
菜鸡自用,避免又一次失忆,找不到东南西北。
在网上搜刮各位测试大佬的文章,终于搭起来基本的po模型框架
不得不说,脚本跑通带来的自豪感真是棒极了O(∩_∩)O哈哈~
其实脚本中还有很多问题,但是能够读懂里面的代码,并且应用到脚本中,进步不少,继续加油!
如果觉得还可以的话,麻烦给新人一个小小的赞吧~~~
1、Common
base_page:公共元素封装
定义driver初始化、查找元素、点击、输入、错误截图等一些方法;值得一提的是,我在错误截图的方法中加入了allure,当生成错误截图时,会把这个截图保存进allure报告,并且名称与路径一致
# encoding: utf-8
from selenium.webdriver.remote.webdriver import WebDriver
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from Common.log_handle import logger
from Config.path_name import PathName
from Common import time
import allure
class BasePage:
# 定义类变量driver和base_url
_driver = None
_base_url = "https://test.com"
def __init__(self, driver: WebDriver = None):
# 判断是否传入了driver,如果初次调用,则初始化driver
if driver is None:
self._driver = webdriver.Chrome()
self._driver.maximize_window()
self._driver.implicitly_wait(3)
# 非首次调用,传入了driver,则把传入的driver赋给_driver
else:
self._driver = driver
# 判断base_url是否为空,非空则调用get进行打开操作
if self._base_url != "":
self._driver.get(self._base_url)
def find(self, by, locator):
return self._driver.find_element(by, locator)
# 定义可被点击判断的方法
def wait_for_click(self, locator, time=10):
WebDriverWait(self._driver, time).until(EC.element_to_be_clickable(locator))
# 二次封装元素等待,如果错误,记录日志,并截图保存
def wait(self, loc, filename):
"""
元素等待
:param loc: 等待的元素
:param filename: 截图名字
:return:
这里使用的是隐式等待,同时将隐式等待和元素是否可见的判断进行了结合,这样更加稳定!
"""
logger.info('{}正待等待元素{}'.format(filename, loc))
try:
WebDriverWait(self._driver, timeout=30).until(EC.visibility_of_element_located(loc))
#首先是隐式等待表达式(driver对象,等待时长)
#同时每0.5秒会查看一次,查看元素是否出现,如果超过30s未出现,则报错timeout
#until()是等待元素可见,这里加入了元素是否可见的判断
except Exception as e:
self.error_screenshots(filename)
logger.exception('元素等待错误发生:{}元素为{}'.format(e, loc))
raise
def error_screenshots(self, name):
"""
保存截图,并将对应截图上传至allure报告,图片名称和文件路径一致
:param name:根据被调用传入的名字,生成png的图片
:return:
"""
try:
file_path = PathName.screenshots_path
times = time.time_sj()
filename = file_path + times + '{}.png'.format(name)
self._driver.get_screenshot_as_file(filename)
logger.info("正在保存图片:{}".format(filename))
allure.attach(self._driver.get_screenshot_as_png(), attachment_type=allure.attachment_type.PNG,name=filename)
except Exception as e:
logger.error('图片报存错误:{}'.format(e))
raise
def get_ele(self, loc, filename):
"""
查找元素
:param loc:
:param filename:
:return:
"""
logger.info('{}正在查找元素:{}'.format(filename, loc))
try:
