
文章目录
本篇内容全部基于B站视频link.内容所做的笔记,UP主讲的十分详细,大家可以去看一看。
爬虫不一定要用python,也可以用java和C,但是python是所有编程中最好上手的
robots.txt协议:君子协议,规定了网络中哪些数据可以被爬取数据,哪些不可以
爬虫:通过编写程序来获取网络上的资源
什么是url
URL是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎处理它。
URL由两个主要的部分构成:协议(Protocol)和目的地(Destination)。
“协议”是告诉我们自己面对的是何种类型的Internet资源。
web中最常见的协议是http,它表示从Web中取回的是HTML文档。其他协议还有gopher,ftp和telnet等。
目的地可以是某个文件名、目录名或者某台计算机的名称。
第一个爬虫
#页面源代码from urllib.request import urlopen
url ="https://blog.csdn.net/Jurbo/article/details/52313636"
resp = urlopen(url)print(resp.read().decode("UTF-8"))//输出的字节解码后的
由于各大网站反爬虫的防护做的还是相当可以的,所以这样的基础代码只能算是一个小尝试,并不能拿来应用。
Web请求过程剖析
- 服务器渲染在服务器那边直接把数据和html整合在一起,统一返回给浏览器,在页面源代码中能看到数据
- 客户端渲染第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示,在页面源代码中看不到数据
HTTP协议
协议:两个电脑传输数据时进行的君子约定
HTTP全称Hyper Text Transfer Protocol(超文本传输协议),浏览器和服务器之间数据交互遵守的是HTTP协议
HTTP不论是请求还是响应都是三块内容
#请求
请求行 ——> 请求方式(get/post) 请求url地址 协议
请求头 ——> 放一些服务器需要的附加信息
请求体 ——> 一段放一些请求参数#真正要的东西
#响应
状态行 ——> 协议 状态码
响应头 ——> 放一些客户端要使用的一些附加信息
响应体 ——> 服务器返回的真正客户端要用的内容(HTML,json等)
请求头中常见的一些内容(爬虫需要):
- User-Agent:请求载体的身份标识(用什么发送的请求)
- Referer:防盗链(此次请求是从哪个页面来的)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
Requests
Request模块需要额外安装
案例一(get方式)
import requests
url ='https://www.sogou.com/web?query=%E5%91%A8%E6%9D%B0%E4%BC%A6'
resp = requests.get(url)print(resp)print(resp.text)

