
第一部分 HaDOOP基础知识
第1章 初识hadoop
1.1 面临的问题
存储越来越大,读写跟不上。
并行读多个磁盘。
问题1 磁盘损坏 – 备份数据HDFS
问题2 读取多个磁盘用于分析,数据容易出错 --MR 编程模型
1.2 衍生品
1 在线访问的组件是hbase 。一种使用hdfs底层存储的模型。支持单行的读写,对数据块读写也是不错的。
2 yarn 资源管理系统。允许其他分布式系统对hadoop集群数据运行。
迭代处理(iterative processing) spark.例如机器学习算法,需要很多迭代。mr不支持。sparK 可基于内存计算。
3 流处理 sTORM SPARKSTEMING
4 SEARCH 搜索 solr (Solr它是一种开放源码的、基于Lucene Java 的搜索服务器) 。
1.3 为什么不能用配有大量硬盘的数据库进行大规模分析?为什么需要Hadoop?
因为计算机硬盘的发展趋势是:寻址时间的提升远远不如传输速率的提升,如果访问包含大量地址的数据,读取就会消耗很多时间,
RDBMS B树是传统的数据库 ,适合更新一小部分数据。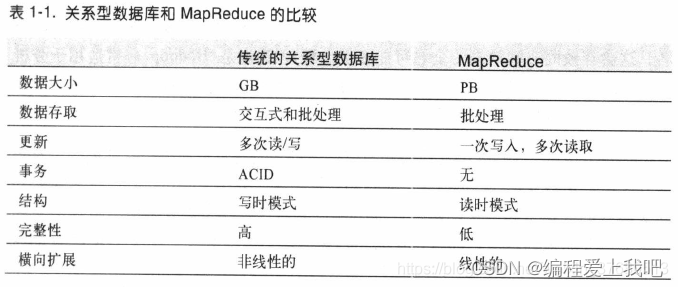
第2章 关于MapReduce
map ->shuffle->reduce
java api调用
map 和 reduce 输入都是 key 和value
中间的shuffle过程是不用我们来操作的,reduce直接写聚合的条件即可。
hadoop中带的数据类型 原因是网络序列化传输的基本类型
IntWritable 对应int
Text 对应 string
LongWritable 对应 long
map端
public class map extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer words = new StringTokenizer(value.toString());
while (words.hasMoreTokens()) {
word.set(words.nextToken());
context.write(word, one);
}
}
}
reduce
public class reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
result.set(count);
context.write(key, result);
}
}
driver 端
public class VoteCount extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(),new VoteCount(),args);
System.exit(res);
}
public int run(String[] args) throws Exception {
if (args.length !=2){
System.out.println("Incorrect input, expected: [input] [output]");
System.exit(-1);
}
Configuration conf = this.getConf();
Job job = new Job(conf, "word count");
job.setJarByClass(VoteCount.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(map.class);
job.setReducerClass(reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputValueClass(TextOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.submit();
return job.waitForCompletion(true) ? 1 : 0;
}
}
对于分片,合理是一个hdfs block128M,
每个分片1个map任务。
hadoop在存储有输入数据(hdfs中的数据)的节点上运行任务,可以获取最佳性能,因为没有使用带宽资源。这就是所谓的数据本地化优化。
map输出的中间结果是存储在本地,而不是hdfs。原因是无需副本,如果map中间结果传送给reduce失败,hadoop将在另一个节点上重新运行这个map任务以再次构建中间层结果。
reduce任务并不具备数据本地化的优势。原因,基本上都是多个map到达一个reduce上,然后存储的话是存储多个副本。一般不在1个机器上存储三个副本。
reduce有多个时,map会为每个reduce进行一个分区(partition) . 一般是根据key的hash。
combiner 二阶段聚合,目的是减少map 到reduce端到数据量传输。不能用于求平均。
cobinner 在driver中设置就可。代码和reduce代码差不多。
hadoop streaming使用unix标准作为Hapoop和应用程序之间的接口。所以我们可以使用任何编程语言通过标准输入/输出来写mapreduce程序。
版权归原作者 春风不会绿大地 所有, 如有侵权,请联系我们删除。