
提示:此文章内容超级全面和详细
文章目录
前言
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
HDFS完全分布式集群,指的是在真实环境下,使用多台机器,共同配合,来构建一个完整的分布式文件系统。
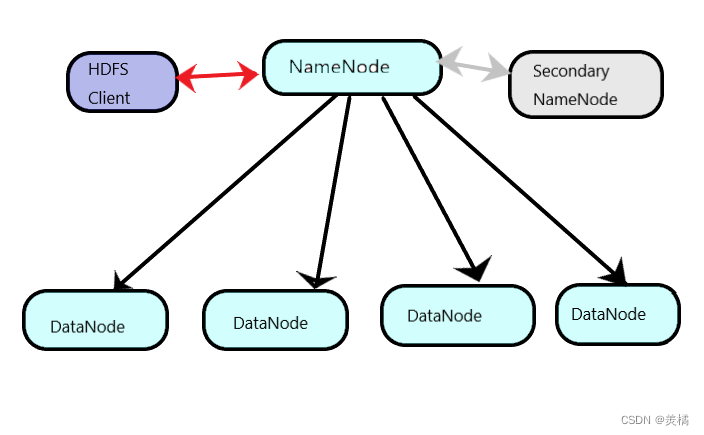
在真实环境中,hdfs中的相关守护进程也会分布在不同的机器中,比如:
- namenode守护进程尽可能的单独部署在一台硬件性能相对来说比较好的机器中。
- 其他的每台机器上都会部署一个datanode守护进程,一般的硬件环境即可。
- secondarynamenode守护进程最好不要和namenode在同一台机器上。
如图所示
二、HDFS完全分布式集群搭建与配置
1.HDFS完全分布式集群搭建
思路:
- 准备3台虚拟机(静态IP,IP映射,主机名称,防火墙关闭,普通用户创建等等)
- 安装JDK,配置环境变量
- 安装Hadoop,配置环境变量
- Hadoop执行本地wordcount案例
首先我们在第一节如何搭建可正常使用的centOS7系统虚拟机节点中,已经将bigdata100虚拟机大部分都已经安装配置好了,接下来的任务就是对这个bigdata100虚拟机进行克隆,将其作为母机或者叫模板机,目的是为了后面搭建分布式集群
首先,需要关闭bigdata100虚拟机,然后右键选择克隆
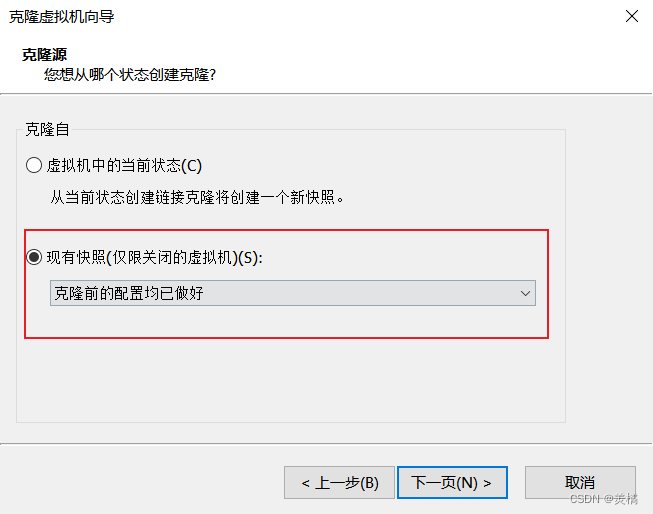
根据当前状态或者克隆前的快照进行克隆操作
或者
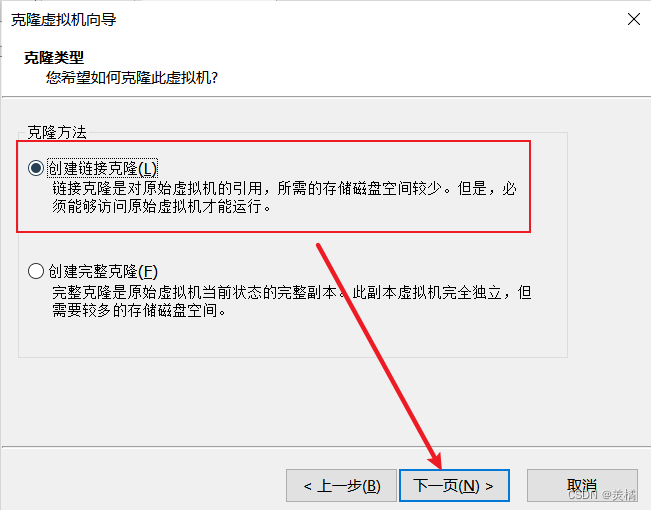
如果我们选择完整克隆,那么就类似计算机上的文档复制粘贴成一个副本文档,内容大小一模一样,这样子的好处是可以完完全全的保存原本的内容,而且副本和原件相互独立互不影响,删除副本或者原件对于另外一个文件没有任何影响;但是不好的地方是,如果文件比较大,那么完整克隆出来的副本就会比较占用空间,我们这里是虚拟机,占用空间比较大,如果多完整克隆几个副本,那么对于磁盘的空间占用比较厉害
所以我们选择第一种,链接克隆,这种方式最大的好处是非常节省空间,一个虚拟机的链接克隆可能也就上百兆即可,但是不太好的地方是,链接克隆需要依赖原件,所以我们的母机/模板机务必不能删除,也最好不要移动,如果是完整克隆就没有影响,其实很类似电脑上的快捷方式
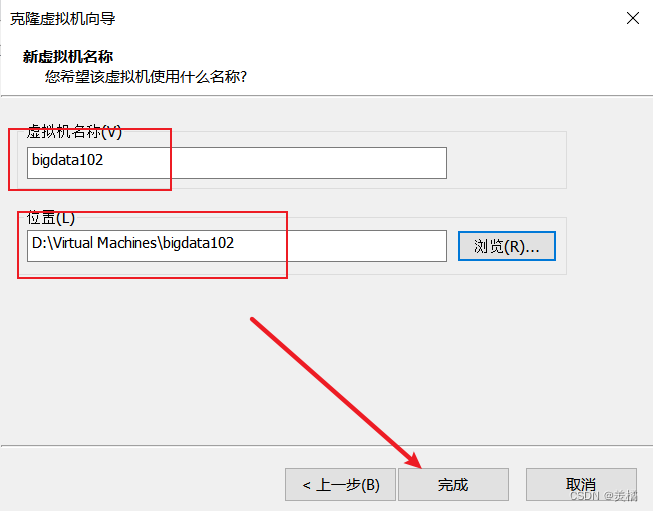
稍等片刻,链接克隆就搞定了
然后启动bigdata102,启动后我们使用root账户登录

