
Flink的TypeInformation以及序列化
TypeInformation主要作用是为了在 Flink系统内有效地对数据结构类型进行管理,能够在分布式计算过程中对数据的类型进行管理和推断。同时基于对数据的类型信息管理,Flink内部对数据存储也进行了相应的性能优化。
Flink 数据类型 & TypeInformation信息_flink typeinformation-CSDN博客
每一个具体的数据类型都对应一个TypeInformation的具体实现,每一个TypeInformation都会为对应的具体数据类型提供一个专属的序列化器。通过 Flink的序列化过程图可以看到TypeInformation会提供一个createSerialize()方法,通过这个方法就可以得到该类型进行数据序列化操作与反序化操作的对象TypeSerializer。
Flink 数据序列化_flink的序列化-CSDN博客
可以看出,TypeInformation在flink的序列化中起了很重要的作用
源码分析
Basic类型
Flink建议通过Pojo进行数据传入,如果传入的数据类型不满足Pojo条件或者不是Flink支持的基础类型,那么就会通过Kryo进行序列化,效率较低
 创建一个包含给定元素的新数据流。元素都必须是相同的类型
创建一个包含给定元素的新数据流。元素都必须是相同的类型
(先看基本类型的数据传入)
ctrl+左键点击进入

TypeExtractor:一种用于对类进行反射分析的实用程序,用于确定转换函数实现的返回类型。
初始化 TypeInformation 根据数据第一个元素进行判断返回类型
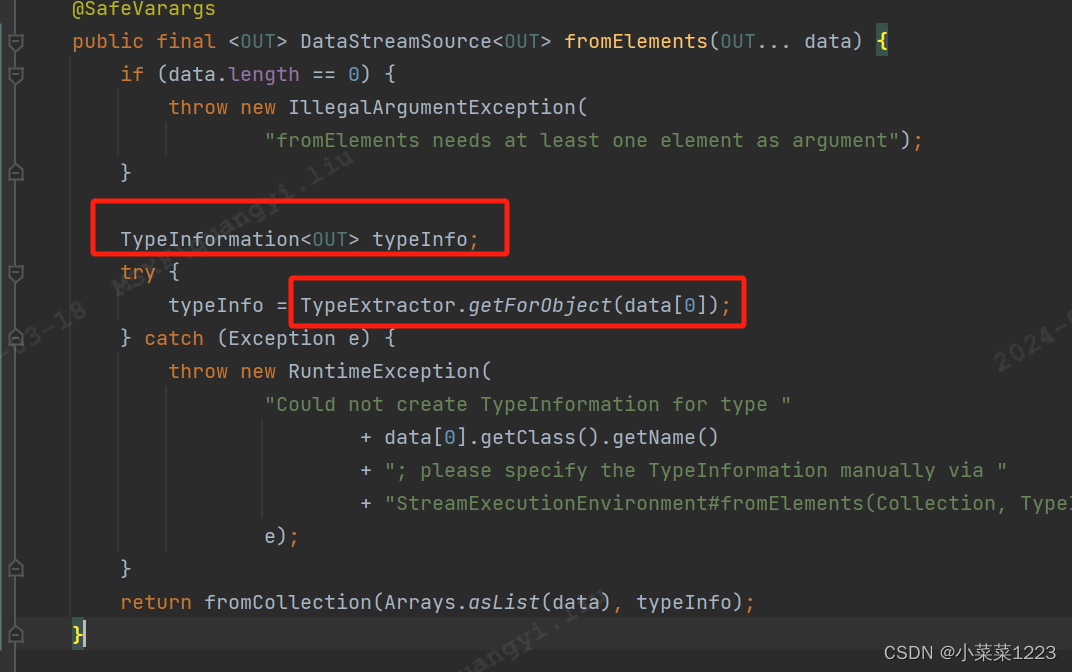
传入第一个元素
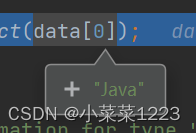
ctrl+左键点击红框方法进入
如果用于此类型或超类型,则使用工厂创建类型信息。否则返回null。
检查我们是否可以从元组中提取类型,否则使用该类

