
一、线程组
线程组元件是所有测试计划的入口。所有的取样器和控制器必须放在线程组下。一个线程组可以看作一个虚拟用户池,其中的每个线程都可以理解为一个虚拟用户,多个虚拟用户同时去执行相同的一批次任务。每个线程之间都是隔离的,互不影响的。一个线程的执行过程中,操作的变量不会影响其他线程的变量值。
线程组的界面如下图:

在线程组界面中可以设置以下数据,进行线程组的控制:
取样器错误后要执行的动作
这几个配置项控制了「当遇到错误的时候测试的执行策略」是否会继续执行。
- 继续:忽略错误,继续执行
- 启动下一进程循环: 忽略错误,线程当前循环终止,执行下一个循环。
- 停止线程:当前线程停止执行,不影响其他线程正常执行。
- 停止测试:整个测试会在所有当前正在执行的线程执行完毕后停止
- 立即停止测试:整个测试会立即停止执行,当前正在执行的取样器可能会被中断。
线程数
线程数也就是并发用户数,每个线程将会完全独立地运行测试计划,互不干扰。测试中使用多个线程用于模仿对服务器的并发访问。
ramp-up时间
ramp-up时间用于设置启动所有线程所需要的时间。例如:线程数设置为10,ramp-up时间设置为100秒,那么JMeter将使用100秒使10个线程启动并运行,每个线程将在前一个线程启动后的10秒启动。
如果ramp-up值设置得很小、线程数又设置得很大,刚开始执行测试时会对服务器产生很大的压力。
循环次数
设置结束前线程组中每个线程循环的次数。
延迟创建线程直到需要
默认情况下,测试开始的时候,所有线程就全部创建了。如果勾选了此选项,那么线程在需要用到的时候才创建。
线程组调度器
调度器配置可以更灵活地控制线程组执行的时间
(1)持续时间:控制测试执行的持续时间,以秒为单位。
(2)启动延迟:控制测试在多久后启动执行,以秒为单位。
二、取样器