虽然bigdata102可以正常联网,但是它的ip却是bigdata100的ip地址,这肯定不行,所以我们接下来要去修改bigdata102的ip

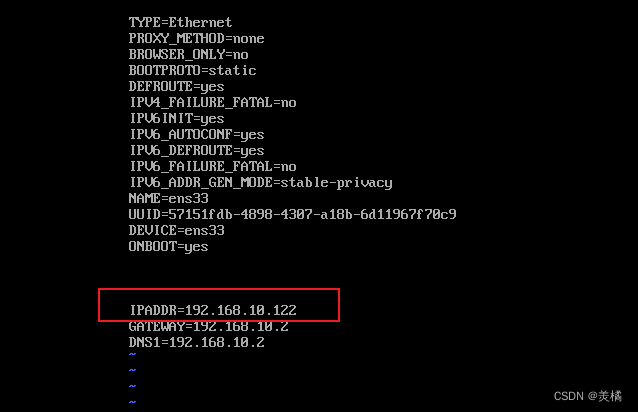
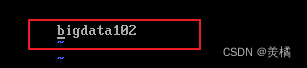
接着我们还要修改主机名以及映射文件

从bigdata100 改成 bigdata102
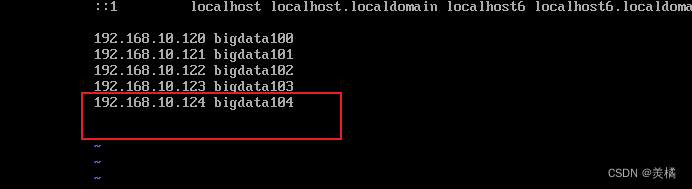
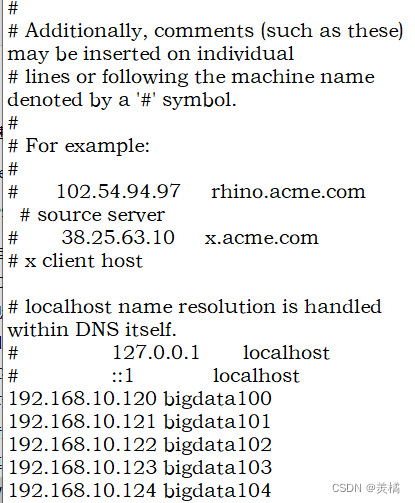
接着修改映射文件