从运行结果可以看出,网页给出了响应,但是明显制止了程序的爬虫操作。为了能够逃过网页的监视,我们要为自己设置一个浏览器身份。
网页鼠标右键点击检查,并进入网络,刷新一下便出现了如下页面。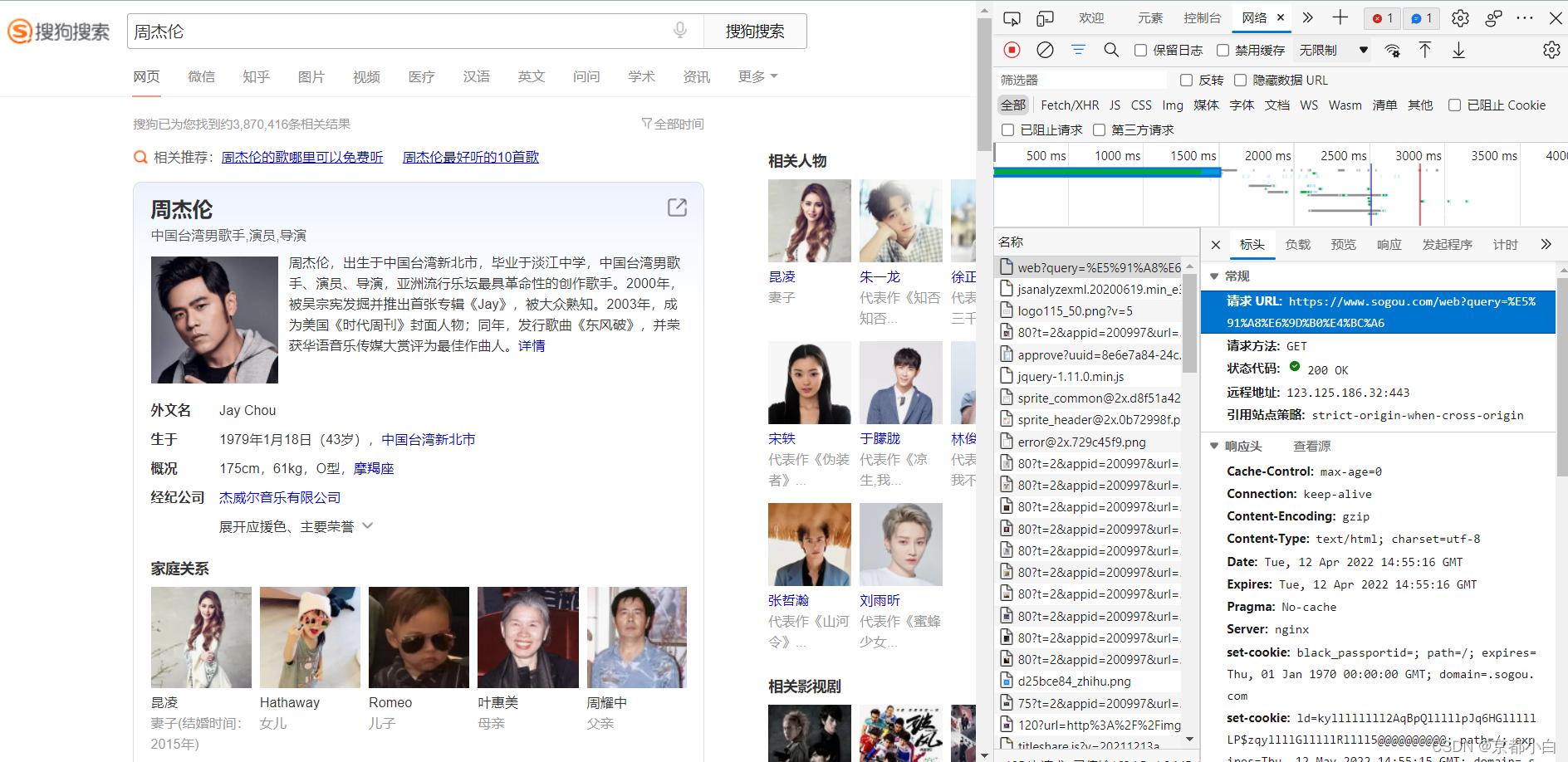
往下翻看,可以看到一个User-Agent,这是网页所显示的访问的浏览器身份,我们将它复制。
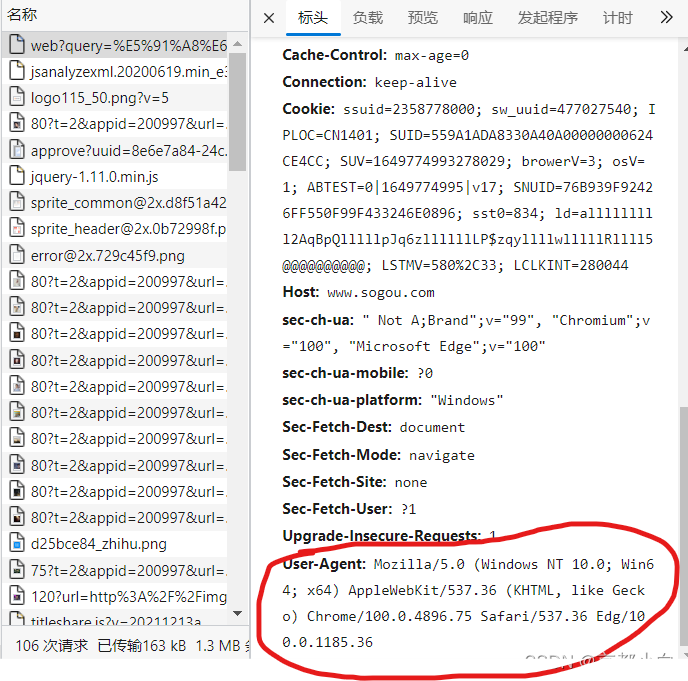
代码更改如下:
import requests
url ='https://www.sogou.com/web?query=%E5%91%A8%E6%9D%B0%E4%BC%A6'
dic ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
