
高可用
高可用背景
单点故障、高可用
单点故障:
(single point of failure 缩写
spof
)是指的是系统中某一点一旦失效,就会让整个系统无法运作,
换句话说单点故障会造成整体故障
**
高可用:
**(high availablelity 缩写
HA
),指系统无中断的执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统意味着系统服务可以更长时间运行,通常通过提高系统的容错率来实现。
高可用性或者高可靠度的系统不会希望有单点故障造成整体故障的情形。一般可以通过冗余的方式增加多个相同机能的的不见,只要这些部件没有同时失效,系统(或至少部分系统)仍可运作,这会让可靠度提高。
实现高可用
主备集群
解决单点故障,实现系统服务高可用的核心并不是让故障永不发生,而是让故障的发生对业务的影响降到最小。因为软硬件故障是难以避免的问题。
当下企业中成熟的做法就是给单点故障的位置设置备份,形成主备架构。通俗描述就是当主挂掉,备份顶上,短暂的中断之后继续提供服务。
常见的是一主一备架构,当然也可以一主多备。备份越多,容错能力越强,与此同时,冗余也越大,浪费资源。

Active、Standby
Active:主角色。活跃的角色,代表正在对外提供服务的角色服务。任意时间有且只有一个active对外提供服务。
Standby:备份角色。需要和主角色保持数据、状态同步,并且时刻准备切换成主角色(当主角色挂掉或者出现故障时),对外提供服务,保持服务的可用性。
可用性评判标准- x个9
在系统的高可用性里有个衡量其可靠性的标准——X个9,这个X是代表数字3-5。X个9表示在系统1年时间的使用过程中,系统可以正常使用时间与总时间(1年)之比。
- 3个9:(1-99.9%)36524=8.76小时,表示该系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
- 4个9:(1-99.99%)36524=0.876小时=52.6分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
- 5个9:(1-99.999%)36524*60=5.26分钟,表示该系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
9越多系统的可靠性越强,能容忍的业务中断时间越少,但是要付出成本更高
HA系统设置核心问题
1、脑裂问题
脑裂(split-brain)是指“大脑分裂”,本是医学名词。在HA集群中,脑裂指的是当联系主备节点的"心跳线"断开时(即两个节点断开联系时),本来为一个整体、动作协调的HA系统,就分裂成为两个独立的节点。由于相互失去了联系,主备节点之间像"裂脑人"一样,使得整个集群处于混乱状态。脑裂的严重后果:
1)集群无主:都认为对方是状态好的,自己是备份角色,后果是无服务;
2)集群多主:都认为对方是故障的,自己是主角色。相互争抢共享资源,结果会导致系统混乱,数据损坏。此外客户端也无法确定到底找谁去提供服务
避免脑裂问题的核心是:保持任意时刻系统有且只有一个主角色提供服务。
2、数据同步问题
主备切换保证服务持续可用性的前提是主备节点之间的状态、数据是一致的,或者说准一致的。如果说备用的节点和主节点之间的数据差距过大,即使完成了主备切换的动作,那也是没有意义的。
数据同步常见做法是:通过日志重演操作记录。主角色正常提供服务,发生的事务性操作通过日志记录,备用角色读取日志重演操作。9
HDFS NameNode单点故障问题
在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。每个群集只有一个NameNode,如果该计算机或进程不可用,则整个群集在整个NameNode重新启动或在另一台计算机上启动之前将不可用。
NameNode的单点故障从两个方面影响了HDFS群集的总可用性:
- 如果发生意外事件(例如机器崩溃),则在重新启动NameNode之前,群集将不可用。
- 计划内的维护事件,例如NameNode计算机上的软件或硬件升级,将导致群集停机时间的延长。
HDFS高可用性解决方案:在同一群集中运行两个(从3.0.0起,超过两个)冗余NameNode。这样可以在机器崩溃的情况下快速故障转移到新的NameNode,或者出于计划维护的目的由管理员发起的正常故障转移。