取样器是用来模拟用户操作的,是向服务器发送请求、接收服务器响应数据的运行单元。取样器是包含在线程组内部的组件,因此它必须在线程组中添加。JMeter原生支持多种不同的取样器,如TCP取样器、HTTP请求、FTP请求、JDBC请求、Java请求等,每一种不同类型的取样器根据设置的参数向服务器发出不同类型的请求。
TCP取样器
TCP 取样器通过TCP/IP来连接指定服务器,连接成功后向服务器发送消息,然后等待服务器回复。
界面如图:

TCP取样器中可以设置的属性有:
1.TCPClient classname
表示处理请求的实现类。缺省使用org.apache.jmeter.protocol.tcp.sampler.TCPClientImpl, 使用普通文本进行传输。此外JMeter还内置支持BinaryTCPClientImpl和LengthPrefixedBinaryTCPClientImple, 前者使用十六进制报文,后者在BinaryTCPClientImpl的基础上增加了2个字节的长度前缀。
也可以通过继承org.apache.jmeter.protocol.tcp.sampler.TCPClient来提供自定义的实现类。
2.目标服务器设置
「服务器名称或IP」和「端口号」指定了服务器应用的主机名/IP地址和端口号。
3.连接选项
- Re-use connection:: 如果选中,这个连接会一直处于打开状态,否则读取到数据后就关闭。
- 关闭连接:如果选中,这个连接在TCP取样器运行完毕之后就会被关闭。
- 设置无延迟:如果选中,Nagle算法将被禁用,允许小数据包的发送。
- SO_LINGER:用于控制在关闭连接之前是否要等待缓冲区中的数据发送完成。
- 行尾 (EOL)字节值:用于判断行结束的字节值,如果指定的值大于127或者小于-128,会跳过EOL检查。比如服务器端返回的字符串都是以回车符结尾,那么我们可以将该选项设置成10
4.超时时间:
- Connect Timeout:连接超时
- Response Timeout:响应超时
