
想必我们大家都鼓捣过路由器,路由器可以说是我们日常生活中必不可少的一个装备了,就算你不是程序员,想必你隔壁的七大姑八大姨估计也让你配置过路由器。但是大家有没有想过一个问题,这个路由器是干啥用的?你可能知道这是为终端设备提供 WI-FI 连接上网的一种设备,当我们终端设备连接 WI-FI 后,就可以通过路由器把数据从我的设备传到我想要的地方(其他终端设备),然后实现我想要的东西和内容。
这个回答整体上是能说通的,但是这里我就要问你一个问题了。
路由器是如何把数据发送给其他路由器的呢?
这个问题要回答上来,就要从路由协议来说起了。
在互联网中,不管是局域网还是广域网,一个数据包是可以通过合理的路由控制从一个终端传输到另一个终端的。而起到控制这个数据包发送过程就是路由控制模块,路由控制模块遵循路由协议,路由协议是整个互联网的数据路由的规范和标准。
路由
为了能够让数据包正确的到达目标主机,路由器必须要在数据发送的过程中进行正确的转发,这也是路由器的第一个作用:数据处理,除了能够转发外,数据处理还包括对数据进行分组过滤、加密、压缩等。
那么路由器是怎么知道这个数据是要发往哪里的呢?
路由器内部维护了一个路由表,这个路由表会记录数据包中目标主机的 IP 地址和输出路径。路由器的主要工作就是为每个经过路由的数据包寻找一个最佳的传输路径,关于路由器的一些结构和转发规则我们已经在 路由器你竟然是这样的… 这篇文章中提到过了。
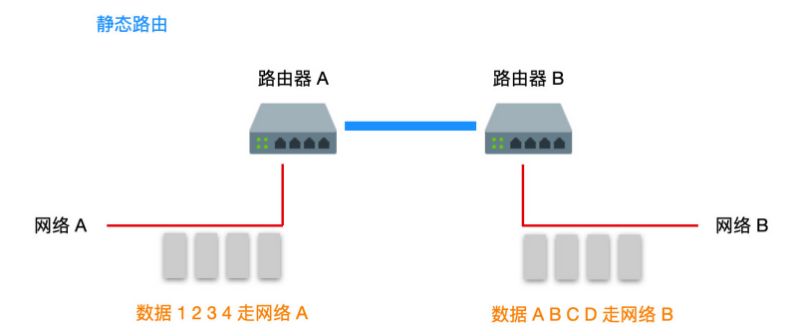
静态路由和动态路由
我们通常会把路由器分为静态路由和动态路由两种,不管是静态路由还是动态路由,都不会脱离路由表。如果数据发送前你已经把路由规则设置好,在发送时数据会按照你事先设置好的路径进行转发的话,这就是静态路由,如果你事先没有设置路由规则,只是让数据在发送的过程中按照路由协议的既定规则进行转发的话,这就是动态路由,这两种路由方式各有利弊。
静态路由会让你做大量且重复的设置路由的工作,效率低而且任务量很大,并且扩展性比较差,一旦新增一个路由,就会让你把所有的路由重新设置一遍,甚至还有单点问题,当传输节点中某一个路由出现故障时,数据基本不会饶过这个路由,需要管理员把路由重新设置才能继续发送。
使用动态路由也需要手动设置一些东西,只不过需要设置的是路由协议,每个路由协议的复杂程度不同,所以设置的难以程度也不同,比如 RIP 协议的设置过程就比较简单,OSPF 的设置过程就比较繁琐。不过一旦设置完成后,如果要新增加一个路由,就只需要设置新增加的单个路由就可以,而且避免了单点问题,动态路由能够选择其他路径从而绕过故障路由。
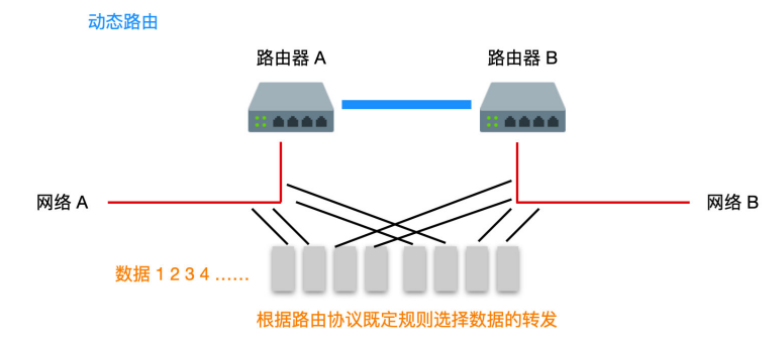
虽然静态路由和动态路由都各有利弊,但是你把他们结合以来一起使用就可以了。成年人全都要。
路由协议
上面讨论了动态路由会根据网络情况动态调整数据的转发路径,那么这种行为方式是以什么为基础的呢?
答案是通过路由之间相互交换路由表来实现的。路由器之间会在合适的时间交换路由表,通过这种方式,可以让网络之间所有的路由器都能够动态调整数据的转发路径。当网络情况发生变化时,路由器之间彼此交换的路由信息会告知对方网络的这种变化,通过信息扩散使所有路由器都能得知网络变化。
常见的动态路由协议有RIP、OSPF、BGP、MPLS 等,根据不同的自治系统还可以分为 IGP(内部网关协议) 和 EGP(外部网关协议)。这个内外有啥区别呢?
