
本博客总结为B站尚硅谷大数据Flink2.0调优,Flink性能优化视频中常见故障排除的的笔记总结。
1. 非法配置异常
如果看到从 TaskExecutorProcessUtils 或 JobManagerProcessUtils 抛出的 IllegalConfigurationException,通常表明存在无效的配置值(例如负内存大小、大于 1 的分数等)或配置冲突。请重新配置内存参数。
2. Java 堆空间异常
如果报 OutOfMemoryError: Java heap space 异常,通常表示 JVM Heap 太小。可以通过增加总内存来增加 JVM 堆大小。也可以直接为 TaskManager 增加任务堆内存或为 JobManager 增加 JVM 堆内存。
还可以为 TaskManagers 增加框架堆内存,但只有在确定 Flink 框架本身需要更多内存时才应该更改此选项。
3. 直接缓冲存储器异常
如果报 OutOfMemoryError: Direct buffer memory 异常,通常表示 JVM 直接内存限制太小或存在直接内存泄漏。检查用户代码或其他外部依赖项是否使用了 JVM 直接内存,以及它是否被正确考虑。可以尝试通过调整直接堆外内存来增加其限制。可以参考如何为 TaskManagers、 JobManagers 和 Flink 设置的 JVM 参数配置堆外内存。
4. 元空间异常
如果报 OutOfMemoryError: Metaspace 异常,通常表示 JVM 元空间限制配置得太小。可以尝试加大 JVM 元空间 TaskManagers 或 JobManagers 选项。
5. 网络缓冲区数量不足
如果报 IOException: Insufficient number of network buffers 异常,这仅与 TaskManager 相关。通常表示配置的网络内存大小不够大。可以尝试增加网络内存。
6. 超出容器内存异常
如果 Flink 容器尝试分配超出其请求大小(Yarn 或 Kubernetes)的内存,这通常表明 Flink 没有预留足够的本机内存。当容器被部署环境杀死时,可以通过使用外部监控系统或从错误消息中观察到这一点。
如果在 JobManager 进程中遇到这个问题,还可以通过设置排除可能的 JVM DirectMemory 泄漏的选项来开启 JVM Direct Memory 的限制:
jobmanager.memory.enable-jvm-direct-memory-limit:true
如果想手动多分一部分内存给 RocksDB 来防止超用,预防在云原生的环境因 OOM 被 K8S kill,可将 JVM OverHead 内存调大。
之所以不调大 Task Off-Heap,是由于目前 Task Off-Heap 是和 Direct Memeory 混在一起的,即使调大整体,也并不一定会分给 RocksDB 来做 Buffer,所以我们推荐通过调整 JVM OverHead 来解决内存超用的问题。
7. Checkpoint 失败
Checkpoint 失败大致分为两种情况:Checkpoint Decline 和 Checkpoint Expire。
7.1. Checkpoint Decline
我们能从 jobmanager.log 中看到类似下面的日志:
ecline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
我们可以在 jobmanager.log 中查找 execution id,找到被调度到哪个 taskmanager 上,类似如下所示:
2019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph (100/289) (87b751b1fd90e32af55f02bb2f9a9892) switched DEPLOYING. - XXXXXXXXXXX from SCHEDULED to
2019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph - DeployingXXXXXXXXXXX (100/289) (attempt #0) to slotcontainer_e24_1566836790522_8088_04_013155_1 on hostnameABCDE
从上面的日志我们知道该 execution 被调度到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot 上,接下来我们就可以到 container_e24_1566836790522_8088_04_013155 的 taskmanager.log 中查找 Checkpoint 失败的具体原因了。
另外对于 Checkpoint Decline 的情况,有一种情况在这里单独抽取出来进行介绍: Checkpoint Cancel。
当前 Flink 中如果较小的 Checkpoint 还没有对齐的情况下,收到了更大的 Checkpoint,则会把较小的 Checkpoint 给取消掉。我们可以看到类似下面的日志:
\$taskNameWithSubTaskAndID: Received checkpoint barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
这个日志表示,当前 Checkpoint 19 还在对齐阶段,我们收到了 Checkpoint 20 的 barrier。然后会逐级通知到下游的 task checkpoint 19 被取消了,同时也会通知 JM 当前 Checkpoint 被 decline 掉了。
在下游 task 收到被 cancelBarrier 的时候,会打印类似如下的日志:
DEBUG $taskNameWithSubTaskAndID: Checkpoint 19 canceled, aborting alignment.