5.要发送的文本
请求发送的报文文本
6.登陆配置
设置连接使用的用户名和密码
HTTP请求取样器
HTTP取样器向web服务器发送HTTP/HTTPS请求。
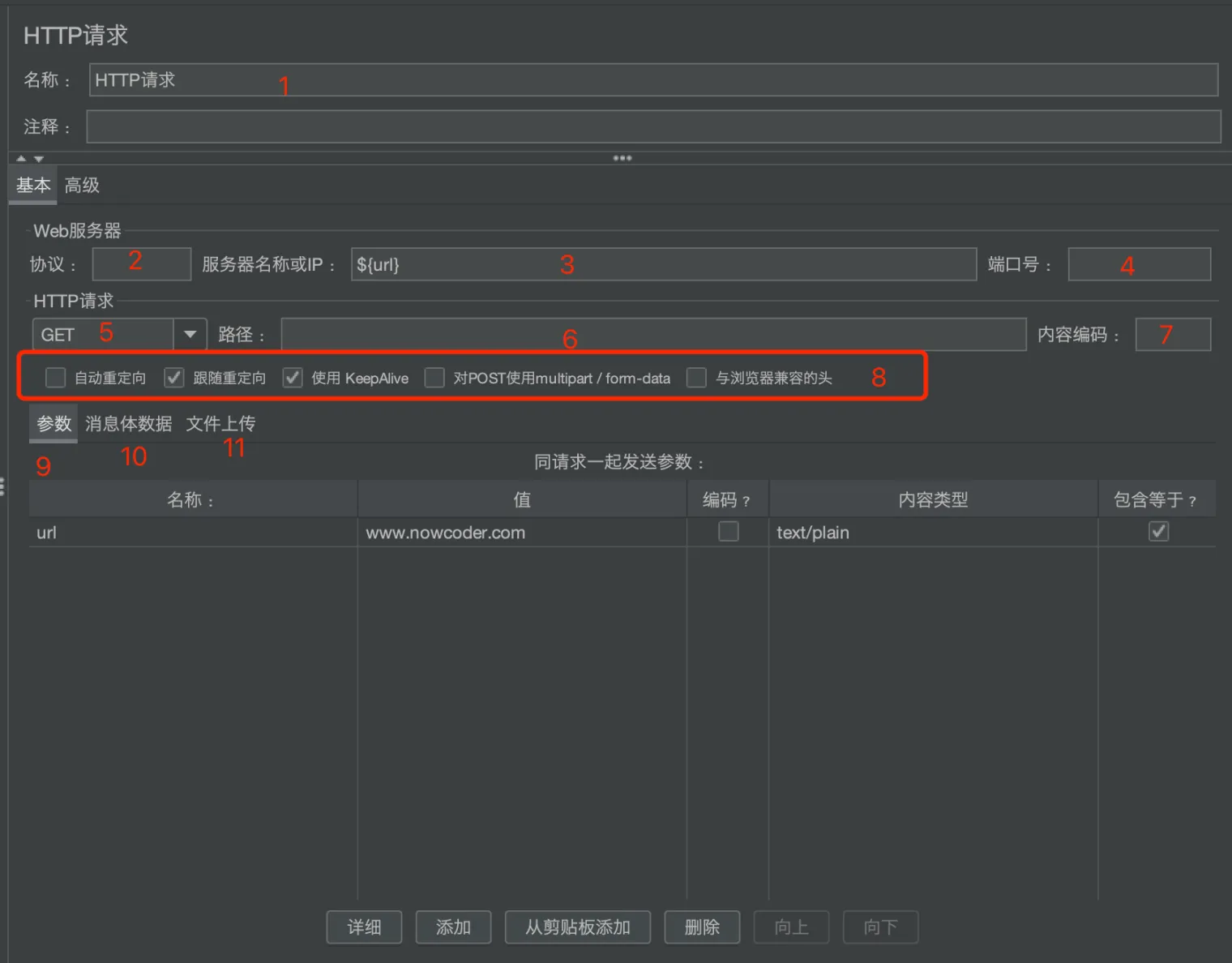
1.名称和注释
2 .请求协议
向目标服务器发送请求时使用的协议,可以是HTTP、HTTPS或FILE,默认为HTTP。
3.域名或IP地址
请求发送的目标服务器名称或IP地址。
4.端口号
Web服务监听的端口号,HTTP默认端口为80,HTTPS默认端口443。
5.请求方法
发送请求的方法,常用GET、POST、DELETE、PUT、TRACE、HEAD、OPTIONS等。
6 .路径
要请求的目标URL路径(不包括服务器地址和端口)。
7.内容编码
适用于POST、PUT、PATCH和FILE这几种请求方式,对请求内容进行编码的方法
8.更多请求选项
- 自动重定向:重定向不会被视为单独的请求,不被JMeter记录。
- 跟随重定向:每次重定向都被视为单独的请求,都会被JMeter记录。
- 使用KeepAlive:如果选中,JMeter和目标服务器之间通信时会在请求头中加入Connection: keep-alive。
- 对POST使用multipart/form-data:如果选中,将使用multipart/form-data 或 application/x-www-form-urlencoded发送请求。
9.参数
JMeter将使用参数键值对来生成请求参数,并根据请求方法以不同方法发送这些请求参数。例如:GET,DELETE请求,参数会附加到请求URL。
10.消息体数据
如果希望传输JSON格式的参数,需要在请求头中配置Content-Type为application/json
11.文件上传
在请求中发送文件,通常HTTP文件上传行为可以通过这种方式模拟。
