
一、实训目标
(1)编程实现按日期统计访问次数
二、实训环境
(1)使用CentOSd Linux操作系统搭建的3个节点
(2)使用JDK
(3)使用Hadoop
三、实训内容
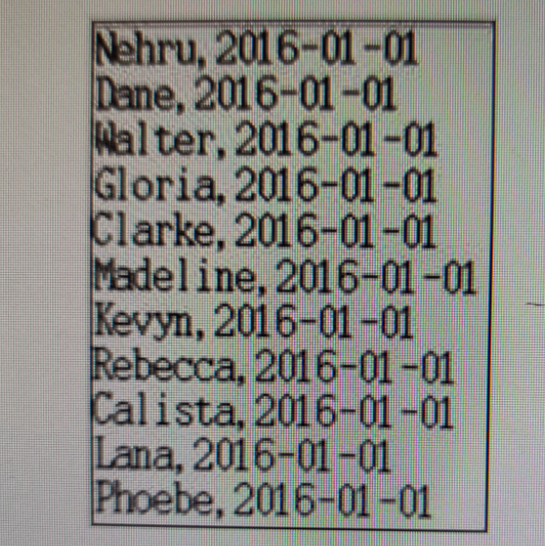
(1)统计用户在2016年度每个自然日的总访问次数,数据格式如图,第一列为用户名,第二列为登录的日期。
四、实例步骤
4.1分析思路与处理逻辑
数据总共有两列,第一列为用户名,第二列为登录的日期,想要统计每个自然日,也就是每一天的访问次数,可以转换为对日期值的词频统计,只要统计出每个日期出现的次数,就可以知道对应日期的日访问次数。将思路转化为MapReduce编程逻辑,需要从以下3个模块考虑。
(1)输入输出格式
(2)Mapper要实现 的计算逻辑
(3)Reducer要实现的计算逻辑
接下来依次分析这几个模块的解决思路与处理逻辑。
1.定义输出格式
通过统计日期的词频来统计每个自然日的访问次数,那么Map的输出就是<访问日期,1>,Reduce输出就是<访问日期,访问次数>。
社区网站用户的访问日期,在格式上都属于文本格式,访问次数为整型数值格式。组成的键值对为<访问日期,访问次数>,因此Map的输出与Reduce的输出都选用Text类与IntWritable类。
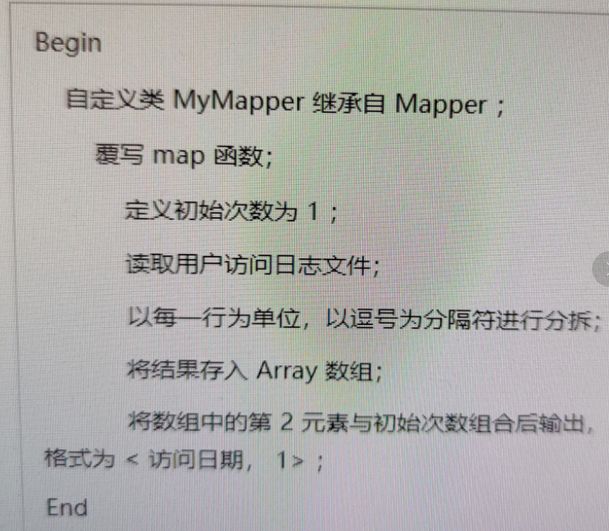
2.Mapper类的逻辑实现
Mapper类中最主要的部分就是map函数。map函数的主要任务是读取用户访问文件中的数据,输出所有访问日期与初始次数的键值对。因为访问日期是数据文件中的第2列,所以先定义一个数组后,再提取第2个元素,与初始次数1一起构成要输出的键值对,即<访问日期,1>。
以下为伪代码来编写Mapper的处理逻辑,代码如下
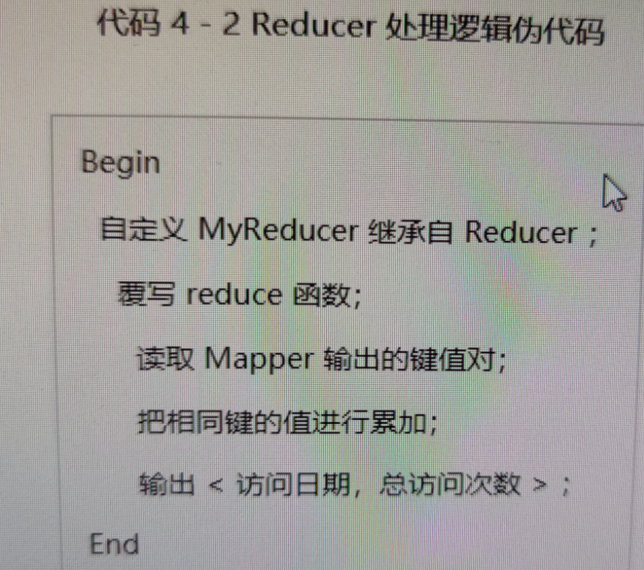
3.Reducer类的逻辑实现
Reducer类中最主要的部分就是reduce函数,reduce函数的主要任务就是读取Mapper输出的键值对<访问日期,1>。这一部分的处理逻辑与官方示例wordcount中的Reducer完全相同。如图
4.2编写核心模块代码
(1)编写Mapper模块代码
package cn.demo.myfriend.data;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
*
* @author zhongyulin
* LongWritable 输入的偏移量
* Text 输入的数据
* Text 输出的key
* IntWritable 输出的value
*/
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line=value.toString();
//按规则拆分成数组
String[] arry=line.split(",");
String keyout=arry[1];
context.write(new Text(keyout),one);
}
}
(2)编写Reducer模块代码
package cn.demo.myfriend.data;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* Reducer模块
* @author zhongyulin
*
*/
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable val : values) {
sum +=val.get();
}
result.set(sum);
context.write(key, result);
}
}
(3)编写Dirver模块
//编写Driver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.初始化相应的hadoop配置