# 这里使用的是find_element查找单个元素,这里需要传入的是一个表达式,需要告诉driver对象使用的是什么定位方法,以及元素定位!
# By是继承了selenium里面的8大定位方法,所以框架里操作元素的皆是By.XPATH或者By.id等等
# 同时因为需要传入的是一个表达式,而By.XPATH是一个元组,这里做了解包处理
ele = self._driver.find_element(*loc)
except Exception as e:
logger.exception('查找元素失败:')
self.error_screenshots(filename)
raise
else:
return ele
def send_key(self, loc, name, filename):
"""
输入文本
:param loc:元素
:param filename:截图名字
:param name: 输入的名字
:return:
"""
logger.info('{}正在操作元素{},输入文本{}'.format(filename, loc, name))
self.wait(loc, filename)
try:
self.get_ele(loc, filename).send_keys(name)
except:
logger.exception('元素错误 {}:')
self.error_screenshots(filename)
raise
def click_key(self, loc, filename):
"""
元素点击
:param loc:
:param filename:
:return:
"""
logger.info('{}正在操作元素{}'.format(filename, loc))
self.wait(loc, filename)
try:
self.get_ele(loc, filename).click()
except Exception as e:
logger.exception('点击元素错误:{}'.format(e))
self.error_screenshots(filename)
raise
def get_ele_text(self, loc, filename):
"""
获取元素文本
:param loc:
:param filename:
:return:
"""""
logger.info('{}正在获取文本{}'.format(filename, loc))
self.wait(loc, filename)
ele = self.get_ele(loc, filename)
try:
text = ele.text
logger.info('获取文本成功{}'.format(text))
return text
except:
logger.exception('获取文本错误:')
self.error_screenshots(filename)
def get_ele_attribute(self, loc, attribute_name, filename):
"""
获取元素属性
:param loc:
:param attribute_name:
:param filename:
:return:
"""
logger.info('{}正在获取元素{}的属性'.format(filename, loc))
self.wait(loc, filename)
ele = self.get_ele(loc, filename)
try:
value = ele.get_attribute(attribute_name)
logger.info('获取属性成功{}'.format(value))
return value
except:
logger.exception('获取属性失败')
self.error_screenshots(filename)
def wait_ele_click(self, loc, filename):
logger.info('{}正待等待可点击元素{}'.format(filename, loc))
try:
WebDriverWait(self._driver, timeout=20).until(EC.element_to_be_clickable(loc))
# logger.info('等待可点击元素{}'.format(loc))
except:
self.error_screenshots(filename)
logger.exception('等待可点击元素错误:元素为{}'.format(loc))
raise
def switch_to_iframe(self, loc, filename):
try:
WebDriverWait(self._driver, 20).until(EC.frame_to_be_available_and_switch_to_it(loc))
logger.info('正在进入嵌套页面:{}'.format(loc))
except:
logger.exception('进入嵌套页面失败{}'.format(loc))
self.error_screenshots(filename)
def click_wait_ele(self, loc, filename):
logger.info('正在等待{}中的可点击元素出现{}'.format(filename, loc))
self.wait_ele_click(loc, filename)
try:
self.get_ele(loc, filename).click()
logger.info('正在{}中点击元素{}'.format(filename, loc))
except:
logger.info('在{}当中点击{}元素失败'.format(filename, loc))
self.error_screenshots(filename)
log_handle:日志封装
# encoding: utf-8
"""
封装log日志模块
"""
import logging
import os
from Config.common_data import Context
from Config.path_name import PathName
log_path_name = os.path.join(PathName.logs_path, Context.log_name)
# print(log_path_name)
class LogHandel(logging.Logger):
"""定义日志类"""
def __init__(self, name, file, level='DEBUG',
fmt="%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"):
super().__init__(name)
self.setLevel(level)
file_headers = logging.FileHandler(file)
file_headers.setLevel(level)
self.addHandler(file_headers)
fmt = logging.Formatter(fmt)
file_headers.setFormatter(fmt)
logger = LogHandel(Context.log_name, log_path_name, level=Context.level)
if __name__ == '__main__':
log = logger
