
配置背景
我使用的root用户,懒得加sudo
所有文件夹在/opt/module
所有安装包在/opt/software
所有脚本文件在/root/bin
三台虚拟机:hadoop102-103-104
分发脚本 fenfa,放在~/bin下,chmod 777 fenfa给权限
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo XXXXXXXXX No Arguement XXXXXXXXX!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
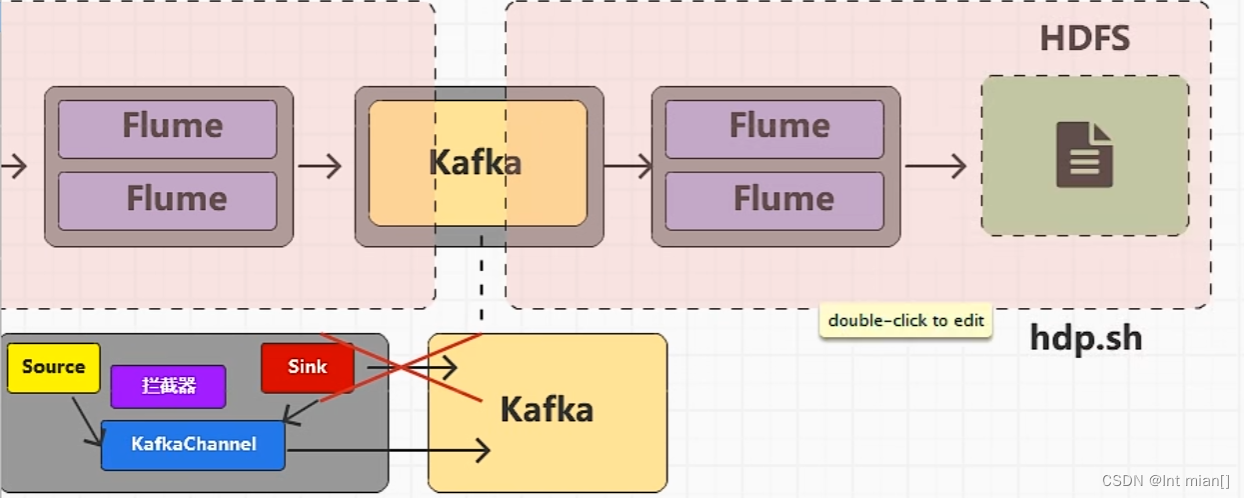
----- 数据采集 -----
Hadoop3.3.4
集群规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置
**hadoop102 **
hadoop103
hadoop104
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
集群安装步骤
下载https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
用xftp工具把安装包传到/opt/software
解压安装包
cd /opt/software/
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module/
改名、软连接(为了之后使用方便)
cd /opt/module
mv hadoop-3.3.4XXX hadoop-334
ln -s hadoop-334 hadoop
环境变量
vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
分发hadoop和环境变量
fenfa /opt/module/hadoop-334
fenfa /opt/module/hadoop
fenfa /etc/profile.d/my_env.sh
配置文件
配置core-site.xml
cd $HADOOP_HOME/etc/hadoop
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
-->
</configuration>
配置hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers
hadoop102
hadoop103
hadoop104
配置历史服务器mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
开启日志聚集功能,应用运行完成以后,将程序运行日志信息上传到HDFS系统上
yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
fenfa配置文件夹$HADOOP_HOME/etc/hadoop
启动
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
hdfs namenode -format
start-dfs.sh
start-yarn.shWeb端查看HDFS的Web页面:http://hadoop102:9870/
启停脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给权限!!!!