同上,如果是Row类型,则进入该代码块
 显然我们这次的例子是Basic 中的String类型,所以
显然我们这次的例子是Basic 中的String类型,所以 进入 privateGetForClass
进入 privateGetForClass
从给定的类(如Integer、String[]或POJO)中创建类型信息。

检查是否可以使用工厂生产类型信息

对象作为泛型类型信息处理,这里返回的 GenericTypeInfo 就是Flink定义的泛型类型的TypeInfo
如果类型满足,则返回泛型

如果类型为数组,则进入

如果类型为hadoop writable则进入

如果是Basic类型的一种,则命中
显然我们的String类型数据命中了Basic

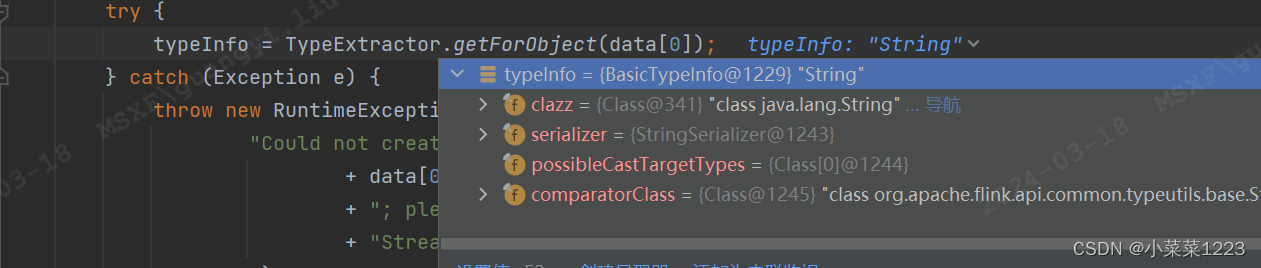
一路返回到 fromElements,typeInfo里的信息包含了选择序列化的类型
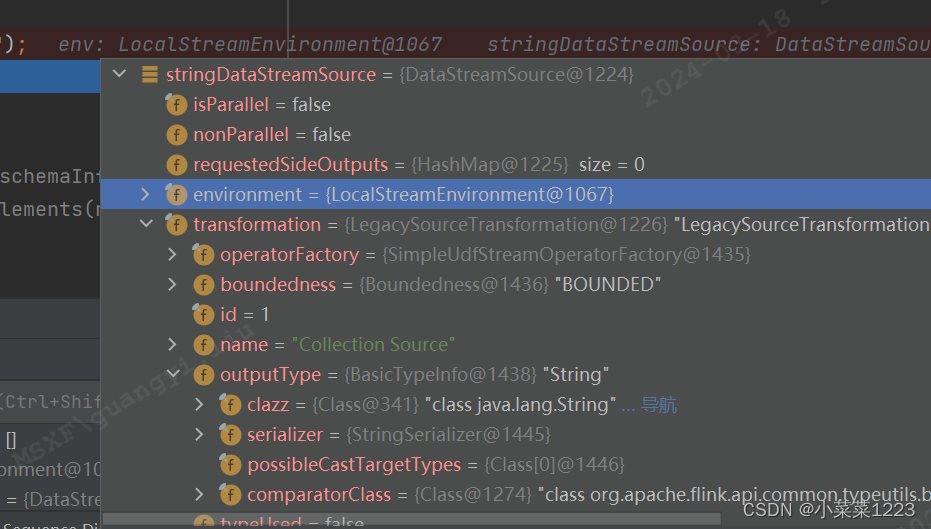
进入fromCollection:从给定的非空集合创建数据流。

不能有null元素和混合元素

最终返回的DataStreamSource数据,typeInfo数据被封装到了其中
Pojo类型
跟Basic类一样,一步一步进入到privateGetForClass