这就需要先了解一下什么是自治系统:
一个自治系统(AS)就是处于一个 ISP 网络服务提供商管理控制下的路由器和网络群组,它可以是一个路由器直接连接到 LAN 上,同时连接到 Internet 上,也可以是由企业骨干网互联的多个局域网。
自治系统内部的动态路由采用的是域内路由协议 IGP,而自治系统之间的路由控制采用的是域间路由协议 EGP。IGP 和 EGP 又可以叫做内部网关协议和外部网关协议。IGP 和 EGP 是相辅相成的关系,没有 EGP 就不可能实现在不同机构之间的通信,没有 IGP 也就不可能实现自治系统的内部通信。IGP 协议可以细分为 RIP、RIP 2、OSPF 等众多协议。EGP 协议使用的是 BGP 协议。
我们下面就来认识一下这些协议。
RIP 协议
RIP 的全称是 Routing Information Protocol,路由信息协议。它是 IGP 中最先得到广泛应用的一种协议,就像很多刚诞生的萌芽一样,最开始一定是非常简单的。
RIP 协议要求每个路由器都要维持一个集合,这个集合主要记录了路由器到目的网络所走过的距离,如果路由器与目的网络直接相连,那么这个距离就是 1 ,否则,在路由器到目的网络的这段距离中,只要走过一个路由器,它的距离就会 + 1,这个距离也称为**跳数(hop count)**,也就是说,每经过一个路由器,跳数就会 + 1,不过,这个跳数是有次数限制的,最大不能超过 15,所以,由此可见,RIP 只适用于小型互联网。
RIP 不能在两个网络之间使用多个路由,相反的,它会选择一条途经路由最少的线路进行传输,哪怕选择这条最少路由传输的线路时延大也没关系。
由此我们可以归纳出 RIP 协议的两个特点:第一个特点就是它只会和相邻的路由器交换消息,那么这个"相邻"该如何判断呢?如果两个路由器之间的通信不需要再经过另一个路由器,就说这两个路由器是相邻的。RIP 还规定不相邻的路由器不会交换信息。第二个特点就是说每个路由器会毫不保留的交换自己知道的全部信息,也就是交换彼此的路由表。
