
👨🎓 博主介绍:
IT邦德,江湖人称jeames007,10年DBA工作经验
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
(Web\java\Python)工作,主要服务于生产制造
现拥有 Oracle 11g OCP/OCM、
Mysql、Oceanbase(OBCA)认证
分布式TBase\TDSQL数据库、国产达梦数据库以及红帽子认证
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,
安装迁移,性能优化、故障应急处理等。
文章目录
前言
分析函数用于计算基于组的某种聚合值,能够实现复杂的逻辑,本文做了详细的阐述~
🍁 一、分析函数语法
function_name(<argument>,<argument>...)over(<partition_Clause><orderby_Clause><windowing_Clause>);
🍃 1.1 参数详解
function_name():函数名称
argument:参数
over( ):开窗函数
partition_Clause:分区子句,数据记录集分组,group by…
order by_Clause:排序子句,数据记录集排序,order by…
windowing_Clause:开窗子句,定义分析函数在操作行的集合,三种开窗方式:rows、range、Specifying
注:使用开窗子句时一定要有排序子句!!!
🍃 1.2 常用分析函数
row_number() over(partition by … order by …)
rank() over(partition by … order by …)
dense_rank() over(partition by … order by …)
count() over(partition by … order by …)
max() over(partition by … order by …)
min() over(partition by … order by …)
sum() over(partition by … order by …)
avg() over(partition by … order by …)
first_value() over(partition by … order by …)
last_value() over(partition by … order by …)
lag() over(partition by … order by …)
lead() over(partition by … order by …)
🍁 二、汇总
1、count() over() :统计分区中各组的行数,partition by 可选,order by 可选
2、sum() over() :统计分区中记录的总和,partition by 可选,order by 可选
3、avg() over() :统计分区中记录的平均值,partition by 可选,order by 可选
4、min() over() :统计分区中记录的最小值,partition by 可选,order by 可选
5、 max() over() :统计分区中记录的最大值,partition by 可选,order by 可选
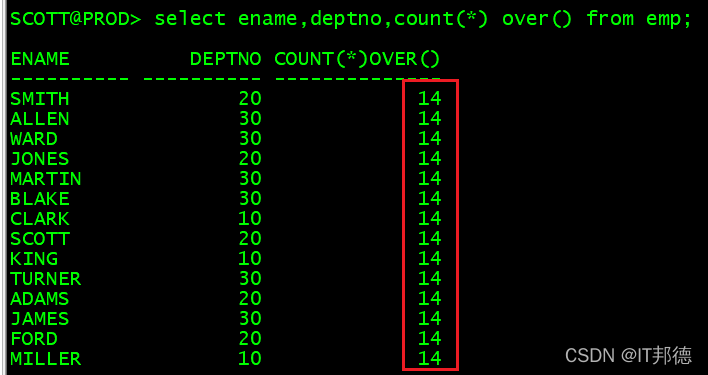
🍃 2.1 总计数
–总计数,统计所有行的总数
select ename,deptno,count(*) over() from emp;
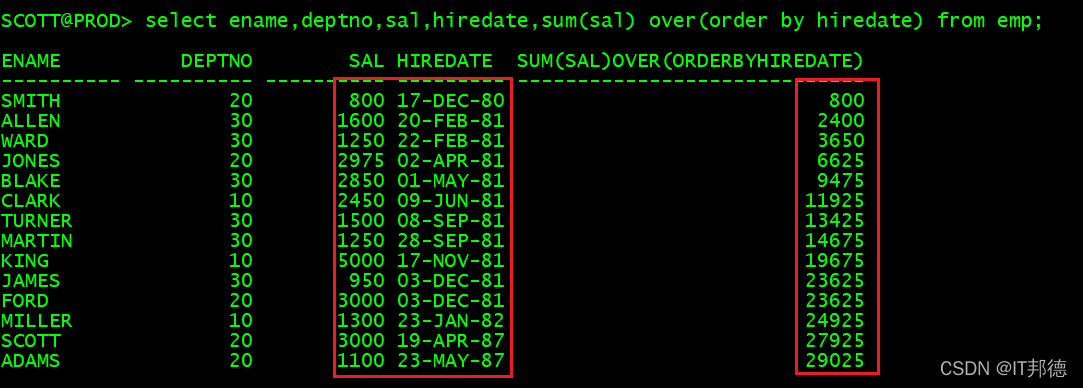
🍃 2.2 递加累计求和
–,先排序,再递加累计求和
select ename,deptno,sal,hiredate,sum(sal) over(order by hiredate) from emp;
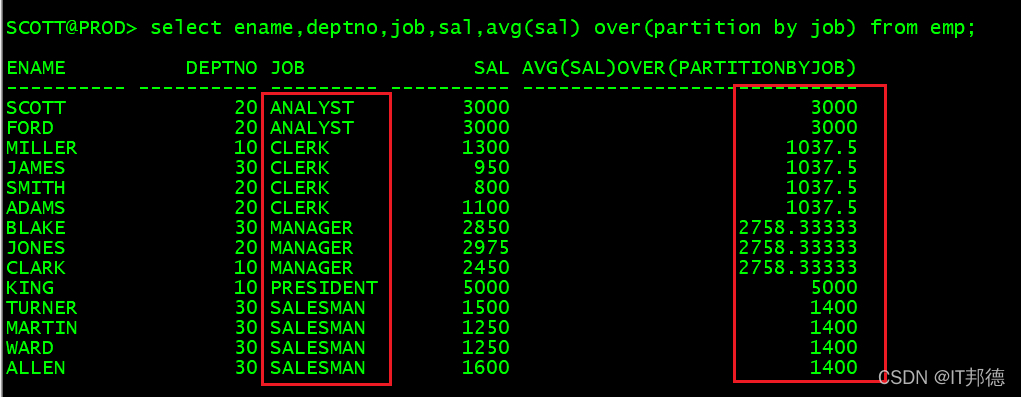
🍃 2.3 分组求平均值
