
文章目录

📋前言
在大数据、人工智能应用越来越普遍的今天,Python 可以说是当下世界上热门、应用广泛的编程语言之一,在人工智能、爬虫、数据分析、游戏、自动化运维等各个方面,无处不见其身影。随着大数据时代的来临,数据的收集与统计占据了重要地位,而数据的收集工作在很大程度上需要通过网络爬虫来爬取,所以网络爬虫技术变得十分重要。
🎯什么是网络爬虫
网络爬虫(Web crawler),也被称为网络蜘蛛、网络机器人,是一种自动获取互联网信息的程序。它通过访问并解析网页上的超链接,从而自动地收集和提取互联网上的信息,通过Python 可以很轻松地编写爬虫程序或者是脚本。
🧩 网络爬虫概述
在生活中网络爬虫经常出现,搜索引擎就离不开网络爬虫。例如,百度搜索引擎的爬虫名字叫作百度蜘蛛(Baiduspider)。百度蜘蛛,是百度搜索引擎的一个自动程序。它每天都会在海量的互联网信息中进行爬取,收集并整理互联网上的网页、图片视频等信息。然后当用户在百度搜索引擎中输入对应的关键词时,百度将从收集的网络信息中找出相关的内容,按照一定的顺序将信息展现给用户。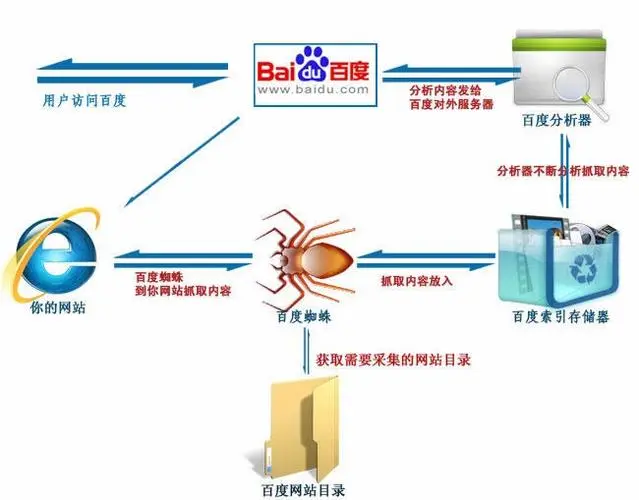
百度蜘蛛在工作的过程中,搜索引擎会构建一个调度程序,来调度百度蜘蛛的工作,这些调度程序都是需要使用一定算法来实现的,采用不同的算法,爬虫的工作效率也会有所不同,爬取的结果也会有所差异。所以,在学习爬虫时不仅需要了解爬虫的实现过程,还需要了解一些常见的爬虫算法。在特定的情况下,还需要开发者自己制定相应的算法。
🎯爬虫案例
以一个简单的新闻爬虫为例。假设我们想要从新闻网站上抓取最新的新闻标题和链接
- 发起请求:选择一个新闻网站作为起点,并向服务器发送HTTP请求,请求该网站的首页内容。
- 获取网页内容:服务器返回的网页内容包含了新闻标题和链接等信息。
- 解析网页:使用HTML解析库解析网页内容,提取出新闻标题和链接。
- 访问链接:在解析过程中,获取新闻列表页面中的每个新闻链接,并添加到待抓取队列。
- 逐个访问链接:从待抓取队列中取出新闻链接,并发起请求,获取对应新闻页面的内容。
- 解析新闻页面:解析新闻页面的内容,提取出新闻标题和正文等信息。
- 存储数据:将抓取到的新闻标题和链接存储到数据库或文件中。
通过以上步骤,我们可以自动化地抓取新闻网站上的最新新闻标题和链接,方便后续的数据分析或展示。然而,需要注意的是,进行网络爬虫时应遵守相关法律法规和伦理准则,尊重网站的使用条款和服务政策,并确保不对目标网站造成过大的访问压力。
🧩代码案例

