
上期文章讲到了通过requests、BeautifulSoup库搭建简单的爬虫来获取“房天下”的基础房价数据. 如果你没有看上期, 请务必先阅读上期内容(传送门), 基础房价数据中我们只获取到了[“户型”, “面积”, “楼层”, “朝向”, “建成时间”, “经纪人”, “地址”, “单价”]这些指标, 尽管这些指标对样本有了一个初步、大概的描述, 但它们仅限于描述统计, 缺少协变量无法进一步探究房价的影响因素、时空变动、组成成分等等. 所以我们还需要得到某一在售商品房周边的情况, 例如下表所示的内容
一级行业分类二级行业分类美食中餐厅、外国餐厅、小吃快餐店、蛋糕甜品店、咖啡厅、茶座、酒吧、其他酒店星级酒店、快捷酒店、公寓式酒店、民宿、其他购物购物中心、百货商场、超市、便利店、家居建材、家电数码、商铺、市场、其他生活服务通讯营业厅、邮局、物流公司、售票处、洗衣店、图文快印店、照相馆、房产中介机构、公用事业、维修点、家政服务、殡葬服务、彩票销售点、宠物服务、报刊亭、公共厕所、步骑行专用道驿站、其他丽日美容、美发、美甲、美体、其他旅游景点公园、动物园、植物园、游乐园、博物馆、水族馆、海滨浴场、文物古迹、教堂、风景区、景点、寺庙、其他休闲娱乐度假村、农家院、电影院、ktv、剧院、歌舞厅、网吧、游戏场所、洗浴按摩、休闲广场、其他运动健身体育场馆、极限运动场所、健身中心、其他教育培训高等院校、中学、小学、幼儿园、成人教育、亲子教育、特殊教育学校、留学中介机构、科研机构、培训机构、图书馆、科技馆、其他文化传媒新闻出版、广播电视、艺术团体、美术馆、展览馆、文化宫、其他医疗综合医院、专科医院、诊所、药店、体检机构、疗养院、急救中心、疾控中心、医疗器械、医疗保健、其他汽车服务汽车销售、汽车维修、汽车美容、汽车配件、汽车租赁、汽车检测场、其他交通设施飞机场、火车站、地铁站、地铁线路、长途汽车站、公交车站、公交线路、港口、停车场、加油加气站、服务区、收费站、桥、充电站、路侧停车位、普通停车位、接送点、其他金融银行、ATM、信用社、投资理财、典当行、其他房地产写字楼、住宅区、宿舍、内部楼栋、其他公司企业公司、园区、农林园艺、厂矿、其他政府机构中央机构、各级政府、行政单位、公检法机构、涉外机构、党派团体、福利机构、政治教育机构、社会团体、民主党派、居民委员会、其他出入口高速公路出口、高速公路入口、机场出口、机场入口、车站出口、车站入口、门(备注:建筑物和建筑物群的门)、停车场出入口、自行车高速出口、自行车高速入口、自行车高速出入口、其他自然地物岛屿、山峰、水系、其他行政地标省、省级城市、地级市、区县、商圈、乡镇、村庄、其他门址门址点、其他
