
目录
一 引言
在这篇文章中,我们将在一个全新的centos7 mini版的Linux虚拟机系统中,我们来安装一个Hadoop的分布式集群。这里推荐大家使用 xshell 去连接虚拟机。
二 介绍
hadoop的安装方式分为以下三种:
- 单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
- 伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
- 分布式模式:使用多个节点构成集群环境来运行Hadoop。
三 安装前的准备工作
- 首先需要一个新用户,并给予他root权限(一搜一大堆 👍)。
- 让虚拟机联网。 安装时,普遍都应该选择的为NAT(网络地址转换)模式,在这种模式下,首先使用 ip addr 查看ip地址,发现新的虚拟机是没有ip地址的,这是因为centos默认关闭了网卡。我们需要使用如下命令。
# 不同系统可能不一样 有的可能是ifcfg-ens34# 最好使用 ls /etc/sysconfig/network-scripts/ 查看下。sudovi /etc/sysconfig/network-scripts/ifcfg-ens33
然后按insert键,将里面的onboot = no 改为 onboot = yes ,并按 Esc -> :(中文冒号) -> wq 退出,然后再敲
sudoservice network restart # 重启网络服务
这下再 ip addr 就发现有ip地址了。
如果还没有的小伙伴也不要着急(博主在这里遇到好多次,不过也要微笑面对 ☀️),在VMware中,选择当前的虚拟机,然后在菜单栏的编辑选项中选择虚拟网络编辑器,查看一下以下两个选项是否勾选上,若没有,请勾选上,接下来应该就有ip地址了,就可以联网了。
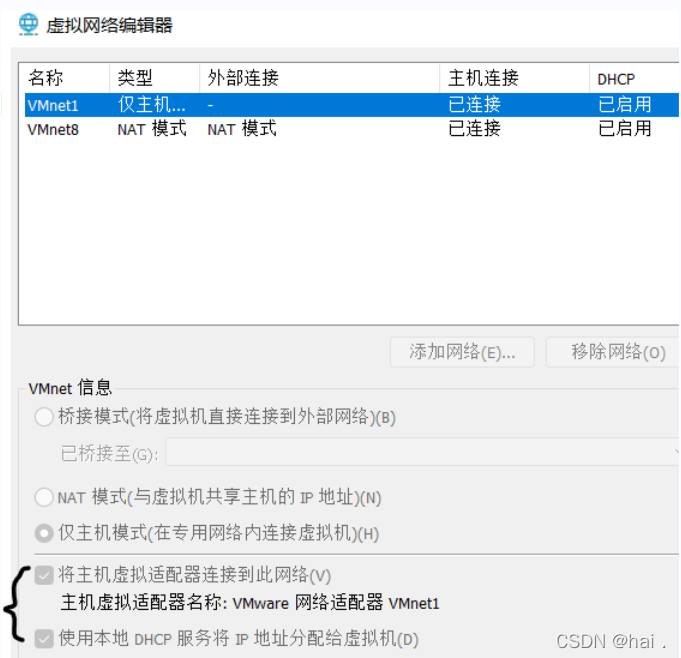
- 关闭防火墙 主要是为了方便集群内的通信。
systemctl stop firewalld 停止防火墙sudo systemctl disable firewalld 永久禁止防火墙开机自启 - 创建文件夹一般我们都在 /opt 目录下存放有关大数据体系的组件和安装文件。
cd /opt #sssudomkdir soft # 用于存放安装文件sudomkdir module # 用于存放 hadoop等组件的文件。同时将module和soft文件夹交给刚刚创建的新用户。# hai:hai :换为你自己的用户名 -> username:username。sudochown -R hai:hai /opt/soft /opt/module
四 正式开始
1 安装java环境
若系统自带JDK,要把系统自带的JDK卸载在安装java环境。
首先需要下载一个 安装包,博主使用的是这个版本:jdk-8u121-linux-x64.tar.gz。然后通过xshell(winscp等皆可)将这个压缩包传到linux系统的/opt/soft目录中,然后通过ls命令查看下上传成功与否。
下面通过tar命令解压到module目录下。
# -z:有zip属性的 -v:显示所有过程 -x:解压# -f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。tar -zxvf /opt/soft/jdk-8u121-linux-x64.tar.gz -C /opt/module

然后更改个名字,这个大家随意。
mv /opt/module/jdk1.8.0_121 /opt/module/jdk1.8.0
接下来配置环境变量(这里要注意先学会vi编辑器的使用)
sudovi /etc/profile
vi的使用方法如果不会可以查一下,很简单的。然后将下面的内容粘贴到文件最后。
JAVA_HOME=/opt/module/jdk1.8.0
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH
保存退出后使用 source /etc/profile 让刚刚配置的环境变量生效。
最后使用 java -version 检查java环境是否已经配好。
至此,Java环境安装完毕。
2 安装Hadoop
首先,和安装java时一样,需要一个安装包,我的是这个版本:hadoop-3.1.3.tar.gz,接着像java的安装包一样,通过xshell(winscp等皆可)将这个压缩包传到linux系统的/opt/soft目录中,然后通过ls命令查看下上传成功与否。
执行以下命令解压
tar -zxvf /opt/soft/hadoop-3.1.3.tar.gz -C /opt/module
配置环境变量
sudovi /etc/profile
