
文章目录
前言
**简单的爬虫只有一个进程、一个线程,因此称为
单线程爬虫
。单线程爬虫每次只访问一个页面,不能充分利用计算机的网络带宽。一个页面最多也就几百KB,所以爬虫在爬取一个页面的时候,多出来的网速和从发起请求到得到源代码中间的时间都被浪费了。如果可以让爬虫同时访问10个页面,就相当于爬取速度提高了10倍。为了达到这个目的,就需要使用
多线程技术
了。**
**微观上的单线程,在宏观上就像同时在做几件事。这种机制在
I/O(Input/Output,输入/输出)密集型的操作
上影响不大,但是在
CPU计算密集型的操作
上面,由于只能使用CPU的一个核,就会对性能产生非常大的影响。所以涉及计算密集型的程序,就需要使用多进程。**
爬虫属于I/O密集型的程序,所以使用多线程可以大大提高爬取效率。
一、多进程库(multiprocessing)
**
multiprocessing
本身是
Python的多进程库
,用来处理与多进程相关的操作。但是由于进程与进程之间不能直接共享内存和堆栈资源,而且启动新的进程开销也比线程大得多,因此使用多线程来爬取比使用多进程有更多的优势。**
**multiprocessing下面有一个
dummy模块
,它可以让Python的线程使用multiprocessing的各种方法。**
**dummy下面有一个
Pool类
,它用来实现线程池。这个线程池有一个
map()方法
,可以让线程池里面的所有线程都“同时”执行一个函数。**
测试案例
** 计算0~9的每个数的平方**
# 循环for i inrange(10):print(i ** i)
也许你的第一反应会是上面这串代码,循环不就行了吗?反正就10个数!
**这种写法当然可以得到结果,但是代码是一个数一个数地计算,效率并不高。而如果使用多线程的技术,让代码同时计算很多个数的平方,就需要使用
multiprocessing.dummy
来实现:**
from multiprocessing.dummy import Pool
# 平方函数defcalc_power2(num):return num * num
# 定义三个线程池
pool = Pool(3)# 定义循环数
origin_num =[x for x inrange(10)]# 利用map让线程池中的所有线程‘同时’执行calc_power2函数
result = pool.map(calc_power2, origin_num)print(f'计算1-10的平方分别为:{result}')
在上面的代码中,先定义了一个函数用来计算平方,然后初始化了一个有3个线程的线程池。这3个线程负责计算10个数字的平方,谁先计算完手上的这个数,谁就先取下一个数继续计算,直到把所有的数字都计算完成为止。
**在这个例子中,线程池的
map()
方法接收两个参数,第1个参数是函数名,第2个参数是一个列表。注意:第1个参数仅仅是函数的名字,是不能带括号的。第2个参数是一个可迭代的对象,这个可迭代对象里面的每一个元素都会被函数
clac_power2()
接收来作为参数。除了列表以外,元组、集合或者字典都可以作为
map()
的第2个参数。**

二、多线程爬虫
**由于爬虫是
I/O密集型
的操作,特别是在请求网页源代码的时候,如果使用单线程来开发,会浪费大量的时间来等待网页返回,所以把多线程技术应用到爬虫中,可以大大提高爬虫的运行效率。**
**下面通过两段代码来对比单线程爬虫和多线程爬虫爬取
CSDN首页
的性能差异:**
import time
import requests
from multiprocessing.dummy import Pool
# 自定义函数defquery(url):
requests.get(url)
start = time.time()for i inrange(100):
query('https://www.csdn.net/')
end = time.time()print(f'单线程循环访问100次CSDN,耗时:{end - start}')
start = time.time()
url_list =[]for i inrange(100):
url_list.append('https://www.csdn.net/')
pool = Pool(5)
pool.map(query, url_list)
end = time.time()print(f'5线程访问100次CSDN,耗时:{end - start}')

**从运行结果可以看到,一个线程用时约
69.4s
,5个线程用时约
14.3s
,时间是单线程的
五分之一
左右。从时间上也可以看到5个线程“同时运行”的效果。**