resp = requests.get(url,headers = dic)print(resp)print(resp.text)
此刻便如愿爬取了网页的源代码
案例二(post方式)
我们用post方式来发送请求,想要获取什么就在右边寻找对应的文件,此时我想要获取蓝色圈住的这些数据,于是我找到了sug文件,并查看它的url。
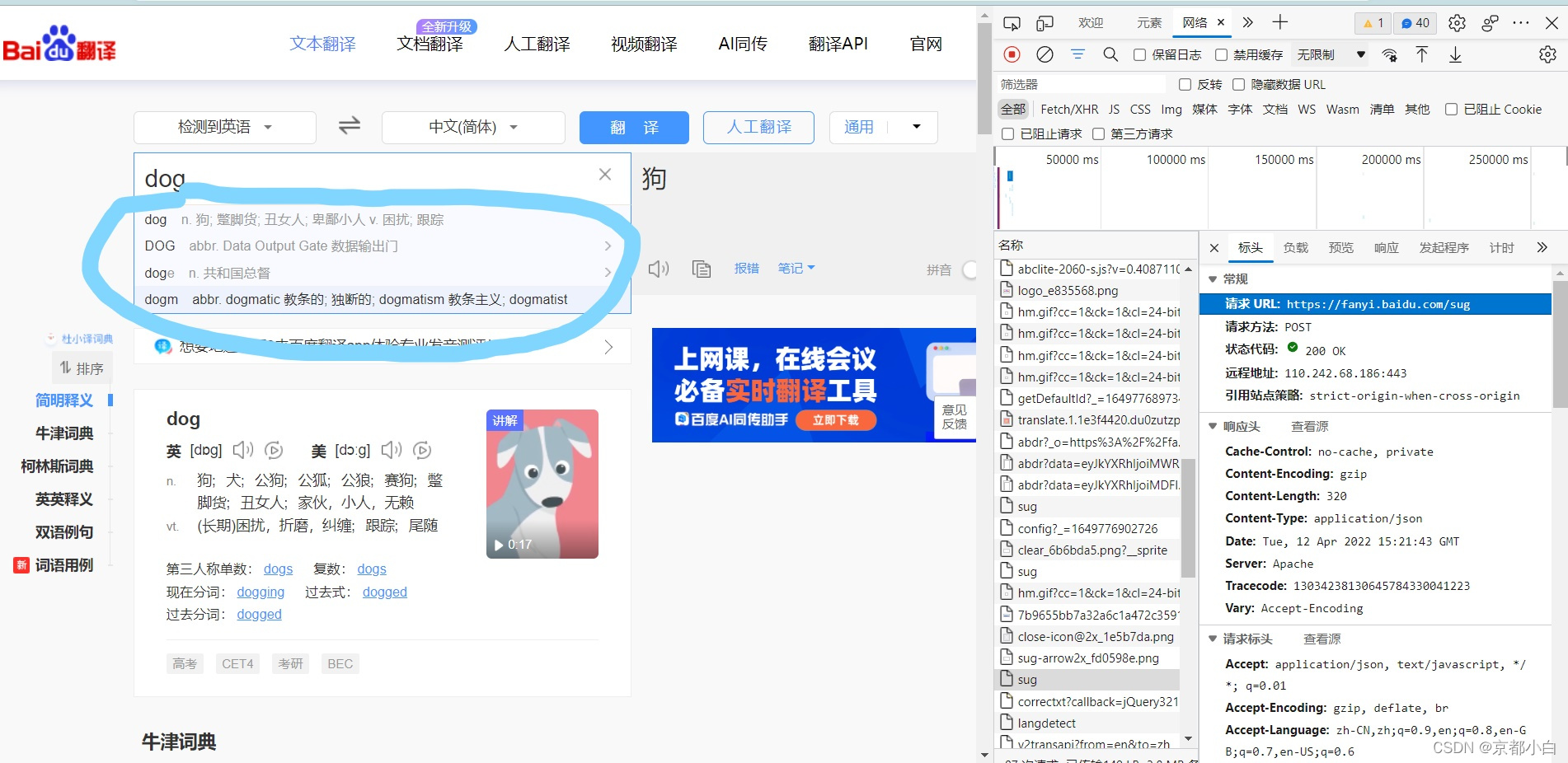
我们将url赋值给代码的数据,并设置字典来保存我们想要查询的数据
import requests
url ="https://fanyi.baidu.com/sug"
s =input("输入")
dic ={"kw": s
}
resp = requests.post(url, data=dic)print(resp.json())

