
1.RabbitMQ的高性能解决方案
1.1 发布确认机制
RabbitMQ提供了3种生产者发布确认的模式:
- 简单模式(Simple Mode):生产者发送消息后,等待服务器确认消息已经被接收。这种模式下,生产者发送消息后会阻塞,直到收到服务器确认消息。如果服务器在确认消息前崩溃,生产者会重新发送消息。 同步等待确认,实现简单,但是吞吐量十分有限。
- 批量模式(Batch Mode):生产者发送一批消息后,等待服务器一次性确认这批消息已经被接收。这种模式相比简单模式有更高的吞吐量,因为确认是批量进行的。批量同步等待确认,实现简单,吞吐量较大,但是很难找出未确认的消息,其中一个失败后需要把一个批次都重试。
- 异步模式(Asynchronous Mode):生产者发送消息后,不会等待服务器的确认消息。而是通过回调函数来处理确认和错误信息。这种模式适用于对消息可靠性要求不高的场景,可以提高生产者的性能。 可靠性和性能最好,在出现未确认消息时容易处理,但是实现困难。
1.2 预取机制
RabbitMQ的默认分发方式是轮询分发,轮询分发的问题是会导致消费快的消费者空闲,消费慢的消费者一直干活。为了解决这个问题,RabbitMQ引入了不公平分发机制,可以把任务分发给空闲的消费者。
Channel channel = connection.createChannel();
channel.basicQos(1)
上面案例中方法basicQos的参数PrefetchCount(案例中等于1)是最大传输信息数,当消息由消费者消费完成之后,再次从Queue中获取消息,达到预取值。
- PrefetchCount = 0:轮询分发
- PrefetchCount = 1:不公平分发
- PrefetchCount > 1:设置不公平分发,并设置预期值
通过预取值的机制可以减少消费者与磁盘之间的交换次数,从而提升消费者的处理能力。