**但并不是说线程池设置得越大越好。从上面的结果也可以看到,5个线程运行的时间其实比一个线程运行时间的五分之一(
13.88s
)要多一点。这多出来的一点其实就是线程切换的时间。这也从侧面反映了Python的多线程在微观上还是串行的。**
因此,如果线程池设置得过大,线程切换导致的开销可能会抵消多线程带来的性能提升。线程池的大小需要根据实际情况来确定,并没有确切的数据。
三、案例实操
**从 https://www.kanunu8.com/book2/11138/ 爬取
《北欧众神》所有章节的网址,再通过一个多线程爬虫将每一章的内容爬取下来。在本地创建一个“北欧众神”文件夹,并将小说中的每一章分别保存到这个文件夹中,且每一章保存为一个文件。**
import re
import os
import requests
from multiprocessing.dummy import Pool
# 爬取的主网站地址
start_url ='https://www.kanunu8.com/book2/11138/'"""
获取网页源代码
:param url: 网址
:return: 网页源代码
"""defget_source(url):
html = requests.get(url)return html.content.decode('gbk')# 这个网页需要使用gbk方式解码才能让中文正常显示"""
获取每一章链接,储存到一个列表中并返回
:param html: 目录页源代码
:return: 每章链接
"""defget_article_url(html):
article_url_list =[]
article_block = re.findall('正文(.*?)<div class="clear">', html, re.S)[0]
article_url = re.findall('<a href="(\d*.html)">', article_block, re.S)for url in article_url:
article_url_list.append(start_url + url)return article_url_list
"""
获取每一章的正文并返回章节名和正文
:param html: 正文源代码
:return: 章节名,正文
"""defget_article(html):
chapter_name = re.findall('<h1>(.*?)<br>', html, re.S)[0]
text_block = re.search('<p>(.*?)</p>', html, re.S).group(1)
text_block = text_block.replace(' ','')# 替换 网页空格符
text_block = text_block.replace('<p>','')# 替换 <p></p> 中的嵌入的 <p></p> 中的 <p>return chapter_name, text_block
"""
将每一章保存到本地
:param chapter: 章节名, 第X章
:param article: 正文内容
:return: None
"""defsave(chapter, article):
os.makedirs('北欧众神', exist_ok=True)# 如果没有"北欧众神"文件夹,就创建一个,如果有,则什么都不做"withopen(os.path.join('北欧众神', chapter +'.txt'),'w', encoding='utf-8')as f:
f.write(article)"""
根据正文网址获取正文源代码,并调用get_article函数获得正文内容最后保存到本地
:param url: 正文网址
:return: None
"""defquery_article(url):
article_html = get_source(url)
chapter_name, article_text = get_article(article_html)# print(chapter_name)# print(article_text)
save(chapter_name, article_text)if __name__ =='__main__':
toc_html = get_source(start_url)
toc_list = get_article_url(toc_html)
pool = Pool(4)
pool.map(query_article, toc_list)
四、案例解析
1、获取网页内容
# 爬取的主网站地址
start_url ='https://www.kanunu8.com/book2/11138/'"""