或者
DEBUG $taskNameWithSubTaskAndID: Checkpoint 19 canceled, skipping alignment.
或者
WARN $taskNameWithSubTaskAndID: Received cancellation barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
上面三种日志都表示当前 task 接收到上游发送过来的 barrierCancel 消息,从而取消了对应的 Checkpoint。
7.2. Checkpoint Expire
如果 Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。当一个 Checkpoint 由于超时而失败时,会在 jobmanager.log 中看到如下的日志:
Checkpoint 1 of job 85d268e6fbc19411185f7e4868a44178 expired before completing.
表示 Chekpoint 1 由于超时而失败,这个时候可以可以看这个日志后面是否有类似下面的日志:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
可以按照 7.1 中的方法找到对应的 taskmanager.log 查看具体信息。
我们按照下面的日志把 TM 端的 snapshot 分为三个阶段:开始做 snapshot 前,同步阶段,异步阶段,需要开启 DEBUG 才能看到:
DEBUG Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
上面的日志表示 TM 端 barrier 对齐后,准备开始做 Checkpoint。
2019-08-06 13:43:02,613 DEBU Gorg.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@70442baf,checkpointDirectory=xxxxxxxx, taskOwnedStateDirectory=xxxxxx, sharedStateDirectory=xxxxxxxx,
metadataFilePath=xxxxxx, reference=(default),fileStateSizeThreshold=1024}, synchronous part) in thread Thread[Async calls on Source: xxxxxx_source - > Filter (27/70),5,Flink Task Threads] took 0 ms.
上面的日志表示当前这个 backend 的同步阶段完成,共使用了 0 ms。
DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation{fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@7908affe,heckpointDirectory=xxxxxx,
taskOwnedStateDirectory=xxxxx, sharedStateDirectory=xxxxx, metadataFilePath=xxxxxx, reference=(default),fileStateSizeThreshold=1024}, asynchronous part) in thread Thread [pool-48-thread-14,5,Flink Task Threads] took 369 ms
上面的日志表示异步阶段完成,异步阶段使用了 369 ms
在现有的日志情况下,我们通过上面三个日志,定位 snapshot 是开始晚,同步阶段做的慢,还是异步阶段做的慢。然后再按照情况继续进一步排查问题。
8. Checkpoint 慢
Checkpoint 慢的情况如下:比如 Checkpoint interval 1 分钟,超时 10 分钟,Checkpoint 经常需要做 9 分钟(我们希望 1 分钟左右就能够做完),而且我们预期 state size 不是非常大。
对于 Checkpoint 慢的情况,我们可以按照下面的顺序逐一检查。
- Source Trigger Checkpoint 慢 这个一般发生较少,但是也有可能,因为 source 做 snapshot 并往下游发送 barrier 的时候,需要抢锁(Flink1.10 开始,用 mailBox 的方式替代当前抢锁的方式,详情参考(https://issues.apache.org/jira/browse/FLINK-12477)。如果一直抢不到锁的话,则可能导致 Checkpoint 一直得不到机会进行。如果在 Source 所在的 taskmanager.log 中找不到开始做 Checkpoint 的 log,则可以考虑是否属于这种情况,可以通过 jstack 进行进一步确认锁的持有情况。