三、逻辑控制器
JMeter 逻辑控制器可以对元件的执行逻辑进行控制,JMeter 官网是这样解释的:「Logic Controllers determine the order in which Samplers are processed」。也就是说逻辑控制器可以控制采样器(samplers)的执行顺序,因此控制器需要和采样器一起使用。除仅一次控制器外,其他逻辑控制器可以相互嵌套。
JMeter 中的逻辑控制器主要分为两类:
- 控制测试计划执行过程中节点的逻辑执行顺序,如:循环控制器、If 控制器等;
- 对测试计划中的脚本进行分组、方便 JMeter 统计执行结果以及进行脚本的运行时控制等,如:吞吐量控制器、事务控制器。
事务控制器
有时候我们想统计一组相关请求的的整体响应时间,这种情形就需要借助事务控制器。
事务控制器会对该控制器下所有子节点的取样器执行消耗时间进行统计。如果事务控制器下定义了多个取样器,所有取样器都运行成功时,整个事务才能算成功。
如下图添加事务控制器:

事务控制器的配置项有:
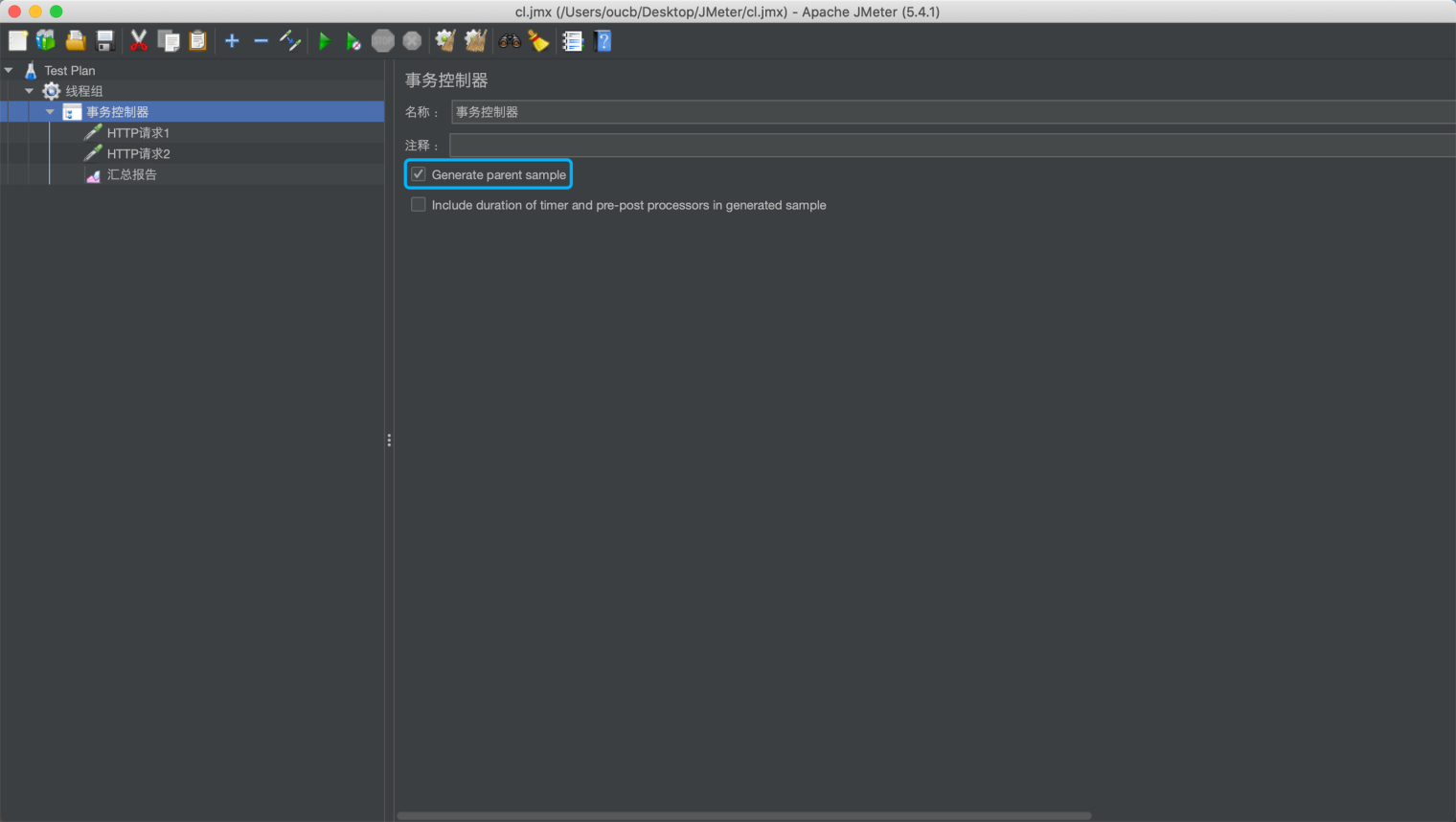
1.Generate parent sample
如果选中,事务控制器将作为其他取样器的父级样本,否则事务控制器仅作为独立的样本。
例如,未勾选情况下汇总报告如下:
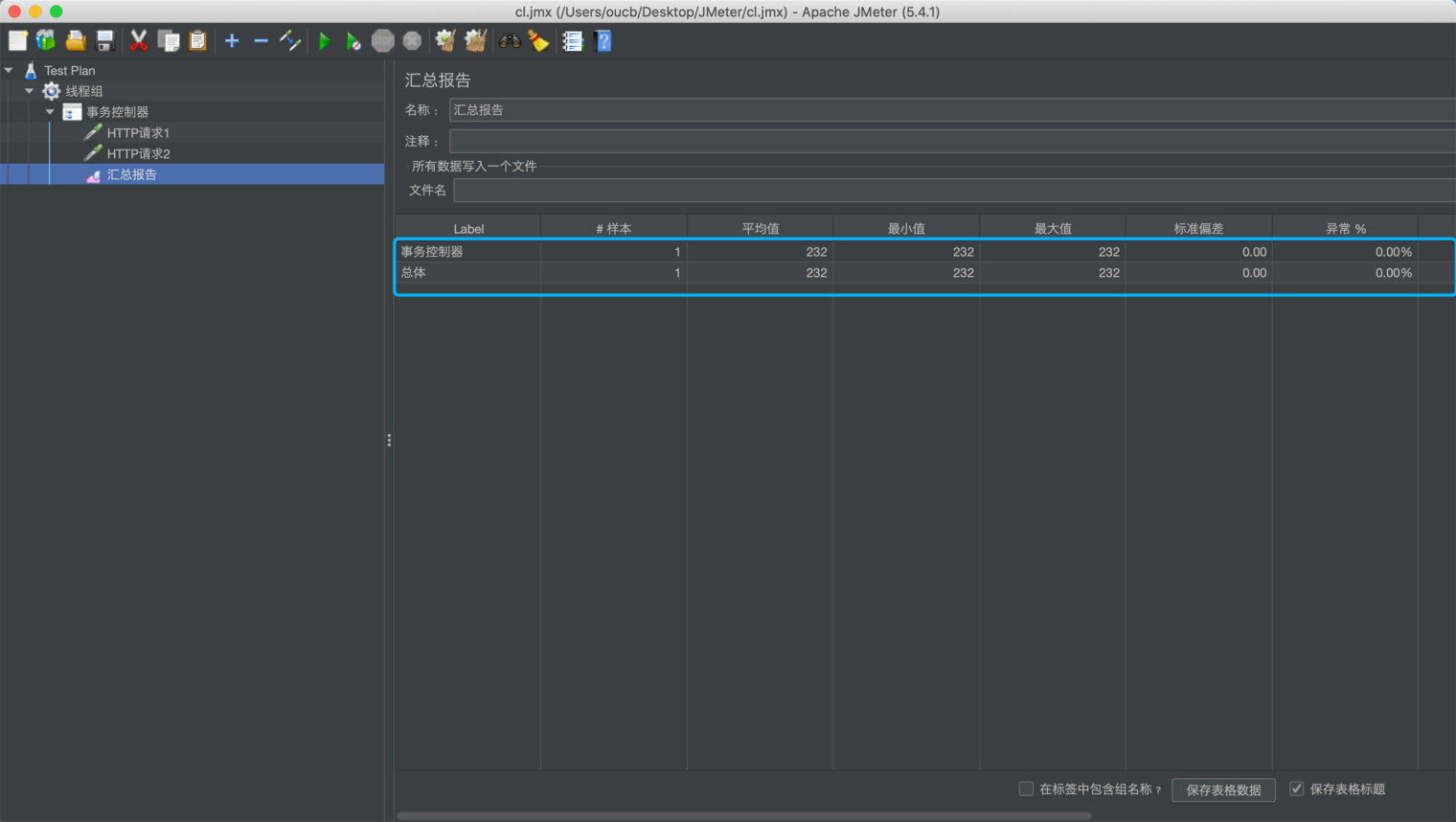
勾选情况下汇总报告如下:
2.include duration of timer and pre-post processors in generated samle:
指定是否包含定时器,如果勾选将在取样器运行前与运行后加上延时。
仅一次控制器
仅一次控制器,顾名思义就是只执行一次的控制器,即在线程组下的循环执行过程中对该控制器下的请求只执行一次。对于需要登录的测试,可以考虑将登录请求放在仅一次控制器中,因为登录请求只需执行一次即可建立会话。
