
主要实现的AI算法有:目标检测、目标追踪
主要实现AI算法功能:越界识别功能(主要是获取统计人流量)
平台:基于Aidlux平台
基础库安装:
(1)lap安装:
先sudo apt-get update,再输入sudo apt-get install -y cmake build-essential python3-dev;最后pip install lap -i https://pypi.tuna.tsinghua.edu.cn/simple。
(2)cython_bbox安装:
先安装cython:pip install cython -i https://pypi.tuna.tsinghua.edu.cn/simple
再安装cython_bbox:pip install cython_bbox -i https://pypi.tuna.tsinghua.edu.cn/simple
(3)torch安装:
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple,如果有安装过则跳过。
(4)torchvision安装:
pip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple,如果有安装过,则跳过。
(5)thop安装:
pip install thop -i https://pypi.tuna.tsinghua.edu.cn/simple
一、前提:
我们通常学习的AI视觉算法,主要是底层的应用技术,比如目标检测、人脸识别、图像分割、关键点检测、语音识别、OCR识别等算法。通常而言,在各个行业实际应用中,不同的场景,对应不同的算法功能,而不同的算法功能则由不同应用技术组合而成。如下图:
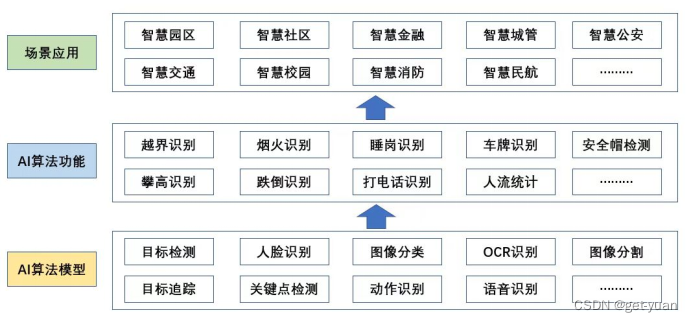
而今天这个人流量的统计应用主要用到的AI算法功能是越界识别,它主要是由基于yolov5框架的目标检测算法和基于Bytetrack多目标追踪算法(当然使用Deepsort多目标追踪算法也是可以的)
以下是论文地址分享:
Deepsort多目标追踪算法论文PDF:
DeepSort多目标追踪算法http://extension//idghocbbahafpfhjnfhpbfbmpegphmmp/assets/pdf/web/viewer.html?file=https://arxiv.org/pdf/1703.07402v1.pdf
Bytetrack多目标追踪算法论文PDF:
Bytetrack多目标追踪算法http://extension//idghocbbahafpfhjnfhpbfbmpegphmmp/assets/pdf/web/viewer.html?file=https://arxiv.org/pdf/2110.06864v3.pdf
实现效果:
personcount
代码实现:
目标检测模块(主要是基于yolov5):
打开yolov5.py进行视频推理测试
# aidlux相关from cvs import *import aidlite_gpufrom utils import detect_postprocess, preprocess_img, draw_detect_resimport timeimport cv2# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidliteaidlite = aidlite_gpu.aidlite()# Aidlite模型路径model_path = '/home/lesson4_codes/aidlux/yolov5n_best-fp16.tflite'# 定义输入输出shapein_shape = [1 * 640 * 640 * 3 * 4]out_shape = [1 * 25200 * 6 * 4]# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)cap = cvs.VideoCapture("/home/lesson4_codes/aidlux/market.mp4")frame_id = 0while True: frame = cap.read() if frame is None: continue frame_id += 1 if not int(frame_id) % 5 == 0: continue # 预处理 img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None) # 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32 aidlite.setInput_Float32(img, 640, 640) # 模型推理API aidlite.invoke() # 读取返回的结果 pred = aidlite.getOutput_Float32(0) # 数据维度转换 pred = pred.reshape(1, 25200, 6)[0] # 模型推理后处理 pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.5, iou_thres=0.45) # 绘制推理结果 res_img = draw_detect_res(frame, pred) cvs.imshow(res_img)
效果截图:
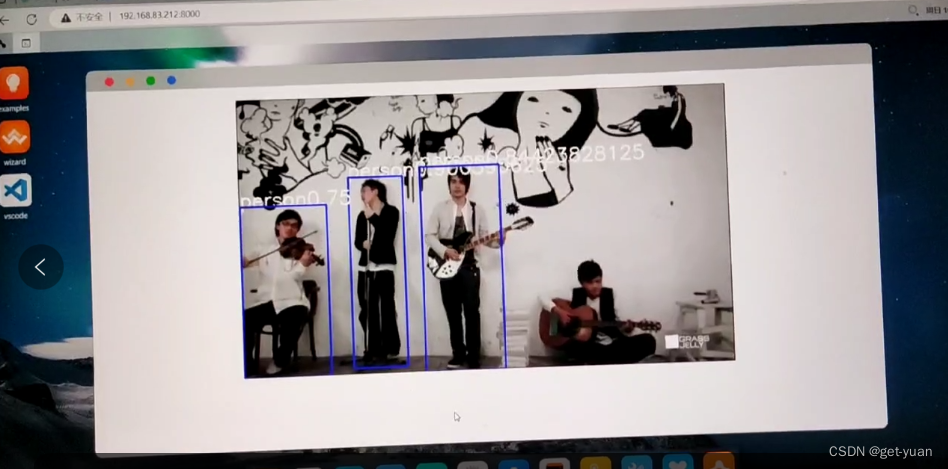
视频效果:
目标检测
标签中的person代表是人,分数代表的是置信度也等同于说这个框内的物体是人的概率值。
目标追踪模块(主要是基于Bytetrack多目标追踪算法):
打开yolov5_bytetrack.py进行视频推理测试
from cvs import *import aidlite_gpufrom utils import detect_postprocess, preprocess_img, draw_detect_res #scale_coords,process_points,isInsidePolygon,is_in_polyimport cv2# bytetrackfrom track.tracker.byte_tracker import BYTETrackerfrom track.utils.visualize import plot_tracking# 加载模型model_path = r'/home/lesson5_codes/aidlux/yolov5n_best-fp16.tflite'in_shape = [1 * 640 * 640 * 3 * 4]out_shape = [1 * 25200 * 6 * 4]# 载入模型aidlite = aidlite_gpu.aidlite()# 载入yolov5检测模型aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)tracker = BYTETracker(frame_rate=30)track_id_status = {}cap = cvs.VideoCapture(r"/home/lesson5_codes/aidlux/videotest1.mp4")frame_id = 0while True: frame = cap.read() if frame is None: continue frame_id += 1 if frame_id % 3 != 0: continue # 预处理 img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None) # 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32 aidlite.setInput_Float32(img, 640, 640) # 模型推理API aidlite.invoke() # 读取返回的结果 pred = aidlite.getOutput_Float32(0) # 数据维度转换 pred = pred.reshape(1, 25200, 6)[0] # 模型推理后处理 pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45) # 绘制推理结果 res_img = draw_detect_res(frame, pred) # 目标追踪相关功能 det = [] # Process predictions for box in pred[0]: # per image box[2] += box[0] box[3] += box[1] det.append(box) if len(det): # Rescale boxes from img_size to im0 size online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]]) online_tlwhs = [] online_ids = [] online_scores = [] # 取出每个目标的追踪信息 for t in online_targets: # 目标的检测框信息 tlwh = t.tlwh # 目标的track_id信息 tid = t.track_id online_tlwhs.append(tlwh) online_ids.append(tid) online_scores.append(t.score) # 针对目标绘制追踪相关信息 res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0) cvs.imshow(res_img)
效果截图:
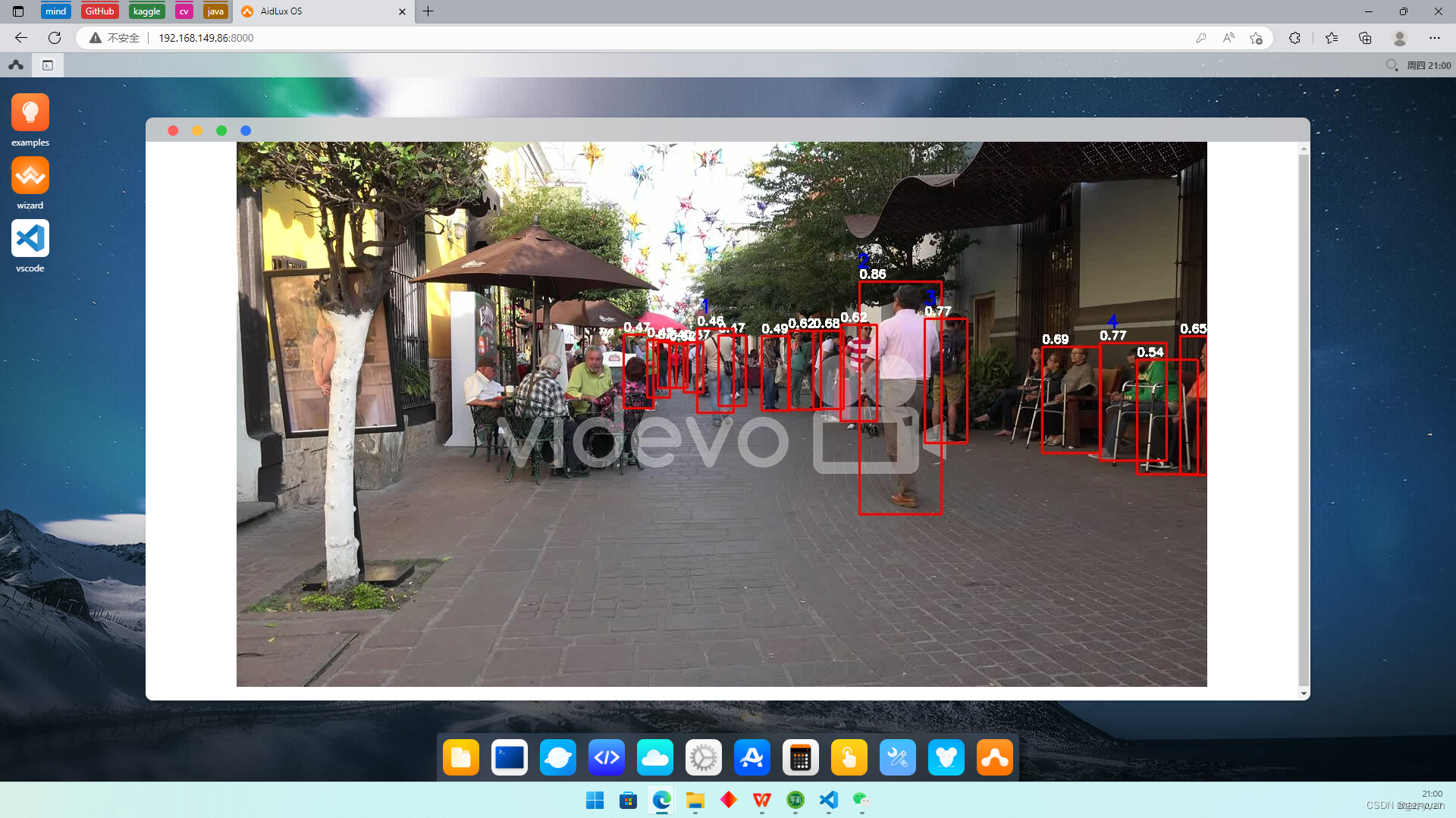
标签上的蓝色数字为track_id,可以理解为每个人框的id号,代表着一个物体,白色数字则为置信度。
实现人流数量统计功能:
将物体检测模块与物体追踪模块相结合:
代码如下:
from cvs import *import aidlite_gpufrom utils import detect_postprocess, preprocess_img, draw_detect_res, process_points,is_passing_line #scale_coords,isInsidePolygon,import cv2# bytetrackfrom track.tracker.byte_tracker import BYTETrackerfrom track.utils.visualize import