还有一个非常重要的问题我们没有考虑到,既然我们知道 RIP 协议规定了交换信息的规则,那它是如何规定交换的时间间隔呢?
RIP 协议规定按照固定的时间间隔交换路由信息,当路由信息发生变更时,它会及时向相邻的路由器通过交换路由表的方式进行更新,更新的原则是路由器要找出最短路径,使用的是距离向量算法。
距离向量算法
对于每一个相邻路由器发送过来的 RIP 报文,通常会进行以下操作:
- 修改 RIP 报文中的内容,会把 RIP 报文中的"下一跳地址" N 、“距离” D 字段的值 + 1。
- 对修改后的 RIP 报文中的每一个内容,进行以下步骤:- 如果原来路由表中没有目的网络的地址 R ,就会修改 RIP 报文中的目的网络地址。- 如果原来路由表中有目的网络的地址,而且下一跳路由的地址是 N,就把收到的 RIP 报文内容替换原路由表中的内容。- 如果原来路由表中有目的网络的地址,但下一跳路由的地址不是 N,如果收到的 RIP 报文中的距离 D 小于路由表中的距离,就会进行更新。
- 如果一段时间内没有收到相邻路由器的路由表更新消息,就把此相邻的路由器标记为不可达,并把距离设置为 16,距离 16 表示为不可达。
RIP 协议报文格式
RIP 协议现阶段主要有两个版本:RIP 1 和 RIP 2 ,现在更多的使用 RIP 2 的版本,RIP 2 协议RIP 协议使用 UDP 协议进行传输控制。
RIP 1 和 RIP 2 的主要区别如下:
- RIP 1 是一个有类路由协议,RIP 报文中不包含子网掩码,这就要求网络中所有设备使用相同的子网掩码,而 RIP 2 是一个无类路由协议,它使用子网掩码。
- RIP 1 在发送更新包的时候是使用的广播方式进行的,而 RIP 2 默认使用的是组播,当然 RIP 2 也支持广播发送,但是使用组播的方式既能够满足需要,又能够节省带宽。
- 第三个区别是 RIP 2 支持明文或者是 MD5 验证,要求两台路由器在同步路由表的时候必须进行验证,这样可以加强安全性。
下面是 RIP 2 的报文格式。
