
(1)项目需求
现在有一份来自美国国家海洋和大气管理局的数据集,里面包含近30年每个气象站、每小时的天气预报数据,每个报告的文件大小大约15M。一共有263个气象站,每个报告文件的名字包含气象站ID,每条记录包含气温、风向、天气状况等多个字段信息。现在要求统计美国各气象站30年平均气温。
(2)数据格式
天气预报每行数据的每个字段都是定长的,完整数据格式如下。

数据格式由Year(年)、Month(月)、Day(日)、Hour(时)、Temperature(气温)、Dew(湿度)、Pressure(气压)、Wind dir.(风向)、Wind speed(风速)、Sky Cond.(天气状况)、Rain 1h(每小时降雨量)、Rain 6h(每6小时降雨量)组成。
(3)实现思路****
我们的目标是统计近30年每个气象站的平均气温,由此可以设计一个MapReduce如下所示:
Map = {key = weather station id, value = temperature}
Reduce = {key = weather station id, value = mean(temperature)}
首先调用mapper的map()函数提取气象站id作为key,提取气温值作为value,然后调用reducer的reduce()函数对相同气象站的所有气温求平均值。
(4)项目开发****
打开IDEA的bigdata项目,开发MapReduce分布式应用程序,统计美国各气象站近30年的平均气温。
(1)引入Hadoop依赖
由于开发MapReduce程序需要依赖Hadoop客户端,所以需要在项目的pom.xml文件中引入Hadoop的相关依赖,添加如下内容:
<dependency>
<groupId>org.apache.hadoop</groupId
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
(2)实现Mapper
由于天气预报每行数据的每个字段都是固定的,所以可以使用substring(start,end)函数提取气温值。因为气象站每个报告文件的名字都包含气象站ID,首先可以使用FileSplit类获取文件名称,再使用substring(start,end)函数截取气象站ID。
在Reducer中,重写reducer()函数,首先对所有气温值累加求和,最后计算出每个气象站的平均气温值。
完整代码如下:
package com.itheima;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WeatherAnalysis {
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
int temperature = Integer.parseInt(line.substring(14, 19).trim());
if (temperature != -9999) {
FileSplit failsplit = (FileSplit) context.getInputSplit();
String id = failsplit.getPath().getName().substring(5, 10);
//输出气象站id
context.write(new Text(id), new IntWritable(temperature));
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable sean = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
for (IntWritable val : values) {
sum += val.get();
count++;
}
//求平均值气温
sean.set(sum / count);
context.write(key, sean);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