获取网页源代码
:param url: 网址
:return: 网页源代码
"""defget_source(url):
html = requests.get(url)return html.content.decode('gbk')# 这个网页需要使用gbk方式解码才能让中文正常显示
2、获取每一章链接
"""
获取每一章链接,储存到一个列表中并返回
:param html: 目录页源代码
:return: 每章链接
"""defget_article_url(html):
article_url_list =[]# 根据正文锁定每一章节的链接区域
article_block = re.findall('正文(.*?)<div class="clear">', html, re.S)[0]# 获取到每一章的链接
article_url = re.findall('<a href="(\d*.html)">', article_block, re.S)for url in article_url:
article_url_list.append(start_url + url)return article_url_list
3、获取每一章的正文并返回章节名和正文
"""
获取每一章的正文并返回章节名和正文
:param html: 正文源代码
:return: 章节名,正文
"""defget_article(html):
chapter_name = re.findall('<h1>(.*?)<br>', html, re.S)[0]
text_block = re.search('<p>(.*?)</p>', html, re.S).group(1)
text_block = text_block.replace(' ','')# 替换 网页空格符
text_block = text_block.replace('<p>','')# 替换 <p></p> 中的嵌入的 <p></p> 中的 <p>return chapter_name, text_block
这里利用正则分别匹配出每章的标题和正文内容: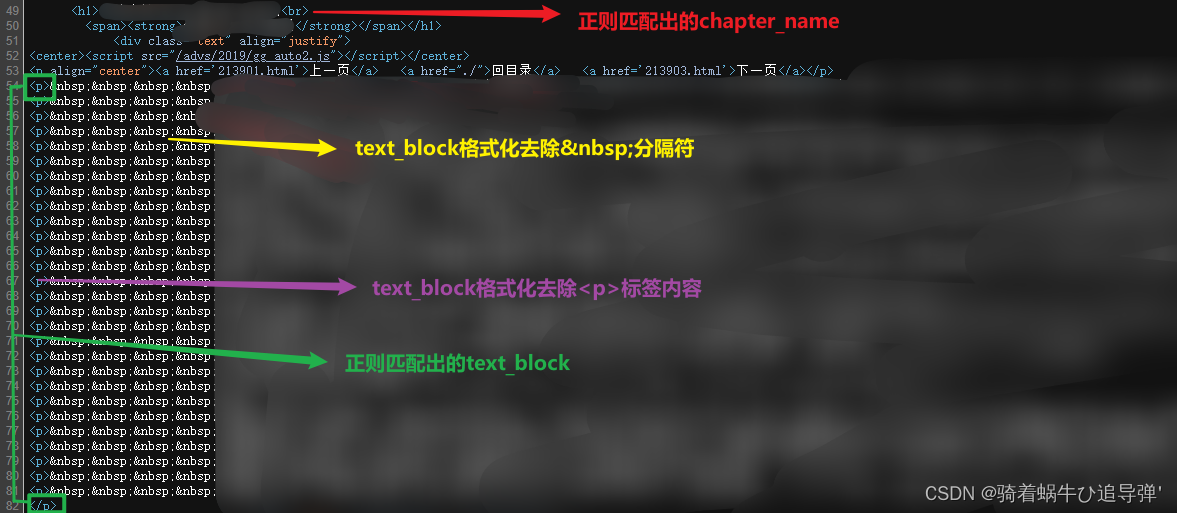
格式化后:
4、将每一章保存到本地
"""
将每一章保存到本地
:param chapter: 章节名, 第X章
:param article: 正文内容
:return: None
"""defsave(chapter, article):
os.makedirs('北欧众神', exist_ok=True)# 如果没有"北欧众神"文件夹,就创建一个,如果有,则什么都不做"withopen(os.path.join('北欧众神', chapter +'.txt'),'w', encoding='utf-8')as f:
f.write(article)
**这里获取到我们处理好的文章标题及内容,并将其写入本地磁盘。首先创建文件夹,然后打开文件夹以
章节名
结尾存储每章内容。**.txt
5、多线程爬取文章
"""
根据正文网址获取正文源代码,并调用get_article函数获得正文内容最后保存到本地
:param url: 正文网址
:return: None
"""defquery_article(url):
article_html = get_source(url)
chapter_name, article_text = get_article(article_html)# print(chapter_name)# print(article_text)
save(chapter_name, article_text)if __name__ =='__main__':
toc_html = get_source(start_url)
toc_list = get_article_url(toc_html)
pool = Pool(4)
pool.map(query_article, toc_list)
**这里
query_article
调用
get_source
、
get_article
函数获取以上分析的内容,再调用
save
函数进行本地存储,主入口main中创建线程池,包含4个线程。**
**
map()方法
,可以让线程池里面的所有线程都“同时”执行一个函数。
同时map()
方法接收两个参数,第1个参数是函数名,第2个参数是一个列表。这里我们需要对每一个章节进行爬取,所以应该是遍历
章节链接的列表
(调用
get_article_url
获取),执行
query_article
方法进行爬取保存。**
最后运行程序即可!
版权归原作者 骑着蜗牛ひ追导弹' 所有, 如有侵权,请联系我们删除。