Configuration conf = new Configuration();
//收集异常信息
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length<2){
System.err.println("需要两个参数,第一个参数是输入文件路径,第二个参数是输出文件路径");
System.exit(2);
}
//2.新建job并且设置主类,这里的job实例需要把configuraction的实例传入,后面的“word count”是该mapreduce任务的名字
Job job = Job.getInstance(conf,"Daily Access Aount");
//3.设置jar包名 通过类型名生成
job.setJarByClass(DailyAccessCount.class);
job.setMapperClass(MyMapper.class);//TODO
//4.里面类名为实际任务的Mapper
//设置combiner类,可选 优化处理
job.setReducerClass(MyReducer.class);//TODO
//5.里面的类名是为实际任务的reducer
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输出键值对类型 ,如果map和reducer输出类型一样,只需要设置总输出
//设置读取的文件路径
//hadoop jar ...jar wordcount /路径1 /路径2
for (int i = 0; i < otherArgs.length-1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//设置输出的文件路径
for (String str : otherArgs) {
FileOutputFormat.setOutputPath(job, new Path(str));
}
System.exit(job.waitForCompletion(true)?0:1);
//7.提交mapreduce任务运行(固定写法),并等待任务运行结束
}
4.3任务实现
在本地上创建一个user_login.txt内容如下
Nehru,2016-01-01
Dane,2016-01-01
Walter,2016-01-01
Gloria,2016-01-01
Clarke,2016-01-01
Madeline,2016-01-01
Kevyn,2016-01-01
Rebecca,2016-01-01
Calista,2016-01-01
Lana,2016-01-01
Phoebe,2016-01-01
Clayton,2016-01-01
Kimberly,2016-01-01
Drew,2016-01-01
Giselle,2016-01-01
Nolan,2016-01-01
Madeson,2016-01-01
Janna,2016-01-01
Raja,2016-01-01
Aurelia,2016-02-01
Wynter,2016-02-01
Mari,2016-02-01
Molly,2016-02-01
Marshall,2016-02-01
Brynne,2016-02-01
Hannah,2016-02-01
Whilemina,2016-02-01
Gage,2016-02-01
Wallace,2016-03-15
Penelope,2016-03-15
Ursa,2016-03-15
Cassidy,2016-03-15
Venus,2016-03-15
Ethan,2016-03-15
Regina,2016-03-15
Orla,2016-03-15
Avram,2016-03-15
