
一、目标整理
今天的目标是爬取小红书上指定笔记下的所有评论数据。
以某篇举例,有2千多条评论。
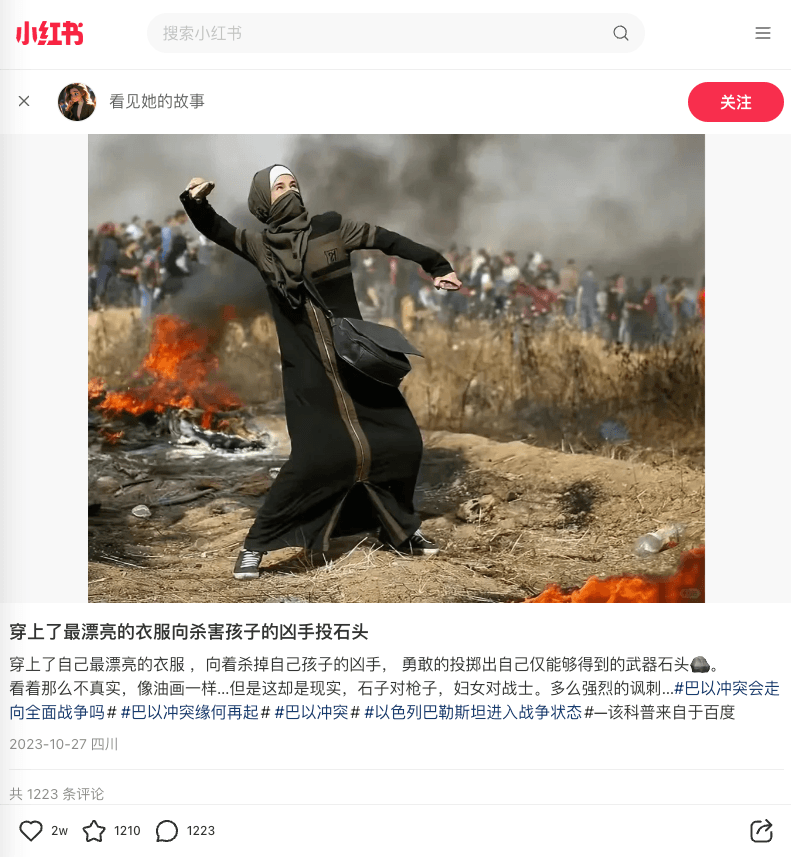
效果如下:
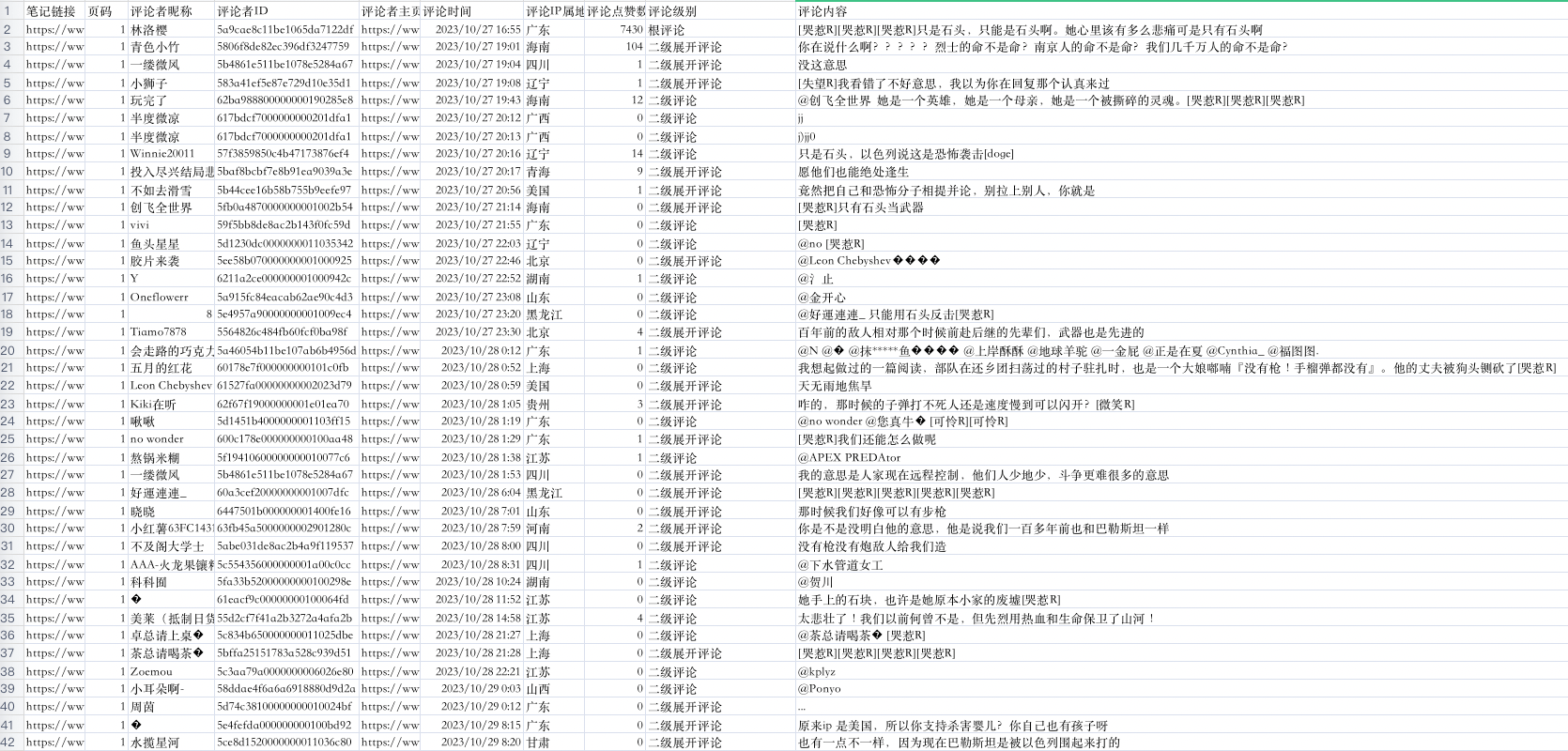