加一行
最后我们使用reboot命令重启一下
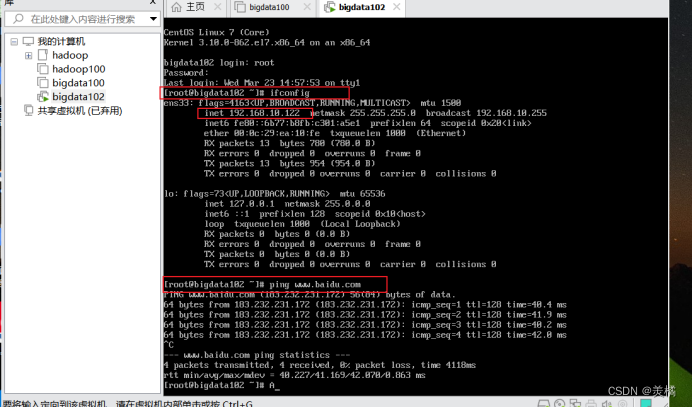
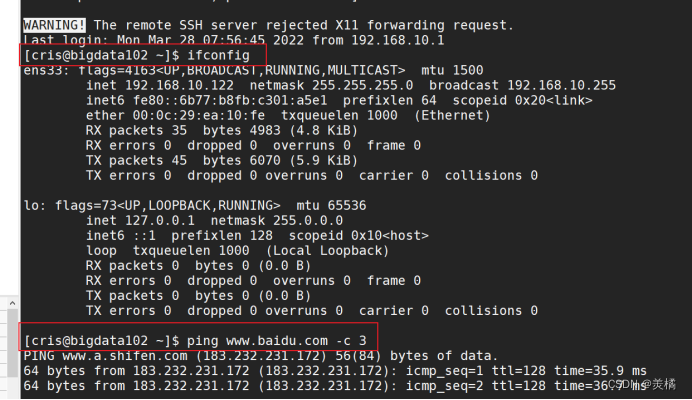
发现主机名已经从bigdata100 变成了bigdata102,并且ip地址也改过来了,并且还可以正常联网
最后关机,对bigdata102克隆机做一个快照。
最后微调一下Windows的hosts文件
之后我们就可以测试使用xshell去连接bigdata102
接下来就需要完成bigdata103和bigdata104的克隆,克隆完成后,一定要记得关机快照!!
完成集群的克隆之后,我们需要在bigdata102上安装jdk
使用普通用户cris登录bigdata102

安装步骤如下:
1.进入到 /opt/software 目录下
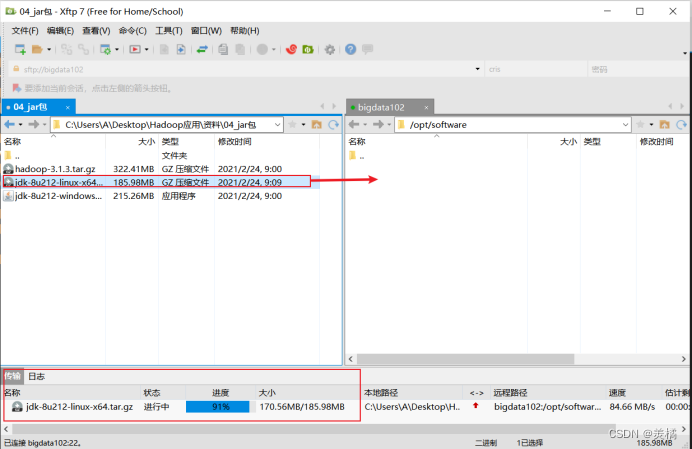
2.然后使用xftp进行jdk的压缩包上传
 使用ll命令进行查看
使用ll命令进行查看

然后解压到 /opt/module 目录下

3.配置jdk的环境变量

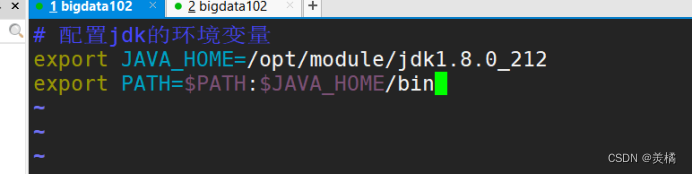
保存退出
原理类似Windows上的环境变量配置
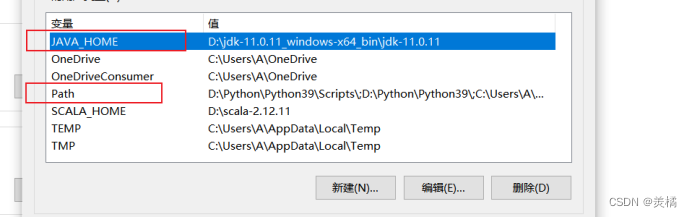
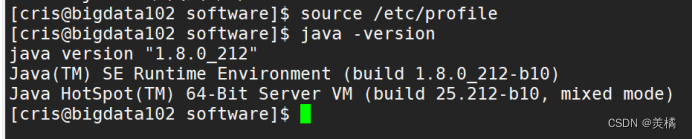
4.刷新环境变量配置文件,然后测试jdk是否安装成功
安装Hadoop压缩包
首先将Hadoop压缩包上传到 /opt/software 目录下

然后使用命令解压


将Hadoop添加到环境变量中
 复制Hadoop的安装路径,然后修改环境变量文件 代码如下(示例):
复制Hadoop的安装路径,然后修改环境变量文件 代码如下(示例):


修改完成后,刷新一下


以上就表示Hadoop安装成功,环境变量配置生效!
做完之后记得在bigdata102上面进行关机快照!
本地执行wordcount案例步骤
在Hadoop的文件路径下,新建一个wcinput文件夹
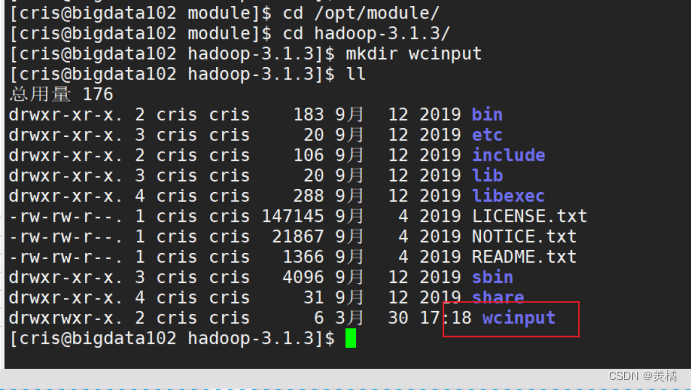
- 创建一个word.txt 文件,并且写入文本