- 使用增量 Checkpoint 现在 Flink 中 Checkpoint 有两种模式,全量 Checkpoint 和 增量 Checkpoint , 其中全量 Checkpoint 会把当前的 state 全部备份一次到持久化存储,而增量 Checkpoint,则只备份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上传的内容会相对更少,在速度上会有更大的优势。 现在 Flink 中仅在 RocksDBStateBackend 中支持增量 Checkpoint,如果已经使用 RocksDBStateBackend,可以通过开启增量 Checkpoint 来加速。
- 作业存在反压或者数据倾斜 task 仅在接受到所有的 barrier 之后才会进行 snapshot,如果作业存在反压,或者有数据倾斜,则会导致全部的 channel 或者某些 channel 的 barrier 发送慢,从而整体影响 Checkpoint 的时间。
- Barrier 对齐慢 从前面我们知道 Checkpoint 在 task 端分为 barrier 对齐(收齐所有上游发送过来的 barrier),然后开始同步阶段,再做异步阶段。如果 barrier 一直对不齐的话,就不会开始做 snapshot。 barrier 对齐之后会有如下日志打印:
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)如果 taskmanager.log 中没有这个日志,则表示 barrier 一直没有对齐,接下来我们需要了解哪些上游的 barrier 没有发送下来, 如果你使用 At Least Once 的话,可以观察到下面的日志:Received barrier for checkpoint 96508 from channel 5表示该 task 收到了 channel 5 来的 barrier,然后看对应 Checkpoint,再查看还剩哪些上游的 barrier 没有接受到。 - 主线程太忙,导致没机会做 snapshot 在 task 端,所有的处理都是单线程的,数据处理和 barrier 处理都由主线程处理,如果主线程在处理太慢(比如使用 RocksDBBackend ,state 操作慢导致整体处理慢),导致 barrier 处理的慢,也会影响整体 Checkpoint 的进度,可以通过火焰图分析。
- 同步阶段做的慢 同步阶段一般不会太慢,但是如果我们通过日志发现同步阶段比较慢的话,对于非 RocksDBBackend 我们可以考虑查看是否开启了异步 snapshot ,如果开启了异步 snapshot,还是慢,需要看整个 JVM 在干嘛,也可以使用火焰图分析。对于 RocksDBBackend 来说,我们可以用 iostate 查看磁盘的压力如何,另外可以查看 tm 端 RocksDB 的 log 的日志如何,查看其中 SNAPSHOT 的时间总共开销多少。 RocksDB 开始 snapshot 的日志如下:
2019/09/10-14:22:55.734684 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:83] Started the snapshot process -- creating snapshot in directory /tmp/flink-io-87c360ce-0b98-48f4-9629-2cf0528d5d53/XXXXXXXXXXX/chk-92729snapshot 结束的日志如下:2019/09/10-14:22:56.001275 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:145] Snapshot DONE. All is good - 异步阶段做的慢 对于异步阶段来说,tm 端主要将 state 备份到持久化存储上,对于非 RocksDBBackend 来说,主要瓶颈来自于网络,这个阶段可以考虑观察网络的 metric,或者对应机器上能够观察到网络流量的情况(比如 iftop)。 对于 RocksDB 来说,则需要从本地读取文件,写入到远程的持久化存储上,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。另外对于 RocksDBBackend 来说,如果觉得网络流量不是瓶颈,但是上传比较慢的话,还可以尝试考虑开启多线程上传功能(Flink 1.13 开始,state.backend.rocksdb.checkpoint.transfer.thread.num 默认值是 4) 。
9. Kafka 动态发现分区
当 FlinkKafkaConsumer 初始化时,每个 subtask 会订阅一批 partition,但是在 Flink 任务运行过程中,如果被订阅的 topic 创建了新的 partition,FlinkKafkaConsumer 如何实现动态发现新创建的 partition 并消费呢?
