
了解什么是分布式事务问题
分布式事务是指涉及多个独立的计算机系统(也称为节点或参与者)之间的事务处理。在分布式系统中,每个节点可能各自拥有自己的数据存储和事务管理机制。分布式事务的目标是保证在跨多个节点执行的一系列操作可以以一致和可靠的方式执行和提交,即使在面对故障或并发操作时也能保持数据的完整性和一致性。
分布式事务通常包括以下四个关键属性:
- 原子性(Atomicity):要么所有的操作都成功执行并提交,要么所有的操作都回滚,保证所有节点的数据状态一致。
- 一致性(Consistency):事务执行前和执行后系统的状态保持一致。
- 隔离性(Isolation):事务在执行期间对其他事务是隔离的,即每个事务都感觉不到其他事务的存在。
- 持久性(Durability):一旦事务提交,其结果必须永久存储,即使在系统故障的情况下也能恢复。
实现分布式事务可以采用两阶段提交(Two-Phase Commit)协议或三阶段提交(Three-Phase Commit)协议等机制。这些协议通过协调参与者之间的状态和决策来实现分布式事务的一致性。然而,由于分布式事务需要跨越网络和多个节点进行通信和协调,因此可能会面临性能和可靠性等挑战。
举例说明:
当服务A通过restTemplate调用服务B的接口,服务A会持久化数据到A数据库,而服务B会持久化数据到数据库B,那么如果这个时候数据传输中间出现了问题,数据库A出现了持久化,而服务B持久化失败执行了回滚,但是数据库A是无法进行事务的回滚了,这个时候可能就会造成脏数据了
通过RabbitMQ来解决分布式事务问题
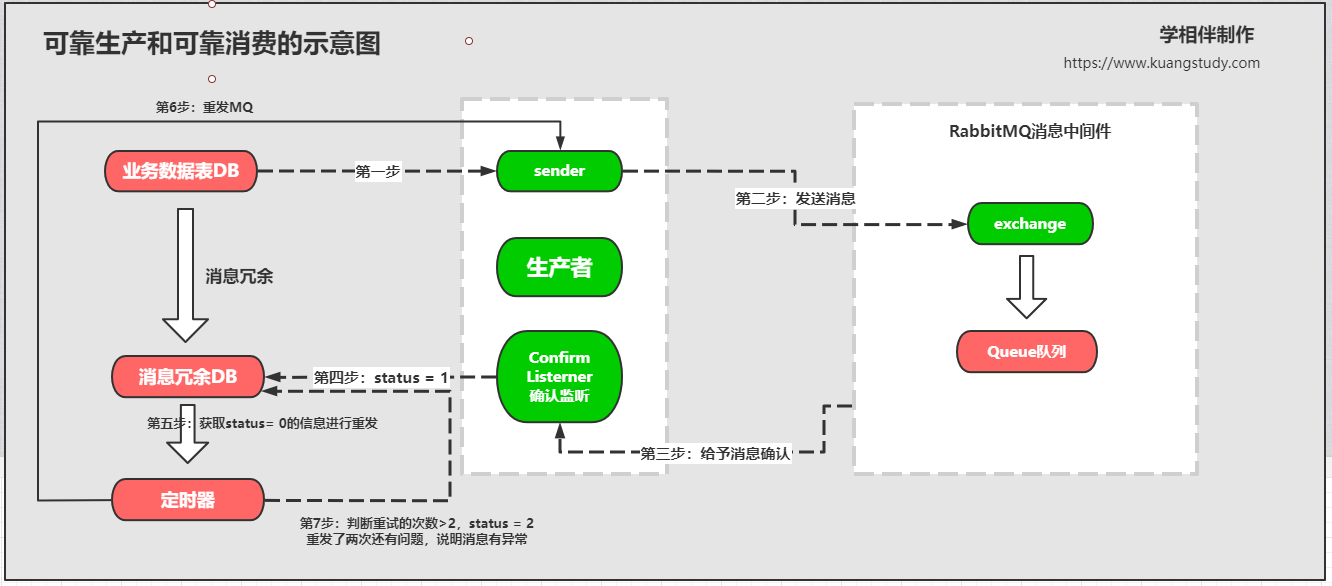
MQ解决分布式事务问题
可靠生产
主要是通过一张冗余表和定时任务解决了可靠生产的问题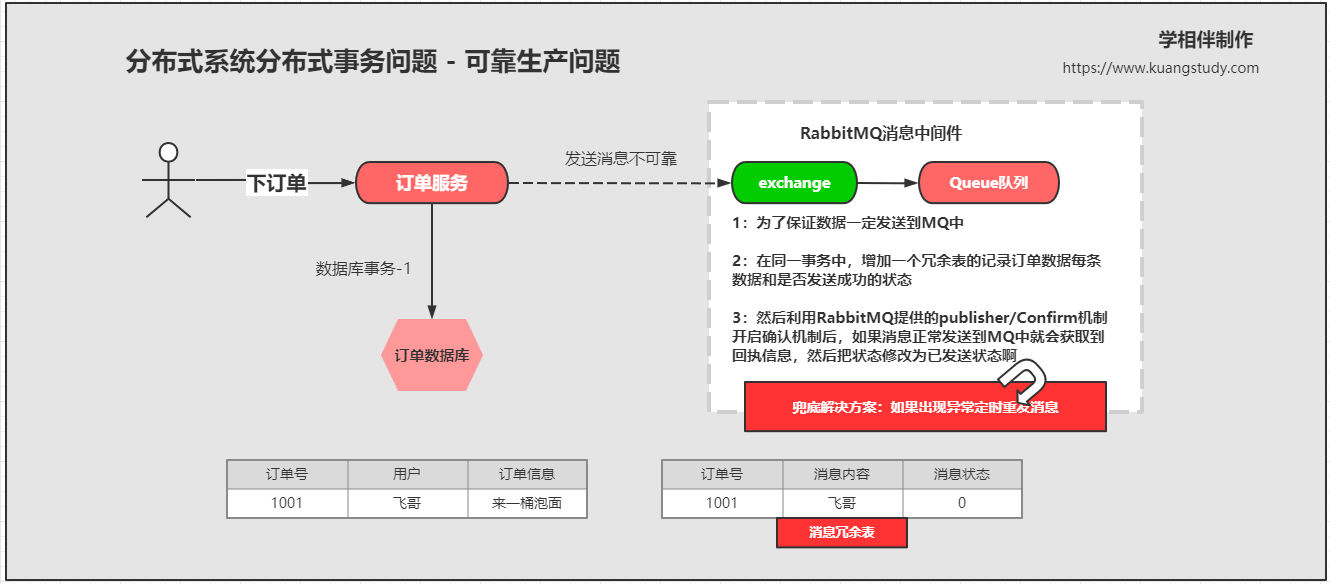
在本地数据库中创建一张冗余表
(1)如果消息可以正常发送到MQ,并且MQ给与了确认消息,那么这条数据会在冗余表中设置status为1;
(2)如果MQ此时宕机,那么这条数据就会存储到冗余表中,设置状态码为0(默认状态),会创建一个定时任务,定时将冗余的消息再发送到MQ中;