–先分组,再对组内求平均值
select ename,deptno,job,sal,avg(sal) over(partition by job) from emp;
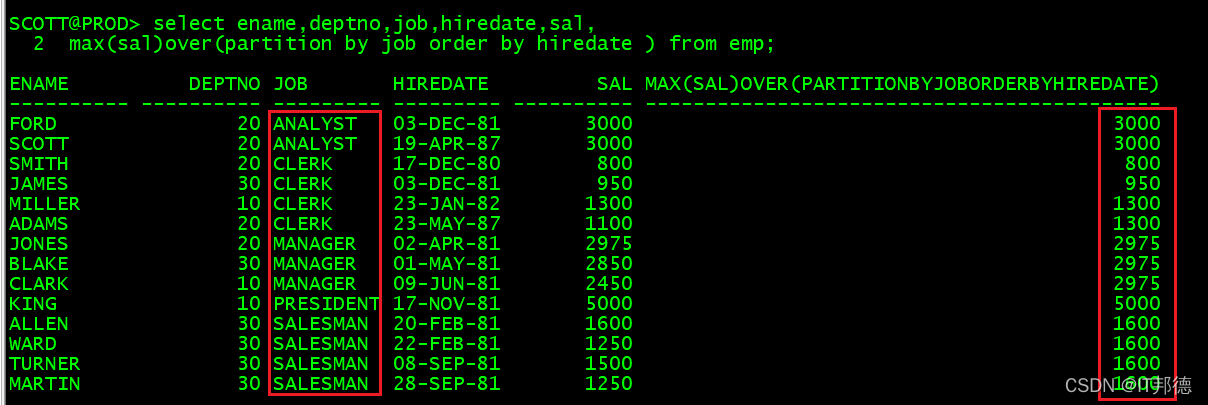
🍃 2.4 分组递加求最大
–先分组排序,再对组内求最大值
select ename,deptno,job,hiredate,sal,
max(sal)over(partition by job order by hiredate ) from emp;
🍁 三、排序
🍃 3.1 无重复值排序
row_number() over() :排序,无重复值,partition by 可选,order by 必选
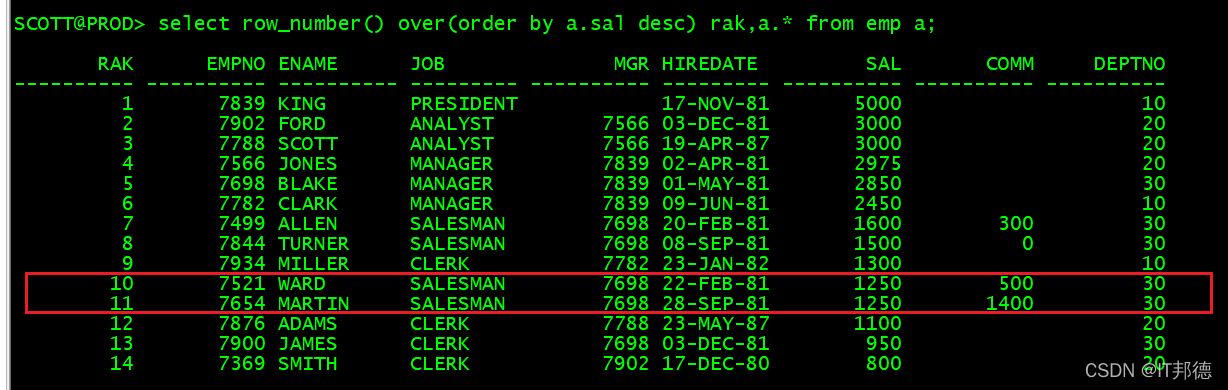
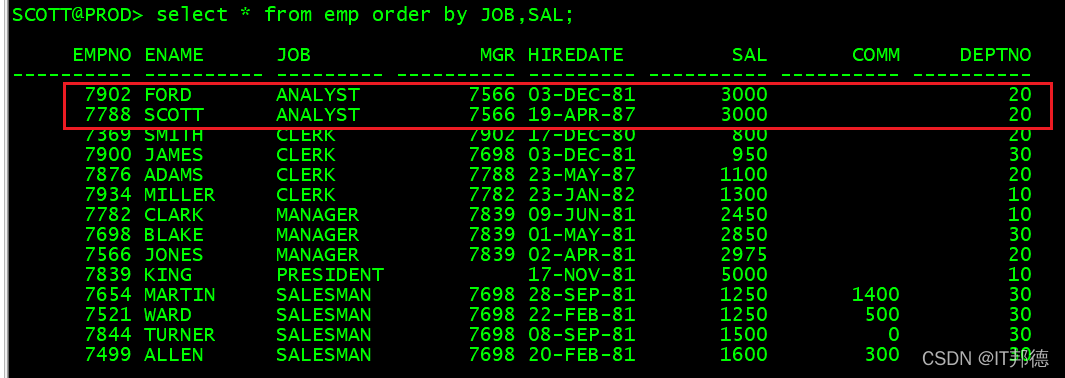
select row_number() over(order by a.sal desc) rak,a.* from emp a;
当SAL相同时,按顺序排序
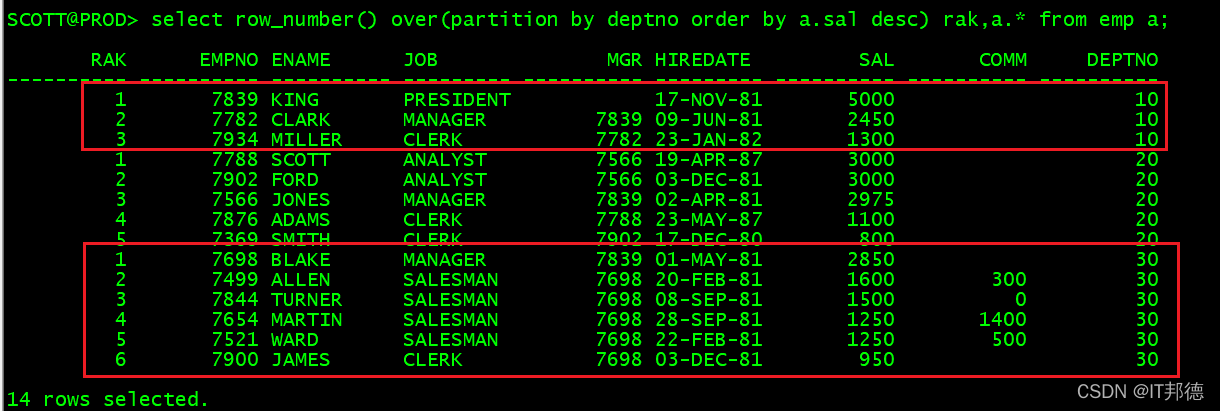
–先分组,再对组内排序,无重复值
select row_number() over(partition by deptno order by a.sal desc) rak,a.* from emp a;
🍃 3.2 排序连续
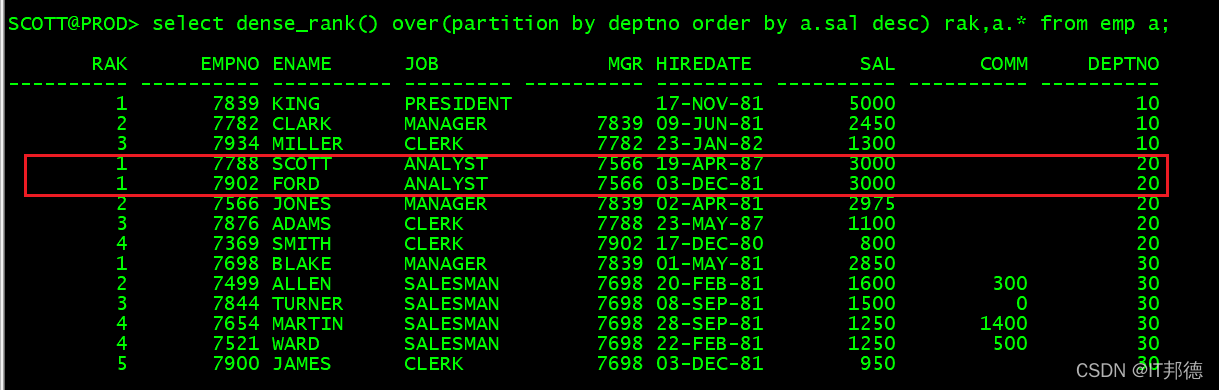
dense_rank() :连续排序,partition by 可选,order by 必选
–当值相同时,排序是连续的
select dense_rank() over(partition by deptno order by a.sal desc) rak,a.* from emp a;
🍃 3.3 排序跳跃
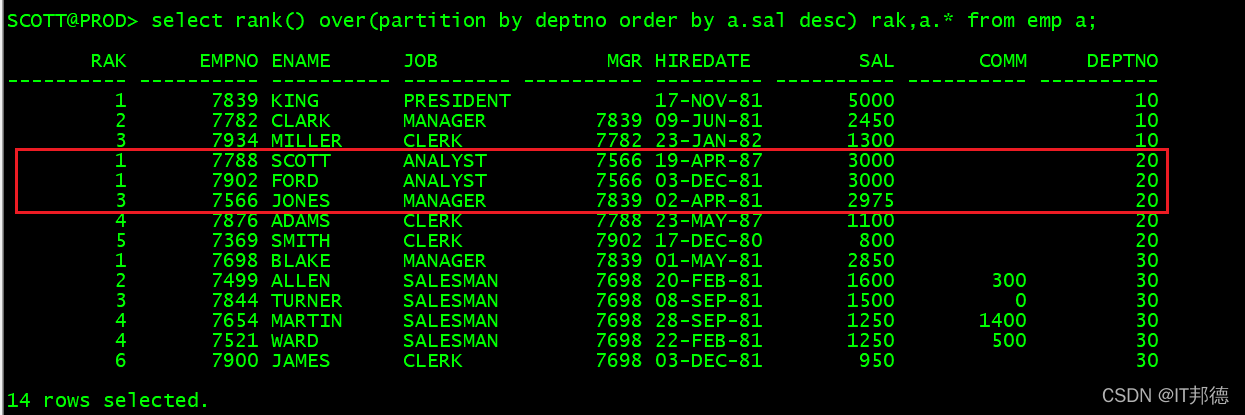
