
你能训练一个机器学习模型来预测你的模型的错误吗?

没有什么能阻止你去尝试。万一成功了呢,对吧。
我们已经不止一次地看到这个想法了。
从表面上看,这听起来很合理。机器学习模型也会出错。让我们利用这些错误,训练另一个模型来预测第一个模型的错误!有点像“信任探测器”,基于我们的模型过去的表现。
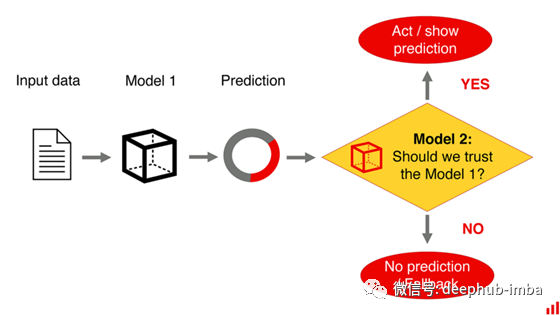
从错误中学习本身就很有意义。
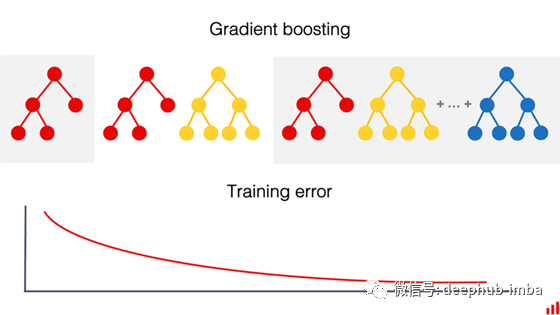
这种方法正是机器学习中提升技术的基础。它在许多集成算法中都得到了实现,如决策树的梯度增强。对下一个模型进行训练,以纠正前一个模型的错误。模型组合比单一组合性能更好。
但它能帮助我们训练另一个模型来预测第一个模型是否正确吗?
答案可能会令人失望。
让我们想想例子。
训练监督器
假设你有一个需求预测模型。当它出错的时候,你希望能进行判断。
你决定在第一个模型错误上训练一个新模型。这到底意味着什么?
这是一个回归任务,我们预测一个连续变量。一旦我们知道了实际销售量,我们就可以计算模型误差。我们可以选择MAPE或RMSE。然后,我们将使用这个指标的值作为目标来训练模型。