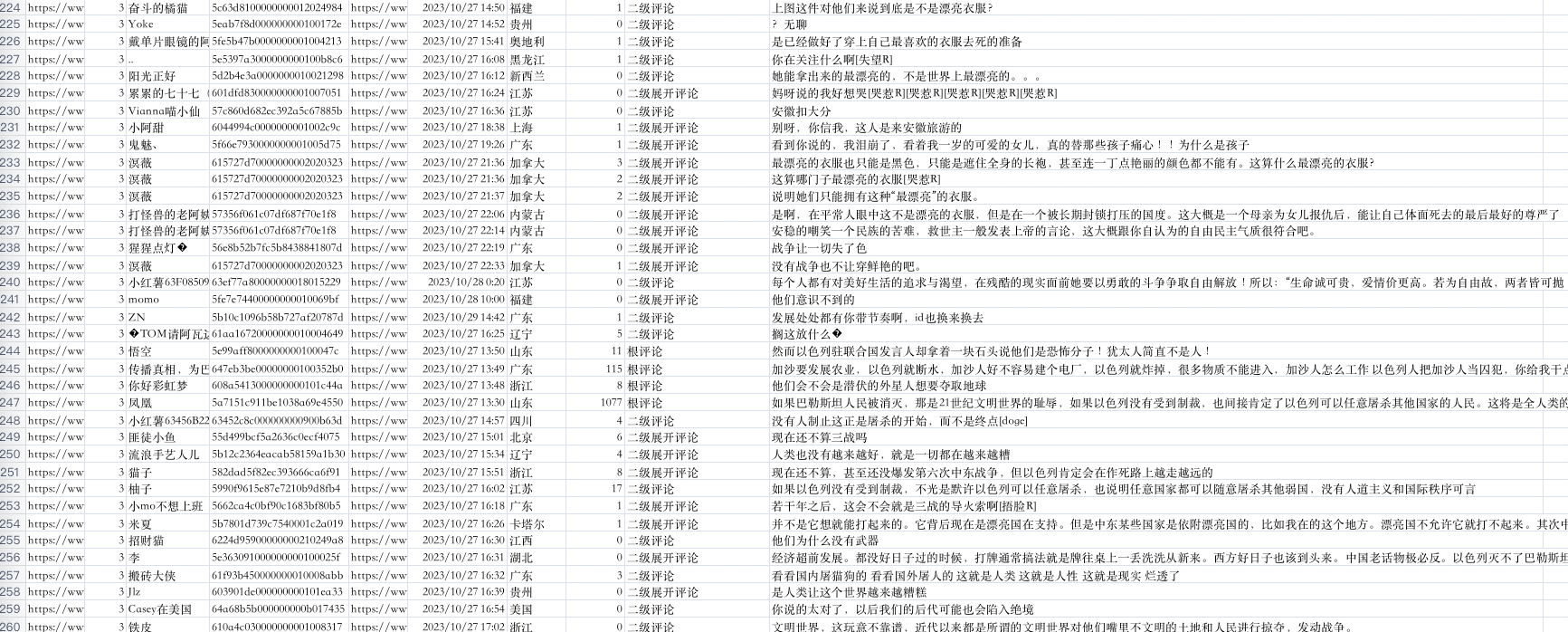
每条评论获取多个字段,
- 笔记链接
- 页码
- 评论者昵称
- 评论者ID
- 评论者主页链接
- 评论时间
- 评论IP属地
- 评论点赞数
- 评论级别
- 评论内容
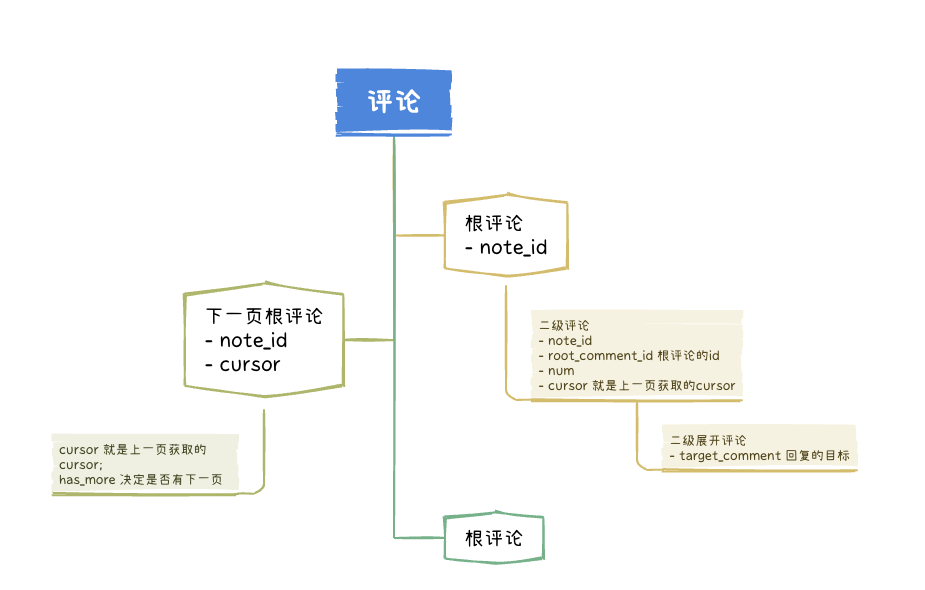