log.warning('测试1')
time:生成时间
# encoding: utf-8
"""
生成时间
"""
import datetime
def time_sj():
sj = datetime.datetime.now().strftime('%m-%d-%H-%M-%S')
return sj
2、Config
common_data 日志等级
# encoding: utf-8
"""
日志等级
"""
class Context:
log_name = 'log打印.txt'
level = 'DEBUG'
path_name 存放路径
# encoding: utf-8
"""
存放路径
"""
import os
class PathName:
# 初始路径
dir_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#
options_path = os.path.join(dir_path, 'Options')
# Logs文件目录地址
logs_path = os.path.join(options_path, 'Logs/')
# report测试报告路径
report_path = os.path.join(options_path, 'report/')
# 错误截图路径
screenshots_path = os.path.join(options_path, 'error_screenshots/')
# 测试用例路径
case_name = os.path.join(dir_path, 'testcases/')
3、Options 文件存放文件夹
在path_name定义的脚本中生成的log、report和错误截图存放路径,在后面的代码中也确实可以在对应的文件夹下面查看到生成的相关数据
4、page 页面元素定位
login
登录页面所有元素定位,直接通过F12复制生成的,后面还需要优化
# encoding: utf-8
"""
登录页面元素定位
"""
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from Common.log_handle import logger
from Common import base_page
class BackGroundLoc(base_page.BasePage):
# 登录窗口
input_user = (By.XPATH, '//*[@id="app"]/div/div/form/div[1]/div/div[1]/input')
# 输入密码
input_code = (By.XPATH, '//*[@id="app"]/div/div/form/div[2]/div/div/div/input')
# 用户登录
user_login = (By.XPATH, '//*[@id="app"]/div/div/form/button')
# 页面名称
title_name = '服务平台'
# error_msg
error_msg = (By.CSS_SELECTOR, '.el-message.el-message--error')
5、PageObject
login_home 登录页面
首先调用BasePage里面的方法将元素内容进行设置,并传入一个描述信息,在后期测试用例中直接引用就好
#!/usr/bin/python3
# coding=gbk
import time
from page.login import BackGroundLoc as BLC
from Common.base_page import BasePage
from selenium.webdriver.remote.webdriver import WebDriver
class Login(BasePage):
# 输入账号密码
def platform_login_succeed(self, phone, code):
self.send_key(BLC.input_user, phone, '登录页_输入用户名')
self.send_key(BLC.input_code, code, '登录页_输入密码')
time.sleep(2)
# 登录
def login(self):
self.click_key(BLC.user_login, '登录页_点击登陆')
time.sleep(2)
def login_fail(self):
error_text = self.get_ele_text(BLC.error_msg,filename='login_fail')
assert error_text == "验证码错误", f"实际错误信息为:{error_text}"
6、test_cases
conftest 前后置条件
# encoding: utf-8
"""
pytest前后置条件
"""
from Common.base_page import BasePage as GD
from Common.log_handle import logger
import pytest
from selenium import webdriver
# @pytest.fixture装饰器,是表示接下来的函数为测试用例的前后置条件
#fixture一共4个级别,默认scope=function(用例,对标为unittest中的setup以及tearDown)
#同时,fixture中包含了前置条件,以及后置条件
#function是每个用例开始和结束执行
#class是类等级,每个测试类执行一次
#modules 是模块级别,也就是当前.py文件执行一次
#session 是会话级别, 指测试会话中所有用例只执行一次
#pytest中区分前置后置是用关键字yield来区分的, yield之前,是前置!yield之后,是后置 yield同行,是返回数据
@pytest.fixture()
def open_browser():
logger.info('-----------正在执行测试用例开始的准备工作,打开浏览器,请求后台-----------')
driver = webdriver.Chrome()
driver.get(GD._base_url)
driver.maximize_window()
yield driver
driver.quit()
run_all 运行
清空测试报告文件夹,运行用例并生成allure报告至前面定义的路径下
import os
import pytest
import shutil
from Config.path_name import PathName
"""运行测试用例并生成allure报告"""
if __name__ == '__main__':
# 清空之前的报告文件夹
if os.path.exists(PathName.report_path):
shutil.rmtree(PathName.report_path)
os.makedirs(PathName.report_path)
# 运行test02测试用例,如果要运行文件夹下面所有的测试用例,则把文件名改为./文件夹名
pytest.main(['test_login.py', "-sv", "--alluredir", PathName.report_path+"json"])
# 生成报告,存储在path_name指定的文件夹下面
os.system("allure generate {} -o {} --clean".