org.apache.hadoop.conf.Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WeatherAnalysis");
job.setJarByClass(WeatherAnalysis.class);
//输入输出路径
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//输入输出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//设置mapper及map输出的key value类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer及reduce输出key value类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
③项目编译打包
在IDEA工具的Terminal控制台中,输入mvn clean package命令对项目进行打包
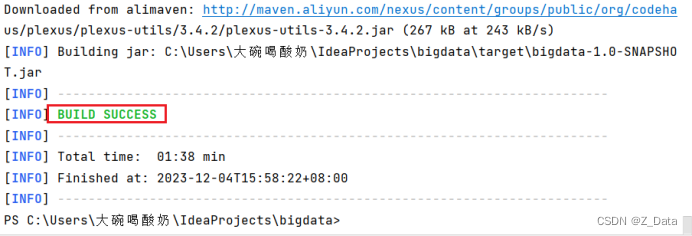
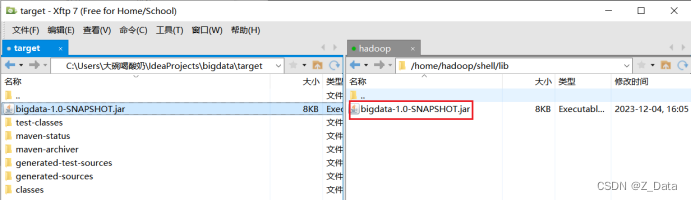
打包成功后,在项目的targer目录下找到编译好的bigdata-1.0-SNAPSHOT.jar包,然后将其上传至/home/hadoop/shell/lib目录下(没有相关目录可手动创建)
④准备数据源
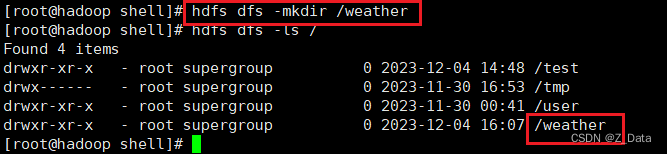
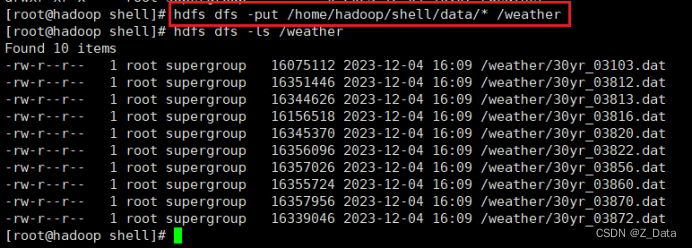
由于气象站比较多,为了方便测试,这里只将10个气象站的天气报告文件上传至HDFS的/weather目录下。(没有需要手动创建该目录)
HDFS上创建/weather目录
hdfs dfs -mkdir /weather
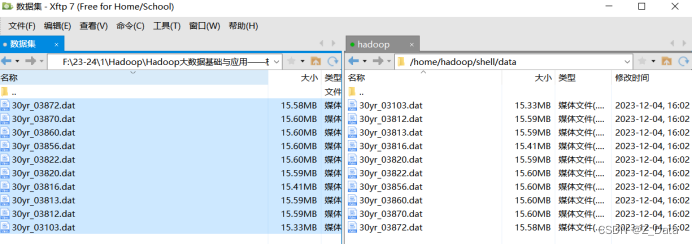
先将数据源上传至本地虚拟机目录/home/hadoop/shell/data(该目录需要手动创建)
再将本地数据源上传至HDFS的/weather目录
hdfs dfs -put /home/hadoop/shell/data/* /weather
⑤编写shell脚本
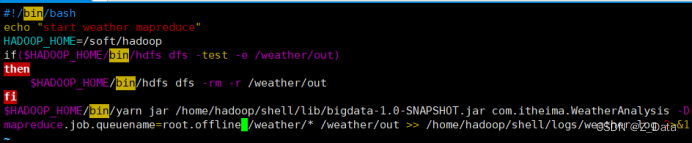
为了便于提交MapReduce作业,在/home/hadoop/shell/bin目录下编写weatherMR.sh脚本,封装作业提交命令,具体脚本内容如下:
#!/bin/bash
echo "start weather mapreduce"
HADOOP_HOME=/soft/hadoop
if($HADOOP_HOME/bin/hdfs dfs -test -e /weather/out)
then
$HADOOP_HOME/bin/hdfs dfs -rm -r /weather/out
fi
$HADOOP_HOME/bin/yarn jar /home/hadoop/shell/lib/bigdata-1.0-SNAPSHOT.jar com.itheima.WeatherAnalysis -Dmapreduce.job.queuename=root.offline /weather/* /weather/out >> /home/hadoop/shell/logs/weather.log 2>&1
⑥为weatherMR.sh 脚本添加可执行权限:
chmod u+x weatherMR.sh

⑦提交MapReduce作业
到该脚本目录下,执行weatherMR.sh脚本提交MapReduce作业
./weatherMR.sh

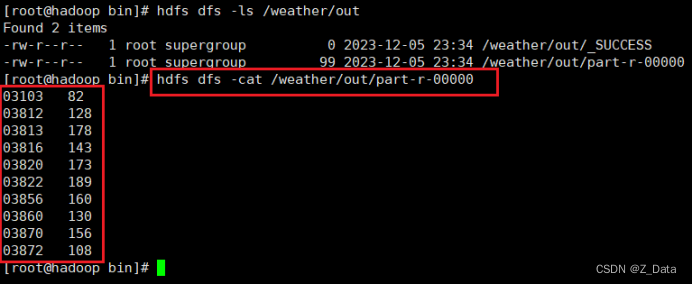
⑧查看运行结果
使用HDFS命令查看美国各气象站近30年的平均气温:
hdfs dfs -cat /weather/out/part-r-00000
版权归原作者 Z_Data 所有, 如有侵权,请联系我们删除。