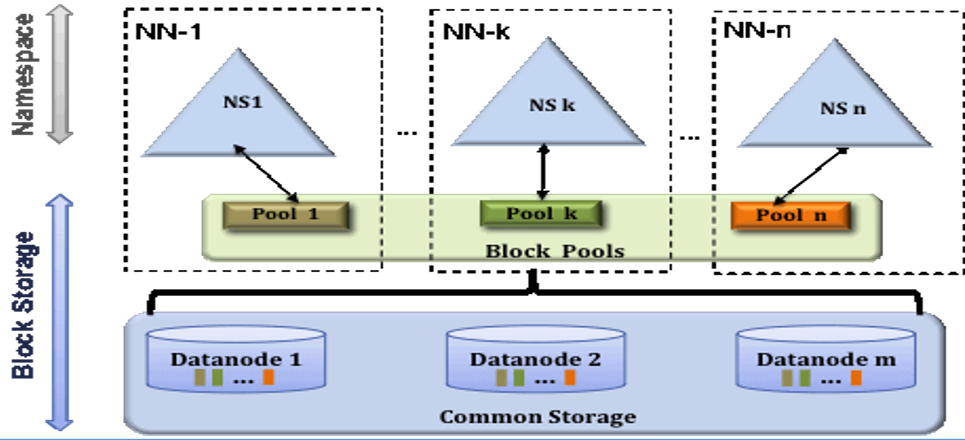
HDFS HA解决方案 -QJM
- QJM 全称
Quorum Journal Manager(仲裁日志管理器),时Hadoop官方最推荐的HDFS HA解决方案 - 使用zookeeper中的ZKFC来实现主备切换
- 使用Journal Node(JN)来实现edits log的共享以达到数据同步的目的
QJM—主备切换、脑裂问题解决
ZKFC(ZK Failover Controller)
ZKFC是一个Zookeeper客户端,主要职责有:
- 监视和管理NameNode健康状态ZKFC通过命令监视的NameNode节点及机器的健康状态
- 维持和ZK集群联系如果本地NameNode运行状态良好,并且ZKFC看到当前没有其他节点持有锁znode,他将自己尝试获取该锁,如果成功,则表明它‘赢得了选举’,并负责运行故障转移以使其本地NameNode处于Active状态,如果已经有其他节点持有锁,zkfc选举失败,则会对该节点注册监听,等待下次继续选举

主备切换、脑裂问题的解决–Fencing(隔离)机制
- 故障转移过程俗称主备角色切换过程,切换过程中最怕的就是脑裂的发生,因此需要Fencing机制来避免,将先前的Active节点隔离,然后将Standby转换为Active状态
- Hadoop公库中对外提供两种Fencing实现,分别是sshfence和shellfence(缺省实现)
sshfence是指通过ssh登录到目标节点上,使用命令fuser将进程杀死(通过tcp端口号定位进程pid,该方法比ips命令更加准确)
shellfence是指执行一个用户事先定义好的shell命令(脚本)完成隔离。
主备数据状态同步问题
- Journal Node (JN)集群是轻量级的分布式系统,主要用于高速读写数据、存储数据
- 通常使用2N+1台Journal Node 存储共享Edits Log(编辑日志)。低等类似于ZK的分布式一致性算法
- 任何修改操作在Active NN上执行时,Journal Node进程同时也会记录edits log 到至少半数以上的JN中,这是Standby NN检测到JN里面的同步log发生变化了会读取JN里面的edits log,然后重演操作记录同步到自己的目录镜像树里面