注:以上指标体系来源于百度云计算平台
回顾上期的爬虫代码, 其中存在着诸多的问题和bug, 因此这次采取了分片区爬取的方式, 之所以要采取这种策略是因为作者发现如果在全区域内搜索在售的商品房,爬取到的样本分布非常的集中, 没有能够很好的覆盖整个乌鲁木齐各区, 如下图所示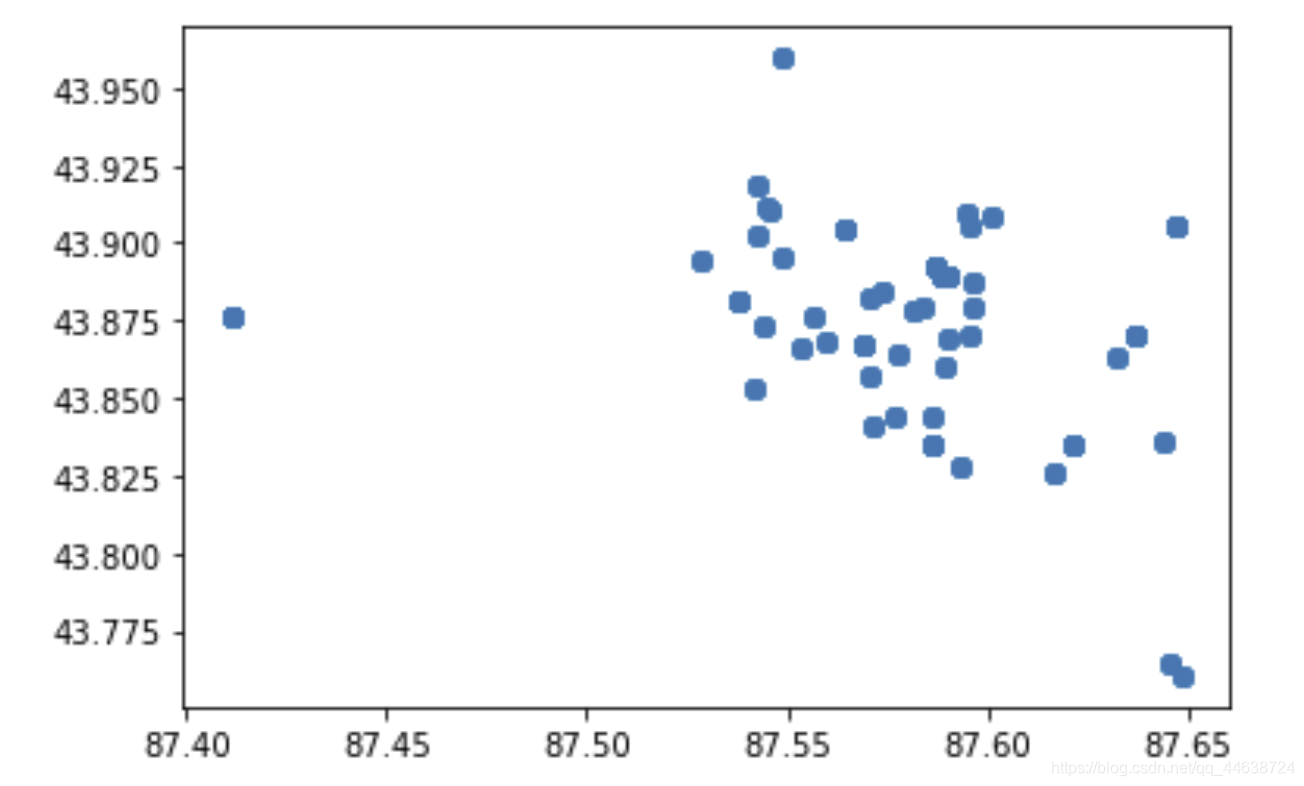
可以看到爬取到的样本点大多集中在一处, 导致了大量的重复(即使在爬取的过程中设置了随机爬取当前的样本, 各大跨度的翻页). 如果我们采用分区域的爬取方式, 那么样本的分布就如下图所示: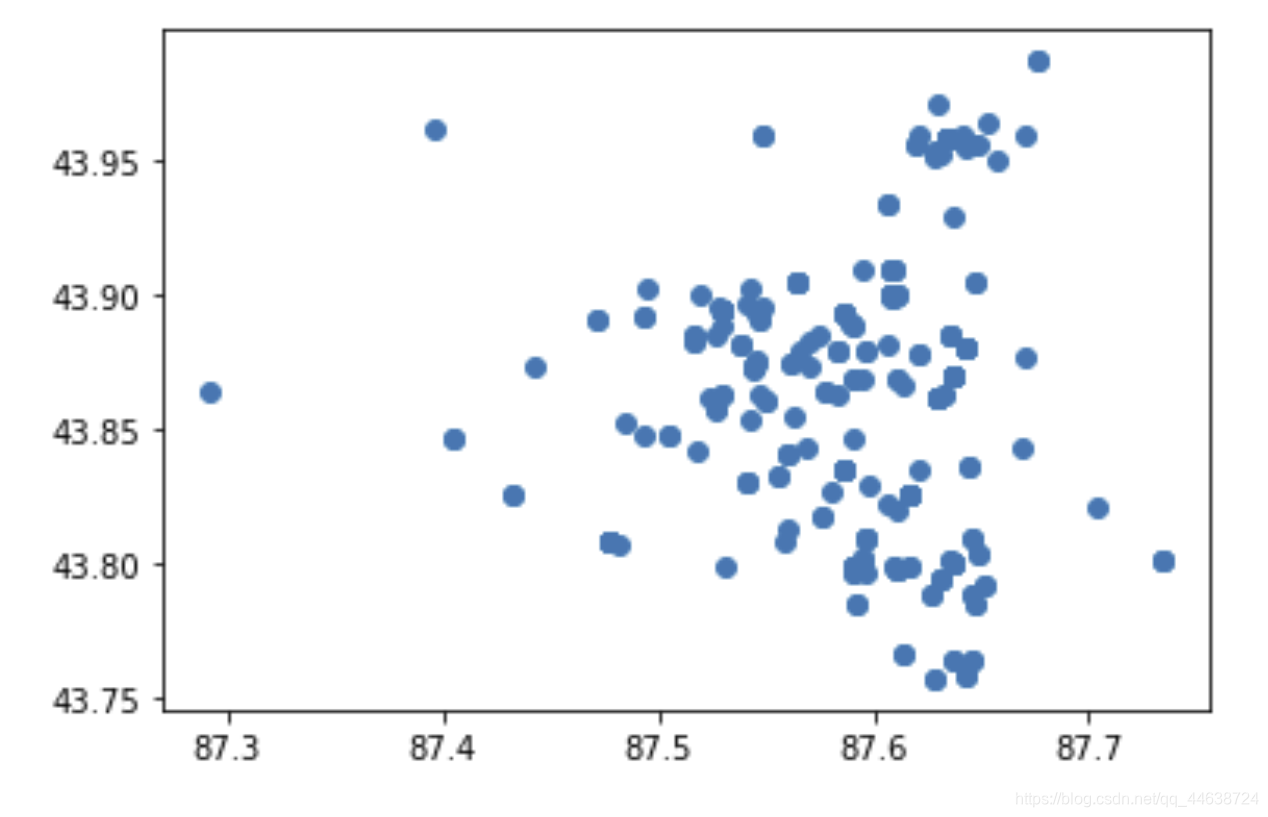
可以看到这种策略下的样本分布结果要分散的多, 覆盖面更广.
- 新市区
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time #这个库很重要from tqdm import tqdm #这是一个可以生成进度条的库, 小巧实用: pip install tqdm 即可
headers ={'User-Agent':
'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
url ="https://xj.esf.fang.com/house-a011523/"#由于需要分区爬取, 所以与上期的url不同
attrs =["户型","面积","楼层","朝向","建成时间","经纪人","地址","单价"]
df_xsq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]#跳转页面的解码, 详细可看(上)期内容
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"33"+"?"+ var_t3 #这里的33是当前爬取的页数, 如果你认为这一页的爬虫结果不好, 就可以选择更改这个数值. 目前已知 31<=页数<=60, 下同.print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i in tqdm(range(n)):#tqdm是创建进度条try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_xsq.loc[i]= info