文本内容如下
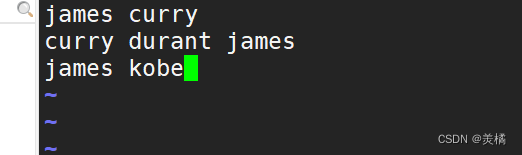
保存退出 :wq
2.回到Hadoop的文件目录

3.执行程序

回车执行以后,会出现以下日志

执行成功后

可以发现每个单词出现的频率,这就是wordcount案例
2.HDFS完全分布式集群配置
思路:
- 编写同步脚本,配置集群
- 配置免密登录,集群配置
编写同步脚本
scp命令(secure copy)
首先安全拷贝命令,主要是用来服务器之间的数据安全拷贝
基本语法: scp[命令] -r[表示递归拷贝] $pdir[表示要拷贝的文件路径] /$fname[文件名称] $user[目的地用户名称] @$host[主机名]: $pdir[目的地路径] /$fname[目的地文件名称]
案例练习:
将bigdata102上面的 jdk 拷贝到bigdata103和bigdata104上面
如果bigdata103和104已经有jdk,可以先删除掉
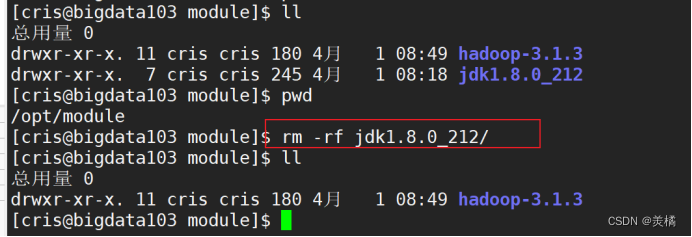
代码如下:
[cris@bigdata102 module]$ scp -r jdk1.8.0_212/ cris@bigdata103:/opt/module/
输入yes表示同bigdata103建立连接,然后输入bigdata103的cris用户密码(123456)
接着我们就可以在bigdata103上看到解压后的jdk 目录了

接着我们同理将bigdata102上的jdk目录拷贝到bigdata104上去,下面界面记得输入yes和密码(123456)

接着我们同步一下配置文件,将bigdata102的配置文件同步到bigdata103和bigdata104上面去,但是为了避免权限问题

我们需要使用root用户权限

做完之后我们还需要source一下

这样子我们bigdata104上面就不要在配置了,直接可以使用java命令
bigdata103同理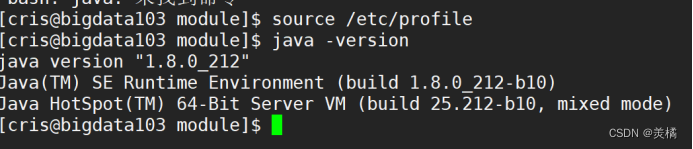
接下来的Hadoop目录也可以通过这种方式进行传输
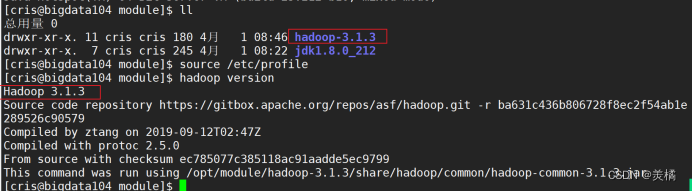
除了使用scp 命令完成上述文件的传输之外,我们其实用的更多的,是rsync这个命令,因为rsync 可以用于备份和镜像,具有速度快,避免复制相同内容以及支持符号链接的优点。
注:rsync和 scp主要的区别是:用rsync 做安全拷贝速度更快,并且只对差异化文件做更新传输,scp默认是将所有文件都进行传输。
rsync 基本语法
rsync -av[递归拷贝以及显示拷贝过程] $pdir/$fname $user@$host:$pdir/$fname
案例演示
我们可以在test文件夹下面修改一个文件a,然后同步到bigdata103和bigdata104上面去,可以发现同步过去的只有一个文件a,b并没有做同步
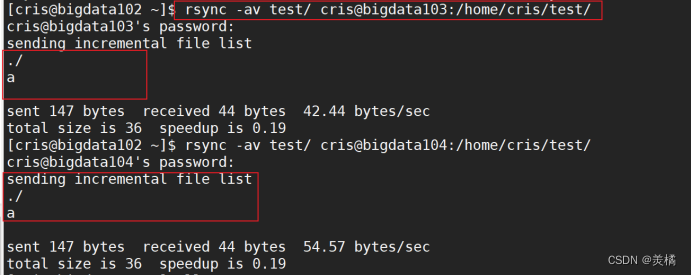
rsync 集群分发脚本编写,因为我们总是需要同步bigdata102的文件到bigdata103和bigdata104上面去,同样的同步命令我们不需要重复执行,只需要执行一遍即可,从bigdata103或者bigdata104上面进行文件同步也是这样子的。所以我们需要写一个同步脚本,去循环复制修改的文件到所有节点相同的目录下面去。
步骤1:在bigdata102上创建bin目录在 /home/cris 目录下
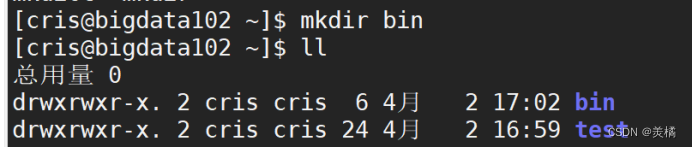
此时系统环境变量可以自动识别bin

