
之前的文章中学习了在集群环境下编写我们的spark已经在IDEA中打jar包。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(17)-CSDN博客文章浏览阅读2.3k次,点赞46次,收藏39次。这篇文章起我会带来两种方式将我们开发环境(IDEA)的代码文件打jar包到我们的集群环境下运行。今天的文章首先来讲我们的本地模式。今天的文章,我会带着大家一起来到Linux集群环境下,学习我们的spark。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137929033?spm=1001.2014.3001.5501这篇文章我会带着大家学习Spark SQL中的DataFrame中show(),selectExpr(),select(),filter()/where,groupBy(),sort()6种方法。了解Spark SQL以及DataFrame。
一、结构化数据
Spark SQL
什么是Spark SQL
- Spark SQL 是一个用于处理结构化数据的 Spark 模块。它允许你使用 SQL 语句来查询 DataFrame。
- Spark SQL 提供了 DataFrame 和 DataSet 的 API,这些 API 允许你以编程方式执行 SQL 查询。此外,它还提供了一个 SQL 引擎,允许你直接在 Spark 集群上执行 SQL 语句。
- Spark SQL 支持多种数据源,包括 Hive、JSON、Parquet、CSV 等。它还支持多种外部数据库和存储系统,如 JDBC、ODBC 和 Apache Arrow。
- Spark SQL 的主要目标是使数据处理更加简单、直观和高效。通过使用 SQL 和 DataFrame API,你可以轻松地执行复杂的数据转换和查询操作,而无需编写大量的底层代码。
Spark SQL架构
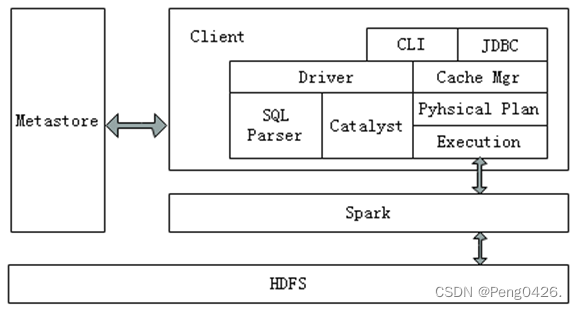
spark sql架构图
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
DataFrame
什么是DataFrame
- DataFrame 是一个分布式数据集,它有一个不可变的、不可空的 schema(即列和类型)。这意味着 DataFrame 知道它的每一列都包含什么类型的数据。
- DataFrame 可以从各种来源创建,如结构化文件(如 Parquet、JSON)、Hive 表、外部数据库或现有的 RDD(通过执行转换操作)。
- DataFrame API 提供了丰富的函数来操作数据,包括选择、过滤、分组、排序等。这些操作通常使用 DataFrame 的 DSL(领域特定语言)风格的方法来实现,这使得代码更加简洁和易于理解。
- DataFrame 底层由 RDD 支持,但 RDD 是低级的、不可读的,并且没有 schema。相比之下,DataFrame 提供了更高级别的抽象,使得处理结构化数据更加容易。
二、DataFrame方法
1.show()
show()方法用来查看我们DataFrame数据,show方法默认只显示我们数据中前20条记录,且最多显示20个字符
方法参数说明
show()
显示 DataFrame 的前 20 行数据(默认)。
show(n)
显示 DataFrame 的前
n
行数据。其中
n
是一个整数,表示要显示的行数。
show(truncate=False)
显示 DataFrame 的所有列,不对列的内容进行截断。默认情况下,如果列的内容过长,Spark 会截断它以适应控制台输出。将此参数设置为
False
可以避免截断。
show(n, truncate=False)
同时设置显示行数和是否截断列的内容。这将显示前
n
行数据,并且不对列的内容进行截断。
**示例代码,显示内容: **
import org.apache.spark.sql.SparkSession
object DataFrameExample {
def main(args: Array[String]): Unit = {
// 创建一个SparkSession
val spark = SparkSession.builder()
.appName("Peng")
.master("local[*]") // 使用所有可用的本地线程
.getOrCreate()
import spark.implicits._
// 创建一个简单的Seq来作为数据源
val data = Seq(("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3),("Alice", 1), ("Bob", 2), ("Charlie", 3))
// 将Seq转换为DataFrame
case class Person(name: String, age: Int)
val p = data.toDF("name", "age") // 或者使用data.map(Person.tupled).toDF()
// 显示DataFrame的内容
p.show()
}
}
可以看到我们的数据集超过了20条,那么使用我们的show()方法不添加参数肯定也只会输出20条。

2.selectExpr()
selectExpr()
方法在 Apache Spark 的 DataFrame API 中用于选择列,并且可以支持 SQL 表达式,这样我们就可以对字段进行特殊处理。
参数说明
exprs: String*
一个或多个 SQL 表达式字符串,用于选择或计算 DataFrame 中的列。