Zookeeper
步骤
Index of /zookeeper
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
mv apache-zookeeper-3.7.1-bin/ zookeeper
在/opt/module/zookeeper/目录下创建zkData
在/opt/module/zookeeper/zkData目录下创建一个myid的文件
在文件中添加与server对应的编号,hadoop102写2,103写3,104写4
2
配置zoo.cfg文件
重命名/opt/module/zookeeper/conf目录下的zoo_sample.cfg为zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper/zkData
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
fenfa整个zookeeper文件夹
记得修改myid文件
启动
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"
done
};;
esac
Kafka
步骤
Apache Kafka
tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/module/
mv kafka_2.12-3.3.1/ kafka
进入到/opt/module/kafka
vim config/server.properties
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop102:9092
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
fenfa整个kafka文件夹
分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id(三个虚拟机分别是1/2/3)及advertised.listeners
在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
fenfa环境变量
启动
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
Flume
步骤
Index of /dist/flume
(1)将apache-flume-1.10.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-flume-1.10.1-bin.tar.gz到/opt/module/目录下
mv /opt/module/apache-flume-1.10.1-bin /opt/module/flume
改vim conf/log4j2.xml
<Properties>
<Property name="LOG_DIR">/opt/module/flume/log</Property>
</Properties>
# 引入控制台输出,方便学习查看日志
<Root level="INFO">
<AppenderRef ref="LogFile" />
<AppenderRef ref="Console" />加上这一行
</Root>
不用分发
配置采集文件
创建Flume****配置文件
在hadoop102节点的Flume的job目录下创建file_to_kafka.conf。
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
这里真泥马坑,不知道尚硅谷怎么顺利运行的,
这里如果taildir_position.json的上级目录存在,是无法运行的,需要多加一个不存在的目录
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c1
测试
#!/bin/bash
case $1 in
"start"){
echo " --------启动 hadoop102 采集flume-------"
ssh hadoop102 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
};;
"stop"){
echo " --------停止 hadoop102 采集flume-------"
ssh hadoop102 "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
};;
esac
----- 数仓 -----
Hive
hive安装
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
注意:官网下载的Hive3.1.3和Spark3.3.1默认是不兼容的。因为Hive3.1.3支持的Spark版本是2.3.0,所以需要我们重新编译Hive3.1.3版本。
编译步骤:官网下载Hive3.1.3源码,修改pom文件中引用的Spark版本为3.3.1,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。(这里直接用尚硅谷的安装包)
解压-改名-环境变量
解决日志Jar包冲突,进入/opt/module/hive/lib目录
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
Hive元数据配置到MySQL, 将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql/mysql-connector-j-8.0.31.jar /opt/module/hive/lib/
配置Metastore到MySQL,在$HIVE_HOME/conf目录下新建hive-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--配置Hive保存元数据信息所需的 MySQL URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
启动Hive,初始化元数据库
初始化Hive元数据库
mysql -u root -p
create database metastore;
schematool -initSchema -dbType mysql -verbose
修改元数据库字符集
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
quit;
启动Hive客户端
hive
show databases;
OK
database_name
default
Time taken: 0.955 seconds, Fetched: 1 row(s)
在Hive所在节点部署Spark纯净版
上传并解压解压spark-3.3.1-bin-without-hadoop.tgz,环境变量
修改spark-env.sh配置文件
mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh
vim /opt/module/spark/conf/spark-env.sh
在末尾加一行
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
在hive中创建spark配置文件
vim /opt/module/hive/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
在HDFS创建如下路径,用于存储历史日志。
hadoop fs -mkdir /spark-history
向HDFS上传Spark纯净版jar包,将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
hadoop fs -mkdir /spark-jars
hadoop fs -put /opt/module/spark/jars/* /spark-jars
修改hive-site.xml****文件
vim /opt/module/hive/conf/hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
测试
hive
create table student(id int, name string);
insert into table student values(1,'abc');
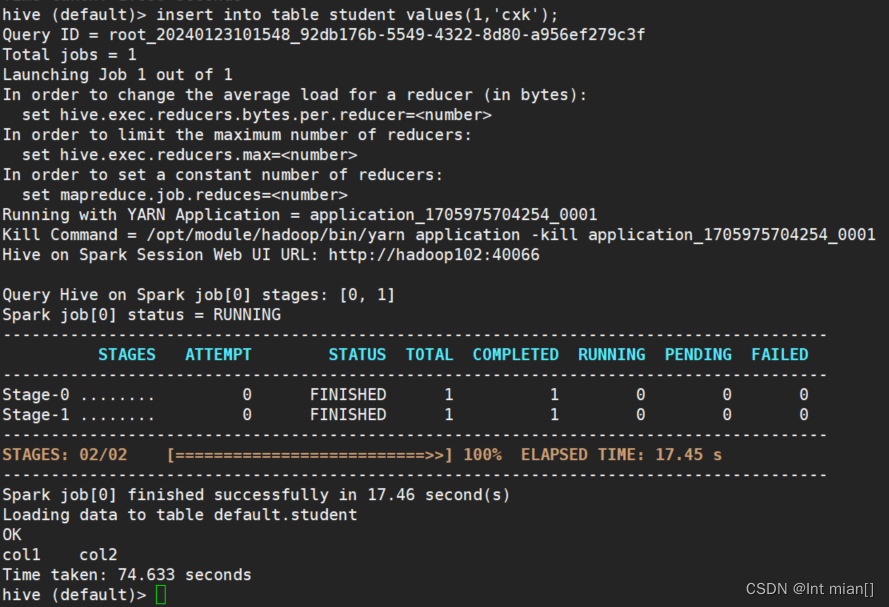
说明是spark引擎,我tm怎么用了74s????
Yarn环境配置
增加ApplicationMaster资源比例
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
故此处可将该值适当调大。
vim /opt/module/hadoop/etc/hadoop/capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property>
分发,重启yarn
版权归原作者 Int mian[] 所有, 如有侵权,请联系我们删除。