
介绍
使用精度和召回率评估目标检测模型可以为模型在不同置信度下的表现提供有价值的见解。类似地,F1分数在确定平衡给定模型的精度和查全率值的最佳置信度时特别有用;但是,该值跨越了从0到1的置信值域。单个值评估指标可以从一个给定模型的F1分数集导出,这可能是一个很好的模型性能指标。
F1得分、准确率和召回率可以用以下公式进行评估:

当以不同的置信值评估模型时,这些度量标准可以很好地协同工作,为模型如何执行以及根据设计规范哪些值优化模型性能提供了有价值的见解。通常,当你提高置信阈值时,精度会提高,召回率会降低,如下图所示的自定义yolo v5模型的结果所示:
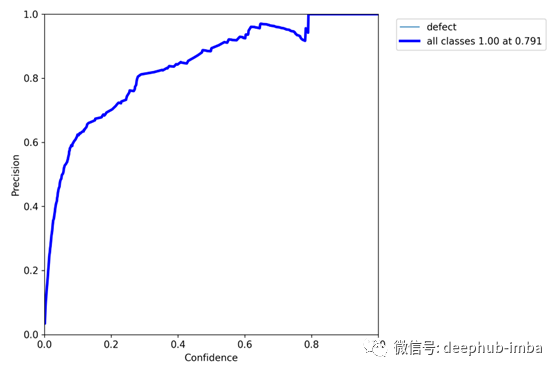
自定义yolo v5目标检测模型的单类精度评分
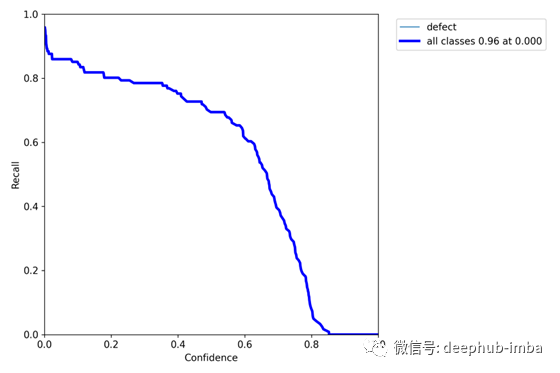
一个自定义yolo v5对象检测模型的单类召回分数
使用F1得分曲线,可以直观地看到精度和召回率之间的平衡,并可以使用下图确定一个设计点:
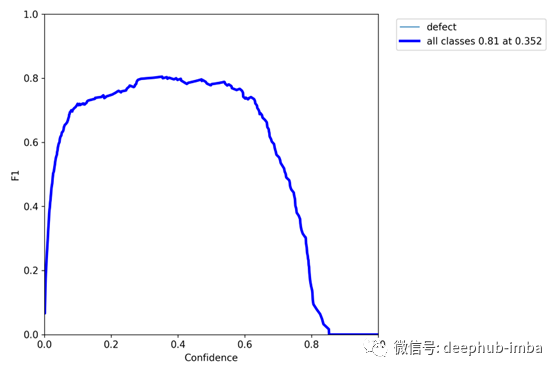
自定义yolo v5目标检测模型的F1分数曲线
从F1曲线来看,优化精度和召回率的置信度值为0.352。在许多情况下,较高的置信值是可取的。在这个模型的情况下,最优的选择可能是置信0.6,因为F1值似乎是大约0.75,这与最大值0.81相差不远。观察置信值为0.6的精度和查全率值也证实了这可能是一个合适的设计点。从0.6左右开始,查全率开始下降,准确率仍大致处于最大值。理论
现在,可以用F1分数中的一个数字来评估模型,方法是提供相应置信度的最大值;然而,这可能不能准确地表示整个模型。从F1得分中得到的一个建议的单数字度量如下所示:
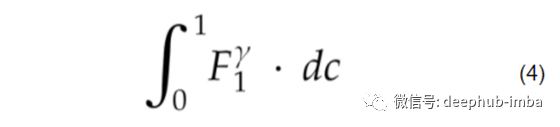
该值是通过对F1分数曲线的指数因子(称为gamma)进行积分来确定的。如果已知F1曲线的方程,可以使用这种形式。在大多数情况下,F1得分曲线是从使用评估或测试数据集评估的值生成的。在这种情况下,可以使用更一般的方程形式:
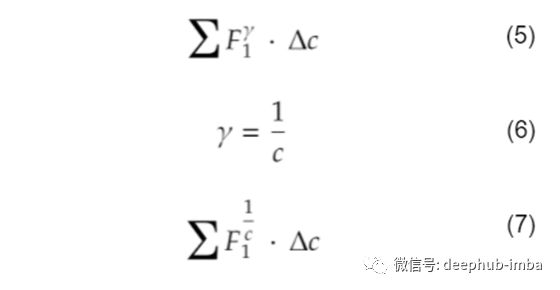
在应用矩形积分时,可以使用一个带有中点规则的方程的详细形式:
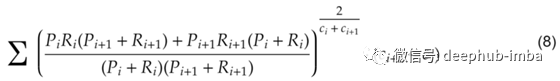
P 是给定索引处的 Precision 值,R 是给定索引处的召回值。指数伽玛 1/c 已被给定指数的平均置信度值所取代。
在这个新符号中,每个数据点的 F1 分数曲线下的面积将被计算并添加到运行总数中。指数因子 gamma 可用于惩罚和奖励 F1 曲线的各个区域。例如,对于 gamma 的标准值,1/c:F1 分数在较低置信度值时会因被驱动为 0 而受到严重惩罚,并且对整体指标的贡献很小。类似地,对于高置信度值的 F1 分数,指数因子对总体分数的影响最小。该metric可以得到的最大值为1,最小值为0。yolo v5模型中F1分数曲线各点的建议metric值如下图所示:
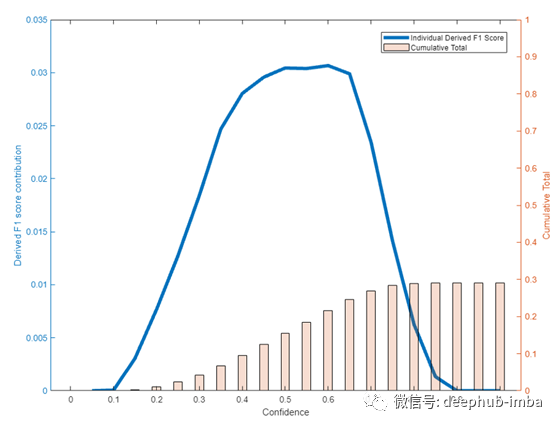
