
第1章 HBase 简介
1.1 什么是NoSQL数据库?
NoSQL(Not Only SQL)数据库是一类非关系型的数据库管理系统,用于存储和检索大量结构化或非结构化数据。与传统的关系型数据库(如Oracle、MySQL)相比,NoSQL数据库具有以下特点:
- 非结构化数据存储:NoSQL数据库可用于存储任意类型的数据,而不需要严格的预定义数据模式。这使得它们适用于存储半结构化和非结构化数据,例如文档、图形、键值对、JSON等。
- 水平可扩展性:NoSQL数据库通常采用分布式架构,可以水平扩展以应对大规模数据和高并发访问的需求。通过添加更多的节点,数据可以被分片存储,并实现负载均衡,从而提供更好的性能和可伸缩性。
- 高性能和低延迟:NoSQL数据库通常采用一些优化策略(如内存存储、索引等)来提供高性能的数据读写操作,并且通常能够在毫秒级别提供快速的数据访问。
- 弱一致性:相对于传统的ACID事务,NoSQL数据库更加注重可用性和分区容错性,可能在一些情况下放宽一致性要求,提供更高的可用性和性能。这种方式被称为BASE(Basically Available, Soft-state, Eventually Consistent)模型。
常见的NoSQL数据库类型包括:
- 文档数据库(Document Database):以文档为单位组织数据,常见的有MongoDB、Couchbase等。
- 键值存储(Key-Value Store):使用键值对的形式存储数据,常见的有Redis、Amazon DynamoDB等。
- 列族数据库(Column Family Database):按列族组织数据,适用于大规模数据分析,常见的有Apache Cassandra、HBase等。
- 图数据库(Graph Database):专用于存储图结构数据,适用于关系导向的数据操作,常见的有Neo4j、Azure Cosmos DB等。
1.2 HBase数据模型
HBase的设计理念依据Google的BigTable论文,数据模型:
Bigtable 是一个稀疏的、分布式的、持久的多维排序 map。
所谓 map 就是我们说的映射关系 Map<K,V>,这里的K是行键,V是列族。比如对于下面这张NoSQL表:
HBase的行键是按照字典序排序的,所以我们可以看到row_key1下一个不是row_key2而是row_11。
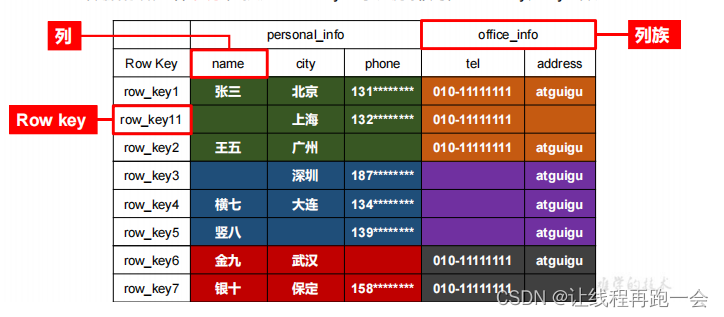
HBase可以表示多种结构的数据,比如JSON,它在HBase中是这样存储的:
{
"row_key1":{
"personal_info":{
"name":"zhangsan",
"city":"北京",
"phone":"131********"
},
"office_info":{
"tel":"010-1111111",
"address":"atguigu"
}
},
"row_key11":{
"personal_info":{
"city":"上海",
"phone":"132********"
},
"office_info":{
"tel":"010-1111111"
}
},
"row_key2":{
......
}
1.3 HBase的物理存储结构
HBase在底层只会存储非空的单元格数据,对于空的单元格是不会存储的。

- 我们知道,Hadoop的HDFS在存储数据的时候是只读不可修改的,因为它本身设计的初衷就是用来实现高吞吐量数据访问的,但是我们的HBase是支持修改的,并提供了低延迟的随机读写能力。
- HBase使用HDFS作为底层的存储,但在其之上实现了一套更完整的数据模型和操作接口,包括对数据的插入、更新、删除和查询等操作。
- HBase适用于需要快速随机读写的场景,例如实时分析、在线交易处理等。
对于上面HBase表格中的一条记录,它在底层中会存储为多行,行数取决于列族下面的列数以及修改的版本数。比如上图中,我们对张三的'phone'字段进行了修改,它并不会修改原有的单元格,而是直接新增一行,这样我们在读取的时候就可以读取到最新的数据了,而且可以通过版本号方便地回滚到特点时间点的数据状态。
尽管新增一行修改后的数据可能会增加存储空间的消耗,但在大规模数据和高吞吐量场景下,这种折衷方案可以提供更好的性能和可用性。
1.4 数据模型
1、Name Space
类似我们关系系数据库中的 database 的概念,每个命名空间下有多个表。
HBase 两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default表是用户默认使用的命名空间。
2、Table
类似于关系型数据库的表概念。不同的是,**HBase 定义表时只需要声明列族即可**,不需要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需指定。因此,和我们传统的关系型数据库相比,前者需要在创建表的时候就把所有表头的字段补充完整,但我们的HBase就不需要,因为它可以随时给列族添加新的列。
3、Row
HBase 表中的每行数据都由一个 **RowKey **和多个 **Column**(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4、Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5、Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入 HBase 的时间。
6、Cell
由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数据全部是字节码形式存贮。
1.5、HBase 基本架构
HBase 的核心架构由五部分组成,分别是 HBase Client、HMaster、Region Server、ZooKeeper 以及 HDFS。

1、HBase Client
HBase Client是指与HBase数据库进行交互的应用程序或库。HBase Client提供了一组API和工具,用于**连接、读取、写入**和操作HBase数据库中的数据。
2、Master
管理元数据表格(hbase: meta):接收用户对表格创建修改删除的命令并执行。
负载Region Server:监控 region 是否需要进行负载均衡,故障转移和 region 的拆分
3、Region Server
负责数据 cell 的处理,例如写入数据 put,查询数据 get 等。
拆分合并 region 的实际执行者,由 master 监控,由 regionServer 执行。
4、Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有 meta 表的位置信息。
HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper 的压力
5、HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
版权归原作者 让线程再跑一会 所有, 如有侵权,请联系我们删除。