经过一堆判断,都没有命中后走到pojo类判断

判断必须是Public类型类
 不能全都是static或者transient字段
不能全都是static或者transient字段

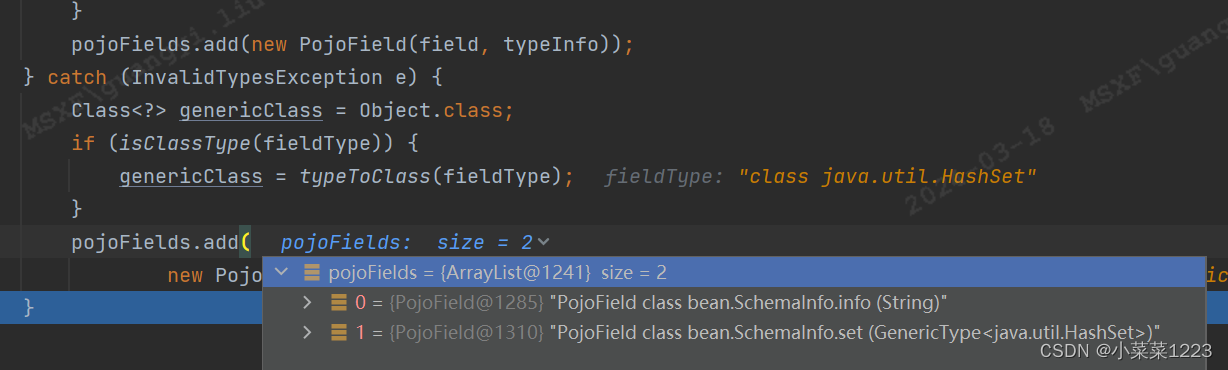
循环读取每个field,字段必须有Get、Set方法

每个字段创建对应的typeInfo添加到pojoFields
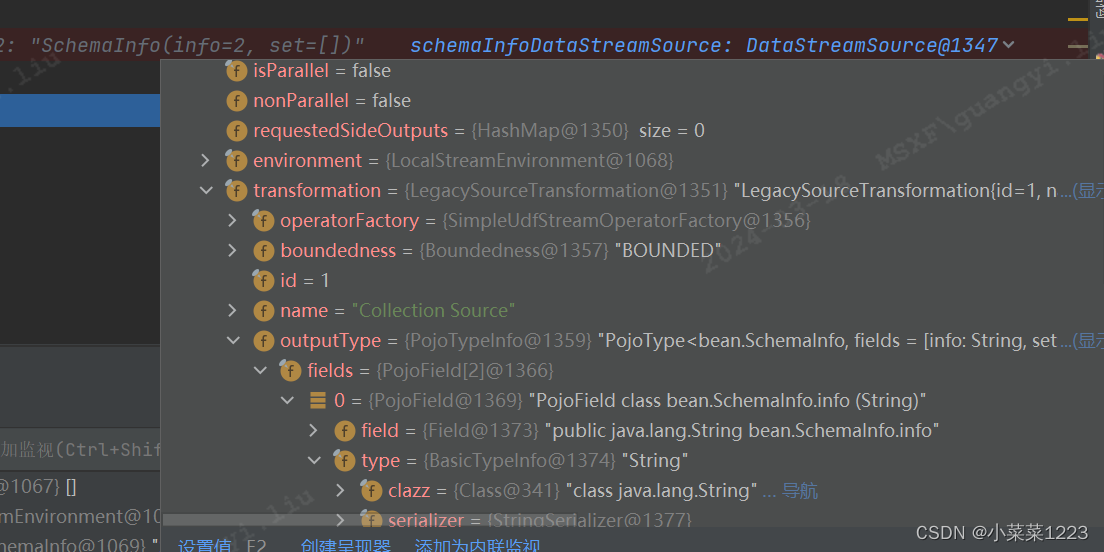
最后返回的DataStream,可以看到Pojo的每个字段以及字段对应的序列化类型都包装进去
版权归原作者 小菜菜1223 所有, 如有侵权,请联系我们删除。