post请求一个数据,网页返回了这个单词的意思,就像pycharm的一个字典一样
发送post的请求必须放在字典中,并用data传递数据
get与post的区别
通过以上两个案例我们可以看到get请求方式仅仅是获取浏览器的数据,称为“显式访问”,而post在访问的时候会发送一个数据,比如上述案例的百度翻译原本我们想要查到的是dog的翻译,post方式发送了mun单词,最后我们获取到了mun的汉语意思,这称为“隐式访问”
案例三
XHR:第二次请求数据
import requests
url ="https://movie.douban.com/j/chart/top_list"#封装参数
param ={"type":"24","interval_id":"100:90","action":"","start":"0","limit":"20"}
reps = requests.get(url=url, params=param)print("默认User-Agent")print(reps.request.headers)#输出默认访问身份

我们寻找浏览器可以进入的User-Agent,并输入
import requests
url ="https://movie.douban.com/j/chart/top_list"#封装参数
param ={"type":"24","interval_id":"100:90","action":"","start":"0","limit":"20"}
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
reps = requests.get(url=url, params=param,headers=headers)print(reps.text)
reps.close()

如愿爬取到了信息,但是此时我们看起来不是很方便,转为json换成我们更熟悉的文件。
爬取完信息一定要记得关掉访问,不然会被反爬盯上
数据解析概述
re解析
re解析即正则解析,在线正则表达式测试:在线正则表达式测试 (oschina.net)
正则语法:使用元字符进行排列组合来匹配字符串
元字符:具有固定含义的特殊符号
常用元字符
. 匹配换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配一个字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中的所有字符
量词:控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n次到m次
贪婪匹配和惰性匹配
.* 贪婪匹配(匹配最长的一条)
.*? 惰性匹配(匹配最短的一条)
findall
import re
# findall:匹配字符串中所有符合正则的内容
lst = re.findall(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")print(lst)

finditer
和findall差不多,只不过返回的是迭代器
import re
# findall:匹配字符串中所有符合正则的内容
lst = re.findall(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")print(lst)# finditer:匹配字符串中所有的内容[返回的是迭代器]
it = re.finditer(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")print(it)

将代码替换
it = re.finditer(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")for i in it:print(i)

<re.Match>是调用了re模块的匹配方法,span表示了所匹配字符的起始和结束位置,match是匹配到的字符。
想要调用迭代器中的内容,就要使用group,再对代码进行更改
it = re.finditer(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")for i in it:print(i.group())
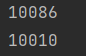
结果为迭代器中的内容,运行无误。
search
# search:找到一个结果就返回,返回的是一个match对象,拿数据需要.group()
s = re.search(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")print(s.group())

search与find的不同之处在于search只要知道有匹配的字符存在就返回,只寻找一个字符串
match
# match:默认从头开始匹配,如果字符串的第一个字符不是可匹配字符,则无返回值
s = re.match(r"\d+","我的电话号码是10086,我女朋友的电话号码是:10010")print(s.group())
complie
预加载正则表达式
当正则表达式过长时,我们可以使用预加载正则表达式,将要寻找的正则表达式格式储存住,调用时可以用不同的字符串,相当于用一种匹配格式匹配多次字符串,不用我们每次都去编写匹配格式,而且将匹配格式和待匹配语句分开写代码看起来更加整洁。
import re
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号码是10086,我女朋友的电话号码是:10010")print(ret)for i in ret:print(i.group())
ret = obj.findall("我的电话号码是10086,我女朋友的电话号码是:10010")print(ret)

预加载正则表达式的好处是我们可以在多个地方多次使用。
迭代
在这里我们要区分几个概念
- 可迭代对象列表、元组、字符串、字典等都是可迭代对象,可以使用for循环遍历出所有元素的都可以称为可迭代对象(Iterable)。
- 迭代器迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 迭代器和可迭代对象的联系1. 可迭代对象是包含迭代器的(迭代器一定是可迭代对象,反之却不一定)2. 如果一个对象定义了__iter()__方法,那它就是可迭代对象。3. 如果一个对象定义了__iter()__方法和__next()方法,那它就是迭代器。(因为迭代器是可迭代对象,所以一定有__iter())
(?P<分组名字>正则)
可以单独从正则匹配内容中单独匹配内容
import re
s ='''
<div class='赘婿'><span id='女主'>宋轶</span></div>
<div class='赘婿'><span id='男主'>郭麒麟</span></div>
'''# re.S让.可以匹配换行符
obj = re.compile(r"<div class='.*?'><span id='.*?'>.*?</span></div>", re.S)
ret = obj.finditer(s)for i in ret:print(i.group())