plot_trackingimport requestsimport time# 加载模型model_path = '/home/lesson4_codes/aidlux/yolov5n_best-fp16.tflite'in_shape = [1 * 640 * 640 * 3 * 4]out_shape = [1 * 25200 * 6 * 4]# 载入模型aidlite = aidlite_gpu.aidlite()# 载入yolov5检测模型aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)tracker = BYTETracker(frame_rate=30)track_id_status = {}cap = cvs.VideoCapture(r"/home/lesson5_codes/aidlux/videotest1.mp4")frame_id = 0count_person=0while True: frame = cap.read() if frame is None: ###相机采集结果### print("camer is over!") ### 统计打印人流数量 ### # 填写对应的喵码 id = '******' # 填写喵提醒中,发送的消息,这里放上前面提到的图片外链 text = "人数统计:"+str(count_person) ts = str(time.time()) # 时间戳 type = 'json' # 返回内容格式 request_url = "http://miaotixing.com/trigger?" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'} result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers) break frame_id += 1 if frame_id % 3 != 0: continue # 预处理 img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None) # 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32 aidlite.setInput_Float32(img, 640, 640) # 模型推理API aidlite.invoke() # 读取返回的结果 pred = aidlite.getOutput_Float32(0) # 数据维度转换 pred = pred.reshape(1, 25200, 6)[0] # 模型推理后处理 pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45) # 绘制推理结果 res_img = draw_detect_res(frame, pred) # 目标追踪相关功能 det = [] # Process predictions for box in pred[0]: # per image box[2] += box[0] box[3] += box[1] det.append(box) if len(det): # Rescale boxes from img_size to im0 size online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]]) online_tlwhs = [] online_ids = [] online_scores = [] # 取出每个目标的追踪信息 for t in online_targets: # 目标的检测框信息 tlwh = t.tlwh # 目标的track_id信息 tid = t.track_id online_tlwhs.append(tlwh) online_ids.append(tid) online_scores.append(t.score) # 针对目标绘制追踪相关信息 res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0) ### 越界识别功能实现 ### # 1.绘制越界监测区域 points = [[204,453],[1274,455]] color_light_green=(255, 0, 0) ##绿色 res_img = process_points(res_img,points,color_light_green) # 2.计算得到人体下方中心点的位置(人体检测监测点调整) pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]] # 3. 人体和违规区域的判断(人体状态追踪判断) track_info = is_passing_line(pt, points) if tid not in track_id_status.keys(): track_id_status.update( {tid:[track_info]}) else: if track_info != track_id_status[tid][-1]: track_id_status[tid].append(track_info) # 4. 判断是否有track_id越界,有的话保存成图片 # 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了 if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1: # 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值 if track_id_status[tid][-2] == -1: track_id_status[tid].append(3) count_person+=1 cv2.putText(res_img,"-1 to 1 person_count:"+str(count_person),(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),2) cvs.imshow(res_img)
实现效果视频展示已经放在了文章的开头:
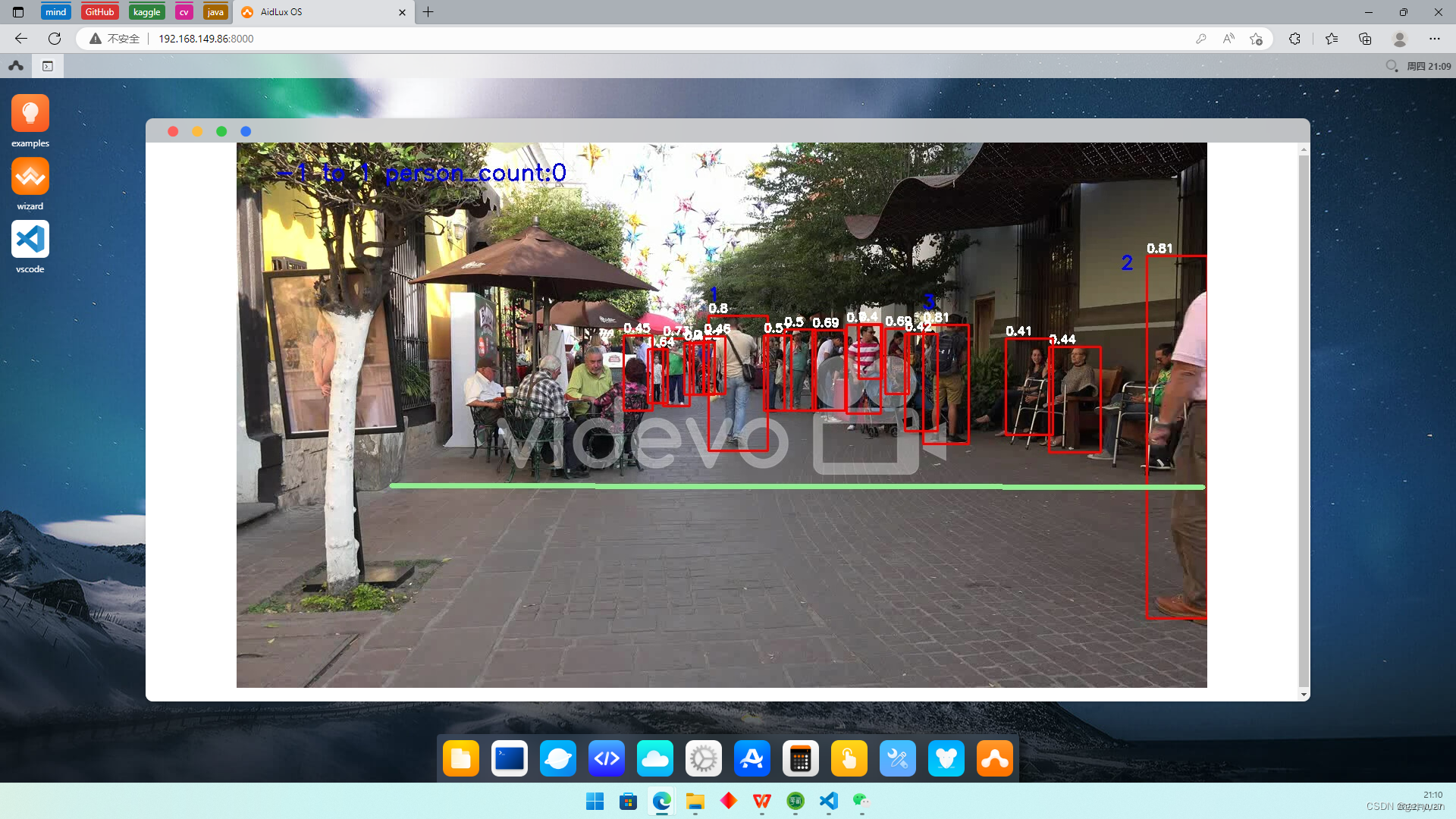
每有一个人通过那条绿线,person_count就会增1,最后人数统计完后,会通过喵提醒功能,将统计人数发送到手机微信端:
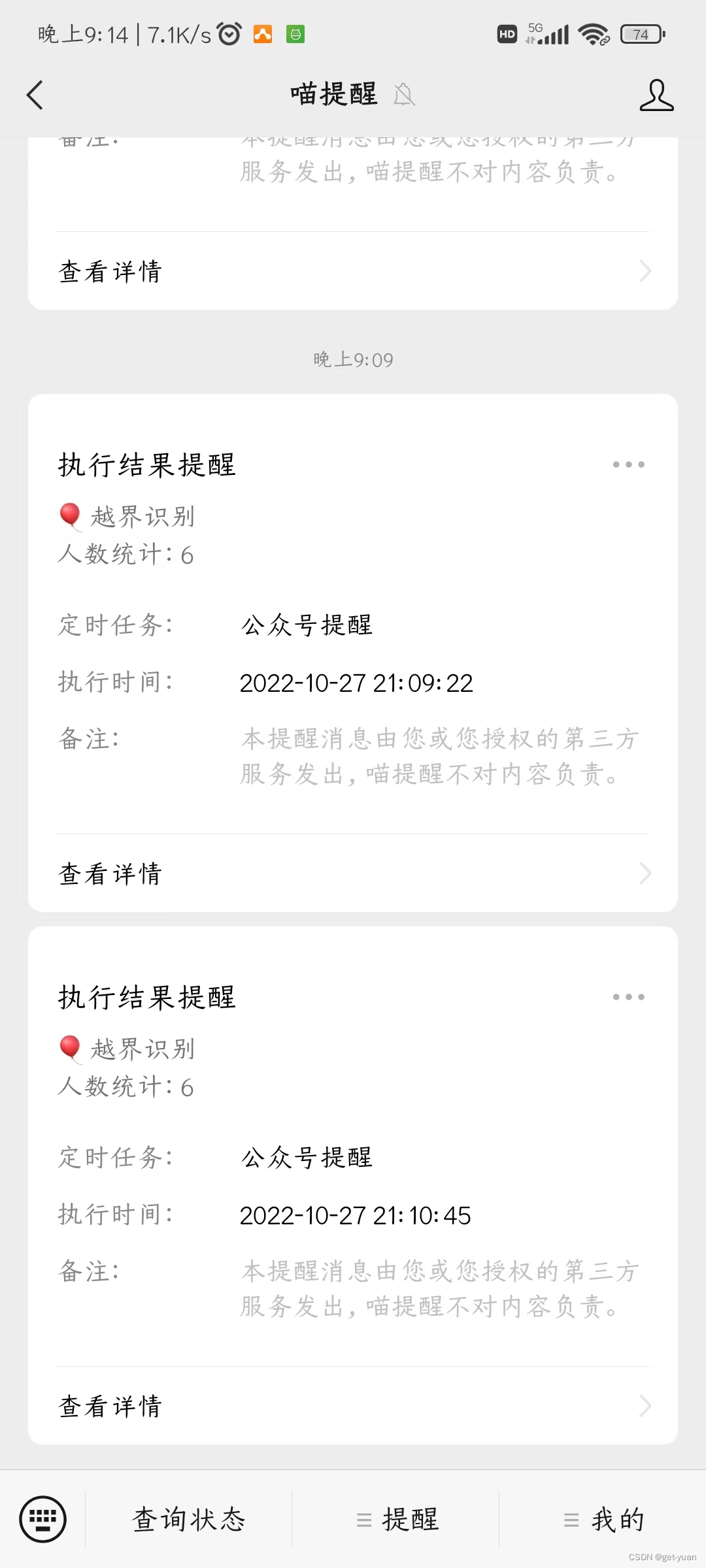
其实整体实现的逻辑也很简单,主要分为五个部分:
(1)人流统计越界线段绘制
# 1.绘制越界监测区域 points = [[204,453],[1274,455]] color_light_green=(255, 0, 0) ##绿色 res_img = process_points(res_img,points,color_light_green)
(2)人体检测统计点调整