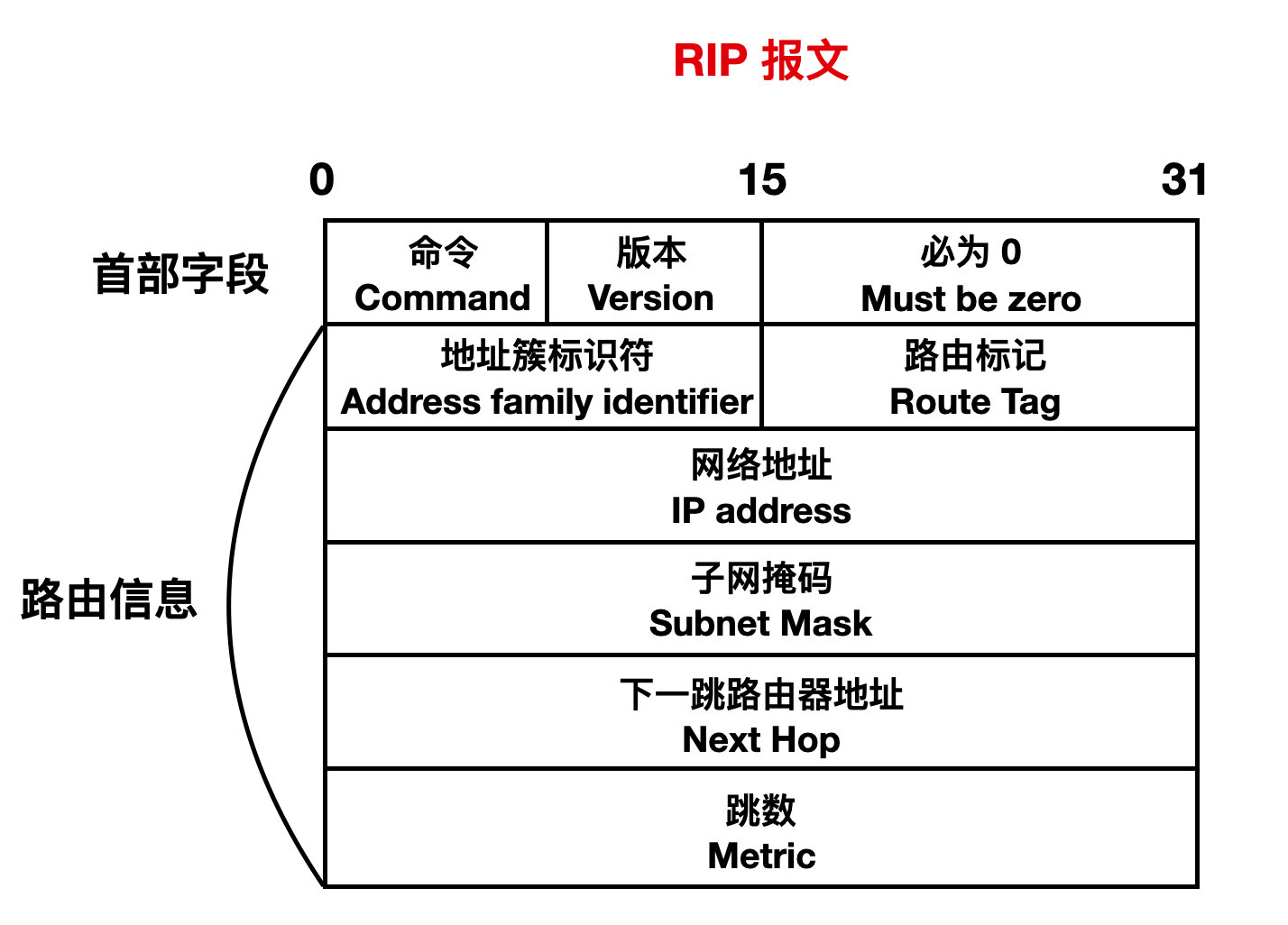
RIP 2 报文可以细分为首部部分和路由部分。
首部部分主要有命令、版本和必为 0字段,其中命令标识报文的类型,1 标识 Request 请求,向相邻路由请求全部或者部分路由信息;2 标识 Response 请求,向相邻路由器发送自己全部或者部分信息。然后是 RIP 版本,表示是 RIP 1 还是 RIP 2。后面的必为 0 其实主要为了要补齐 4 字节设计的。
下面是 RIP 报文的路由信息:
地址簇标识符:其值为 2 时表示 IP 协议。对于 Request 报文,此字段值为 0。路由标记:这个一般填入自治系统号,有可能存在 RIP 收到自治系统以外的路由选择信息。网络地址:这个就表示目的网络地址。子网掩码:目的地址的子网掩码。下一跳路由器地址:表示路由器的下一跳地址,如果为 0.0.0.0,则表示发布此路由的路由器地址就是最优下一跳地址。跳数:需要经过的路由数量。
RIP 存在一个问题是当网络故障时,会经过较长时间才能将信息同步到所有的路由器。
RIP 的主要问题以及解决办法
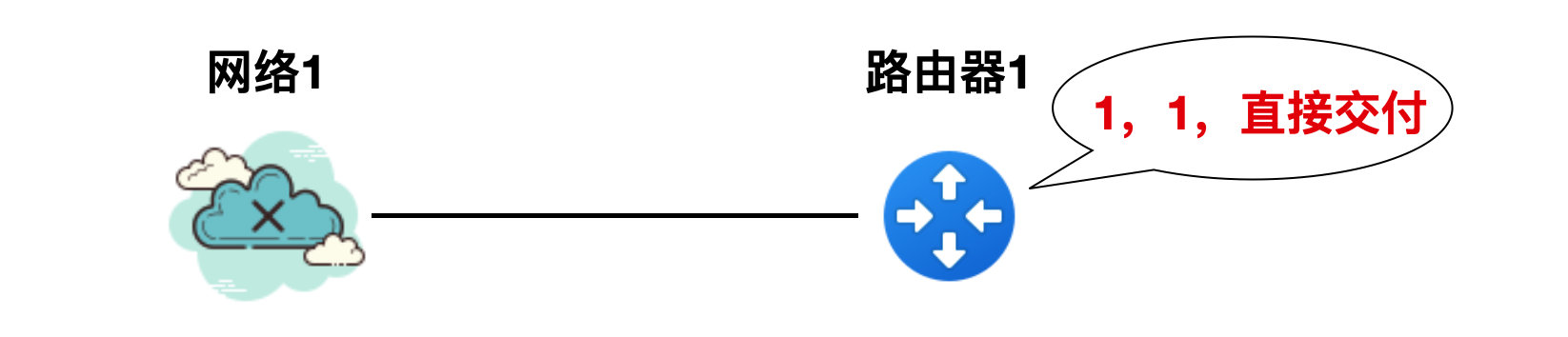
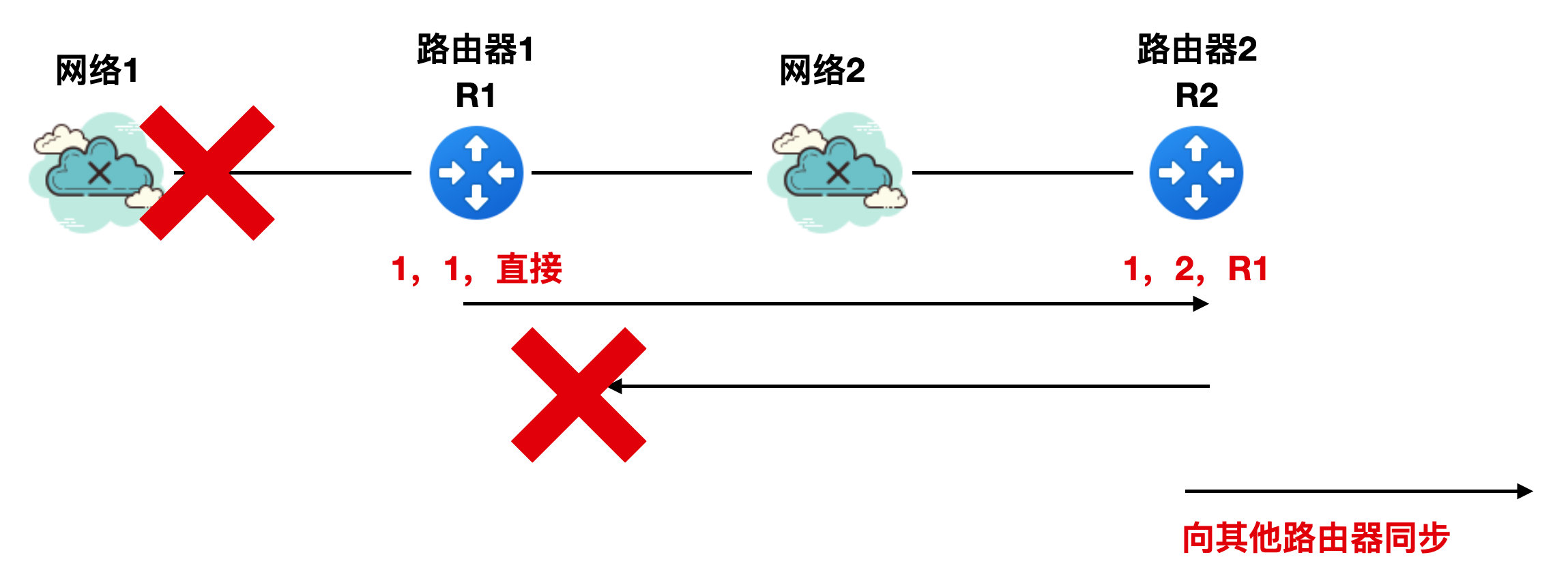
如下图所示,有一个网络1 和路由器 1,路由器 1 到网络 1 的 RIP 报文中的路由信息(为了方便描述,省略其他报字段信息)是"1,1,直接交付",这个意思就是说:到网络 1 的距离是 1 个路由器的跳数,是直连的方式。
此时加进来了网络 2 和路由器 R2,R2 到网络 1 的 RIP 报文是 “1,2,R1”,它表示路由器 R2 到网络 1 的距离是 2 跳,下一个路由器是 R1。
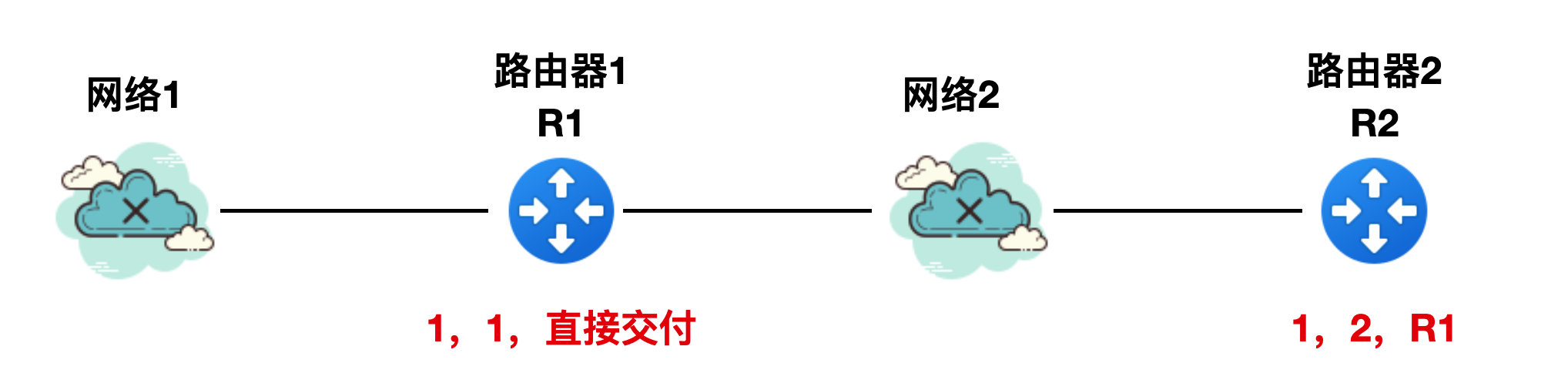
好了,上面两幅图中都能正常发送 RIP 报文,相安无事。此时网络 1 出现了故障,导致 R1 无法直接到达网络 1,那么R1、 R2 此时 RIP 的报文该如何发送呢?