HDFS HA集群搭建
Step 1:集群基础环境准备
1.修改Linux主机名 /etc/hostname
2.修改IP /etc/sysconfig/network-scripts/ifcfg-ens33
3.修改主机名和IP的映射关系 /etc/hosts
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等 /etc/profile
7.集群时间同步
8.配置主备NN之间的互相免密登录
Step 2:HA集群规划
机器运行角色hadoop132-fatherNameode、zkfc、DataNode、Zookeeper、journal nodehadoop133NameNode、ZKFC、DataNode、journal nodehadoop134DataNode、zookeeper、journal node
Step 3 : 解压Hadoop
环境变量搭建
由于之前环境变量已经进行过操作了,这里采用懒人模式,将原来的hadoop更改名称,然后重新解压一个新的,省事
Step 4 : Hadoop 配置文件配置
hadoop-env.sh
直接在最后几行加上这个
export JAVA_HOME=/opt/module/jdk1.8.0_301
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
core-site.xml
<configuration><!-- HA集群名称,该值要和hdfs-site.xml中的配置保持一致 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- hadoop本地磁盘存放数据的公共目录 --><property><name>hadoop.tmp.dir</name><value>/opt/data/ha-hadoop</value></property><!-- ZooKeeper集群的地址和端口--><property><name>ha.zookeeper.quorum</name><value>hadoop132-father:2181,hadoop133:2181,hadoop134:2181</value></property></configuration>
hdfs-site.xml
<configuration><!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- mycluster下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop132-father:8020</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop132-father:9870</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop133:8020</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop133:9870</value></property><!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop132-father:8485;hadoop133:8485;hadoop134:8485/mycluster</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/opt/data/journaldata</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 指定该集群出故障时,哪个实现类负责执行故障切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制方法--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property></configuration>
yarn-site.xml
<configuration><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop132-father</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop133</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>hadoop132-father:2181,hadoop133:2181,hadoop134:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
mapred-site.xml
<configuration><!-- 指定mr框架为yarn方式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
workers
此处是ip
hadoop132-father
hadoop133
hadoop134
Step 5 :分发到集群
这边直接采用老方法
rsync -av hadoop-3.3.1 root@hadoop133:/opt/modul/hadoop-3.3.1
执行之后以此类推,对hadoop134也进行相同的操作,即可完成
其他: zookeeper配置
高可用需要zookeeper来进行操作,所以需要安装zookeeper并搭建集群 zookeeper还没学,后续慢慢补上
zookeeper 下载与安装
zookeeper的安装地址 -点击直接下载,版本:3.7.1
下载后进行解压
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
解压后需要对配置文件进行修改
cd apache-zookeeper-3.7.1-bin/
mv apache-zookeeper-3.7.1-bin /opt/module/zookeeper # 移动到modulcd /opt/module/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
对配置文件进行编写:
server.1=hadoop132-father:2888:3888
server.2=hadoop133:2888:3888
server.3=hadoop134:2888:3888
dataDir=/opt/data/zookeeper #此处进行一个修改
随后在进行一个分发,大致与hadoop分发相同,这里就不再进行操作
启动zookeeper
进入到bin目录下
./zkServer.sh start
对各个都进行启动,随后查看状态
查看状态命令:
./zkServer.sh status
查看各个状态
hadoop132-father的状态:

hadoop133状态

hadoop134状态

当前状态有2个follower和1个leader
集群搭建完毕
Step 6:HA集群初始化
启动zookeeper
这里在集群搭建过程中已经进行了启动这里不再演示
手动启动JN集群
指令:
hdfs -daemon start journalnode
通过jps查看是否启动成功:

显然已经启动成功,随后将其他的机器都启动
格式化namenode
在hadoop132-father上进行格式化
hdfs namenode -faomat
到此我们就格式化成功
启动namenode进程
hdfs --daemon namemode
在hadoop133中进行namenode元数据同步
hdfs namenode --bootstrapStandby

表示已经成功
格式化ZKFC
注意: 在哪台机器上执行,那台机器就将成为第一次的Active NN
hdfs zkfc -formatZK

Step 6 : 启动HA
直接启动HDFS集群即可
直接启动全部
start-all.sh
可能会存在报错,报错我忘了说什么了,大概是因为meyarn没有指定用户啥的,需要填上,可以参考之前文章配置HDFS那里
查看启动效果:

该启动的都启动了,下播
HDFS HA效果演示
查看UI
去hadoop132-father里面进行查看

去查看hadoop133节点:

去浏览文件系统
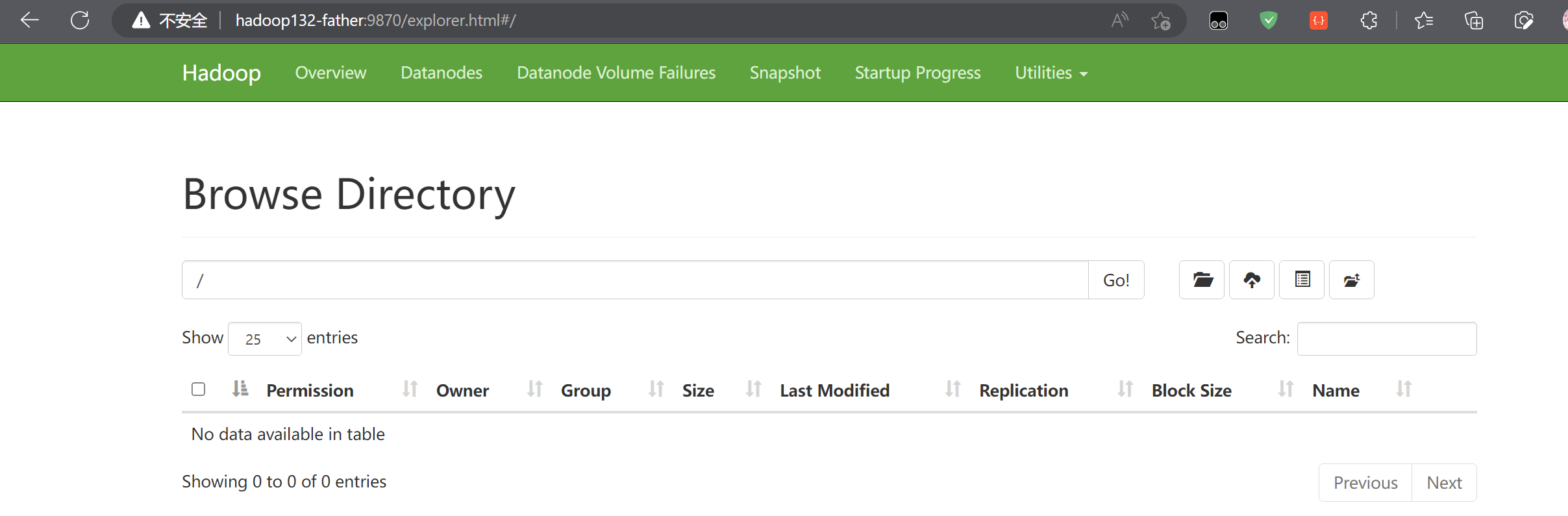
可以看到文件正常,虽然说没有任何文件 (🙆)
但是呢hadoop133就不乐观了
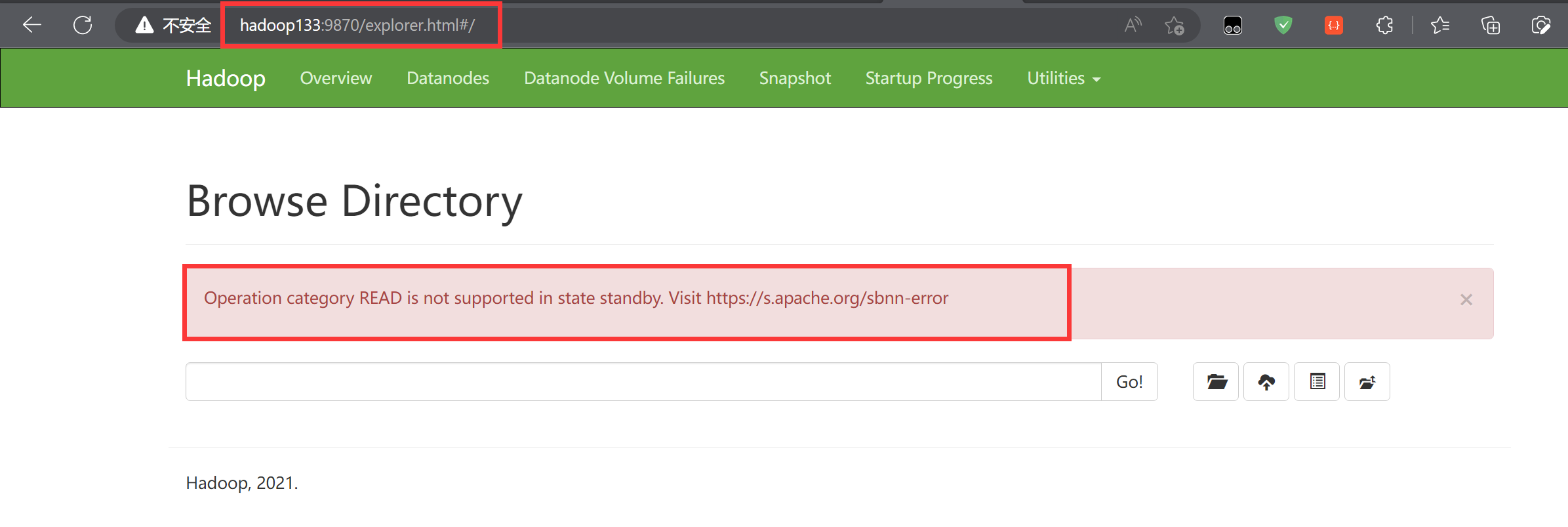
人家直接告诉你目前是准备状态,不支持读取操作
模拟宕机
我们手动的杀死hadoop132-father节点中的namenode查看是否能用
kill -9 namenode
这时候我们再次查看UI