主要分析人体下方中心点,和人流统计线段的位置关系。检测框的四个点信息,[左上角点x,左上角点y,宽w,高h]。所以我们需要通过代码,转换成人体下方的点,即[左上角点x+1/2*宽w,左上角点y+高h]。
# 2.计算得到人体下方中心点的位置(人体检测监测点调整) pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]]
(3)人体和线段的位置状态判断
这里主要分析人体下方点,和统计线段的位置关系,这部分的代码在utils.py的is_passing_line函数中。当人体在线段的下方时,人体状态是-1。当人体在线段的上方时,人体状态是1。
# 3. 人体和违规区域的判断(人体状态追踪判断) track_info = is_passing_line(pt, points) if tid not in track_id_status.keys(): track_id_status.update( {tid:[track_info]}) else: if track_info != track_id_status[tid][-1]: track_id_status[tid].append(track_info)
(4)人流统计分析判断
那么当人体的状态,从-1变化到1的时候,就统计成为人员越线了。
4. 判断是否有track_id越界 # 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了 if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1: # 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值 if track_id_status[tid][-2] == -1: track_id_status[tid].append(3) count_person+=1
(5)喵提醒发送
当整个视频跑完后,就可以得到人流统计整体的数据了。为了及时知道人流的信息状态,我们也可以将最后的结果,以喵提醒的方式进行发送。
if frame is None: ###相机采集结果### print("camer is over!") ### 统计打印人流数量 ### # 填写对应的喵码 id = '******' # 填写喵提醒中,发送的消息,这里放上前面提到的图片外链 text = "人数统计:"+str(count_person) ts = str(time.time()) # 时间戳 type = 'json' # 返回内容格式 request_url = "http://miaotixing.com/trigger?" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'} result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers) break
目前只是简单的介绍了各个模块的相应功能,由于篇幅较多,后续会对每个相应模块进行搭建和详细代码解释。
学习心得
刚开始进行代码实际操作时,对项目的搭建有点吃力,尤其是刚开始对AidLux平台中的环境配置时,由于第一次使用,不太熟悉操作,花费了很多时间,不过幸亏江大白老师非常耐心的给予解答,才事半功倍,同时经过一阵子的学习也培养了我debug程序的能力,这段时间通过对yolo框架源码的学习以及论文的阅读,大大的提高了我对yolo框架的认知和使用(虽然用的并不是那么熟练)
AidLux使用心得
先介绍下什么是AidLux?