此时我们可以在结果中看到惰性匹配为我们把语句全部匹配了出来,但是如果我们只需要’赘婿‘’女主‘这样的信息的话,还需要再添加一个标签,将所需信息保存在标签中并将标签打印输出。
我们将代码更改如下
import re
s ='''
<div class='赘婿'><span id='女主'>宋轶</span></div>
<div class='赘婿'><span id='男主'>郭麒麟</span></div>
'''# re.S让.可以匹配换行符
obj = re.compile(r"<div class='(?P<class>.*?)'><span id=(?P<id>'.*?')>(?P<name>.*?)</span></div>", re.S)
ret = obj.finditer(s)for i in ret:print(i.group("class"))print(i.group("id"))print(i.group("name"))

完美爬取。如果不想要进行换行输出,可以在print后加上end="",但是建议加上循环换行
豆瓣电影网练手
#拿到页面源代码 requests#通过re来提取想要的有效信息 re模块import requests
import re
url ='https://movie.douban.com/top250'
header ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
resp = requests.get(url, headers=header)
page_content = resp.text #爬取到的页面源代码
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>', re.S)
result = obj.finditer(page_content)for i in result:print(i.group("name"))

成功爬取电影名称
这段代码的思路很简单,首先通过responses获取信息,再建立预加载正则表达式,注意在建立的时候我们要观察所有代码的共同点,不然容易匹配错误从而获取不到我们想要的信息,最后再finditer匹配打印输出。
进一步爬取电影年份信息
#拿到页面源代码 requests#通过re来提取想要的有效信息 re模块import requests
import re
url ='https://movie.douban.com/top250'
header ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
resp = requests.get(url, headers=header)
page_content = resp.text #爬取到的页面源代码
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?<br>(?P<year>.*?) ', re.S)
result = obj.finditer(page_content)for i in result:print(i.group("name"))print(i.group("year").strip())#strip()函数可以消除字符前面或后面的空格,不能消除字符中间的空格