except:passprint(i/n,end="")print("爬取完毕!")
df_xsq.drop_duplicates(subset=["地址"], keep='first')
当我们限定了爬虫结果的格式时( [“户型”, “面积”, “楼层”, “朝向”, “建成时间”, “经纪人”, “地址”, “单价”]), 采用
t
r
y
,
e
x
c
e
p
t
\rm{try,except}
try,except的结构能够很好的跳过不符合我们规定格式的样本, 因为这种小规模爬虫的效率已经足够高, 与其费尽心思调整每一个不符合格式的样本, 不如直接选择跳过.
也有朋友会认为经纪人这一指标无用, 实际上爬虫的结果通常无法避免大规模重复, 那我们我们就可以认当为两个样本的经纪人完全相同时即发生了重复, 从而进一步考虑删除重复的样本, 当然也可以通过两个样本的地址完全相同这一规则来删除重复(本文的做法)
- 沙依巴克区
url ="https://xj.esf.fang.com/house-a011522/"
df_sybkq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"33"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i inrange(n):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_sybkq.loc[i]= info
except:passprint((i+1)/n,end="")print("爬取完毕!")
df_sybkq.drop_duplicates(subset=["地址"], keep='first')
- 水磨沟区
url ="https://xj.esf.fang.com/house-a011524/"
df_smgq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"34"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i inrange(n):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_smgq.loc[i]= info
except:passprint((i+1)/n,end="")print("爬取完毕!")