2. Kafka的高性能解决方案
2.1 批量发送
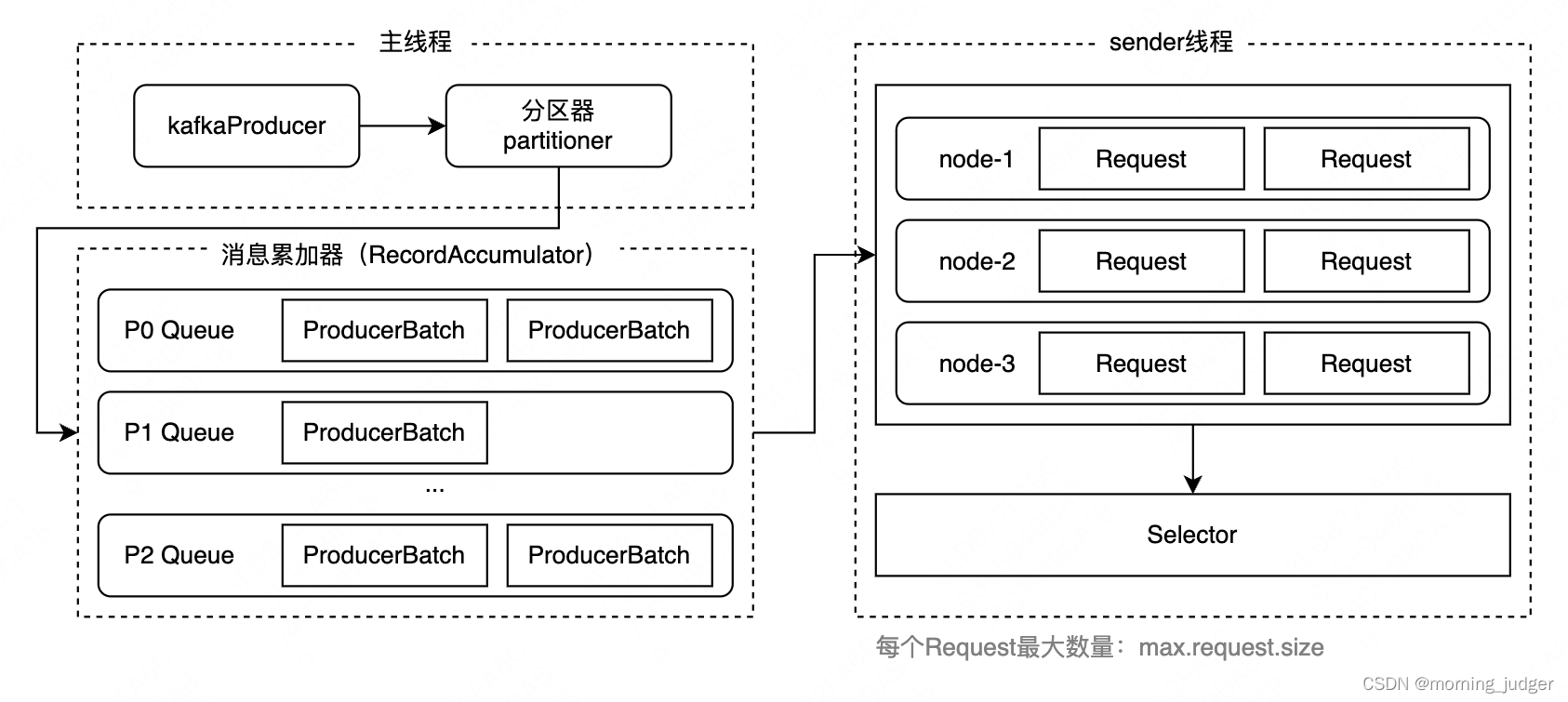
Producer会为每个Partition创建一个双端队列来缓存客户端的消息,队列中的每个元素是PorducerBatch,PorducerBatch的每个元素就是客户端要发送的Msg。
- KafkaProducer发送消息后,会先经过分区器判断发往哪个双端队列。
- 找到具体的双端队列后,先判断ProducerBatch是否已满,若满了则创建一个新的ProducerBatch,否则追加到以后的ProducerBatch中。
接下来sender线程工作机制是:
- 寻找ReadyNode:sender到消息累加器中轮询存在哪些Node已经准备好的ProducerBatch,只要一个Node有任何一个ProducerBatch准备好,这个Node就会被认为是ReadyNode。
- 创建Request:拿到所有的ReadyNode,寻找其中准备好的ProducerBatch,对于一个Node下的ProducerBatch打包成一个Request,其中一个Request最多包含的ProducerBatch由max.request.size控制。
- 发起通讯:然后每个Request通过Selector发起通讯。
sender把消息发送到Broker有两个条件:
- 消息大小达到阈值(通常为1M,可以由message.max.bytes控制)
- 消息发送等待时间达到阈值(默认为60000ms,可以由max.block.ms控制)
2.2 消息持久化
磁盘通查查询一条数据的过程如下:
- 磁头寻道:磁盘驱动器中的读写磁头会移动到指定的磁道上。磁道是磁盘表面的一个环形轨道,用于存储数据。