成功获取年份
同理我们也可以根据这种方式获取电影评分和观看人数。
#拿到页面源代码 requests#通过re来提取想要的有效信息 re模块import requests
import re
url ='https://movie.douban.com/top250'
header ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
resp = requests.get(url, headers=header)
page_content = resp.text #爬取到的页面源代码
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?<br>(?P<year>.*?)'r' .*?<span class="rating_num" property="v:average">(?P<point>.*?)</span>.*?<span>(?P<people>.*?)人评价', re.S)
result = obj.finditer(page_content)for i in result:print(i.group("name"))print(i.group("year").strip())print(i.group("point"))print(i.group("people"))
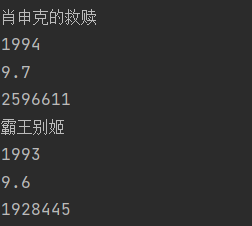
将数据保存在csv文件中
csv文件中的东西都是通过,分隔开的,对我们以后做数据分析很有帮助
import requests
import re
import csv
url ='https://movie.douban.com/top250'
header ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
resp = requests.get(url, headers=header)
page_content = resp.text #爬取到的页面源代码
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?<br>(?P<year>.*?)'r' .*?<span class="rating_num" property="v:average">(?P<point>.*?)</span>.*?<span>(?P<people>.*?)人评价', re.S)
result = obj.finditer(page_content)
f =open("data.csv", mode="w",encoding='UTF-8')
cswriter = csv.writer(f)for i in result:
dic = i.groupdict()
dic['year']= dic['year'].strip()
cswriter.writerow(dic.values())
运行结果如下:
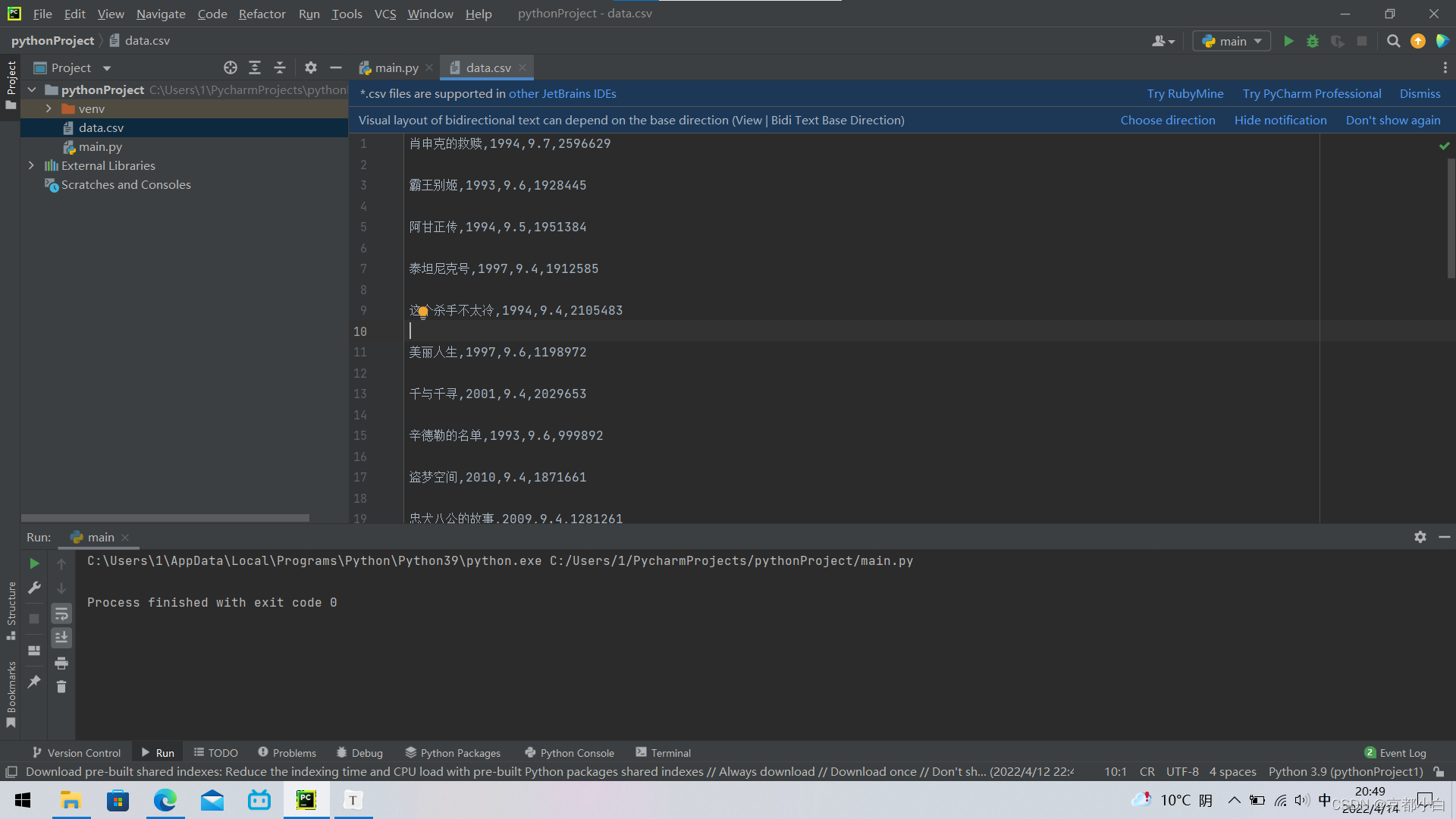
pycharm会自动生成一个csv文件,爬取的数据会自动保存到该文件中,看起来是不是特别条理清晰
bs4解析
bs全称Beatiful Soup ,也需要另外安装,如果使用的是pycharm编译器,点击Terminal输入pip install bs4,pycharm便自动为我们安装好了bs模块
#1. 拿到页面源代码
#2. 使用bs4进行解析,拿到数据
解析数据:
1.把页面源代码交给BeautifulSoup进行处理,生成bs对象
page = BeautifulSoup(resp.text,"html.parser")#指定html解析器
2.从bs对象中查找数据
- find(标签,属性=值):只找第一个
- find_all(标签,属性=值):返回页面所有符合要求的
page.find("table", class_ ="hq_table")#class是python的关键字,所有这里加上_
但是每次这么写都要记得class后面加_,我们可以换一种方式来写
page.find("table", attrs={"class":"hq_table"})
图片链接爬取
#1.拿到主页面的源代码,提取到子页面的链接地址#2.通过href拿到子页面的内容,从子页面中拿到图片的下载地址#3.下载图片import requests
from bs4 import BeautifulSoup
import re
url ="http://bizhi360.com/weimei/"
resp = requests.get(url)
resp.encoding ="UTF-8"
main_page = BeautifulSoup(resp.text,"html.parser")
alist = main_page.find("div", attrs={"class":"pic-list"}).find_all("a")for a in alist:
s ="http://bizhi360.com/"+a.get("href")#拿到子页面的源代码
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36"}
child_page_resp = requests.get(s, headers=headers)
child_page_resp.encoding ="UTF-8"
child_page_text = child_page_resp.text
#从子页面中拿到图片的下载途径
child_page = BeautifulSoup(child_page_text,"html.parser")
p = child_page.find("figure")print(p)
resp.close()