Barry,2016-03-15
Dalton,2016-03-15
Rhea,2016-03-15
Patrick,2016-03-15
Unity,2016-03-15
Zachary,2016-03-15
Hedley,2016-03-15
Sasha,2016-03-15
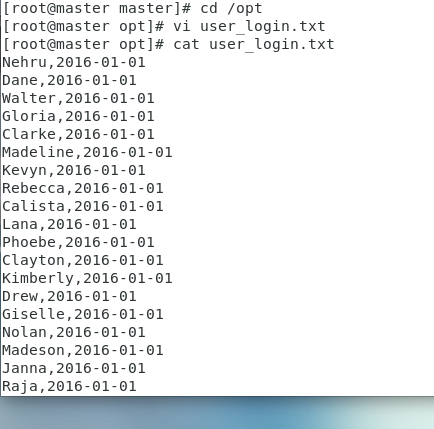
在集群上创建一个文件夹user
(1)上传文件/opt/user_login.txt到/user
hdfs dfs -put /opt/user_login.txt /user
(2)在工程src下创建一个test包,创建类dailyAccessCount.java ,类中完整内容如下
package dailyAccessCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount;
import org.apache.hadoop.examples.WordCount.IntSumReducer;
import org.apache.hadoop.examples.WordCount.TokenizerMapper;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* 任务目标是统计用户在2019年每个自然日的总访问次数
* 原始数据文件中提供了用户名称和访问日期
* @author student
* 想要的数据格式:2019-11-06 3
* oax,2019-11-06
* map任务输出格式:2019-11-06,1
* reduce任务输出格式:2019-11-06,3
*/
public class DailyAccessCount {
//extends Mapper 变成一个map模块
//1.继承Mapper
//2.设置输入/输出键值对类型 tips:输出对类型需要和Driver中设置的mapper输出的键值对类型保持一致
public static class MyMapper extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1) ;
//3.编写map方法,针对每条输入键值对执行函数中定义的逻辑处理,并按照规定的键值对格式输出。
@Override
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String array[] = value.toString().split(",");
//4.mapper输出内容
context.write(new Text(array[1]), one);
}
}
//extends Reducer 变成一个reducer 模块
//1.继承reducer类
//2.设置输入\输出格式 (reducer输入格式是是mapper的输出格式,reducer输出格式要个driver中设置reducer输出格式保持一致)
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//3.编写reduce 对shuffle处理后的map数据进行处理
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0 ;
for (IntWritable value : values) {
sum = sum + value.get();
}
//4.输出内容
context.write(key, new IntWritable(sum));
}
}
//编写Driver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.初始化相应的hadoop配置
Configuration conf = new Configuration();