如下图添加仅一次控制器:

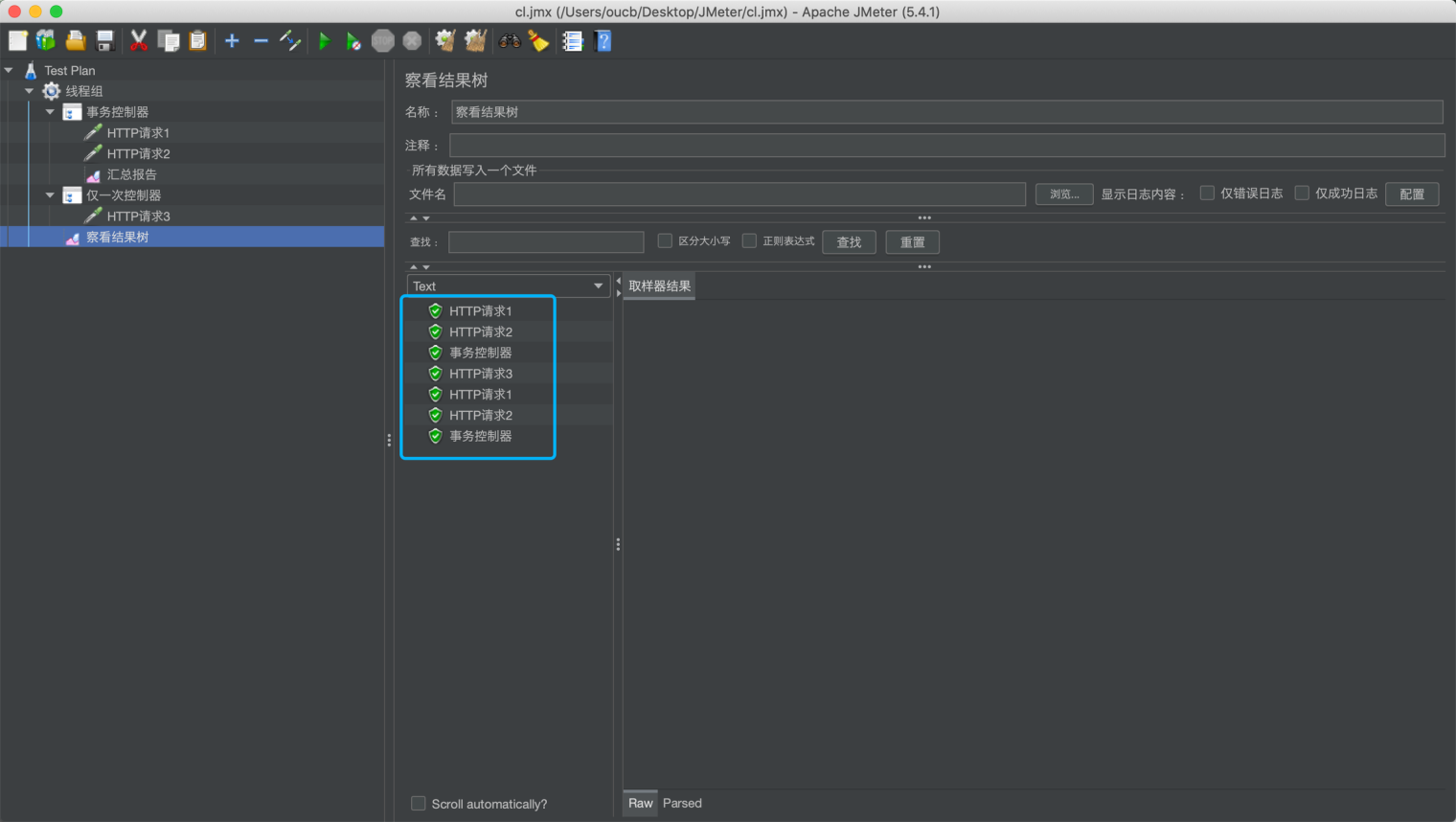
如果我们将线程组循环次数设置为 2,运行后查看结果树,可看到仅一次控制器下的请求“HTTP请求3”只执行了1次,其它请求执行了2次
四、监听器
监听器是用于对测试结果数据进行处理和可视化展示的一系列元件。察看结果树、 图形结果、聚合报告等都是我们经常用到的监听器组件。
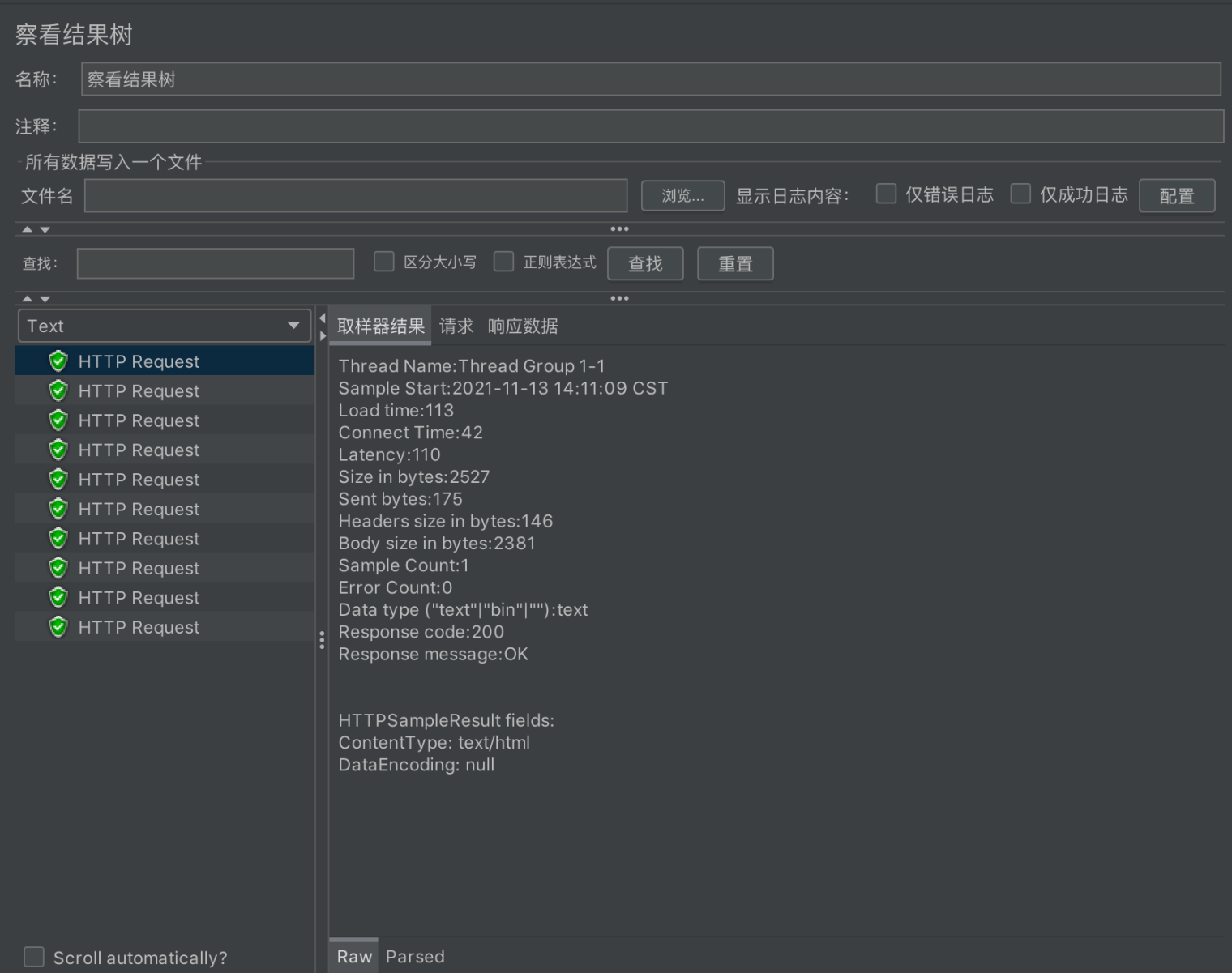
察看结果树
该组件以树形结构展示了每一个取样器的结果、请求内容、响应时间、响应码、响应内容等信息,查看这些信息可以辅助分析是否存在问题。它提供多种的查看格式和筛选方法,也可以将结果写入指定文件进行批量分析处理。
五、配置元件
配置元件用于提供对静态数据配置的支持。它可以定义在测试计划层级下,也可以定义在线程组或取样器层级下,定义在不同层级,作用域也不同。配置元件主要有用户自定义变量、CSV数据文件设置、TCP取样器配置、HTTP Cookie管理器等。
用户自定义变量
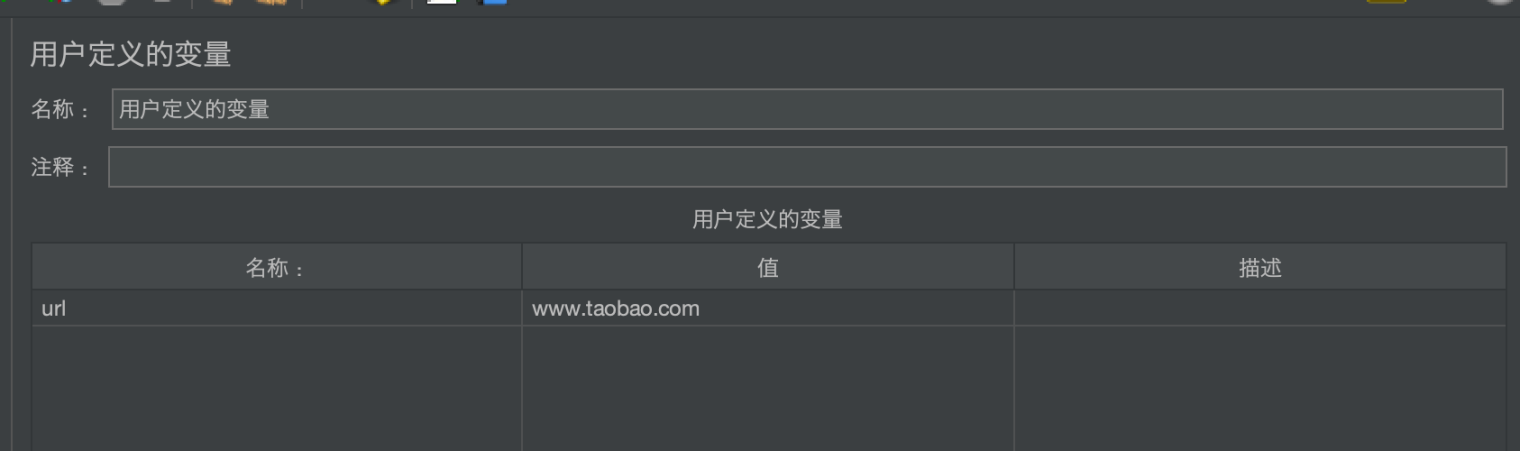
通过设置一系列的变量,达到在性能测试过程中可以随机选取变量的目的。变量名可以在作用域内引用,通过${变量名}方式来引用变量。
除了“用户自定义变量”这个组件外,测试计划和HTTP请求等多个组件中也可以定义变量:
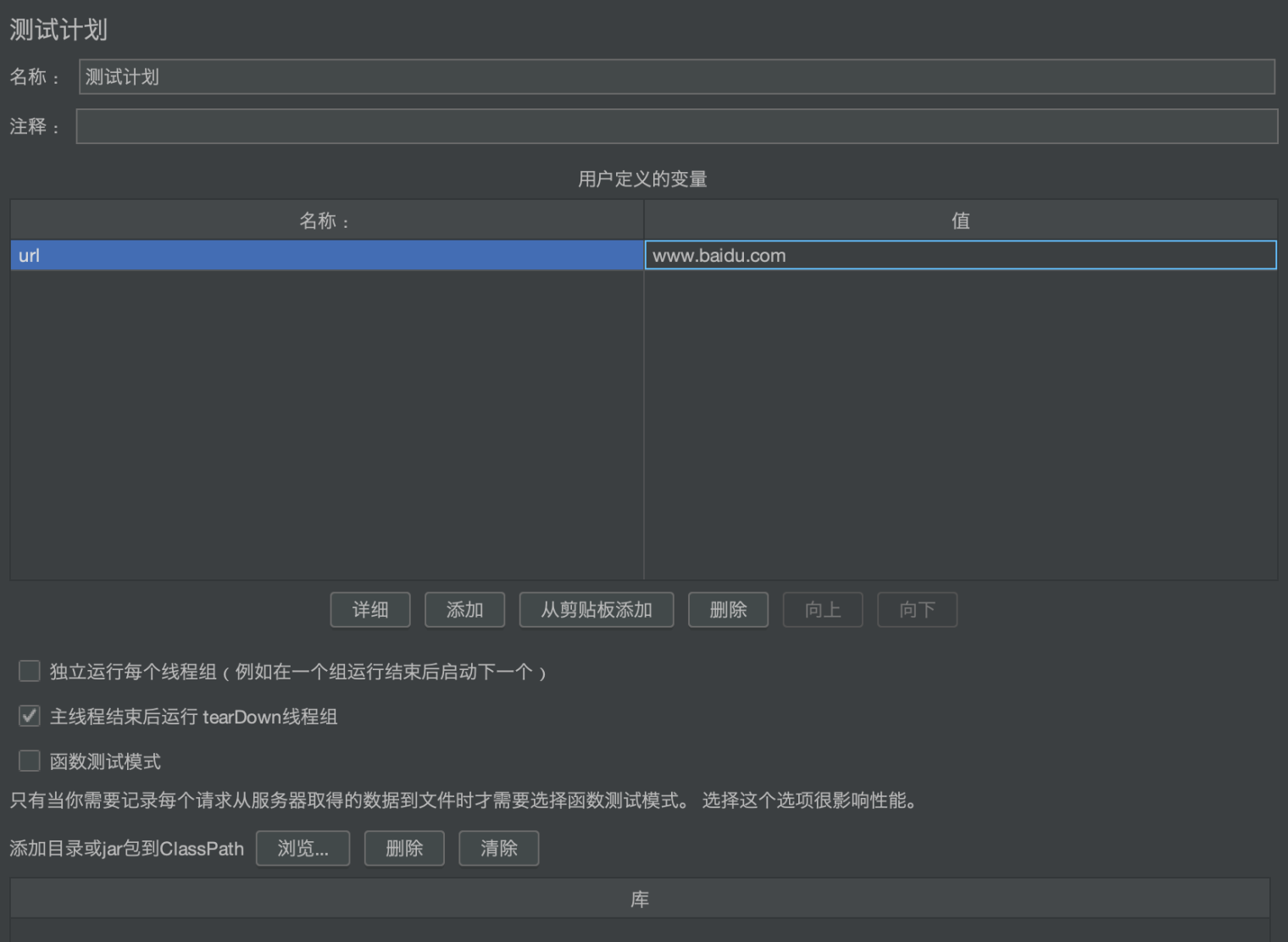
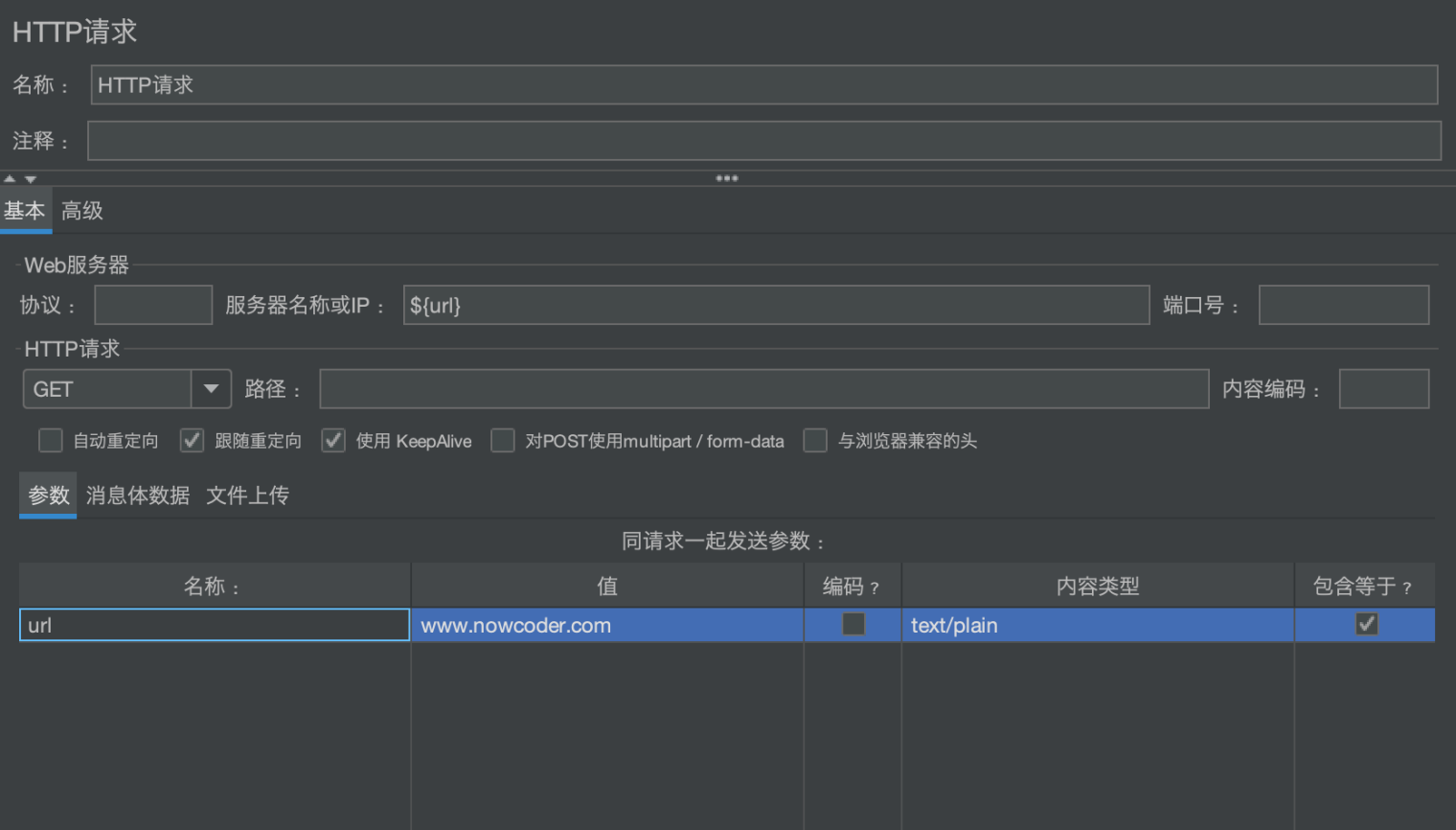
例如:在HTTP请求中引用了已定义的变量:

查看执行结果,能看到确实获取到了变量的取值:
CSV数据文件设置
在性能测试过程中我们往往需要一些参数化的输入参数,比如登录操作里面的用户名密码。当并发量比较大的时候 ,运行时生成数据会对CPU和内存造成较大的负担,而CSV数据文件配置可以作为这种场景下所需的参数来源。