rank() over() :跳跃排序,partition by 可选,order by 必选
当值相同时,排序是跳跃的
select rank() over(partition by deptno order by a.sal desc) rak,a.* from emp a;、
🍁 四、KEEP函数
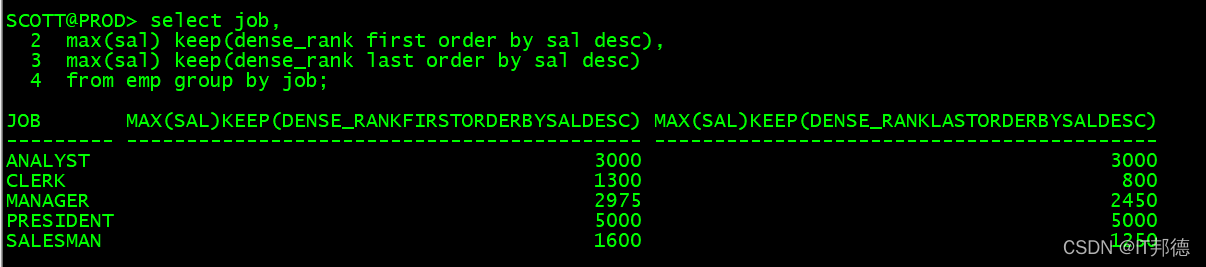
max(#) keep(dense_rank first order by # desc)
min(#) keep(dense_rank last order by # desc)
从DENSE_RANK返回的集合中取出排在最后面或者最前面的一个值的行
可能多行,因为值可能相等,因此完整的语法需要在开始处加上一个集合函数以从中取出记录
select job, max(sal) keep(dense_rank first order by sal desc), max(sal) keep(dense_rank last order by sal desc) from emp group by job;
🍁 五、开窗函数
指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化
50preceding:前50行
150following:后150行
UNBOUNDED :不受控的,无限的
currentrow 当前行
// 从当前行到最后的数据betweencurrentrowandunboundedfollowing//前面所有行与当前行的累加rowsbetweenunboundedprecedingandcurrentrow//前一行的值+当前行的值+后一行的值rowsbetween1precedingand1following//开始到结束的所有数据ROWSBETWEENUNBOUNDEDPRECEDINGANDUNBOUNDEDFOLLOWING
🍃 5.1 ROW窗口