而评论包含根级评论、二级评论和二级展开评论(评论回复)。
二、逻辑分析
接口分析
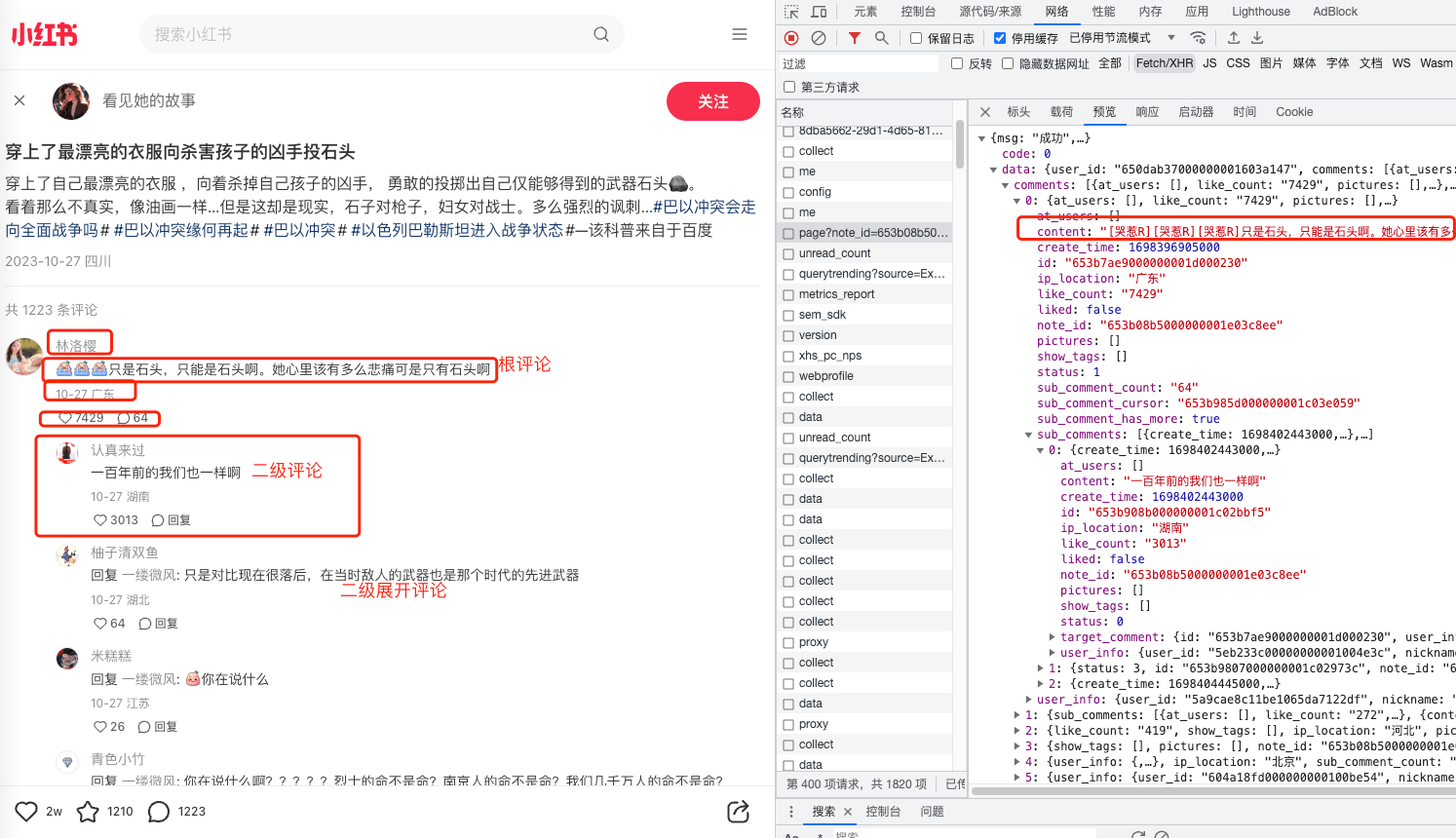
可以看到从这个接口中获取了我们想要的数据,左边是内容展示,右边是接口返回的相关字段。
请求头