在使用 FlinkKafkaConsumer 时,可以开启 partition 的动态发现。通过 Properties 指定参数开启(单位是毫秒):
FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS
该参数表示间隔多久检测一次是否有新创建的 partition。默认值是 Long 的最小值,表示不开启,大于 0 表示开启。开启时会启动一个线程根据传入的 interval 定期获取 Kafka 最新的元数据,新 partition 对应的那一个 subtask 会自动发现并从 earliest 位置开始消费,新创建的 partition 对其他 subtask 并不会产生影响。
代码如下所示:
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVA_L_MILLIS,30*1000+"");
10. Watermark 不更新
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。比如 Kafka 的Topic 中,由于某些原因,造成个别 Partition 一直没有新的数据。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化,导致窗口、定时器等不会被触发。
为了解决这个问题,可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();Properties properties =newProperties();
properties.setProperty("bootstrap.servers","hadoop1:9092,hadoop2:9092,hadoop3:9092");
properties.setProperty("group.id","fffffffffff");FlinkKafkaConsumer<String> kafkaSourceFunction =newFlinkKafkaConsumer<>("flinktest",newSimpleStringSchema(), properties);
kafkaSourceFunction.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMinutes(2)).withIdleness(Duration.ofMinutes(5)));
env.addSource(kafkaSourceFunction);
11. 依赖冲突
ClassNotFoundException
NoSuchMethodError
IncompatibleClassChangeError
...
一般都是因为用户依赖第三方包的版本与 Flink 框架依赖的版本有冲突导致。根据报错信息中的类名,定位到冲突的 jar 包,idea 可以借助 maven helper 插件查找冲突的有哪些。打包插件建议使用 maven-shade-plugin。
12. 超出文件描述符限制
java.io.IOException: Too many open files
首先检查 Linux 系统 ulimit -n 的文件描述符限制,再注意检查程序内是否有资源(如各种连接池的连接)未及时释放。值得注意的是,低版本 Flink 使用 RocksDB 状态后端也有可能 会抛出这个异常,此时需修改 flink-conf.yaml 中的 state.backend.rocksdb.files.open 参数,如果不限制,可以改为-1 (1.13 默认就是-1) 。
13. 脏数据导致数据转发失败
org.apache.flink.streaming.runtime.tasks.ExceptionInChainedOperatorException: Could not forward element to next operator
该异常几乎都是由于程序业务逻辑有误,或者数据流里存在未处理好的脏数据导致的,继续向下追溯异常栈一般就可以看到具体的出错原因,比较常见的如 POJO 内有空字段,或者抽取事件时间的时间戳为 null 等。
14. 通讯超时
akka.pattern.AskTimeoutException: Ask timed out on [Actor [akka://...]] after [10000 ms]
Akka 超时导致,一般有两种原因:一是集群负载比较大或者网络比较拥塞,二是业务逻辑同步调用耗时的外部服务。如果负载或网络问题无法彻底缓解,需考虑调大 akka.ask.timeout 参数的值(默认只有 10 秒);另外,调用外部服务时尽量异步操作(Async I/O)。
15. 提交的flink程序重启失败
15.1. 错误日志
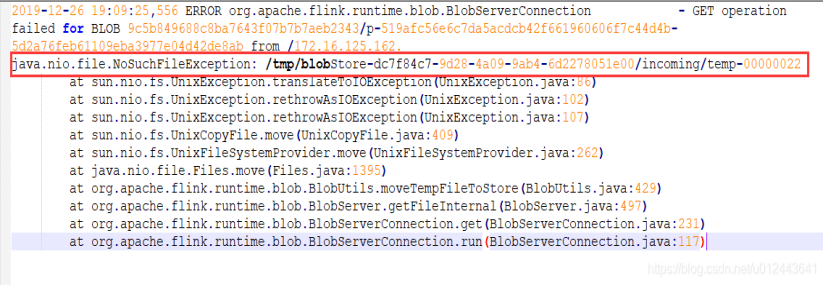
从图中可以看出,flink程序在自动重启时,需要寻找 /tmp 目录下面的一些文件。但是由于 linux 系统的 /tmp 目录会被很多程序以及操作系统本身用到,所以很难避免文件的误删除操作。
这个错误一般只会出现在使用 flink standalone 集群时发生。
15.2. 解决方案
在flink的 flink-conf.yaml 文件中,有个配置项叫 io.tmp.dirs ,该配置用于决定程序运行过程中一些临时文件保存的目录。建议将该目录配置为 flink 专用目录。
16. flink集群无法通过 stop-cluster.sh 脚本停止
16.1. 错误现象
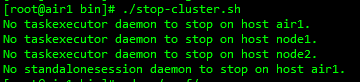

通过脚本停止集群,发现无法在对应的机器上找到对应的flink服务,出现在 flink standalone 模式集群。
16.2. 解决方案
在flink的安装目录下的 /bin 目录下有个 config.sh 脚本文件,里面有一项配置用来配置 flink 服务的 pid 文件目录,配置名称为: DEFAULT_ENV_PID_DIR ,默认值为 /tmp 。由于 linux 系统的 /tmp 目录会被很多程序以及操作系统本身用到,所以很难避免文件的误删除操作。出现上述日志就是因为 pid 文件被删除,导致 flink 找不到机器上的进程 pid 编号所致。因此我们需要修改该默认配置为一个 flink 专用目录。
17. flink sql on hive 太多max函数
flink版本:1.11.1
运行了一个sql语句,查询 hive 表的数据,有
group by
,然后对很多字段取最大值,示例代码如下:
select user_id,max(column1),max(column2),max(column3)from test.test
groupby user_id
;
select 后面的 max 字段有 150 多个,然后运行代码报错如下:
java.lang.RuntimeException: Could not instantiate generated class 'LocalSortAggregateWithKeys$1975'
at org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:67)
at org.apache.flink.table.runtime.operators.CodeGenOperatorFactory.createStreamOperator(CodeGenOperatorFactory.java:40)