CSV数据文件设置中部分参数的说明如下:
- 变量名称:定义CSV文件中的参数名,定义后可在脚本在以${变量名}的方式引用
- 遇到文件结束符再次循环:如果设置为True,允许对CSV文件循环取值
- 遇到文件结束符停止线程:如果设置为True,则读取完CSV文件中的记录后停止运行
- 线程共享模式:设置在线程及线程组间共享的模式
六、断言
断言即检查接口的返回是否符合预期。断言是自动化测试脚本中举足轻重的一环,因此要十分重视。
JMeter 常用断言主要有响应断言(Response Assertion)、JSON断言(JSON Assertion)、大小断言(Size Assertion)、断言持续时间(Duration Assertion)、beanshell 断言(Beanshell Assertion)等,这里我们只介绍经常要用到的 JSON断言。
JSON 断言
用于对 JSON 格式的响应内容进行断言。
下图在一个HTTP取样器上添加 JSON 断言:
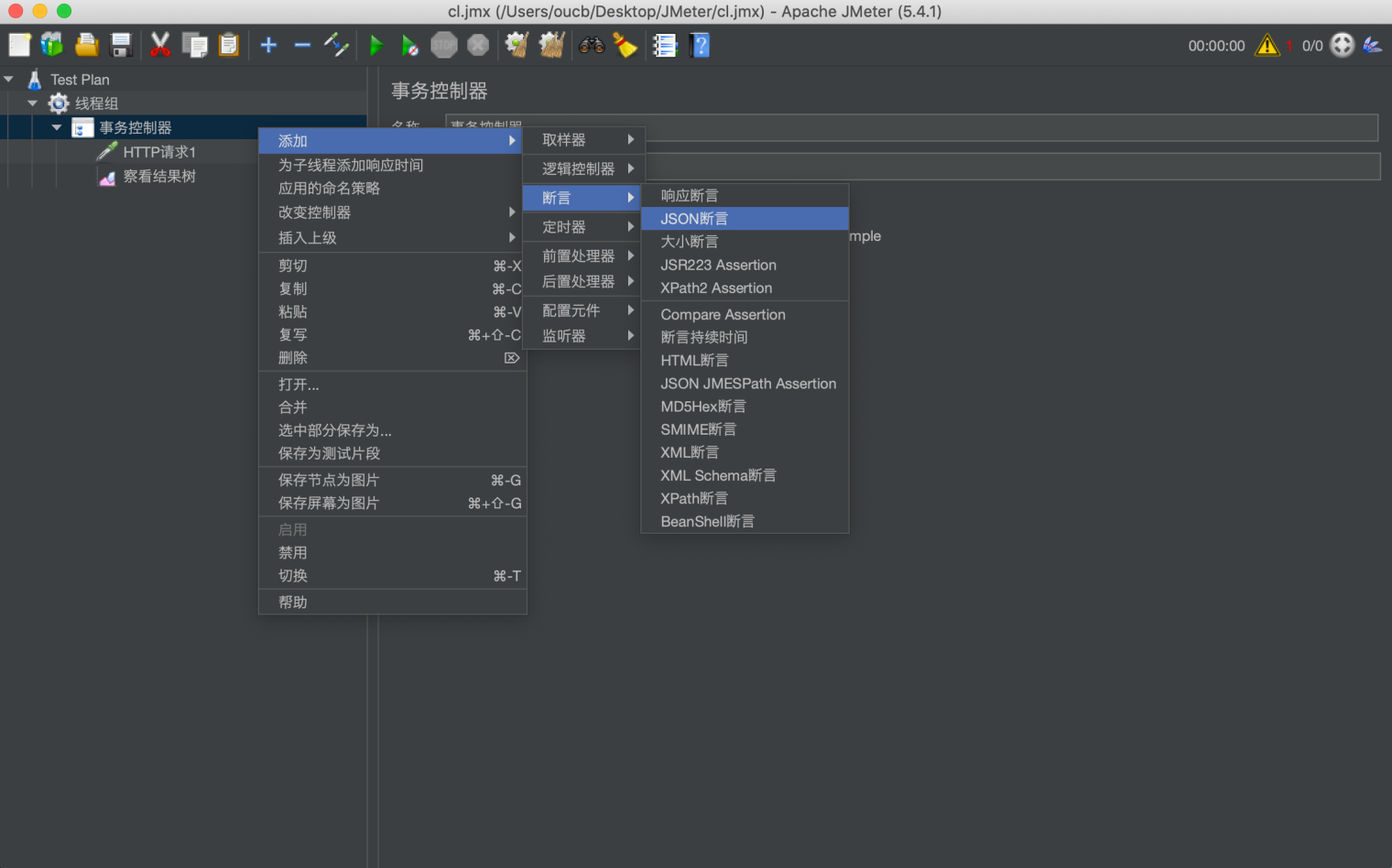
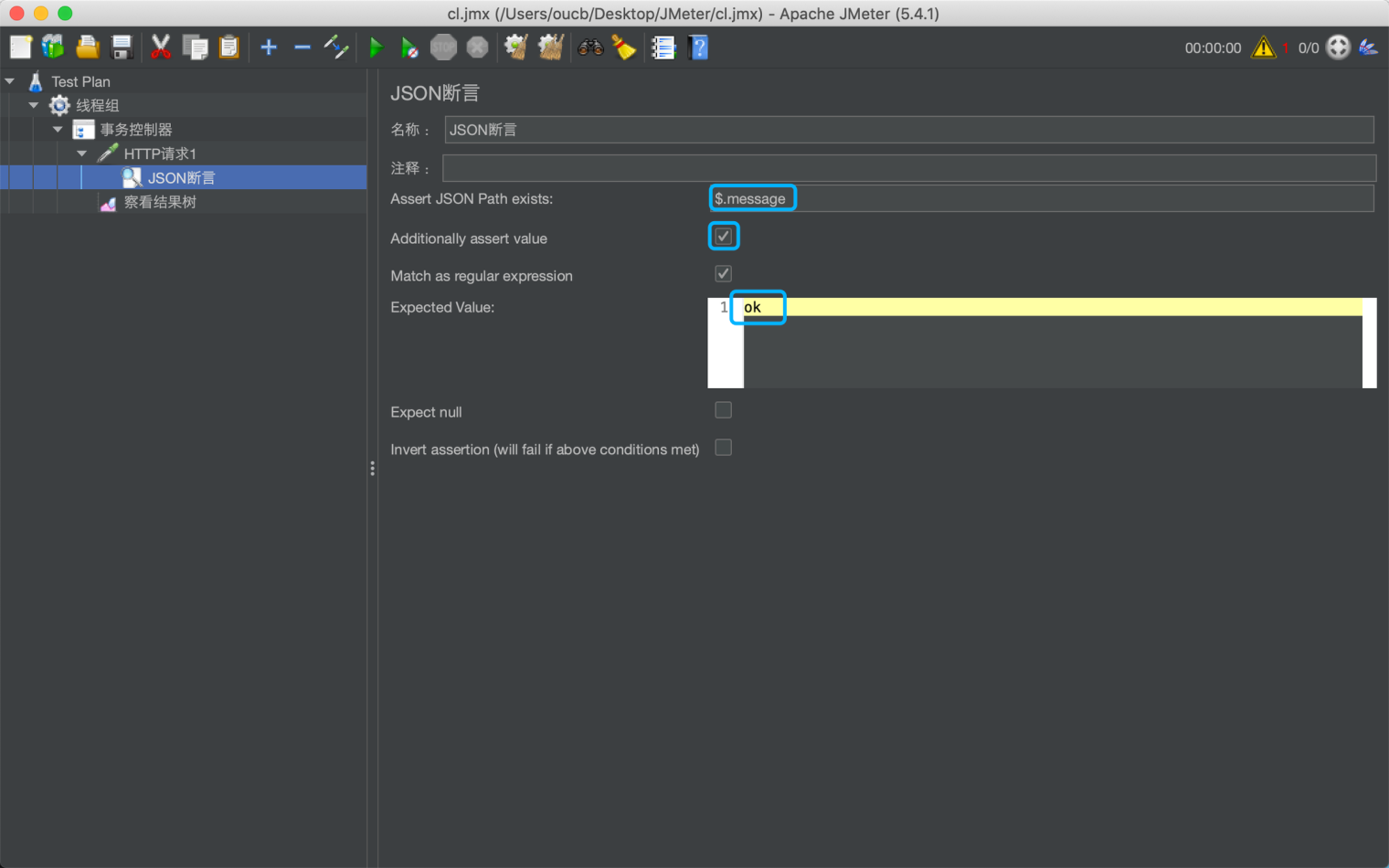
JSON断言配置项有:
- Assert JSON Path exists:需要断言的 JSON 表达式
- Additionally assert value:如果要根据值去断言,请勾选
- Match as regular expression:如果要根据正则表达式去断言,请勾选
- Expected Value:期望值
- Expect null:如果期望是 null 则勾选
- Invert assertion:取反