//收集异常信息
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length<2){
System.err.println("需要两个参数,第一个参数是输入文件路径,第二个参数是输出文件路径");
System.exit(2);
}
//2.新建job并且设置主类,这里的job实例需要把configuraction的实例传入,后面的“word count”是该mapreduce任务的名字
Job job = Job.getInstance(conf,"Daily Access Aount");
//3.设置jar包名 通过类型名生成
job.setJarByClass(DailyAccessCount.class);
job.setMapperClass(MyMapper.class);//TODO
//4.里面类名为实际任务的Mapper
//设置combiner类,可选 优化处理
job.setReducerClass(MyReducer.class);//TODO
//5.里面的类名是为实际任务的reducer
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输出键值对类型 ,如果map和reducer输出类型一样,只需要设置总输出
//设置读取的文件路径
//hadoop jar ...jar wordcount /路径1 /路径2
for (int i = 0; i < otherArgs.length-1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//设置输出的文件路径
for (String str : otherArgs) {
FileOutputFormat.setOutputPath(job, new Path(str));
}
System.exit(job.waitForCompletion(true)?0:1);
//7.提交mapreduce任务运行(固定写法),并等待任务运行结束
}
}
(3)编译打包程序,生成JAR文件
dailyAccessCount.jar。右键单击dailyAccessCount类,选择“Export” a "java" a "jar file" ,单击“next”在所示界面填写jar文件名称和jar文件存放路径,单击“finish”

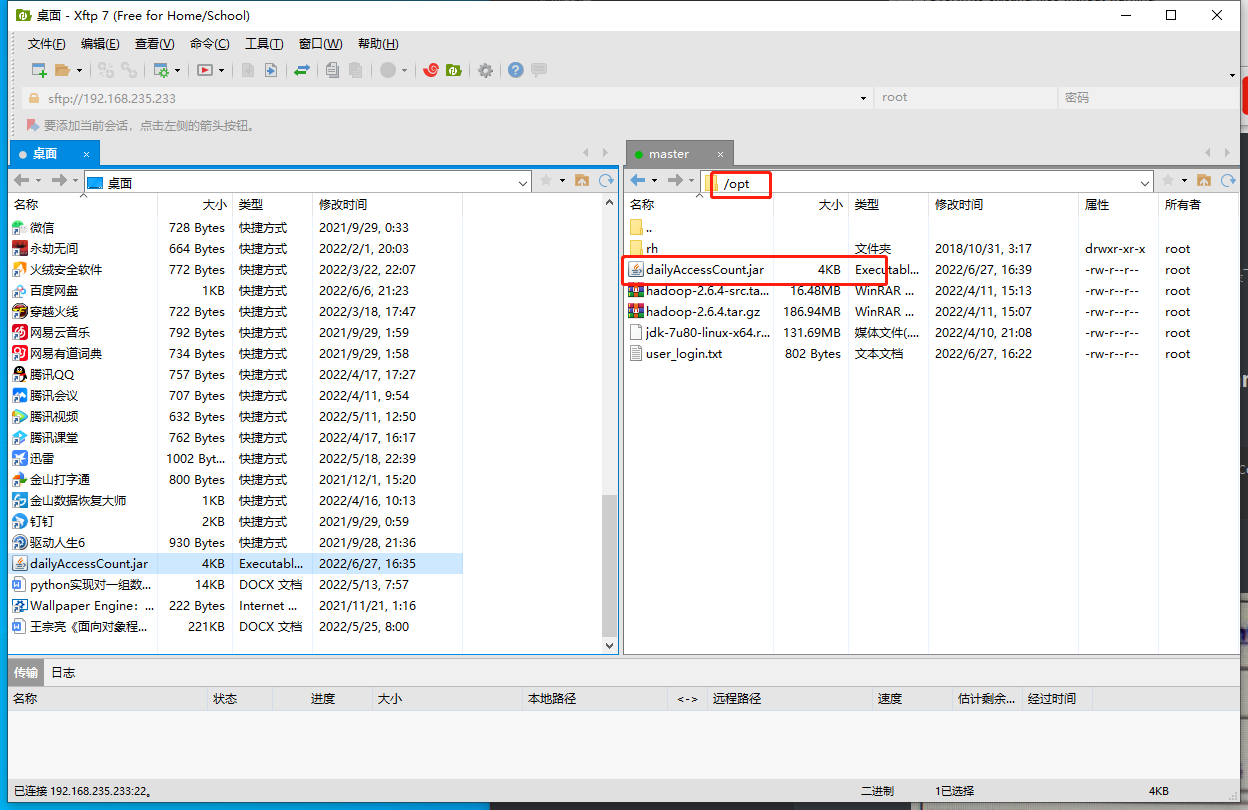
将dailyAccessCount.java生成jar包上传到hadoop的/opt目录下
(4)在jar文件所在目录,以hadoop jar命令提交任务,具体命令如下
hadoop jar dailyAccessCount.jar test.dailyAccessCount /user/user_login.txt /user/AccessCount

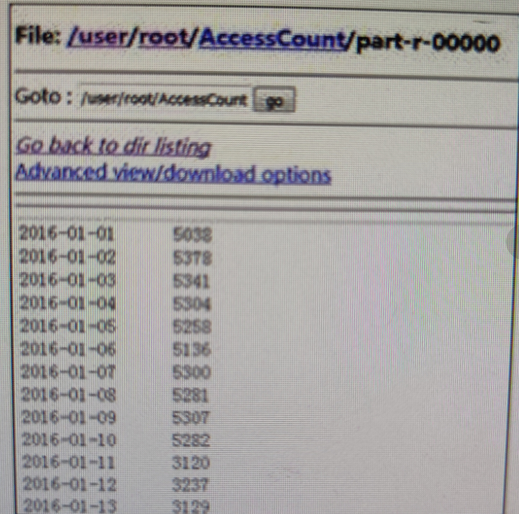
(5)检查输出结果类似如下
1.在HDFS中/user/AccessCount/part-r-00000下即可查看结果
2.集群监控查看如下
结论比较:数据量比较低,节点比较少
/***
* ,%%%%%%%%,
* ,%%/\%%%%/\%%
* ,%%%\c "" J/%%%
* %. %%%%/ o o \%%%
* `%%. %%%% _ |%%%
* `%% `%%%%(__Y__)%%'
* // ;%%%%`\-/%%%'
* (( / `%%%%%%%'
* \\ .' |
* \\ / \ | |
* \\/ ) | |
* \ /_ | |__
* (___________))))))) 攻城湿
*/
版权归原作者 鸷鸟之不群 所有, 如有侵权,请联系我们删除。