本次人流统计项目使用到了AidLux平台,等同于大家所说的边缘设备,虽然用的是边缘设备,但是却是以安卓和Linux双系统的方式,只使用Python就能对算法加速优化。通常AI项目边缘设备落地方案有很多,AI边缘设备是非常重要的算力载体设备。 其中非常关键的,就是AI芯片,当然市面上的销售方式,主要有两种:
(1)AI芯片模组:公司自研AI芯片,比如寒武纪,对外销售的主要是AI芯片模组,由一些外部的设备公司再集成到边缘设备或者工控机,以设备公司的品牌对外销售;
(2)AI边缘设备:以销售AI边缘设备为主,比如英伟达,算能科技,阿加犀。通常会自研或者采购AI芯片,并以AI边缘设备的形态对外销售,为很多AI解决方案公司提供算力设备;当然其中的一些自研AI芯片的公司,除了边缘设备之外,也会提供AI芯片/模组方面的产品,直接对外销售,比如算能科技。
当然一般来说,想要玩转边缘设备,通常会开发一整套的视频结构化功能。通过C++的方式调用算力,将需要处理的结构化信息输出,比如编程Json形式,为后面的业务处理提供分析的信息。常规来说,市面上所有的边缘设备,主要是以C++的方式来进行开发。不过这里使用的另外一种边缘设备开发的方案,即以Python的方式。好处在于,算法工程师使用Python开发的模型,可以直接无缝衔接来继续开发应用了。比如采用AidBox GS865边缘设备。

这里所说的边缘设备AidBox,主要是采用高通ARM端芯片开发的。不过我们在学习的时候,都没有AidBox边缘设备硬件。因此也可以采用另外一种思路,即AidLux边缘设备软件,这个环境和现实的边缘计算设备AidBox基本一样。
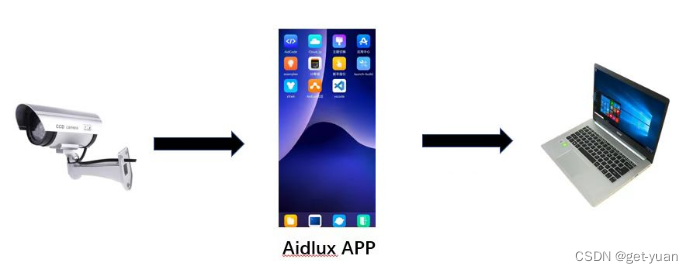
当然AidLux中还存在着一些小bug和适配的问题,比如我的手机是安卓12的,当AidLux后端运行时常常会被手机系统清理掉,就算我设置为白名单也不行。后面需要使用开发者调试进行修改。当运行了代码时,你会在手机版本的Aidlux和PC端网页的Aidlux中,都可以看到推理的显示结果,需要注意的是,在运行的时候,需要把手机版本里面的aidlux页面叉掉,不然可能会有冲突,运行的线程会直接被killed掉。刚开始我就是没注意到这点,非常痛苦的在那儿找错。
更新时间(2022/10/27 22:04:00)后期持续更新~~~
版权归原作者 get-yuan 所有, 如有侵权,请联系我们删除。