format(PathName.report_path + "json", PathName.report_path + "html"))
# 生成报告,存储在当前文件夹下面
# os.system("allure generate ./report/json -o ./report/html --clean")
test_login 登录测试用例
# encoding: utf-8
from Common.log_handle import logger
from PageObject.login_home import Login
from Test_Data.test_data import TestData as TD
import pytest,allure
import time
data = TD.test_data
@allure.epic('服务平台')
@allure.feature('登录页面')
# pytest.mark.usefixtures()是使用前置条件,括号中填写要使用的前置条件函数名称
# 因为封装前置条件的py文件名称固定,所以这里不需要导入,是由pytest自动遍历查找
# 放在类方法上,是表示测试类下所有测试方法,都会使用这个前置条件
@pytest.mark.usefixtures('open_browser') # 用此方法可以提前打开网页
class Test_heart_login:
"""
# #正向场景
# 3.输入账号密码,点击登陆
# 4.选择对应子平台
# 6.判断首页元素是否可见
# :return:
# """
@allure.story('[case01] 登录成功')
def test_login_success(self,open_browser):
try:
with allure.step('打开页面'):
lg = Login(open_browser)
with allure.step('输入手机号、验证码登录'):
lg.platform_login_succeed(TD.just_data['phone'], TD.just_data['code'])
time.sleep(1)
with allure.step('点击登录按钮'):
lg.login()
logger.info('正在执行测试用例:手机号{},验证码{}'.format(TD.just_data['phone'], TD.just_data['code']))
except Exception as e:
logger.error('用例执行错误:{}'.format(e))
raise AssertionError
"""
@pytest.mark.parametrize()装饰器是用来执行数据驱动的,需要传入两个值