at org.apache.flink.streaming.api.operators.StreamOperatorFactoryUtil.createOperator(StreamOperatorFactoryUtil.java:70)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createChainedOperator(OperatorChain.java:470)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createOutputCollector(OperatorChain.java:393)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createChainedOperator(OperatorChain.java:459)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createOutputCollector(OperatorChain.java:393)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createChainedOperator(OperatorChain.java:459)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.createOutputCollector(OperatorChain.java:393)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.\<init\>(OperatorChain.java:155)
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:453)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:522)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:721)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:546)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.util.FlinkRuntimeException:org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
at org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:68)
at org.apache.flink.table.runtime.generated.GeneratedClass.compile(GeneratedClass.java:78)
at org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:65)
... 14 more
Caused by: org.apache.flink.shaded.guava18.com.google.common.util.concurrent.UncheckedExecutionException: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$Segment.get(LocalCache.java:2203)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache.get(LocalCache.java:3937)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$LocalManualCache.get(LocalCache.java:4739)
at org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:66)
... 16 more
Caused by: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
at org.apache.flink.table.runtime.generated.CompileUtils.doCompile(CompileUtils.java:81)
at org.apache.flink.table.runtime.generated.CompileUtils.lambda\$compile\$1(CompileUtils.java:66)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$LocalManualCache\$1.load(LocalCache.java:4742)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$LoadingValueReference.loadFuture(LocalCache.java:3527)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$Segment.loadSync(LocalCache.java:2319)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$Segment.lockedGetOrLoad(LocalCache.java:2282)
at org.apache.flink.shaded.guava18.com.google.common.cache.LocalCache\$Segment.get(LocalCache.java:2197)
... 19 more
Caused by: java.lang.StackOverflowError
at org.codehaus.janino.CodeContext.extract16BitValue(CodeContext.java:700)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:478)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:557)
at org.codehaus.janino.CodeContext.flowAnalysis(CodeContext.java:557)
主要错误是:StackOverflowError,栈溢出。这个错误意思是说,方法嵌套太多。
之后试了一下,发现是一个 sql 里面的聚合函数不能写太多,最大大概是 120 左右。建议聚合函数个数超过 100 个,就写两个 sql ,然后再把两个 sql 的结果进行合并。
18. 调用太多次get_json_value函数
将处理完的数据写入 pulsar 主题,主题字段特别多,超过 200 个,通过调用 get_json_value (类似于 hive 中的 get_json_object)函数,将处理完的结果数据(为 json 字符串)的内容提取出来,然后发现处理速度很慢。
解决方式就是,结果就保存一个字段,将 json 字符串输入,下游处理时再通过 get_json_value 函数获取需要的字段值,或者是在自定义 UDF 中获取。
19. 其他
Flink on YARN(下):常见问题与排查思路
版权归原作者 第一片心意 所有, 如有侵权,请联系我们删除。