
--><property><name>dfs.replication</name><value>3</value></property>
yarn-site.xml
<!--
指定MR走shuffle过程
--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--
指定ResourceManager的地址
--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!--
设置日志保留7天
--><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
mapred-site.xml
<!--指定MapReduce程序运行在Yarn上--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--历史服务器地址--><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value></property><!--历史服务器web地址--><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value></property>
版权归原作者 coffee_mao 所有, 如有侵权,请联系我们删除。