或者让我们举一个分类的例子:信贷违约的概率。
我们的贷款预测模型很可能是一种概率分类。每个客户都会得到一个从0到100的分数,关于他们违约的可能性。在某个临界值下,我们拒绝贷款。
总有一天,我们会知道真相。我们的一些预测可能是负面的:我们给那些仍然违约的人贷款。
但是,如果我们在没有回顾的情况下对所有预测都采取行动,我们就永远不会知道假阳性。如果我们错误地拒绝了一笔贷款,这个反馈就会留给客户。
我们仍然可以利用我们得到的部分信息。也许,对违约客户的预测概率,然后训练一个新的模型来预测类似的错误?
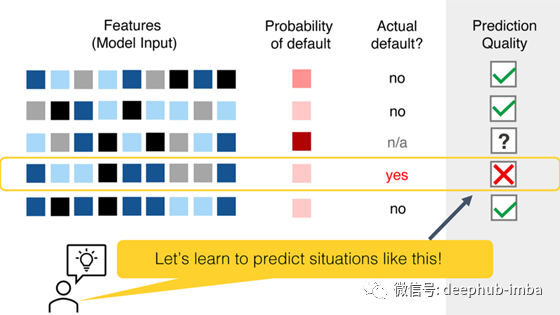
这种方案可行吗
是的,却又不是。
它在技术上是可行的。也就是说,你可以训练一个模型来预测一些事情。
但如果是这样,这意味着您应该重新训练初始模型!
让我们解释一下。
为什么机器学习模型会出错?撇开数据质量不谈,它通常是以下两种情况之一:
模型训练的数据中没有足够的信号。或者没有足够的数据。总的来说,或者是针对某个失败的特定部分。模型没有学到任何有用的东西,现在返回一个奇怪的响应。(我们的模型不够好。)从数据中正确捕捉信号太简单了。它不知道一些可能学到的东西。
在第一种情况下,模型错误没有模式。因此,任何训练“监督”模式的尝试都将失败。没有什么新东西需要学习。
在第二种情况下,你可以训练出一个更好的模型!一个更复杂的模式,它更适合捕捉所有模式的数据。
但如果你能做到,为什么要训练“监督器”呢?为什么不更新第一个模型呢?当我们第一次使用它时,它可以从同样的现实世界反馈中学习。
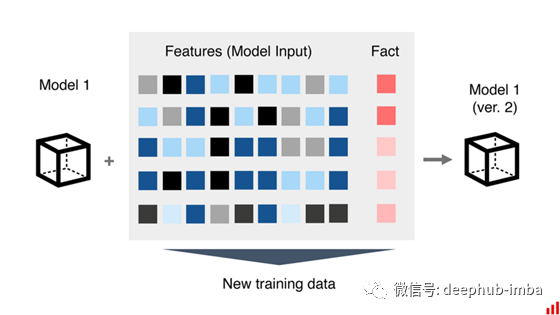
用一种模式来完成所有
有可能的是,我们最初的模型并不“糟糕”。这些人可能是改变了模式的客户,也可能是带来新模式的一些现实世界条件。想想影响销售和信用行为的问题。同样的旧数据和概念漂移我们已经讨论过了。
我们可以获取关于销售和贷款违约的新数据,并将其添加到我们的旧训练集。
我们不会预测“错误”。我们将教我们的模型预测完全相同的事情。一个人拖欠贷款的可能性有多大?销售量将是多少?但这将是一个从自身错误中吸取教训的新的、更新的模式。
就是这样!
它旁边的“监督器”模式不会增加价值。
它只是没有其他数据可以学习。这两种型号使用相同的功能集,并有访问相同的信号。
如果一种新模式犯了错误,“监督器”模式也会犯错。
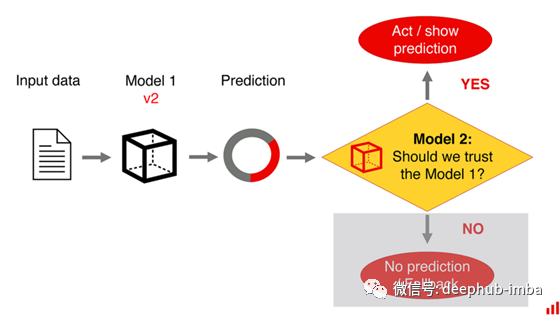
一个例外可能是,如果我们不能访问原始模型,并且不能直接对它进行再训练。例如,它属于第三方或根据规定是固定的。
如果我们有来自真实应用上下文和实际标签的新数据,我们确实可以构建第二个模型。然而,这是一种人为的限制。如果我们自己要维护原始模型,那么这样做毫无意义。
我们能做些什么呢?
“监督器”模式的想法并不奏效。我们还能做什么?
让我们从原因开始。
我们的主要目标是建立在生产中表现良好的值得信赖的模型。我们要尽量减少错误的预测。其中一些对我们来说可能很昂贵。
假设我们在建模方面做了我们所能做的一切,我们可以使用其他方法来确保我们的模型可靠地执行。
首先,建立一个定期监控流程。
是的,这种方法并没有直接解决模型所犯的每个错误。但它建立了一种方法来维护和改善模型性能,从而在规模上最小化错误。
这包括通过监测输入分布和预测的变化来检测数据和概念漂移的早期迹象。
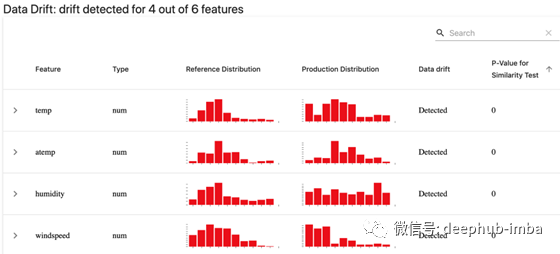
第二,考虑将机器学习与好的旧规则结合起来。
如果我们更详细地分析我们的模型行为,我们可以识别出它表现不好的地方。然后,我们可以将模型应用限制在那些我们知道模型有更多成功机会的情况下。
例如:如何在员工流失预测任务中应用这一思想。添加自定义阈值的概率分类,以平衡假阳性和假阴性错误。

第三,我们可以在模型输入上添加统计检查。
在“监督器”模型中,其思想是判断我们是否可以信任模型输出。相反,我们可以检测输入数据中的异常值。目的是验证它与模型训练的内容有何不同。例如,如果一个特定的输入与模型之前看到的“太不同”,我们可以发送它进行手动检查。
在回归问题中,有时你可以建立一个“监督器”模型。当您的原始模型考虑到它的符号优化预测误差时,就会发生这种情况。如果第二个“监督器”模型预测的是绝对错误,它可能会从数据集中得到更多信息。
但有一件事:如果它成功了,这并不能说明这个模型是“错误的”,也不能说明如何纠正它。相反,它是一种间接的方法来评估数据输入的不确定性。
在实践中,这将返回到相同的替代解决方案。我们不训练第二个模型,而是检查输入数据是否属于相同的分布!
总结
我们都希望我们的机器学习模型表现良好,并且知道我们可以信任模型输出。
虽然用另一种受监督的“监督器”模型来监控你的机器学习模型的乐观想法成功的几率很低,但这种意图本身有其优点。还有其他方法可以确保您的模型的生产质量。
其中包括构建完整的监控流程、设计自定义模型应用程序场景、检测异常值等等。
作者:Emeli Dral
deephub翻译组