通过以上步骤,我们可以自动化地抓取新闻网站上的最新新闻标题和链接,方便以下是一个使用 Python 语言和 Beautiful Soup 库的简单网络爬虫代码案例,用于从一个新闻网站抓取最新新闻标题和链接(仅供参考)。
import requests
from bs4 import BeautifulSoup
# 发起请求
url ="https://www.example.com/news"# 修改为目标新闻网站的URL
response = requests.get(url)# 解析网页
soup = BeautifulSoup(response.content,"html.parser")# 提取新闻标题和链接
news_list = soup.find_all("a", class_="news-title")# 根据网页结构和标签属性进行查找,这里假设新闻标题使用class为"news-title"的<a>标签for news in news_list:
title = news.text # 获取新闻标题文本
link = news["href"]# 获取新闻链接属性print("标题:", title)print("链接:", link)print("---------------------")
此外,网络爬虫的实现还需要考虑请求的频率、数据存储等方面的问题,并遵守相关的法律法规和伦理准则。在实际应用中,请确保遵守相关规定并尊重网站的使用条款和服务政策。
🔥文末送书

🧩编辑推荐
《Python网络爬虫从入门到精通》从零基础开始,提供了Python网络爬虫开发从入门到编程高手所必需的各类知识。无论有没有Python基础,通过本书你都能*终成为网络爬虫高手。
(1)主流技术,全面解析。本书涵盖网页抓取、App抓包、识别验证码、Scrapy爬虫框架,以及Scrapy_Redis分布式爬虫等技术,一本书教你掌握网络爬虫领域的主流核心技术。
(2)由浅入深,循序渐进。本书引领读者按照基础知识→核心技术→高级应用→项目实战循序渐进地学习,符合认知规律。
(3)边学边练,学以致用。200个应用示例 1个行业项目案例 136集Python零基础扫盲课,边学边练,在实践中提升技能。
(4)精彩栏目,贴心提醒。本书设置了很多“注意”“说明”“技巧”等小栏目,让读者在学习的过程中更轻松地理解相关知识点及概念,更快地掌握数据分析技能和应用技巧。
(5)在线解答,高效学习。在线答疑QQ及技术支持网站,不定期进行在线直播课程。
🧩内容介绍
《Python网络爬虫从入门到精通》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python实现网络爬虫开发应该掌握的技术。全书共分19章,内容包括初识网络爬虫、了解Web前端、请求模块urllib、请求模块urllib3、请求模块requests、高级网络请求模块、正则表达式、XPath解析、解析数据的BeautifulSoup、爬取动态渲染的信息、多线程与多进程爬虫、数据处理、数据存储、数据可视化、App抓包工具、识别验证码、Scrapy爬虫框架、Scrapy_Redis分布式爬虫、数据侦探。书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,读者可轻松领会网络爬虫程序开发的精髓,快速提高开发技能。
🧩作者介绍
明日科技,全称是吉林省明日科技有限公司,是一家专业从事软件开发、教育培训以及软件开发教育资源整合的高科技公司,其编写的教材非常注重选取软件开发中的必需、常用内容,同时也很注重内容的易学、方便性以及相关知识的拓展性,深受读者喜爱。其教材多次荣获“全行业优秀畅销品种”“全国高校出版社优秀畅销书”等奖项,多个品种长期位居同类图书销售排行榜的前列。
🔥参与方式

清华社【秋日阅读企划】领券立享优惠
IT好书 5折叠加10元 无门槛优惠券:https://u.jd.com/Yqsd9wj
活动时间:9月4日-9月17日,先到先得,快快来抢

《 Python网络爬虫从入门到精通》免费包邮送出 3 本!
抽奖方式:评论区随机抽取 3 位小伙伴免费送出!
参与方式:关注博主、点赞、收藏、评论区评论 “人生苦短,我学Python!” (切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间:2023-09-17 22:00:00
京东自营店购买链接:https://item.jd.com/13291912.html


版权归原作者 黛琳ghz 所有, 如有侵权,请联系我们删除。