**示例代码,使用
selectExpr()
方法将年龄+1:**
import org.apache.spark.sql.SparkSession
object p1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PENG")
.master("local[*]")
.getOrCreate()
import spark.implicits._ // 导入隐式转换和DSL
// 创建一个简单的Seq来作为数据源
val data = Seq(("Alice", 28), ("Bob", 22), ("Charlie", 30), ("David", 25))
// 将Seq转换为DataFrame
val peopleDF = data.toDF("name", "age")
// 使用selectExpr()方法选择列并进行一些计算
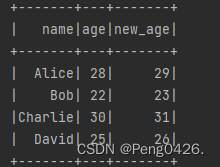
val selectedDF = peopleDF.selectExpr(
"name", // 选择name列
"age", // 选择age列
"(age + 1) as new_age" // 使用SQL表达式计算新的列new_age
)
// 显示选择后的DataFrame的内容
selectedDF.show()
}
}
3.select()
select()
方法在 Apache Spark 的 DataFrame API 中用于选择 DataFrame 中的列,获取相对应的值。
参数说明
cols: Column*
一个或多个 Column 表达式,用于指定要选择的列。这些可以是列名、Column 对象或 Column 表达式。
**示例代码,对列重命名: **
import org.apache.spark.sql.SparkSession
object DataFrameSelectExample {
def main(args: Array[String]): Unit = {
// 创建一个SparkSession
val spark = SparkSession.builder()
.appName("Peng")
.master("local[*]") // 使用所有可用的本地线程
.getOrCreate()
import spark.implicits._ // 导入隐式转换和DSL
// 创建一个简单的Seq来作为数据源
val data = Seq(("Alice", 28), ("Bob", 22), ("Charlie", 30), ("David", 25))
// 将Seq转换为DataFrame
val peopleDF = data.toDF("name", "age")
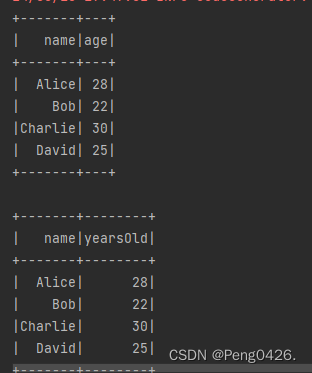
// 使用select()方法选择列
val selectedDF = peopleDF.select($"name", $"age")
// 显示选择后的DataFrame的内容
selectedDF.show()
// 对列进行重命名,直接使用$"columnName".as("newName")
val renamedDF = peopleDF.select($"name", $"age".as("yearsOld"))
// 显示重命名后的DataFrame的内容
renamedDF.show()
}
}
4.filter()/where
使用filter或where方法可以查询数据中符合条件的所有字段信息。
方法参数类型说明示例
filter()
conditionExpr: Column
Column
使用Column表达式来过滤DataFrame的行。这可以是一个Column对象、SQL表达式字符串或Scala中的Column API表达式。
df.filter($"column1" === 1).show()
where()
conditionExpr: String
String
使用SQL表达式字符串来过滤DataFrame的行。
df.where("column1 = 1").show()
示例代码,实现过滤年龄大小:
import org.apache.spark.sql.SparkSession
object p1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PENG")
.master("local[*]")
.getOrCreate()
import spark.implicits._ // 导入隐式转换和DSL
// 创建一个简单的Seq来作为数据源
val data = Seq(("Alice", 28), ("Bob", 22), ("Charlie", 30), ("David", 25))
// 将Seq转换为DataFrame
val peopleDF = data.toDF("name", "age")
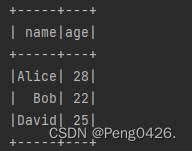
// 使用filter()方法过滤年龄大于25的人
val filteredDF1 = peopleDF.filter($"age" > 25)
// 使用where()方法过滤年龄小于30的人
val filteredDF2 = peopleDF.where($"age" < 30)
filteredDF1.show()
filteredDF2.show()
}
}
5.groupBy()
groupBy()
方法接受一个或多个列名、列表达式或列引用作为参数,并返回一个分组后的对象(在 Spark SQL 中是