意味着我们在 /home/cris/bin 下面写的脚本可以自动被系统识别,自动补全
步骤2:编写集群同步脚本xsync
在 /home/cris/bin 目录下新建一个脚本 xsync,赋予执行权限
touch xsync
chmod +x xsync
执行上面命令后,xsync 文件名变绿色说明赋予执行权限成功
然后编辑xsync脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有的机器
for host in bigdata102 bigdata103 bigdata104
do
echo =========================== $host ================
#3. 遍历所有目录,发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
接着我们可以测试

执行上面的命令,输入bigdata103和bigdata104的密码,执行完毕后,发现bigdata103和bigdata104上同步了bin目录,并且还有xsync文件即证明脚本没有问题
接着我们最后将 xsync 放入到 /bin 目录下,这样子root用户也可以正常用到这个同步命令

然后同步到其他服务器的 /bin 目录下
 接下来,我们需要完成 SSH 免密登录,目的就是为了在使用 xsync命令的时候,不去重复输入各个虚拟机的密码
接下来,我们需要完成 SSH 免密登录,目的就是为了在使用 xsync命令的时候,不去重复输入各个虚拟机的密码
免密登录
1.原理
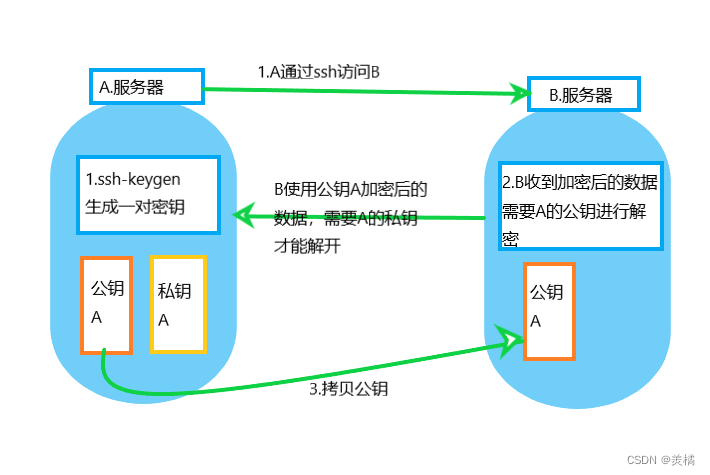
2. 实现步骤
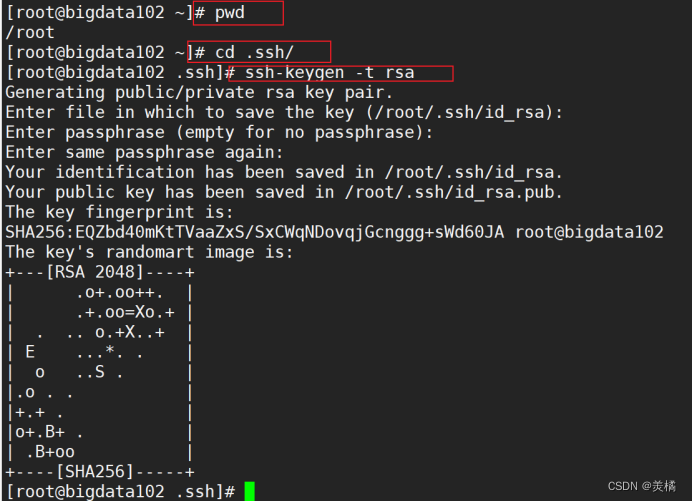
- 首先进入 .ssh 目录生成对应的公钥和私钥
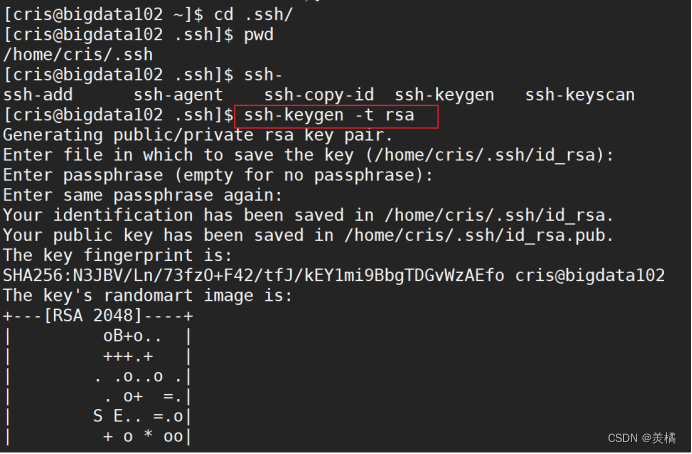
输入命令后记得敲三次回车(采用默认配置),此时会生成两个文件,一个是 id_rsa(私钥),一个是 id_rsp.pub(公钥)