其中 JSON path 中的「根成员对象」总是被称为$,可以通过 「dot–notation」(.号)或 「bracket–notation」([]号)这两种不同的风格来表示,比如 $.message[0].name 或 $['message'][0]['name']。
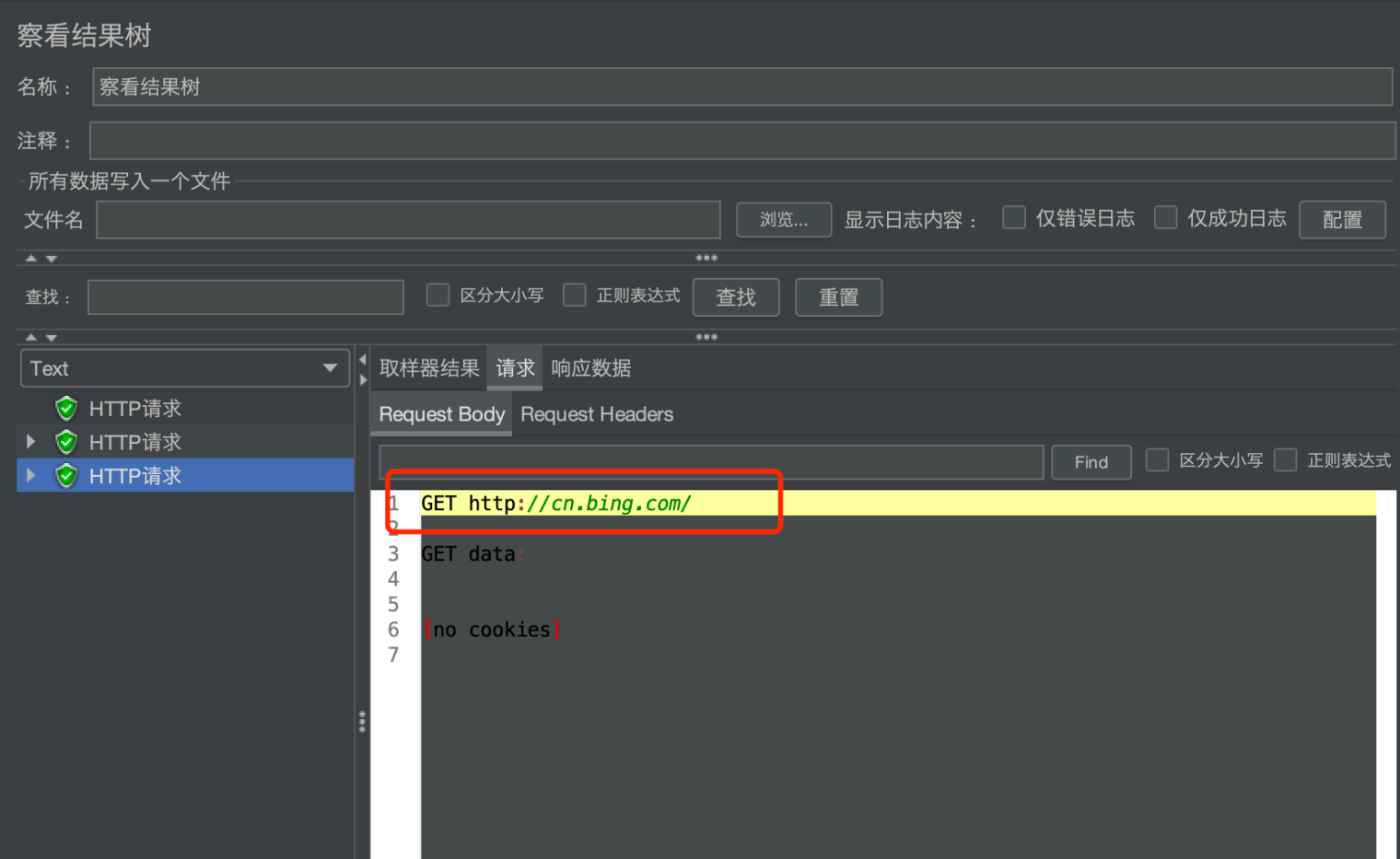
下面以请求 http://www.kuaidi100.com/query 为例,其中 $.message 表示响应 json 对象的中 message,勾选 Additionally assert value 表示要根据 message 的值去判断,Expected value 为 ok 表示判断 message的值是否为 ok。
运行脚本,查看结果,可看到断言是通过的
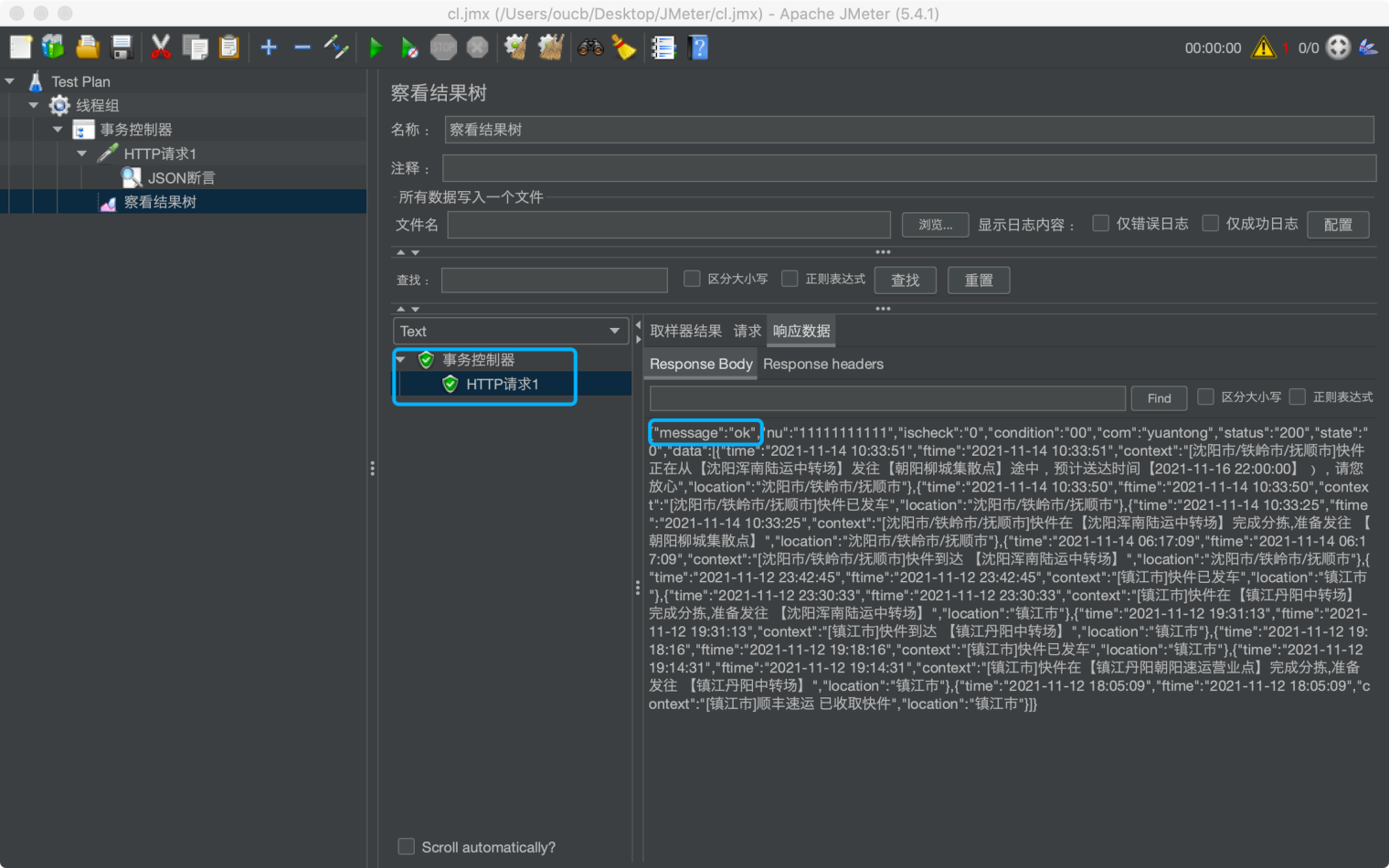
断言的判断条件主要包括:如果响应结果不是 json 格式的,失败;如果 json path 找不到元素,失败;如果 json path 找到元素,没有设置条件,通过;如果 json path 找到元素,但不符合条件,失败;如果 json path 找到元素,且符合条件,通过;如果 json path 返回的是一个数组,会迭代判断是否有元素符合条件,有则通过,没有则失败。回到“JSON断言”,勾选 Invert assertion
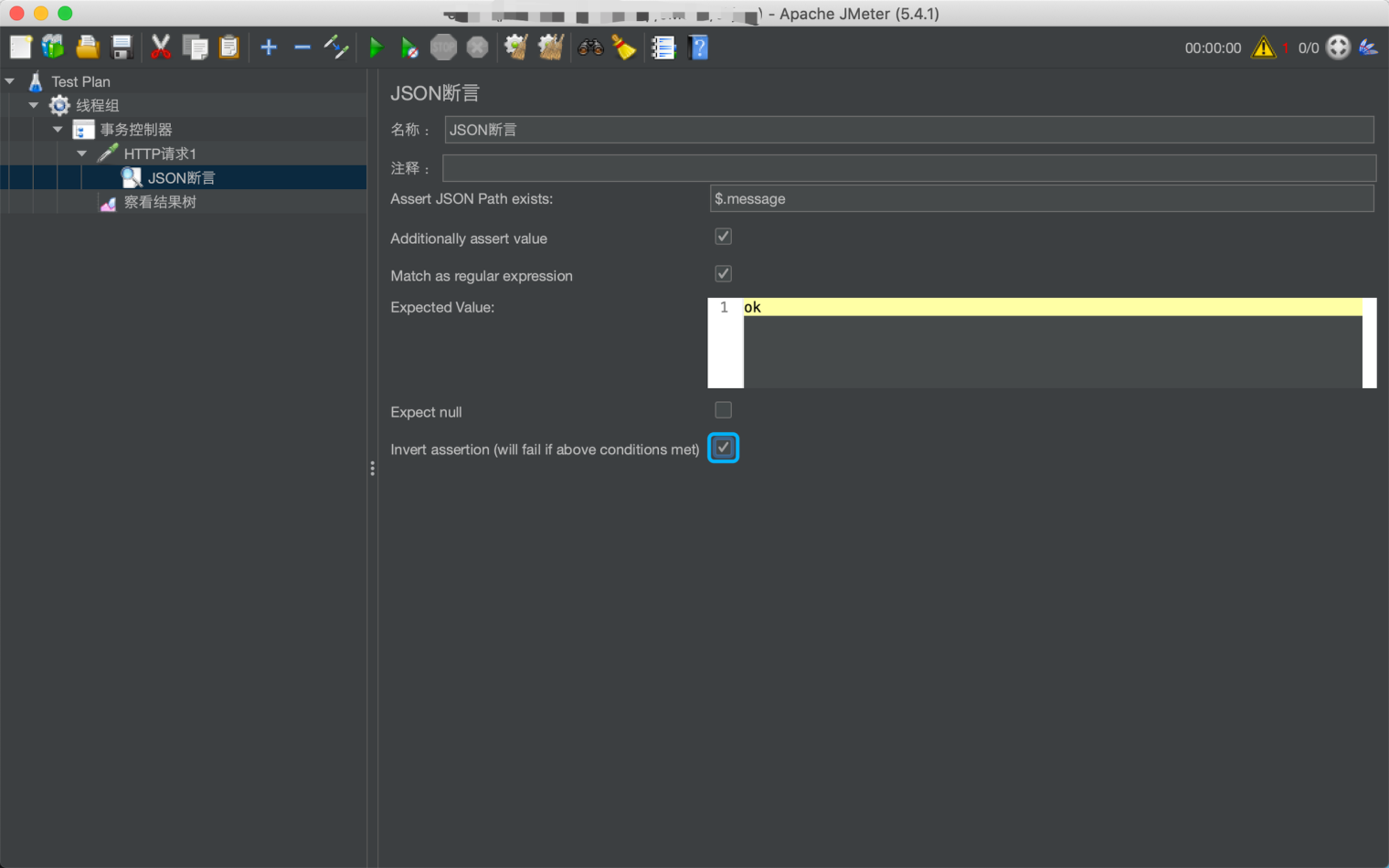
运行脚本,查看结果,可看到断言是失败的

七、定时器
在性能测试中,访问请求之间的停顿时间被称之为思考时间。在实际操作中,停顿时间可以是内容查找、阅读等花费的时间,而定时器正是用来模拟这种停顿时间。其中:
- 同一作用域下的所有定时器优先于 取样器之前执行。
- 如果希望定时器仅应用于其中一个取样器,则把定时器加入到该取样器的子节点。