RelationalGroupedDataset
),该对象表示按指定列或表达式分组的数据。
属性/参数类型说明示例分组列列名、表达式、列表等指定要按照哪些列或表达式对数据进行分组
df.groupBy("columnName")
或
df.groupBy($"columnName")
聚合函数聚合函数在每个分组上应用的聚合函数,如
count()
,
sum()
,
avg()
,
max()
,
min()
等
df.groupBy("columnName").count().show()
返回值RelationalGroupedDataset返回一个RelationalGroupedDataset对象,该对象可以进一步调用聚合函数
val grouped = df.groupBy("columnName")
- 返回值RelationalGroupedDataset
方法返回一个RelationalGroupedDataset对象,而不是一个普通的DataFrame。该对象允许你进一步调用聚合函数。-2. 排序-在使用groupBy()
方法之前,通常不需要对数据进行排序,因为Spark会根据分组列的值自动进行排序。但如果你需要按照特定的顺序输出结果,可以在调用groupBy()
之后使用groupBy()
方法。orderBy()grouped.orderBy("columnName").show() - 分组键-分组后的结果中,分组键会成为结果DataFrame的索引(在Spark SQL中)。如果你不希望这样,可以使用
方法删除索引列。drop()grouped.drop("columnName").show() - 多列分组-你可以通过传递一个包含多个列名的列表或元组来按多列进行分组。
df.groupBy("columnName1", "columnName2").count().show() - 聚合多个指标-你可以在一个
调用中聚合多个指标。这可以通过使用groupBy()
方法并传递一个包含多个聚合函数的列表来实现。agg()df.groupBy("columnName").agg(sum("columnValue"), avg("columnValue")).show()
**下面是使用groupBy实现简单分组的示例代码: **
import org.apache.spark.sql.SparkSession
object p1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PENG")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// 创建一个简单的 DataFrame
val data = Seq(("A", 1), ("B", 2), ("A", 3), ("B", 1), ("C", 2))
val df = data.toDF("category", "value")
// 使用 groupBy 对 category 列进行分组,并计算每个分组中的行数
val p = df.groupBy("category").count()
p.show()
}
}

6.sort()
sort()
方法通常用于对数据进行排序。
属性/参数类型说明示例colstr 或 Column 或 list of str/Column要按其进行排序的列名、Column 对象或列名/Column 对象的列表。
df.sort("columnName")
或
df.sort(df("columnName").desc)
或
df.sort(col("columnName1"), col("columnName2").desc)
ascendingbool 或 list of bool是否按升序排序,默认为 True。如果提供了多个列,则可以传递一个布尔值列表来指定每个列的排序顺序。
df.sort("columnName", ascending=False)
globalbool在分布式环境中,是否进行全局排序。请注意,全局排序可能非常昂贵,并且可能不适用于大数据集。默认为 False(即分区内排序)。通常不直接设置此参数,而是通过其他方式(如
repartition
)来控制排序的范围。
以下是对年龄排序的示例代码:
import org.apache.spark.sql.SparkSession
object p1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("PENG")
.master("local[*]")
.getOrCreate()
import spark.implicits._ // 导入隐式转换和DSL
// 创建一个简单的Seq来作为数据源
val data = Seq(("Alice", 28), ("Bob", 22), ("Charlie", 30), ("David", 25))
// 将Seq转换为DataFrame
val peopleDF = data.toDF("name", "age")
// 对DataFrame按年龄进行排序
val sortedDF = peopleDF.sort("age") // 默认为升序
// 显示排序后的DataFrame的内容
sortedDF.show()
// 如果你想要降序排序,可以添加一个降序参数
val sortedDescDF = peopleDF.sort($"age".desc)
// 显示降序排序后的DataFrame的内容
sortedDescDF.show()
}
}
版权归原作者 Peng0426. 所有, 如有侵权,请联系我们删除。