# 将内容写到配置文件尾,java上面写了就不用了JAVA_HOME=/opt/module/jdk1.8.0
# hadoop家目录HADOOP_HOME=/opt/module/hadoop-3.1.3
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 导出export JAVA_HOME PATH HADOOP_HOME
保存退出后同样也要使用 source /etc/profile 让刚刚配置的环境变量生效(切记)。
这样输入
hadoop version
,只要出现了如下信息就说明环境变量配置成功。
接下来,我们可以去克隆虚拟机了!
3 克隆虚拟机
现将虚拟机关机,右键点击虚拟机,点击克隆。
选择虚拟机当前状态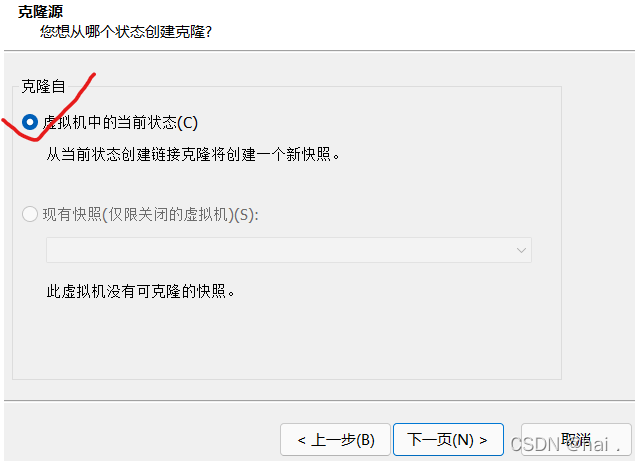
选择创建完整克隆
自定义虚拟机名称和克隆文件的存放位置。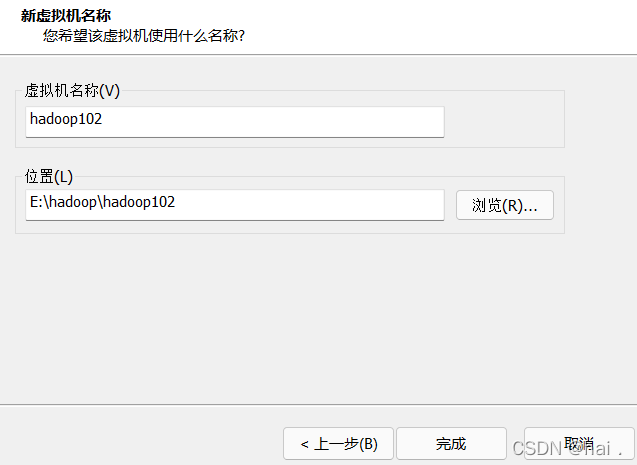
上面的操作再执行一次
,这样就拥有了3台虚拟机了。
4 更改主机名
一般我们会把/etc/hostname中原有名字全部删除,写入新的名字(hadoop101),这样可以区分各个主机。
# 三台虚拟机都执行这个命令sudovi /etc/hostname
第一台虚拟机中的内容改为:hadoop101
第二台虚拟机中的内容改为:hadoop102
第三台虚拟机中的内容改为:hadoop103
重启生效
。
5 映射IP地址和主机名
在三台主机中都要进行如下操作
:
sudovi /etc/hosts
配置主机和ip地址之间的映射关系(自己主机的ip不一样,按照自己的ip配置)。
6 配置ssh登录权限
主要是为了集群之间传输文件、跨主机操作等不用输入密码,方便。
- 在hadoop101机器上,切换到/home/hai/.ssh目录下(hai为用户名,更换为自己的),执行下面语句生成id。
ssh-keygen -t rsa # 执行后一直回车即可。
- 之后执行
ssh-copy-id hadoop101、ssh-copy-id hadoop102、ssh-copy-id hadoop103,就是将id发送到101、102和103上。
在其它两台机器上也执行上述1、2操作。同时将生成的公钥发送到集群中的所有主机。
7 配置Hadoop的配置文件
集群规划:
Hadoop101Hadoop102Hadoop103NamenodeResourcemanagerSecondarynamenodeDatanodeDatanodeDatanodeNodemanagerNodemanagerNodemanager
- 接着我们需要配置四个文件:
- 全局核心配置文件:core-site.xml
<!-- 决定Hadoop运行模式,hdfs:完全分布式运行的协议,固定到hadoop101,8020为端口号,常用的有8020,9000,9820 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 配置hadoop数据的存储临时目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置web端页面的静态用户,设置为自己的用户名 --><property><name>hadoop.http.staticuser.user</name><value>hai</value></property><!--定义HDFS所开放的代理服务 --><property><name>hadoop.proxyuser.hai.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hai.groups</name><value>*</value></property>
- HDFS配置文件:hdfs-site.xml
<property><!-- NameNode 的 web端访问地址(对用户的查询端口)--><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><!-- SecondaryNameNode 的 web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value></property>
- YARN配置文件:yarn-site.xml