JMeter定时器主要包括:固定定时器(Constant Timer),统一随机定时器(Uniform Random Timer),精准吞吐量定时器(Precise Throughput Timer),常数吞吐量定时器(Constant Throughput Timer),高斯随机定时器(Gaussian Random Timer),JSR223 定时器(JSR223 Timer),泊松随机定时器(Poisson Random Timer),同步定时器(Synchronizing Timer),BeanShell 脚本编写定时器(BeanShell Timer)。
固定定时器
固定定时器,即配置每个请求之间的间隔时间为固定值。
下图在一个事务控制器上添加固定定时器:

将线程延迟分别配置为 100 和 1000后,运行脚本
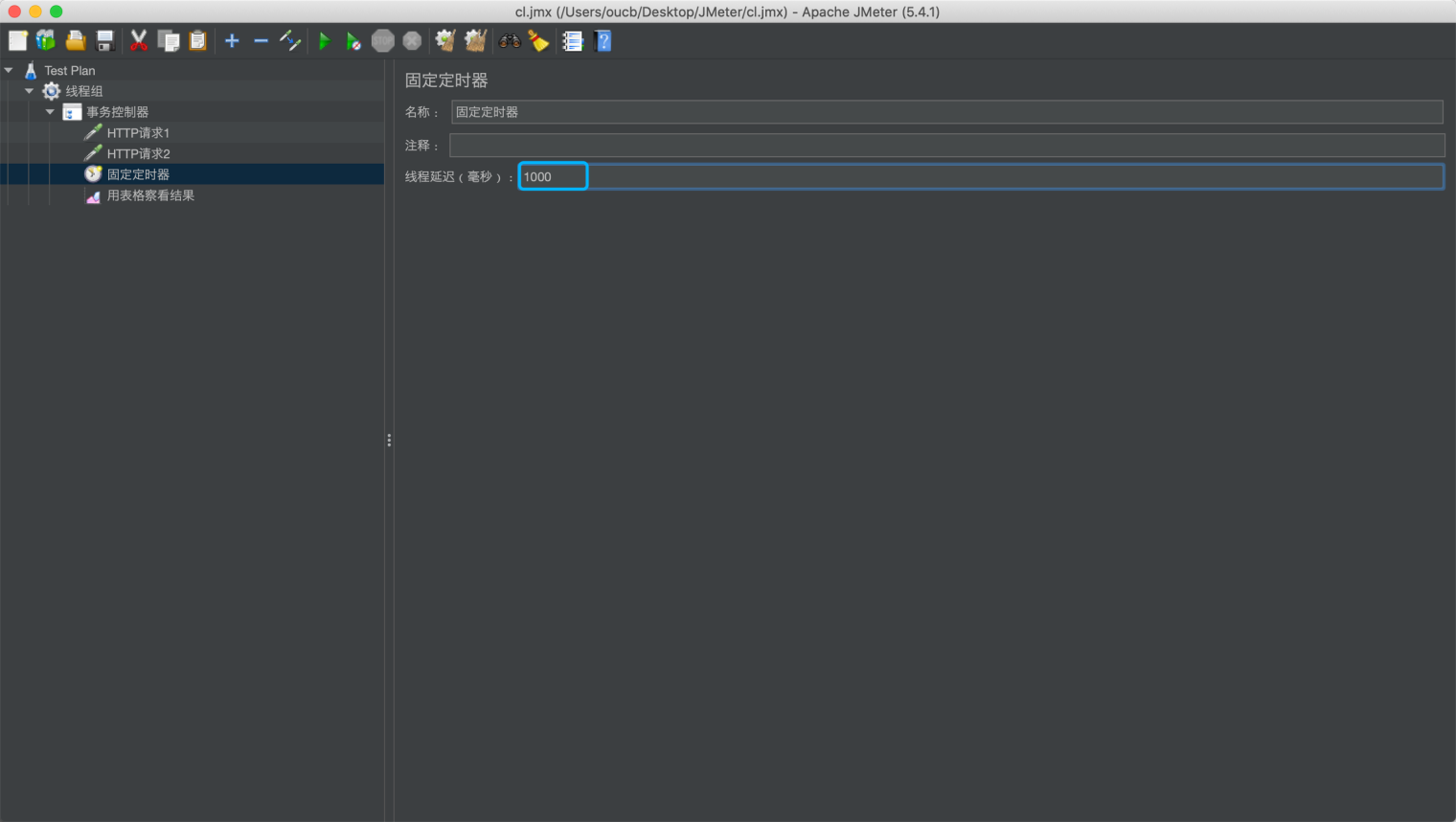
查看表格结果中的数据,其中1、2是配置为 100 毫秒时的运行结果,4、5是配置为 1000 毫秒时的运行结果,可看到 4、5 的间隔时间明显比 1、2 的间隔时间长

常数吞吐量定时器:
常数吞吐量定时器用于控制请求按指定的吞吐量去执行。
下图在一个事务控制器上添加常数吞吐量定时器:
配置目标吞吐量为 120(注意单位是分钟),基于计算吞吐量选择“当前线程组中的所有活动线程(共享)”
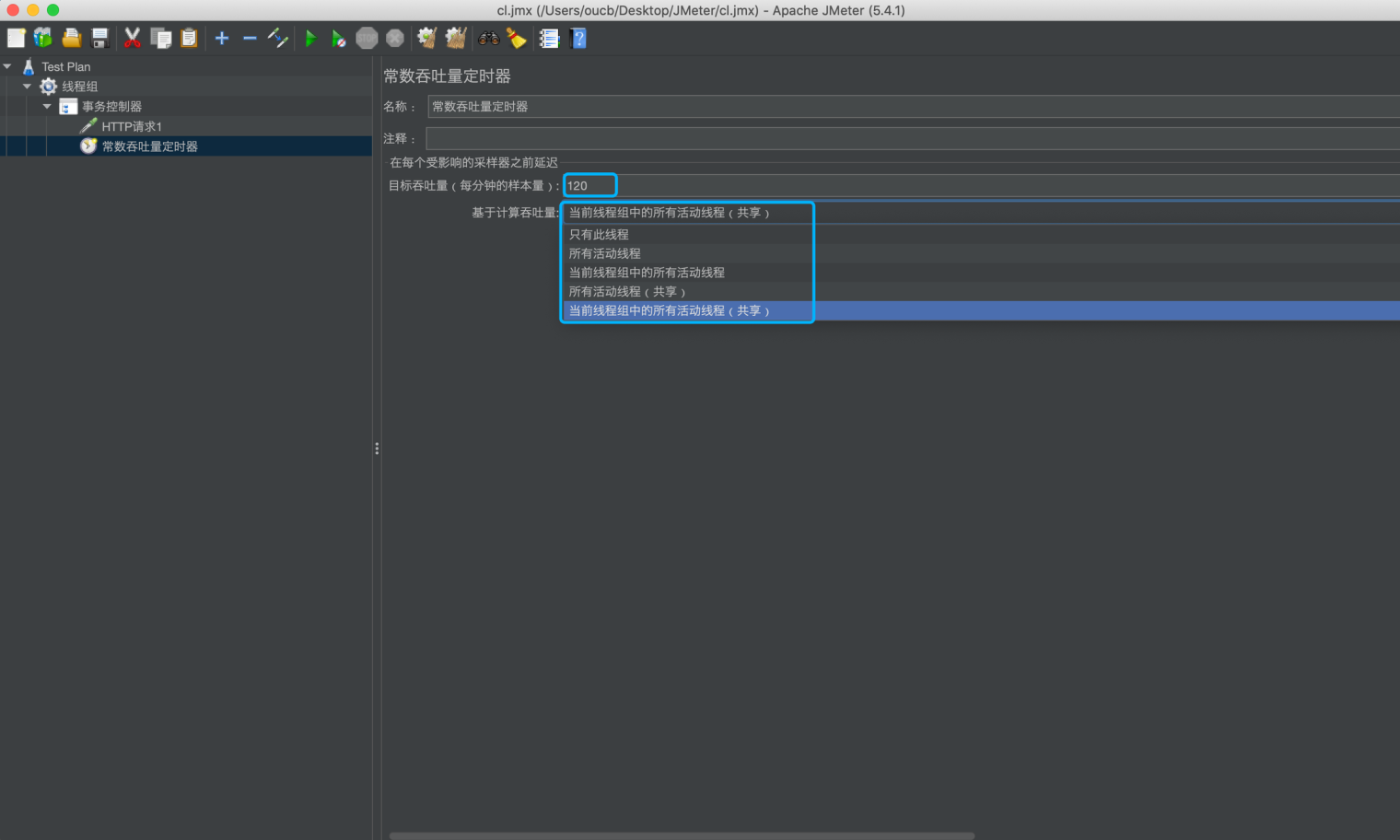
运行脚本,查看结果,可看到吞吐量基本维持在 2/每秒(120/60)

八、前置处理器和后置处理器
前置处理器是取样器请求之前执行一些操作,经常用于在取样器请求运行前修改参数,设置环境变量,或更新未从响应文本中提取的变量。
同样的,后置处理器是在取样器请求之后执行一些操作。有时候服务器的响应数据在后续请求中需要用到,我们就需要对这些响应数据进行处理。比如获取响应中的jwt token,在后续请求中使用以进行身份验证,这时就会使用后置处理器。
版权归原作者 要成为大V的小v 所有, 如有侵权,请联系我们删除。