发现hadoop133可以正常使用了而且叶转换成了active状态了
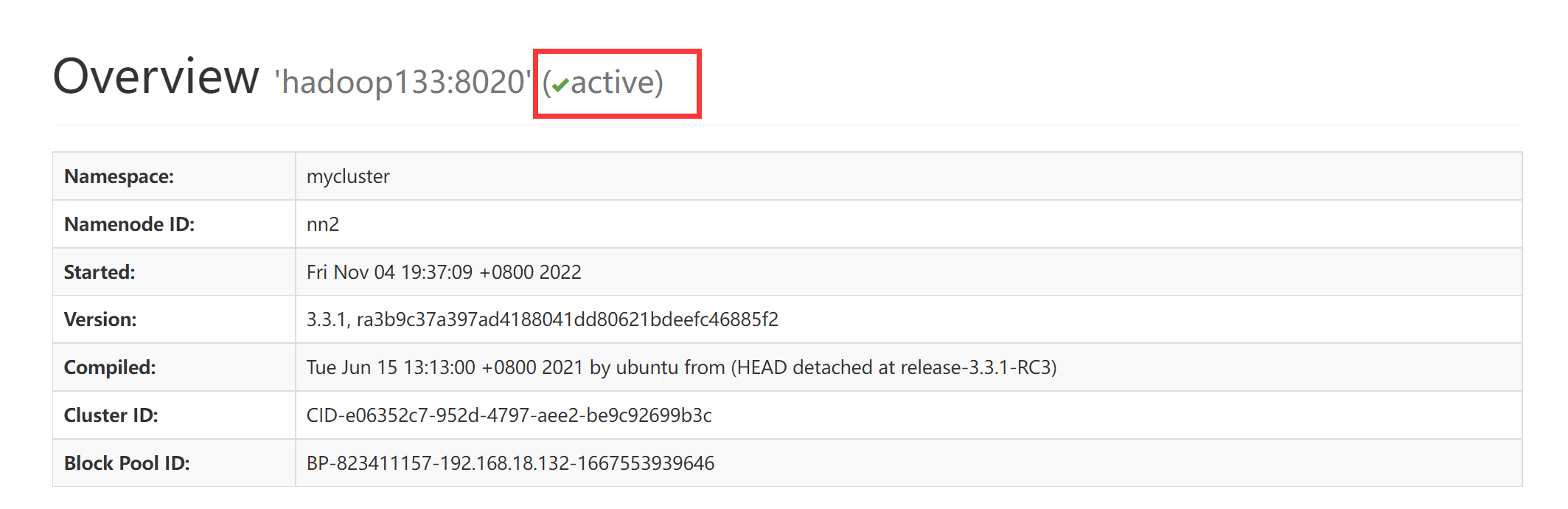
至于hadoop132-father 他就直接死掉了,页面都打不开了
其他
使用该方法一般情况下时会成功的,但是也会存在异常,可能会报
bash fuser:command not found
这样的异常,提示我们未找到fuser程序,导致无法进行隔离。可以通过以下命令来进行安装,Psmisc软件包中包含了fuser程序(需要注意的是,两个NN机器都得安装)
yum install psmisc -y

我这里是已经进行过安装了所以没有任何问题
版权归原作者 不知落叶何时落 所有, 如有侵权,请联系我们删除。