2. 将公钥拷贝到要免密登录的三台服务器上



做完之后,我们还需要在bigdata103和bigdata104上重复上面的操作
免密测试
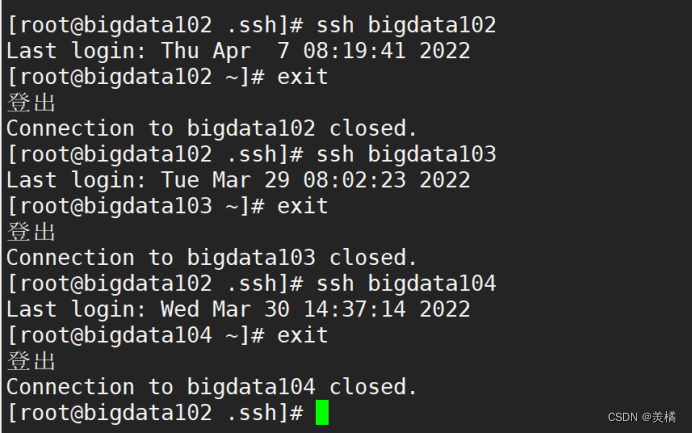
可以在bigdata102上去登录bigdata102,bigdata103以及bigdata104,发现不用输入密码,表示免密登录成功!
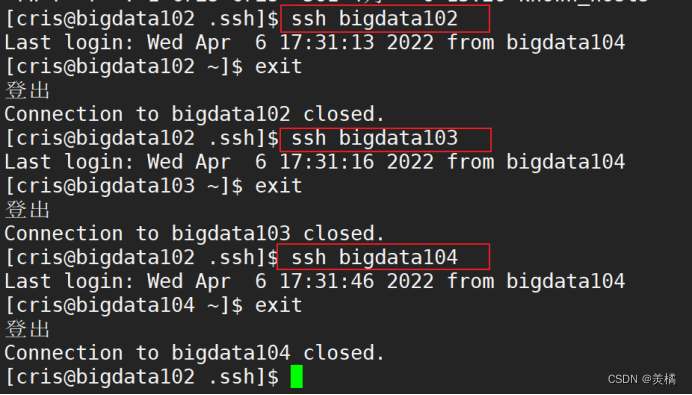
同理,我们还要在bigdata103和bigdata104上进行同样的测试
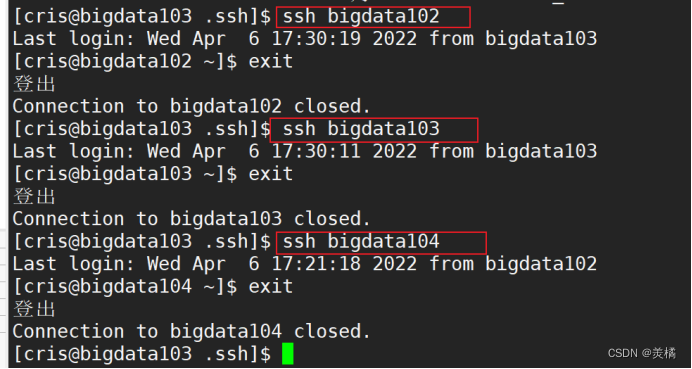
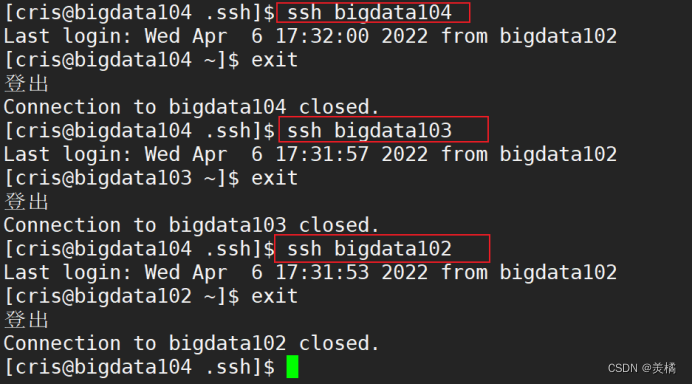
至此,才能证明我们的免密登录已经完成!
然后我们就可以使用xsync 命令去同步差异化的文件,并且不需要输入密码!
测试如下
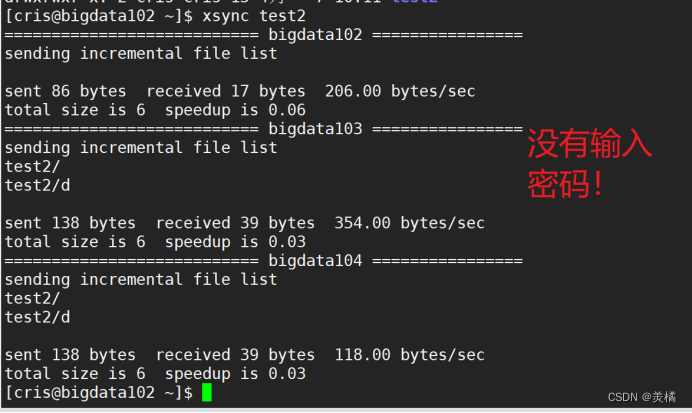
最后,我们只在bigdata102上使用root用户做一下免密登录即可,重复上面的步骤
切换root用户
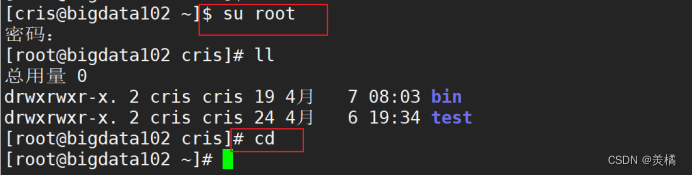
进入 root用户的 .ssh 目录进行免密操作