1.数据名称,不固定,自由填写
2.数据
但是数据名称要在使用数据驱动的方法里当作参数传入,对标ddt当中的传值接收
"""
@allure.story('[case02] 登录失败')
@pytest.mark.parametrize('test_data', TD.test_data)
def test_login_02_fail(self, open_browser, test_data):
"""
3.输入账号密码
4.选择对应平台
5.点击登陆
6.查看失败提示
:return:
"""
logger.info('+++++正在执行逆向向登陆测试用例+++++')
try:
with allure.step('打开页面'):
pf = Login(open_browser)
with allure.step('输入手机号、验证码登录'):
pf.platform_login_succeed(test_data['phone'], test_data['code'])
time.sleep(1)
with allure.step('点击登录按钮'):
pf.login()
pf.login_fail()
pf.error_screenshots('login_fail')
logger.info('正在执行逆向场景用例用户名{},密码{}'.format(test_data['phone'], test_data['code']))
except Exception as e:
logger.error('逆向场景用件执行失败{}'.format(e))
7、Test_Data 测试数据
test_data测试数据
# encoding: utf-8
"""
测试数据
"""
class TestData:
# 正确账号密码
just_data = {
'phone': '1234567899',
'code': '123456'
}
# 错误测试数据
test_data = [{'phone': '12345678999', 'code': '116611'},
{'phone': '12345678999', 'code': '116612'}]
8、运行脚本后,访问本地allure报告
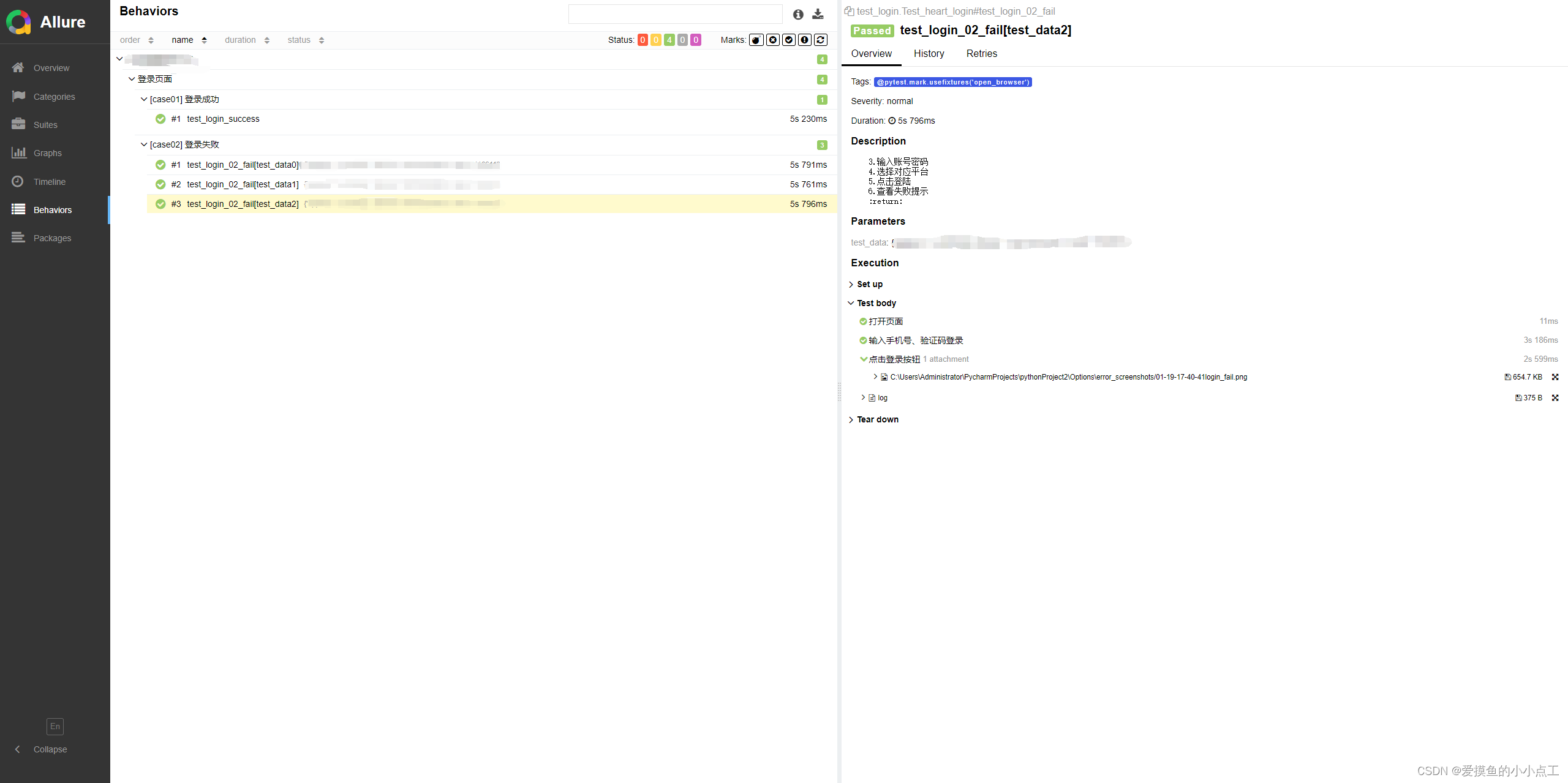
页面中的测试项目、模块、步骤都是在测试用例中标记的节点
本文转载自: https://blog.csdn.net/Zhu_33/article/details/135703968
版权归原作者 爱摸鱼的小小点工 所有, 如有侵权,请联系我们删除。
版权归原作者 爱摸鱼的小小点工 所有, 如有侵权,请联系我们删除。