实际上,与网络 1 直接相连的是 R1,所以 R1 首先知道网络 1 是不可用的,一旦 R1 知道网络 1 不可用,就会修改 RIP 报文为 “1,16,直接”,然后向 R2 同步路由表,如下图所示:
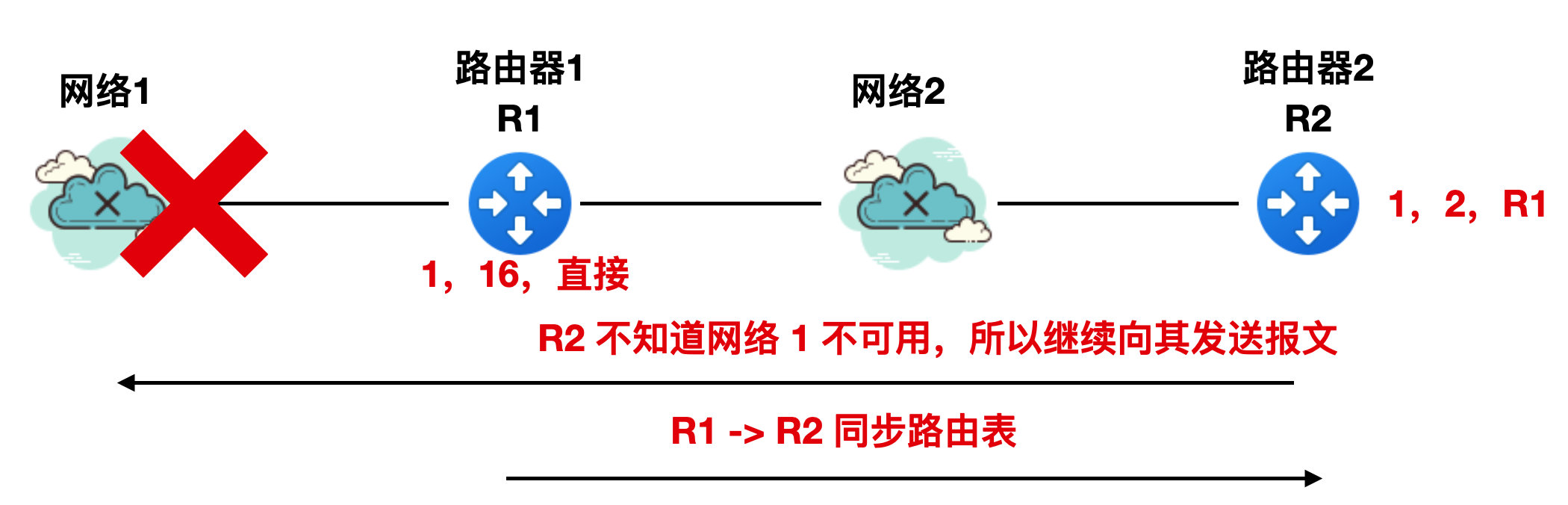
但是由于 RIP 协议本身的特性,这个路由表同步过程没那么快速的完成,而此时 R2 不知道网络 1 不可用,所以它还是继续经过 R1 向网络 1 发送报文。
一旦 R2 的报文发送给 R1 ,R1 就会认为经过 R2 可以到达网络 1 ,所以 R1 就会把 RIP 报文修改为 “1,3,R2”,表明我到网络 1 的距离是 3 跳,下一个路由器要经过 R2 ,如下图所示
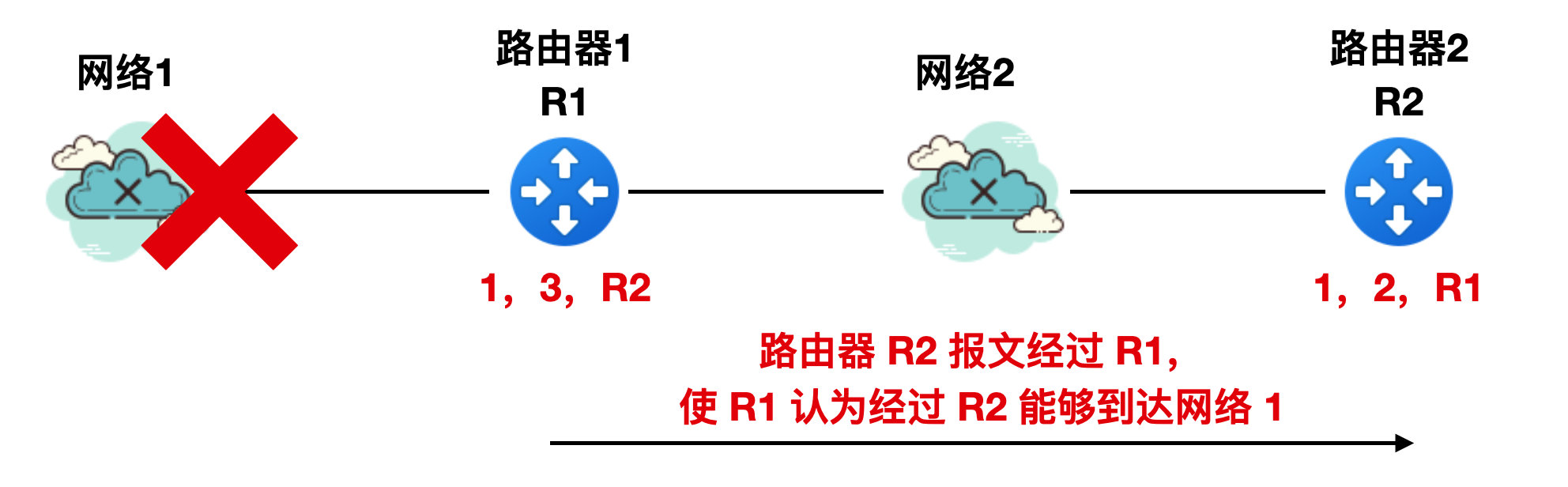
同理,R2 收到 R1 的报文后会将其 RIP 报文修改为 “1,4,R1”。。。。。。然后不断进行 R1 和 R2 的循环。
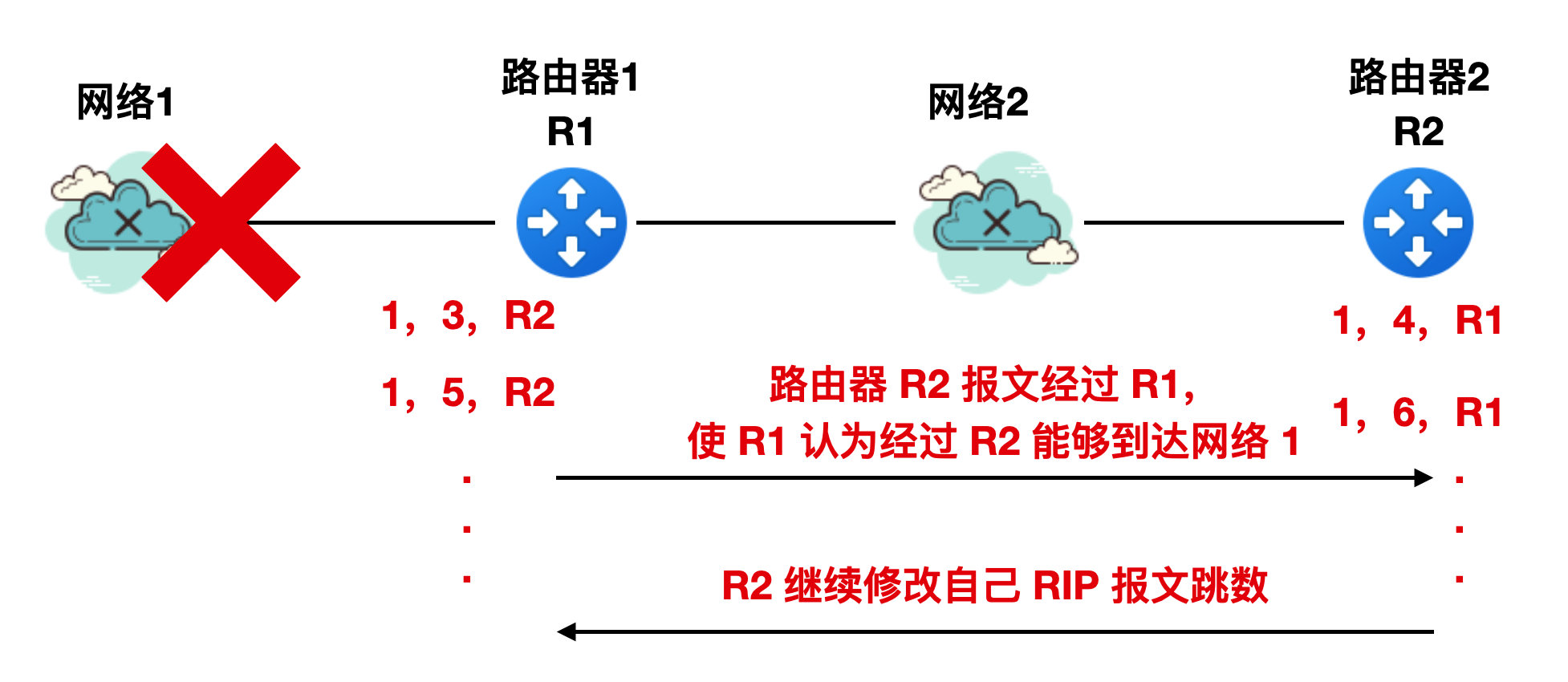
这个循环什么时候终止呢?
直到 R1 和 R2 的跳数都增大到 16 时,R1 和 R2 才直到网络 1 是不可达的。这不就是白干么?不过这就是 RIP 协议的一个特点。这个特点通俗一点来讲就是好消息传播的快,坏消息传播的慢。
有没有什么方法能够补救一下这种传播慢的方式?
一种方式就是控制跳数为 16,这相当于是从报文传输时间上进行控制;二是规定路由器不会再把收到的消息反向传输给发送端,这种方式被称为水平分割,如下图所示
还有一种方式就是当路由信息发生变化时,不等待一定的时间(例如 30 秒)而是直接发送出去,这看起来是更容易想到的方式,想想也是,网络都断了,还要等待 30 s 才发送,真的很鸡肋。
