
【MySQL系列】- Select查询SQL执行过程详解
文章目录
一、SQL查询语句的执行过程
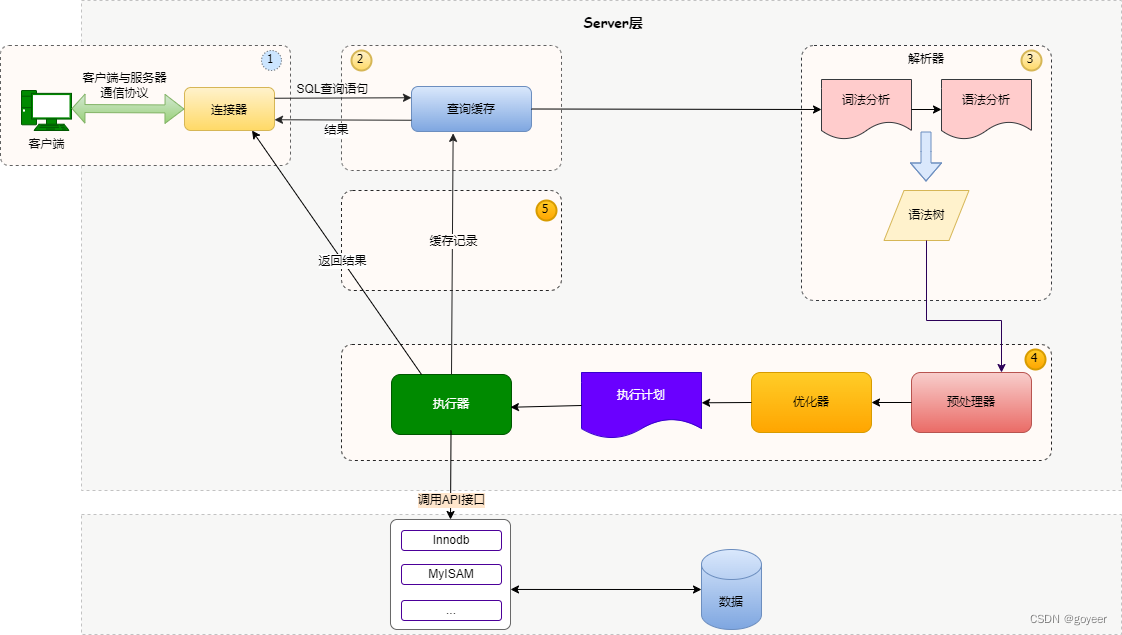
二、SQL执行过程详解
一条SQL语句从发送到数据并返回结果,主要经历以下几个过程:
- 连接器:
- 查询缓存:如果开启了查询缓存,则会经过这一步,但是大多数情况下都不是开启的,也不建议开启;MySQL8.0之后也删除了这一块功能。
- 分析器:
- 优化器
- 执行器
2.1. 连接器
如果想对MySQL进行操作,第一步建立数据库连接,这个过程就是连接器来完成的,它主要负责与客户端的通信,验证用户名和密码是否正确等。大多数的应用系统会在第一次启动的时候建立好一定数量的数据库连接池,这个就是通过连接器与数据库提前建立好连接。
2.2. 查询缓存
开启了查询缓存,在select查询语句过来的时候会先到查询缓存看之前是不是执行过这条语句,查询缓存存储的数据是以键值对的形式进行存储(类似与Map),key就是查询的SQL语句,VALUE是查询的结果。由于查询缓存这一块那么重要而且MySQL8.0之后也删除了。
2.3. 分析器
对客户端传过来的SQL进行分析,包括预处理与解析过程,并进行关键词的提取、解析,并组成一个解析树。主要提取如/
update
/
delete
/
or
/
in
/
where
/
group by
/
having
/
count
/
limi
t等这个的关键词。
select * from user where id=1
例如这样的一条语句,在分析器中就通过语义规则器将select from where这些关键词提取和匹配出来,将用户的匹配字段和自定义语句识别出来,这个阶段也会做一些校验,比如效验user表是否存在,表中是否有id字段等。
2.4. 优化器
经过前面的步骤,数据库已经知道SQL可以执行了,接下来优化器会根据执行计划选择最优的选择,匹配合适的索引,选择最佳的方案。
2.5. 执行器
执行器会调用对应的存储引擎执行 sql。主流的存储引擎是MyISAM 和 Innodb。
三、undo log 和 redo log作⽤
3.1. redo log (重做日志)
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
redo log什么时候产生?