# 请求头
headers ={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',# cookie需定期更换'Cookie':'xxxxxx',}
请求头这部分主要的就是UA和Cookie,其中Cookie需要定期更换,否则会出现响应数据为空的情况。
请求参数


简单说明一下这几个参数:
- note_id 这个是笔记的ID,为固定值
- cusor,获取第一页的时候可以为空,获取后面评论的时候需要使用,稍后再讲
- top_comment_id ,同样首次请求可以为空,之后才需要。
- image_scenes 固定值
响应数据分析
根评论
首次请求接口后会返回如下数据,接下来需要具体分析一下可能用到的字段。

从图中可以很清晰的猜出部分字段的功能:
- comments 以list的方式存储每条评论的数据。 - content、create_time、id、ip_location、like_count、- sub_comment_count 这是个布尔类型的字段,可以猜测一下这个字段的含义,后面还有两个字段带有sub。 - 根据
sub可以联想到subsequent,也就是随后的,后来的意思,所以很可能就是和二级评论或者二级展开评论有关。- count 的含义就是计数,也就是说当前这条评论有多少二级评论。- sub_comment_cursor- sub_comment_has_more 还有更多? - cursor 游标
- has_more 还有更多?
简单总结一下,我们获取到了首次请求的数据,而且获取了一些其他的字段,比如has_more很有可能就是可以继续翻页的意思。那么就是说如果这个字段一直为true,就可以一直翻页,省去了我们单独计算需要多少页的问题。那么如何拼接第二页的请求参数呢,接着看第二次请求。

点击加载更多后进行了第二次请求,可以看到请求参数中的
cursor
这次有了值,但是这个值
653b643a000000001c02bf62
是从哪里获取的呢?可以对照一下第一次的响应结果,看是否在里面。

很明显就是第一次响应数据中的
cursor
字段的值。所以目前为止,我们有能力获取所有的根评论了。
二级评论和二级展开评论
上一节中说到了sub相关的字段,接下来我们根据这几个字段多看几次接口请求是否能发现一些规律。所以这次我们再查看的时候肯定是要从同一个根评论去定位,而不是直接往后翻。随机找一个数量小点的评论,方便观察。