蓝线表示公式7在每个数据点的计算值。注意,随着数据点数量的增加,这个值会越来越小。浅橙色条表示所有计算的单数据点得分的累计。
由于伽玛因子,大多数F1得分在置信值为0.1或更少的情况下被推到零,F1得分贡献被抑制直到置信值为0.4。F1分数值被惩罚的程度可以使用gamma因子来控制。例如,如果需要更高的惩罚,可以将gamma因子的分子从1/c增加到10/c。这将使置信值0.4之前的所有值比之前的值受到更严重的惩罚,但它不会移动惩罚开始移动的置信值。
类似地,如果想要更少的惩罚,减少分子或甚至删除gamma指数将有所帮助。用来评价控制惩罚程度和惩罚点的变量的度量的方程形式可以用以下方式描述:
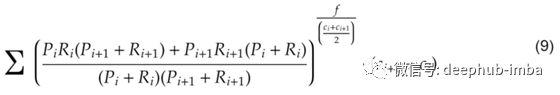
其中f用于控制惩罚的数量(默认值1),这已经在上面讨论过了。注意,将f增加到大于1的值将显著影响分数。比较
让我们比较三个模型:前面提到的基本模型、比基本模型差的模型和比基本模型好的模型。这些模型被指定为比基本模型更好或更差的方式可以总结为:
- F1曲线,积分面积,罚分积分面积
- 手动评估推理结果
- 通过更少的训练数据,不同的配置参数,以及epoch和batch变异来训练的更好或更差
各模型的F1曲线、非惩罚积分积分曲线和惩罚积分积分曲线如下:
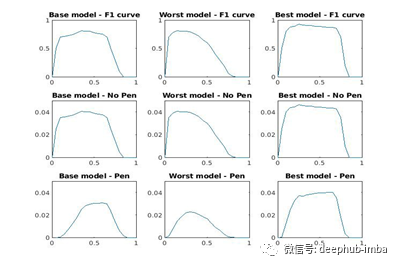
非惩罚曲线将遵循F1曲线的相同轮廓,因为它们是线性相关的。请注意,F1曲线和非惩罚积分曲线之间的幅度是不同的。这是由于方程9中的置信项。任何整合分数的最大值都是用于整合F1曲线的增量。在本例中,使用了0.05的增量,因此非惩罚积分和惩罚积分的最大值为0.05。当置信值接近0.4时,惩罚曲线的低置信值部分明显减少,严重程度逐渐减弱。所有惩罚曲线的f值均为1。
以上曲线的最终得分总结如下:
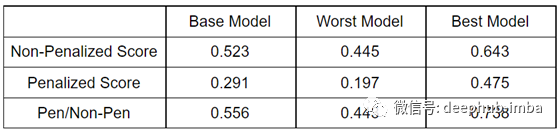
最后一行是罚分与非罚分的比率。表示积分F1得分处于较高置信区域的部分。如果想要获得更高的置信度,这可能是一个很好的指标,可以用来确定非惩罚分数的实际相关性。
GitHub已经公开了一个存储库,可以方便地计算惩罚和非惩罚积分。可在以下网址找到:
https://github.com/plebbyd/integrated-F1
此外,该存储库中的函数将返回任何给定的置信度输入和F1评分值的惩罚率和非惩罚率。
结论
罚分和非罚分的综合F1得分可能是评价目标检测模型的一个很好的单一数字度量。如果在研究或训练多个模型期间不可能手动检查F1曲线,那么评估这些新的度量标准可能会有帮助。
引用
[1] Powers, David M. W. (2011). “Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation”. Journal of Machine Learning Technologies. 2 (1): 37–63.
[2] Yolo v5 (2021). In: GitHub. https://github.com/ultralytics/yolov5. Accessed May 31, 2021.
作者:Peter Lebiedzinski