df_smgq.drop_duplicates(subset=["地址"], keep='first')
- 头屯河区
url ="https://xj.esf.fang.com/house-a011525/"
df_tthq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"32"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i inrange(n):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_tthq.loc[i]= info
except:passprint((i+1)/n,end="")print("爬取完毕!")
df_tthq.drop_duplicates(subset=["地址"], keep='first')
- 米东区
url ="https://xj.esf.fang.com/house-a011526/"
df_mdq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"31"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i inrange(n):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_mdq.loc[i]= info
except:passprint((i+1)/n,end=" ")print("爬取完毕!")
df_mdq.drop_duplicates(subset=["地址"], keep='first')
- 天山区
url ="https://xj.esf.fang.com/house-a011521/"
df_tsq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"31"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i inrange(n):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_tsq.loc[i]= info
except:passprint((i+1)/n,end=" ")print("爬取完毕!")
df_tsq.drop_duplicates(subset=["地址"], keep='first')
- 开发区
from tqdm import tqdm
url ="https://xj.esf.fang.com/house-a013192/"
df_kfq = pd.DataFrame(columns=attrs)
n =100
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
tag = soup.find_all("script")[3]
a =str(tag).find("rfss")
var_t4 = url
var_t3 =str(tag)[a:a +28]
newUrl = var_t4 +"31"+"?"+ var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text,"html.parser")for i in tqdm(range(n)):try:
p = newSoup.find_all("dl",{"class":"clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p",{"class":"add_shop"})[i]#地址信息
info = p.text.replace("\t","").replace("\n","").split("|")#信息汇总(list)
price = newSoup.find_all("dd",{"class":"price_right"})[i]#单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df_kfq.loc[i]= info
except:passprint("爬取完毕!")
df_kfq.drop_duplicates(subset=["地址"], keep='first')
- 各区合并
holedf = df_xsq.append(df_kfq).append(df_tsq).append(df_sybkq).append(df_smgq).append(df_mdq).append(df_tthq).append(df_tsq)#这样写是为了易懂
- 重置标签与导出
holeDF = holedf.reset_index(drop=True)
holeDF.to_excel("D:\Desktop\jhk.xls",encoding="utf-8")
- 结果
 上图中包含了经度纬度信息, 由于上期已经详细讲过, 这里就省略不写了.
上图中包含了经度纬度信息, 由于上期已经详细讲过, 这里就省略不写了. - 借助百度开放平台来获取POI信息
import requests
from bs4 import BeautifulSoup
import json
import time
import pandas as pd
defPOI(query, location, radius, output):
d ={}'''
query = "银行"
location = "43.807,87.625"
radius = "2000"
output = "json"
coord_type = 3
page_size = 20
'''
coord_type =3
ak ="去百度地图开放平台申请并认证"
ak2 ="去百度地图开放平台申请并认证"
url ="https://api.map.baidu.com/place/v2/search?query="
api = url + query +"&location="+str(
location
)+"&radius="+ radius +"&output="+ output +"&coord_type="+str(coord_type)+"&page_size=20"+"&ak="+ ak
print(api)
re = requests.get(api)
r = re.json()return r
result =[]
total =[]
total_gw =[]
quary1 ="美食"
quary2 ="超市"
k =len(location)for i in tqdm(range(k)):try:print("正在查询第{0}条周边{1}信息".format(i,quary2))
poi = POI(quary2, location[i][0].split(',')[1]+","+ location[i][0].split(',')[0],"2000","json")
time.sleep(8)
name =[]
lat =[]
lng =[]
total_gw.append(poi["total"])for i inrange(len(poi["results"])):
name.append(poi["results"][i]["name"])
lat.append(poi["results"][i]["location"]["lat"])
lng.append(poi["results"][i]["location"]["lng"])
dd ={"name": name,"lat": lat,"lng": lng}
PD = pd.DataFrame(dd)except:
total.append(0)
- 与基本信息合并
 这样就在本文的示例中获取了两个POI数据
这样就在本文的示例中获取了两个POI数据
思考
可见爬取的最终结果中也存在着缺失值的情况, 需要进一步考虑如何解决.
版权归原作者 Infinity343 所有, 如有侵权,请联系我们删除。