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value></property><!-- 环境变量的继承 container--><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- nodemanager最多给多少内存给resourcemanager--><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!--检查物理内存,只要超出任务所给存储就杀死任务,所以这里配置false,避免杀死 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 检查虚拟内存--><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://hadoop102:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
- MapReduce配置文件:mapred-site.xml
<!-- mapreduce的配置 --><!--classic、local:使用本机一台的资源、yarn:使用集群的资源--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器运行机器以及端口 --><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value></property><!-- 历史服务器web端地址 19888,可以查看程序的历史运行情况--><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value></property>
- 配置到rsync发送文件在
三台机器中都要安装rsync:先检查是否安装了rpm -qa|grep rsync,没有安装的小伙伴再执行sudo yum install rsync(遇到选项按y),将配置的文件传输到hadoop102和hadoop103对应的目录中。
# hai@hadoop102 替换成 自己的用户名@自己的主机名rsync -av /opt/module/hadoop-3.1.3/etc/hadoop/ hai@hadoop102:/opt/module/hadoop-3.1.3/etc/hadoop/
rsync -av /opt/module/hadoop-3.1.3/etc/hadoop/ hai@hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop/
- 格式化namenoede 在配置namenode的机器上进行格式化namenode,我的是Hadoop101上,所以在Hadoop101上执行。
hadoop namenode -format
- 启动(分别启动)
Hadoop101命令:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
Hadoop102命令:
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
yarn-daemon.sh start resourcemanager
mapred --daemon start historyserver # 历史服务器的启动
Hadoop103命令:
hadoop-daemon.sh start secondarynamenode
yarn-daemon.sh start nodemanager
hadoop-daemon.sh start datanode
然后分别在三台机器上使用
jps
查看机器上对应的组件启动了没。
- 停止 就是把启动命令中的start替换成stop。当然第一次启动后,后面我们也可以写就集群启动、集群停止的脚本。
- 集群停止与启动 首先需要配置/opt/module/hadoop-3.1.3/etc/hadoop/workers中的内容为集群中的节点名称。
三台主机的这个文件都要配置。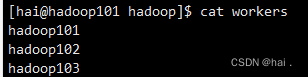 然后执行下面的命令启动了。
然后执行下面的命令启动了。
启动:
1.在hadoop101这台机器上执行
start-dfs.sh # 启动集群中HDFS的组件2.在hadoop102(因为ResourceManager配置在102中的)这台机器上执行
start-yarn.sh # 启动集群中的Yarn组件
停止:
1.在hadoop101这台机器上执行
stop-dfs.sh # 启动集群中HDFS的组件2.在hadoop102(因为ResourceManager配置在102中的)这台机器上执行
stop-yarn.sh # 启动集群中的Yarn组件
至此,Hadoop的基本配置工作就到此结束!
错误总结:
- 若出现找不到命令,则要配置hadoop-env.sh
版权归原作者 hai . 所有, 如有侵权,请联系我们删除。