最后测试效果如下
常见的自定义配置文件:
core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml 这四个配置文件存放在/opt/module/hadoop-3.1.3/etc/hadoop这个路径下,我们可以根据需要去修改这四个配置文件
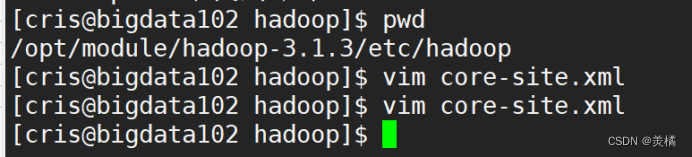
开始配置操作:
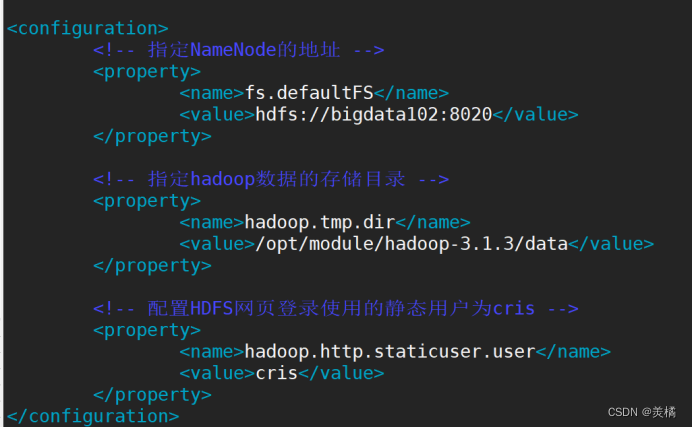
- 修改核心配置文件core-site.xml
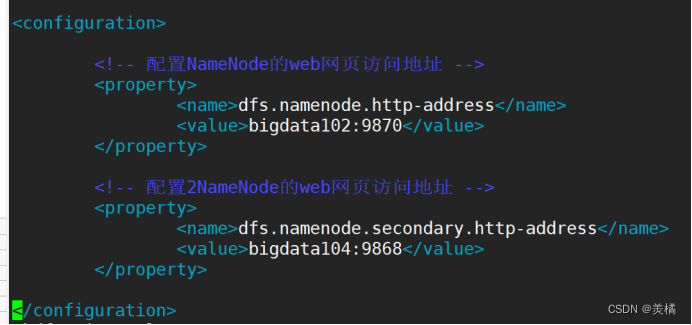
接着修改 hdfs-site.xml

修改内容如下
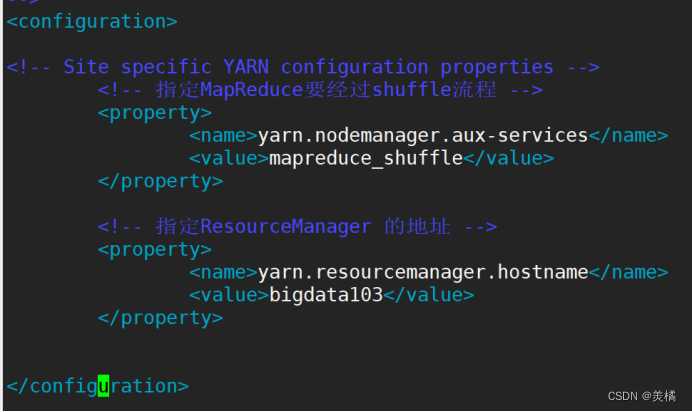
接着修改yarn-site.xml
最后配置MapReduce配置文件