- 磁道选择:一旦到达正确的磁道,磁头会选择正确的扇区。扇区是磁道上的一个小块,用于存储数据。
- 磁头等待:一旦选择了正确的扇区,磁头会等待磁盘旋转到正确的位置。这是为了确保磁头在正确的时间读取或写入数据。
- 数据读取/写入:一旦磁盘旋转到正确位置,磁头会读取或写入数据。数据通过磁场变化在磁盘表面上进行存储和读取。
从上面的过程可以看出,如果我们查询/写入一条数据是随机在磁盘的一个位置,那么整个过程会比较耗时。对于Kafka来说,采用的策略是使用顺序IO,这样就可以避免寻址的过程,直接操作对数据的读/写操作。
2.3 零拷贝
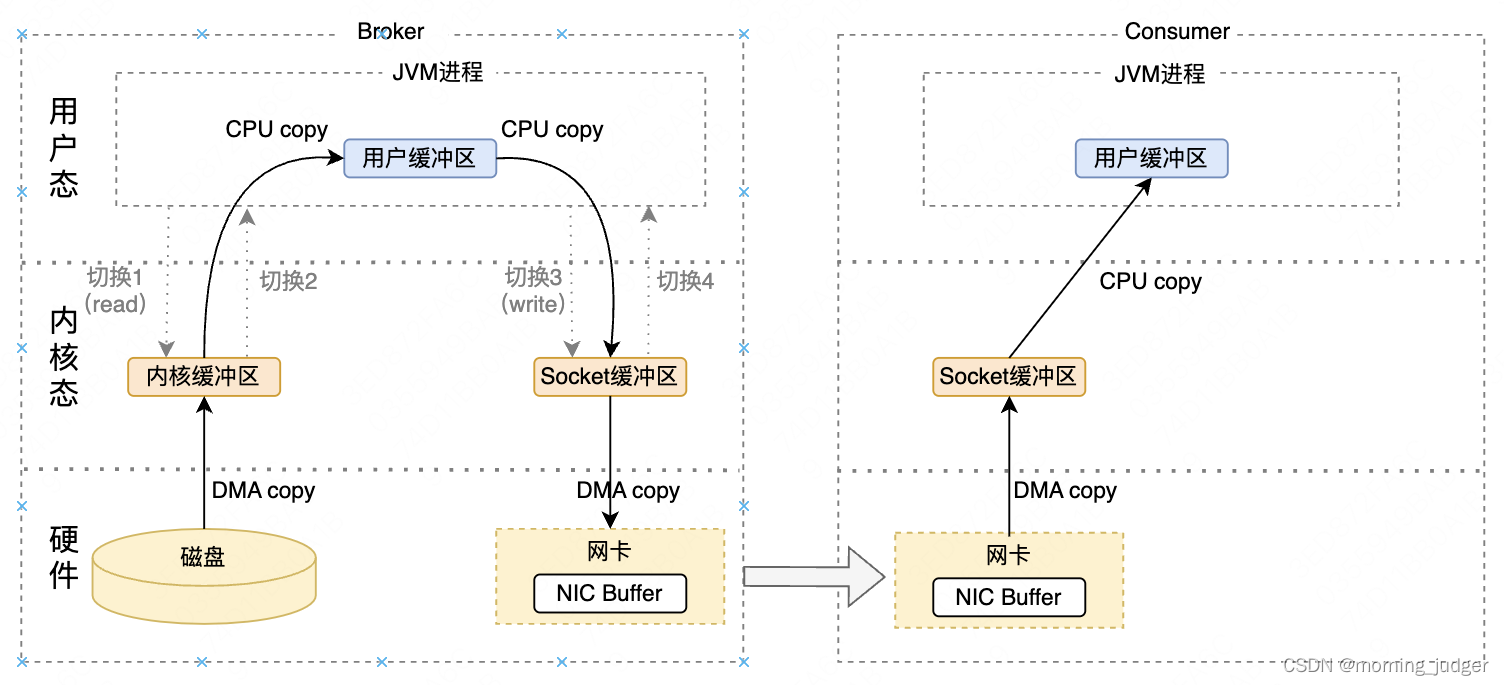
传统情况下,从磁盘读取数据,并通过网络发出去需要2次CPU copy和2次DMA copy:
- 数据读取过程:DMA执行了一次数据拷贝,数据从磁盘拷贝到内核空间。cpu再将数据从内核空间拷贝到用户空间(用户缓冲区)。
- 数据发送过程:cpu发生第三次数据拷贝,由cpu将数据从用户空间拷贝至内核空间(socket缓冲区),DMA执行第四次数据拷贝,将数据从内核空间写到网卡。
Linux2.4+的Linux系统支持了sendfile + DMA Gather:
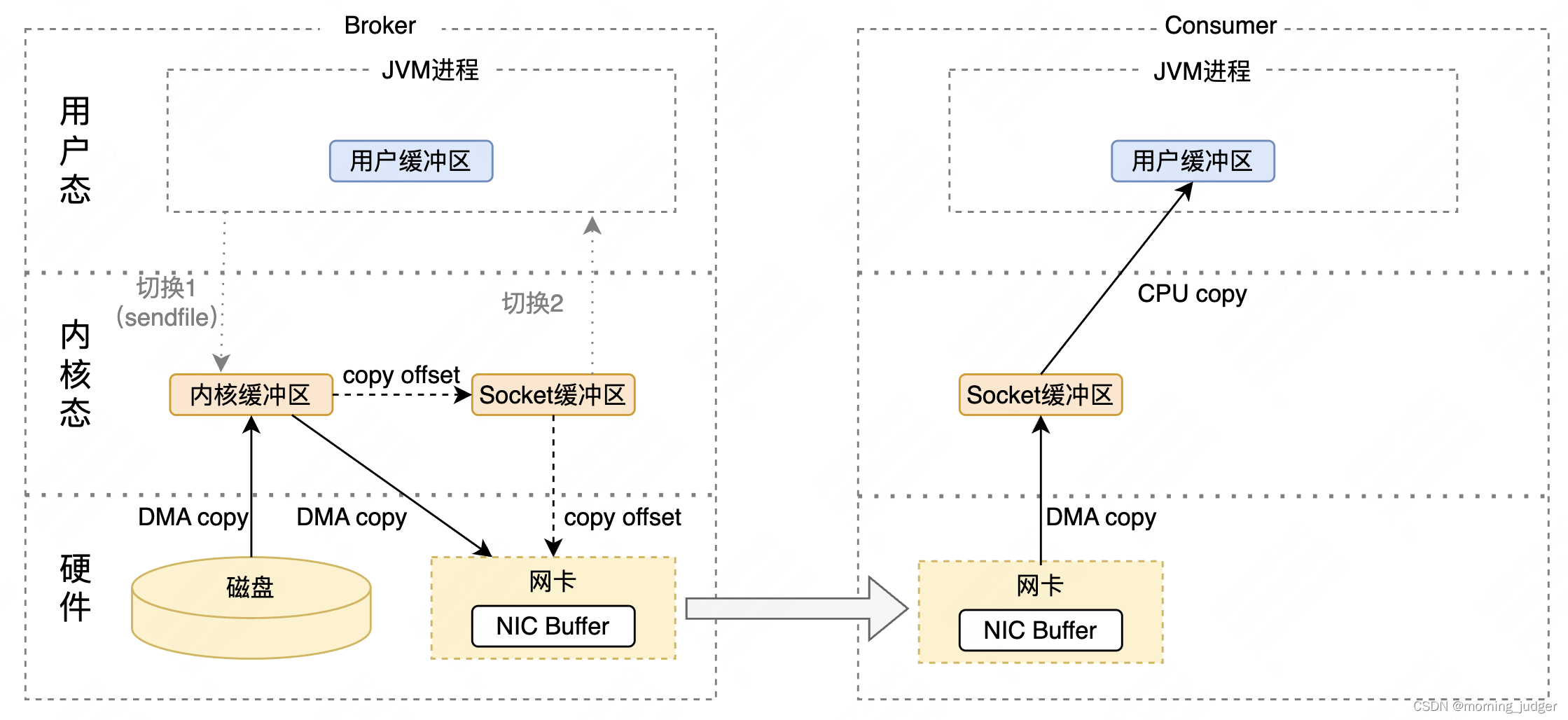
- 发起一次sendfile()系统调用,进行一次上下文切换,数据从磁盘DMA copy到内核缓冲区。
- 将内核缓冲区中带有文件位置、文件信息的缓冲区描述符copy到Socket缓冲区,然后借助DMA Gather真正的数据直接DMA copy到网卡。
这样只有两次上下文切换和两次DMA copy极大的减少了系统开支。
3.RocketMQ的高性能解决方案
3.1 异步机制
RocketMQ在高性能上与Kafka类似,使用异步、批量、零拷贝的机制,来实现高吞吐量。具体RocketMQ的异步机制如下:
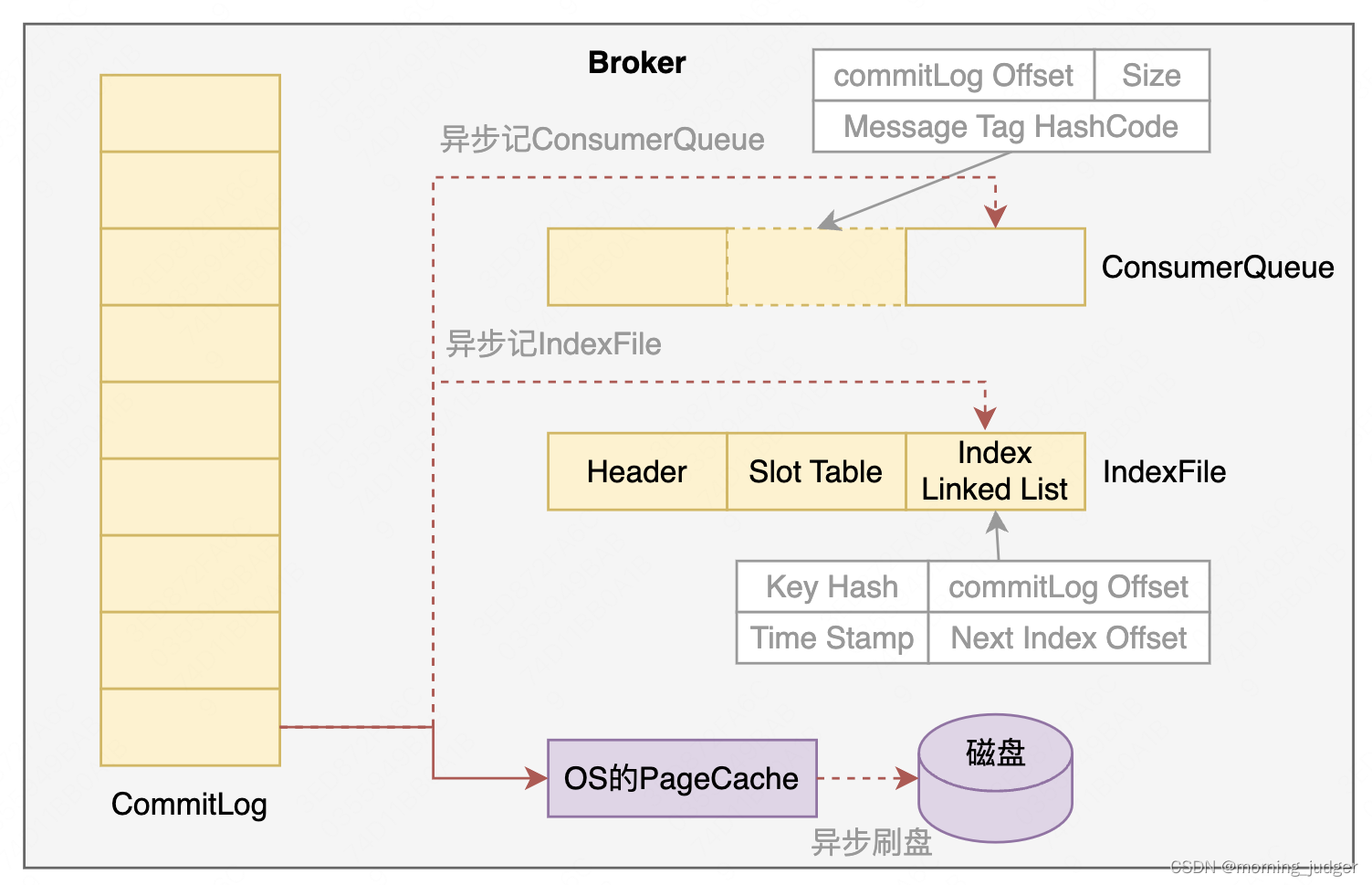
- 数据写入CommitLog:Broker接收来自Producer发出的消息,获取CommitLog最新offset,并往CommitLog对应ByteBuffer追加数据。
- 异步写磁盘:Broker通过同步/异步的方式写入到磁盘。若为异步写入磁盘,则是把数据写入OS的Page Cache就给Producer返回ACK,后台线程异步把Page Cache的数据写的磁盘。
- 异步复制:Broker通过同步/异步的方式进行Master/Slave之间的数据同步。若为异步复制,则是数据写入Master成功即视为成功,再后台异步同步至其他Slave。
- 异步写ConsumerQueue:后台线程轮询CommitLog的offset是否发生变化,若发生变化,则计算CommitLog对应消息的commitLog Offset、size、Message Tag HashCode写入ConsumerQueue。
- 异步写IndexFIle:写入ConsumerQueue后,再将消息Key Hash、commitLog Offset、TimeStamp、Next Index Offset写入到到IndexFile。
(在RocketMQ中使用的批量发送、零拷贝等机制在上面已讲过,不再重复陈述)
4. 参考文档
Kafka由浅入深(6) Sender线程执行源码解析_kafka sender源码解析_架构源启的博客-CSDN博客
Kafka全面学习_kafka学习_oraen的博客-CSDN博客
零拷贝技术----sendfile_socket 零拷贝_不吃树叶的树袋熊的博客-CSDN博客
kafka-生产者源码解析_kafka request.timeout.ms_SnaiI的博客-CSDN博客