总之,因为其协议特征和报文限制了其只能用在小型网络中。
OSPF 协议
OSPF 是为了克服 RIP 的缺点在 1989 年开发出来的,OSPF 称为 开放最短路径优先 ( Open Shortest Path First ) 协议。注意虽然它被叫做最短路径优先协议,但是却并不能说明其他协议不是最短路径优先的,一般自治系统内的路由器都会选择一个最短路径来进行传输。
OSPF 使用的是分布式的链路状态协议,而非像 RIP 那样的距离向量协议。和 RIP 协议相比,OSPF 主要有下面这些变化:
- OSPF 会向自治系统内的所有路由器发送消息,OSPF 首先会向相邻的路由器发送消息,然后相邻的路由器又向与之相邻的路由器发送消息,渐渐的会同步所有的路由器。而 RIP 仅仅会向周围几个距离比较近的路由器发送消息。
- OSPF 发送的消息就是路由器相邻的所有路由器的链路状态,这些状态包括了路由器都与哪些路由器相邻,以及链路的 metric,其实就是 RIP 中的跳数。对于 RIP 协议来说,它仅仅会向相邻的路由器同步整个路由表。
- OSPF 会在链路发生变化时向所有路由器同步消息,而 RIP 在不管网络状态是否发生变化,都会定期交换路由表信息。
由此来看,OSPF 和 RIP 的区别还是比较大的。
由于 OSPF 会定期向周围的路由器同步链路信息,因此这些路由器可以建立一个链路状态数据库,每一个路由器都知道自治系统内有多少路由器,以及和这些路由器的 metric,因此每个路由器都可以以自己为根来构建一个路由表。RIP 协议虽然也能知道这些信息,只不过它无法知悉整个自治系统内的所有路由信息。
说了这么多,那为什么 OSPF 协议为啥比 RIP 协议更适用于大型网络?