(3)如果发送次数超过两会,也就是status字段为2,那么就会判断是消息出现了问题,然后通知人工来排查问题所在
可靠消费
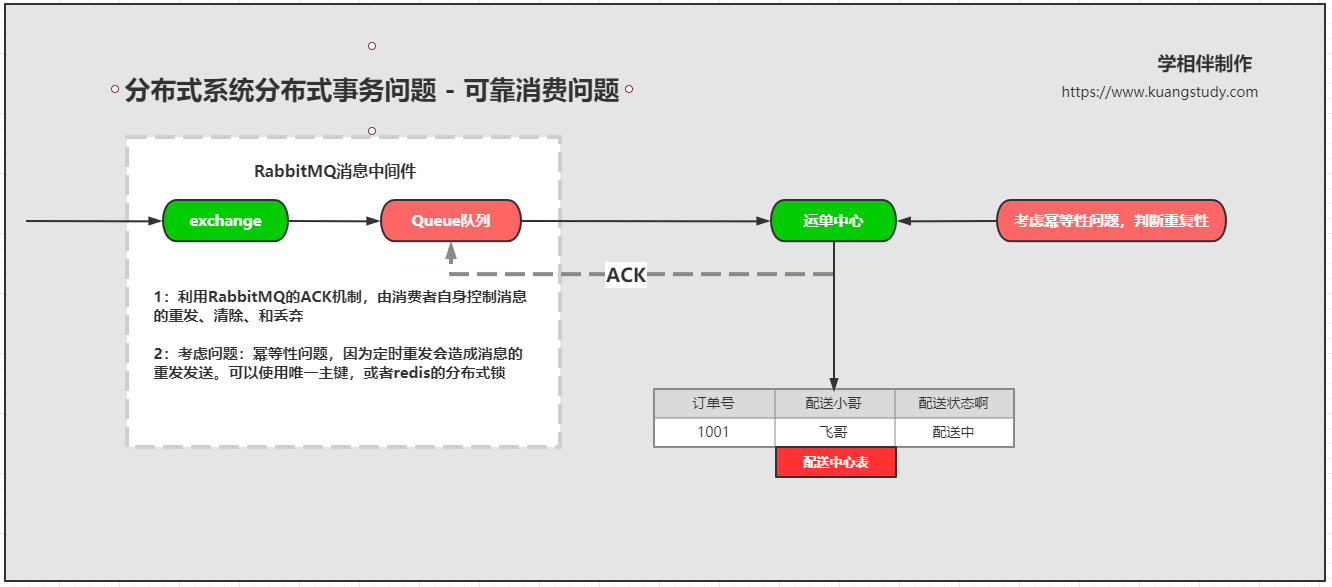
1.首先创建一个消费者,监听队列中的消息
2.如果消费者在消费消息的时候,出现了异常(代码中默认设置的是1/0的异常),那么就会触发MQ的重试机制,会导致死循环。解决消息重试的几种方案:(面试常问)
(1)控制重发的次数
在配置文件中进行相关重试次数的配置,如果达到了最大的重试次数,会把这条消息在队列中移除!
如果我们在配置文件中没有开启手动ack,使用默认的自动ack,那么会存在消息丢失的情况,一般不会使用这种方法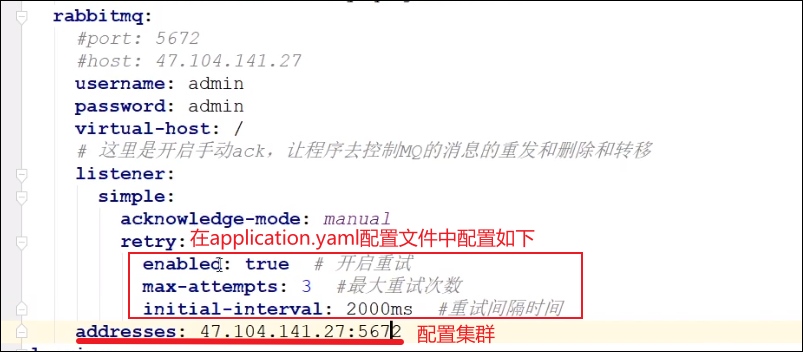
(2)try + catch + 手动ack
①第一步首先要在yaml配置文件开启手动ack,这样消息在出现异常,甚至是超过重试次数的时候就不会被移除,我们还能将这条消息转移到死信队列中!