最后分发文件,将bigdata102上面修改好的文件分发到103和104上面去

最好在103和104上面再确认一下,文件有没有修改过来


配置workers文件

这里是配置集群里面总共有三台节点
配置完成后,分发

验证,103和104上的workers已经和102一致


启动集群测试
1.先要格式化NameNode,一定要在102上去格式化

格式化结束后,日志结尾如下图,如果格式化报错,一定要去看屏幕上的信息,修改配置文件,然后再格式化

2.启动HDFS

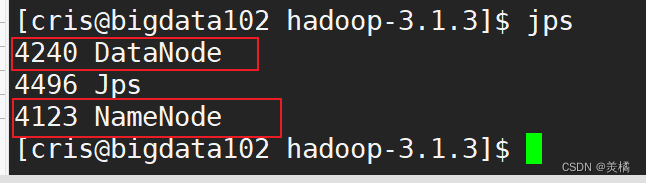

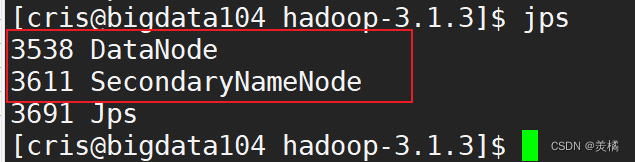
** 此时说明HDFS启动成功!**
接着我们在103上启动Yarn

稍等片刻,使用jps查看进程
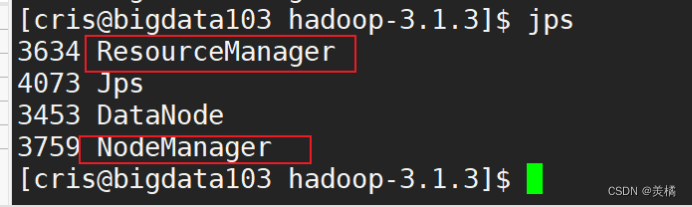

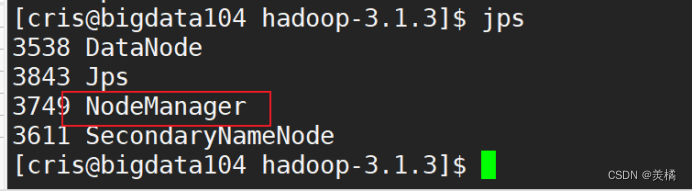
最后,web端查看NameNode和Yarn
HDFS 查看地址:http://bigdata102:9870/
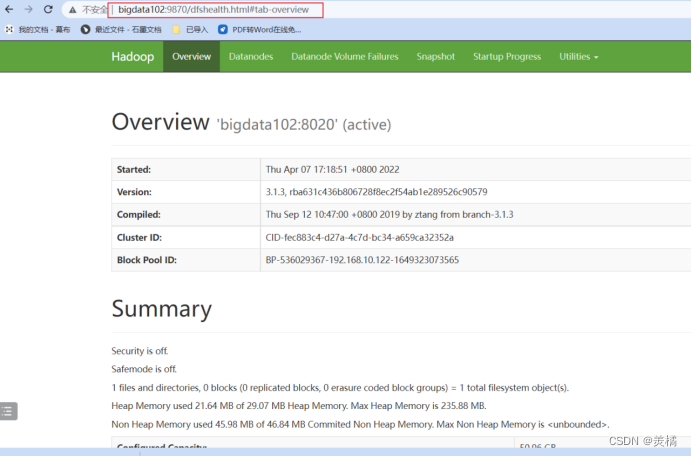
Yarn查看地址:http://bigdata103:8088/
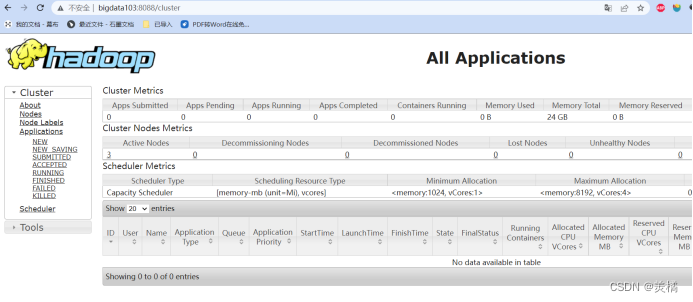
最后,关闭所有进程再关机快照!三台虚拟机都要做好快照


HDFS完全分布式集群搭建与配置的常见问题总结
提示:这里对文章进行会产生的问题总结:
- 格式化结束后,日志结尾如下图,如果格式化报错,一定要去看屏幕上的信息,修改配置文件,然后再格式化

2.在启动HDFS时,稍等片刻,查看启动情况,如果启动失败,也要看屏幕上的日志,一般都是 配置文件写错了。进行修改即可。
注:配置文件内容一定要完全一致,否则就会报错!
3.NameNode和SecondaryNameNode不能安装在同一台服务器上;ResourceManager同样比较 消耗性能,最好不要和NameNode以及SecondaryNameNode配置在一起
以上就是今天要讲的内容,本文仅仅简单介绍了HDFS完全分布式集群,HDFS完全分布式集群搭建与配置,HDFS完全分布式集群搭建与配置的常见问题总结。
版权归原作者 羙橘 所有, 如有侵权,请联系我们删除。