首先 OSPF 没有跳数限制,而且 OSPF 会将自治系统划分为更小的区域,每个区域都有一个标识,当然区域的划分也是有范围的,最大不能超过 200 个,下面就是一个 OSPF 对自治系统内不同区域的划分。
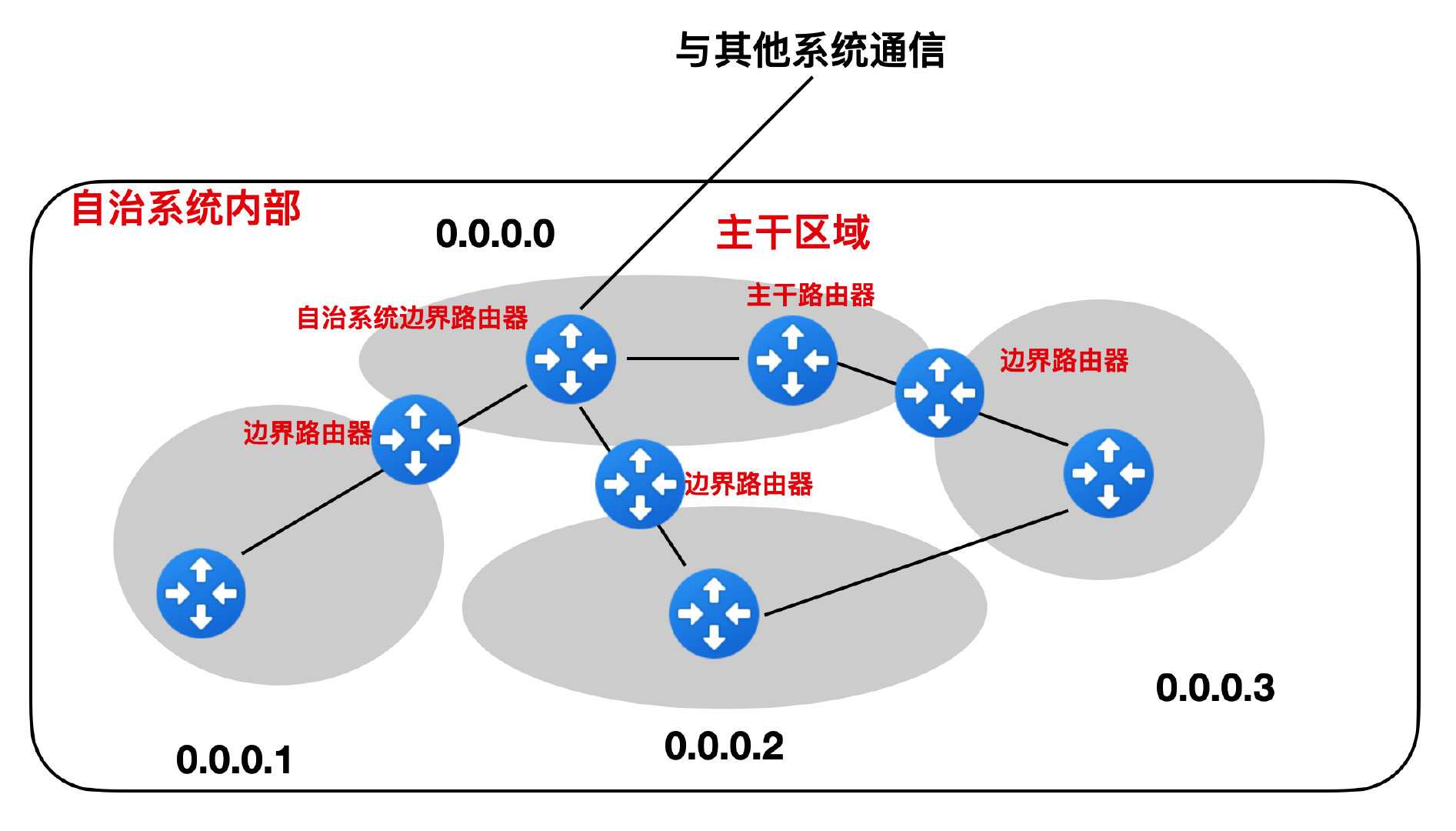
这么做的好处是能够提高区域内的消息传输效率,减少通信量。想象一下,如果是一个特别大的自治系统内部不做任何划分的话,那么每个路由器同步一次消息需要多大的通信量啊。
OSPF 的划分采用的是一种分层的方式,分为上下两层,在上层的叫做主干区域,主干区域的标识符规定为 0.0.0.0,主干区域的作用主要用来连接其他在下层的区域,每个区域内部都有负责和主干区域路由器通信的中间路由器,这个中间路由器叫做 区域边界路由器,而主干区域内的路由器叫做 主干路由器,主干路由器可以是区域边界路由器,在所有的主干路由器中,还有一个负责和外部自治系统进行通信的路由器,这个路由器叫做自制边界系统路由器。
分层思想虽然解决了 OSPF 内通信量庞大的问题,但是通信的种类大大增加,让 OSPF 这个协议变的很复杂。不过,分层的思想是极其重要的,因为任何大型网络也好,操作系统也好,都会体现分层的思想,毕竟解耦是一门艺术。
OSPF 没有使用任何传输层协议进行通信,相反的它会直接传输 IP 数据报。
那么问题来了,为什么还有协议不会使用传输层协议传输报文呢?