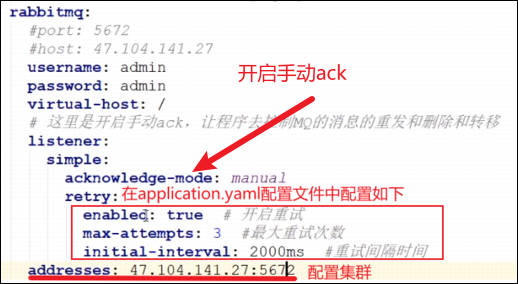
②在消费者消费消息的业务代码中,在catch中设置ack
调用basicNack方法,参数requeue,如果设置成false,那么消息如果消异常,就会将他转移到死信队列中,如果设置成true,那么就会将这条消息移除掉
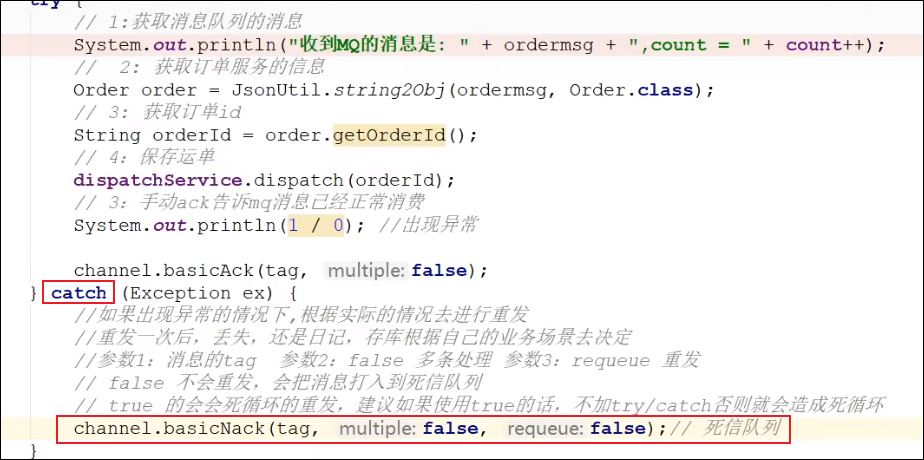
(3)try + catch + 手动ack + 死信队列处理 + 人工干预
①在上面开启手动ack的基础上,创建死信交换机和死信队列,绑定到接收消息的队列中,如果消息出现异常,那么就会将消息转移到死信队列中
②创建一个新的消费者来监听死信队列,这个消费者中的业务逻辑就不能包含处理异常消息的代码了,一般到了监听死信队列的情况下,再往后就得需要人工干预了!
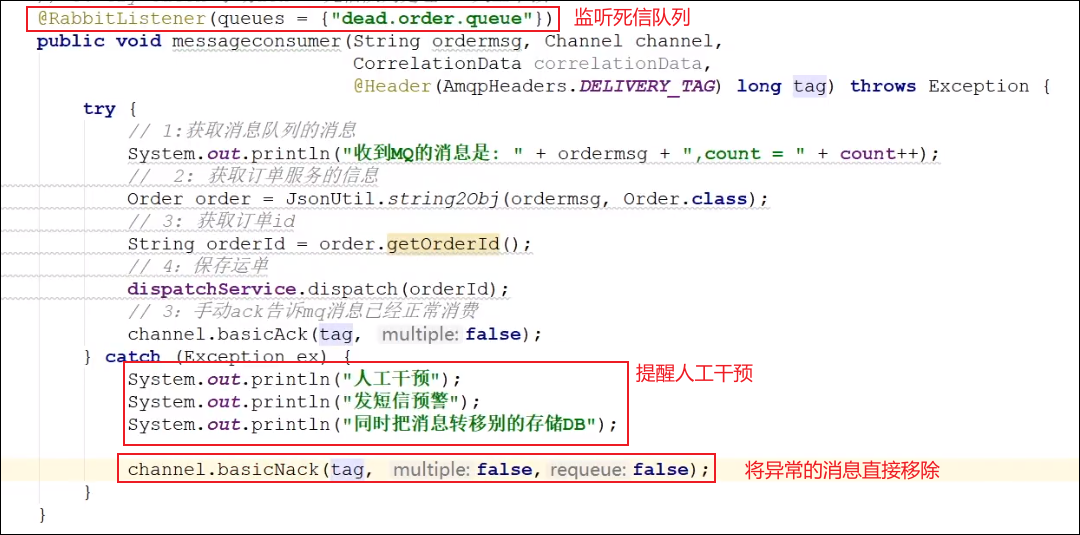
③还需要考虑数据的幂等性,就是要保证数据在数据库中不被重复添加
直接把订单号设置成主键,这样主键就一定是唯一的啦!
或者是使用分布式锁!
至此,关于RabbitMQ解决分布式事务的问题介绍完毕,后续还会持续更新相关技术点,敬请期待~~~
版权归原作者 Be explorer 所有, 如有侵权,请联系我们删除。