这里可以看到又有一个带有
cursor
的字段,值为
653c85510000000025009516
。根据之前的经验,很有可能是进行下一次请求的游标。接下来点击展开更多回复。
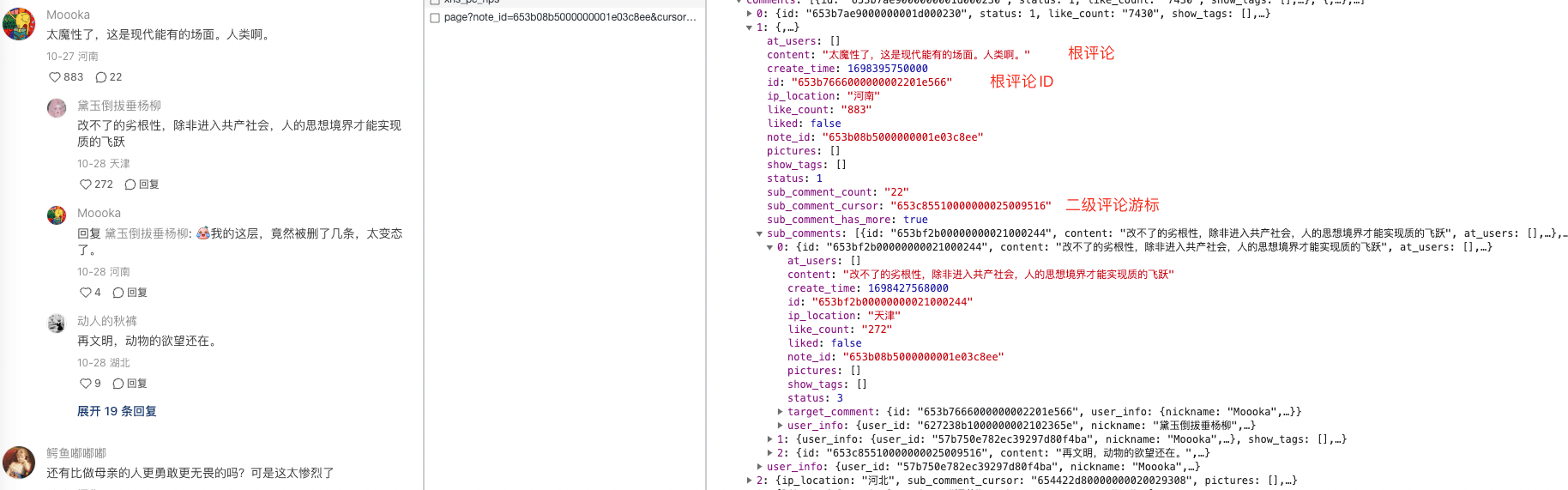
可以看到之前的cursor就是下次请求中cursor的值。

还有一个’root_comment_id’这个可以理解为根节点的ID,就是第一次请求中的根评论的ID。

至此,我们已经梳理好接口逻辑能力获取所有的评论了。
简单总结
获取所有评论的思路就像从树枝上摘叶子。
三、代码实现
分两部分,首先是根评论获取:
resp = requests.get(note_url, headers=headers, params=params)
data = resp.json()
next_cursor = data['data']['cursor']# 翻页游标,一级评论for c in data['data']['comments']:# 数据存储ifint(c['sub_comment_count'])>0:
root_comment_id = c['id']
next_cursor_id = c['sub_comment_cursor']# 获取二级评论或二级展开评论
has_more = data['data']['has_more']print(':::', next_cursor, has_more)if has_more isTrue:print(f'当前页{page},下一页{page +1}')
page +=1# 直接更新当前页
二级评论获取:
resp = requests.get(note_url, headers=headers, params=params)if resp.status_code ==200:try:
data = resp.json()for c in data['data']['comments']:# 数据存储ifnot data['data']['has_more']:# 如果has_more 为false说明没有数据了return# 结束递归else:
next_cursor = data['data']['cursor']# 进行下一次请求except Exception as e:print('二级评论', e)
至此,爬虫代码开发完毕。
四、总结
思路是借鉴大佬的,具体代码是自己摸索中实现的。开发过程中也遇到了一定的问题,但都不重要,没有太多参考价值。后来又更新了一下代码,提高了抓速度,修复了少于3条评论未获取的情况。如有需要请私信。

版权归原作者 爬虫小恐龙 所有, 如有侵权,请联系我们删除。