因为 OSPF 需要执行可靠的多播操作,它会尽可能和自治系统内的多个邻居路由器通信,而 TCP 是不支持多播的,并且 UDP 无法保证可靠传输,所以 OSPF 实现了自己的传输机制,从而绕过了 TCP 和 UDP。
OSPF 构成的数据包不大,这样可以减少通信量,还有一个好处就是不必将数据包进行分片,因为但凡分片后的数据片丢失任意一个,就无法组装成发送的数据包,必须进行重传。
下面是 OSPF 的报文以及各个字段的含义。
( 1 ) 版本 Version :当前 OSPF 版本号是 v2 ,主要标准是 RFC 1583 和 RFC 2328。
( 2 ) 类型 Type:OSPF 的报文类型有五类,这个类型可以表示任何一类 OSPF 报文。
( 3 ) 分组长度 Packet length:包括 OSPF 首部在内的分组长度,以字节为单位。
( 4 ) 路由器标识符 Router ID:标志这个分组是由哪个路由器接口发出的,这个路由器的 IP 地址。
( 5 ) 区域标识符 Area ID:表示这个分组属于哪个区域,它的一个标识符。
( 6 ) 检验和:用于检测分组中是否出现差错。
( 7 ) 鉴别类型:目前只有两种鉴别类型,0 (不用) 和 1(口令)。
( 8 ) 鉴别:鉴别类型为 0 是鉴别就填 0 ,为 1 时鉴别就填入 8 个字符口令。
OSPF 除了上述这些报文的特点之外,还有一些其他特点:
( 1 ) 如果到一个目的网络有多条相同 metric 的路径,那么 OSPF 会通过负载均衡的方式来使用每一条路径。
( 2 ) OSPF 允许管理员手动的设置 metric,如果是敏感的业务就可以设置较高的 metric,如果对于敏感性要求没那么高,就可以设置较低的 metric。 这在 RIP 中根本不可能,RIP 只允许一条最短路径。
( 3 ) OSPF 分组具有鉴别功能,这保证了传输链路信息的安全性。
( 4 ) OSPF 支持可变长度的子网划分和无分类编址 CIDR 。
( 5 ) 由于网络中的链路状态经常会发生变化,因此 OSPF 会让每一个链路带上一个 32 位的序号,序号越大状态越新。
上面说到 OSPF 有五种报文类型,主要有下面这五种:
- 类型 1 :hello 报文,这个报文会定期以组播的形式发送,主要作用就是维护和邻居路由器的可达性,确保能够双向通信,但是并不是所有的报文都会建立关系,必须和报文中的所有字段都匹配后,才能建立。下面是 hello 报文的字段。

Nestwork Mask:网络掩码。
Hello Interval:发送 hello 报文的时间间隔。默认情况下,OSPF 在 P2P 或广播类型的接口上发送 hello 间隔为10 s,在 NBMA 和 P2MP 类型接口上hello间隔为 30 s。
Options:可选项,路由器通过设置 options 字段来通告自己能够支持某种特性
Router Pri:路由器优先级
Router Dead Interval :路由器失效时间。默认情况下该路由接口为 hello interval 的 4 倍关系,如果在此时间内未收到邻居发来的 hello 报文,则认为邻居失效。
Designated Router:指定路由器。如果字段为 0.0.0.0 表示 DR 尚未指定或者没有 DR。
Backup Designated Router:备份指定路由器。网络中 BDR 的接口 IP 地址。如果字段为 0.0.0.0 表示 BDR 尚未指定或者没有 BDR。
Neighbor:邻居。此处填充的是邻居的 Router ID。
- 类型 2 :数据库分组(Database Description),用于向相邻站点同步自己的链路数据库中的链路状态信息。

Interface MTU:最大接口数据单元,由此接口发出最大的 IP 数据长度,默认为 0 。
I:initial bit,初始标志位,当连续发送多个 DD 报文时,如果此报文时第一个就是 1 ,否则就是 0 。
M:more ,如果设置为1表示后面还有其他的 DD 报文,如果这是最后一个 DD 报文则设置为 0。
M/S:此位设置为 1 表示为 master 路由器。
DD sequence number DD 报文序列号。主从双方利用序列号来保证 DD 报文传输的可靠性和完整性。
LSA headers:DD 报文中所含 LSA 的头部信息。
- 类型 3:链路状态请求 ( Link State Request ) 分组,用 LSR 报文请求完整的 LSA 消息。

LS Type :链路状态类型。
Link State ID:LSA 标识。
Advertising Router:产生该 LSA 的路由器 Router ID。
- 类型 4: 链路状态更新 ( Link State Update ) 分组,

路由器收到 LSR 后会以 LSU 报文进行回应,在 LSU 报文中就包含了对方请求的 LSA 完整的信息。
详细的 LSA 报文通常会分开来写,包括 LSA Header,Router-LSA,Network-LSA。
- 类型 5: 链路状态确认 ( Link State Acknowledgment ) 分组,用来对接受到的 LSU 报文进行确认。内容是需要确认的 LS A的 header,一个 LSACK 报文可以对多个 LSA 进行确认。

OSPF 规定,每隔 10 s 就要交换一次 Hello 分组,来判断网络链路是否可达,这就很像某种心跳检测机制。路由表就会根据 Hello 分组的检测结果来制定的。在正常情况下,绝大多数分组都是 Hello 分组,如果在 40 s 内没有收到发过来的 Hello 分组,就会认为相邻路由器不可达,应该立刻修改链路状态数据库中所记录的链路信息,还要重新制定路由表。
其他四种 OSPF 报文都是用来进行链路状态数据库同步的。这个同步的意思就是说不同路由器的链路状态相同。两个同步的路由器被称为完全相邻的。并不是在物理距离上离的比较近就被称为相邻,而是要判断它的链路状态。
总结一下上面五种报文类型的用途:通过发送 Hello 报文确认是否连接;通过 DD 分组来进行链路状态信息同步;在路由运行阶段,通过链路状态请求包请求路由控制信息,然后由链路状态更新包接收路由同步信息,最后通过链路状态确认包通知已接收到路由控制信息。
当新加一个路由器开始工作时,它不知道应该向谁同步链路信息,所以它需要通过分组来判断相邻的路由器都有哪些,以及向相邻路由器发送的 metric 是多少,如果所有的路由器都把自己的状态信息对全网进行广播的话,那么各个路由器把链路状态信息组合起来就能得到状态链路数据库,不过这样开销太大了。
所以,OSPF 通过使用数据库分组和相邻路由器交换链路信息状态来得到全网的状态链路数据库,下面是组合成状态链路数据库所需要发送过的 OSPF 报文。
这样一来,就会建立状态链路数据库,在网络运行过程中发生路由状态变更的话,只需要发送链路状态更新分组即可,更新完成后需要发送链路状态确认报文。
而且 OSPF 不像 RIP 一样具有好消息传播快,坏消息传播慢的问题。
原文链接:万字长文爆肝路由协议!
公众号干货很多,欢迎大家关注。
版权归原作者 程序员cxuan 所有, 如有侵权,请联系我们删除。