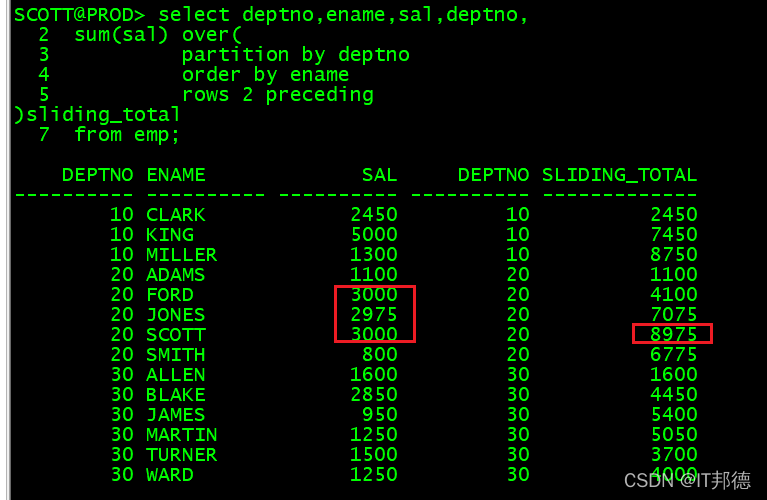
rows是物理窗口,在一组内基于任意变化或固定的窗口中,可以用该子句来让分析函数计算它的值
这将在一组内创建一个变化的窗口,请注意,要使用窗口,必须使用ORDER BY 子句
select deptno,ename,sal,deptno,sum(sal)over(partitionby deptno
orderby ename
rows2preceding)sliding_total
from emp
🍃 5.2 Range窗口
range是逻辑窗口,是对范围进行统计
是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内
有数字,记住precding,就是减,following是加, 统计在这个范围内的数据
rows表示行,就是前n行,后n行
而range表示的是具体的值,比这个值小n的行,比这个值大n的行
range between是以当前值为锚点进行计算
range between 4 preceding AND 7 following
表示:如果当前值为10的话就取前后的值在6到17之间的数据。
sum(close) range between 100 preceding and 200 following
表示:通过字段差值来进行选择。如当前行的 close 字段值是 200,
那么这个窗口大小的定义就会选择分区中 close 字段值落在 100 至 400 区间的记录(行)。
select ename,hiredate,sal,deptno,sum(sal)over(partitionby deptno orderby sal asc range 100preceding) sum_sal
from emp;

大家点赞、收藏、关注、评论啦 👇🏻👇🏻👇🏻微信公众号👇🏻👇🏻👇🏻
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。