RocketMQ源码分析之消息写入_rocketmq 写入 json数据_不爱学习的小妞的博客-CSDN博客
RocketMQ源码解读四 Broker写入数据_python 从mq写入文件_colspanprince的博客-CSDN博客
Java 两种zero-copy零拷贝技术mmap和sendfile的介绍_sendfile和mmap的比较_刘Java的博客-CSDN博客
多图详解 kafka 生产者消息发送过程_kafka生产者发送消息_Java程序V的博客-CSDN博客
Rabbitmq消息队列详解_rabbitmq查看消息队列_☜阳光的博客-CSDN博客
【RabbitMQ】Producer之publisher confirm、transaction - 基于AMQP 0-9-1_穿越在未来的博客-CSDN博客
spring-rabbit消费过程解析及AcknowledgeMode选择_acknowledge-mode_JinchaoLv的博客-CSDN博客
RabbitMQ持久化机制_琦彦的博客-CSDN博客
rabbitmq基础8——持久化、存储机制、ETS、队列结构、消息状态、内存告警、磁盘告警_rabbitmq存储机制_百慕卿君的博客-CSDN博客
从数据存储分析RocketMQ的高性能设计_rocketmq性能_怪兽靠边闪的博客-CSDN博客
RabbitMQ、RocketMQ和Kafka之间有什么性能差距?_mq性能对比_Java技术攻略的博客-CSDN博客
计算机操作系统(二十二):磁盘_操作系统 磁盘转速 扇区_BKSW.的博客-CSDN博客
零拷贝技术:mmap和sendfile_零拷贝mmap和sendfile_johnny233的博客-CSDN博客
版权归原作者 morning_judger 所有, 如有侵权,请联系我们删除。