事务开始之后就产生redo log,redo log的落盘并不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo log文件中。
redo log什么时候删除?
当对应事务的脏页写入到磁盘之后,redo log的使命也就完成了,redo log占用的空间就可以被重用(被覆盖)。
3.2. undo log(回滚日志)
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
undo log什么时候产生
事务开始之前,将当前数据的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性。
undo log什么时候删除
当事务提交之后,undo log并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
undo log 和redo log 主要用来保证事务相关操作,除此之外还有binlog(二进制日志,用于主从复制和基于时间点的还原等)、errorlog(错误日志)等
四、脏页是什么?何时刷新脏页
4.1 mysql脏页
当内存数据页和磁盘数据页上的内容不一致时,我们称这个内存页为脏页,内存数据写入磁盘后,内存页上的数据和磁盘页上的数据就一致了,我们称这个内存页为干净页。
4.2 刷脏页的时机
- redo log写满时,没有空间了,此时需要将checkpoint向前推进,推进的这部分日志对应的脏页刷入到磁盘,此时所有的更新全部阻塞,写的性能变为0,必须待刷一部分脏页后才能更新。
- 系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘。
- MySQL认为空闲的时候进行刷新。
- MySQL正常关闭之前,会把所有脏页刷入磁盘。
五、sql优化或你做过哪些方面的优化
- 考虑where和order等涉及的字段上建立索引,当然索引不是越多越好,建的多影响更新、插入性能。
- 字段已经有索引了,则需要避免索引失效,如:避免对索引字段进行计算操作(如num+1等),避免使用函数,避免索引字段使用not,<>,!=,IS NULL,IS NOT NULL,LIKE等,同时要注意索引字段的顺序,遵循最左匹配原则。
- 避免使用DISTINCT,order等耗资源的操作
- select语句中避免使用select * from 使用明确的字段代替*号
- 多表关联查询时,数据量小的表在前,数据量大的表在后
- 针对复杂的SQL语句,考虑拆分成多个单条语句,在业务上处理
六、包含子查询语句的SELECT语句的执行过程
- 解析SQL语句:将SQL语句解析成语法树,并对语法树进行语义分析。语法树是一个树状结构,它将SQL语句中的各个元素按照一定的规则组织起来,以便数据库引擎进行处理。
- 执行子查询:对子查询进行解析和语义分析,并生成子查询的结果集。子查询是一个嵌套在外部查询中的查询,它可以返回一组值,这组值可以作为外部查询的过滤条件或计算条件。子查询可以是一个SELECT语句、一个表达式、一个常量或者一个函数调用。子查询的执行过程类似于普通的SELECT语句的执行过程,也需要进行解析、优化和执行。数据库引擎会首先解析子查询,然后生成执行计划,最后执行查询并返回结果集。如果子查询中包含其他子查询,则需要按照嵌套的层次依次执行。子查询的结果集可以存储在内存或者磁盘中,以便后续查询操作快速访问。
- 执行外部查询:使用子查询的结果集进行处理,生成一个临时的虚拟表格。该表格包含了所有符合外部查询条件的行和子查询结果集中的所有行。外部查询可以使用该虚拟表格进行排序、分组、聚合等操作。如果外部查询中包含了GROUP BY、HAVING、ORDER BY、DISTINCT等关键字,那么在处理过程中需要对临时表格进行分组、聚合、排序等操作。
- 返回结果集:将临时表格中的数据按照需要的顺序返回给用户。如果存在LIMIT限制,则只返回指定的行数。在返回结果集之前,数据库引擎还需要对结果集进行格式化,包括将日期、时间等数据类型转换成适当的格式,将NULL值转换成适当的表示方式等。
需要注意的是,在执行包含子查询语句的SELECT语句时,数据库引擎会优化查询计划,以提高查询性能。通常情况下,数据库引擎会将子查询的结果集存储在内存或者磁盘中,以便后续查询操作快速访问。另外,如果外部查询中的WHERE条件能够过滤掉大部分不符合条件的行,那么数据库引擎也会尽可能地减少扫描的数据量,以提高查询性能。
版权归原作者 goyeer 所有, 如有侵权,请联系我们删除。