通过一个网站进入子网链接,并对图片地址进行爬取,但是可能是因为进入次数太多,遭到了反爬,只能进行到如上图所示这一步,下次我换个网站试试吧
xpath解析
xpath需要下载lxml模块
XPath 使用路径表达式来选取 XML 文档中的节点或节点集,节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
表达式描述nodename选取此节点的所有子节点。/从根节点选取。//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。.选取当前节点。…选取当前节点的父节点。@选取属性。./从当前节点选取
举例说明:
路径表达式结果bookstore选取 bookstore 元素的所有子节点。/bookstore选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!bookstore/book选取属于 bookstore 的子元素的所有 book 元素。//book选取所有 book 子元素,而不管它们在文档中的位置。bookstore//book选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。//@lang选取名为 lang 的所有属性。
路径表达式:
路径表达式结果/bookstore/book[1]选取属于 bookstore 子元素的第一个 book 元素。/bookstore/book[last()]选取属于 bookstore 子元素的最后一个 book 元素。/bookstore/book[last()-1]选取属于 bookstore 子元素的倒数第二个 book 元素。/bookstore/book[position()❤️]选取最前面的两个属于 bookstore 元素的子元素的 book 元素。//title[@lang]选取所有拥有名为 lang 的属性的 title 元素。//title[@lang=‘eng’]选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。/bookstore/book[price>35.00]选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。/bookstore/book[price>35.00]/title选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。通配符描述*匹配任何元素节点。@*匹配任何属性节点。node()匹配任何类型的节点。路径表达式结果/bookstore/*选取 bookstore 元素的所有子元素。//选取文档中的所有元素。//title[@]选取所有带有属性的 title 元素。
猪八戒网实战
#拿到页面源代码#提取和解析数据import requests
from lxml import etree
url ="https://taiyuan.zbj.com/search/f/?kw=saas"
resp = requests.get(url)#解析
html = etree.HTML(resp.text)
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")for div in divs:#每一个服务商的div
price = div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")[0].strip('¥')
title ='saas'.join(div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()"))
com_name = div.xpath("./div/div/a[1]/div[1]/p/text()")[1]print(price)print(title)print(com_name)
resp.close()
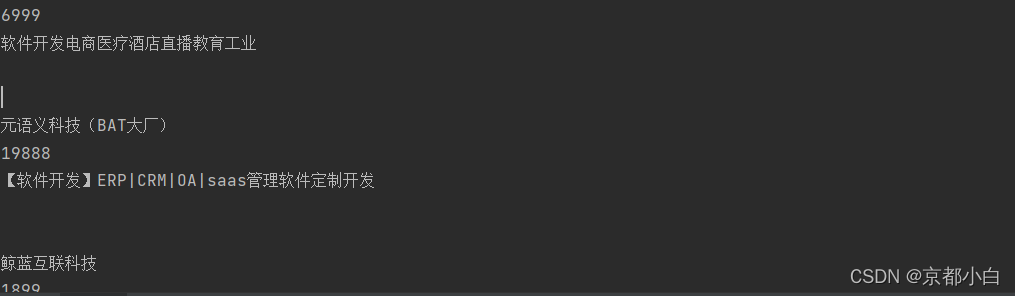
运行结果还算完美吧
一路学下来,感觉爬虫其实只是一些包的运用,多动手做些案例都能搞明白,继续加油吧!
版权归原作者 京都小白 所有, 如有侵权,请联系我们删除。